
בדף הזה מפורטים טיפים לפתרון בעיות ואסטרטגיות לניפוי באגים שיכולים לעזור לכם אם אתם נתקלים בבעיות בבנייה או בהפעלה של צינור Dataflow. המידע הזה יכול לעזור לכם לזהות כשל בצינור, לקבוע את הסיבה להרצת צינור שנכשלה ולהציע כמה דרכי פעולה לתיקון הבעיה.
הדיאגרמה הבאה מציגה את תהליך העבודה לפתרון בעיות ב-Dataflow שמתואר בדף הזה.

Dataflow מספק משוב בזמן אמת על העבודה, ויש קבוצה בסיסית של שלבים שאפשר להשתמש בהם כדי לבדוק את הודעות השגיאה, את היומנים ואת התנאים, כמו התקדמות העבודה שנעצרה.
הנחיות לפתרון שגיאות נפוצות שאתם עשויים להיתקל בהן כשמריצים את משימת Dataflow זמינות במאמר פתרון שגיאות ב-Dataflow. כדי לעקוב אחרי הביצועים של צינור עיבוד הנתונים ולפתור בעיות שקשורות אליהם, אפשר לעיין במאמר מעקב אחרי הביצועים של צינור עיבוד הנתונים.
שיטות מומלצות לצינורות עיבוד נתונים
בהמשך מפורטות שיטות מומלצות לצינורות עיבוד נתונים של Java, Python ו-Go.
- בכל צינורות הנתונים, חשוב להגדיר מיקומים שונים למיקום הזמני ולמיקום של שלב הביניים.
- שימוש בדלי נפרד של שלב ההכנה יכול להאיץ את ההפעלה מחדש של צינור עיבוד הנתונים, כי אפשר לעשות שימוש חוזר בארטיפקטים במקום להוריד אותם מחדש.
- קבצים שהועברו לאזור ההמתנה מכילים ארטיפקטים שנוצרו בזמן התחלת העבודה, כמו קוד צינור הנתונים, ואפשר לעשות בהם שימוש חוזר במהלך משך החיים של העבודה.
- אחרי שנגמרים עיבוד אצווה או עבודות סטרימינג, אפשר למחוק את הקבצים שהועלו.
- במשימות באצווה או במשימות של סטרימינג שנמצאות בתהליך, אל תמחקו קבצים זמניים, גם אחרי עדכון של צינור הנתונים.
- קבצים זמניים לא נמחקים אוטומטית. אם אין לכם מדיניות למחיקת קבצים ישנים, כמו זמן חיים (TTL), תצטרכו להסיר אותם באופן ידני. כדי להימנע מעלויות אחסון, צריך להגדיר מדיניות של אורך חיים (TTL) עבור דליים זמניים ודליים של סביבת פיתוח.
- למאגר הזמני, מגדירים TTL קצת יותר ארוך ממשך הזמן של העבודה הארוכה ביותר. לדוגמה, זמן חיים (TTL) של 7 ימים הוא נקודת התחלה סבירה.
- בדלי של הסביבה הזמנית, מגדירים TTL ארוך יותר כדי לאפשר שימוש חוזר בארטיפקטים בין הפעלות עוקבות של משימות, וכך לקצר את זמן ההפעלה של המשימה. לדוגמה, נקודת התחלה סבירה היא TTL של 6 חודשים.
- כדי להימנע מעלויות אחסון מיותרות, מומלץ להשבית את המחיקה הרכה בדליים הזמניים ובדליים של שלבי הביניים.
בדיקת הסטטוס של הפייפליין
אפשר לזהות שגיאות בהרצות של צינורות העיבוד באמצעות ממשק המעקב של Dataflow.
- עוברים אל Google Cloud המסוף.
- בוחרים את הפרויקט Google Cloud מהרשימה.
- בתפריט הניווט, בקטע Big Data, לוחצים על Dataflow. רשימה של משימות פעילות מופיעה בחלונית השמאלית.
