
כשמשתמשים בשאילתות SQL כדי לחפש נתונים, Spanner משתמש באופן אוטומטי באינדקסים משניים שיכולים לעזור לאחזר את הנתונים בצורה יעילה יותר. עם זאת, במקרים מסוימים, יכול להיות ש-Spanner יבחר באינדקס שיגרום לשאילתות להיות איטיות יותר. כתוצאה מכך, יכול להיות שתבחינו בכך שחלק מהשאילתות פועלות לאט יותר מאשר בעבר.
בדף הזה מוסבר איך לזהות שינויים במהירות ההפעלה של שאילתות, לבדוק את תוכנית ההפעלה של השאילתות האלה ולציין אינדקס אחר לשאילתות עתידיות, אם צריך.
זיהוי שינויים במהירות הביצוע של שאילתות
סביר להניח שתראו שינוי במהירות הביצוע של השאילתה אחרי שתבצעו אחד מהשינויים הבאים:
- שינוי משמעותי של כמות גדולה של נתונים קיימים שיש להם אינדקס משני.
- הוספה, שינוי או הסרה של אינדקס משני.
יש כמה כלים שבהם אפשר להשתמש כדי לזהות שאילתה ספציפית ש-Spanner מבצעת לאט יותר מהרגיל:
- תובנות לגבי שאילתות ונתונים סטטיסטיים לגבי שאילתות.
מדדים ספציפיים לאפליקציה שאתם אוספים ומנתחים באמצעות Cloud Monitoring. לדוגמה, אפשר לעקוב אחרי המדד מספר השאילתות כדי לקבוע את מספר השאילתות במופע לאורך זמן ולגלות איזו גרסה של אופטימיזציית שאילתות שימשה להרצת שאילתה.
כלים לניטור בצד הלקוח שמודדים את הביצועים של האפליקציה.
הערה לגבי מסדי נתונים חדשים
כשמריצים שאילתות על מסדי נתונים שנוצרו לאחרונה עם נתונים שנוספו או יובאו לאחרונה, יכול להיות שמערכת Spanner לא תבחר את האינדקסים המתאימים ביותר, כי לוקח עד שלושה ימים עד שמייעל השאילתות אוסף נתונים סטטיסטיים באופן אוטומטי. כדי לבצע אופטימיזציה של השימוש באינדקס במסד נתונים חדש של Spanner מוקדם יותר, אפשר ליצור ידנית חבילת נתונים סטטיסטיים חדשה.
בדיקת הסכימה
אחרי שמאתרים את השאילתה שהאטה את המערכת, בודקים את הצהרת ה-SQL של השאילתה ומזהים את הטבלאות שבהן ההצהרה משתמשת ואת העמודות שהיא מאחזרת מהטבלאות האלה.
לאחר מכן, מאתרים את האינדקסים המשניים שקיימים בטבלאות האלה. בודקים אם אחד מהאינדקסים כולל את העמודות שאתם שולחים לגביהן שאילתה. אם כן, יכול להיות ש-Spanner ישתמש באחד מהאינדקסים כדי לעבד את השאילתה.
- אם יש אינדקסים רלוונטיים, השלב הבא הוא לאתר את האינדקס ש-Spanner השתמש בו בשאילתה.
אם אין אינדקסים רלוונטיים, משתמשים בפקודה
gcloud spanner operations listכדי לבדוק אם לאחרונה השמטתם אינדקס רלוונטי:gcloud spanner operations list \ --instance=INSTANCE \ --database=DATABASE \ --filter="@TYPE:UpdateDatabaseDdlMetadata"אם השמטתם אינדקס רלוונטי, יכול להיות שהשינוי הזה השפיע על הביצועים של השאילתות. הוספת האינדקס המשני בחזרה לטבלה. אחרי ש-Spanner מוסיף את האינדקס, מריצים את השאילתה שוב ובודקים את הביצועים שלה. אם הביצועים לא משתפרים, השלב הבא הוא למצוא את האינדקס ש-Spanner השתמש בו בשאילתה.
אם לא השמטתם אינדקס רלוונטי, בחירת האינדקס לא גרמה לירידה בביצועי השאילתה. כדאי לחפש שינויים אחרים בנתונים או בדפוסי השימוש שאולי השפיעו על הביצועים.
איך מוצאים את האינדקס שמשמש לשאילתה
כדי לגלות באיזה אינדקס Spanner משתמש כדי לעבד שאילתה, אפשר לעיין בתוכנית ההפעלה של השאילתה במסוף Google Cloud :
נכנסים לדף Instances ב-Spanner במסוףGoogle Cloud .
לוחצים על שם המופע שרוצים לשלוח לו שאילתה.
בחלונית הימנית, לוחצים על מסד הנתונים שרוצים לשלוח אליו שאילתה, ואז לוחצים על Spanner Studio.
