

Nosso Serviço de avaliação de IA generativa oferece ferramentas de nível empresarial para uma avaliação de modelos de IA generativa objetiva e baseada em dados. Ele oferece suporte e informações para várias tarefas de desenvolvimento, como migrações de modelos, edição de comandos e ajuste de detalhes.
Recursos do serviço de avaliação de IA generativa
O recurso principal do serviço de avaliação de IA generativa é a capacidade de usar rubricas adaptáveis, um conjunto de testes personalizados de aprovação ou reprovação para cada comando individual. As rubricas de avaliação são semelhantes aos testes de unidade no desenvolvimento de software e visam melhorar o desempenho do modelo em várias tarefas.
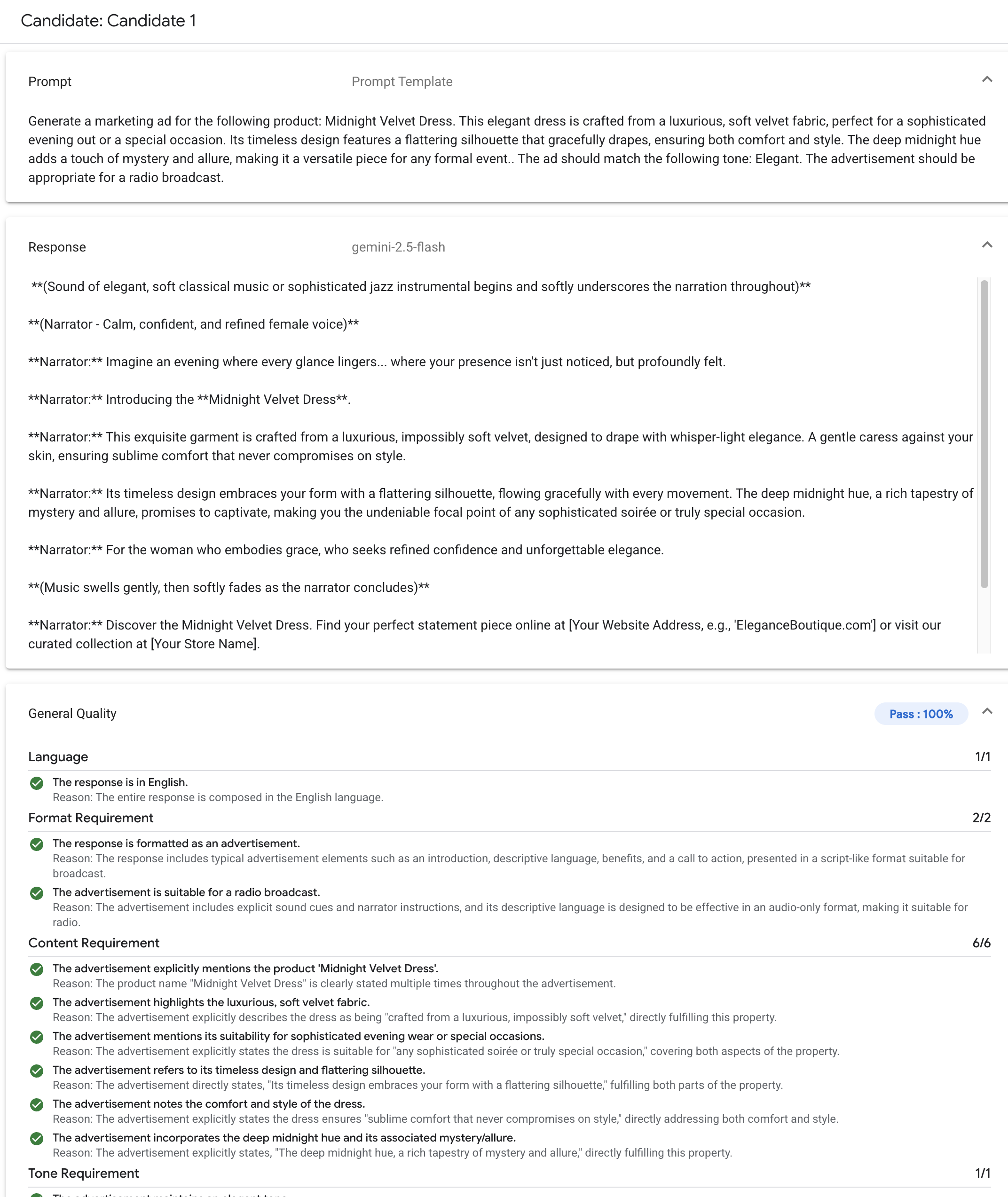
O serviço de avaliação de IA generativa é compatível com os seguintes métodos de avaliação comuns:
Rubricas adaptativas (recomendado): gera um conjunto exclusivo de rubricas de aprovação ou reprovação para cada comando individual no seu conjunto de dados.
