

Important: Set the corpus description when creating a RAG corpus. The description is not editable after creation. High-quality descriptions are crucial for effective cross-corpus retrieval, as the system relies on them to select the appropriate corpora for your query.
This page describes two APIs, AsyncRetrieveContexts and AskContexts, that support RAG Cross Corpus Retrieval, powered by Agentic Retrieval in the backend.
AsyncRetrieveContexts API: This is an asynchronous API that allows users to retrieve relevant contexts from multiple RAG-managed corpora. This is a long-running API. Users can use the operation ID to get the status of the query and result.
AskContexts API: This is a synchronous API that directly generates the answer to the query by searching across multiple RAG-managed corpora.
Important: To use this feature, you must grant the Vertex AI User role in your project to the RAG Engine service account: service-[Your project's automatically generated project number]@gcp-sa-vertex-rag.iam.gserviceaccount.com.
Important: This feature is only available in us-central1.
System Architecture and Corpus Selection
This section describes the architecture of the RAG Cross Corpus Retrieval system and how it selects appropriate corpora for retrieval.
System Architecture
The Cross Corpus Retrieval system uses an agentic approach to orchestrate retrieval across multiple corpora. A high-level overview of the architecture includes the following components:
- Orchestrator/Router: Receives the user query and coordinates the retrieval process.
- Planning Agent: Analyzes the query and determines which corpora are most relevant based on their
descriptions. - Retrieval Engine: Performs semantic search on the selected RAG corpora.
- Reasoning Agent: Evaluates if the retrieved contexts are sufficient to answer the query. If insufficient, it generates feedback to trigger another retrieval loop based on Sufficient Context Awareness (SCA). For more details, see the SCA blog post and the research paper.
- LLM Generator (for
AskContexts): Synthesizes the retrieved contexts to generate a final answer.
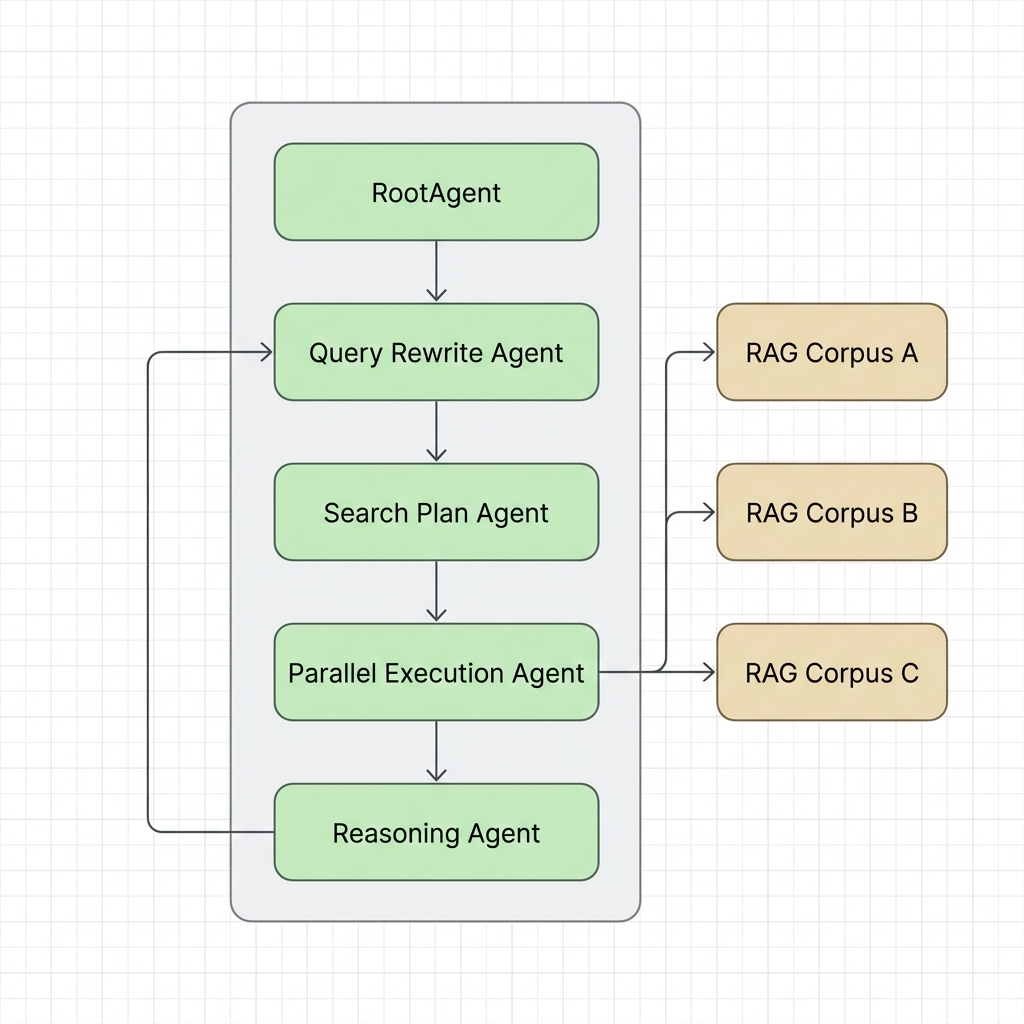
How Corpora are Selected
When a query is executed across multiple RAG managed corpora, the system must determine which corpus contains the information needed to answer the query. This is achieved through Agentic Retrieval:
- Corpus Mapping: The system maintains a map of available RAG corpora along with their technical descriptions (specified in the
descriptionfield of the RAG corpus). - Semantic Matching: A strategic planning agent (powered by a Gemini model) evaluates the user's query against the
descriptionsof the available corpora. - Targeted Routing: The planner generates a retrieval plan that maps specific parts of the query to the most relevant corpora, ensuring that retrieval is focused and efficient rather than searching all corpora naively.
