
במאמר הזה מוסבר איך להשתמש בלוח הבקרה של תובנות המערכת כדי לעקוב אחרי מופעים ומסדי נתונים של Spanner.
סקירה כללית של תובנות המערכת
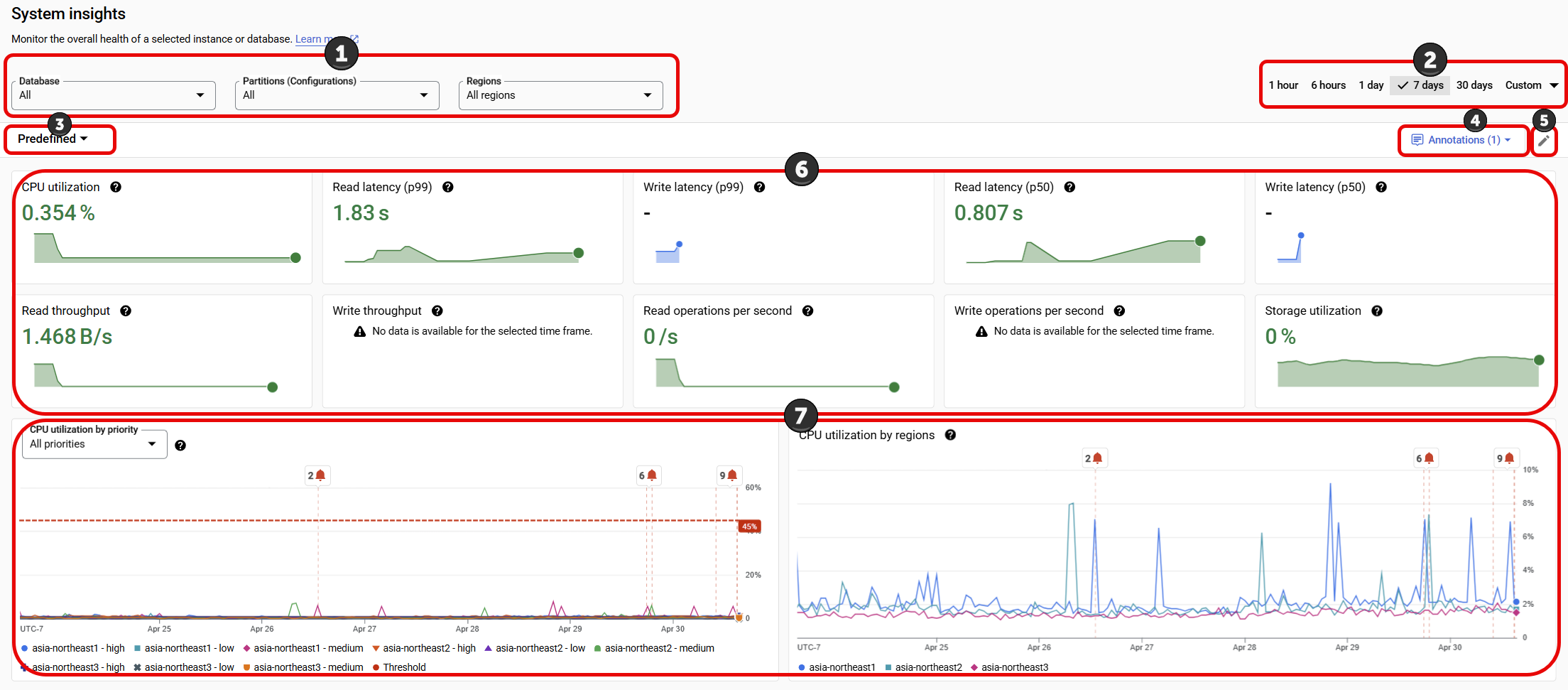
במרכז הבקרה של תובנות המערכת מוצגים כרטיסי מידע ותרשימים לגבי מופע או מסד נתונים שנבחרו, ומוצגים מדדים של זמן אחזור, ניצול CPU, אחסון, קצב העברת נתונים ונתונים סטטיסטיים אחרים של ביצועים. אפשר לראות תרשימים של תקופות זמן לבחירה, החל משעה אחת ועד 30 ימים.
לוח הבקרה של תובנות המערכת כולל את הקטעים הבאים, עם מספרים שתואמים לצילום המסך הבא של ממשק המשתמש:
- אפשרויות בחירה של תובנות: בוחרים את מסדי הנתונים, מחיצות המופעים והאזורים שיוצגו בלוח הבקרה. בתובנות לגבי המערכת מוצגים מחיצות של מופעים ובחירות של אזורים, אם יש במופע כמה מחיצות או אזורים.
- מסנן טווח זמן: סינון הנתונים הסטטיסטיים לפי טווח זמן, כמו שעות, ימים או טווח מותאם אישית.
- בורר מרכזי הבקרה: מאפשר לבחור תצוגות שהמשתמשים התאימו אישית, או לאפס את התובנות של המערכת לתצוגת ברירת המחדל המוגדרת מראש.
- הערות: בוחרים את סוגי האירועים של התראות על תובנות כדי להוסיף הערות לתרשימים.
- התאמה אישית של מרכזי בקרה: אפשר להתאים אישית את המראה, המיקום והתוכן של הווידג'טים במרכז הבקרה ושל מרכז הבקרה של תובנות המערכת. במסמך הזה מתואר אופן ההצגה של לוח הבקרה המוגדר מראש.
- כרטיסי מדדים: מציגים נתונים סטטיסטיים בנקודת זמן מסוימת, במהלך התקופה שנבחרה.
