
במאמר הזה מוסבר איך להגדיר תרשים זמני שמציג את נתוני הסדרות העיתיות שנאספו בפרויקט. ב-Metrics Explorer אפשר להציג רק נתונים מספריים של סדרות זמנים.
בחירת הנתונים להצגה
כדי להגדיר אילו סדרות זמנים יוצגו בתרשים, אפשר לבנות שאילתה על ידי בחירה מתוך תפריטים, או לכתוב שאילתה. כשכותבים שאילתה, בוחרים את שפת השאילתה ואז משתמשים בכלי לעריכת שאילתות או בממשק מבוסס-טקסט:
שאילתות של Prometheus Query Language (PromQL) מציינות סדרות זמן ואת האופן שבו סדרות הזמן האלה מקובצות ומיושרות. ממשק PromQL תומך בעורך עם הצעות.
בדרך כלל אי אפשר להמיר שאילתות PromQL לטפסים שאפשר להשתמש בהם בממשקים האחרים. השאילתות שלא נשמרו יימחקו כשעוברים לכרטיסייה PromQL או יוצאים ממנה.
שאילתות של מסנן מעקב מציינות את סדרת הזמן אבל לא כוללות הצהרות של קיבוץ או יישור.
אפשר לציין כל סדרת זמנים שניתן ליצור לה תרשים ב-Monitoring באמצעות מסנן של Monitoring. לדוגמה, כדי ליצור תרשים של מספר התהליכים שפועלים במכונה וירטואלית, צריך להשתמש במסנן של Monitoring שמציין פונקציה.
לא תמיד אפשר להמיר מסנן מעקב לפורמט שנדרש בממשקים אחרים. לכן, יכול להיות שהשאילתה תימחק אם תעברו לממשק אחר.
בדרך כלל, בשאילתות מציינים סוג מדד, סוג משאב ומסננים:
סוג מדד מזהה את המדידות שצריך לאסוף ממשאב. הוא כולל תיאור של מה שנמדד ואיך מפרשים את המדידות. סוג מדד נקרא לפעמים מדד. דוגמה למדד היא 'ניצול CPU'. מידע על המושגים מופיע במאמר סוגי מדדים.
סוג משאב מציין מאיזה משאב נאספים נתוני המדד. המונח סוג משאב נקרא לפעמים סוג המשאב שבמעקב או משאב. דוגמה למשאב היא "מכונה וירטואלית (VM) של Compute Engine". מידע על המושגים מופיע במאמר משאבים במעקב.
שאילתות PromQL כוללות הצהרות על קיבוץ והתאמה. עם זאת, כשכותבים מסנן של Monitoring או משתמשים בתפריטים כדי לבחור את סדרת הזמן לתרשים, מגדירים את ההגדרות של הקיבוץ והיישור באמצעות תפריטים.
יצירת שאילתות באמצעות תפריטים
הגדרת ברירת המחדל היא יצירת שאילתות באמצעות תפריטים. בדרך כלל, אם בוחרים מדד ומסנן ואז עוברים לממשק אחר, הבחירות נשמרות ומעוצבות מחדש עבור הממשק הזה. כלומר, אפשר להמיר שאילתה שנוצרה באמצעות תפריטים לשאילתת PromQL.
כדי לחזור מהממשקים האחרים לממשק מבוסס התפריטים, לוחצים על tune כלי בנייה. עם זאת, השאילתה שלך תימחק. כלומר, אי אפשר להמיר שאילתת PromQL לטופס מקביל מבוסס-תפריט.
כדי ליצור שאילתה באמצעות תפריטים:
-
נכנסים לדף leaderboard Metrics explorer במסוף Google Cloud :
אם משתמשים בסרגל החיפוש כדי למצוא את הדף הזה, בוחרים בתוצאה שבה הכותרת המשנית היא Monitoring.
- בסרגל הכלים של מסוף Google Cloud , בוחרים את Google Cloud הפרויקט. בהגדרות של מרכז האפליקציות, בוחרים את הפרויקט המארח או את פרויקט הניהול של מרכז האפליקציות.
בסרגל הכלים של חלונית השאילתה:
ברכיב מדד, מרחיבים את התפריט בחירת מדד.
התפריט Select a metric כולל תכונות שעוזרות לכם למצוא את סוגי המדדים שזמינים:
- כדי למצוא סוג מדד ספציפי, משתמשים בfilter_list סרגל הסינון.
לדוגמה, אם מזינים
util, התפריט יציג רק את האפשרויות שכוללות אתutil. הערכים מוצגים אם הם עוברים בדיקה לא תלוית-רישיות מסוג 'מכיל'. - כדי להציג את כל סוגי המדדים, גם אלה שלא כוללים נתונים, לוחצים על פעיל. כברירת מחדל, בתפריטים מוצגים רק סוגי מדדים עם נתונים.
