
As assinaturas de pensamento são representações criptografadas do processo de raciocínio interno do modelo. As assinaturas de pensamento preservam o estado de raciocínio do Gemini durante conversas de várias etapas e turnos, o que pode ser útil ao usar chamadas de função. As respostas podem incluir um campo thought_signature em qualquer parte do conteúdo (por exemplo, text, functionCall).
Os modelos do Gemini 3 aplicam uma validação mais rigorosa nas assinaturas de pensamento do que as versões anteriores do Gemini porque melhoram a performance do modelo para chamadas de função. Para garantir que o modelo mantenha o contexto completo em vários turnos de uma conversa, retorne as assinaturas de pensamento das respostas anteriores nas solicitações subsequentes, mesmo ao usar níveis de pensamento MINIMAL. Se uma assinatura de pensamento obrigatória não for retornada ao usar
modelos do Gemini 3, o modelo vai retornar um erro 400.
Embora o Gemini 3 Pro Image não exija essa validação, para garantir que o modelo mantenha o contexto completo em várias trocas de uma conversa, você ainda precisa retornar as assinaturas de pensamento das respostas anteriores nas suas solicitações subsequentes. O Gemini 3 Pro Image não retorna um erro 400 se uma assinatura de pensamento não for retornada. Para exemplos de código relacionados à edição de imagens em várias etapas
usando o Gemini 3 Pro Image, consulte
Exemplo de edição de imagens em várias etapas usando assinaturas de pensamento.
Se você estiver usando o SDK oficial de IA generativa do Google (Python, Node.js, Go ou Java) e os recursos padrão de histórico de chat ou anexando a resposta completa do modelo ao histórico, as assinaturas de pensamento serão processadas automaticamente.
Por que elas são importantes?
Quando um modelo de raciocínio chama uma ferramenta externa, ele pausa o processo de raciocínio interno. A assinatura de pensamento funciona como um "estado de salvamento", permitindo que o modelo retome a cadeia de pensamento sem problemas assim que você fornecer o resultado da função. Sem assinaturas de pensamento, o modelo "esquece" as etapas específicas de raciocínio durante a fase de execução da ferramenta. Ao transmitir a assinatura de volta, você garante:
