
In dieser Anleitung wird gezeigt, wie Sie zustandsorientierte Anwendungen in GKE von älteren Maschinentypen wie N2 mit angehängten nichtflüchtigen Volumes zu neueren Maschinentypen wie N4 mit angehängten Hyperdisk-Volumes migrieren. Dazu wird Backup for GKE verwendet. Weitere Informationen zu Maschinentypen, die Hyperdisk unterstützen, finden Sie in der Compute Engine-Dokumentation.
Zur Veranschaulichung der Migration werden in dieser Anleitung die Sakila-Datenbank und die World-Datenbank verwendet, um Beispieldatasets bereitzustellen. Sakila ist eine von MySQL bereitgestellte Beispieldatenbank, die einen fiktiven DVD-Verleih darstellt. Die Welt-Datenbank enthält Daten zu Ländern und Städten. Im Tutorial werden zwei verschiedene Datasets in separaten Namespaces verwendet, um eine komplexe Mehrmandantenumgebung zu simulieren.
Diese Anleitung richtet sich an Speicherspezialisten und Speicheradministratoren, die Speicherplatz erstellen und zuweisen sowie Datensicherheit und Datenzugriff verwalten. Weitere Informationen zu gängigen Rollen und Beispielaufgaben, auf die in Google Cloud-Inhalten verwiesen wird, finden Sie unter Häufig verwendete GKE-Nutzerrollen und -Aufgaben.
Bereitstellungsarchitektur
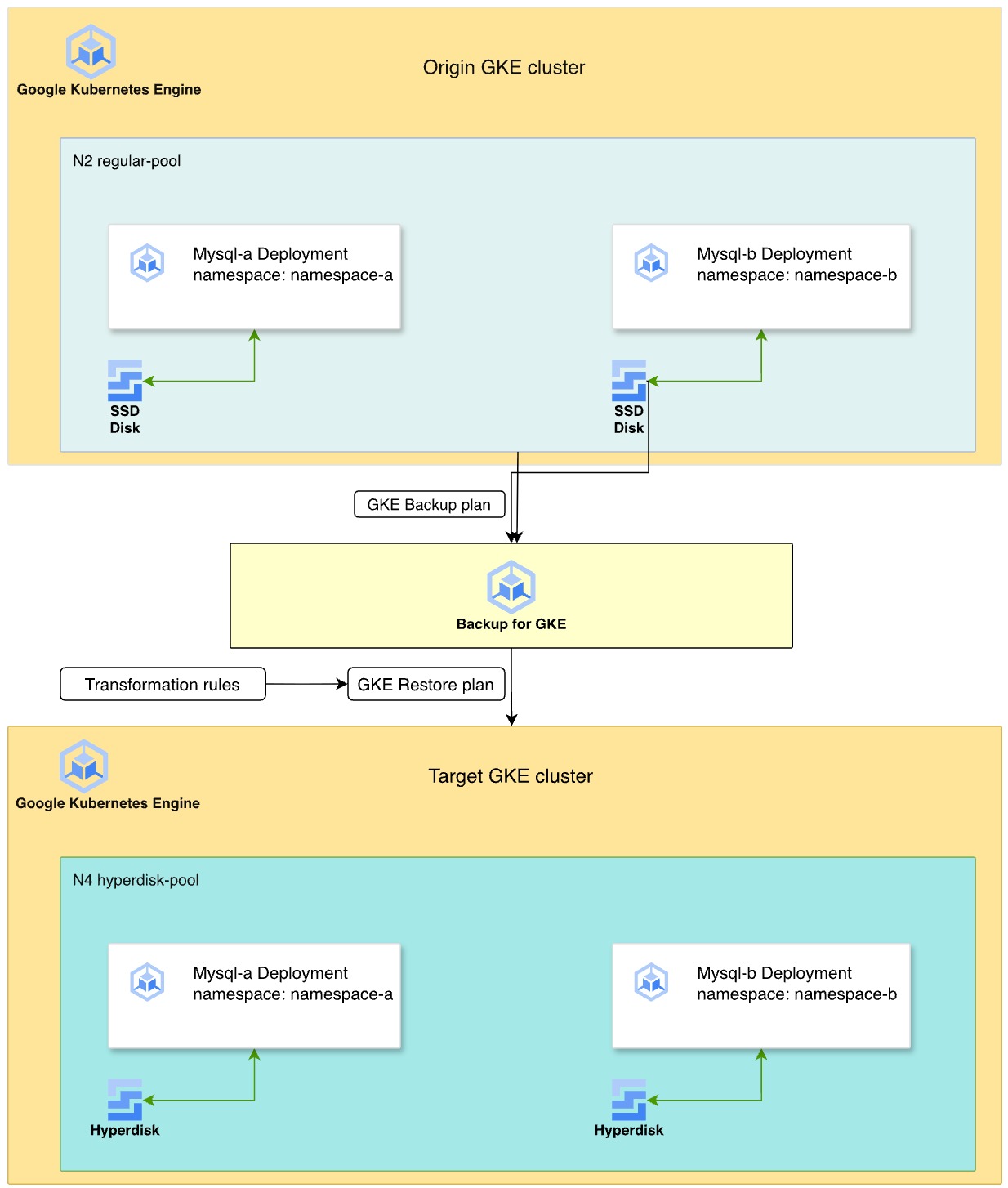
Das folgende Diagramm veranschaulicht den Prozess der Migration zustandsorientierter MySQL-Arbeitslasten von nichtflüchtigem Speicher auf N2-Maschinentypen zu Hyperdisk auf N4-Maschinentypen mit Backup for GKE.
- Quellcluster:Zwei MySQL-Bereitstellungen befinden sich in separaten Namespaces,