מזינים את השאילתה לבדיקה.
ברשימה הנפתחת הפעלת שאילתה, בוחרים באפשרות הסבר בלבד. תוצג תוכנית השאילתה ב-Spanner.
חפשו לפחות אחד מהאופרטורים הבאים בתוכנית השאילתה:
- סריקת טבלה
- סריקת אינדקס
- CROSS APPLY או DISTRIBUTED CROSS APPLY
בקטעים הבאים מוסבר מה המשמעות של כל אופרטור.
אופרטור לסריקת טבלאות
האופרטור table scan מציין ש-Spanner לא השתמש באינדקס משני:
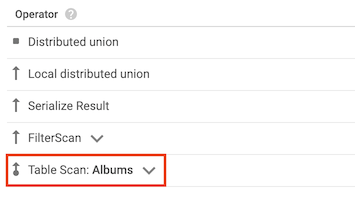
לדוגמה, נניח שלטבלה Albums אין אינדקסים משניים, ואתם מריצים את השאילתה הבאה:
SELECT AlbumTitle FROM Albums WHERE STARTS_WITH(AlbumTitle, "Now");
מכיוון שאין אינדקסים לשימוש, תוכנית השאילתה כוללת אופרטור של סריקת טבלה.
אופרטור סריקת אינדקס
האופרטור index scan מציין ש-Spanner השתמש באינדקס משני כשעיבד את השאילתה:
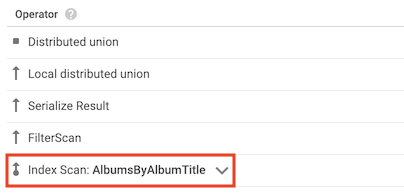
לדוגמה, נניח שמוסיפים אינדקס לטבלה Albums:
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
ואז מריצים את השאילתה הבאה:
SELECT AlbumTitle FROM Albums WHERE STARTS_WITH(AlbumTitle, "Now");
האינדקס AlbumsByAlbumTitle מכיל את AlbumTitle, שהיא העמודה היחידה שהשאילתה בוחרת. כתוצאה מכך, תוכנית השאילתה כוללת אופרטור של סריקת אינדקס.
אופרטור של החלה צולבת
במקרים מסוימים, Spanner משתמש באינדקס שמכיל רק חלק מהעמודות שהשאילתה בוחרת. כתוצאה מכך, מערכת Spanner צריכה לבצע הצטרפות של האינדקס לטבלת הבסיס.
כשמתבצעת הצטרפות מסוג כזה, תוכנית השאילתה כוללת את האופרטורים cross apply או distributed cross apply עם הקלט הבא:
- אופרטור של סריקת אינדקס עבור אינדקס של טבלה
- אופרטור של סריקת טבלה עבור הטבלה שהאינדקס שייך לה
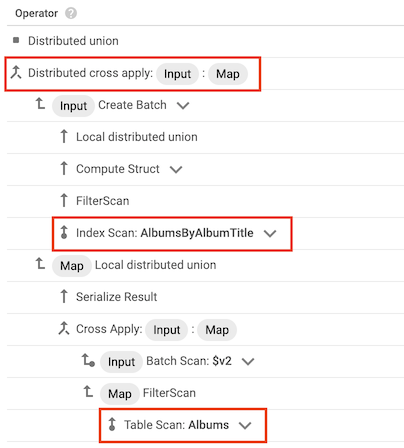
לדוגמה, נניח שמוסיפים אינדקס לטבלה Albums:
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
ואז מריצים את השאילתה הבאה:
SELECT * FROM Albums WHERE STARTS_WITH(AlbumTitle, "Now");
האינדקס AlbumsByAlbumTitle מכיל את AlbumTitle, אבל השאילתה בוחרת את כל העמודות בטבלה, ולא רק את AlbumTitle. כתוצאה מכך, תוכנית השאילתה כוללת אופרטור מבוזר של cross apply, עם סריקת אינדקס של AlbumsByAlbumTitle וסריקת טבלה של Albums כקלט.
בחירת אינדקס אחר
אחרי שמאתרים את האינדקס שבו Spanner השתמש בשאילתה, מנסים להריץ את השאילתה עם אינדקס אחר, או על ידי סריקה של טבלת הבסיס במקום שימוש באינדקס. כדי לציין את האינדקס, מוסיפים הנחיית FORCE_INDEX לשאילתה.
אם מצאתם גרסה מהירה יותר של השאילתה, עדכנו את האפליקציה כך שתשתמש בגרסה המהירה יותר.