- Continuidade do contexto:o modelo preserva e pode verificar as etapas de raciocínio que justificaram a chamada da ferramenta.
- Raciocínio complexo:permite tarefas de várias etapas em que a saída de uma ferramenta informa o raciocínio para a próxima.
Turnos e etapas
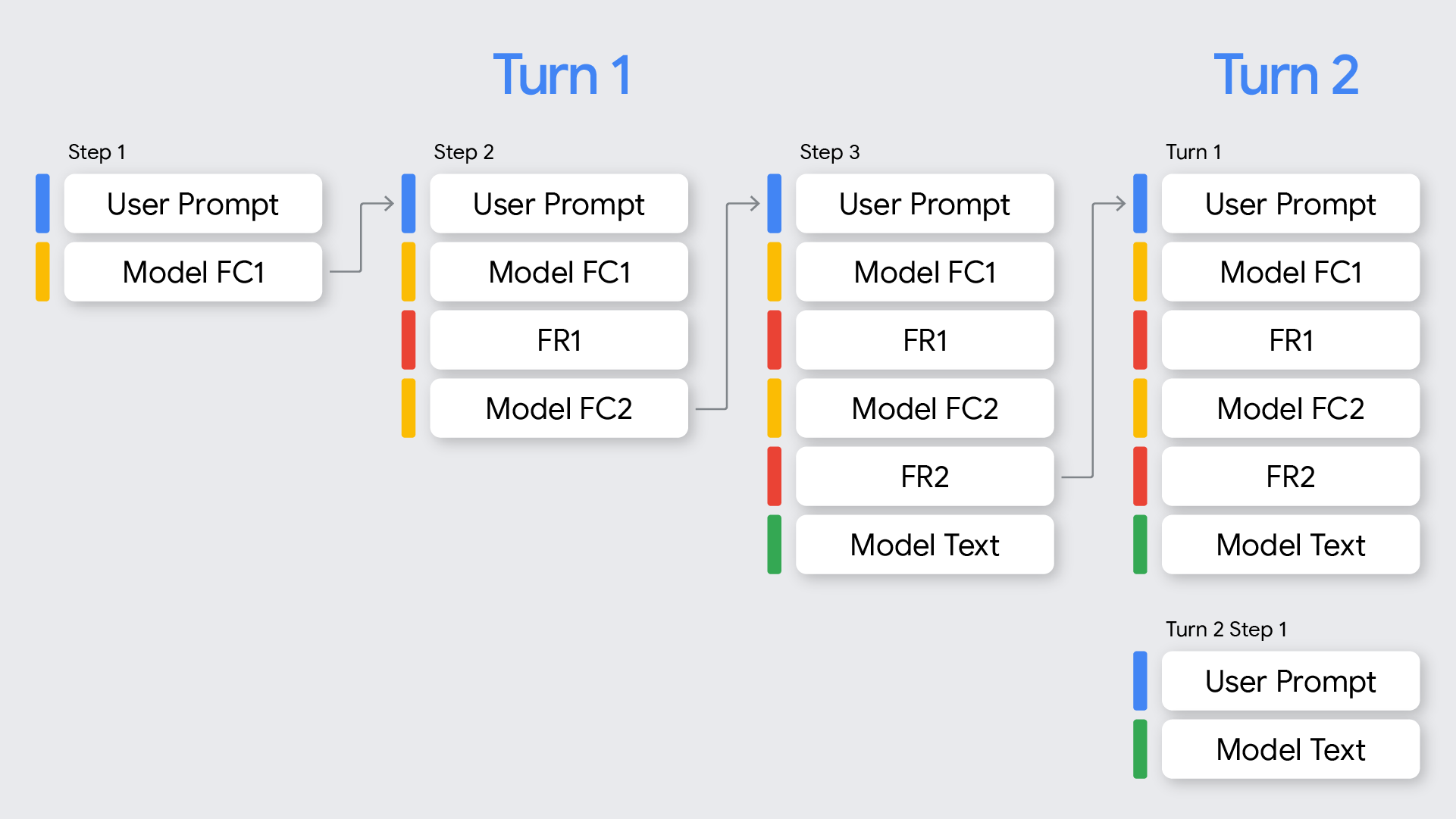
No contexto da chamada de função, é importante entender a diferença entre rodadas e etapas:
- Uma rodada representa uma troca de conversa completa, começando com um comando do usuário e terminando quando o modelo fornece uma resposta final, sem chamada de função, a esse comando.
- Uma etapa ocorre em uma única vez quando o modelo invoca uma função e exige uma resposta de função para continuar o processo de raciocínio. Como mostrado no diagrama, uma única interação pode envolver várias etapas se o modelo precisar chamar várias funções em sequência para atender à solicitação do usuário.
Como usar assinaturas de pensamento
A maneira mais simples de lidar com assinaturas de pensamento é incluir todos os
Parts de todas as mensagens anteriores no histórico da conversa ao enviar uma
nova solicitação, exatamente como foram retornados pelo modelo.
Se você não estiver usando um dos SDKs de IA generativa do Google ou precisar modificar ou reduzir o histórico de conversas, verifique se as assinaturas de pensamento são preservadas e enviadas de volta ao modelo.
Ao usar o SDK da IA generativa do Google (recomendado)
Ao usar os recursos de histórico de chat dos SDKs ou anexar o objeto content do modelo da resposta anterior ao contents da próxima solicitação, as assinaturas são processadas automaticamente.
O exemplo de Python a seguir mostra o processamento automático:
from google import genai
from google.genai.types import Content, FunctionDeclaration, GenerateContentConfig, Part, ThinkingConfig, Tool
client = genai.Client()
# 1. Define your tool
get_weather_declaration = FunctionDeclaration(
name="get_weather",
description="Gets the current weather temperature for a given location.",
parameters={
"type": "object",
"properties": {"location": {"type": "string"}},
"required": ["location"],
},
)
get_weather_tool = Tool(function_declarations=[get_weather_declaration])
# 2. Send a message that triggers the tool
prompt = "What's the weather like in London?"