namespace-aundnamespace-b, in einem Knotenpool der N2-Maschinenserie. Bei diesen Bereitstellungen wird ein nichtflüchtiger SSD-Speicher für die Datenspeicherung verwendet. - Sicherungsstrategie:Sie aktivieren den Sicherung für GKE-Agenten im Cluster und erstellen einen Sicherungsplan, um die Namespaces, Volumedaten und Secrets zu erfassen. Anschließend führen Sie eine manuelle Sicherung aus, um einen Wiederherstellungspunkt zu einem bestimmten Zeitpunkt zu erstellen.
- Transformation und Wiederherstellung:Sie definieren einen Wiederherstellungsplan mithilfe von Transformationsregeln, um die Ressourcen für die Zielumgebung anzupassen.
Diese Regeln haben folgende Auswirkungen:
- Tauschen Sie
StorageClassvonpremium-rwo(PD) gegen eine Hyperdisk-Speicherklasse mit dem Namenbalanced-storageaus. - Ändern Sie die Pod-Affinitätsregeln, um dafür zu sorgen, dass die wiederhergestellten Arbeitslasten in einem neuen N4-Knotenpool geplant werden.
- Tauschen Sie
- Zielumgebung:Sie stellen einen neuen GKE-Cluster mit N4-Maschinentypen bereit. Beim Wiederherstellungsvorgang werden die Laufwerke aus der Sicherung als Hyperdisk-Volumes neu erstellt und die MySQL-Instanzen auf den kompatiblen N4-Knoten bereitgestellt.
Ziele
In dieser Anleitung erfahren Sie, wie Sie Folgendes tun:
- Statusbehaftete GKE-Anwendungen für die Sicherung vorbereiten.
- Aktivieren Sie das Add-on „Sicherung für GKE.
- Erstellen Sie einen Sicherungsplan und sichern Sie den Quellcluster.
- Erstellen Sie einen Wiederherstellungsplan, in dem Transformationsregeln verwendet werden, um Speicher zu Hyperdisk zu migrieren.
