
סקירה כללית
בדף הזה מוסבר על תוכניות להרצת שאילתות ואיך Spanner משתמש בהן כדי להריץ שאילתות בסביבה מבוזרת. כדי לדעת איך לאחזר תוכנית ביצוע של שאילתה ספציפית באמצעות מסוףGoogle Cloud , אפשר לעיין במאמר הסבר על אופן הביצוע של שאילתות ב-Spanner. אפשר גם לראות תוכניות היסטוריות של שאילתות שנדגמו ולהשוות את הביצועים של שאילתה מסוימת לאורך זמן. מידע נוסף זמין במאמר בנושא תוכניות שאילתות לדוגמה.
ב-Spanner משתמשים בהצהרות SQL דקלרטיביות כדי להריץ שאילתות על מסדי הנתונים. הצהרות SQL מגדירות מה המשתמש רוצה, בלי לציין איך להשיג את התוצאות. תוכנית להרצת שאילתה היא קבוצת השלבים להשגת התוצאות. יכולות להיות כמה דרכים לקבל את התוצאות של הצהרת SQL מסוימת. אופטימיזציית השאילתות ב-Spanner מעריכה תוכניות ביצוע שונות ובוחרת את התוכנית שהיא רואה כיעילה ביותר. Spanner משתמש בתוכנית הביצוע כדי לאחזר את התוצאות. תוכניות הביצוע תומכות במסדי נתונים של ניב GoogleSQL ובמסדי נתונים של ניב PostgreSQL.
מבחינה מושגית, תוכנית ביצוע היא עץ של אופרטורים יחסיים. כל אופרטור קורא שורות מהקלט שלו ומפיק שורות פלט. התוצאה של האופרטור ברמת הבסיס של הביצוע מוחזרת כתוצאה של שאילתת ה-SQL.
לדוגמה, השאילתה הזו:
SELECT s.SongName FROM Songs AS s;
התוצאה היא תוכנית להפעלת שאילתה שאפשר להציג אותה באופן הבא:
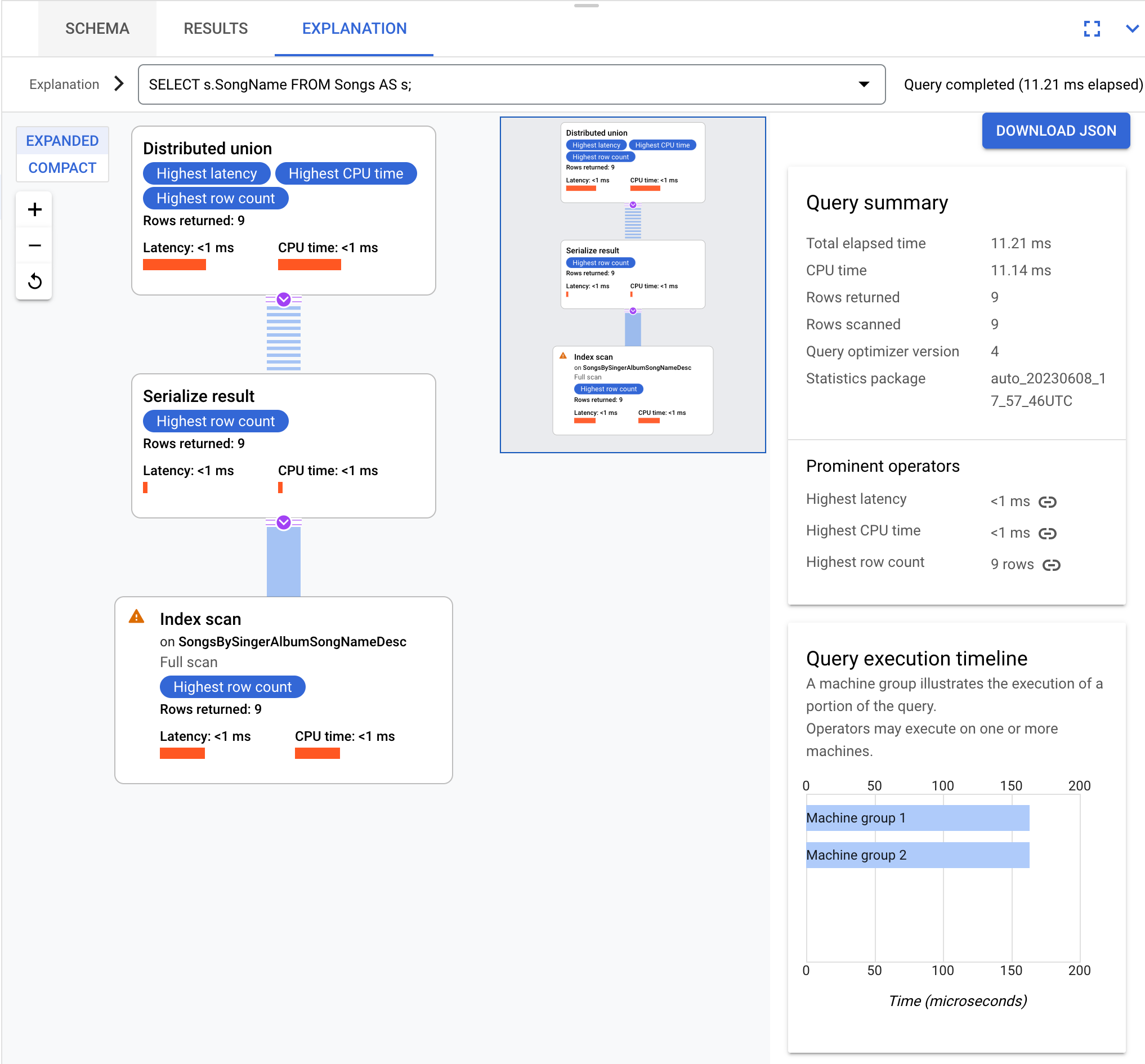
השאילתות ותוכניות הביצוע בדף הזה מבוססות על סכימת מסד הנתונים הבאה:
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
BirthDate DATE
) PRIMARY KEY(SingerId);
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
MarketingBudget INT64
) PRIMARY KEY(SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) STORING (MarketingBudget);
CREATE TABLE Songs (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
TrackId INT64 NOT NULL,
SongName STRING(MAX),
Duration INT64,
SongGenre STRING(25)
) PRIMARY KEY(SingerId, AlbumId, TrackId),
INTERLEAVE IN PARENT Albums ON DELETE CASCADE;
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC), INTERLEAVE IN Albums;