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=prompt,
config=GenerateContentConfig(
tools=[get_weather_tool],
thinking_config=ThinkingConfig(include_thoughts=True)
),
)
# 3. Handle the function call
function_call = response.function_calls[0]
location = function_call.args["location"]
print(f"Model wants to call: {function_call.name}")
# Execute your tool (for example, call an API)
# (This is a mock response for the example)
print(f"Calling external tool for: {location}")
function_response_data = {
"location": location,
"temperature": "30C",
}
# 4. Send the tool's result back
# Append this turn's messages to history for a final response.
# The `content` object automatically attaches the required thought_signature behind the scenes.
history = [
Content(role="user", parts=[Part(text=prompt)]),
response.candidates[0].content, # Signature preserved here
Content(
role="tool",
parts=[
Part.from_function_response(
name=function_call.name,
response=function_response_data,
)
],
)
]
response_2 = client.models.generate_content(
model="gemini-2.5-flash",
contents=history,
config=GenerateContentConfig(
tools=[get_weather_tool],
thinking_config=ThinkingConfig(include_thoughts=True)
),
)
# 5. Get the final, natural-language answer
print(f"\nFinal model response: {response_2.text}")
Ao usar REST ou processamento manual
Se você estiver interagindo diretamente com a API, implemente o processamento de assinaturas com base nas seguintes regras para o Gemini 3 Pro:
- Chamada de função:
- Se a resposta do modelo contiver uma ou mais partes
functionCall, umthought_signatureserá necessário para o processamento correto. - Em casos de chamadas de função paralelas em uma única resposta, apenas a
parte
functionCallprimeira vai conter othought_signature. - Em casos de chamadas de função sequenciais em várias etapas de um turno,
cada parte
functionCallvai conter umthought_signature. - Regra: ao criar a próxima solicitação, inclua o
partque contém ofunctionCalle othought_signatureexatamente como foi retornado pelo modelo. Para chamadas de função sequenciais (em várias etapas), a validação é realizada em todas as etapas da vez atual. Omitir umthought_signatureobrigatório para a primeira partefunctionCallem qualquer etapa da vez atual resulta em um erro400. Uma interação começa com a mensagem mais recente do usuário que não é umfunctionResponse. - Se o modelo retornar chamadas de função paralelas (por exemplo,
FC1+signature,FC2), sua resposta precisará conter todas as chamadas de função seguidas de todas as respostas de função (FC1+signature,FC2,FR1,FR2). Intercalar respostas (FC1+signature,FR1,FC2,FR2) resulta em um erro400. - Em casos raros, é necessário fornecer partes de
functionCallque não foram geradas pela API e, portanto, não têm uma assinatura de pensamento associada. Por exemplo, ao transferir o histórico de um modelo que não inclui assinaturas de pensamento. Você pode definirthought_signaturecomoskip_thought_signature_validator, mas isso deve ser um último recurso, já que afeta negativamente o desempenho do modelo.
- Se a resposta do modelo contiver uma ou mais partes
- Chamada não funcional:
- Se a resposta do modelo não tiver um
functionCall, ela poderá incluir umthought_signatureno últimopartda resposta (por exemplo, a última partetext). - Regra: incluir essa assinatura na próxima solicitação é recomendado para ter a melhor performance, mas omitir não vai causar um erro. Ao fazer streaming, essa assinatura pode ser retornada em uma parte com conteúdo de texto vazio. Portanto, analise todas as partes até que
finish_reasonseja retornado pelo modelo.
- Se a resposta do modelo não tiver um
Siga estas regras para garantir que o contexto do modelo seja preservado:
- Sempre envie o
thought_signaturede volta ao modelo dentro doPartoriginal. - Não mescle um
Partcom uma assinatura e outro sem. Isso quebra o contexto posicional do pensamento. - Não combine dois
Parts que contenham assinaturas, porque as strings de assinatura não podem ser mescladas.
Exemplo de chamada de função sequencial
O exemplo a seguir mostra uma chamada de função de várias etapas em que o usuário pergunta "Verifique o status do voo AA100 e reserve um táxi se houver atraso", o que exige várias tarefas.
REST
O exemplo a seguir demonstra como processar assinaturas de pensamento em várias etapas em um fluxo de trabalho sequencial de chamada de função usando a API REST.
Turno 1, etapa 1 (solicitação do usuário)
{ "contents": [ { "role": "user", "parts": [ { "text": "Check flight status for AA100 and book a taxi 2 hours before if delayed." } ] } ], "tools": [ { "functionDeclarations": [ { "name": "check_flight", "description": "Gets the current status of a flight", "parameters": { "type": "object", "properties": { "flight": { "type": "string", "description": "The flight number to check" } }, "required": [ "flight" ] } }, { "name": "book_taxi", "description": "Book a taxi", "parameters": { "type": "object", "properties": { "time": { "type": "string", "description": "time to book the taxi" } }, "required": [ "time" ] } } ] } ] }
Turno 1, etapa 1 (resposta do modelo)
{ "content": { "role": "model", "parts": [ { "functionCall": { "name": "check_flight", "args": { "flight": "AA100" } }, "thoughtSignature": "<SIGNATURE_A>" } ] } }
Turno 1, etapa 2 (resposta do usuário: envio de saídas da ferramenta)
Como essa vez do usuário contém apenas um functionResponse (sem texto novo), ainda estamos na vez 1. É necessário preservar <SIGNATURE_A>.
