
בדף הזה נסביר על המושג המתקדם של סשנים ב-Spanner, כולל שיטות מומלצות לשימוש בסשנים כשיוצרים ספריית לקוח, כשמשתמשים בממשקי ה-API ל-REST או ל-RPC או כשמשתמשים בספריות הלקוח של Google.
סשן מייצג ערוץ תקשורת עם שירות מסד הנתונים של Spanner. סשן משמש לביצוע טרנזקציות שקוראות, כותבות או משנות נתונים במסד נתונים של Spanner. כל סשן חל על מסד נתונים יחיד.
בכל סשן אפשר להריץ עסקה אחת או יותר בכל פעם. כשמבצעים כמה עסקאות, הסשן נקרא סשן מרובה ערוצים. קריאות, כתיבות ושאילתות עצמאיות משתמשות בעסקה אחת באופן פנימי.
היתרונות של מאגר סשנים מבחינת ביצועים
יצירת סשן היא פעולה יקרה. כדי להימנע מהפגיעה בביצועים בכל פעם שמבצעים פעולה במסד נתונים, הלקוחות צריכים לשמור מאגר סשנים, שהוא מאגר של סשנים זמינים שמוכנים לשימוש. המאגר צריך לאחסן סשנים קיימים ולהחזיר את סוג הסשן המתאים כשמתבקש, וגם לטפל בניקוי של סשנים שלא נעשה בהם שימוש. דוגמה להטמעה של מאגר סשנים מופיעה בקוד המקור של אחת מספריות הלקוח של Spanner, כמו ספריית הלקוח של Go.
הסשנים נועדו להיות ארוכי טווח, ולכן אחרי שמשתמשים בסשן לפעולת מסד נתונים, הלקוח צריך להחזיר את הסשן למאגר לשימוש חוזר.
סקירה כללית של ערוצי gRPC
הלקוח של Spanner משתמש בערוצי gRPC לתקשורת. ערוץ gRPC אחד שווה בערך לחיבור TCP. ערוץ gRPC אחד יכול לטפל בעד 100 בקשות בו-זמנית. כלומר, לאפליקציה צריך להיות לפחות מספר ערוצי gRPC ששווה למספר הבקשות המקבילות שהאפליקציה תבצע, חלקי 100.
לקוח Spanner יוצר מאגר של ערוצי gRPC כשיוצרים אותו.
שיטות מומלצות לשימוש בספריות הלקוח של Google
בהמשך מפורטות שיטות מומלצות לשימוש בספריות הלקוח של Google ל-Spanner.
הגדרת מספר הסשנים וערוצי ה-gRPC במאגרי המידע
בספריות הלקוח יש מספר ברירת מחדל של סשנים במאגר הסשנים ומספר ברירת מחדל של ערוצי gRPC במאגר הערוצים. שתי ברירות המחדל מתאימות לרוב המקרים. בטבלה הבאה מפורטים מספר הסשנים המינימלי והמקסימלי שמוגדר כברירת מחדל ומספר ערוצי gRPC שמוגדר כברירת מחדל לכל שפת תכנות.
C++
MinSessions: 100
MaxSessions: 400
NumChannels: 4
C#
MinSessions: 100
MaxSessions: 400
NumChannels: 4
Go
MinSessions: 100
MaxSessions: 400
NumChannels: 4
Java
MinSessions: 100
MaxSessions: 400
NumChannels: 4
Node.js
הלקוח Node.js לא תומך בכמה ערוצי gRPC. לכן, מומלץ ליצור כמה לקוחות במקום להגדיל את גודל מאגר הסשנים מעבר ל-100 סשנים ללקוח יחיד.
MinSessions: 25
MaxSessions: 100
PHP
לקוח PHP לא תומך במספר ערוצי gRPC שניתן להגדרה.
MinSessions: 1
MaxSessions: 500
Python
Python תומך בארבעה סוגים שונים של מאגרי סשנים שבהם אפשר להשתמש כדי לנהל סשנים.
Ruby
לקוח Ruby לא תומך בכמה ערוצי gRPC. לכן, מומלץ ליצור כמה לקוחות במקום להגדיל את גודל מאגר הסשנים מעבר ל-100 סשנים ללקוח יחיד.
