
בדף הזה מתוארות הטכניקות שמשמשות לשינוי נתונים של סדרות זמן. התוכן הזה מבוסס על המושגים והדיון במאמר מדדים, סדרות זמנים ומשאבים.
צריך לערוך נתוני סדרות זמן גולמיים לפני שאפשר לנתח אותם, ולרוב הניתוח כולל סינון של חלק מהנתונים וצירוף של חלק מהם. בדף הזה מתוארות שתי טכניקות עיקריות לשיפור נתונים גולמיים:
- סינון, שגורם להסרת חלק מהנתונים.
- צבירה, שמשלבת כמה חלקי נתונים לקבוצה קטנה יותר לפי מאפיינים שאתם מציינים.
סינון וצבירה הם כלים שימושיים שיעזרו לכם לזהות דפוסים מעניינים, להדגיש מגמות או חריגים בנתונים ועוד.
במאמר הזה מוסבר על המושגים שמאחורי סינון וצבירה. הוא לא מסביר איך ליישם אותן ישירות. כדי להחיל סינון או צבירה על נתוני סדרת הזמן, אפשר להשתמש ב-Cloud Monitoring API או בכלי התרשימים וההתראות במסוף Google Cloud . דוגמאות אפשר למצוא במאמרים מדיניות לדוגמה של API ודוגמאות לשפת השאילתות של Monitoring.נתונים גולמיים של פעולות על ציר הזמן
כמות נתוני המדדים הגולמיים בסדרת זמן יחידה יכולה להיות עצומה, ובדרך כלל יש הרבה סדרות זמן שמשויכות לסוג מדד. כדי לנתח את כל מערך הנתונים ולמצוא בו נקודות משותפות, מגמות או חריגות, צריך לעבד את סדרת הזמן במערך. אחרת, יש יותר מדי נתונים לבדיקה.
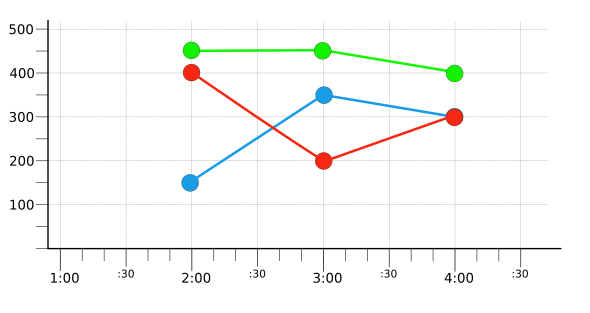
כדי להציג סינון וצבירה, הדוגמאות בדף הזה משתמשות במספר קטן של סדרות זמן היפותטיות. לדוגמה, באיור הבא מוצגים נתונים גולמיים של כמה שעות משלוש סדרות זמן:
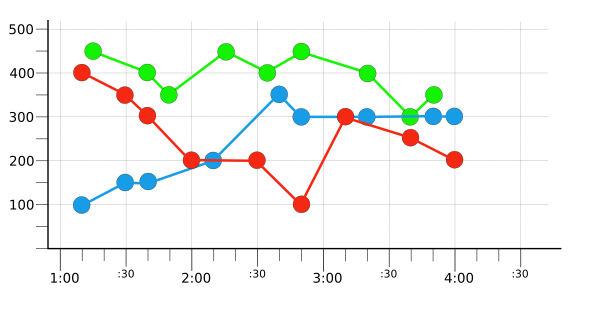
כל סדרת זמן צבועה באדום, בכחול או בירוק, כדי לשקף את הערך של תווית היפותטית color. יש סדרת זמן אחת לכל ערך של התווית. שימו לב שהערכים לא מסודרים בצורה מסודרת, כי הם נרשמו בזמנים שונים.
סינון
אחד הכלים הכי שימושיים לניתוח הוא סינון, שמאפשר לכם להסתיר נתונים שלא מעניינים אתכם באופן מיידי.
אפשר לסנן נתונים של סדרות עיתיות לפי:
- זמן.
- ערך של תווית אחת או יותר.