{ "role": "user", "parts": [ { "text": "Check flight status for AA100 and book a taxi 2 hours before if delayed." } ] }, { "role": "model", "parts": [ { "functionCall": { "name": "check_flight", "args": { "flight": "AA100" } }, "thoughtSignature": "<SIGNATURE_A>" } ] }, { "role": "user", "parts": [ { "functionResponse": { "name": "check_flight", "response": { "status": "delayed", "departure_time": "12 PM" } } } ] }
Turno 1, etapa 2 (resposta do modelo)
Agora, o modelo decide reservar um táxi com base na saída da ferramenta anterior.
{ "content": { "role": "model", "parts": [ { "functionCall": { "name": "book_taxi", "args": { "time": "10 AM" } }, "thoughtSignature": "<SIGNATURE_B>" } ] } }
Turno 1, etapa 3 (resposta do usuário: envio da saída da ferramenta)
Para enviar a confirmação da reserva de táxi, inclua assinaturas para todas
as chamadas de função neste loop (<SIGNATURE_A> e <SIGNATURE_B>).
{ "role": "user", "parts": [ { "text": "Check flight status for AA100 and book a taxi 2 hours before if delayed." } ] }, { "role": "model", "parts": [ { "functionCall": { "name": "check_flight", "args": { "flight": "AA100" } }, "thoughtSignature": "<SIGNATURE_A>" } ] }, { "role": "user", "parts": [ { "functionResponse": { "name": "check_flight", "response": { "status": "delayed", "departure_time": "12 PM" } } } ] }, { "role": "model", "parts": [ { "functionCall": { "name": "book_taxi", "args": { "time": "10 AM" } }, "thoughtSignature": "<SIGNATURE_B>" } ] }, { "role": "user", "parts": [ { "functionResponse": { "name": "book_taxi", "response": { "booking_status": "success" } } } ] } }
Conclusões de chat
O exemplo a seguir demonstra como processar assinaturas de pensamento em várias etapas de um fluxo de trabalho sequencial de chamada de função usando a API Chat Completions.
Turno 1, etapa 1 (solicitação do usuário)
{ "model": "google/gemini-3-pro-preview", "messages": [ { "role": "user", "content": "Check flight status for AA100 and book a taxi 2 hours before if delayed." } ], "tools": [ { "type": "function", "function": { "name": "check_flight", "description": "Gets the current status of a flight", "parameters": { "type": "object", "properties": { "flight": { "type": "string", "description": "The flight number to check." } }, "required": [ "flight" ] } } }, { "type": "function", "function": { "name": "book_taxi", "description": "Book a taxi", "parameters": { "type": "object", "properties": { "time": { "type": "string", "description": "time to book the taxi" } }, "required": [ "time" ] } } } ] }
Turno 1, etapa 1 (resposta do modelo)
{ "role": "model", "tool_calls": [ { "extra_content": { "google": { "thought_signature": "<SIGNATURE_A>" } }, "function": { "arguments": "{\"flight\":\"AA100\"}", "name": "check_flight" }, "id": "function-call-1", "type": "function" } ] }
Turno 1, etapa 2 (resposta do usuário: envio de saídas da ferramenta)
Como essa vez do usuário contém apenas um functionResponse (sem texto novo), ainda estamos na vez 1. É necessário preservar <SIGNATURE_A>.
"messages": [ { "role": "user", "content": "Check flight status for AA100 and book a taxi 2 hours before if delayed." }, { "role": "model", "tool_calls": [ { "extra_content": { "google": { "thought_signature": "<SIGNATURE_A>" } }, "function": { "arguments": "{\"flight\":\"AA100\"}", "name": "check_flight" }, "id": "function-call-1", "type": "function" } ] }, { "role": "tool", "name": "check_flight", "tool_call_id": "function-call-1", "content": "{\"status\":\"delayed\",\"departure_time\":\"12 PM\"}" } ]
Turno 1, etapa 2 (resposta do modelo)
Agora, o modelo decide reservar um táxi com base na saída da ferramenta anterior.
