
בדף הזה מוסבר איך להשתמש במדדים ובטבלאות של ניצול ה-CPU, וגם בכלי בדיקה אחרים, כדי לבדוק שימוש גבוה ב-CPU במסד הנתונים.
זיהוי אם משימה של המערכת או של המשתמש גורמת לניצול גבוה של המעבד
Google Cloud מסוף Spanner מספק כמה כלי מעקב, שמאפשרים לכם לראות את הסטטוס של המדדים החשובים ביותר של המופע. אחד מהם הוא תרשים שנקרא CPU utilization - Total. בתרשים הזה מוצג ניצול המעבד הכולל, כאחוז ממשאבי המעבד של המכונה, עם פירוט לפי עדיפות המשימה וסוג הפעולה. יש שני סוגים של משימות: משימות משתמש, כמו קריאה וכתיבה, ומשימות מערכת, שכוללות משימות אוטומטיות ברקע כמו דחיסה ומילוי חוזר של אינדקסים.
איור 1 מציג דוגמה לתרשים CPU utilization - Total.
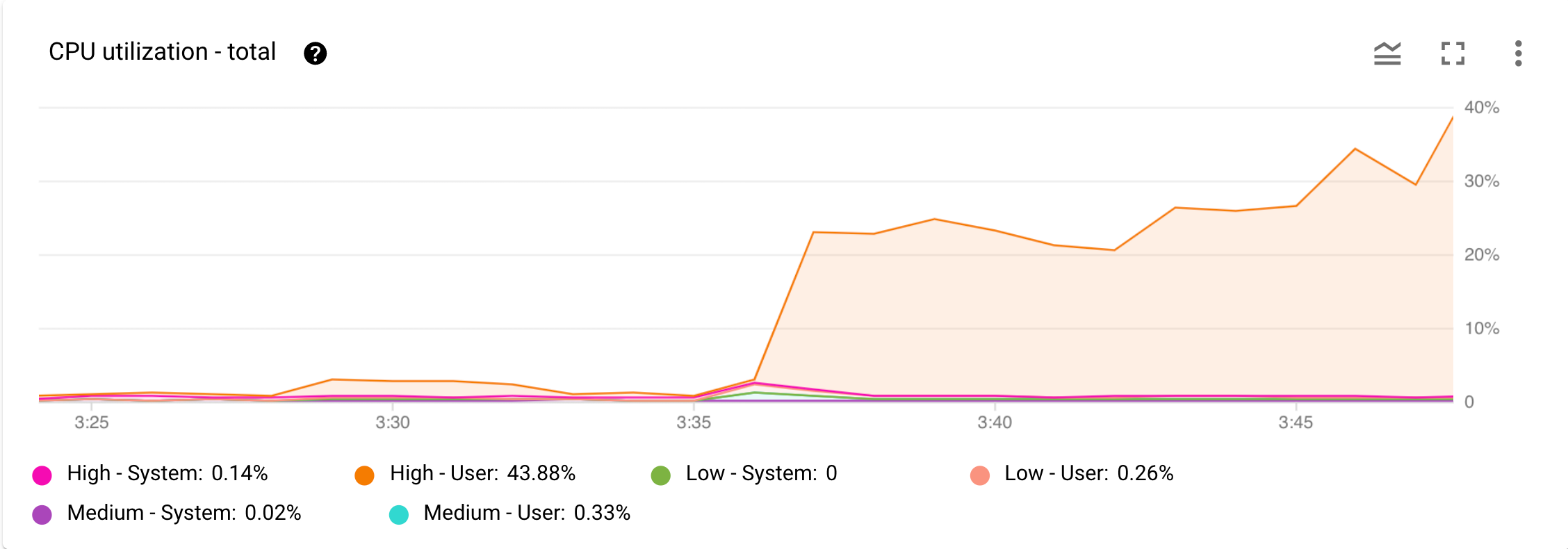
איור 1. תרשים CPU utilization - total במרכז הבקרה Monitoring במסוףGoogle Cloud .