- בוחרים את משימת הצינור שרוצים לראות. אפשר לראות את סטטוס העבודות במבט חטוף בשדה סטטוס: 'פועל', 'הושלם' או 'נכשל'.
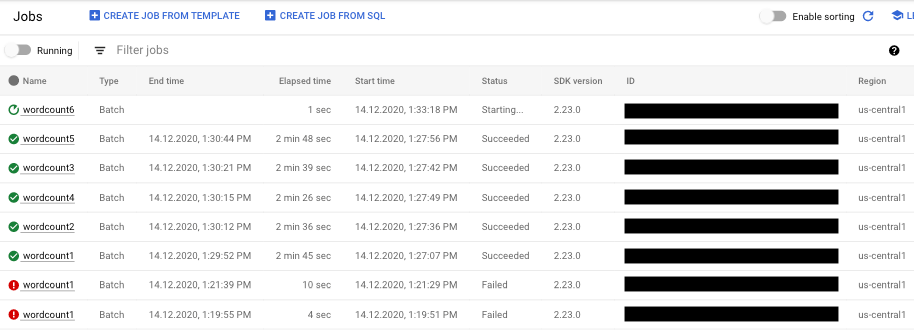
איך מחפשים מידע על כשלים בצינורות עיבוד נתונים
אם אחת מהמשימות בצינור נכשלת, אפשר לבחור את המשימה כדי לראות מידע מפורט יותר על השגיאות ועל תוצאות ההרצה. כשבוחרים משימה, אפשר לראות תרשימים מרכזיים של צינור הנתונים, גרף הביצוע, החלונית פרטי המשימה והחלונית יומנים עם הכרטיסיות יומני משימות, יומני עובדים, אבחון והמלצות.
בדיקת הודעות שגיאה של משימות
כדי לראות את יומני העבודות שנוצרו על ידי קוד צינור הנתונים ושירות Dataflow, בחלונית Logs, לוחצים על segmentShow.
כדי לסנן את ההודעות שמופיעות ביומני המשימות, לוחצים על מידעarrow_drop_down ועל filter_listסינון. כדי להציג רק הודעות שגיאה, לוחצים על מידעarrow_drop_down ובוחרים באפשרות שגיאה.
כדי להרחיב הודעת שגיאה, לוחצים על הקטע שניתן להרחבה arrow_right.
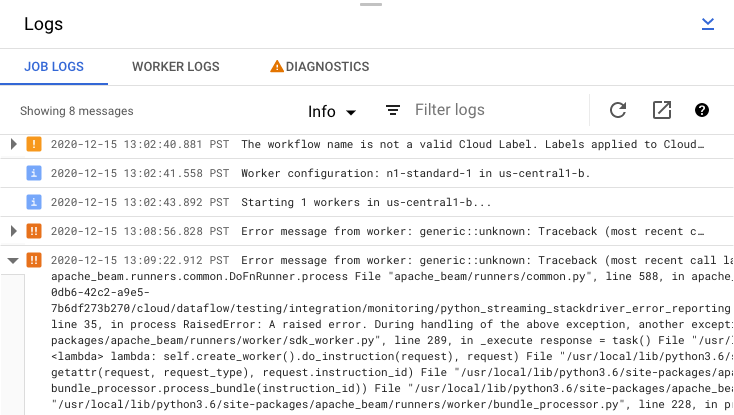
אפשר גם ללחוץ על הכרטיסייה 'אבחון'. בכרטיסייה הזו מוצגים המקומות שבהם התרחשו שגיאות לאורך ציר הזמן שנבחר, ספירה של כל השגיאות שנרשמו והמלצות אפשריות לפייפליין.