Rubricas estáticas: aplicam um conjunto fixo de critérios de pontuação em todos os comandos.
Métricas baseadas em computação: use algoritmos determinísticos como
ROUGEouBLEUquando houver informações empíricas disponíveis.Funções personalizadas: defina sua própria lógica de avaliação em Python para requisitos especializados.
Geração de conjunto de dados de avaliação
É possível criar um conjunto de dados de avaliação usando os seguintes métodos:
Faça upload de um arquivo com instâncias de comandos completas ou forneça um modelo de comando com um arquivo correspondente de valores de variáveis para preencher os comandos concluídos.
Faça uma amostragem diretamente dos registros de produção para avaliar o uso do modelo no mundo real.
Use a geração de dados sintéticos para criar um grande número de exemplos consistentes para qualquer modelo de solicitação.
Interfaces compatíveis
É possível definir e executar suas avaliações usando as seguintes interfaces:
Google Cloud console: uma interface de usuário da Web que oferece um fluxo de trabalho guiado de ponta a ponta. Gerencie seus conjuntos de dados, faça avaliações e analise relatórios e visualizações interativos. Consulte Realizar a avaliação usando o console.
SDK do Python: execute avaliações de forma programática e renderize comparações lado a lado de modelos diretamente no seu ambiente do Colab ou Jupyter. Consulte Realizar uma avaliação usando o cliente da IA generativa no SDK do Agent Platform
Casos de uso
O serviço de avaliação de IA generativa permite ver como um modelo funciona em tarefas específicas e de acordo com seus critérios exclusivos, fornecendo insights valiosos que não podem ser derivados de rankings públicos e comparativos gerais. Isso apoia tarefas de desenvolvimento importantes, incluindo:
Migrações de modelos: compare versões de modelos para entender as diferenças de comportamento e ajuste seus comandos e configurações de acordo com isso.
Encontrar o melhor modelo: faça comparações diretas de modelos do Google e de terceiros nos seus dados para estabelecer um desempenho de base e identificar a melhor opção para seu caso de uso.
Melhoria de comandos: use os resultados da avaliação para orientar seus esforços de personalização. Executar uma avaliação novamente cria um ciclo de feedback restrito, fornecendo feedback imediato e quantificável sobre suas mudanças.
Ajuste fino do modelo: avalie a qualidade de um modelo ajustado aplicando critérios de avaliação consistentes a cada execução.
Avaliação do agente: avalie a performance de um agente usando métricas específicas, como rastreamentos e qualidade da resposta.
Fluxo de trabalho de avaliação
Para concluir uma avaliação, geralmente é necessário seguir estas etapas:
Crie um conjunto de dados de avaliação: reúna um conjunto de dados de instâncias de comandos que reflitam seu caso de uso específico. É possível incluir respostas de referência (informações empíricas) se você planeja usar métricas baseadas em computação.
Defina métricas de avaliação: escolha as métricas que você quer usar para medir a performance do modelo.
Gerar respostas do modelo: selecione um ou mais modelos para gerar respostas para seu conjunto de dados. O SDK da Agent Platform é compatível com qualquer modelo que possa ser chamado por
LiteLLM, enquanto o console é compatível com os modelos do Google Gemini.Executar a avaliação: execute o job de avaliação, que analisa as respostas de cada modelo em relação às métricas selecionadas.
Interprete os resultados: revise as pontuações agregadas e as respostas individuais para analisar a performance do modelo.