- כדי למצוא סוג מדד ספציפי, משתמשים בfilter_list סרגל הסינון.
לדוגמה, אם מזינים
בוחרים אפשרות מהתפריט Resources, מהתפריט Metric categories ומהתפריט Metrics, ואז לוחצים על Apply.
לדוגמה, כדי ליצור תרשים של ניצול המעבד של מכונה וירטואלית של Compute Engine, אפשר לבחור באפשרויות VM instance, Instance, CPU utilization ואז ללחוץ על Apply.
בתפריט Resources מופיע המשאב שממנו נאספים הנתונים. אם לא מציינים מדד עבור משאב, בוחרים באפשרות לא צוין.
אחרי שבוחרים את סוג המשאב והמדד, בתרשים מוצגות כל סדרות הזמנים שזמינות לצמד הזה:
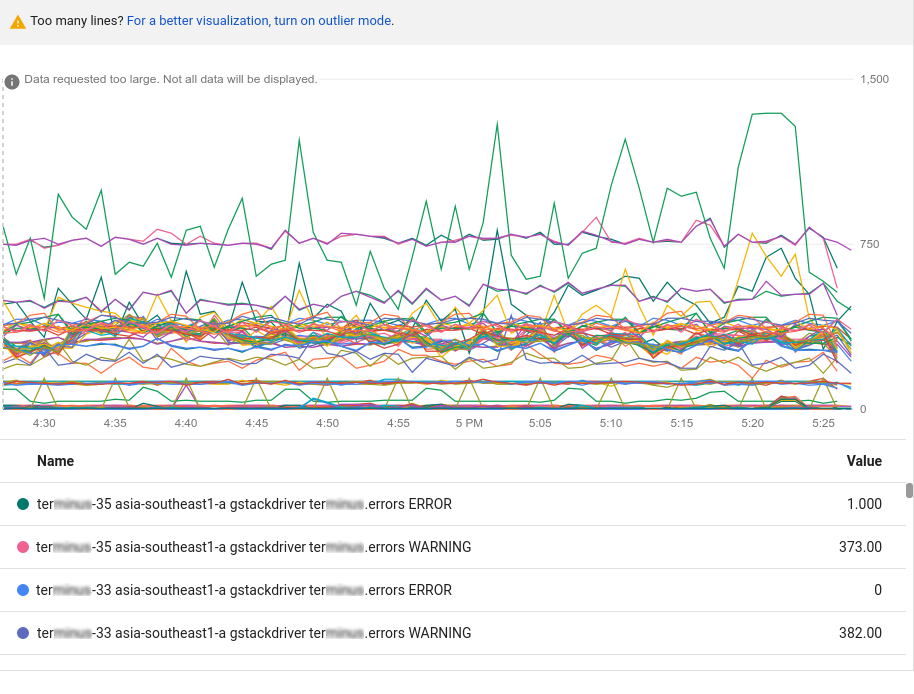
התרשים הקודם מכיל יותר נתונים מכפי שאפשר להציג. תרשימים מוגבלים ל-50 שורות שניתן להציג. בתרשים מוצגת הודעה שיש יותר מדי נתונים להצגה. כדי לצמצם את כמות הנתונים, משתמשים ברכיב מיון והגבלה בסרגל הכלים של השאילתה. מידע נוסף זמין במאמר בנושא הצגת ערכים חריגים.
אפשר גם להשתמש באפשרויות הסינון והצבירה כדי לצמצם את כמות הנתונים בתרשים. הטכניקות האלה הופכות את התרשימים לשימושיים יותר לצורך אבחון וניתוח, והן משפרות את הביצועים ואת מהירות התגובה של ממשק המשתמש עצמו.
אופציונלי: מוסיפים מסננים כדי להגביל את סדרות הזמן שיוצגו. בקטע הבא מפורטות אפשרויות הסינון.
אופציונלי: מגדירים איך סדרות הזמנים מקובצות ומוצגות. מידע נוסף מופיע במאמר בחירת אופן הצגת הנתונים בתרשים.
סינון נתונים בתרשים
המסננים מוודאים שיוצגו בתרשים רק סדרות זמן שעומדות בקבוצה מסוימת של קריטריונים. כשמחילים מסננים, יכול להיות שמספר הקווים בתרשים יקטן, מה שיכול לשפר את הביצועים של התרשים. דרך נוספת לשפר את מהירות התגובה של תרשים היא להגדיר אפשרויות צבירה, למיין את סדרות הזמן שמוצגות ולהגביל את מספרן. מידע נוסף זמין במאמר בנושא הצגת ערכים חריגים.