- תרשימים: תרשימים של ניצול המעבד, קצב העברת הנתונים, זמן האחזור, השימוש באחסון ועוד. התראות על תובנות שהוגדרו באמצעות הערות מופיעות בתרשימים עם סמלי פעמון.
התפקידים הנדרשים
כדי לקבל את ההרשאות שדרושות לצפייה בלוחות בקרה של תובנות או לשינוי שלהם, כולל לוחות בקרה בהתאמה אישית, צריך לבקש מהאדמין להקצות לכם את תפקידי ה-IAM הבאים בפרויקט:
-
כדי לגשת למדדים שנוצרו על ידי פרויקט Spanner:
צפייה ב-Cloud Spanner (
roles/spanner.viewer) -
כדי ליצור ולערוך לוחות בקרה בהתאמה אישית:
כלי העריכה של לוח הבקרה של Monitoring (
roles/monitoring.dashboardEditor) -
כדי לפתוח ולראות תרשימים של Metrics Explorer, כולל מרכזי בקרה בהתאמה אישית:
צפייה בהגדרות של לוח הבקרה של Monitoring (
roles/monitoring.dashboardViewer) -
כדי ליצור ולערוך התראות ב-Metrics Explorer:
עריכת Monitoring (
roles/monitoring.editor) -
כדי להציג את הדף 'תובנות לגבי המערכת':
Cloud Spanner Database Reader (
roles/spanner.databaseReader) -
כדי לצפות ביומנים שנוצרו על ידי שינוי גודל אוטומטי מנוהל:
מציג היומנים (
roles/logging.viewer)
להסבר על מתן תפקידים, ראו איך מנהלים את הגישה ברמת הפרויקט, התיקייה והארגון.
התפקידים המוגדרים מראש האלה כוללים את ההרשאות שנדרשות כדי להציג או לשנות לוחות בקרה של תובנות, כולל לוחות בקרה בהתאמה אישית. כדי לראות בדיוק אילו הרשאות נדרשות, אפשר להרחיב את הקטע ההרשאות הנדרשות:
ההרשאות הנדרשות
כדי להציג או לשנות מרכזי תובנות, כולל מרכזי תובנות בהתאמה אישית, נדרשות ההרשאות הבאות:
-
כדי לגשת למדדים שנוצרו על ידי פרויקט Spanner:
monitoring.timeSeries.list -
כדי ליצור מרכזי בקרה בהתאמה אישית:
monitoring.dashboards.create -
כדי לערוך מרכזי בקרה בהתאמה אישית:
monitoring.dashboards.update -
כדי להציג מרכזי בקרה בהתאמה אישית:
monitoring.dashboards.get, monitoring.dashboards.list -
כדי לראות את דף התובנות לגבי המערכת:
spanner.databases.beginReadOnlyTransaction, spanner.databases.select, spanner.sessions.create -
כדי לראות את היומנים שנוצרו על ידי כלי לשינוי גודל אוטומטי מנוהל:
logging.logEntries.list, logging.logs.list, logging.logServices.list
יכול להיות שתקבלו את ההרשאות האלה באמצעות תפקידים בהתאמה אישית או תפקידים מוגדרים מראש אחרים.
התאמה אישית של מרכז הבקרה של תובנות המערכת
לוח הבקרה 'תובנות לגבי המערכת' הוא לוח בקרה מוגדר מראש שאפשר להתאים אישית כדי להציג את המידע שהכי חשוב לכם. אפשר להוסיף תרשימים חדשים, לשנות את הפריסה ולסנן את הנתונים כדי להתמקד במשאבים ספציפיים.
השינויים בלוח הבקרה של תובנות המערכת לא הרסניים, ואפשר לאפס אותם על ידי הגדרת בורר לוחות הבקרה למוגדר מראש.
שינוי לוח הבקרה
כדי לשנות את מרכז הבקרה, לוחצים על התאמה אישית של מרכזי בקרה. אלה האפשרויות שעומדות לרשותכם:
- כדי להוסיף ווידג'ט: בסרגל הכלים של לוח הבקרה, לוחצים על הוספת ווידג'ט, בוחרים את הווידג'ט שרוצים להוסיף ומגדירים אותו.
- כדי לערוך ווידג'ט: מעבירים את העכבר מעל הווידג'ט כדי להציג את סרגל הכלים שלו, ואז לוחצים על עריכה. אפשר לשנות את סוג הווידג'ט ולהתאים אישית את הנתונים שמוצגים בו.
- שיבוט של ווידג'ט: מעבירים את העכבר מעל הווידג'ט כדי להציג את סרגל הכלים שלו, לוחצים על אפשרויות נוספות של התרשים ואז על שיבוט הווידג'ט.
- כדי למחוק ווידג'ט: מעבירים את העכבר מעל הווידג'ט כדי להציג את סרגל הכלים שלו, לוחצים על אפשרויות נוספות של התרשים ואז על מחיקת הווידג'ט.
- שינוי הפריסה: אפשר לגרור את הווידג'טים כדי לשנות את המיקום שלהם, ולגרור את הפינות שלהם כדי לשנות את הגודל שלהם.
- נותנים שם לתצוגה המותאמת אישית: אפשר להגדיר את השם של התצוגה המותאמת אישית בתיבה שם התצוגה המותאמת אישית.
- שמירת לוח הבקרה: כדי לשמור את התצוגה המותאמת אישית, לוחצים על שמירה. אפשר גם לצאת בלי לשמור את השינויים על ידי לחיצה על יציאה ממצב עריכה.