עכשיו, נניח שקיבלתם התראה מ-Cloud Monitoring על עלייה משמעותית בשימוש במעבד. פותחים את מרכז הבקרה Monitoring של המופע במסוף Google Cloud ובודקים את התרשים CPU Utilization - Total במסוף Google Cloud . כפי שמוצג באיור 1, אפשר לראות את העלייה בניצול ה-CPU ממשימות משתמש בעדיפות גבוהה. השלב הבא הוא לגלות איזו פעולת משתמש בעדיפות גבוהה גורמת לעלייה בשימוש במעבד.
אתם יכולים להשתמש בלוחות הבקרה של תובנות לגבי שאילתות כדי להציג את המדד הזה ומדדים אחרים כסדרת זמן. מרכזי הבקרה המוכנים מראש האלה עוזרים לכם לראות עליות חדות בניצול המעבד ולזהות שאילתות לא יעילות.
זיהוי פעולת המשתמש שגורמת לעלייה החדה בשימוש במעבד
בתרשים CPU utilization - Total באיור 1 אפשר לראות שמשימות משתמש בעדיפות גבוהה הן הסיבה לשימוש גבוה יותר במעבד.
בשלב הבא, בודקים את התרשים CPU Utilization by operation type בGoogle Cloud console. בתרשים הזה מוצג פירוט של השימוש במעבד לפי פעולות שהמשתמש יזם עם עדיפות גבוהה, בינונית ונמוכה.
מהי פעולה שמתבצעת על ידי משתמש?
פעולה שמופעלת על ידי המשתמש היא פעולה שמופעלת דרך בקשת API. מערכת Spanner מקבצת את הבקשות האלה לסוגי פעולות או לקטגוריות, ואפשר להציג כל סוג פעולה כקו בתרשים CPU utilization by operation type. בטבלה הבאה מתוארות שיטות ה-API שנכללות בכל סוג פעולה.
| פעולה | שיטות API | תיאור |
|---|---|---|
| read_readonly | Read StreamingRead |
כולל קריאות שמביאות שורות ממסד הנתונים באמצעות חיפושים וסריקות של מפתחות. |
| read_readwrite | Read StreamingRead |
כולל קריאות בתוך עסקאות קריאה-כתיבה. |
| read_withpartitiontoken | Read StreamingRead |
כולל פעולות קריאה שמתבצעות באמצעות קבוצה של טוקנים של מחיצות. |
| executesql_select_readonly | ExecuteSql ExecuteStreamingSql |
כולל ביצוע של הצהרת SQL מסוג Select ושאילתות של שינוי הזרם. |
| executesql_select_readwrite | ExecuteSql ExecuteStreamingSql |
כולל ביצוע של הצהרת Select בתוך עסקאות קריאה-כתיבה. |
| executesql_select_withpartitiontoken | ExecuteSql ExecuteStreamingSql |
כולל את ההוראה execute Select שבוצעה באמצעות קבוצה של טוקנים של מחיצות. |
| executesql_dml_readwrite | ExecuteSql ExecuteStreamingSql ExecuteBatchDml |
כולל הפעלה של הצהרת DML SQL. |
| executesql_dml_partitioned | ExecuteSql ExecuteStreamingSql ExecuteBatchDml |
כולל ביצוע של הצהרת SQL של DML עם חלוקה למחיצות. |
| beginorcommit | BeginTransaction Commit Rollback |
כולל עסקאות של התחלה, אישור וביטול. |
| שונות | PartitionQuery PartitionRead GetSession CreateSession |
כולל PartitionQuery, PartitionRead, Create Database, Create Instance, פעולות שקשורות לסשן, פעולות פנימיות שקשורות להצגת נתונים בזמן אמת וכו'. |
דוגמה לתרשים של מדד השימוש במעבד לפי סוגי פעולות.
