
בדף הזה מתואר נפח המחשוב של Spanner ושתי יחידות המידה שמשמשות לכימות שלו: צמתים ויחידות עיבוד.
קיבולת מחשוב
כשיוצרים מכונה, בוחרים הגדרת מכונה וכמות של קיבולת מחשוב למכונה. לקיבולת החישוב של המופע יש את המאפיינים הבאים:
- הוא קובע את כמות משאבי השרת והאחסון שזמינים למסדי הנתונים במופע, כולל עומס הדיסק. עומס הדיסק רלוונטי רק לעומסי עבודה שמתבצעת בהם גישה לנתונים שמאוחסנים באחסון HDD. מידע נוסף מופיע במאמר סקירה כללית על אחסון בשכבות.
הוא נמדד ביחידות עיבוד (PU) או בצמתים, כאשר 1,000 יחידות עיבוד שוות לצומת אחד.
- צומת או 1,000 יחידות עיבוד (PU) הם יחידה לוגית של קיבולת מחשוב, והם לא מייצגים שרת פיזי יחיד. משאבי ה-Compute של כל צומת מחולקים בין כמה מכונות פיזיות בסיסיות, או שרתים. מספר השרתים בכל צומת תלוי בהגדרות של המופע. לדוגמה, מופע אזורי משתמש לפחות בשלושה שרתים לכל צומת, ואילו מופע מרובה אזורים משתמש לפחות בחמישה. מידע נוסף זמין במאמר קיבולת מחשוב והגדרות של מכונות וירטואליות.
- כשמגדירים או משנים את קיבולת החישוב במופע, צריך לציין יחידות עיבוד בכפולות של 100 (לדוגמה, 100, 200, 300). כשמספר יחידות העיבוד מגיע ל-1,000, אפשר לציין כמויות גדולות יותר כמכפלות של 1,000 יחידות עיבוד (לדוגמה, 1,000, 2,000, 3,000) או כצמתים (לדוגמה, 1, 2, 3).
כשמפעילים התאמה אוטומטית לעומס במופע, אפשר להגדיר ולבצע התאמה אוטומטית לעומס של הרפליקות לקריאה בלבד באופן עצמאי, כדי להגדיר יכולות חישוב שונות לכל רפליקה. מידע נוסף מופיע במאמר בנושא שינוי גודל אוטומטי אסימטרי לקריאה בלבד.
Spanner מאפשר להשתמש בקיבולת המחשוב שצוינה (משוכפלת) במלואה בכל אזור שמארח עותק משוכפל של הנתונים. לדוגמה, אם תקצו 1,000 יחידות עיבוד (PU) למופע אזורי, שבדרך כלל יש לו רפליקות בשלושה אזורים, לכל אחד משלושת האזורים האלה יהיו זמינות 1,000 יחידות העיבוד המלאות כדי להפעיל את הרפליקה שלו. Spanner לא מחלק או מפזר את סך יחידות העיבוד בין האזורים. יחידת המידה שבה אתם משתמשים לא משנה, אלא אם אתם יוצרים מכונה שהקיבולת שלה קטנה מ-1,000 יחידות עיבוד (צומת אחד). במקרה כזה, צריך להשתמש ביחידות PU כדי לציין את יכולת החישוב של המופע.
מופעים עם פחות מ-1, 000 יחידות עיבוד מיועדים לגדלים קטנים יותר של נתונים, שאילתות ועומסי עבודה. יש להם משאבי מחשוב מוגבלים, ולכן יכול להיות שחלק מעומסי העבודה לא יתאימו את עצמם באופן ליניארי ויהיו בעיות בביצועים. יכול להיות שיהיו גם מקרים של עלייה לסירוגין בזמני האחזור.
זמינות של Spanner
Spanner מתוכנן לזמינות גבוהה. קיבולת החישוב של כל מופע מתפרסת על פני כמה שרתים באזורים שונים, ולכן Spanner עמיד בפני כשל של כל שרת. אובדן של שרת בודד לא נחשב לכשל בצומת. מערכת Spanner מנהלת את המשאבים הבסיסיים שלה באופן אוטומטי כדי לספק זמינות רציפה למופע.