MinSessions: 10
MaxSessions: 100
מספר הסשנים שבהם האפליקציה משתמשת שווה למספר העסקאות המקבילות שהאפליקציה מבצעת. כדאי לשנות את הגדרות ברירת המחדל של מאגר הסשנים רק אם אתם צופים שמופע יחיד של אפליקציה יבצע יותר עסקאות בו-זמניות ממה שמאגר הסשנים יכול לטפל בו.
באפליקציות עם רמת מקביליות גבוהה מומלץ:
- מגדירים את
MinSessionsלמספר הצפוי של עסקאות בו-זמניות שיתבצעו על ידי לקוח יחיד. - מגדירים את
MaxSessionsלמספר המקסימלי של עסקאות בו-זמניות שלקוח יחיד יכול לבצע. - מגדירים את
MinSessions=MaxSessionsאם רמת המקבילות הצפויה לא משתנה באופן משמעותי במהלך משך החיים של האפליקציה. כך נמנעת הגדלה או הקטנה של מאגר הסשנים. גם הגדלה או הקטנה של מאגר הסשנים צורכות משאבים. - מגדירים את
NumChannelsלהיותMaxSessions / 100. ערוץ gRPC אחד יכול לטפל בעד 100 בקשות בו-זמנית. כדאי להגדיל את הערך הזה אם מבחינים בזמן אחזור ארוך (זמן אחזור p95/p99), כי זה יכול להצביע על עומס בערוץ gRPC.
הגדלת מספר הסשנים הפעילים דורשת שימוש במשאבים נוספים בשירות מסד הנתונים של Spanner ובספריית הלקוח. הגדלת מספר הסשנים מעבר למה שנדרש בפועל באפליקציה עלולה לפגוע בביצועי המערכת.
הגדלת מאגר הסשנים לעומת הגדלת מספר הלקוחות
גודל מאגר הסשנים של אפליקציה קובע כמה טרנזקציות מקבילות יכולה לבצע מופע יחיד של אפליקציה. לא מומלץ להגדיל את גודל מאגר הסשנים מעבר למקסימום של פעולות בו-זמניות שמופע יחיד של אפליקציה יכול לטפל בהן. אם האפליקציה מקבלת פרץ של בקשות שחורג ממספר הסשנים במאגר, הבקשות מוכנסות לתור בזמן ההמתנה עד שסשן יהיה זמין.
אלה המשאבים שספריית הלקוח צורכת:
- כל ערוץ gRPC משתמש בחיבור TCP אחד.
- כל הפעלה של gRPC דורשת שרשור. מספר ה-threads המקסימלי שבו משתמשים בספריית הלקוח שווה למספר המקסימלי של שאילתות מקבילות שהאפליקציה מריצה. השרשורים האלה מופיעים מעל כל השרשורים שהאפליקציה משתמשת בהם ללוגיקה העסקית שלה.
לא מומלץ להגדיל את הגודל של מאגר הסשנים מעבר למספר המקסימלי של השרשורים שמופע יחיד של אפליקציה יכול לטפל בהם. במקום זאת, צריך להגדיל את מספר המופעים של האפליקציה.
ניהול השבר של סשנים עם הרשאות כתיבה
בספריות לקוח מסוימות, Spanner שומר חלק מהסשנים לעסקאות קריאה-כתיבה. החלק הזה נקרא 'שבריר הסשנים לכתיבה'. אם האפליקציה שלכם משתמשת בכל סשני הקריאה, מערכת Spanner משתמשת בסשנים של קריאה וכתיבה, גם לעסקאות לקריאה בלבד. סשנים עם הרשאות קריאה וכתיבה דורשים
spanner.databases.beginOrRollbackReadWriteTransaction. אם המשתמש נמצא בתפקיד IAM spanner.databaseReader, השיחה תיכשל ו-Spanner יחזיר את הודעת השגיאה הבאה:
generic::permission_denied: Resource %resource% is missing IAM permission:
spanner.databases.beginOrRollbackReadWriteTransaction
בספריות הלקוח ששומרות את השבר של סשנים של כתיבה, אפשר להגדיר את השבר של סשנים של כתיבה.
C++
כל הסשנים של C++ זהים. אין סשנים עם הרשאת קריאה בלבד או הרשאת קריאה וכתיבה בלבד.
C#
ברירת המחדל של שבריר סשנים של כתיבה ב-C# היא 0.2. אפשר לשנות את השבר באמצעות השדה WriteSessionsFraction של SessionPoolOptions.