CREATE INDEX SongsBySongName ON Songs(SongName);
CREATE TABLE Concerts (
VenueId INT64 NOT NULL,
SingerId INT64 NOT NULL,
ConcertDate DATE NOT NULL,
BeginTime TIMESTAMP,
EndTime TIMESTAMP,
TicketPrices ARRAY<INT64>
) PRIMARY KEY(VenueId, SingerId, ConcertDate);
אפשר להשתמש בהצהרות הבאות של שפת טיפול בנתונים (DML) כדי להוסיף נתונים לטבלאות האלה:
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate)
VALUES (1, "Marc", "Richards", "1970-09-03"),
(2, "Catalina", "Smith", "1990-08-17"),
(3, "Alice", "Trentor", "1991-10-02"),
(4, "Lea", "Martin", "1991-11-09"),
(5, "David", "Lomond", "1977-01-29");
INSERT INTO Albums (SingerId, AlbumId, AlbumTitle)
VALUES (1, 1, "Total Junk"),
(1, 2, "Go, Go, Go"),
(2, 1, "Green"),
(2, 2, "Forever Hold Your Peace"),
(2, 3, "Terrified"),
(3, 1, "Nothing To Do With Me"),
(4, 1, "Play");
INSERT INTO Songs (SingerId, AlbumId, TrackId, SongName, Duration, SongGenre)
VALUES (2, 1, 1, "Let's Get Back Together", 182, "COUNTRY"),
(2, 1, 2, "Starting Again", 156, "ROCK"),
(2, 1, 3, "I Knew You Were Magic", 294, "BLUES"),
(2, 1, 4, "42", 185, "CLASSICAL"),
(2, 1, 5, "Blue", 238, "BLUES"),
(2, 1, 6, "Nothing Is The Same", 303, "BLUES"),
(2, 1, 7, "The Second Time", 255, "ROCK"),
(2, 3, 1, "Fight Story", 194, "ROCK"),
(3, 1, 1, "Not About The Guitar", 278, "BLUES");
קשה להשיג תוכניות ביצוע יעילות כי Spanner מחלק את הנתונים לפיצולים. הפיצולים יכולים לנוע באופן עצמאי ולהיות מוקצים לשרתים שונים, שיכולים להיות במיקומים פיזיים שונים. כדי להעריך תוכניות ביצוע על נתונים מבוזרים, Spanner משתמש בביצוע שמבוסס על:
- ביצוע מקומי של תוכניות משנה בשרתים שמכילים את הנתונים
- תזמור וצבירה של מספר ביצועים מרחוק עם גיזום אגרסיבי של ההפצה
Spanner משתמש באופרטור הפרימיטיבי distributed union, יחד עם הווריאציות שלו distributed cross apply ו-distributed outer apply, כדי להפעיל את המודל הזה.