באיור הבא מוצגת התוצאה של סינון כדי להציג רק את סדרת הזמן האדומה מתוך קבוצת סדרות הזמן המקורית (שמוצגת באיור 1):
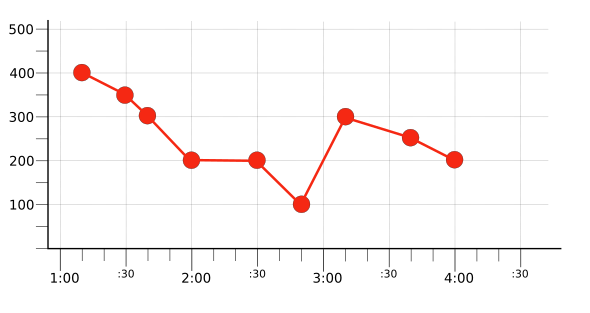
סדרת הזמן הזו, שנבחרה באמצעות סינון, משמשת בקטע הבא להדגמת התאמה.
צבירה
דרך נוספת לצמצם את כמות הנתונים היא ליצור סיכום שלהם, או לצבור אותם. יש שני היבטים לצבירה:
- יישור, או נרמול נתונים בתוך סדרת זמן אחת.
- הפחתה, או שילוב של כמה סדרות זמן.
כדי לצמצם סדרות עיתיות, צריך קודם ליישר אותן. בקטעים הבאים מתואר תהליך ההתאמה והצמצום באמצעות סדרות זמן שמאחסנות ערכים של מספרים שלמים. המושגים הכלליים האלה רלוונטיים גם כשסדרת זמן כוללת סוג ערך של Distribution, אבל במקרה הזה יש כמה מגבלות נוספות. מידע נוסף זמין במאמר בנושא מדדים עם ערכי התפלגות.
התאמה: רגולריזציה בתוך סדרה
השלב הראשון בצבירת נתונים של סדרות זמן הוא יישור. ההתאמה יוצרת סדרת זמן חדשה שבה הנתונים הגולמיים עברו רגולריזציה בזמן, כך שאפשר לשלב אותם עם סדרות זמן אחרות שעברו התאמה. ההתאמה יוצרת סדרות זמן עם נתונים במרווחים קבועים.
תהליך ההתאמה כולל שני שלבים:
חלוקת סדרת הזמנים למרווחי זמן קבועים, שנקראת גם חלוקת הנתונים לקטגוריות. המרווח הזה נקרא תקופה, תקופת התאמה או חלון התאמה.
חישוב ערך יחיד לנקודות בתקופת ההתאמה. אתם בוחרים איך לחשב את הנקודה היחידה הזו. למשל, אפשר לסכום את כל הערכים, לחשב את הממוצע שלהם או להשתמש בערך המקסימלי.
מכיוון שסדרת הזמן החדשה שנוצרת על ידי היישור מייצגת את כל הערכים מסדרת הזמן הגולמית שנמצאים בתקופת היישור באמצעות ערך יחיד, היא נקראת גם צמצום בתוך סדרת הזמן או צבירה בתוך סדרת הזמן.
התאמה של מרווחי זמן
כדי לנתח נתונים של סדרות זמנים, נקודות הנתונים צריכות להיות זמינות במרווחי זמן שווים. התאמה היא התהליך שמאפשר את זה.
ההתאמה יוצרת סדרת זמן חדשה עם מרווח קבוע, תקופת ההתאמה, בין נקודות הנתונים. בדרך כלל מיישרים כמה סדרות עיתיות כדי להכין אותן לעיבוד נוסף.
בקטע הזה מוסברות הפעולות שצריך לבצע כדי ליישר את הנתונים, באמצעות יישום שלהן על סדרת זמן אחת. בדוגמה הזו, תקופת התאמה של שעה אחת מוחלת על סדרת הזמן לדוגמה שמוצגת באיור 2. בסדרת הזמן מוצגים נתונים שנאספו במשך שלוש שעות. אם מחלקים את הנקודות על הגרף לתקופות של שעה, מקבלים את הנקודות הבאות בכל תקופה:
| נקודה | ערכים |
|---|---|
| 1:01–2:00 | 400, 350, 300, 200 |
| 2:01–3:00 | 200, 100 |
| 3:01–4:00 | 300, 250, 200 |
בחירת תקופות יישור
משך תקופת ההתאמה תלוי בשני גורמים:
- רמת הפירוט של מה שאתם מנסים למצוא בנתונים.
- תקופת הדגימה של הנתונים, כלומר באיזו תדירות הם מדווחים.
בקטעים הבאים מוסבר בהרחבה על הגורמים האלה.