- Stellen Sie die Arbeitslast in einem neuen Cluster wieder her und prüfen Sie die Daten.
Kosten
In diesem Dokument verwenden Sie die folgenden kostenpflichtigen Komponenten von Google Cloud:
- GKE
- Compute Engine (Persistent Disk and Hyperdisk)
- Backup for GKE
Mit dem Preisrechner können Sie eine Kostenschätzung für Ihre voraussichtliche Nutzung vornehmen.
Hinweis
- Melden Sie sich in Ihrem Google Cloud -Konto an. Wenn Sie mit Google Cloudnoch nicht vertraut sind, erstellen Sie ein Konto, um die Leistungsfähigkeit unserer Produkte in der Praxis sehen und bewerten zu können. Neukunden erhalten außerdem ein Guthaben von 300 $, um Arbeitslasten auszuführen, zu testen und bereitzustellen.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Compute Engine, GKE, Backup for GKE, and IAM APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Compute Engine, GKE, Backup for GKE, and IAM APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
Prüfen Sie, ob Sie die folgenden Rollen für das Projekt haben: roles/container.admin, roles/iam.serviceAccountAdmin, roles/compute.admin, roles/gkebackup.admin, roles/monitoring.viewer
Rollen prüfen
-
Rufen Sie in der Google Cloud Console die Seite IAM auf.
IAM aufrufen - Wählen Sie das Projekt aus.
-
Suchen Sie in der Spalte Hauptkonto nach allen Zeilen, in denen Sie oder eine Gruppe, zu der Sie gehören, angegeben sind. Fragen Sie Ihren Administrator, zu welchen Gruppen Sie gehören.
- Prüfen Sie in allen Zeilen, in denen Sie angegeben oder enthalten sind, die Spalte Rolle, um zu sehen, ob die Liste der Rollen die erforderlichen Rollen enthält.
Rollen zuweisen
-
Rufen Sie in der Google Cloud Console die Seite IAM auf.
IAM aufrufen - Wählen Sie das Projekt aus.
- Klicken Sie auf Zugriffsrechte erteilen.
-
Geben Sie im Feld Neue Hauptkonten Ihre Nutzer-ID ein. Das ist in der Regel die E‑Mail-Adresse eines Google-Kontos.
- Klicken Sie auf Rolle auswählen und suchen Sie nach der Rolle.
- Klicken Sie auf Weitere Rolle hinzufügen, wenn Sie weitere Rollen zuweisen möchten.
- Klicken Sie auf Speichern.
-
Cloud Shell einrichten
-
Aktivieren Sie Cloud Shell in der Google Cloud Console.
Eine Cloud Shell-Sitzung wird gestartet und eine Eingabeaufforderung wird angezeigt. Das Initialisieren der Sitzung kann einige Sekunden dauern.
- Legen Sie ein Standardprojekt fest:
gcloud config set project PROJECT_IDErsetzen Sie
PROJECT_IDdurch Ihre Projekt-ID.
Umgebung einrichten
In diesem Abschnitt bereiten Sie die Umgebungsvariablen vor und klonen das Beispiel-Repository.
Legen Sie die Umgebungsvariablen für Ihr Projekt, die Clusternamen und die Zone fest:
export PROJECT_ID=PROJECT_ID export KUBERNETES_CLUSTER_PREFIX=backup-gke-migration export TARGET_CLUSTER_PREFIX=restore-gke-migration export ZONE=us-central1-aErsetzen Sie
PROJECT_IDdurch Ihre Google CloudProjekt-ID.Klonen Sie das Beispielcode-Repository und wechseln Sie in das Verzeichnis:
git clone https://github.com/GoogleCloudPlatform/kubernetes-engine-samples cd kubernetes-engine-samples/databases/backup-migration
GKE-Quellcluster erstellen
Erstellen Sie einen zonalen Cluster mit einem Knotenpool, in dem N2-Maschinentypen und angehängte nichtflüchtige Speicher verwendet werden.