מדדי ביצועים מרכזיים
כלי ההמחשה של תוכנית השאילתה ב-Spanner Studio מציג מדדי סיכום של ביצוע השאילתה. מדדי הסיכום מייצגים את הצבירה של מדדים מכל האופרטורים האישיים שהופעלו במהלך השאילתה. בטבלה הבאה מפורטים מדדי הביצועים המרכזיים:
| מדד | תיאור |
|---|---|
| הזמן הכולל שחלף | הזמן הכולל שחלף מהרגע שהשאילתה התחילה לרוץ ועד שהיא הסתיימה. |
| זמן CPU (מעבד) | הסכום הכולל של זמן המעבד שהושקע בכל השרתים שהיו מעורבים בהרצת השאילתה. חלקים מסוימים של ביצוע השאילתה יכולים להתבצע במקביל, ולכן זמן השימוש במעבד יכול להיות גדול יותר מהזמן הכולל שחלף. |
תוכניות שאילתות לדוגמה
תוכניות שאילתות לדוגמה ב-Spanner מאפשרות לכם לראות דוגמאות של תוכניות שאילתות היסטוריות ולהשוות את הביצועים של שאילתה לאורך זמן. לא לכל השאילתות יש תוכניות שאילתה לדוגמה. יכול להיות שיידגמו רק שאילתות שצורכות יותר מעבד. משך הזמן לשמירת נתונים של דוגמאות של תוכניות שאילתות ב-Spanner הוא 30 יום. דוגמאות לתוכניות שאילתות מופיעות בדף Query insights במסוף Google Cloud . הוראות מפורטות מופיעות במאמר הצגת תוכניות שאילתה לדוגמה.
המבנה של תוכנית שאילתה לדוגמה זהה לזה של תוכנית רגילה להרצת שאילתה. מידע נוסף על הבנת תוכניות חזותיות ושימוש בהן כדי לנפות באגים בשאילתות זמין במאמר סיור בכלי להמחזת תוכניות של שאילתות.
תרחישים נפוצים לדוגמה לתוכניות שאילתה עם דגימה:
דוגמאות לתרחישי שימוש נפוצים בתוכניות שאילתות עם דגימה:
- אפשר לראות שינויים בתוכנית השאילתות בעקבות שינויים בסכימה (למשל, הוספה או הסרה של אינדקס).
- שימו לב לשינויים בתוכנית השאילתות בעקבות עדכון של גרסת האופטימיזציה.
- אפשר לעקוב אחרי שינויים בתוכנית השאילתות בעקבות נתונים סטטיסטיים חדשים של אופטימיזציה, שנאספים אוטומטית כל שלושה ימים או באופן ידני באמצעות הפקודה
ANALYZE.
אם הביצועים של שאילתה משתנים באופן משמעותי לאורך זמן או אם רוצים לשפר את הביצועים של שאילתה, כדאי לעיין בשיטות מומלצות ל-SQL כדי ליצור הצהרות שאילתה שעברו אופטימיזציה ועוזרות ל-Spanner למצוא תוכניות ביצוע יעילות.
מחזור החיים של שאילתה
שאילתת SQL ב-Spanner עוברת קודם קומפילציה לתוכנית ביצוע, ואז היא נשלחת לשרת הבסיס הראשוני לביצוע. שרת הבסיס נבחר כך שמספר הקפיצות כדי להגיע לנתונים שבשאילתה יהיה מינימלי. שרת הבסיס:
- מתחיל ביצוע מרחוק של תוכניות משנה (אם יש צורך)
- המתנה לתוצאות מההרצות מרחוק
- מטפל בכל שלבי ההרצה המקומיים שנותרו, כמו צבירת התוצאות
- מחזירה תוצאות לשאילתה
שרתים מרוחקים שמקבלים תוכנית משנית פועלים כשרת 'בסיס' עבור התוכנית המשנית שלהם, לפי אותו מודל כמו שרת הבסיס העליון. התוצאה היא עץ של הרצות מרחוק. מבחינה קונספטואלית, הביצוע של השאילתה מתבצע מלמעלה למטה, ותוצאות השאילתה מוחזרות מלמטה למעלה.הדיאגרמה הבאה מציגה את הדפוס הזה:

הדוגמאות הבאות ממחישות את התבנית הזו בפירוט רב יותר.