בנוסף, Cloud Monitoring שומר נתונים של מדדים לפרק זמן מוגבל. התקופה משתנה בהתאם לסוג המדד. פרטים נוספים זמינים במאמר בנושא שמירת נתונים. תקופת השמירה היא תקופת ההתאמה הארוכה ביותר שיש לה משמעות.
רמת פירוט
אם אתם יודעים שמשהו קרה בטווח של כמה שעות ואתם רוצים לבדוק את זה לעומק, כדאי להשתמש בפרק זמן של שעה או כמה דקות לצורך ההתאמה.
אם אתם רוצים לבדוק מגמות לאורך תקופות ארוכות יותר, כדאי להגדיר תקופת התאמה ארוכה יותר. בדרך כלל, תקופות יישור ארוכות לא מועילות לבדיקת תנאים חריגים לטווח קצר. אם משתמשים, למשל, בתקופת יישור של כמה שבועות, עדיין אפשר לזהות אנומליה בתקופה הזו, אבל יכול להיות שהנתונים המיושרים יהיו גסים מדי ולא יעזרו במיוחד.
תדירות הדגימה
התדירות שבה הנתונים נכתבים, קצב הדגימה, יכולה גם להשפיע על הבחירה של תקופת ההתאמה. ברשימת המדדים אפשר לראות את שיעורי הדגימה של מדדים מובנים. לדוגמה, נסתכל על האיור הבא שמציג סדרת זמן עם קצב דגימה של נקודה אחת לדקה:
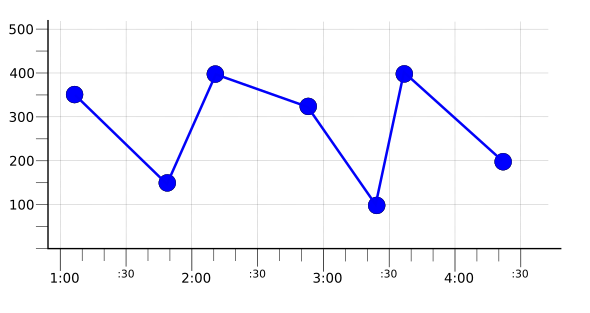
אם תקופת ההתאמה זהה לתקופת הדגימה, אז יש נקודה על הגרף אחת בכל תקופת התאמה. המשמעות היא שאם משתמשים, לדוגמה, באחד מהאמצעים ליישור max, mean או min, מתקבלת אותה סדרת זמן מיושרת. באיור הבא מוצגת התוצאה הזו, לצד סדרת הזמנים המקורית כקו דהוי:
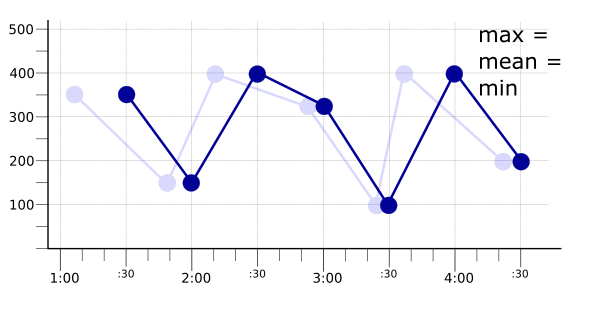
מידע נוסף על אופן הפעולה של פונקציות ההתאמה זמין במאמר בנושא פונקציות התאמה.
אם תקופת ההתאמה מוגדרת לשתי דקות, או כפליים מתקופת הדגימה, אז יש שתי נקודות נתונים בכל תקופה. אם מיישמים את כלי ההזזה max, mean או min על הנקודות במהלך תקופת ההתאמה של שתי הדקות, סדרת הזמן שמתקבלת תהיה שונה. באיור הבא מוצגות התוצאות האלה, יחד עם סדרת הזמנים המקורית כקו דהוי:
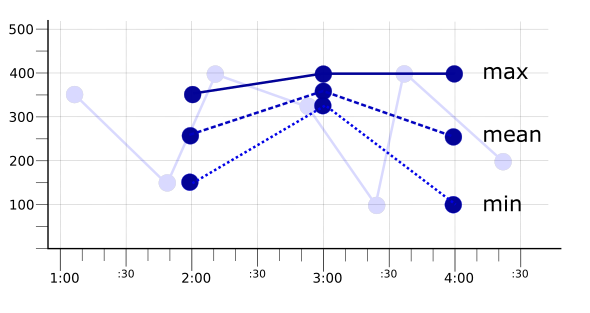
כשבוחרים תקופת התאמה, צריך לוודא שהיא ארוכה יותר מתקופת הדגימה, אבל קצרה מספיק כדי להציג מגמות רלוונטיות. יכול להיות שתצטרכו להתנסות כדי לקבוע תקופת התאמה שימושית. לדוגמה, אם הנתונים נאספים בקצב של נקודה אחת ביום, תקופת התאמה של שעה אחת קצרה מדי כדי להיות שימושית: ברוב השעות לא יהיו נתונים.