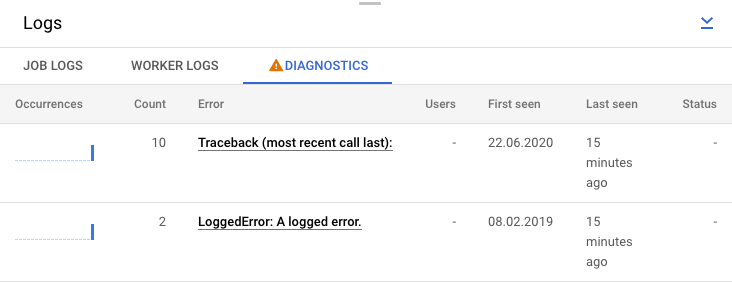
הצגת יומני שלבים של המשימה
כשבוחרים שלב בתרשים של צינור העברת הנתונים, החלונית 'יומנים' משנה את התצוגה מיומני עבודות שנוצרו על ידי שירות Dataflow ליומנים ממופעי Compute Engine שמריצים את השלב בצינור העברת הנתונים.
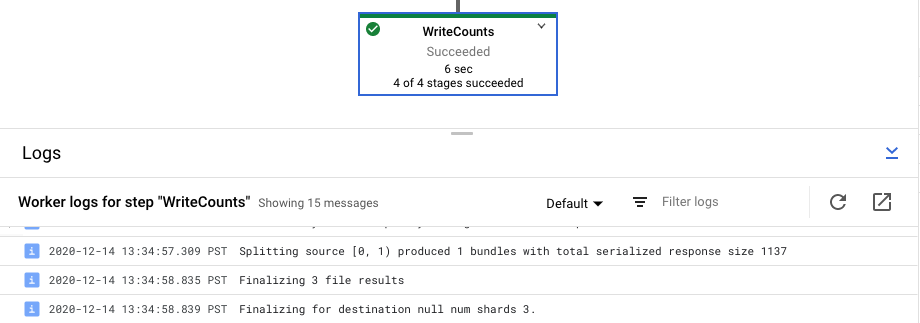
Cloud Logging משלב את כל היומנים שנאספו מהמכונות של Compute Engine בפרויקט שלכם במקום אחד. מידע נוסף על השימוש ביכולות השונות של Dataflow לרישום ביומן מופיע במאמר רישום ביומן של הודעות בצינור.
טיפול בדחייה של צינור אוטומטי לעיבוד נתונים
במקרים מסוימים, שירות Dataflow מזהה שצינור הנתונים שלכם עלול להפעיל בעיות ידועות ב-SDK. כדי למנוע שליחה של צינורות שסביר שיעלו בעיות, Dataflow דוחה באופן אוטומטי את הצינור ומציג את ההודעה הבאה:
The workflow was automatically rejected by the service because it might trigger an identified bug in the SDK (details below). If you think this identification is in error, and would like to override this automated rejection, please re-submit this workflow with the following override flag: [OVERRIDE FLAG]. Bug details: [BUG DETAILS]. Contact Google Cloud Support for further help. Please use this identifier in your communication: [BUG ID].
אחרי קריאת האזהרות בפרטי הבאג המקושרים, אם בכל זאת רוצים להריץ את צינור הנתונים, אפשר לבטל את הדחייה האוטומטית. מוסיפים את הדגל
--experiments=<override-flag> ושולחים מחדש את צינור העיבוד.
זיהוי הגורם לכשל בצינור עיבוד נתונים
בדרך כלל, הפעלה של צינור עיבוד נתונים ב-Apache Beam נכשלת בגלל אחת מהסיבות הבאות:
- שגיאות בבניית גרף או צינור עיבוד נתונים. השגיאות האלה מתרחשות כש-Dataflow נתקל בבעיה בבניית הגרף של השלבים שמרכיבים את צינור העיבוד, כפי שמתואר בצינור העיבוד של Apache Beam.
- שגיאות באימות המשרה. שירות Dataflow מאמת כל משימת פייפליין שאתם מפעילים. שגיאות בתהליך האימות יכולות למנוע את היצירה או ההפעלה של המשימה. שגיאות אימות יכולות לכלול בעיות בקטגוריה של Cloud Storage בפרויקט Google Cloud או בהרשאות של הפרויקט.