כרטיסי מידע, תרשימים ומדדים של תובנות לגבי המערכת
בלוח הבקרה של תובנות המערכת מוצגים התרשימים והמדדים הבאים, כדי להציג את הסטטוס הנוכחי וההיסטורי של מופע. רוב התרשימים והמדדים זמינים ברמת המופע. אפשר גם לראות הרבה תרשימים ומדדים של מסד נתונים יחיד בתוך מופע.
כרטיסי מידע זמינים
| שם | תיאור |
|---|---|
| ניצול יחידת העיבוד המרכזית (CPU) | סה"כ השימוש במעבד במופע או במסד נתונים נבחר. במופע של שני אזורים או של כמה אזורים, המדד הזה מייצג את ממוצע השימוש במעבד באזורים. |
| זמן אחזור (p99) | חביון P99 (האחוזון ה-99) לפעולות קריאה וכתיבה במופע או במסד נתונים נבחר, שמייצג את הזמן שבו 99% מהפעולות האלה מסתיימות. |
| זמן אחזור (p50) | חביון P50 (האחוזון ה-50) לפעולות קריאה וכתיבה בתוך מופע או מסד נתונים נבחר, שמייצג את הזמן שבו 50% מהפעולות האלה מסתיימות. |
| תפוקה | כמות הנתונים הלא דחוסים שנקראו מהמופע או מהמסד או נכתבו אליהם בכל שנייה. הערך הזה נמדד בבייטים בינאריים, כמו KiB, MiB או GiB. |
| פעולות לשנייה | מספר הפעולות בשנייה (קצב) של קריאה וכתיבה במופע או במסד נתונים שנבחר. |
| ניצול נפח האחסון | ברמת המופע, זהו אחוז ניצול האחסון הכולל בתוך מופע. ברמת מסד הנתונים, זהו סך נפח האחסון שמשמש את מסד הנתונים שנבחר. |
תרשימים ומדדים זמינים
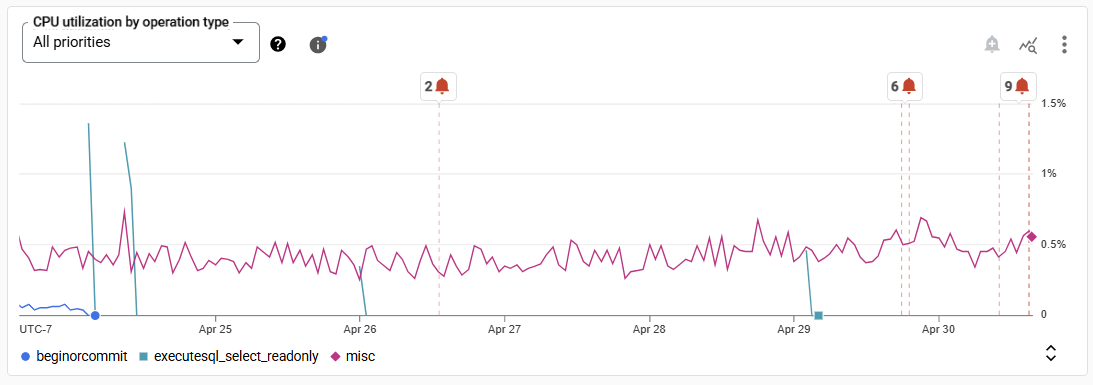
התרשים הבא מציג מדד לדוגמה, ניצול המעבד לפי סוג הפעולה:
סרגל הכלים בכל תרשים כולל את האפשרויות הסטנדרטיות הבאות. חלק מהרכיבים מוסתרים אלא אם מחזיקים את הסמן מעל התרשים.
כדי להגדיל חלק מסוים בתרשים, גוררים את מצביע העכבר על החלק שרוצים לראות. הפעולה הזו מגדירה טווח זמן מותאם אישית, שאפשר לשנות או לבטל באמצעות המסנן Time range.
כדי לראות תיאור של התרשים והנתונים שלו, לוחצים על הסמל help.
כדי לראות את המסננים והקיבוצים שמוחלים על התרשים, לוחצים על info.
כדי ליצור התראה על סמך הנתונים בתרשים, לוחצים על add_alert.
כדי לעיין בנתונים בתרשים, לוחצים על הסמל query_stats.
כדי לראות עוד אפשרויות לתרשים, לוחצים על more_vert עוד אפשרויות לתרשים.
כדי להציג תרשים במסך מלא, לוחצים על הצגה במסך מלא. כדי לצאת ממסך מלא, לוחצים על ביטול או מקישים על Esc.
כדי להרחיב או לכווץ את מקרא התרשים, לוחצים על הרחבה או כיווץ של מקרא התרשים.
כדי להוריד את התרשים, לוחצים על הורדה ובוחרים פורמט הורדה.
כדי לשנות את הפורמט החזותי של התרשים, לוחצים על מצב ובוחרים מצב תצוגה.
כדי לראות את המדד ב-Metrics Explorer, לוחצים על View in Metrics Explorer. אפשר לראות מדדים אחרים של Spanner ב-Metrics Explorer אחרי שבוחרים את סוג המשאב Spanner Database.