מיישרים
אחרי שהנתונים מחולקים לתקופות התאמה, בוחרים פונקציה, את הכלי להתאמה, שתופעל על נקודות הנתונים בתקופה הזו. הכלי להתאמת תאריכים יוצר ערך יחיד שמוצב בסוף כל תקופת התאמה.
אפשרויות ההתאמה כוללות סיכום של הערכים, מציאת הערך המקסימלי, המינימלי או הממוצע של הערכים, מציאת ערך אחוזון נבחר, ספירת הערכים ועוד. Cloud Monitoring API תומך בקבוצה גדולה של פונקציות יישור, הרבה יותר מהקבוצה שמוצגת כאן. הרשימה המלאה מופיעה במאמר Aligner. לתיאור של כלי יישור של שיעורים ודלתא, שמבצעים טרנספורמציה של נתוני סדרות זמן, אפשר לעיין במאמר סוגים, סוגים והמרות.
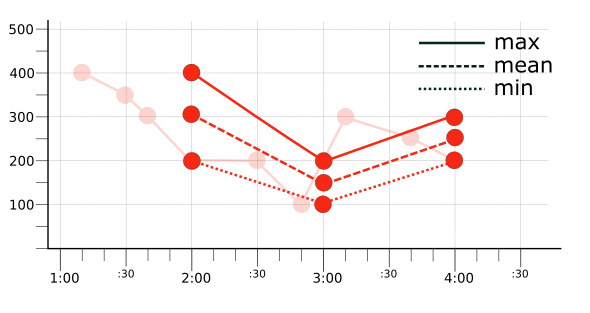
לדוגמה, אם לוקחים את הנתונים שסווגו לקטגוריות מסדרת הזמנים הגולמית (כפי שמוצג באיור 1), בוחרים פונקציית יישור ומחילים אותה על הנתונים בכל קטגוריה. בטבלה הבאה מוצגים הערכים הגולמיים והתוצאות של שלושה כלים שונים להתאמה, max, mean ו-min:
| נקודה | ערכים | Aligner: max | Aligner: mean | Aligner: min |
|---|---|---|---|---|
| 1:01–2:00 | 400, 350, 300, 200 | 400 | 312.5 | 200 |
| 2:01–3:00 | 200, 100 | 200 | 150 | 100 |
| 3:01–4:00 | 300, 250, 200 | 300 | 250 | 200 |
באיור הבא מוצגות התוצאות של החלת הכלי max, mean או min על סדרת הזמן האדומה המקורית (שמיוצגת על ידי הקו המטושטש באיור) באמצעות תקופת התאמה של שעה אחת:
מיישרים אחרים
בטבלה הבאה מוצגים אותם ערכים גולמיים ותוצאות של שלושה אלגוריתמים אחרים ליישור:
- ספירה סופרת את מספר הערכים בתקופת ההשוואה.
- סכום: סכום כל הערכים בתקופת ההתאמה.
- הערך הקודם משתמש בערך העדכני ביותר בתקופה כערך ההתאמה.
| נקודה | ערכים | התאמה: מספר | התאמה: סכום | מיישר: הבא הקודם |
|---|---|---|---|---|
| 1:01–2:00 | 400, 350, 300, 200 | 4 | 1250 | 200 |
| 2:01–3:00 | 200, 100 | 2 | 300 | 100 |
| 3:01–4:00 | 300, 250, 200 | 3 | 750 | 200 |
התוצאות האלה לא מוצגות בתרשים.
צמצום: שילוב של סדרות עיתיות
השלב הבא בתהליך, צמצום, הוא תהליך של שילוב כמה סדרות זמן מיושרות לסדרת זמן חדשה. בשלב הזה, כל הערכים בגבול של תקופת ההתאמה מוחלפים בערך יחיד. הצמצום פועל על פני סדרות זמן נפרדות, ולכן הוא נקרא גם צבירה בין סדרות.