המשך
כל הסשנים של Go זהים. אין הפעלות עם הרשאת קריאה בלבד או קריאה וכתיבה בלבד.
Java
כל הסשנים של Java זהים. אין סשנים עם הרשאת קריאה בלבד או הרשאת קריאה וכתיבה בלבד.
Node.js
כל הסשנים של Node.js זהים. אין סשנים עם הרשאת קריאה בלבד או הרשאת קריאה וכתיבה בלבד.
PHP
כל הסשנים של PHP זהים. אין סשנים עם הרשאת קריאה בלבד או הרשאת קריאה וכתיבה בלבד.
Python
Python תומך בארבעה סוגים שונים של מאגרי סשנים שאפשר להשתמש בהם כדי לנהל סשנים של קריאה ושל קריאה וכתיבה.
Ruby
ברירת המחדל של שבריר הסשנים של כתיבה ב-Ruby היא 0.3. אפשר לשנות את השבר באמצעות שיטת האתחול של הלקוח.
שיטות מומלצות ליצירת ספריית לקוח או לשימוש ב-REST/RPC
בהמשך מפורטות שיטות מומלצות להטמעה של סשנים בספריית לקוח של Spanner, או לשימוש בסשנים עם ממשקי REST או RPC API.
ההמלצות האלה רלוונטיות רק אם אתם מפתחים ספריית לקוח, או אם אתם משתמשים בממשקי REST/RPC API. אם אתם משתמשים באחת מספריות הלקוח של Google ל-Spanner, כדאי לעיין במאמר שיטות מומלצות לשימוש בספריות לקוח של Google.
יצירה של מאגר סשנים והגדרת הגודל שלו
כדי לקבוע את הגודל האופטימלי של מאגר הסשנים לתהליך לקוח, מגדירים את הגבול התחתון למספר העסקאות הצפויות בו-זמנית, ואת הגבול העליון למספר בדיקה ראשוני, כמו 100. אם הגבול העליון לא מספיק, צריך להגדיל אותו. הגדלת מספר הסשנים הפעילים צורכת משאבים נוספים בשירות מסד הנתונים של Spanner, ולכן אם לא מנקים סשנים שלא נמצאים בשימוש, הביצועים עלולים להיפגע. למשתמשים שעובדים עם RPC API, מומלץ להגביל את מספר הסשנים ל-100 לכל ערוץ gRPC.
טיפול בסשנים שנמחקו
יש שלוש דרכים למחוק סשן:
- לקוח יכול למחוק סשן.
- שירות מסד הנתונים של Spanner יכול למחוק סשן אם הוא לא פעיל במשך יותר משעה.
- יכול להיות ששירות מסד הנתונים של Spanner ימחק סשן אם הוא נוצר לפני יותר מ-28 ימים.
ניסיון להשתמש בסשן שנמחק יגרום להחזרת הערך NOT_FOUND. אם השגיאה הזו מופיעה, צריך ליצור סשן חדש ולהשתמש בו, להוסיף את הסשן החדש למאגר ולהסיר את הסשן שנמחק מהמאגר.
איך שומרים על סשן לא פעיל
שירות מסד הנתונים Spanner שומר לעצמו את הזכות להסיר סשן שלא נעשה בו שימוש. אם אתם צריכים להשאיר סשן לא פעיל פתוח, למשל אם צפויה עלייה משמעותית בשימוש במסד הנתונים בטווח הקרוב, אתם יכולים למנוע את סגירת הסשן. מבצעים פעולה לא יקרה כמו הפעלת שאילתת ה-SQL SELECT 1 כדי שהסשן יישאר פעיל. אם יש לכם סשן לא פעיל שלא נדרש לשימוש בטווח הקרוב, כדאי לאפשר ל-Spanner להפסיק את הסשן, ואז ליצור סשן חדש בפעם הבאה שסשן יידרש.
תרחיש אחד לשמירת הפעלות פעילות הוא טיפול בביקוש שיא קבוע במסד הנתונים. אם יש שימוש כבד במסד הנתונים מדי יום בין השעות 9:00 ל-18:00, כדאי להשאיר כמה סשנים לא פעילים פתוחים במהלך הזמן הזה, כי סביר להניח שהם נדרשים לשימוש בשיא. אחרי השעה 18:00, אפשר לאפשר ל-Spanner להפסיק סשנים לא פעילים. לפני השעה 9:00 בכל יום, יוצרים כמה סשנים חדשים כדי שיהיו מוכנים לביקוש הצפוי.