בטבלה הבאה מתוארים התרשימים שמופיעים כברירת מחדל בלוח הבקרה של תובנות המערכת. סוג המדד של כל תרשים מופיע ברשימה. מחרוזות של סוגי מדדים מתחילות בתחילית הבאה: spanner.googleapis.com/. סוג המדד מתאר מדידות שאפשר לאסוף ממשאב במעקב.
| שם התרשים וסוג המדד |
תיאור | זמין למופעים | זמין למסדי נתונים |
|---|---|---|---|
|
ציר זמן של תקינות קוורום בשני אזורים instance/dual_region_quorum_availability |
התרשים הזה מוצג רק עבור הגדרות של מופעים עם שני אזורים. מוצג בו הסטטוס של שלוש קבוצות קוורום: קבוצת הקוורום בשני אזורים ( Global) וקבוצת הקוורום החד-אזורית בכל אזור (לדוגמה, Sydney ו-Melbourne). אם יש שיבוש בשירות, מוצג פס כתום בציר הזמן. אפשר להעביר את העכבר מעל הסרגל כדי לראות את זמני ההתחלה והסיום של השיבוש. אפשר להשתמש בתרשים הזה לצד שיעורי השגיאות ומדדי זמן האחזור כדי לקבל החלטות לגבי ניהול עצמי של מעבר לגיבוי בעת כשל אזורי. מידע נוסף זמין במאמר בנושא מעבר לגיבוי (Failover) וחזרה מגיבוי (Failback). כדי לבצע מעבר לגיבוי פעיל וחזרה מגיבוי פעיל באופן ידני, אפשר לעיין במאמר בנושא שינוי קוורום של שני אזורים. |
done |
done |
ניצול המעבד (CPU) לפי עדיפות instance/cpu/utilization_by_priority |
אחוז משאבי ה-CPU של המופע למשימות בעדיפות גבוהה, בינונית או נמוכה. המשימות האלה כוללות בקשות שאתם יוזמים ומשימות תחזוקה ש-Spanner צריך להשלים במהירות. במקרים של מופעים בשני אזורים או במספר אזורים, המדדים מקובצים לפי האזור והעדיפות. מידע נוסף על משימות בעדיפות גבוהה מידע נוסף על ניצול המעבד |
done |
close |
|
ניצול המעבד לפי אזור instance/cpu/utilization_by_priority |
השימוש במעבד המרכזי במופע או במסד הנתונים שנבחרו, מקובץ לפי אזור. | done |
done |
|
ניצול המעבד (CPU) לפי מסד נתונים instance/cpu/utilization_by_priority |
הניצול של המעבד במופע שנבחר, מקובץ לפי מסד נתונים ואזור. | done |
close |
|
ניצול המעבד (CPU) לפי משתמש/מערכת instance/cpu/utilization_by_priority |
השימוש במעבד המרכזי במופע או במסד הנתונים שנבחרו, מקובץ לפי משימות של משתמשים ומשימות של המערכת, ולפי עדיפות. | done |
done |
ניצול המעבד (CPU) לפי סוג הפעולה instance/cpu/utilization_by_operation_type |
תרשים עמודות מוערמות של ניצול המעבד כאחוז ממשאבי המעבד של המכונה, מקובצים לפי פעולות שהמשתמש יזם, כמו קריאות, כתיבות והתחייבויות. אפשר להשתמש במדד הזה כדי לקבל פירוט של השימוש במעבד ולפתור בעיות נוספות, כמו שמוסבר במאמר בדיקת ניצול גבוה של המעבד. אפשר לסנן עוד יותר לפי העדיפות של המשימות באמצעות רשימת האפשרויות. במקרים של מופעים בשני אזורים או במספר אזורים, המדדים בתרשים הקווים מציגים את אחוז הממוצע בין האזורים. |
done |
done |
ניצול המעבד (ממוצע נע ב-24 שעות) instance/cpu/smoothed_utilization |
ממוצע נע של סה"כ השימוש במעבד של Spanner, כאחוז ממשאבי המעבד של המופע, לכל מסד נתונים. כל נקודה על הגרף מייצגת את הממוצע של 24 השעות האחרונות. |
done |
close |
זמן אחזור api/request_latencies |
משך הזמן שחלף עד ש-Spanner טיפל בבקשת קריאה או כתיבה. המדידה הזו מתחילה כש-Spanner מקבל בקשה, ומסתיימת כש-Spanner מתחיל לשלוח תגובה. אפשר להשתמש ברשימת האפשרויות כדי לראות את מדדי זמן האחזור של האחוזון ה-50 והאחוזון ה-99. |
close |
done |
זמן אחזור לפי מסד נתונים api/request_latencies |
משך הזמן שחלף מרגע ש-Spanner קיבל בקשת קריאה או כתיבה ועד לטיפול בה, מקובץ לפי מסד נתונים. המדידה הזו מתחילה כש-Spanner מקבל בקשה, ומסתיימת כש-Spanner מתחיל לשלוח תגובה. כדי לראות את מדדי השהייה של האחוזון ה-50 וה-99, צריך להשתמש ברשימת התצוגה בתרשים הזה. |
done |
close |
זמן האחזור לפי שיטת API api/request_latencies |
הזמן שחלף מרגע שליחת הבקשה ועד ש-Spanner סיים לטפל בה, מקובץ לפי שיטות Spanner API. המדידה הזו מתחילה כש-Spanner מקבל בקשה, ומסתיימת כש-Spanner מתחיל לשלוח תגובה. כדי לראות את מדדי השהיות באחוזון ה-50 ובאחוזון ה-99, אפשר להשתמש ברשימת התצוגה בתרשים הזה. |
close |
done |
Transaction latency api/request_latencies_by_transaction_type |