סף הפרשי גובה
פונקציית צמצום היא פונקציה שמוחלת על הערכים בסדרה של נתונים כרונולוגיים כדי ליצור ערך בודד.
אפשרויות לצמצום כוללות סיכום של הערכים המיושרים, או מציאת הערך המקסימלי, המינימלי או הממוצע של הערכים. Cloud Monitoring API תומך בקבוצה גדולה של פונקציות צמצום. הרשימה המלאה מופיעה במאמר Reducer.
רשימת ה-reducers מקבילה לרשימת ה-aligners.
כדי לצמצם סדרות עתיות, צריך ליישר אותן קודם. באיור הבא מוצגות התוצאות של יישור כל שלוש סדרות הזמן הגולמיות (מאיור 1) לתקופות של שעה אחת באמצעות כלי היישור mean:
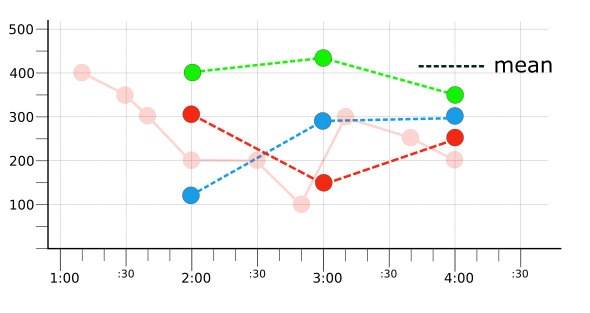
הערכים משלושת סדרות הזמן שמתאימות לממוצע (כפי שמוצג באיור 4) מופיעים בטבלה הבאה:
| גבול היישור | אדום | כחול | ירוק |
|---|---|---|---|
| 2:00 | 312.5 | 133.3 | 400 |
| 3:00 | 150 | 283.3 | 433.3 |
| 4:00 | 250 | 300 | 350 |
בעזרת הנתונים המיושרים בטבלה הקודמת, בוחרים פונקציית צמצום ומחילים אותה על הערכים. בטבלה הבאה מוצגות התוצאות של החלת פונקציות צמצום שונות על הנתונים שמותאמים לממוצע:
| גבול היישור | סף הפרשי גובה: מקסימום | Reducer: mean | סף הפרשי גובה: מינימום | פונקציית צמצום: סכום |
|---|---|---|---|---|
| 2:00 | 400 | 281.9 | 133.3 | 845.8 |
| 3:00 | 433.3 | 288.9 | 150 | 866.7 |
| 4:00 | 350 | 300 | 250 | 900 |
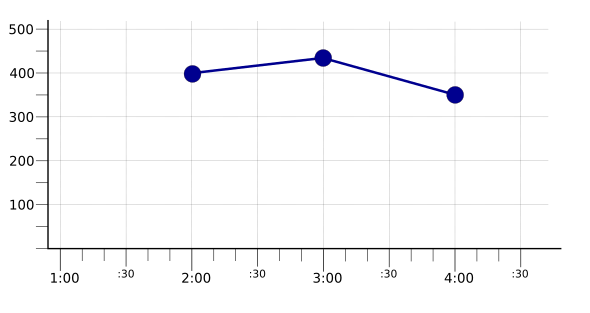
כברירת מחדל, ההפחתה חלה על כל סדרות הזמנים, וכתוצאה מכך נוצרת סדרת זמן אחת. באיור הבא מוצגת התוצאה של צבירת שלוש סדרות הזמן שתואמות לממוצע באמצעות הפונקציה max, שמחזירה את ערכי הממוצע הגבוהים ביותר בסדרות הזמן:
אפשר גם לשלב בין פעולת הצמצום לבין קיבוץ, שבו סדרות הזמן מאורגנות בקטגוריות, ופעולת הצמצום מוחלת על סדרות הזמן בכל קבוצה.
קיבוץ
קיבוץ מאפשר להחיל פונקציית צמצום על קבוצות משנה של סדרות הזמן, ולא על כל סדרות הזמן. כדי לקבץ סדרות זמן, בוחרים תווית אחת או יותר. לאחר מכן, סדרות הזמנים מקובצות על סמך הערכים שלהן עבור התוויות שנבחרו. הקיבוץ יוצר סדרת זמן אחת לכל קבוצה.