- חריגים בקוד של ה-Worker. השגיאות האלה מתרחשות כשיש שגיאות או באגים בקוד שהמשתמש סיפק, ש-Dataflow מפיץ לעובדים מקבילים, כמו מופעי
DoFnשל טרנספורמציהParDo. - שגיאות שנגרמות בגלל כשלים חולפים בשירותים אחרים Google Cloud . יכול להיות שהצינור ייכשל בגלל הפסקת שירות זמנית או בעיה אחרת בGoogle Cloud שירותים ש-Dataflow תלוי בהם, כמו Compute Engine או Cloud Storage.
זיהוי שגיאות בבניית גרף או צינור עיבוד נתונים
שגיאה ביצירת תרשים יכולה להתרחש כש-Dataflow יוצר את תרשים הביצוע של צינור עיבוד הנתונים מהקוד בתוכנית Dataflow. במהלך בניית הגרף, Dataflow בודק אם יש פעולות לא חוקיות.
אם Dataflow מזהה שגיאה ביצירת הגרף, חשוב לזכור שלא נוצרת משימה בשירות Dataflow. לכן, לא מוצג משוב בממשק המעקב של Dataflow. במקום זאת, מופיעה הודעת שגיאה דומה לזו שמוצגת במסוף או בחלון הטרמינל שבו הפעלתם את צינור הנתונים של Apache Beam:
Java
לדוגמה, אם צינור העיבוד מנסה לבצע צבירה כמו
GroupByKey בחלון גלובלי, לא מופעל,
לא מוגבל PCollection, מופיעה הודעת שגיאה שדומה להודעה הבאה:
... ... Exception in thread "main" java.lang.IllegalStateException: ... GroupByKey cannot be applied to non-bounded PCollection in the GlobalWindow without a trigger. ... Use a Window.into or Window.triggering transform prior to GroupByKey ...
Python
לדוגמה, אם צינור הנתונים משתמש ברמזים לגבי סוגים, וסוג הארגומנט באחד מהטרנספורמציות לא תואם למה שציפיתם, תופיע הודעת שגיאה דומה לזו:
... in <module> run()
... in run | beam.Map('count', lambda (word, ones): (word, sum(ones))))
... in __or__ return self.pipeline.apply(ptransform, self)
... in apply transform.type_check_inputs(pvalueish)
... in type_check_inputs self.type_check_inputs_or_outputs(pvalueish, 'input')
... in type_check_inputs_or_outputs pvalue_.element_type))
google.cloud.dataflow.typehints.decorators.TypeCheckError: Input type hint violation at group: expected Tuple[TypeVariable[K], TypeVariable[V]], got <type 'str'>
המשך
לדוגמה, אם צינור הנתונים משתמש ב-`DoFn` שלא מקבל קלט, תופיע הודעת שגיאה דומה לזו:
... panic: Method ProcessElement in DoFn main.extractFn is missing all inputs. A main input is required. ... Full error: ... inserting ParDo in scope root/CountWords ... graph.AsDoFn: for Fn named main.extractFn ... ProcessElement method has no main inputs ... goroutine 1 [running]: ... github.com/apache/beam/sdks/v2/go/pkg/beam.MustN(...) ... (more stacktrace)
אם נתקלתם בשגיאה כזו, עליכם לבדוק את קוד צינור הנתונים כדי לוודא שהפעולות בצינור הנתונים חוקיות.
זיהוי שגיאות באימות של משימות Dataflow
אחרי ששירות Dataflow מקבל את הגרף של צינור הנתונים, הוא מנסה לאמת את העבודה. האימות הזה כולל את הפעולות הבאות:
- מוודאים שלשירות יש גישה לקטגוריות של Cloud Storage שמשויכות לעבודה לצורך העברה זמנית של קבצים ופלט זמני.
- בודקים אם יש לכם את ההרשאות הנדרשות בפרויקט Google Cloud .
- לוודא שלשירות יש גישה למקורות של קלט ופלט, כמו קבצים.