משך הזמן שנדרש ל-Spanner לעיבוד עסקה. אתם יכולים לבחור להציג מדדים עבור טרנזקציות מסוג קריאה-כתיבה וקריאה בלבד. ההבדל העיקרי בין תרשים ההשהיה לבין תרשים ההשהיה של העסקאות הוא שבתרשים ההשהיה של העסקאות אפשר לראות את מעורבות הלידים בסוג הקריאה בלבד. יכול להיות שזמן האחזור יהיה ארוך יותר לפעולות קריאה שכוללות את הלידר. אפשר להשתמש בתרשים הזה כדי להעריך אם כדאי להשתמש בקריאות של נתונים לא עדכניים בלי לתקשר עם הלידר, בהנחה שהגבלת חותמת הזמן היא לפחות 15 שניות. בעסקאות קריאה-כתיבה, הצומת הראשי תמיד מעורב בעסקה, ולכן הנתונים שמוצגים בתרשים תמיד כוללים את הזמן שנדרש לבקשה להגיע לצומת הראשי ולקבל תשובה. המיקום תואם לאזור של הקצה הקדמי של Cloud Spanner API. כדי לראות את מדדי השהיות באחוזון ה-50 ובאחוזון ה-99, אפשר להשתמש ברשימת התצוגה בתרשים הזה. |
close |
done |
זמן אחזור של עסקאות לפי מסד נתונים api/request_latencies_by_transaction_type |
משך הזמן שנדרש ל-Spanner לעיבוד עסקה. ההבדל העיקרי בין תרשים זמן האחזור לבין תרשים זמן האחזור של העסקאות לפי מסד הנתונים הוא שבתרשים זמן האחזור של העסקאות לפי מסד הנתונים אפשר לראות את מעורבות הלידים בסוג הקריאה בלבד. יכול להיות שזמן הטעינה יהיה ארוך יותר לקריאות שכוללות את הלידר. אתם יכולים להשתמש בתרשים הזה כדי להעריך אם כדאי להשתמש בקריאות לא עדכניות בלי לתקשר עם ה-leader, בהנחה שהגבלת חותמת הזמן היא לפחות 15 שניות. בעסקאות קריאה-כתיבה, הצומת הראשי תמיד מעורב בעסקה, ולכן הנתונים שמוצגים בתרשים תמיד כוללים את הזמן שנדרש לבקשה להגיע לצומת הראשי ולקבל תשובה. המיקום תואם לאזור של הקצה הקדמי של Cloud Spanner API. כדי לראות את מדדי השהיות באחוזון ה-50 ובאחוזון ה-99, אפשר להשתמש ברשימת התצוגה בתרשים הזה. |
done |
close |
Transaction latency by API method api/request_latencies_by_transaction_type |
משך הזמן שנדרש ל-Spanner לעיבוד עסקה. ההבדל העיקרי בין תרשים זמן האחזור לבין תרשים זמן האחזור של העסקאות לפי שיטת API הוא שבתרשים זמן האחזור של העסקאות לפי שיטת API אפשר לראות את מעורבות הלידים בסוג הקריאה בלבד. יכול להיות שזמן הטעינה יהיה ארוך יותר לקריאות שכוללות את הלידר. אתם יכולים להשתמש בתרשים הזה כדי להעריך אם כדאי להשתמש בקריאות לא עדכניות בלי לתקשר עם ה-leader, בהנחה שהחותמת של הגבול הזמני היא לפחות 15 שניות. בעסקאות קריאה-כתיבה, תמיד יש מעורבות של הלידר בעסקה, ולכן הנתונים שמוצגים בתרשים תמיד כוללים את הזמן שנדרש לבקשה להגיע ללידר ולקבל תשובה. המיקום תואם לאזור של הקצה הקדמי של Cloud Spanner API. |
close |
done |
פעולות בשנייה api/api_request_count |
מספר פעולות הקריאה והכתיבה ש-Spanner מבצעת בכל שנייה, או מספר שגיאות השרת של Spanner בכל שנייה. אפשר לבחור אילו פעולות יוצגו בתרשים הזה:
|
close |
done |
Operations per second by database api/api_request_count |
מספר פעולות הקריאה והכתיבה ש-Spanner מבצעת בכל שנייה, או מספר שגיאות השרת של Spanner בכל שנייה. התרשים הזה מקובץ לפי מסד נתונים. אפשר לבחור אילו פעולות יוצגו בתרשים הזה:
|
done |
close |
פעולות בשנייה לפי שיטת API api/api_request_count |
מספר הפעולות ש-Spanner ביצע בכל שנייה, מקובצות לפי שיטת Spanner API |
close |
done |
Throughput api/sent_bytes_count (read) api/received_bytes_count (write) |
כמות הנתונים הלא דחוסים שנקראים מהמסד או נכתבים בו בכל שנייה. הערך הזה נמדד בבייטים בינאריים, כמו KiB, MiB או GiB. הנתון 'קצב העברת נתונים לקריאה' כולל בקשות ותגובות לשיטות בread API ולשאילתות SQL. הוא כולל גם בקשות ותגובות של הצהרות DML. התפוקה של פעולות כתיבה כוללת בקשות ותגובות לשמירת נתונים באמצעות mutation API. הוא לא כולל בקשות ותשובות להצהרות DML. |
close |
done |
Throughput by database api/sent_bytes_count (read) api/received_bytes_count (write) |
כמות הנתונים הלא דחוסים שנקראו מהמופע ונכתבו אליו בכל שנייה, מקובצים לפי מסד נתונים. הערך הזה נמדד בבייטים בינאריים, כמו KiB, MiB או GiB. הנתון 'קצב העברת נתונים לקריאה' כולל בקשות ותגובות לשיטות בread API ולשאילתות SQL. הוא כולל גם בקשות ותגובות של הצהרות DML. התפוקה של פעולות כתיבה כוללת בקשות ותגובות לשמירת נתונים באמצעות mutation API. הוא לא כולל בקשות ותשובות להצהרות DML. |
done |
close |
Throughput by API method api/sent_bytes_count (read) api/received_bytes_count (write) |