אם סוג המדד מתעד ערכים לתוויות zone ו-color, תוכלו לקבץ את סדרות הזמנים לפי אחת מהתוויות או לפי שתיהן. כשמחילים את הפונקציה לצמצום, כל קבוצה מצטמצמת לסדרת זמן אחת. אם מקבצים לפי צבע, מקבלים סדרת זמן אחת לכל צבע שמיוצג בנתונים.
אם מקבצים לפי אזור, מקבלים סדרת זמן לכל אזור שמופיע בנתונים. אם מקבצים לפי שניהם, מקבלים סדרת זמן לכל שילוב של צבעים ואזורים.
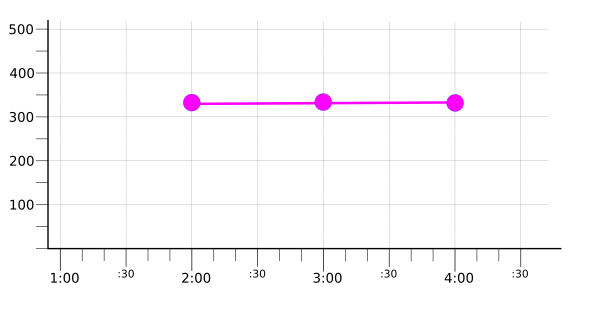
לדוגמה, נניח שתייגתם הרבה סדרות זמן עם הערכים 'אדום', 'כחול' ו'ירוק' עבור התווית color. אחרי שמיישרים את כל סדרות הזמן, אפשר לקבץ אותן לפי ערך color ואז לצמצם אותן לפי קבוצה. התוצאה היא שלוש סדרות עיתיות ספציפיות לצבע:
בדוגמה לא מצוין הכלי ליישור או לצמצום שבו נעשה שימוש. הנקודה כאן היא שקיבוץ מאפשר לצמצם קבוצה גדולה של סדרות זמן לקבוצה קטנה יותר, שבה כל סדרת זמן מייצגת קבוצה שחולקת מאפיין משותף: בדוגמה הזו, הערך של התווית color.
צבירה משנית
Cloud Monitoring מבצע שני שלבי צבירה.
צבירה ראשונית: הנתונים שנמדדו עוברים נרמול, ואז מתבצע שילוב של סדרות הזמן המנורמלות באמצעות פונקציית צמצום. כשמשתמשים באפשרות grouping, יכול להיות שיתקבלו יותר מסדרת זמן אחת כתוצאה מהצמצום שמתבצע כחלק מהשלב הזה.
צבירה משנית, שחלה על התוצאות של שלב הצבירה הראשי, מאפשרת לכם לשלב את סדרות הזמן המקובצות לתוצאה אחת באמצעות פונקציית צמצום שנייה.
בטבלה הבאה מוצגים הערכים של סדרת הזמן המקובצת (כפי שמודגם באיור 6):
| גבול היישור | קבוצה אדומה | קבוצה כחולה | קבוצה ירוקה |
|---|---|---|---|
| 2:00 | 400 | 150 | 450 |
| 3:00 | 200 | 350 | 450 |
| 4:00 | 300 | 300 | 400 |
אפשר לצמצם עוד יותר את שלוש סדרות הזמן שכבר צומצמו באמצעות צבירה משנית. בטבלה הבאה מוצגות התוצאות של החלת פעולות צמצום נבחרות:
| גבול היישור | סף הפרשי גובה: מקסימום | Reducer: mean | סף הפרשי גובה: מינימום | פונקציית צמצום: סכום |
|---|---|---|---|---|
| 2:00 | 450 | 333.3 | 150 | 1000 |
| 3:00 | 450 | 333.3 | 200 | 1000 |
| 4:00 | 400 | 333.3 | 300 | 1000 |
באיור הבא מוצגת התוצאה של צבירת שלוש הסדרות המקובצות באמצעות פונקציית הצמצום mean:
סוגים, סוגים והמרות
כדאי לזכור שנקודות הנתונים בסדרת זמן מאופיינות לפי סוג מדד וסוג ערך. אפשר לעיין במאמר בנושא סוגי ערכים וסוגי מדדים. יכול להיות שההתאמות והצמצומים שמתאימים למערך נתונים אחד לא יתאימו למערך נתונים אחר. לדוגמה, כלי ליישור או לצמצום שסופר את מספר הערכים False מתאים לנתונים בוליאניים, אבל לא לנתונים מספריים. באופן דומה, פעולת יישור או צמצום שמחשבת ממוצע מתאימה לנתונים מספריים אבל לא לנתונים בוליאניים.