שאילתות מצטברות
שאילתה מצטברת מיישמת GROUP BY שאילתות.
לדוגמה, באמצעות השאילתה הזו:
SELECT s.SingerId, COUNT(*) AS SongCount
FROM Songs AS s
WHERE s.SingerId < 100
GROUP BY s.SingerId;
אלה התוצאות:
+----------+-----------+
| SingerId | SongCount |
+----------+-----------+
| 3 | 1 |
| 2 | 8 |
+----------+-----------+
באופן מושגי, זו תוכנית הביצוע:
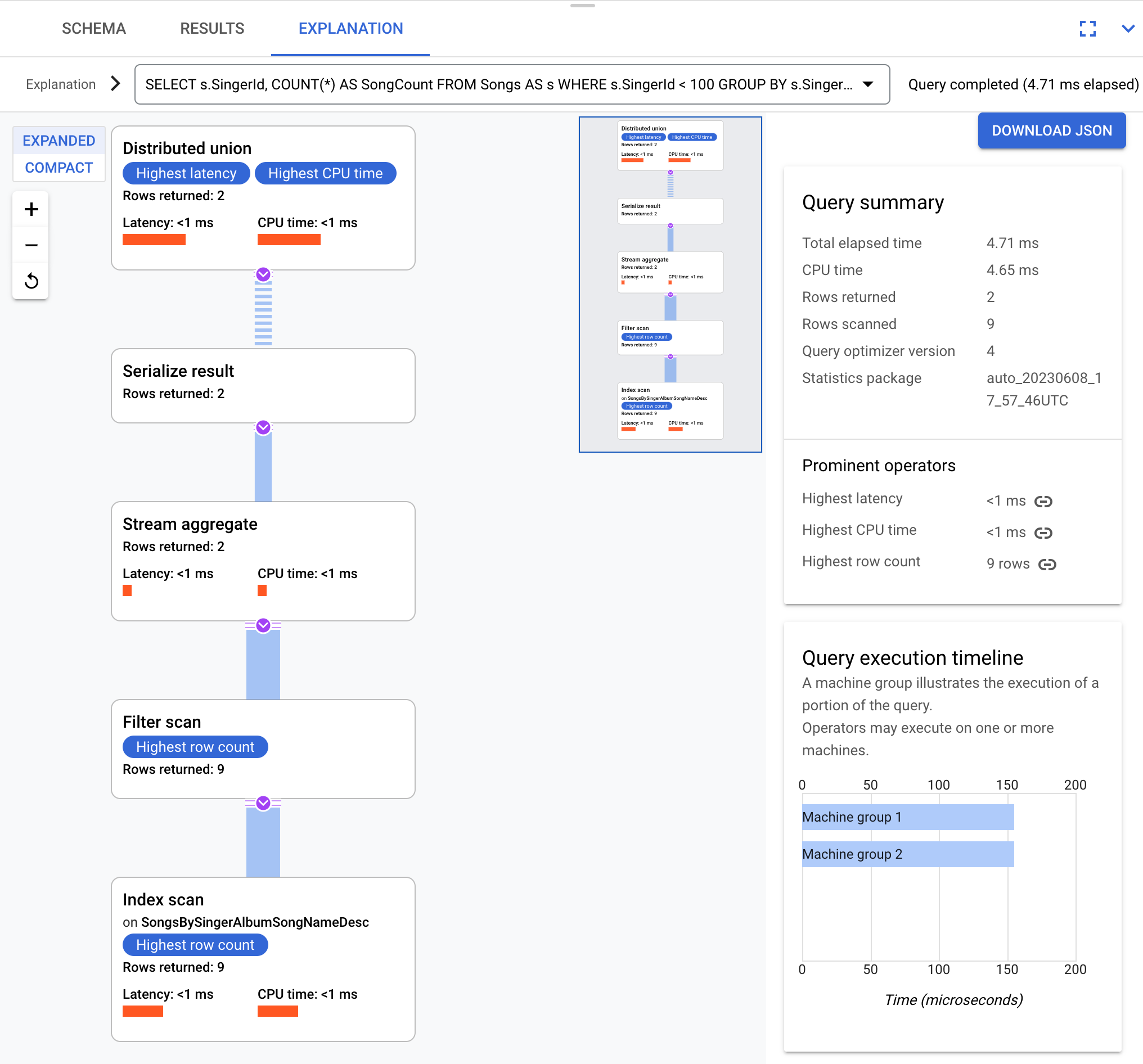
Spanner שולח את תוכנית ההפעלה לשרת בסיס שמתאם את הפעלת השאילתה ומבצע את ההפצה מרחוק של תוכניות משנה.