מסנן מורכב מתווית, מאופרטור השוואה ומערך. לדוגמה, כדי להתאים את כל סדרות הזמן שהתווית zone שלהן מתחילה ב-"us-central1", אפשר להשתמש במסנן zone=~"us-central1.*", שמשתמש בביטוי רגולרי כדי לבצע את ההשוואה. יש ארבעה אופרטורים להשוואה:
- שווה ל-,
= - לא שווה ל-
!= - התאמה של ביטוי רגולרי,
=~ - הביטוי הרגולרי לא תואם,
!=~
כשמסננים לפי מזהה הפרויקט או מאגר המשאבים, צריך להשתמש באופרטור השווה, (=). כשמסננים לפי תוויות אחרות, אפשר להשתמש בכל אופרטור השוואה נתמך.
בדרך כלל אפשר לסנן את תוויות המדדים והמשאבים, וגם לפי קבוצת משאבים.
כשמספקים כמה קריטריונים לסינון, בתרשים המתאים מוצגות רק סדרות הזמן שעומדות בכל הקריטריונים, כלומר מתבצעת פעולת AND לוגית.
כדי להוסיף מסנן כשמשתמשים בממשק מבוסס-תפריט של מסוף Google Cloud :
ברכיב Filter, לוחצים על Add filter ובוחרים אפשרות מהתפריט.
כדי לשנות את ההשוואה, בוחרים ערך מהתפריט השוואה.
בשדה ערך, מזינים או בוחרים ערך:
כדי לבצע השוואה ישירה,
=או!=, בוחרים את הערך מהתפריט או מזינים ערך ולוחצים על אישור. אפשר להזין ערכים כמוus-central1-a, או ליצור מחרוזת מסנן שמתחילה ב-starts_withאו ב-ends_with. לדוגמה, כדי להציג נתונים של אזורus-central1כלשהו, אפשר להזין את מחרוזת המסנןstarts_with("us-central1"). מידע נוסף על מחרוזות של מסננים זמין במאמר בנושא מסנני Monitoring.מכיוון שהערכים בתפריט נגזרים מסדרות הזמנים שהתקבלו, אם משאב שנמצא במעקב לא יוצר נתונים עבור המדד שנבחר, צריך להזין ערך לתווית.
כדי להשוות ביטוי רגולרי,
=~או!=~, מזינים ביטוי רגולרי של RE2 בשדה ערך ולוחצים על אישור. לדוגמה, הביטוי הרגולריus-central1-.*תואם לכל האזוריםus-central1.כדי להתאים לכל אזור בארה"ב שמסתיים ב-a, אפשר להשתמש בביטוי הרגולרי
^us.*.a$.אי אפשר להשתמש בביטויים רגולריים כדי לסנן את
project_idתווית המשאב.לדוגמה, כדי להציג רק את סדרת הזמן מאחד מ
us-central1האזורים, מפעילים מסנןzone=~"us-central1.*".
כשמוסיפים כמה מסננים, חשוב לשים לב לנקודות הבאות:
אפשר להשתמש באותה תווית כמה פעמים, וכך לציין מסנן לטווח של ערכים.
כל קריטריוני הסינון צריכים להתקיים. הם מהווים
ANDלוגי.
כדי לערוך את הערך או את האופרטור להשוואה של מסנן, לוחצים על arrow_drop_down תפריט ברכיב המסנן, מבצעים את השינויים ואז לוחצים על אישור.
כדי למחוק מסנן, לוחצים על cancel ביטול.
כתיבת שאילתות PromQL
כדי להזין שאילתת PromQL:
-
נכנסים לדף leaderboard Metrics explorer במסוף Google Cloud :
אם משתמשים בסרגל החיפוש כדי למצוא את הדף הזה, בוחרים בתוצאה שבה הכותרת המשנית היא Monitoring.
- בסרגל הכלים של מסוף Google Cloud , בוחרים את Google Cloud הפרויקט. בהגדרות של מרכז האפליקציות, בוחרים את הפרויקט המארח או את פרויקט הניהול של מרכז האפליקציות.
- בסרגל הכלים של החלונית ליצירת שאילתות, לוחצים על הלחצן ששמו code PromQL.
- אופציונלי: משביתים את המתג הפעלה אוטומטית.
-
מזינים את השאילתה בעורך השאילתות. לדוגמה, כדי ליצור תרשים של ניצול המעבד הממוצע של המכונות הווירטואליות בפרויקט Google Cloud , משתמשים בשאילתה הבאה:
avg(compute_googleapis_com:instance_cpu_utilization)
מידע נוסף על השימוש ב-PromQL זמין במאמר PromQL ב-Cloud Monitoring.
לוחצים על Run query.
כשהמתג הפעלה אוטומטית מופעל, לא מוצג הלחצן הפעלת שאילתה.