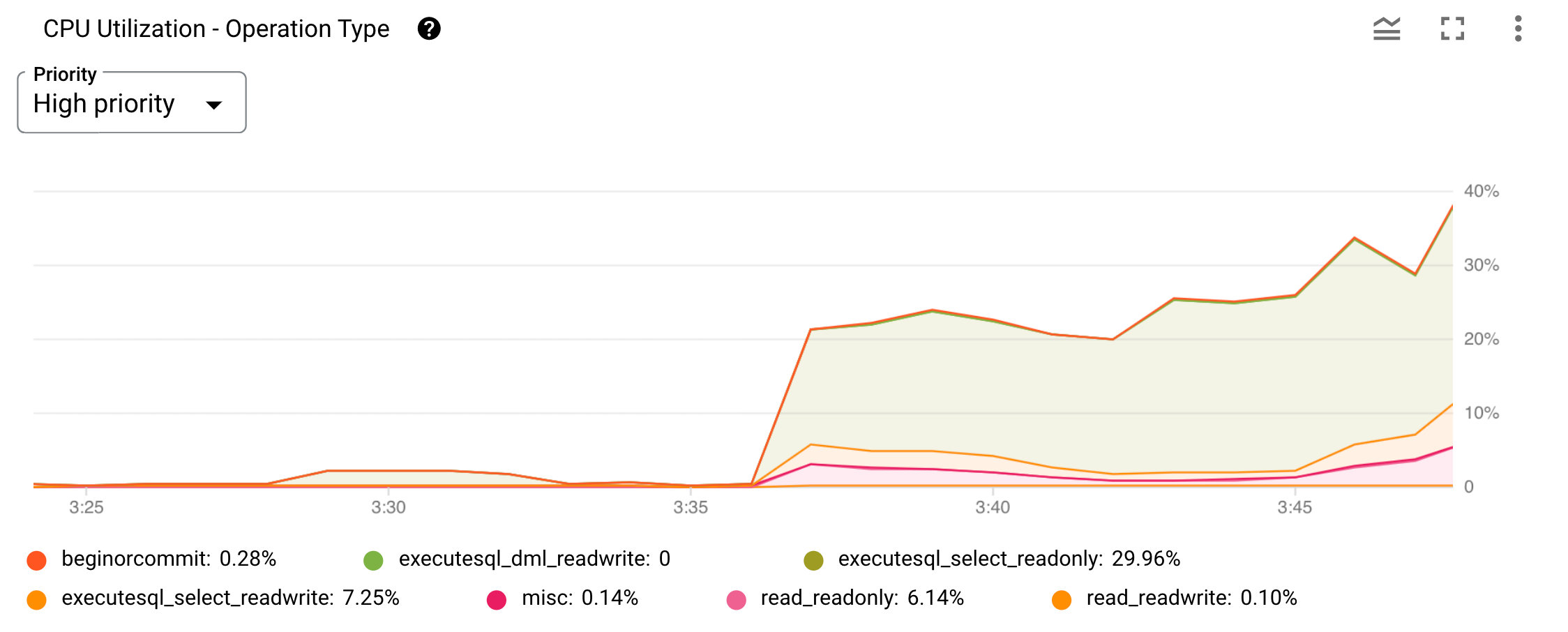
איור 2. תרשים ניצול יחידת העיבוד המרכזית (CPU) לפי סוג הפעולה במסוףGoogle Cloud .
כדי להגביל את התצוגה לעדיפות ספציפית, משתמשים בתפריט עדיפות שמעל התרשים. כל סוג או קטגוריה של פעולה מוצגים בתרשים קו. הקטגוריות שמופיעות מתחת לתרשים מזהות כל גרף. כדי להסתיר או להציג כל תרשים, בוחרים או מבטלים את הבחירה של מסנן הקטגוריה המתאים.
אפשר גם ליצור את התרשים הזה בכלי לבחירת מדדים, כמו שמתואר בהמשך:
יצירת תרשים של ניצול המעבד לפי סוג פעולה ב-Metrics Explorer
- במסוף Google Cloud , בוחרים באפשרות Monitoring, או לוחצים על הלחצן הבא:
- בחלונית הניווט, בוחרים באפשרות Metrics Explorer (כלי לבחירת מדדים).
-
בשדה Find resource type and metric מזינים את הערך
spanner.googleapis.com/instance/cpu/utilization_by_operation_typeובוחרים את השורה שמופיעה מתחת לתיבה. -
בשדה Filter, מזינים את הערך
instance_id, ואז מזינים את מזהה המופע שרוצים לבדוק ולוחצים על >Apply. -
בשדה Group By, בוחרים באפשרות
categoryמהתפריט הנפתח. בתרשים יוצג השימוש במעבד של משימות המשתמשים, מקובצות לפי סוג או קטגוריה של פעולה.