מגבלות על אחסון נתונים
כפי שמפורט במאמר בנושא מכסות ומגבלות, כדי לספק זמינות גבוהה וחביון נמוך כשניגשים למסד נתונים, Spanner משתמש בקיבולת החישוב של מופע כבסיס לקביעת מגבלות האחסון, לפי ההנחיות הבאות:
- במקרים שבהם הגודל של המופע קטן מ-1 צומת (1,000 יחידות עיבוד), מערכת Spanner מקצה 1,024.0 GiB של נתונים לכל 100 יחידות עיבוד במסד הנתונים.
- במקרים של צומת אחד ומעלה, מערכת Spanner מקצה 10TiB של נתונים לכל צומת.
לדוגמה, כדי ליצור מופע למסד נתונים בנפח 300GB, אפשר להגדיר את קיבולת החישוב שלו ל-100 יחידות עיבוד. כמות כושר החישוב הזו מאפשרת למופע להישאר מתחת למגבלה עד שמסד הנתונים גדל ליותר מ-1,024.0 GiB. אחרי שהמסד נתונים מגיע לגודל הזה, צריך להוסיף עוד 100 יחידות עיבוד כדי לאפשר את הגדלת המסד. אחרת, יכול להיות ש-Spanner ידחה פעולות כתיבה למסד הנתונים. מידע נוסף זמין במאמר בנושא המלצות לניצול נפח אחסון במסד נתונים.
ב-Spanner החיוב הוא על נפח האחסון שהמופעים משתמשים בו בפועל, ולא על נפח האחסון הכולל שהוקצה להם.
ביצועים
ערכי השיא של קצב העברת הנתונים לקריאה ולכתיבה שניתן להשיג באמצעות כמות מסוימת של קיבולת מחשוב תלויים בתצורת המופע, כמו גם בעיצוב הסכימה ובמאפיינים של מערך הנתונים. מידע נוסף מופיע במאמר סקירה כללית של הביצועים.
אתם משתמשים במופעים עם פחות מ-1,000 יחידות עיבוד לנתונים, לשאילתות ולעומסי עבודה קטנים יותר. במקרה של עומסי עבודה גדולים יותר, משאבי המחשוב המוגבלים עלולים לגרום לשינוי לא לינארי בביצועים ובקנה מידה, עם עלייה לסירוגין בזמני האחזור.
קיבולת מחשוב והגדרות של מופעים
כפי שמתואר במאמר בנושא הגדרות אזוריות, הגדרות של שני אזורים והגדרות של מספר אזורים, Spanner מפזר מופע בין אזורים של אזור אחד או יותר כדי לספק ביצועים גבוהים וזמינות גבוהה. כתוצאה מכך, Spanner גם מחלק את משאבי השרתים שמסופקים על ידי יכולת המחשוב של המופע.
התרשים הבא ממחיש את חלוקת משאבי השרת.
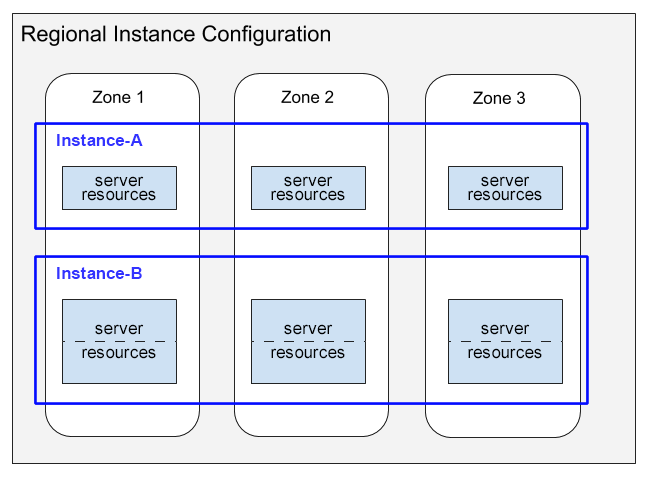
בתרשים הזה מוצגים שני מקרים עם הגדרות אזוריות:
- Instance-A מציג אירוע של 1,000 יחידות עיבוד (צומת אחד) עם חלוקת קיבולת החישוב שלו שצורכת משאבי שרת בכל אחד משלושת האזורים.
- Instance-B מציג מופע של 2,000 יחידות עיבוד (2 צמתים) עם חלוקת קיבולת החישוב שלו שצורכת משאבי שרת בכל אחד משלושת האזורים.