כתיבת שאילתות של מסנני מעקב
כדי לבצע את הפעולות הבאות, צריך להשתמש במצב סינון ישיר, שמאפשר להזין מסנן מעקב:
- הצגת יעד למדידת רמת השירות (SLO).
- הצגת מספר התהליכים שפועלים במכונות וירטואליות (VM).
- להציג מדד מותאם אישית שעדיין אין לכם נתונים לגביו.
- מסננים סדרת נתונים לפי תווית שעוד אין לכם נתונים לגביה.
מסנן מעקב, או לחלופין מסנן מדדים, הוא ביטוי שמשמש את Monitoring לזיהוי סדרות הזמנים שיוצגו בתרשים.
לדוגמה, הביטוי הבא יוצר תרשים שמציג את מספר התהליכים שהשם שלהם כולל את nginx:
select_process_count("monitoring.regex.full_match(\".*nginx.*\")")
resource.type="gce_instance"
אפשר גם להשתמש במסנני Monitoring כדי לזהות סדרות עיתיות לפי המשאב וסוג המדד שלהן. הביטוי הבא יוצר תרשים שמציג את מספר הרשומות ביומן של כל המכונות הווירטואליות Google Cloud באזור us-east1-b:
metric.type="logging.googleapis.com/log_entry_count"
resource.type="gce_instance"
resource.label."zone"="us-east1-b"
כדי להזין מסנן של מעקב:
-
נכנסים לדף leaderboard Metrics explorer במסוף Google Cloud :
אם משתמשים בסרגל החיפוש כדי למצוא את הדף הזה, בוחרים בתוצאה שבה הכותרת המשנית היא Monitoring.
- בסרגל הכלים של מסוף Google Cloud , בוחרים את Google Cloud הפרויקט. בהגדרות של מרכז האפליקציות, בוחרים את הפרויקט המארח או את פרויקט הניהול של מרכז האפליקציות.
לוחצים על help_outline עזרה ברכיב מדד, ואז בוחרים באפשרות מצב סינון ישיר.
האלמנטים Metric ו-Filter נמחקים, ונוצר אלמנט Filters שמאפשר להזין טקסט.
אם בחרתם סוג משאב, מדד או מסננים לפני שעברתם למצב Direct Filter Mode, ההגדרות האלה יוצגו באלמנט Filters.
באזור הטקסט של רכיב Filters, מזינים ביטוי של מסנן לניטור. מידע על התחביר זמין במאמרים הבאים:
כשמשתמשים במצב של מסנן ישיר ולא זמינים נתונים שתואמים למסנן, מוצגת שגיאה. הודעות השגיאה הנפוצות כוללות את
Chart definition invalidואתNo data is available for the selected timeframe.אופציונלי: מגדירים איך סדרות הזמנים מקובצות ומוצגות. מידע נוסף מופיע במאמר בחירת אופן הצגת הנתונים בתרשים.
כדי לחזור לממשק מבוסס-תפריטים, לוחצים על tune יציאה ממצב סינון ישיר.
בחירת אופן הצגת הנתונים בתרשים
בקטע הזה מוסבר איך להציג את הנתונים שנבחרו על ידי הגדרת שדות הצבירה. צבירה כוללת יישור של נקודות נתונים בסדרת זמן ושילוב של סדרות זמן שונות. הסבר מפורט על צבירה מופיע במאמר סינון וצבירה: מניפולציה של סדרות זמן.
- מידע על אפשרויות התצוגה מופיע במאמר בנושא הגדרת אפשרויות התצוגה של תרשימים.
- מידע נוסף על אינטראקציה עם התרשים עצמו זמין במאמר איך בודקים את הנתונים בתרשים.
התוכן של הקטע הזה לא רלוונטי כשבוחרים את הנתונים לתרשים באמצעות PromQL.
שילוב של סדרות זמנים
אפשר לצמצם את כמות הנתונים שמוחזרת עבור מדד על ידי שילוב של סדרות זמן שונות. כדי לשלב כמה סדרות עיתיות, בדרך כלל מציינים תווית אחת או יותר ופונקציה. סדרות זמן עם אותו ערך לכל התוויות שצוינו מקובצות, ואז הפונקציה שציינת משלבת את סדרות הזמן האלה לסדרת זמן חדשה.
ההגדרות ברכיב Aggregation יכולות לשנות את מספר סדרות הזמן שמוצגות בתרשים. הגדרות ברירת המחדל של הרכיב הזה נקבעות לפי סוג המדד שבחרתם. כדי לשנות את התצוגה, מבצעים אחת מהפעולות הבאות:
כדי להציג את כל סדרות הזמנים, מוודאים שבתפריט הראשון של הרכיב Aggregation מוגדרת האפשרות Unaggregated ובתפריט השני מוגדרת האפשרות None.