Erstellen Sie den Cluster:
gcloud container clusters create ${KUBERNETES_CLUSTER_PREFIX}-cluster \ --location ${ZONE} \ --node-locations ${ZONE} \ --shielded-secure-boot \ --shielded-integrity-monitoring \ --machine-type "e2-micro" \ --num-nodes "1"Erstellen Sie einen Knotenpool mit
n2-standard-4-Maschinentypen für die Quellarbeitslast:gcloud container node-pools create regular-pool \ --cluster ${KUBERNETES_CLUSTER_PREFIX}-cluster \ --machine-type n2-standard-4 \ --zone ${ZONE} \ --num-nodes 1Aktivieren Sie das Add-on „Sicherung für GKE“ im Quellcluster:
gcloud container clusters update ${KUBERNETES_CLUSTER_PREFIX}-cluster \ --project=${PROJECT_ID} \ --location=${ZONE} \ --update-addons=BackupRestore=ENABLEDRufen Sie Anmeldedaten für den Cluster ab:
gcloud container clusters get-credentials ${KUBERNETES_CLUSTER_PREFIX}-cluster --zone ${ZONE}Prüfen, ob der Sicherung für GKE-Agent aktiviert ist:
gcloud container clusters describe ${KUBERNETES_CLUSTER_PREFIX}-cluster \ --project=${PROJECT_ID} \ --location=${ZONE}Die Ausgabe sieht dann ungefähr so aus und bestätigt, dass der Sicherungsagent aktiviert ist:
addonsConfig: gkeBackupAgentConfig: enabled: true
MySQL mit Beispieldaten bereitstellen
Stellen Sie zwei MySQL-Datenbanken in separaten Namespaces bereit, um eine Produktionsumgebung zu simulieren.
Erstellen Sie die Namespaces
namespace-aundnamespace-b:kubectl create namespace namespace-a kubectl create namespace namespace-bStellen Sie die MySQL-Arbeitslasten in
namespace-aundnamespace-bbereit:Stellen Sie die Datei
mysql-a-deployment.yamlbereit:kubectl apply -f manifests/02-mysql/mysql-a-deployment.yaml -n namespace-aMit dem folgenden Manifest wird ein MySQL-Pod in
namespace-amit dynamisch bereitgestellten Persistent Disk-SSDs auf denregular-pool-Knoten erstellt. Das Root-Passwort ist aufmigrationfestgelegt:Stellen Sie die Datei
mysql-b-deployment.yamlbereit:kubectl apply -f manifests/02-mysql/mysql-b-deployment.yaml -n namespace-bMit dem folgenden Manifest wird ein MySQL-Pod in
namespace-bmit dynamisch bereitgestellten Persistent Disk-SSDs auf denregular-pool-Knoten erstellt. Das Root-Passwort ist aufmigrationfestgelegt:
Stellen Sie einen MySQL-Client-Pod bereit, um Beispieldatasets hochzuladen:
kubectl apply -f manifests/02-mysql/mysql-client.yaml kubectl wait pods mysql-client --for condition=Ready --timeout=300sDas folgende Manifest stellt einen MySQL-Client-Pod bereit:
Stellen Sie eine Verbindung zum Client-Pod her:
kubectl exec -it mysql-client -- bashLaden Sie im Pod die Sakila- und World-Beispieldatasets herunter:
curl --output dataset.tgz "https://downloads.mysql.com/docs/sakila-db.tar.gz" tar -xvzf dataset.tgz -C ./ curl --output world-db.tar.gz "https://downloads.mysql.com/docs/world-db.tar.gz" tar xvzf world-db.tar.gz -C ./Importieren Sie das Sakila-Dataset in die Datenbank
mysql-a:mysql -u root -h mysql-a.namespace-a -p # Enter password: migration SOURCE /sakila-db/sakila-schema.sql; SOURCE /sakila-db/sakila-data.sql;Importierte Sakila-Daten prüfen:
USE sakila; SELECT table_name, table_rows FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA = 'sakila';Beenden Sie MySQL:
exitImportieren Sie das Dataset „World“ in die Datenbank
mysql-b:mysql -u root -h mysql-b.namespace-b -p # Enter password: migration SOURCE /world-db/world.sql;Importierte Weltdaten prüfen:
USE world; SELECT table_name, table_rows FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA = 'world';Die Ausgabe sieht etwa so aus:
+-----------------+------------+ | table_name | table_rows | +-----------------+------------+ | city | 4079 | | country | 239 | | countrylanguage | 984 | +-----------------+------------+Beenden Sie MySQL:
exitBeenden Sie die Client-Pod-Shell:
exit
GKE-Cluster sichern
Sichern Sie den gesamten Cluster, einschließlich Secrets und Volumes.