Code Samples
The following code samples demonstrate how to use the RAG Cross Corpus Retrieval APIs.
AsyncRetrieveContexts API
This code sample demonstrates how to retrieve contexts from multiple RAG corpora asynchronously.
Python
from vertexai.preview import rag
import vertexai
PROJECT_ID = "PROJECT_ID"
LOCATION = "LOCATION"
RAG_CORPUS_1_ID = "RAG_CORPUS_1_ID"
RAG_CORPUS_2_ID = "RAG_CORPUS_2_ID"
# Initialize API once per session
vertexai.init(project=PROJECT_ID, location=LOCATION)
# Async retrieve contexts from multiple corpora
# This can be run in an environment like a Colab notebook.
response = await rag.async_retrieve_contexts(
text="Why is the sky blue?",
rag_resources=[
rag.RagResource(
rag_corpus=f"projects/{PROJECT_ID}/locations/{LOCATION}/ragCorpora/{RAG_CORPUS_1_ID}",
),
rag.RagResource(
rag_corpus=f"projects/{PROJECT_ID}/locations/{LOCATION}/ragCorpora/{RAG_CORPUS_2_ID}",
),
],
)
print(response)
REST
PROJECT_ID="PROJECT_ID"
LOCATION="LOCATION"
RAG_CORPUS_1_ID="RAG_CORPUS_1_ID"
RAG_CORPUS_2_ID="RAG_CORPUS_2_ID"
QUERY="Why is the sky blue?"
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
"https://${LOCATION}-aiplatform.googleapis.com/v1beta1/projects/${PROJECT_ID}/locations/${LOCATION}:asyncRetrieveContexts" \
-d '{
"query": {
"text": "'"$QUERY"'"
},
"tools": {
"retrieval": {
"disable_attribution": false,
"vertex_rag_store": {
"rag_resources": {
"rag_corpus": "projects/'"${PROJECT_ID}"'/locations/'"${LOCATION}"'/ragCorpora/'"${RAG_CORPUS_1_ID}"'"
},
"rag_resources": {
"rag_corpus": "projects/'"${PROJECT_ID}"'/locations/'"${LOCATION}"'/ragCorpora/'"${RAG_CORPUS_2_ID}"'"
}
}
}
}
}'
Get Operation Result
Since AsyncRetrieveContexts is a long-running operation, you can use the GetOperations API to poll for the result using the operation ID.
Python
from google.cloud import aiplatform_v1beta1
PROJECT_ID = "PROJECT_ID"
LOCATION = "LOCATION"
OPERATION_ID = "OPERATION_ID"
client = aiplatform_v1beta1.VertexRagServiceClient(
client_options={"api_endpoint": f"{LOCATION}-aiplatform.googleapis.com"}
)
operation = client.get_operation(
request={"name": f"projects/{PROJECT_ID}/locations/{LOCATION}/operations/{OPERATION_ID}"}
)
if operation.done:
print(operation.response)
else:
print("Operation is still running")
REST
PROJECT_ID="PROJECT_ID"
LOCATION="LOCATION"
OPERATION_ID="OPERATION_ID"
curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://${LOCATION}-aiplatform.googleapis.com/v1beta1/projects/${PROJECT_ID}/locations/${LOCATION}/operations/${OPERATION_ID}"
AskContexts API
This code sample demonstrates how to directly generate an answer by searching across multiple RAG corpora synchronously.
Python
from vertexai.preview import rag
import vertexai
PROJECT_ID = "PROJECT_ID"
LOCATION = "LOCATION"
RAG_CORPUS_1_ID = "RAG_CORPUS_1_ID"
RAG_CORPUS_2_ID = "RAG_CORPUS_2_ID"
# Initialize API once per session
vertexai.init(project=PROJECT_ID, location=LOCATION)
# Ask contexts from multiple corpora
response = rag.ask_contexts(
text="Why is the sky blue?",
rag_resources=[
rag.RagResource(
rag_corpus=f"projects/{PROJECT_ID}/locations/{LOCATION}/ragCorpora/{RAG_CORPUS_1_ID}",
),
rag.RagResource(
rag_corpus=f"projects/{PROJECT_ID}/locations/{LOCATION}/ragCorpora/{RAG_CORPUS_2_ID}",
),
],
)
print(response)
REST
PROJECT_ID="PROJECT_ID"
LOCATION="LOCATION"
RAG_CORPUS_1_ID="RAG_CORPUS_1_ID"
RAG_CORPUS_2_ID="RAG_CORPUS_2_ID"
QUERY="Why is the sky blue?"
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
"https://${LOCATION}-aiplatform.googleapis.com/v1beta1/projects/${PROJECT_ID}/locations/${LOCATION}:askContexts" \
-d '{
"query": {
"text": "'"$QUERY"'"
},
"tools": {
"retrieval": {
"disable_attribution": false,
"vertex_rag_store": {
"rag_resources": {
"rag_corpus": "projects/'"${PROJECT_ID}"'/locations/'"${LOCATION}"'/ragCorpora/'"${RAG_CORPUS_1_ID}"'"
},
"rag_resources": {
"rag_corpus": "projects/'"${PROJECT_ID}"'/locations/'"${LOCATION}"'/ragCorpora/'"${RAG_CORPUS_2_ID}"'"
}
}
}
}
}'
What's next
- To learn more about the RAG API, see RAG Engine API.
- To learn more about the responses from RAG, see Retrieval and Generation Output of RAG Engine.
- To learn about the RAG Engine, see the RAG Engine overview.