כדי לשלב סדרות עיתיות, באלמנט Aggregation:
מרחיבים את התפריט הראשון ובוחרים פונקציה.
התרשים מתעדכן ומוצגת בו סדרת זמן אחת. לדוגמה, אם בוחרים באפשרות ממוצע, סדרת הזמן שמוצגת היא הממוצע של כל סדרות הזמן.
תפריט הפונקציות תומך בפונקציות אלגבריות נפוצות, כמו ממוצע, מינימום, מקסימום וסכום. האפשרות ספירת סדרות עיתיות סופרת את מספר הסדרות העיתיות שתואמות להגדרות המדד והמסנן. אפשרויות האחוזון, כמו אחוזון 99, הן ערכים סטטיסטיים שנגזרים מסדרת הזמן שתואמת למדד ולהגדרות הסינון.
כדי לשלב סדרות זמנים עם אותם ערכי תוויות, מרחיבים את התפריט השני ובוחרים תוויות אחת או יותר.
התרשים מתרענן ומוצגת בו סדרת זמן אחת לכל שילוב ייחודי של ערכי תוויות. לדוגמה, כדי להציג את סדרת הזמן לפי אזור, מגדירים את התפריט השני לאזור.
כדי להגדיר את המרווח בין נקודות הנתונים, לוחצים על add הוספת רכיב שאילתה, בוחרים באפשרות מרווח מינימלי ומזינים ערך.
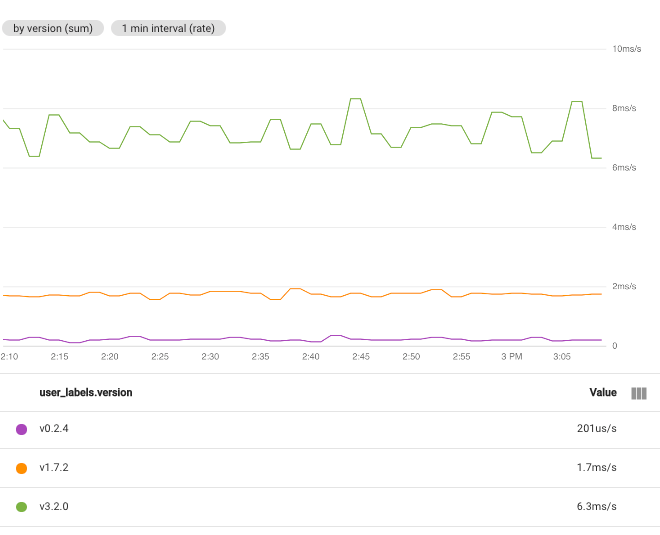
לדוגמה, אם מגדירים את הפונקציה ל-Sum ובוחרים את התווית user_labels.version, אז יש סדרת זמן אחת לכל ערך של התווית user_labels.version. נקודות הנתונים בכל סדרת זמן מחושבות מסכום כל הערכים של סדרות זמן נפרדות לגרסה ספציפית:
כשבוחרים כמה תוויות, סדרות זמן עם אותם ערכים לתוויות שנבחרו משולבות. בתרשים שמתקבל מוצגת סדרת זמן אחת לכל שילוב של ערכי התווית. הסדר שבו מציינים את התוויות לא משנה. בצילום המסך הבא מוצג תרשים שבו סדרות הזמנים משולבות לפי התוויות user_labels.version ו-system_labels.machine_image:
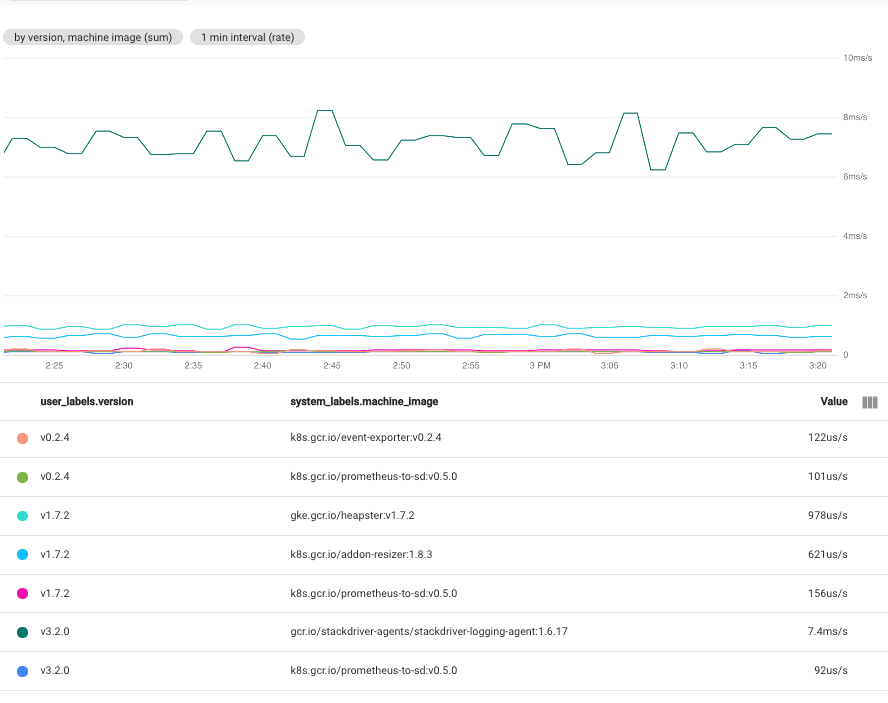
כפי שרואים, בתרשים מוצגת סדרת זמן אחת לכל זוג של ערכי תוויות. העובדה שמקבלים סדרת זמנים לכל שילוב של תוויות אומרת שטכניקה כזו יכולה ליצור יותר נתונים מכפי שאפשר להציג בצורה מועילה בתרשים אחד.