So erstellen Sie einen Sicherungsplan:
gcloud beta container backup-restore backup-plans create main-plan \ --project=${PROJECT_ID} \ --location=us-central1 \ --cluster=projects/${PROJECT_ID}/locations/${ZONE}/clusters/${KUBERNETES_CLUSTER_PREFIX}-cluster \ --selected-namespaces=namespace-a,namespace-b,default \ --include-secrets \ --include-volume-data \ --target-rpo-minutes=1440 \ --backup-retain-days=7 \ --backup-delete-lock-days=3 \ --locked--selected-namespaces:Sichert bestimmte Namespaces, um Konflikte mit Systemressourcen zu vermeiden.--include-volume-data:Damit werden die Daten des nichtflüchtigen Speichers gesichert.--target-rpo-minutes: Konfiguriert den Sicherungszeitplan basierend auf dem Recovery Point Objective (RPO). Das RPO ist das maximal zulässige Zeitfenster, in dem Daten verloren gehen können. Es bestimmt die Häufigkeit von Back-ups. Bei einem Intervall von1440Minuten (1 Tag) werden Sicherungen täglich ausgeführt.
Sicherung erstellen:
gcloud beta container backup-restore backups create first-backup \ --project=${PROJECT_ID} \ --location=us-central1 \ --backup-plan=main-plan \ --wait-for-completionWarten Sie, bis in der Ausgabe
Backup state: SUCCEEDEDangezeigt wird.Prüfen Sie, ob die Sicherung erstellt wurde:
gcloud beta container backup-restore backups list \ --project=${PROJECT_ID} \ --location=us-central1 \ --backup-plan=main-plan
Wiederherstellung mit Hyperdisk-Transformation
Stellen Sie die Sicherung in einem neuen Cluster wieder her. Bei der Wiederherstellung wird der Speicher von Persistent Disk in Hyperdisk umgewandelt und Arbeitslasten werden auf N4-Knoten verschoben.
Erstellen Sie den GKE-Zielcluster auf einem N4-Knoten:
gcloud container clusters create ${TARGET_CLUSTER_PREFIX}-cluster \ --location ${ZONE} \ --node-locations ${ZONE} \ --shielded-secure-boot \ --shielded-integrity-monitoring \ --machine-type "e2-micro" \ --num-nodes "1"Erstellen Sie einen Knotenpool mit
n4-standard-4-Maschinentypen, die für Hyperdisk erforderlich sind:gcloud container node-pools create hyperdisk-pool \ --cluster ${TARGET_CLUSTER_PREFIX}-cluster \ --machine-type n4-standard-4 \ --zone ${ZONE} \ --num-nodes 1Rufen Sie Anmeldedaten für den Zielcluster ab:
gcloud container clusters get-credentials ${TARGET_CLUSTER_PREFIX}-cluster --zone ${ZONE}Wenden Sie die Hyperdisk
StorageClassmit dem Namenbalanced-storagean:kubectl apply -f manifests/01-storage-class/storage-class-hdb.yamlDas folgende Manifest definiert eine Hyperdisk
StorageClass:Sehen Sie sich die Transformationsregeln in der Datei
manifests/03-transformation-rule/volume.yamlan. In dieser Datei wird definiert, wie Ressourcen während der Wiederherstellung geändert werden:- PVC-Transformation:Ändert
storageClassNameinbalanced-storage(Hyperdisk). - Deployment-Transformation:Aktualisiert die Knotenaffinität, um Pods auf
n4-standard-4-Knoten zu planen.