תוכנית הביצוע הזו מתחילה באיחוד מבוזר, שמפיץ תוכניות משנה לשרתים מרוחקים שהפיצולים שלהם עומדים בדרישות של SingerId < 100. אחרי שהסריקה של כל פיצול מסתיימת, האופרטור stream aggregate מצמיד שורות כדי לקבל את המספרים של כל SingerId. האופרטור serialize result מבצע סריאליזציה של התוצאה. לבסוף, האיחוד המבוזר משלב את כל התוצאות ומחזיר את תוצאות השאילתה.
מידע נוסף על צבירות זמין במאמר בנושא אופרטור צבירה.
שאילתות של צירוף שנמצאות באותו מיקום
טבלאות משולבות מאוחסנות פיזית עם השורות שלהן בטבלאות קשורות באותו מיקום. שאילתת איחוד (join) של טבלאות שמוצבות זו לצד זו היא שאילתת איחוד בין טבלאות שמוצבות זו לצד זו. הצטרפות של טבלאות שנמצאות באותו מיקום יכולה להניב שיפור בביצועים בהשוואה להצטרפות של טבלאות שדורשות אינדקסים או הצטרפות של טבלאות שנמצאות במיקומים שונים.
לדוגמה, באמצעות השאילתה הזו:
SELECT al.AlbumTitle, so.SongName
FROM Albums AS al, Songs AS so
WHERE al.SingerId = so.SingerId AND al.AlbumId = so.AlbumId;
(השאילתה הזו מניחה ש-Songs משולב ב-Albums).
אלה התוצאות:
+-----------------------+--------------------------+
| AlbumTitle | SongName |
+-----------------------+--------------------------+
| Nothing To Do With Me | Not About The Guitar |
| Green | The Second Time |
| Green | Starting Again |
| Green | Nothing Is The Same |
| Green | Let's Get Back Together |
| Green | I Knew You Were Magic |
| Green | Blue |