{ "role": "model", "tool_calls": [ { "extra_content": { "google": { "thought_signature": "<SIGNATURE_B>" } }, "function": { "arguments": "{\"time\":\"10 AM\"}", "name": "book_taxi" }, "id": "function-call-2", "type": "function" } ] }
Turno 1, etapa 3 (resposta do usuário: envio da saída da ferramenta)
Para enviar a confirmação da reserva de táxi, inclua assinaturas para todas
as chamadas de função neste loop (<SIGNATURE_A> e <SIGNATURE_B>).
"messages": [ { "role": "user", "content": "Check flight status for AA100 and book a taxi 2 hours before if delayed." }, { "role": "model", "tool_calls": [ { "extra_content": { "google": { "thought_signature": "<SIGNATURE_A>" } }, "function": { "arguments": "{\"flight\":\"AA100\"}", "name": "check_flight" }, "id": "function-call-1d6a1a61-6f4f-4029-80ce-61586bd86da5", "type": "function" } ] }, { "role": "tool", "name": "check_flight", "tool_call_id": "function-call-1d6a1a61-6f4f-4029-80ce-61586bd86da5", "content": "{\"status\":\"delayed\",\"departure_time\":\"12 PM\"}" }, { "role": "model", "tool_calls": [ { "extra_content": { "google": { "thought_signature": "<SIGNATURE_B>" } }, "function": { "arguments": "{\"time\":\"10 AM\"}", "name": "book_taxi" }, "id": "function-call-65b325ba-9b40-4003-9535-8c7137b35634", "type": "function" } ] }, { "role": "tool", "name": "book_taxi", "tool_call_id": "function-call-65b325ba-9b40-4003-9535-8c7137b35634", "content": "{\"booking_status\":\"success\"}" } ]
Exemplo de chamada de função paralela
O exemplo a seguir mostra uma chamada de função paralela em que o usuário pergunta "Confira o clima em Paris e Londres".
REST
O exemplo a seguir demonstra como processar assinaturas de pensamento em um fluxo de trabalho de chamada de função paralela usando a API REST.
Turno 1, etapa 1 (solicitação do usuário)
{ "contents": [ { "role": "user", "parts": [ { "text": "Check the weather in Paris and London." } ] } ], "tools": [ { "functionDeclarations": [ { "name": "get_current_temperature", "description": "Gets the current temperature for a given location.", "parameters": { "type": "object", "properties": { "location": { "type": "string", "description": "The city name, e.g. San Francisco" } }, "required": [ "location" ] } } ] } ] }
Turno 1, etapa 1 (resposta do modelo)
{ "content": { "parts": [ { "functionCall": { "name": "get_current_temperature", "args": { "location": "Paris" } }, "thoughtSignature": "<SIGNATURE_A>" }, { "functionCall": { "name": "get_current_temperature", "args": { "location": "London" } } } ] } }
Turno 1, etapa 2 (resposta do usuário: envio de saídas da ferramenta)
Preserve <SIGNATURE_A> na primeira parte exatamente como recebido.
[ { "role": "user", "parts": [ { "text": "Check the weather in Paris and London." } ] }, { "role": "model", "parts": [ { "functionCall": { "name": "get_current_temperature", "args": { "city": "Paris" } }, "thought_signature": "<SIGNATURE_A>" }, { "functionCall": { "name": "get_current_temperature", "args": { "city": "London" } } } ] }, { "role": "user", "parts": [ { "functionResponse": { "name": "get_current_temperature", "response": { "temp": "15C" } } }, { "functionResponse": { "name": "get_current_temperature", "response": { "temp": "12C" } } } ] } ]
Conclusões de chat
O exemplo a seguir demonstra como processar assinaturas de pensamento em um fluxo de trabalho de chamada de função paralela usando a API Chat Completions.
Turno 1, etapa 1 (solicitação do usuário)
{ "contents": [ { "role": "user", "parts": [ { "text": "Check the weather in Paris and London." } ] } ], "tools": [ { "functionDeclarations": [ { "name": "get_current_temperature", "description": "Gets the current temperature for a given location.", "parameters": { "type": "object", "properties": { "location": { "type": "string", "description": "The city name, e.g. San Francisco" } }, "required": [ "location" ] } } ] } ] }
Turno 1, etapa 1 (resposta do modelo)
{ "role": "assistant", "tool_calls": [ { "extra_content": { "google": { "thought_signature": "<SIGNATURE_A>" } }, "function": { "arguments": "{\"location\":\"Paris\"}", "name": "get_current_temperature" }, "id": "function-call-f3b9ecb3-d55f-4076-98c8-b13e9d1c0e01", "type": "function" }, { "function": { "arguments": "{\"location\":\"London\"}", "name": "get_current_temperature" }, "id": "function-call-335673ad-913e-42d1-bbf5-387c8ab80f44", "type": "function" } ] }
Turno 1, etapa 2 (resposta do usuário: envio de saídas da ferramenta)
Preserve <SIGNATURE_A> na primeira parte exatamente como recebido.