אם העבודה נכשלת בתהליך האימות, תוצג הודעת שגיאה בממשק המעקב של Dataflow, וגם במסוף או בחלון הטרמינל אם משתמשים בהפעלה חוסמת. הודעת השגיאה דומה לזו:
Java
INFO: To access the Dataflow monitoring console, please navigate to
https://console.developers.google.com/project/google.com%3Aclouddfe/dataflow/job/2016-03-08_18_59_25-16868399470801620798
Submitted job: 2016-03-08_18_59_25-16868399470801620798
...
... Starting 3 workers...
... Executing operation BigQuery-Read+AnonymousParDo+BigQuery-Write
... Executing BigQuery import job "dataflow_job_16868399470801619475".
... Stopping worker pool...
... Workflow failed. Causes: ...BigQuery-Read+AnonymousParDo+BigQuery-Write failed.
Causes: ... BigQuery getting table "non_existent_table" from dataset "cws_demo" in project "my_project" failed.
Message: Not found: Table x:cws_demo.non_existent_table HTTP Code: 404
... Worker pool stopped.
... com.google.cloud.dataflow.sdk.runners.BlockingDataflowPipelineRunner run
INFO: Job finished with status FAILED
Exception in thread "main" com.google.cloud.dataflow.sdk.runners.DataflowJobExecutionException:
Job 2016-03-08_18_59_25-16868399470801620798 failed with status FAILED
at com.google.cloud.dataflow.sdk.runners.DataflowRunner.run(DataflowRunner.java:155)
at com.google.cloud.dataflow.sdk.runners.DataflowRunner.run(DataflowRunner.java:56)
at com.google.cloud.dataflow.sdk.Pipeline.run(Pipeline.java:180)
at com.google.cloud.dataflow.integration.BigQueryCopyTableExample.main(BigQueryCopyTableExample.java:74)
Python
INFO:root:Created job with id: [2016-03-08_14_12_01-2117248033993412477] ... Checking required Cloud APIs are enabled. ... Job 2016-03-08_14_12_01-2117248033993412477 is in state JOB_STATE_RUNNING. ... Combiner lifting skipped for step group: GroupByKey not followed by a combiner. ... Expanding GroupByKey operations into optimizable parts. ... Lifting ValueCombiningMappingFns into MergeBucketsMappingFns ... Annotating graph with Autotuner information. ... Fusing adjacent ParDo, Read, Write, and Flatten operations ... Fusing consumer split into read ... ... Starting 1 workers... ... ... Executing operation read+split+pair_with_one+group/Reify+group/Write ... Executing failure step failure14 ... Workflow failed. Causes: ... read+split+pair_with_one+group/Reify+group/Write failed. Causes: ... Unable to view metadata for files: gs://dataflow-samples/shakespeare/missing.txt. ... Cleaning up. ... Tearing down pending resources... INFO:root:Job 2016-03-08_14_12_01-2117248033993412477 is in state JOB_STATE_FAILED.
המשך
בשלב הזה, אימות העבודה שמתואר בקטע הזה לא נתמך ב-Go. שגיאות שנובעות מהבעיות האלה מופיעות כחריגות של העובד.
זיהוי חריגה בקוד של Worker
במהלך הפעלת העבודה, יכול להיות שתיתקלו בשגיאות או בחריגים בקוד של העובד. בדרך כלל השגיאות האלה מעידות על כך שהפקודות DoFn בקוד של צינור העברת הנתונים יצרו חריגים שלא טופלו, ולכן המשימות בעבודת Dataflow נכשלו.
חריגים בקוד המשתמש (לדוגמה, מופעי DoFn) מדווחים בממשק המעקב של Dataflow.
אם מריצים את צינור הנתונים עם חסימת הביצוע, הודעות השגיאה מודפסות במסוף או בחלון המסוף, כמו בדוגמה הבאה:
Java
INFO: To access the Dataflow monitoring console, please navigate to https://console.developers.google.com/project/example_project/dataflow/job/2017-05-23_14_02_46-1117850763061203461
Submitted job: 2017-05-23_14_02_46-1117850763061203461
...