| Green | 42 |
| Terrified | Fight Story |
+-----------------------+--------------------------+
זו תוכנית הביצוע:
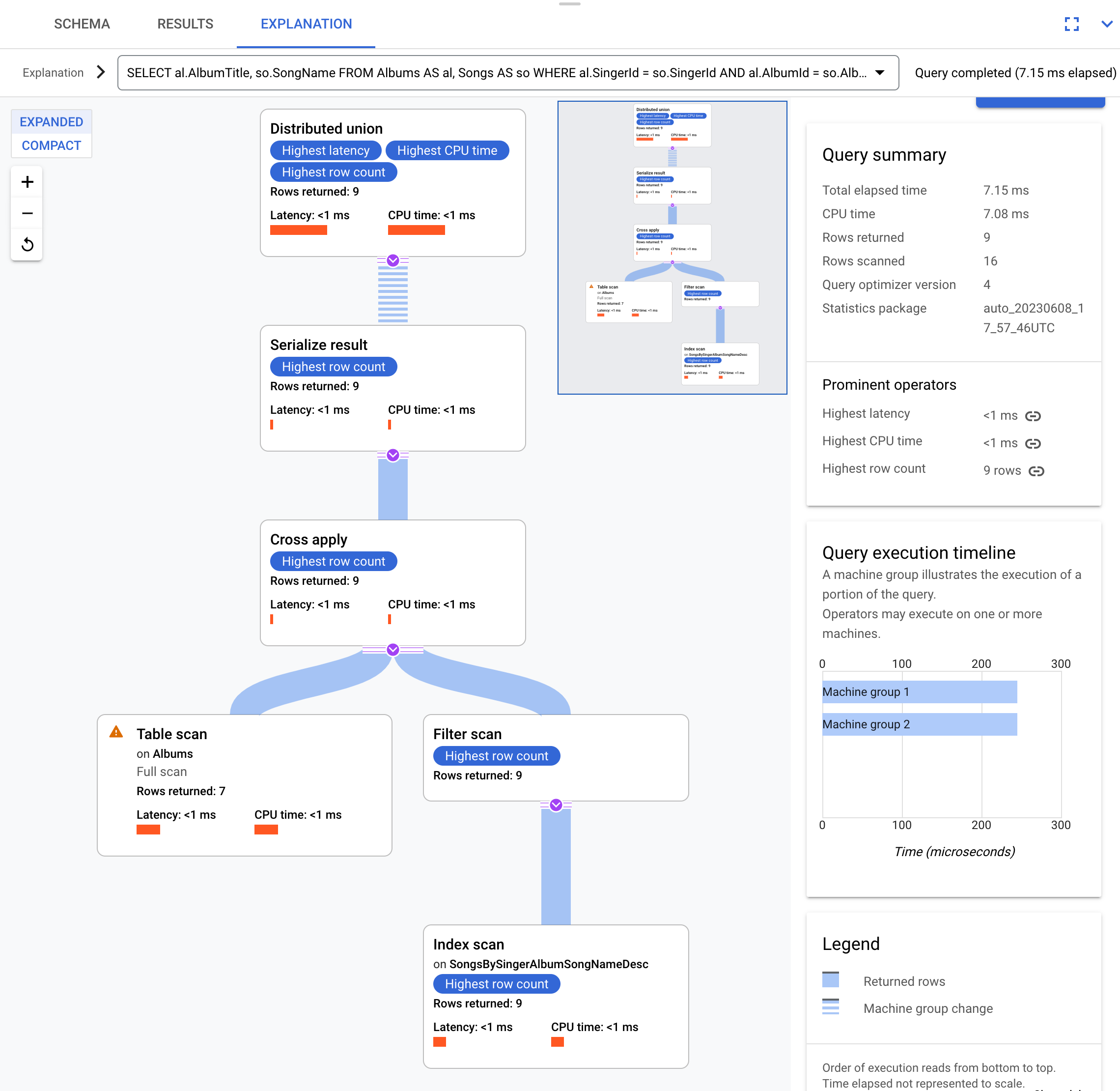
תוכנית הביצוע הזו מתחילה באיחוד מבוזר, שמפיץ תוכניות משנה לשרתים מרוחקים שמכילים פיצולים של הטבלה Albums.
מכיוון ש-Songs היא טבלה משולבת של Albums, כל שרת מרוחק יכול להריץ את תוכנית המשנה כולה בכל שרת מרוחק בלי שיידרש צירוף לשרת אחר.
תוכניות המשנה מכילות cross apply. כל פעולת cross apply מבצעת סריקה של טבלה בטבלה Albums כדי לאחזר את SingerId, AlbumId ו-AlbumTitle. הפונקציה cross apply ממפה את הפלט מסריקת הטבלה לפלט מסריקת אינדקס באינדקס SongsBySingerAlbumSongNameDesc, בכפוף למסנן של SingerId באינדקס שתואם ל-SingerId מהפלט של סריקת הטבלה. כל פעולת cross apply שולחת את התוצאות שלה לאופרטור serialize result שמבצע סריאליזציה של הנתונים AlbumTitle ו-SongName ומחזיר את התוצאות ל-distributed unions המקומי. האיחוד המבוזר אוסף תוצאות מאיחודים מבוזרים מקומיים ומחזיר אותן כתוצאה של השאילתה.
אינדקס ושאילתות של צירוף שמאלי
בדוגמה שלמעלה נעשה שימוש באיחוד של שתי טבלאות, שאחת מהן משולבת בשנייה. תוכניות הביצוע מורכבות יותר ופחות יעילות כששתי טבלאות, או טבלה ואינדקס, לא משולבות.
נניח שיצרתם אינדקס באמצעות הפקודה הבאה:
CREATE INDEX SongsBySongName ON Songs(SongName)
השתמש באינדקס הזה בשאילתה הזו:
SELECT s.SongName, s.Duration
FROM Songs@{force_index=SongsBySongName} AS s