"messages": [ { "role": "user", "content": "Check the weather in Paris and London." }, { "role": "assistant", "tool_calls": [ { "extra_content": { "google": { "thought_signature": "<SIGNATURE_A>" } }, "function": { "arguments": "{\"location\":\"Paris\"}", "name": "get_current_temperature" }, "id": "function-call-f3b9ecb3-d55f-4076-98c8-b13e9d1c0e01", "type": "function" }, { "function": { "arguments": "{\"location\":\"London\"}", "name": "get_current_temperature" }, "id": "function-call-335673ad-913e-42d1-bbf5-387c8ab80f44", "type": "function" } ] }, { "role":"tool", "name": "get_current_temperature", "tool_call_id": "function-call-f3b9ecb3-d55f-4076-98c8-b13e9d1c0e01", "content": "{\"temp\":\"15C\"}" }, { "role":"tool", "name": "get_current_temperature", "tool_call_id": "function-call-335673ad-913e-42d1-bbf5-387c8ab80f44", "content": "{\"temp\":\"12C\"}" } ]
Assinaturas em Parts que não são do functionCall
O Gemini também pode retornar um thought_signature no Part final de uma resposta, mesmo que nenhuma chamada de função esteja presente.
- Comportamento:o conteúdo final
Part(text,inlineDataetc.) retornado pelo modelo pode conter umthought_signature. - Requisito:retornar essa assinatura é recomendado para garantir que o modelo mantenha um raciocínio de alta qualidade, principalmente para instruções complexas ou fluxos de trabalho simulados com agentes.
- Validação:a API não aplica estritamente a validação para
assinaturas em partes que não são
functionCall. Você não vai receber um erro de bloqueio se omitir esses dados, mas o desempenho pode ser prejudicado.
Exemplo de resposta do modelo com assinatura na parte de texto:
Os exemplos a seguir mostram uma resposta do modelo em que um thought_signature é incluído em um functionCall Part e como lidar com isso em uma solicitação subsequente.
Turno 1, etapa 1 (resposta do modelo)
{ "role": "model", "parts": [ { "text": "I need to calculate the risk. Let me think step-by-step...", "thought_signature": "<SIGNATURE_C>" // OPTIONAL (Recommended) } ] }
Turno 2, etapa 1 (usuário)
[ { "role": "user", "parts": [{ "text": "What is the risk?" }] }, { "role": "model", "parts": [ { "text": "I need to calculate the risk. Let me think step-by-step...", // If you omit <SIGNATURE_C> here, no error will occur. } ] }, { "role": "user", "parts": [{ "text": "Summarize it." }] } ]
Exemplo de edição de imagens em várias etapas usando assinaturas de pensamento
Os exemplos a seguir ilustram como recuperar e transmitir assinaturas de pensamento durante a criação e edição de imagens em várias etapas com o Gemini 3 Pro Image.
Turno 1: receber a resposta e salvar dados que incluem assinaturas de pensamento
chat = client.chats.create( model="gemini-3-pro-image-preview", config=types.GenerateContentConfig( response_modalities=['TEXT', 'IMAGE'] ) ) message = "Create an image of a clear perfume bottle sitting on a vanity." response = chat.send_message(message) data = b'' for part in response.candidates[0].content.parts: if part.text: display(Markdown(part.text)) if part.inline_data: data = part.inline_data.data display(Image(data=data, width=500))
Turno 2: transmita os dados que incluem assinaturas de pensamento
response = chat.send_message( message=[ types.Part.from_bytes( data=data, mime_type="image/png", ), "Make the perfume bottle purple and add a vase of hydrangeas next to the bottle.", ], ) for part in response.candidates[0].content.parts: if part.text: display(Markdown(part.text)) if part.inline_data: display(Image(data=part.inline_data.data, width=500))
A seguir
- Saiba mais sobre o Thinking.
- Saiba mais sobre a chamada de função.
- Saiba como criar comandos multimodais.