- PVC-Transformation:Ändert
Erstellen Sie einen Wiederherstellungsplan mit diesen Transformationsregeln:
gcloud beta container backup-restore restore-plans create main-restore \ --project=${PROJECT_ID} \ --location=us-central1 \ --backup-plan=projects/${PROJECT_ID}/locations/us-central1/backupPlans/main-plan \ --cluster=projects/${PROJECT_ID}/locations/${ZONE}/clusters/${TARGET_CLUSTER_PREFIX}-cluster \ --namespaced-resource-restore-mode=merge-replace-on-conflict \ --all-namespaces \ --cluster-resource-conflict-policy=use-existing-version \ --cluster-resource-scope-selected-group-kinds=cluster-resource-scope-all-group-kinds \ --volume-data-restore-policy=restore-volume-data-from-backup \ --transformation-rules-file=manifests/03-transformation-rule/volume.yamlWiederherstellung durchführen:
gcloud beta container backup-restore restores create first-restore \ --project=${PROJECT_ID} \ --location=us-central1 \ --restore-plan=main-restore \ --backup=projects/${PROJECT_ID}/locations/us-central1/backupPlans/main-plan/backups/first-backup
Migration überprüfen
Prüfen Sie, ob die Anwendungen auf dem neuen Cluster ausgeführt werden und die Daten intakt sind.
Prüfen Sie, ob die Pods ausgeführt werden:
kubectl get pods -AStellen Sie eine Verbindung zum MySQL-Client-Pod im neuen Cluster her:
# Verify that the client Pod is running kubectl apply -f manifests/02-mysql/mysql-client.yaml kubectl wait pods mysql-client --for condition=Ready --timeout=300s kubectl exec -it mysql-client -- bashPrüfen Sie die wiederhergestellte Sakila-Datenbank in
namespace-a:mysql -u root -h mysql-a.namespace-a -p # Password: migration USE sakila; SELECT table_name, table_rows FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA = 'sakila';Prüfen Sie die wiederhergestellte World-Datenbank in
namespace-b:mysql -u root -h mysql-b.namespace-b -p # Password: migration USE world; SELECT table_name, table_rows FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA = 'world';
Bereinigen
Damit Ihrem Google Cloud-Konto die in dieser Anleitung verwendeten Ressourcen nicht in Rechnung gestellt werden, löschen Sie entweder das Projekt, das die Ressourcen enthält, oder Sie behalten das Projekt und löschen die einzelnen Ressourcen.
Löschen Sie die GKE-Cluster:
gcloud container clusters delete ${KUBERNETES_CLUSTER_PREFIX}-cluster --location ${ZONE} --quiet gcloud container clusters delete ${TARGET_CLUSTER_PREFIX}-cluster --location ${ZONE} --quietLöschen Sie die Sicherungs- und Wiederherstellungspläne:
# Delete the restore plan gcloud beta container backup-restore restore-plans delete main-restore \ --project=${PROJECT_ID} \ --location=us-central1 \ --quiet # Delete the Backup gcloud beta container backup-restore backups delete first-backup \ --project=${PROJECT_ID} \ --location=us-central1 \ --backup-plan=main-plan \ --quiet # Delete the backup plan gcloud beta container backup-restore backup-plans delete main-plan \ --project=${PROJECT_ID} \ --location=us-central1 \ --quiet
Nächste Schritte
- Weitere Informationen zu Backup for GKE
- Weitere Informationen zu Hyperdisk-Speicherpools