הצגת כל סדרות הזמנים
כדי להציג את כל סדרות הזמנים, בתפריט Aggregation, בוחרים באפשרות Unaggregated בתפריט הראשון ובאפשרות None בתפריט השני.
התאמה של סדרות זמנים
ההתאמה היא תהליך של המרת נתונים מסדרת זמן שמתקבלים מ-Monitoring לסדרת זמן חדשה עם נקודות נתונים במרווחי זמן קבועים. תהליך ההתאמה כולל איסוף של כל נקודות הנתונים שהתקבלו בפרק זמן קבוע, הפעלת פונקציה לשילוב נקודות הנתונים האלה והקצאת חותמת זמן לתוצאה. הפונקציה הזו יכולה לחשב את הממוצע של כל הדגימות או לחלץ את הערך המקסימלי של כל הדגימות.
הגדרת מרווח ההתאמה
כדי לציין את משך הזמן הקבוע לשילוב הנקודות, לוחצים על add הוספת רכיב שאילתה בחלונית השאילתה, בוחרים באפשרות מרווח מינימלי ומשלימים את תיבת הדו-שיח.
לדוגמה, נניח שיש מדד עם תקופת דגימה של דקה אחת. אם התרשים מוגדר להצגת נתונים של שעה אחת, הוא יכול להציג את כל 60 נקודות הנתונים. אם השדה Min Interval מוגדר ל-10 minutes, התרשים יציג 6 נקודות נתונים. אבל אם תגדירו עכשיו את התרשים כך שיוצגו בו נתונים של שבוע אחד, יהיו יותר מדי נקודות להצגה בתרשים, ולכן המרווח שבו הנקודות משולבות ישתנה באופן אוטומטי.
בדוגמה הזו, המרווח שונה לשעה אחת.
בצילום המסך הבא מוצג ניצול המעבד של מכונות וירטואליות ב-Compute Engine בפרויקט מסוים Google Cloud .
בתמונה הזו, השדה Min Interval מוגדר ל-1 minute:
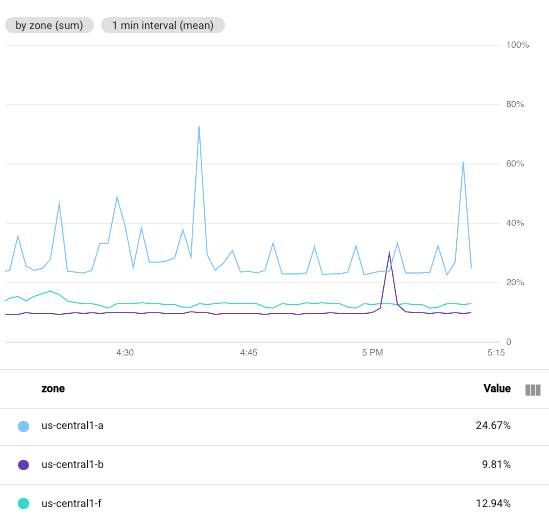
לשם השוואה, צילום המסך הבא ממחיש את ההשפעה של שינוי המרווח מ-1 minute ל-5 minutes:
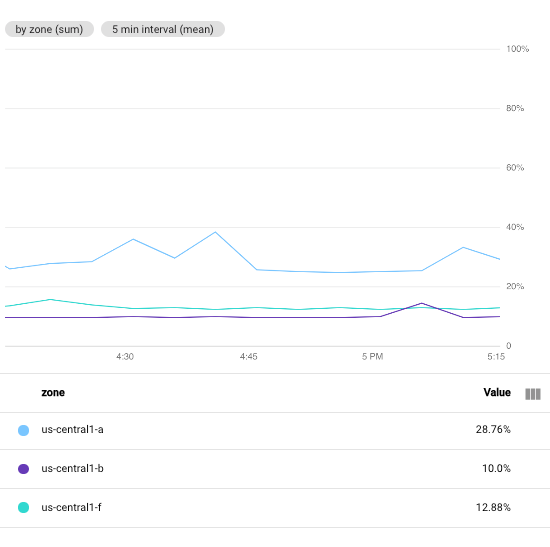
אם מגדילים את התקופה, מספר הנקודות בתרשים קטן. למשל, מ-60 נקודות לכל סדרת זמן ל-10 נקודות לכל סדרת זמן. הגדלת הערך בשדה Min Interval (מרווח מינימלי) גורמת לשילוב של יותר נקודות, וכך מתקבל אפקט החלקה על הנתונים שמוצגים בתרשים.