WHERE STARTS_WITH(s.SongName, "B");
אלה התוצאות:
+----------+----------+
| SongName | Duration |
+----------+----------+
| Blue | 238 |
+----------+----------+
זו תוכנית הביצוע:
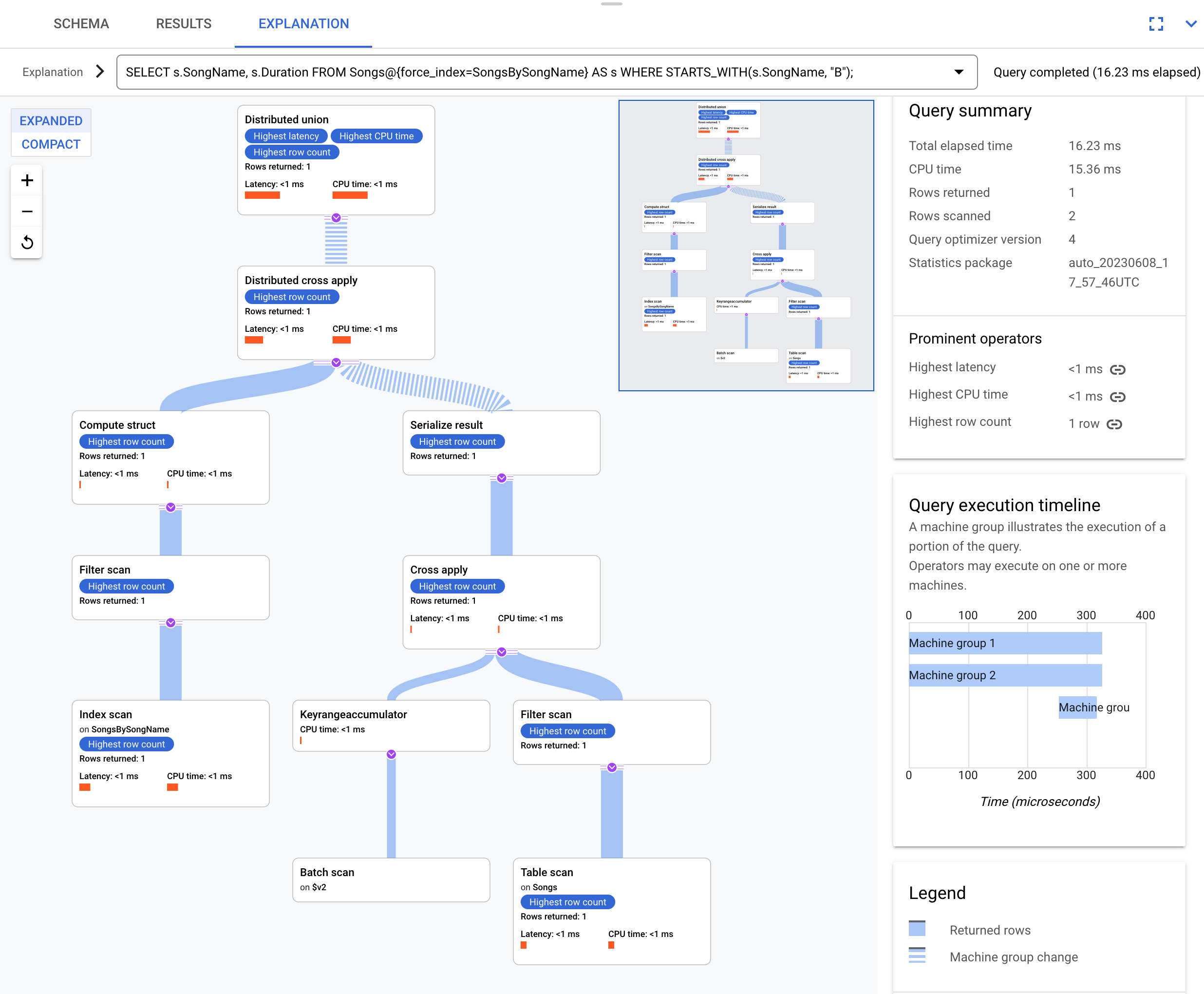
תוכנית הביצוע שמתקבלת היא מורכבת כי האינדקס SongsBySongName
לא מכיל את העמודה Duration. כדי לקבל את הערך Duration, Spanner צריך לבצע back join של התוצאות שנוצרו על סמך האינדקס לטבלה Songs. זהו צירוף, אבל הוא לא נמצא באותו מיקום כי הטבלה Songs והאינדקס הגלובלי SongsBySongName לא משולבים. תוכנית הביצוע שמתקבלת מורכבת יותר מהדוגמה של הצטרפות לוקלית, כי Spanner מבצע אופטימיזציות כדי להאיץ את הביצוע אם הנתונים לא נמצאים באותו מיקום.
האופרטור העליון הוא distributed cross apply. הקלט של האופרטור הזה הוא קבוצות של שורות מהאינדקס SongsBySongName שמקיימות את התנאי STARTS_WITH(s.SongName, "B"). הפונקציה המבוזרת cross apply ממפה את האצוות האלה לשרתים מרוחקים שהפיצולים שלהם מכילים את נתוני Duration. השרתים המרוחקים משתמשים בסריקת טבלה כדי לאחזר את העמודה Duration.
סריקת הטבלה משתמשת במסנן Condition:($Songs_key_TrackId' =
$batched_Songs_key_TrackId), שמצטרף ל-TrackId מהטבלה Songs ל-TrackId של השורות שחולקו למנות מהאינדקס SongsBySongName.
התוצאות מצטברות לתשובה הסופית לשאילתה. בתמורה, הצד של הקלט של הצלבה מבוזרת מכיל זוג של איחוד מבוזר/איחוד מבוזר מקומי כדי להעריך שורות מהאינדקס שמספקות את התנאי STARTS_WITH.