תרחיש נוסף הוא אם יש לכם אפליקציה שמשתמשת ב-Spanner אבל צריכה להימנע מתקורה של חיבור כשהיא עושה זאת. כדי למנוע את התקורה של החיבור, אפשר להשאיר קבוצה של סשנים פעילים.
הסתרת פרטי הסשן מהמשתמש בספריית הלקוח
אם אתם יוצרים ספריית לקוח, אל תחשפו את הסשנים לצרכן של ספריית הלקוח. הלקוח יכול לבצע קריאות למסד הנתונים בלי הצורך ליצור סשנים ולתחזק אותם. דוגמה לספריית לקוח שמסתירה את פרטי הסשן מהמשתמש בספריית הלקוח: ספריית הלקוח של Spanner ל-Java.
טיפול בשגיאות בעסקאות כתיבה שהן לא אידמפוטנטיות
יכול להיות ששינויים בעסקאות כתיבה ללא הגנה מפני הפעלה חוזרת יחולו יותר מפעם אחת.
אם מוטציה היא לא אידמפוטנטית, מוטציה שמוחלת יותר מפעם אחת עלולה לגרום לכשל. לדוגמה, יכול להיות שפעולת הוספה תיכשל עם השגיאה ALREADY_EXISTS, גם אם השורה לא הייתה קיימת לפני הניסיון לכתוב. מצב כזה יכול לקרות אם השרת העורפי ביצע את השינוי אבל לא הצליח להעביר את ההודעה על ההצלחה ללקוח. במקרה כזה, יכול להיות שיתבצע ניסיון חוזר למוטציה, וכתוצאה מכך תופיע השגיאה ALREADY_EXISTS.
אלה דרכים אפשריות לטפל בתרחיש הזה כשמטמיעים ספריית לקוח משלכם או משתמשים ב-API ל-REST:
- כדאי לבנות את פעולות הכתיבה כך שיהיו אידמפוטנטיות.
- שימוש בפעולות כתיבה עם הגנה מפני הפעלה חוזרת.
- מטמיעים שיטה שמבצעת לוגיקה של 'upsert': מוסיפה אם חדש או מעדכנת אם קיים.
- טיפול בשגיאה בשם הלקוח.
שמירה על חיבורים יציבים
כדי ליהנות מהביצועים הטובים ביותר, החיבור שבו אתם משתמשים כדי לארח סשן צריך להיות יציב. אם החיבור שמארח סשן משתנה, יכול להיות ש-Spanner יבטל את הטרנזקציה הפעילה בסשן ויגרום לעומס נוסף קל על מסד הנתונים בזמן שהוא מעדכן את המטא-נתונים של הסשן. זה בסדר אם כמה חיבורים משתנים באופן ספורדי, אבל כדאי להימנע ממצבים שבהם מספר גדול של חיבורים משתנים בו-זמנית. אם אתם משתמשים בשרת proxy בין הלקוח ל-Spanner, אתם צריכים לשמור על יציבות החיבור לכל סשן.
מעקב אחרי סשנים פעילים
אפשר להשתמש בפקודה ListSessions כדי לעקוב אחרי סשנים פעילים במסד הנתונים משורת הפקודה, באמצעות ה-API ל-REST או באמצעות ה-RPC API. ListSessions מציג את הסשנים הפעילים למסד נתונים נתון. האפשרות הזו שימושית אם אתם צריכים למצוא את הסיבה לדליפת נתונים בסשן. (דליפת סשנים היא אירוע שבו נוצרים סשנים אבל הם לא מוחזרים למאגר סשנים לשימוש חוזר).
ListSessions מאפשר לכם לראות מטא-נתונים על הסשנים הפעילים, כולל מתי נוצר סשן ומתי היה השימוש האחרון בסשן. ניתוח הנתונים האלה יעזור לכם לפתור בעיות בסשנים. אם לרוב הסשנים הפעילים אין approximate_last_use_time עדכני, יכול להיות שהאפליקציה לא משתמשת בסשנים בצורה נכונה. מידע נוסף על השדה approximate_last_use_time זמין במאמר בנושא הפניית API של RPC.
מידע נוסף על השימוש ב-ListSessions זמין בחומר העזר בנושא REST API, בחומר העזר בנושא RPC API או בחומר העזר בנושא כלי שורת הפקודה של gcloud.