... To cancel the job using the 'gcloud' tool, run: gcloud beta dataflow jobs --project=example_project cancel 2017-05-23_14_02_46-1117850763061203461
... Autoscaling is enabled for job 2017-05-23_14_02_46-1117850763061203461.
... The number of workers will be between 1 and 15.
... Autoscaling was automatically enabled for job 2017-05-23_14_02_46-1117850763061203461.
...
... Executing operation BigQueryIO.Write/BatchLoads/Create/Read(CreateSource)+BigQueryIO.Write/BatchLoads/GetTempFilePrefix+BigQueryIO.Write/BatchLoads/TempFilePrefixView/BatchViewOverrides.GroupByWindowHashAsKeyAndWindowAsSortKey/ParDo(UseWindowHashAsKeyAndWindowAsSortKey)+BigQueryIO.Write/BatchLoads/TempFilePrefixView/Combine.GloballyAsSingletonView/Combine.globally(Singleton)/WithKeys/AddKeys/Map/ParMultiDo(Anonymous)+BigQueryIO.Write/BatchLoads/TempFilePrefixView/Combine.GloballyAsSingletonView/Combine.globally(Singleton)/Combine.perKey(Singleton)/GroupByKey/Reify+BigQueryIO.Write/BatchLoads/TempFilePrefixView/Combine.GloballyAsSingletonView/Combine.globally(Singleton)/Combine.perKey(Singleton)/GroupByKey/Write+BigQueryIO.Write/BatchLoads/TempFilePrefixView/BatchViewOverrides.GroupByWindowHashAsKeyAndWindowAsSortKey/BatchViewOverrides.GroupByKeyAndSortValuesOnly/Write
... Workers have started successfully.
...
... org.apache.beam.runners.dataflow.util.MonitoringUtil$LoggingHandler process SEVERE: 2017-05-23T21:06:33.711Z: (c14bab21d699a182): java.lang.RuntimeException: org.apache.beam.sdk.util.UserCodeException: java.lang.ArithmeticException: / by zero
at com.google.cloud.dataflow.worker.runners.worker.GroupAlsoByWindowsParDoFn$1.output(GroupAlsoByWindowsParDoFn.java:146)
at com.google.cloud.dataflow.worker.runners.worker.GroupAlsoByWindowFnRunner$1.outputWindowedValue(GroupAlsoByWindowFnRunner.java:104)
at com.google.cloud.dataflow.worker.util.BatchGroupAlsoByWindowAndCombineFn.closeWindow(BatchGroupAlsoByWindowAndCombineFn.java:191)
...
... Cleaning up.
... Stopping worker pool...
... Worker pool stopped.
Python
INFO:root:Job 2016-03-08_14_21_32-8974754969325215880 is in state JOB_STATE_RUNNING. ... INFO:root:... Expanding GroupByKey operations into optimizable parts. INFO:root:... Lifting ValueCombiningMappingFns into MergeBucketsMappingFns INFO:root:... Annotating graph with Autotuner information. INFO:root:... Fusing adjacent ParDo, Read, Write, and Flatten operations ... INFO:root:...: Starting 1 workers... INFO:root:...: Executing operation group/Create INFO:root:...: Value "group/Session" materialized. INFO:root:...: Executing operation read+split+pair_with_one+group/Reify+group/Write INFO:root:Job 2016-03-08_14_21_32-8974754969325215880 is in state JOB_STATE_RUNNING. INFO:root:...: ...: Workers have started successfully. INFO:root:Job 2016-03-08_14_21_32-8974754969325215880 is in state JOB_STATE_RUNNING. INFO:root:...: Traceback (most recent call last): File ".../dataflow_worker/batchworker.py", line 384, in do_work self.current_executor.execute(work_item.map_task) ... File ".../apache_beam/examples/wordcount.runfiles/py/apache_beam/examples/wordcount.py", line 73, in <lambda> ValueError: invalid literal for int() with base 10: 'www'
המשך
... 2022-05-26T18:32:52.752315397Zprocess bundle failed for instruction ... process_bundle-4031463614776698457-2 using plan s02-6 : while executing ... Process for Plan[s02-6] failed: Oh no! This is an error message!