כמות הנתונים הלא דחוסים שנקראו מהמופע או מהמסד, או שנכתבו למופע או למסד, בכל שנייה, מקובצים לפי שיטת API. הערך הזה נמדד בבייטים בינאריים, כמו KiB, MiB או GiB. הנתון 'קצב העברת נתונים לקריאה' כולל בקשות ותגובות לשיטות בread API ולשאילתות SQL. הוא כולל גם בקשות ותגובות של הצהרות DML. התפוקה של פעולות כתיבה כוללת בקשות ותגובות לשמירת נתונים באמצעות mutation API. הוא לא כולל בקשות ותשובות להצהרות DML. |
close |
done |
חיבורים חדשים instance/connection_creation_count |
השיעור הממוצע של חיבורים פעילים חדשים שנוצרו עם מסד הנתונים, בחיבורים לדקה. |
done |
done |
בייטים שנקראו או נסרקו instance/read/bytes |
השיעור הממוצע של בייטים של נתונים שנקראו או נסרקו ממסד הנתונים, בבייטים לדקה. |
done |
done |
בייטים שהוחזרו api/sent_bytes_count |
הקצב הממוצע של בייטים של נתונים שמוחזרים על ידי מסד הנתונים, בבייטים לדקה. |
done |
done |
Bytes written api/received_bytes_count |
הקצב הממוצע של בייטים של נתונים שנכתבו במסד הנתונים, בבייטים לדקה. |
done |
done |
DML throughput (insert) instance/dml/inserted_rows_count |
השיעור הממוצע של שורות DML של הכנסה שהופעלו, בשורות לדקה. |
done |
done |
קצב העברת הנתונים של DML (עדכון) instance/dml/updated_rows_count |
השיעור הממוצע של שורות DML של עדכון שהופעלו, בשורות לדקה. |
done |
done |
קצב העברת הנתונים של DML (מחיקה) instance/dml/deleted_rows_count |
השיעור הממוצע של שורות DML שנמחקו, ביחידות של שורות לדקה. |
done |
done |
נפח אחסון כולל instance/storage/used_bytes |
כמות הנתונים שמאוחסנים במסד הנתונים. הערך הזה נמדד בבייטים בינאריים, כמו KiB, MiB או GiB. |
close |
done |
Total database storage by database instance/storage/used_bytes |
כמות הנתונים שמאוחסנים במופע, מקובצים לפי מסד נתונים. הערך הזה נמדד בבייטים בינאריים, כמו KiB, MiB או GiB. |
done |
close |
נפח האחסון הכולל של הגיבוי instance/backup/used_bytes |
כמות הנתונים שמאוחסנים בגיבויים שמשויכים למסד הנתונים. הערך הזה נמדד בבייטים בינאריים, כמו KiB, MiB או GiB. |
close |
done |
זמן המתנה לנעילה lock_stat/total/lock_wait_time |
זמן ההמתנה לנעילה של עסקה הוא הזמן שנדרש כדי לקבל נעילה של משאב שנמצא בשימוש על ידי עסקה אחרת. זמן ההמתנה הכולל לנעילה עבור lock מחלוקות מתועד עבור כל מסד הנתונים. |
close |
done |
זמן ההמתנה לנעילה לפי מסד נתונים lock_stat/total/lock_wait_time |
זמן ההמתנה לנעילה של טרנזקציה הוא הזמן שנדרש כדי לקבל נעילה של משאב שנמצא בשימוש של טרנזקציה אחרת, מקובץ לפי מסד נתונים. זמן ההמתנה הכולל לנעילה עבור lock conflicts מתועד עבור כל המופע. |
done |
close |
נפח אחסון הגיבוי הכולל לפי מסד נתונים instance/backup/used_bytes |
כמות הנתונים שמאוחסנים בגיבויים שמשויכים למופע, מקובצים לפי מסד נתונים. הערך הזה נמדד בבייטים בינאריים, כמו KiB, MiB או GiB. |
done |
close |
קיבולת מחשוב instance/processing_units instance/nodes |
קיבולת החישוב היא כמות יחידות העיבוד או הצמתים שזמינים במכונה. אתם יכולים לבחור להציג את הקיבולת ביחידות עיבוד או בצמתים. |
done |
close |
התפלגות של מנהיגים instance/leader_percentage_by_region |
במקרים של מכונות בשני אזורים או במספר אזורים, אפשר לראות את מספר מסדי הנתונים עם רוב הלידים (>=50%) באזור נתון. בתפריט הרשימה Regions (אזורים), אם בוחרים אזור ספציפי, בתרשים מוצג המספר הכולל של מסדי הנתונים במופע הזה שבו האזור שנבחר הוא האזור הראשי. אם בוחרים באפשרות All regions בתפריט הרשימה Regions, בתרשים תוצג שורה לכל אזור, וכל שורה תציג את המספר הכולל של מסדי הנתונים במופע שמוגדר בו האזור הזה כאזור הראשי. במסדי נתונים במופע של שני אזורים או מספר אזורים, אפשר לראות את אחוז הלידים שמקובצים לפי אזור. לדוגמה, אם במסד נתונים יש חמישה מובילים, אחד ב- us-west1 וארבעה ב-us-east1 בנקודת זמן מסוימת, בתרשים 'כל האזורים' יוצגו שני קווים (אחד לכל אזור). קו אחד של us-west1 נמצא ב-20%, והקו השני של us-east1 נמצא ב-80%. בתרשים us-west1 מוצג קו יחיד ב-20%, ובתרשים us-east1 מוצג קו יחיד ב-80%.הערה: אם מסד נתונים נוצר לאחרונה או שאזור ראשי עבר שינוי לאחרונה, יכול להיות שהתרשימים לא יתייצבו מיד. התרשים הזה זמין רק למופעים של שני אזורים או מספר אזורים. |