Métricas de avaliação
Confira a seguir os principais conceitos relacionados às métricas de avaliação:
Rubricas: os critérios para avaliar a resposta de um modelo ou aplicativo de LLM.
Métricas: uma pontuação que mede a saída do modelo em relação às rubricas de classificação.
O serviço de avaliação de IA generativa oferece as seguintes categorias de métricas:
Métricas com base em instruções: incorporam LLMs aos fluxos de trabalho de avaliação para analisar a qualidade das respostas do modelo. As avaliações com base em rubricas são adequadas para várias tarefas, especialmente qualidade de escrita, segurança e obediência a instruções, que costumam ser difíceis de avaliar com algoritmos deterministas.
Instruções adaptáveis (recomendado): as instruções são geradas dinamicamente para cada comando, como testes de unidade. As respostas são avaliadas com um conjunto exclusivo de testes de aprovação ou reprovação para cada comando individual no conjunto de dados. As rubricas mantêm a avaliação relevante para a tarefa solicitada e visam fornecer resultados objetivos, justificáveis e consistentes.
As rubricas adaptativas são geralmente a maneira mais rápida de começar a fazer avaliações, garantindo que cada uma delas seja relevante para a tarefa específica que está sendo avaliada.
Rubricas estáticas: são definidas explicitamente e a mesma rubrica se aplica a todos os comandos. As respostas são avaliadas com o mesmo conjunto de avaliadores numéricos baseados em pontuação. Uma única pontuação numérica (como de 1 a 5) por solicitação. Use rubricas estáticas quando uma avaliação for necessária em uma dimensão muito específica ou quando a mesma rubrica for necessária em todos os comandos.
Métricas baseadas em computação: avaliam respostas com algoritmos determinísticos, geralmente usando informações empíricas. Uma pontuação numérica (como 0,0 a 1,0) por comando. Quando as informações empíricas estão disponíveis e podem ser combinadas com um método determinístico.
Métricas de função personalizadas (somente SDK da Agent Platform): defina sua própria métrica usando uma função do Python.
Exemplo de rubrica adaptativa
O processo de avaliação de cada comando usa um sistema de duas etapas:
Geração de rubricas: primeiro, o serviço analisa seu comando e gera uma lista de testes específicos e verificáveis (as rubricas) que uma boa resposta precisa atender.
Validação da rubrica: depois que o modelo gera uma resposta, o serviço avalia a resposta em relação a cada rubrica, fornecendo um veredito
PassouFailclaro e uma justificativa.
O resultado final é uma taxa de aprovação agregada e uma análise detalhada de quais rubricas o modelo passou, oferecendo insights úteis para diagnosticar problemas e medir melhorias.
Ao passar de pontuações subjetivas de alto nível para resultados de testes granulares e objetivos, você pode adotar um ciclo de desenvolvimento orientado por avaliação e trazer as práticas recomendadas de engenharia de software para o processo de criação de aplicativos de IA generativa.
O exemplo a seguir mostra rubricas adaptativas geradas para um conjunto de comandos:
Comando do usuário: Write a four-sentence summary of the provided article about renewable energy, maintaining an optimistic tone.
Para esse comando, a etapa de geração de rubricas pode produzir as seguintes rubricas:
Rubrica 1: a resposta é um resumo do artigo fornecido.
Rubrica 2: a resposta contém exatamente quatro frases.
Rubrica 3: a resposta mantém um tom otimista.
O modelo pode gerar a seguinte resposta: The article highlights significant growth in solar and wind power. These advancements are making clean energy more affordable. The future looks bright for renewables. However, the report also notes challenges with grid infrastructure.
Durante a validação da rubrica, o serviço de avaliação de IA generativa avalia a resposta em relação a cada rubrica:
Rubrica 1: a resposta é um resumo do artigo fornecido.
Veredicto:
PassMotivo: a resposta resume com precisão os pontos principais.
Rubrica 2: a resposta contém exatamente quatro frases.
Veredicto:
PassMotivo: a resposta é composta de quatro frases distintas.
Rubrica 3: a resposta mantém um tom otimista.
Veredicto:
FailMotivo: a frase final apresenta um ponto negativo, que prejudica o tom otimista.
A taxa de aprovação final para essa resposta é de 66,7%. Para comparar dois modelos, avalie as respostas deles com o mesmo conjunto de testes gerados e compare as taxas gerais de aprovação.
Como começar a usar as avaliações
Você pode começar a fazer avaliações usando o console.
Como alternativa, o código a seguir mostra como concluir uma avaliação com o cliente da IA generativa no SDK do Agent Platform:
from vertexai import Client
from vertexai import types
import pandas as pd
client = Client(project=PROJECT_ID, location=LOCATION)
# Create an evaluation dataset
prompts_df = pd.DataFrame({
"prompt": [
"Write a simple story about a dinosaur",
"Generate a poem about Agent Platform",
],
})
# Get responses from one or multiple models
eval_dataset = client.evals.run_inference(model="gemini-2.5-flash", src=prompts_df)
# Define the evaluation metrics and run the evaluation job
eval_result = client.evals.evaluate(
dataset=eval_dataset,
metrics=[types.RubricMetric.GENERAL_QUALITY]
)
# View the evaluation results
eval_result.show()
O serviço de avaliação de IA generativa oferece duas interfaces do SDK da Agent Platform:
Cliente de IA generativa no Agent Platform SDK (recomendado) (prévia)
from vertexai import clientO cliente de IA generativa é a interface mais recente e recomendada para avaliação, acessada pela classe de cliente unificada. Ele oferece suporte a todos os métodos de avaliação e foi projetado para fluxos de trabalho que incluem comparação de modelos, visualização no notebook e insights para personalização de modelos.
Módulo de avaliação no SDK da Agent Platform (GA)
from vertexai.evaluation import EvalTaskO módulo de avaliação é a interface mais antiga, mantida para compatibilidade com versões anteriores de fluxos de trabalho atuais, mas não está mais em desenvolvimento ativo. Ele é acessado pela classe
EvalTask. Esse método é compatível com LLM padrão como um juiz e métricas baseadas em computação, mas não com métodos de avaliação mais recentes, como rubricas adaptativas.
Regiões compatíveis
As seguintes regiões são compatíveis com o serviço de avaliação de IA generativa:
Iowa (
us-central1)Norte da Virgínia (
us-east4)Oregon (
us-west1)Las Vegas, Nevada (
us-west4)Bélgica (
europe-west1)Países Baixos (
europe-west4)Paris, França (
europe-west9)
Notebooks disponíveis
| Links do notebook | Descrição |
|---|---|
| Introdução: avaliação rápida de IA generativa | Apresenta o serviço de avaliação de IA generativa. |
| Avaliar modelos de terceiros com o serviço de avaliação de IA generativa | Demonstra como usar o **SDK da Agent Platform** para avaliar vários tipos de modelos de terceiros, incluindo modelos acessados usando API (como OpenAI, Anthropic), modelo como serviço (MaaS) do Vertex Model Garden e endpoints Bring Your Own Model (BYOM). |
| Migração de modelos com o serviço de avaliação de IA generativa | Mostra como usar o **SDK do Agent Platform** para o serviço de avaliação de IA generativa e comparar dois modelos próprios (como o Gemini 2.0 Flash e o Gemini 2.5 Flash). Ele destaca o uso de métricas adaptativas predefinidas baseadas em rubricas e como os resultados da avaliação podem orientar a otimização de comandos. Também aborda recursos importantes, como avaliação de vários candidatos, visualização no notebook e avaliação assíncrona em lote. |
| Como avaliar a qualidade da conversão de texto em imagem com o Serviço de avaliação de IA generativa | Mostra como usar o SDK da Vertex AI para o serviço de avaliação de IA generativa e avaliar a qualidade das imagens geradas com base em comandos de texto. Ele demonstra o uso da métrica Gecko predefinida e adaptativa baseada em rubrica. |
| Avaliar a qualidade de texto para vídeo com o serviço de avaliação de IA generativa | Mostra como usar o **SDK da Agent Platform** para o serviço de avaliação de IA generativa e avaliar a qualidade dos vídeos gerados com base em comandos de texto. Ele demonstra o uso da métrica Gecko predefinida e adaptativa baseada em rubrica. |