כדאי להוסיף לטיפול בשגיאות בקוד מטפלים בחריגים. לדוגמה, אם רוצים להשמיט רכיבים שלא עוברים אימות קלט מותאם אישית שבוצע ב-ParDo, צריך לטפל בחריגה בתוך DoFn ולהשמיט את הרכיב.
יש כמה דרכים לעקוב אחרי רכיבים שנכשלים:
- אפשר לרשום ביומן את הרכיבים שנכשלו ולבדוק את הפלט באמצעות Cloud Logging.
- כדי לבדוק אם יש אזהרות או שגיאות ביומנים של תהליך העבודה של Dataflow ושל הפעלת תהליך העבודה, פועלים לפי ההוראות במאמר בנושא הצגת יומנים.
- אפשר לבקש מ-
ParDoלכתוב את הרכיבים שנכשלו בפלט נוסף לבדיקה מאוחרת יותר.
כדי לעקוב אחרי המאפיינים של צינור עיבוד נתונים שפועל, אפשר להשתמש במחלקה Metrics, כמו בדוגמה הבאה:
Java
final Counter counter = Metrics.counter("stats", "even-items"); PCollection<Integer> input = pipeline.apply(...); ... input.apply(ParDo.of(new DoFn<Integer, Integer>() { @ProcessElement public void processElement(ProcessContext c) { if (c.element() % 2 == 0) { counter.inc(); } });
Python
class FilterTextFn(beam.DoFn): """A DoFn that filters for a specific key based on a regex.""" def __init__(self, pattern): self.pattern = pattern # A custom metric can track values in your pipeline as it runs. Create # custom metrics to count unmatched words, and know the distribution of # word lengths in the input PCollection. self.word_len_dist = Metrics.distribution(self.__class__, 'word_len_dist') self.unmatched_words = Metrics.counter(self.__class__, 'unmatched_words') def process(self, element): word = element self.word_len_dist.update(len(word)) if re.match(self.pattern, word): yield element else: self.unmatched_words.inc() filtered_words = ( words | 'FilterText' >> beam.ParDo(FilterTextFn('s.*')))
המשך
func addMetricDoFnToPipeline(s beam.Scope, input beam.PCollection) beam.PCollection { return beam.ParDo(s, &MyMetricsDoFn{}, input) } func executePipelineAndGetMetrics(ctx context.Context, p *beam.Pipeline) (metrics.QueryResults, error) { pr, err := beam.Run(ctx, runner, p) if err != nil { return metrics.QueryResults{}, err } // Request the metric called "counter1" in namespace called "namespace" ms := pr.Metrics().Query(func(r beam.MetricResult) bool { return r.Namespace() == "namespace" && r.Name() == "counter1" }) // Print the metric value - there should be only one line because there is // only one metric called "counter1" in the namespace called "namespace" for _, c := range ms.Counters() { fmt.Println(c.Namespace(), "-", c.Name(), ":", c.Committed) } return ms, nil } type MyMetricsDoFn struct { counter beam.Counter } func init() { beam.RegisterType(reflect.TypeOf((*MyMetricsDoFn)(nil))) } func (fn *MyMetricsDoFn) Setup() { // While metrics can be defined in package scope or dynamically // it's most efficient to include them in the DoFn. fn.counter = beam.NewCounter("namespace", "counter1") } func (fn *MyMetricsDoFn) ProcessElement(ctx context.Context, v beam.V, emit func(beam.V)) { // count the elements fn.counter.Inc(ctx, 1) emit(v) }
פתרון בעיות של צינורות שפועלים לאט או שלא מפיקים פלט
אפשר לעיין בדפים הבאים:
שגיאות נפוצות ופעולות מומלצות
אם אתם יודעים מהי השגיאה שגרמה לכשל בצינור עיבוד הנתונים, תוכלו להיעזר בהנחיות לפתרון בעיות שמופיעות בדף פתרון בעיות ב-Dataflow.