אפשר להשתמש בחלק מהכלים ליישור ולצמצום כדי לשנות באופן מפורש את סוג המדד או את סוג הערך של הנתונים בסדרת זמן. חלק מהפעולות, כמו ALIGN_COUNT, עושות זאת כתופעת לוואי.
סוג המדד: מדד מצטבר הוא מדד שבו כל ערך מייצג את הסכום הכולל מאז שהתחיל איסוף הערכים. אי אפשר להשתמש במדדים מצטברים ישירות בתרשימים, אבל אפשר להשתמש במדדי דלתא, שבהם כל ערך מייצג את השינוי מאז המדידה הקודמת.
אפשר גם להמיר מדדים מצטברים ומדדי דלתא למדדי מד. לדוגמה, נניח שיש מדד דלתא שציר הזמן שלו הוא כדלקמן:
(שעת התחלה, שעת סיום] (דקות) ערך (MiB) (0, 2] 8 (2, 5] 6 (6, 9] 9 נניח שבחרתם במיישר של
ALIGN_DELTAובמשך יישור של שלוש דקות. מכיוון שתקופת ההתאמה לא תואמת ל-(שעת ההתחלה, שעת הסיום] של כל דגימה, נוצרת סדרת זמן עם ערכים משוערים. בדוגמה הזו, סדרת הזמן שעברה אינטרפולציה היא:(שעת התחלה, שעת סיום] (דקות) ערך האינטרפולציה (MiB) (0, 1] 4 (1, 2] 4 (2, 3] 2 (3, 4] 2 (4, 5] 2 (5, 6] 0 (6, 7] 3 (7, 8] 3 (8, 9] 3 לאחר מכן, מסכמים את כל הנקודות בפרק הזמן של שלוש דקות כדי ליצור את הערכים המותאמים:
(שעת התחלה, שעת סיום] (דקות) ערך מיושר (MiB) (0, 3] 10 (3, 6] 4 (6, 9] 9 אם בוחרים באפשרות
ALIGN_RATE, התהליך זהה, רק שהערכים המותאמים מחולקים בתקופת ההתאמה. בדוגמה הזו, תקופת היישור היא שלוש דקות, ולכן לסדרת הזמן המיושרת יש את הערכים הבאים:(שעת התחלה, שעת סיום] (דקות) ערך מיושר (MiB / second) (0, 3] 0.056 (3, 6] 0.022 (6, 9] 0.050 כדי ליצור תרשים של מדד מצטבר, צריך להמיר אותו למדד דלתא או למדד קצב. התהליך של מדדים מצטברים דומה לזה שתיארנו קודם. אפשר לחשב סדרת זמן של דלתא מסדרת זמן מצטברת על ידי חישוב ההפרש בין מונחים סמוכים.
Value type: חלק מהפונקציות לשינוי ציר הזמן והפונקציות לצמצום נתונים לא משנות את סוג הערך של נתוני הקלט. לדוגמה, נתוני מספרים שלמים נשארים נתוני מספרים שלמים גם אחרי שינוי ציר הזמן. אמצעים אחרים להתאמה ולהפחתה ממירים נתונים מסוג אחד לסוג אחר, מה שאומר שאפשר לנתח את המידע בדרכים שלא מתאימות לסוג הערך המקורי.
לדוגמה, אפשר להחיל את הפונקציה
REDUCE_COUNTעל נתונים מספריים, בוליאניים, מחרוזות ונתוני התפלגות, אבל התוצאה שהיא יוצרת היא מספר שלם בן 64 ביט שסופר את מספר הערכים בתקופה.REDUCE_COUNTאפשר להחיל רק על מדדים מסוג gauge ו-delta, והוא לא משנה את סוג המדד.
בטבלאות ההפניה של Aligner ושל Reducer מצוין לאילו סוגי נתונים כל אחד מהם מתאים, וגם כל המרה שמתקבלת. לדוגמה, כאן מוצג הערך של ALIGN_DELTA:
