
Le moteur RAG Vertex AI propose différents modes de déploiement pour faire fonctionner vos instances RAG. Le mode de déploiement que vous choisissez détermine l'emplacement de stockage de vos données, la façon dont ce stockage évolue à mesure que vos données augmentent et le niveau de gestion de l'infrastructure dont vous avez besoin. En comprenant le fonctionnement de ces modes, vous pouvez choisir le bon équilibre entre simplicité, évolutivité et coûts pour votre projet.
Le moteur RAG Vertex AI propose deux modes de déploiement : sans serveur et Spanner. Vous pouvez passer d'un mode à l'autre facilement. Les données de chaque mode restent isolées des autres.
Modes de déploiement disponibles
Dans cette section, nous allons aborder les deux modes de déploiement disponibles pour le moteur RAG Vertex AI :
Mode sans serveur
Le mode sans serveur est le moyen le plus abordable et le plus recommandé pour commencer à utiliser le moteur RAG Vertex AI. Il s'agit d'une base de données entièrement gérée, à l'échelle mondiale et adaptée aux entreprises, qui élimine l'ensemble du provisionnement et du scaling de la base de données.
- Idéal pour : la plupart des utilisateurs, l'intégration rapide et le scaling fluide sans avoir à gérer les configurations d'infrastructure.
- Fonctionnalités clés : aucune gestion des niveaux n'est requise. Il utilise automatiquement Vertex AI Vector Search géré par RAG comme base de données vectorielle par défaut pour offrir une expérience RAG simplifiée et prête à l'emploi.
En mode sans serveur, la base de données gérée par RAG permet de gérer les opérations commerciales RAG et de stocker les ressources RAG. Ces ressources incluent, sans s'y limiter, RagCorpus, RagFiles, RagMetadata, DataSchema, etc. Toutefois, elles ne peuvent plus être utilisées pour l'indexation d'embedding et la recherche vectorielle.
Les utilisateurs devront toujours choisir une autre base de données vectorielle séparément. En mode "Sans serveur", le moteur RAG Vertex AI provisionne par défaut une collection Vertex AI Vector Search 2.0 dans votre projet pour l'indexation des embeddings et la recherche vectorielle. Par rapport au mode Spanner, le provisionnement de Vertex AI Vector Search 2.0 dans votre projet vous offre une visibilité et un contrôle complets sur l'utilisation et les coûts de la base de données vectorielle. Pour une comparaison détaillée, consultez la section Mode Spanner et mode sans serveur.
Mode Spanner
Le mode Spanner alloue une infrastructure Spanner dédiée spécifiquement pour servir de base à votre déploiement du moteur RAG Vertex AI. Elle est conçue pour les charges de travail qui nécessitent des fonctionnalités de conformité spécifiques (comme CMEK) ou des instances de base de données dédiées et isolées. Le mode Spanner est attribué par défaut si aucun mode n'est explicitement sélectionné.
Lorsque vous utilisez le mode Spanner, vous devez gérer votre infrastructure en sélectionnant un niveau de performances :
- Niveau de base (par défaut) : niveau à coût fixe et faible puissance de calcul, adapté aux expérimentations, aux petits volumes de données ou aux charges de travail peu sensibles à la latence.
- Niveau évolutif : offre des performances de niveau production avec une fonctionnalité d'autoscaling. Il convient aux clients disposant de grandes quantités de données ou de charges de travail sensibles aux performances.
Isolation des données et modes de commutation
Le moteur RAG Vertex AI vous permet de changer le mode de déploiement de votre projet tant qu'aucune opération n'est en cours dans votre mode de déploiement actif. Vous pouvez avoir des données dans les deux modes. Toutefois, un seul mode peut être actif à la fois, et les données sont strictement isolées entre les modes de déploiement.
Pour vous aider, imaginez que votre projet se comporte comme s'il disposait de deux backends complètement distincts. Les ressources que vous créez (corpus, fichiers importés et importés, et embeddings analysés) sont définitivement liées au mode de déploiement qui était actif lors de leur création. Toutes les demandes de récupération, directement ou via Gemini, seront également limitées aux corpus et aux fichiers présents dans votre mode de déploiement actuel. Passer d'un mode à l'autre ne transfère pas vos données ni ne les supprime de l'autre mode.