המדד CPU utilization by priority (ניצול המעבד לפי עדיפות) שמוסבר בקטע הקודם עזר לקבוע אם משימה של משתמש או של המערכת גרמה לעלייה בשימוש במשאבי המעבד. בעזרת המדד CPU utilization by operation type (ניצול המעבד לפי סוג הפעולה) אפשר לקבל מידע מפורט יותר ולגלות את סוג הפעולה שהמשתמש יזם, שגרמה לעלייה הזו בשימוש במעבד.
זיהוי הבקשה ממשתמש שגורמת לשימוש מוגבר במעבד
כדי לזהות איזו בקשה ספציפית של משתמש אחראית לעלייה החדה בשימוש במעבד (CPU) בגרף של סוג הפעולה executesql_select_readonly שמוצג באיור 2, תצטרכו להשתמש בטבלאות הסטטיסטיקה המובנות של בדיקת עצמית כדי לקבל תובנות נוספות.
הטבלה הבאה יכולה לעזור לכם להחליט איזו טבלת נתונים סטטיסטיים לשאול שאילתה לגביה, בהתאם לסוג הפעולה שגורמת לשימוש גבוה ב-CPU.
| סוג הפעולה | שאילתה | קריאה | עסקה |
|---|---|---|---|
| read_readonly | לא | כן | לא |
| read_readwrite | לא | כן | כן |
| read_withpartitiontoken | לא | כן | לא |
| executesql_select_readonly | כן | לא | לא |
| executesql_select_withpartitiontoken | כן | לא | לא |
| executesql_select_readwrite | כן | לא | כן |
| executesql_dml_readwrite | כן | לא | כן |
| executesql_dml_partitioned | לא | לא | כן |
| beginorcommit | לא | לא | כן |
לדוגמה, אם הבעיה היא read_withpartitiontoken, אפשר לפתור אותה באמצעות נתוני קריאה.
בתרחיש הזה, נראה שהפעולה executesql_select_readonly היא הסיבה לשימוש המוגבר במעבד שאתם רואים. על סמך הטבלה שלמעלה, כדאי לעיין בנתונים סטטיסטיים של שאילתות כדי לגלות אילו שאילתות יקרות, מופעלות לעיתים קרובות או סורקות הרבה נתונים.
כדי לגלות אילו שאילתות צורכות הכי הרבה CPU בשעה האחרונה, אפשר להריץ את השאילתה הבאה בטבלת הנתונים הסטטיסטיים query_stats_top_hour.
SELECT text,
execution_count AS count,
avg_latency_seconds AS latency,
avg_cpu_seconds AS cpu,
execution_count * avg_cpu_seconds AS total_cpu
FROM spanner_sys.query_stats_top_hour
WHERE interval_end =
(SELECT MAX(interval_end)
FROM spanner_sys.query_stats_top_hour)
ORDER BY total_cpu DESC;
בפלט יוצגו שאילתות ממוינות לפי השימוש במעבד. אחרי שמזהים את השאילתה עם השימוש הכי גבוה במעבד, אפשר לנסות את האפשרויות הבאות כדי לכוונן אותה.
כדאי לעיין בתוכנית הביצוע של השאילתה כדי לזהות חוסר יעילות אפשרי שעלול לתרום לשימוש גבוה במעבד.
כדאי לבדוק את השאילתה כדי לוודא שהיא עומדת בשיטות המומלצות ל-SQL.
כדאי לעיין בעיצוב הסכימה של מסד הנתונים ולעדכן את הסכימה כדי לאפשר שאילתות יעילות יותר.
קובעים ערך בסיסי למספר הפעמים שבהן Spanner מריץ שאילתה במהלך מרווח זמן. באמצעות נתון הבסיס הזה, תוכלו לזהות ולחקור את הסיבה לכל חריגה לא צפויה מההתנהגות הרגילה.
אם לא הצלחתם למצוא שאילתה שצורכת הרבה משאבי CPU, תוכלו להוסיף קיבולת חישוב למופע. הוספת קיבולת מחשוב מספקת יותר משאבי CPU ומאפשרת ל-Spanner לטפל בעומס עבודה גדול יותר. למידע נוסף, קראו את המאמר הגדלת קיבולת החישוב.
המאמרים הבאים
מידע נוסף על שיטות מומלצות ל-SQL ב-Spanner
כאן מפורטת רשימת המדדים מ-Spanner.