ניקוי אוטומטי של דליפות בסשן
כשמנצלים את כל הסשנים במאגר הסשנים, כל טרנזקציה חדשה ממתינה עד שסשן יוחזר למאגר. כשסשנים נוצרים אבל לא מוחזרים למאגר הסשנים לשימוש חוזר, זה נקרא דליפת סשנים. כשמתרחשת דליפת סשן, טרנזקציות שממתינות לסשן פתוח נתקעות ללא הגבלת זמן וחוסמות את האפליקציה. דליפות של סשנים נגרמות לרוב בגלל טרנזקציות בעייתיות שפועלות במשך זמן רב מאוד ולא מתבצעות.
אתם יכולים להגדיר את מאגר הסשנים כך שהמערכת תפתור אוטומטית את הבעיות האלה בעסקאות לא פעילות. כשמפעילים בספריית הלקוח את האפשרות לפתור באופן אוטומטי מעברים לא פעילים, המערכת מזהה עסקאות בעייתיות שעלולות לגרום לדליפת נתונים בסשן, מסירה אותן ממאגר הסשנים ומחליפה אותן בסשן חדש.
הרישום ביומן יכול גם לעזור לזהות את העסקאות הבעייתיות האלה. אם הרישום ביומן מופעל, יומני אזהרה משותפים כברירת מחדל כשנעשה שימוש ביותר מ-95% ממאגר הסשנים. אם השימוש בסשנים גבוה מ-95%, צריך להגדיל את מספר הסשנים המקסימלי שמותר במאגר הסשנים, או שיש דליפת סשנים. יומני אזהרות מכילים עקבות מחסנית של עסקאות שפועלות זמן רב מהצפוי, ויכולים לעזור לזהות את הסיבה לניצול גבוה של מאגר הסשנים. יומני אזהרות נדחפים בהתאם להגדרות של כלי ייצוא היומנים.
הפעלת ספריית הלקוח כדי לפתור באופן אוטומטי עסקאות לא פעילות
אתם יכולים להפעיל את ספריית הלקוח כדי לשלוח יומני אזהרה ולפתור באופן אוטומטי עסקאות לא פעילות, או להפעיל את ספריית הלקוח כדי לקבל רק יומני אזהרה.
Java
כדי לקבל יומני אזהרות ולהסיר טרנזקציות לא פעילות, משתמשים בפקודה setWarnAndCloseIfInactiveTransactions.
final SessionPoolOptions sessionPoolOptions = SessionPoolOptions.newBuilder().setWarnAndCloseIfInactiveTransactions().build()
final Spanner spanner =
SpannerOptions.newBuilder()
.setSessionPoolOption(sessionPoolOptions)
.build()
.getService();
final DatabaseClient client = spanner.getDatabaseClient(databaseId);
כדי לקבל רק יומני אזהרה, משתמשים ב-setWarnIfInactiveTransactions.
final SessionPoolOptions sessionPoolOptions = SessionPoolOptions.newBuilder().setWarnIfInactiveTransactions().build()
final Spanner spanner =
SpannerOptions.newBuilder()
.setSessionPoolOption(sessionPoolOptions)
.build()
.getService();
final DatabaseClient client = spanner.getDatabaseClient(databaseId);
המשך
כדי לקבל יומני אזהרות ולהסיר טרנזקציות לא פעילות, משתמשים בפקודה
SessionPoolConfig עם InactiveTransactionRemovalOptions.
client, err := spanner.NewClientWithConfig(
ctx, database, spanner.ClientConfig{SessionPoolConfig: spanner.SessionPoolConfig{
InactiveTransactionRemovalOptions: spanner.InactiveTransactionRemovalOptions{
ActionOnInactiveTransaction: spanner.WarnAndClose,
}
}},
)
if err != nil {
return err
}
defer client.Close()
כדי לקבל רק יומני אזהרה, משתמשים בפונקציה customLogger.
customLogger := log.New(os.Stdout, "spanner-client: ", log.Lshortfile)
// Create a logger instance using the golang log package
cfg := spanner.ClientConfig{
Logger: customLogger,
}
client, err := spanner.NewClientWithConfig(ctx, db, cfg)
סשנים מרובי-ערוצים
סשנים מרובי-ערוצים מאפשרים ליצור מספר גדול של בקשות בו-זמניות בסשן יחיד. סשן מרובב הוא מזהה שמשתמשים בו בכמה ערוצי gRPC. הוא לא יוצר צווארי בקבוק נוספים. לשימוש בשיטת המולטיפלקס יש את היתרונות הבאים:
- צריכת משאבי ה-Backend פחתה בגלל פרוטוקול פשוט יותר לניהול סשנים. לדוגמה, הם נמנעים מפעולות תחזוקה של סשנים שקשורות לתחזוקה של בעלות על סשנים ולניקוי של נתונים מיותרים.