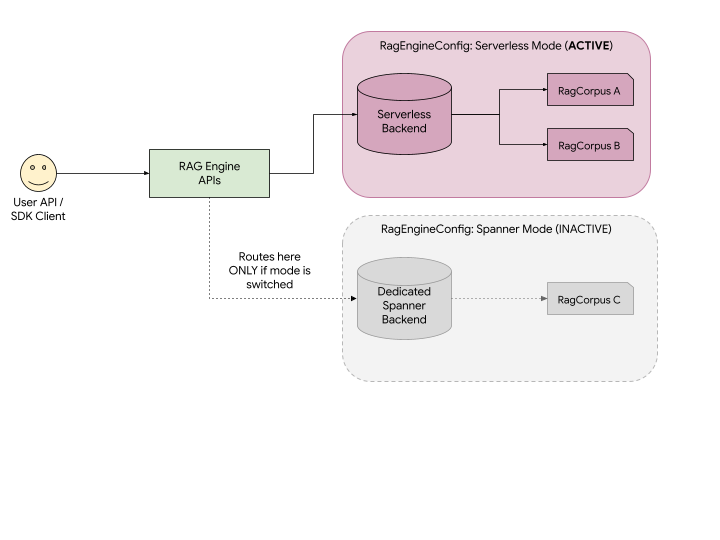
Comme illustré dans le schéma :
- API unifiée : vous utilisez exactement les mêmes API RAG Vertex AI pour créer et gérer des ressources. L'API achemine automatiquement vos requêtes vers le backend associé à votre mode de déploiement actif.
- Visibilité : si le mode sans serveur est actif, votre application ne peut voir et interagir qu'avec RagCorpus A et B. RagCorpus C, qui a été créé en mode Spanner, reste stocké de manière sécurisée, mais est complètement masqué et inaccessible à votre application tant que vous ne repassez pas en mode Spanner pour votre projet.
- Aucune perte de données : le changement de mode ne supprime pas vos données. Elle ne fait que modifier le "backend" que l'API examine.
Gérer votre mode de déploiement
Le mode de déploiement est un paramètre au niveau du projet. Vous pouvez afficher ou modifier votre mode actuel à l'aide des API GetRagEngineConfig et UpdateRagEngineConfig. Consultez la page Passer d'un mode à l'autre pour savoir comment passer d'un mode de déploiement à l'autre et choisir le niveau approprié pour votre mode Spanner.
Supprimer les données et arrêter la facturation
Étant donné que les données sont isolées entre les modes, les processus de nettoyage des ressources et d'arrêt de la facturation diffèrent légèrement selon l'emplacement de vos données.
- Pour supprimer des données Serverless, assurez-vous que votre mode actif est défini sur "Serverless". Appelez l'API
ListRagCorporapour afficher vos ressources, puis supprimez manuellement chaque corpus à l'aide de l'APIDeleteRagCorpus. - Pour supprimer des données Spanner (déprovisionnement), assurez-vous que votre mode actif est défini sur Spanner. Mettez à jour votre
RagEngineConfiget définissez le niveau Spanner surUnprovisioned. Votre instance Spanner dédiée et toutes les données RAG qu'elle contient seront immédiatement supprimées, ce qui mettra fin à toute facturation associée au mode Spanner. Remarque : Les données supprimées avec le niveau "Non provisionné" ne peuvent pas être récupérées.
Mode Spanner et mode sans serveur
| Fonctionnalité | Mode sans serveur | Mode Spanner |
|---|---|---|
| Coût |
|
|
| Scaling | Autoscaling entièrement géré | Vous devez configurer le niveau de service, mais il propose un niveau d'autoscaling. |
| Isolation | Le stockage n'est pas isolé | Fournit une isolation du stockage et des performances. |
| CMEK | Pas de CMEK pour le moment | Compatible avec CMEK |
| Contrôles de sécurité VPC | Compatible | Compatible |
| Bases de données vectorielles compatibles |
|
|
Étapes suivantes
- Pour commencer à utiliser le moteur RAG de Vertex AI, consultez le démarrage rapide RAG.
- Pour modifier votre mode de déploiement ou le niveau de votre mode Spanner, consultez Passer d'un mode à l'autre.
- Pour supprimer votre instance Spanner, consultez Passer au niveau non provisionné.
- Pour en savoir plus sur le mode Spanner, consultez Gérer le mode Spanner.
- Pour en savoir plus sur le mode sans serveur, consultez Mode sans serveur.
- Pour en savoir plus sur les tarifs, consultez Facturation du moteur RAG de Vertex AI.