done |
done |
ציון שיא השימוש ב-CPU המפוצל instance/peak_split_peak |
השימוש המקסימלי במעבד שחולק בין כל הפיצולים במסד נתונים. המדד הזה מציג את אחוז המשאבים של יחידת העיבוד שנעשה בהם שימוש בפיצול. אחוז של מעל 50% הוא פיצול חם, כלומר הפיצול משתמש במחצית מהמשאבים של יחידת העיבוד של שרת המארח. אחוז של 100% הוא פיצול חם, כלומר פיצול שמשתמש ברוב משאבי יחידת העיבוד של שרת המארח. Spanner משתמש בפיצול מבוסס-עומס כדי לפתור בעיות של נקודות חמות ולאזן את העומס. עם זאת, יכול להיות ש-Spanner לא יוכל לאזן את העומס, גם אחרי כמה ניסיונות פיצול, בגלל דפוסים בעייתיים באפליקציה. לכן, אם נקודות חמות נמשכות לפחות 10 דקות, יכול להיות שצריך לבצע פתרון בעיות נוסף, ואולי גם לשנות את האפליקציה. מידע נוסף מופיע במאמר בנושא איתור אזורים חמים בפיצולים. | done |
done |
|
קריאות לשירותים מרחוק query_stat/total/remote_service_calls_count |
מספר הקריאות לשירותים מרוחקים, מקובצות לפי השירות וקודי התגובה. משיב עם קוד תגובת HTTP, כמו 200 או 500. |
done |
done |
|
זמן אחזור: קריאות לשירותים מרוחקים query_stat/total/remote_service_calls_latencies |
החביון של קריאות לשירותים מרוחקים, מקובצים לפי שירות. אפשר להציג את מדדי זמן האחזור של האחוזון ה-50 וה-99 של זמני האחזור באמצעות רשימת האפשרויות. |
done |
done |
|
שורות שעובדו בשירות מרוחק query_stat/total/remote_service_processed_rows_count |
מספר השורות שעובדו על ידי שירות מרוחק, מקובצות לפי נותן השירות וקודי התגובה. משיב עם קוד תגובת HTTP, כמו 200 או 500. |
done |
done |
|
זמן אחזור: שורות של שירות מרוחק query_stat/total/remote_service_processed_rows_latencies |
מספר השורות שעובדו על ידי שירות מרוחק, מקובצות לפי השירות וקודי התגובה. אפשר להשתמש ברשימת האפשרויות כדי לראות את מדדי זמן האחזור של האחוזון ה-50 וה-99. |
done |
done |
|
Remote service network bytes query_stat/total/remote_service_network_bytes_sizes |
מספר הבייטים ברשת שהועברו עם השירות המרוחק, מקובצים לפי שירות וכיוון. הערך הזה נמדד בבייטים בינאריים, כמו KiB, MiB או GiB. הכיוון מתייחס לתנועה שנשלחת או מתקבלת. אפשר להשתמש ברשימת האפשרויות כדי לראות את המדדים של חילופי בייטים ברשת באחוזון ה-50 ובאחוזון ה-99. |
done |
done |
|
קריאות לשירותי מיקרו query_stat/total/remote_service_calls_count |
מספר הקריאות לשירותי מיקרו, מקובצות לפי שירות מיקרו וקוד תגובה. | done |
done |
|
זמן אחזור: קריאות לשירותי מיקרו query_stat/total/remote_service_calls_latencies |
זמני האחזור של קריאות לשירותי מיקרו, מקובצים לפי שירות מיקרו. | done |
done |
Database storage by table (none) |
כמות הנתונים שמאוחסנים במופע או במסד הנתונים, מקובצים לפי טבלאות במסד הנתונים שנבחר. הערך הזה נמדד בבייטים בינאריים, כמו KiB, MiB או GiB. הנתונים בתרשים הזה מתקבלים משאילתה של SPANNER_SYS.TABLE_SIZES_STATS_1HOUR. מידע נוסף זמין במאמר בנושא
נתונים סטטיסטיים על גדלי טבלאות. |
close |
done |
Most-used tables by operations (none) |
15 הטבלאות והאינדקסים שהכי הרבה משתמשים בהם במופע או במסד הנתונים, לפי מספר פעולות הקריאה, הכתיבה או המחיקה. הנתונים בתרשים הזה מתקבלים משאילתות על טבלאות הנתונים הסטטיסטיים של פעולות הטבלה. מידע נוסף מופיע בקטע נתונים סטטיסטיים של פעולות בטבלה. |
close |
done |
טבלאות שהשימוש בהן הכי נמוך לפי פעולות (none) |
15 הטבלאות והאינדקסים שהשימוש בהם הכי נמוך במופע או במסד הנתונים, לפי מספר פעולות הקריאה, הכתיבה או המחיקה. הנתונים בתרשים הזה מתקבלים משאילתות על טבלאות הנתונים הסטטיסטיים של פעולות הטבלה. מידע נוסף מופיע בקטע נתונים סטטיסטיים של פעולות בטבלה. |
close |
done |
תרשימים ומדדים של קנה מידה אוטומטי מנוהל
המדדים הבאים זמינים למופעים שבהם מופעלת התכונה 'שינוי גודל אוטומטי מנוהל'.
| שם המדד וסוג המדד | תיאור |
|---|---|
| ניצול המעבד (CPU) לפי הגדרות של שינוי גודל אוטומטי |
אחוז ניצול המעבד בזמן אמת ובמכונת הבסיס, וכן העתקים לקריאה בלבד ומחיצות של מכונות עם התאמה אוטומטית לעומס שמופעלת.