- סשן לטווח ארוך שלא דורש בקשות keep-alive כשהוא לא פעיל.
סשנים עם ריבוב נתמכים במוצרים הבאים:
- ספריות הלקוח של C++, Go, Java, Node.js, PHP, Python ו-Ruby.
כלים במערכת האקולוגית של Spanner שתלויים בספריות הלקוח שצוינו, כמו PGAdapter, JDBC, Hibernate, database/sql driver, dbAPI driver ו-GORM.
כלים במערכת האקולוגית של Spanner שתלויים בספריות הלקוח של Java ו-Go, כמו PGAdapter, JDBC, Hibernate, מנהל מסד נתונים או מנהל SQL ו-GORM. אפשר להשתמש במדדים של OpenTelemetry כדי לראות איך התנועה מתחלקת בין מאגר הסשנים הקיים לבין סשן המולטיפלקס. ב-OpenTelemetry יש מסנן מדדים,
is_multiplexed, שמציג סשנים מרובי-ערוצים כשהוא מוגדר לערךtrue.
יש תמיכה בסשנים מרובי-ערוצים בכל סוגי העסקאות.
ספריות לקוח מבצעות רוטציה של סשנים מרובי-ערוצים כל 7 ימים כדי למנוע שליחת טרנזקציות בסשנים לא פעילים.
בספריות לקוח מסוימות, הפעלת סשנים מרובי-ערוצים מוגדרת כברירת מחדל. במקרים אחרים, צריך להשתמש במשתני סביבה כדי להפעיל אותם. פרטים נוספים מופיעים במאמר בנושא הפעלת סשנים מרובי-ערוצים.
לתשומת ליבכם
אם אתם מנסים לבצע טרנזקציה ריקה של קריאה או כתיבה, או טרנזקציה שבה כל שאילתה או הצהרת DML נכשלו, יש כמה תרחישים שכדאי לקחת בחשבון כשמשתמשים בסשנים מרובי-ערוצים. בסשנים מרובי-ערוצים צריך לכלול אסימון לפני ביצוע (pre-commit) שנוצר על ידי השרת בכל בקשת ביצוע (commit). בעסקאות שמכילות שאילתות או DML, צריך שתהיה לפחות שאילתה אחת או עסקת DML קודמת שהצליחה כדי שהשרת ישלח בחזרה אסימון תקין לספריית הלקוח. אם לא היו שאילתות או טרנזקציות DML מוצלחות, ספריית הלקוח מוסיפה באופן מרומז את SELECT 1 לפני ביצוע commit.
בטרנזקציה של קריאה או כתיבה בסשן מרובה משתתפים שיש בו רק מוטציות, אם אחת מהמוטציות היא לטבלה או לעמודה שלא קיימות בסכימה, הלקוח יכול להחזיר שגיאת INVALID_ARGUMENT במקום שגיאת NOT_FOUND.
הפעלת סשנים מרובים
הפעלת סשנים מרובי-ערוצים מופעלת כברירת מחדל בספריות הלקוח הבאות:
- C++ בגרסה 2.41.0 ואילך.
- גרסה 1.85.0 ואילך.
- Java בגרסה 6.98.0 ואילך.
- Node.js בגרסה 8.3.0 ואילך.
- PHP בגרסה 2.0.0 ואילך.
- Python בגרסה 3.57.0 ואילך.
- Ruby בגרסה 2.30.0 ואילך.
כדי להשתמש בסשנים מרובי-ערוצים בגרסאות קודמות של ספריות הלקוח של Node.js, Java ו-Go, צריך קודם להגדיר משתנה סביבה כדי להפעיל את התכונה.