הגדרת פונקציית יישור
כשבוחרים את הפונקציה לצבירה, Cloud Monitoring בוחר בשבילכם את פונקציית היישור. Cloud Monitoring קובע את פונקציית היישור האופטימלית על סמך סוג המדד שבחרתם והבחירה שלכם בפונקציית הצבירה. עם זאת, אפשר לציין פונקציית יישור ולשנות את הבחירה שנעשתה על ידי Cloud Monitoring.
כדי לציין את פונקציית היישור, מבצעים את הפעולות הבאות:
- ברכיב צבירה, מרחיבים את התפריט הראשון ובוחרים באפשרות הגדרת כלי ההתאמה. האלמנטים פונקציית היישור וקיבוץ מתווספים.
- מרחיבים את הרכיב Alignment function (פונקציית היישור) ובוחרים אפשרות.
רוב פונקציות היישור הנתמכות מבצעות פונקציות מתמטיות נפוצות, אבל חלקן מבצעות פעולות מורכבות יותר:
הבא ישן יותר: כדי לשמור רק את הדגימה האחרונה בתקופת ההתאמה, בוחרים באפשרות הבא ישן יותר. בדרך כלל משתמשים בפונקציה הזו עם בדיקות זמינות, והיא מתאימה כשרוצים לדעת רק את הערך האחרון.
הפונקציה הזו תקפה רק למדדי מד.
אחוזון: כדי להציג מדד התפלגות בתרשים קו, בתרשים שטח מוערם או בתרשים עמודות מוערם, צריך לבחור איזה אחוזון בהתפלגות רוצים להציג. אחת הדרכים לציין את האחוזון הזה היא לבחור פונקציית אחוזון. אפשר לבחור את האחוזונים ה-5, ה-50, ה-95 וה-99. נקודת הנתונים המותאמת נקבעת על ידי חישוב האחוזון שצוין באמצעות כל נקודות הנתונים בתקופת ההתאמה.
הפונקציה הזו תקפה רק למדדים מסוג מדד רמת דיוק ומדד דלתא, כשהם מסוג נתוני התפלגות.
delta: כדי להמיר מדד מצטבר או מדד דלתא למדד דלתא עם דגימה אחת לכל תקופת התאמה, משתמשים בפונקציה הזו. יכול להיות שתתבצע אינטרפולציה של נתונים כשמשתמשים בפונקציה הזו. דוגמה אפשר לראות במאמר Kinds, types, and conversions (סוגים, סוגים והמרות).
הפונקציה הזו תקפה רק למדדים מצטברים ולמדדי דלתא.
rate: כדי להמיר מדד מצטבר או מדד דלתא למדד של מדד רמת הדיוק, משתמשים בפונקציה הזו. אם בוחרים בפונקציה הזו, אפשר לחשוב על סדרת הזמן כאילו היא עברה טרנספורמציה באמצעות פונקציית דלתא, ואז חולקה לפי תקופת היישור. לדוגמה, אם היחידה של סדרת הזמן המקורית היא MiB והיחידה של תקופת ההתאמה היא שנייה, אז היחידה של התרשים היא MiB לשנייה. מידע נוסף זמין במאמר סוגים, סוגים והמרות.
הפונקציה הזו תקפה רק למדדים מצטברים ולמדדי דלתא.
מידע נוסף על פונקציות היישור הזמינות מופיע במאמר Aligner בהפניית ה-API.
קיבוץ משני ויישור
אם יש לכם כמה סדרות זמן שכבר מייצגות צבירות, אתם יכולים לצמצם את כל סדרות הזמן בתרשים לסדרת זמן אחת על ידי בחירת צבירה משנית. לדוגמה, אם מקבצים נתונים לפי אזור, בתרשים מוצגות סדרות זמן לכל אזור. כדי ליצור תרשים עם סדרת זמן אחת, משתמשים בשדות של צבירה משנית.