שימו לב לנקודות הבאות בתרשים:
לכל מופע, Spanner מקצה משאבי שרת בכל אזור בהגדרה האזורית. כל משאב שרת לכל אזור משתמש בשכפול הנתונים באזור שלו. מידע על רפליקות של נתונים בהגדרות של מופעים זמין במאמר הגדרות אזוריות, הגדרות בשני אזורים והגדרות במספר אזורים. מידע על האופן שבו Spanner שומר על סנכרון של העתקי הנתונים האלה זמין במאמר שכפול.
משאבי השרת של מופע א' מוצגים בתיבות בודדות, ואילו משאבי השרת של מופע ב' מוצגים בתיבות שמחולקות לשני חלקים. ההבדל הזה ממחיש ש-Spanner מקצה משאבי שרת באופן שונה למופעים בגדלים שונים:
- במקרים של 1,000 יחידות עיבוד (צומת אחד) ומטה, מערכת Spanner מקצה משאבי שרת במשימת שרת יחידה לכל אזור.
- במקרים של מופעים גדולים מ-1,000 יחידות עיבוד (צומת אחד), Spanner מקצה משאבי שרת בכמה משימות שרת לכל אזור, עם משימה אחת לכל 1,000 יחידות עיבוד. שימוש בכמה משימות שרת לכל אזור מספק ביצועים טובים יותר ומאפשר ל-Spanner ליצור פיצולים של מסדי נתונים ולספק ביצועים טובים עוד יותר.
שינוי קיבולת המחשוב
אחרי שיוצרים מופע, אפשר להגדיל את קיבולת החישוב שלו בהמשך. ברוב המקרים, הבקשות מושלמות תוך כמה דקות. במקרים נדירים, יכול להיות שיעברו עד שעה לפני שהגדלת הקיבולת תסתיים.
אפשר להקטין את קיבולת החישוב של מופע Spanner, למעט במקרים הבאים:
אי אפשר לאחסן יותר מ-10TiB של נתונים לכל צומת (1,000 יחידות עיבוד).
יש מספר גדול של פיצולים בנתונים של המופע. בתרחיש הזה, יכול להיות ש-Spanner לא יוכל לנהל את הפיצולים אחרי שתקטינו את קיבולת החישוב. אפשר לנסות להקטין את קיבולת המחשוב בסכומים קטנים יותר ויותר עד שתמצאו את הקיבולת המינימלית ש-Spanner צריך כדי לנהל את כל הפיצולים של המופע.
Spanner יכול ליצור מספר גדול של פיצולים כדי להתאים לדפוסי השימוש שלכם. אם דפוסי השימוש שלכם משתנים, יכול להיות שאחרי שבוע או שבועיים, מערכת Spanner תמזג כמה פיצולים, ותוכלו לנסות להקטין את קיבולת החישוב של המכונה.
כשמסירים קיבולת חישוב, כדאי לעקוב אחרי ניצול המעבד (CPU) והשהיות של הבקשות ב-Cloud Monitoring כדי לוודא שניצול המעבד נשאר מתחת ל-65% במופעים אזוריים ומתחת ל-45% בכל אזור במופעים מרובי-אזורים. יכול להיות שתהיה עלייה זמנית בחביון של הבקשות בזמן הסרת קיבולת מחשוב.
ל-Spanner אין מצב השהיה. קיבולת החישוב של Spanner היא משאב ייעודי, וגם כשלא מריצים עומס עבודה, Spanner מבצע לעיתים קרובות עבודה ברקע כדי לבצע אופטימיזציה של הנתונים ולהגן עליהם.
אפשר להשתמש במסוףGoogle Cloud , ב-Google Cloud CLI או בספריות הלקוח של Spanner כדי לשנות את קיבולת המחשוב. מידע נוסף זמין במאמר שינוי קיבולת החישוב.
קיבולת מחשוב לעומת עותקים משוכפלים
אם אתם צריכים להגדיל את משאבי השרת והאחסון במופע, אתם יכולים להגדיל את קיבולת החישוב של המופע. שימו לב שהגדלת קיבולת החישוב לא מגדילה את מספר הרפליקות (שהוא קבוע עבור הגדרת מופע נתונה), אלא מגדילה את המשאבים של כל רפליקה במופע. הגדלת קיבולת החישוב מעניקה לכל עותק משוכפל יותר CPU ו-RAM, וכך מגדילה את קצב העברת הנתונים של העותק המשוכפל (כלומר, יכולים להתבצע יותר קריאות וכתיבות בשנייה).