כדי להפעיל סשנים מרובי-ערוצים, מגדירים את משתנה הסביבה GOOGLE_CLOUD_SPANNER_MULTIPLEXED_SESSIONS לערך TRUE. הדגל הזה מפעיל גם את התמיכה בסשנים מרובים של ReadOnly טרנזקציות.
export GOOGLE_CLOUD_SPANNER_MULTIPLEXED_SESSIONS=TRUE
כדי להפעיל תמיכה בפעולות מחולקות בסשנים מרובי-ערוצים, מגדירים את משתנה הסביבה GOOGLE_CLOUD_SPANNER_MULTIPLEXED_SESSIONS_PARTITIONED_OPS לערך TRUE.
export GOOGLE_CLOUD_SPANNER_MULTIPLEXED_SESSIONS_PARTITIONED_OPS=TRUE
כדי להפעיל תמיכה בעסקאות קריאה-כתיבה בסשנים מרובי-ערוצים, מגדירים את משתנה הסביבה GOOGLE_CLOUD_SPANNER_MULTIPLEXED_SESSIONS_FOR_RW ל-TRUE.
export GOOGLE_CLOUD_SPANNER_MULTIPLEXED_SESSIONS_FOR_RW=True
כדי לתמוך בטרנזקציה בסשן מרובה ערוצים, צריך להגדיר את GOOGLE_CLOUD_SPANNER_MULTIPLEXED_SESSIONS לערך TRUE.
צפייה בתנועה של סשנים רגילים וסשנים עם ריבוב
ב-OpenTelemetry יש מסנן is_multiplexed להצגת התנועה בסשנים מרובי-ערוצים. כדי לראות סשנים רגילים, מגדירים את המסנן הזה לערך true to view multiplexed sessions
andfalse`.
- מגדירים את OpenTelemetry ל-Spanner באמצעות ההוראות שבקטע לפני שמתחילים במאמר בנושא Spanner OpenTelemetry.
עוברים אל Metrics Explorer.
בתפריט הנפתח מדד, מסננים לפי
generic.לוחצים על Generic Task ועוברים אל Spanner > Spanner/num_acquired_sessions.
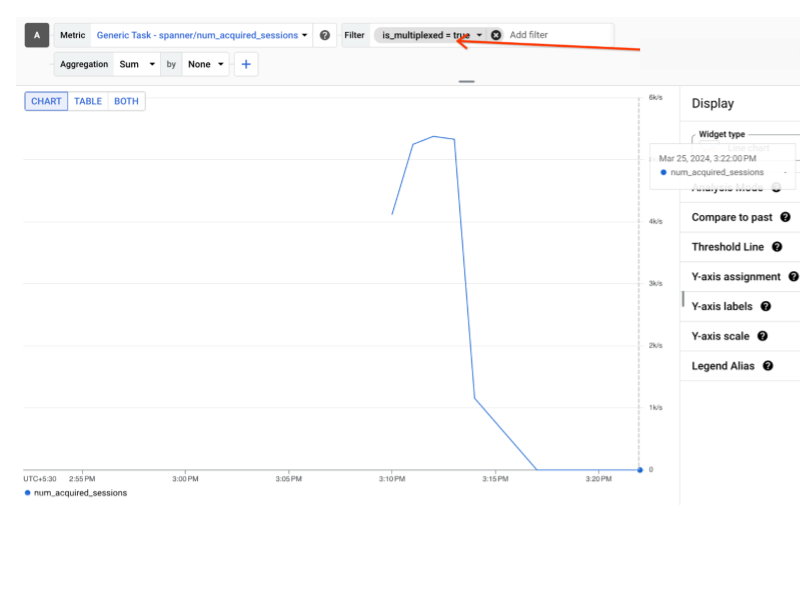
בשדה Filter, בוחרים באחת מהאפשרויות הבאות:
א.
is_multiplexed = falseכדי לראות סשנים רגילים. ב. is_multiplexed = trueכדי לראות סשנים מרובי-ערוצים.בתמונה הבאה מוצגת האפשרות Filter עם בחירה של הפעלות מרובות.
מידע נוסף על שימוש ב-OpenTelemetry עם Spanner זמין במאמרים Leveraging OpenTelemetry to democratize Spanner Observability ו-Examine latency in a Spanner component with OpenTelemetry.
פתרון בעיות
הנה כמה דוגמאות לשגיאות נפוצות שקשורות להפעלת אפליקציות:
Session not foundRESOURCE_EXHAUSTED
מידע נוסף זמין במאמר בנושא שגיאות בסשן.