בחלק מסוגי המדדים, יש לכם אפשרות לשנות את הנתונים. אם האפשרות הזו זמינה ואם מגדירים בשדה Transform ערך שונה מ-None, כל שאר השדות הם הגדרות הצבירה המשנית.
כשניתן להגדיר את שדות הצבירה המשניים, כדי לגשת לשדות האלה, לדברים הבאים:
- לוחצים על add הוספת רכיב שאילתה ואז בוחרים באפשרות צבירה משנית.
- מגדירים את הרכיב Secondary aggregation.
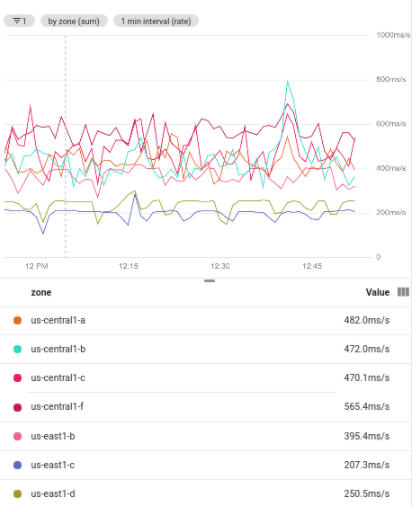
בצילום המסך הבא מוצגות כמה סדרות זמן שמתקבלות מקיבוץ של קבוצת נתונים מסוננת. כדי להשתמש בקיבוץ, צריך לבצע צבירה. כל קבוצת שורות מצטברת לשורה אחת. בצילום המסך הבא מוצגות סדרות עיתיות שמקובצות לפי אזור:
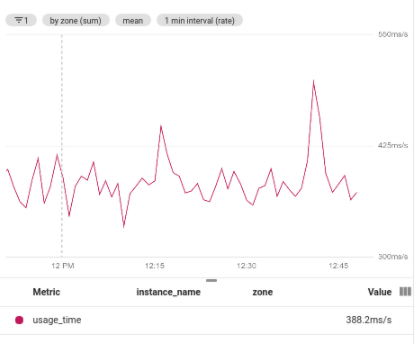
בצילום המסך הבא מוצגת התוצאה של שימוש באגרגציה משנית כדי למצוא את הערך הממוצע בסדרת הזמן המקובצת:
הגדרת השם של עמודת מקרא
בשדה כינוי מקרא אפשר להתאים אישית את התיאור של סדרת הזמן בתרשים. התיאורים האלה מופיעים בתיבת הטיפ של התרשים ובמקרא של התרשים בעמודה שם. כברירת מחדל, התיאורים במקרא נוצרים בשבילכם מהערכים של תוויות שונות בסדרת הזמן. מכיוון שהמערכת בוחרת את התוויות, יכול להיות שהתוצאות לא יהיו שימושיות. כדי ליצור תבנית לתיאורים, משתמשים בשדה הזה.
אפשר להזין טקסט פשוט ותבניות בשדה כינוי מקרא. כשמוסיפים תבנית, מוסיפים ביטוי שמוערך כשהמקרא מוצג.
כדי להוסיף תבנית מקרא לתרשים:
- בחלונית Display, מרחיבים את expand_more Legend Alias.
- לוחצים על add הצגת הצעות למשתני תבנית ובוחרים באפשרות מהתפריט.
לדוגמה, אם בוחרים באפשרות
zone, התבנית${resource.labels.zone}מתווספת.
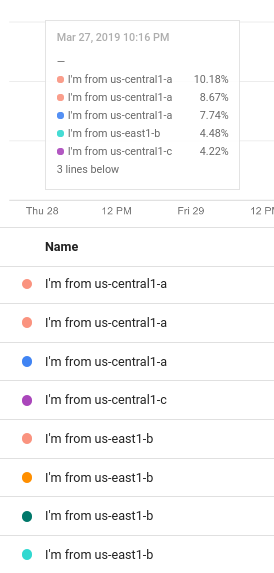
לדוגמה, בצילום המסך הבא מוצגת תבנית מקרא שמכילה טקסט רגיל ואת הביטוי ${resource.labels.zone}:

במקרא של התרשים, הערכים שנוצרו מהתבנית מופיעים בעמודה עם הכותרת שם ובתיאור הכלים:
אפשר להגדיר את תבנית המקרא כך שתכלול כמה מחרוזות טקסט ותבניות, אבל שטח התצוגה הזמין בתיבת הטיפים מוגבל.
המאמרים הבאים
- עיון בנתונים בתרשים
- סקירה כללית של מדדים שהוגדרו על ידי המשתמש
- הגדרת תבנית המקרא
- הגדרת אפשרויות התצוגה של תרשים