אפשר להשתמש בתפריטים הנפתחים כדי לבחור את מסד הנתונים הספציפי, את מחיצת המופע ואת האזור שיוצגו בתרשים. בתרשים מוצגים יעדי ניצול המעבד כקווים מקווקווים. קווים מלאים מציגים את אחוזי הניצול בזמן אמת. |
| קיבולת מחשוב | כשצמתים נבחרים. |
|
instance/autoscaling/min_node_count |
מספר הצמתים המינימלי שהכלי לשינוי גודל אוטומטי מוגדר להקצות למופע. |
|
instance/autoscaling/max_node_count |
המספר המקסימלי של צמתים שהקצאתם למופע שלכם בהגדרה של קנה מידה אוטומטי. |
|
instance/autoscaling/recommended_node_count_for_cpu |
מספר הצמתים המומלץ על סמך השימוש במעבד של המופע. |
|
instance/autoscaling/recommended_node_count_for_storage |
מספר הצמתים המומלץ על סמך נפח האחסון הנדרש של המופע. |
| קיבולת מחשוב | עם יחידות עיבוד שנבחרו. |
|
instance/autoscaling/min_processing_units |
המספר המינימלי של יחידות עיבוד שהמערכת להגדלת קיבולת אוטומטית מוגדרת להקצות למופע. |
|
instance/autoscaling/max_processing_units |
המספר המקסימלי של יחידות עיבוד שהמערכת להגדלת קיבולת אוטומטית מוגדרת להקצות למופע. |
|
instance/autoscaling/recommended_processing_units_for_cpu |
מספר יחידות העיבוד המומלץ. ההמלצה הזו מבוססת על השימוש הקודם במעבד של המופע. |
|
instance/autoscaling/recommended_processing_units_for_storage |
מספר יחידות העיבוד המומלץ לשימוש. ההמלצה הזו מבוססת על נפח האחסון הנדרש הקודם של המכונה. |
| ניצול המעבד לפי עדיפות | |
|
instance/autoscaling/high_priority_cpu_utilization_target |
יעד לניצול המעבד (CPU) בעדיפות גבוהה לשימוש בהתאמת קנה מידה אוטומטית. |
|
instance/autoscaling/total_cpu_utilization_target replica/autoscaling/total_cpu_utilization_target |
יעד ניצול המעבד הכולל לשימוש בהתאמה אוטומטית לעומס. השימוש הכולל במעבד כולל את כל המשימות בעדיפות נמוכה, בינונית וגבוהה. |
| נפח אחסון כולל | עם יחידות עיבוד שנבחרו. |
|
instance/storage/limit_bytes |
מגבלת נפח האחסון של המופע בבייטים. |
|
instance/autoscaling/storage_utilization_target |
יעד ניצול נפח האחסון שמשמש להתאמה אוטומטית לעומס. |
תרשימים ומדדים של אחסון לפי רמות
המדדים הבאים זמינים למופעים שמשתמשים באחסון מדורג.
| שם המדד וסוג המדד | תיאור |
|---|---|
| instance/storage/used_bytes | סה"כ בייט של נתונים שמאוחסנים באחסון SSD ו-HDD. |
| instance/storage/combined/limit_bytes | מגבלות אחסון משולבות של SSD ו-HDD. |
| instance/storage/combined/limit_per_processing_unit | מגבלת האחסון המשולבת של SSD ו-HDD לכל יחידת עיבוד. |
| instance/storage/combined/utilization | שטח האחסון הכולל שנוצל בכונני ה-SSD וה-HDD, בהשוואה למגבלת האחסון הכוללת. |
| instance/disk_load | עומס השימוש ב-HDD. |
שמירת נתונים
התקופה המקסימלית לשמירת נתונים ברוב המדדים בלוח הבקרה של תובנות המערכת היא 6 שבועות. עם זאת, בתרשים Database storage by table, הנתונים נלקחים מהטבלה SPANNER_SYS.TABLE_SIZES_STATS_1HOUR (במקום מ-Spanner), שבה תקופת השמירה המקסימלית היא 30 יום.
מידע נוסף על שמירת נתונים
הצגת מרכז הבקרה של תובנות המערכת
כדי להציג את לוח הבקרה של תובנות המערכת, פועלים לפי השלבים הבאים:
במסוף Google Cloud , פותחים את רשימת מופעי Spanner.
מבצעים אחת מהפעולות הבאות:
כדי לראות מדדים של מכונה, לוחצים על השם של המכונה שרוצים לקבל עליה מידע ואז לוחצים על תובנות לגבי המערכת בתפריט הניווט.
כדי לראות מדדים של מסד נתונים, לוחצים על שם המופע, בוחרים מסד נתונים ואז לוחצים על תובנות לגבי המערכת בתפריט הניווט.
אופציונלי: כדי לראות נתונים היסטוריים מתקופת זמן אחרת, מחפשים את הלחצנים בפינה השמאלית העליונה של הדף ולוחצים על התקופה שרוצים לראות.
אופציונלי: כדי לקבוע אילו נתונים יוצגו בתרשים, לוחצים על אחת מהרשימות בתרשים. לדוגמה, אם המופע משתמש בהגדרה של שני אזורים או של מספר אזורים, בחלק מהתרשימים מוצגת רשימה שמאפשרת לראות נתונים של אזור ספציפי. לא לכל התרשימים יש רשימות צפייה.
המאמרים הבאים
- הסבר על מדדי השימוש במעבד והחביון ב-Spanner.
- הגדרה של תרשימים והתראות בהתאמה אישית באמצעות Monitoring.
- מידע נוסף על סוגי מכונות Spanner