הנחיות לבחירת אינדקס
ההנחיות הבאות יעזרו לכם להחליט איזה אינדקס לבדוק בשאילתה:
אם השאילתה שלכם עומדת באחד מהקריטריונים האלה, נסו להשתמש בטבלת הבסיס במקום באינדקס משני:
- השאילתה בודקת שוויון עם תחילית של המפתח הראשי של טבלת הבסיס (לדוגמה,
SELECT * FROM Albums WHERE SingerId = 1). - מספר גדול של שורות עומד בתנאי השאילתה (לדוגמה,
SELECT * FROM Albums WHERE AlbumTitle != "There Is No Album With This Title"). - השאילתה משתמשת בטבלת בסיס שמכילה רק כמה מאות שורות.
- השאילתה בודקת שוויון עם תחילית של המפתח הראשי של טבלת הבסיס (לדוגמה,
אם השאילתה מכילה פרדיקט סלקטיבי מאוד (לדוגמה,
REGEXP_CONTAINS,STARTS_WITH,<,<=,>,>=או!=), נסו להשתמש באינדקס שכולל את אותן עמודות שבהן אתם משתמשים בפרדיקט.
בדיקת השאילתה המעודכנת
אפשר להשתמש במסוף Google Cloud כדי לבדוק את השאילתה המעודכנת ולגלות כמה זמן לוקח לעבד אותה.
אם השאילתה כוללת פרמטרים של שאילתה, ופרמטר של שאילתה מאוגד לכמה ערכים הרבה יותר פעמים מאשר לאחרים, כדאי לאגד את הפרמטר של השאילתה לאחד מהערכים האלה בבדיקות. לדוגמה, אם השאילתה כוללת פרדיקט כמו WHERE country = @countryId, וכמעט כל השאילתות שלכם קושרות את @countryId לערך US, כדאי לקשור את @countryId ל-US בבדיקות הביצועים. הגישה הזו עוזרת לכם לבצע אופטימיזציה של השאילתות שאתם מריצים הכי הרבה פעמים.
כדי לבדוק את השאילתה המעודכנת במסוף Google Cloud , פועלים לפי השלבים הבאים:
נכנסים לדף Instances ב-Spanner במסוףGoogle Cloud .
לוחצים על שם המופע שרוצים לשלוח לו שאילתה.
בחלונית הימנית, לוחצים על מסד הנתונים שרוצים לשלוח אליו שאילתה, ואז לוחצים על Spanner Studio.
מזינים את השאילתה לבדיקה, כולל ההנחיה
FORCE_INDEX, ולוחצים על הפעלת השאילתה.במסוף Google Cloud נפתחת הכרטיסייה טבלת תוצאות, ואז מוצגות תוצאות השאילתה, כולל משך הזמן שנדרש לשירות Spanner לעיבוד השאילתה.
המדד הזה לא כולל מקורות אחרים של זמן אחזור, כמו הזמן שלקח למסוף לפרש ולהציג את תוצאות השאילתה. Google Cloud
קבלת פרופיל מפורט של שאילתה בפורמט JSON באמצעות API בארכיטקטורת REST
כברירת מחדל, כשמריצים שאילתה, מוחזרות רק תוצאות של הצהרות. הסיבה לכך היא שהערך של QueryMode מוגדר כ-NORMAL. כדי לכלול בתוצאות השאילתה נתונים סטטיסטיים מפורטים על הביצוע, מגדירים את QueryMode לערך PROFILE.
יצירת סשן
לפני שמעדכנים את מצב השאילתה, צריך ליצור סשן שמייצג ערוץ תקשורת עם שירות מסד הנתונים של Spanner.
- לוחצים על
projects.instances.databases.sessions.create. מזינים את מזהה הפרויקט, המכונה ומסד הנתונים בטופס הבא:
projects/[\PROJECT_ID]/instances/[\INSTANCE_ID]/databases/[\DATABASE_ID]
לוחצים על Execute. התשובה תציג את הסשן שיצרתם בפורמט הבא:
projects/[\PROJECT_ID]/instances/[\INSTANCE_ID]/databases/[\DATABASE_ID]/sessions/[\SESSION]
תשתמשו בו כדי להריץ את פרופיל השאילתה בשלב הבא. הסשן שנוצר יהיה פעיל למשך שעה לכל היותר בין שימוש לשימוש, לפני שהוא יימחק על ידי מסד הנתונים.
ניתוח השאילתה
מפעילים את מצב PROFILE בשאילתה.
- לוחצים על
projects.instances.databases.sessions.executeSql. בשדה session, מזינים את מזהה ההפעלה שיצרתם בשלב הקודם:
projects/[PROJECT_ID]/instances/[INSTANCE_ID]/databases/[DATABASE_ID]/sessions/[SESSION]
בקטע Request body (גוף הבקשה), משתמשים בערכים הבאים:
{ "sql": "[YOUR_SQL_QUERY]", "queryMode": "PROFILE" }
לוחצים על Execute. התשובה שתתקבל תכלול את תוצאות השאילתה, את תוכנית השאילתה ואת נתוני הביצוע של השאילתה.