אפשר לנסות שאילתה קצת שונה שלא בוחרת את העמודה s.Duration:
SELECT s.SongName
FROM Songs@{force_index=SongsBySongName} AS s
WHERE STARTS_WITH(s.SongName, "B");
השאילתה הזו יכולה להשתמש באינדקס באופן מלא, כפי שמוצג בתוכנית הביצוע הזו:
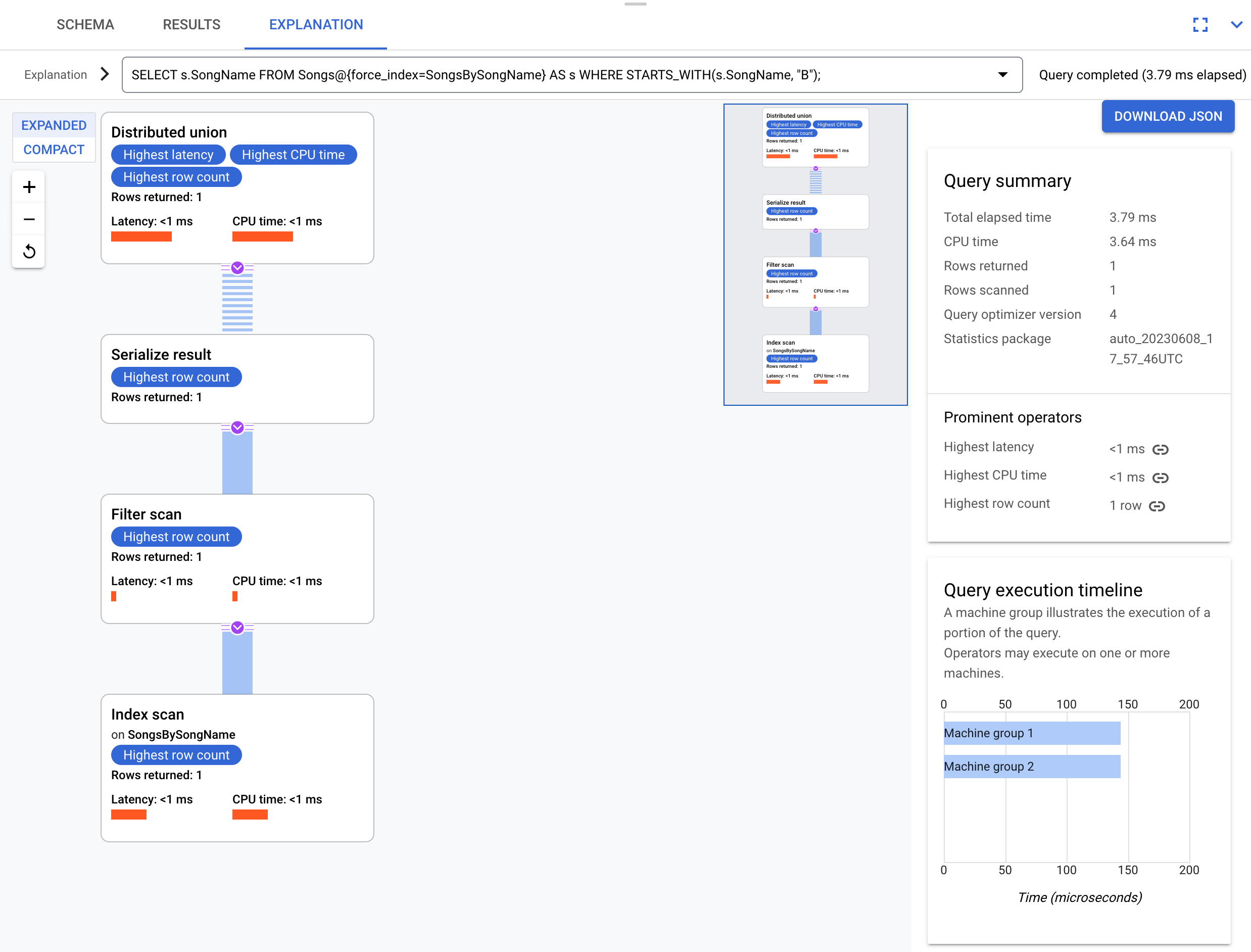
תוכנית הביצוע לא דורשת הצטרפות חוזרת כי כל העמודות שהשאילתה מבקשת נמצאות באינדקס.
המאמרים הבאים
מידע נוסף על אופטימיזציית השאילתות ב-Spanner