
Auf dieser Seite werden die Messwerte und Dashboards beschrieben, die zum Überwachen der Startlatenz von Google Kubernetes Engine-Arbeitslasten (GKE) und den zugrunde liegenden Clusterknoten verfügbar sind. Sie können die Messwerte verwenden, um die Startlatenz zu verfolgen, Fehler zu beheben und sie zu reduzieren.
Diese Seite richtet sich an Plattformadministratoren und -betreiber, die die Startlatenz ihrer Arbeitslasten überwachen und optimieren müssen. Weitere Informationen zu den häufig verwendeten Rollen, auf die wir uns im Inhalt beziehen Google Cloud , finden Sie unter Häufig verwendete GKE Nutzerrollen und -aufgaben.
Übersicht
Die Startlatenz hat erhebliche Auswirkungen darauf, wie Ihre Anwendung auf Trafficspitzen reagiert, wie schnell sich die Replikate von Unterbrechungen erholen und wie effizient die Betriebskosten Ihrer Cluster und Arbeitslasten sein können. Wenn Sie die Startlatenz Ihrer Arbeitslasten überwachen, können Sie Latenzverschlechterungen erkennen und die Auswirkungen von Arbeitslast- und Infrastrukturupdates auf die Startlatenz verfolgen.
Die Optimierung der Startlatenz von Arbeitslasten bietet folgende Vorteile:
- Die Antwortlatenz Ihres Dienstes für Nutzer wird bei Trafficspitzen reduziert.
- Die überschüssige Bereitstellungskapazität, die zum Abfangen von Nachfragespitzen erforderlich ist, während neue Replikate erstellt werden, wird reduziert.
- Die Leerlaufzeit von Ressourcen, die bereits bereitgestellt wurden und darauf warten, dass die restlichen Ressourcen bei Batchberechnungen gestartet werden, wird reduziert.
Hinweis
Führen Sie die folgenden Aufgaben aus, bevor Sie beginnen:
- Aktivieren Sie die Google Kubernetes Engine API. Google Kubernetes Engine API aktivieren
- Wenn Sie die Google Cloud CLI für diesen Task verwenden möchten,
installieren und dann
initialisieren Sie die
gcloud CLI. Wenn Sie die gcloud CLI bereits installiert haben, rufen Sie die neueste
Version mit dem
gcloud components updateBefehl ab. Ältere gcloud CLI-Versionen unterstützen möglicherweise nicht die Ausführung der Befehle in diesem Dokument.
Aktivieren Sie die Cloud Logging API und die Cloud Monitoring API.
Rollen, die zum Aktivieren von APIs erforderlich sind
Zum Aktivieren von APIs benötigen Sie die IAM-Rolle „Service Usage-Administrator“ (
roles/serviceusage.serviceUsageAdmin), die die Berechtigungserviceusage.services.enableenthält. Informationen zum Zuweisen von Rollen.
Voraussetzungen
Damit Sie Messwerte und Dashboards für die Startlatenz von Arbeitslasten aufrufen können, muss Ihr GKE-Cluster die folgenden Anforderungen erfüllen:
- Sie benötigen GKE-Version 1.31.1-gke.1678000 oder höher.
- Sie müssen die Erfassung von Systemmesswerten konfigurieren.
- Sie müssen die Erfassung von Systemlogs konfigurieren.
- Aktivieren Sie Kube State Metrics mit
der
PODKomponente in Ihren Clustern, um die Pod- und Containermesswerte aufzurufen.
Erforderliche Rollen und Berechtigungen
Bitten Sie Ihren Administrator, Ihnen die folgenden IAM-Rollen zuzuweisen, um die Berechtigungen zu erhalten, die Sie zum Aktivieren der Loggenerierung und zum Zugriff auf Logs und deren Verarbeitung benötigen:
-
GKE-Cluster, -Knoten und -Arbeitslasten ansehen:
Kubernetes Engine-Betrachter (
roles/container.viewer) für Ihr Projekt -
Auf Messwerte zur Startlatenz zugreifen und die Dashboards aufrufen:
Monitoring Viewer (
roles/monitoring.viewer) für Ihr Projekt -
Auf Logs mit Latenzinformationen wie Kubelet-Image-Abrufereignissen zugreifen und sie im Log-Explorer und in Observability Analytics ansehen:
Log-Betrachter (
roles/logging.viewer) für Ihr Projekt
Weitere Informationen zum Zuweisen von Rollen finden Sie unter Zugriff auf Projekte, Ordner und Organisationen verwalten.
Sie können die erforderlichen Berechtigungen auch über benutzerdefinierte Rollen oder andere vordefinierte Rollen erhalten.
Messwerte zur Startlatenz
Messwerte zur Startlatenz sind in den GKE-Systemmesswerten enthalten und werden in Cloud Monitoring im selben Projekt exportiert wie der GKE-Cluster.
Die Cloud Monitoring-Messwertnamen in dieser Tabelle müssen das Präfix kubernetes.io/ haben. Dieses Präfix wurde in den Einträgen der Tabelle weggelassen.
| Messwerttyp (Ebenen der Ressourcenhierarchie) Anzeigename |
|
|---|---|
|
Art, Typ, Einheit
Überwachte Ressourcen |
Beschreibung Labels |
pod/latencies/pod_first_ready
(Projekt)
Latenz der Pod-Bereitschaft |
|
GAUGE, Double, s
k8s_pod |
Die End-to-End-Startlatenz des Pods (von Created bis Ready), einschließlich Image-Abrufen. Alle 60 Sekunden wird eine Stichprobe erstellt. |
node/latencies/startup
(Projekt)
Latenz beim Knotenstart |
|
GAUGE, INT64, s
k8s_node |
Die gesamte Startlatenz des Knotens, von CreationTimestamp der GCE-Instanz bis Kubernetes node ready zum ersten Mal. Alle 60 Sekunden wird eine Stichprobe erstellt.accelerator_family: Eine Klassifizierung von Knoten basierend auf Hardwarebeschleunigern: gpu, tpu, cpu.
kube_control_plane_available: Gibt an, ob die Knotenerstellungsanfrage empfangen wurde, als KCP (kube control plane) verfügbar war.
|
autoscaler/latencies/per_hpa_recommendation_scale_latency_seconds
(Projekt)
Latenz pro HPA-Skalierungsempfehlung |
|
GAUGE, DOUBLE, s
k8s_scale |
Latenz der Skalierungsempfehlung des horizontalen Pod-Autoscalers (HPA) (Zeit zwischen dem Erstellen von Messwerten und dem Anwenden der entsprechenden Skalierungsempfehlung auf den API-Server) für das HPA-Ziel. Alle 60 Sekunden wird eine Stichprobe erstellt. Nach der Stichprobenerstellung sind die Daten bis zu 20 Sekunden lang nicht sichtbar.metric_type: Der Typ der Messwertquelle. Er sollte einer der folgenden Werte sein: "ContainerResource", "External", "Object", "Pods" oder "Resource".
|
Dashboard „Startlatenz“ für Arbeitslasten aufrufen
Das Dashboard Startlatenz für Arbeitslasten ist nur für Deployments verfügbar. Führen Sie die folgenden Schritte in der Google Cloud Console aus, um Messwerte zur Startlatenz für Deployments aufzurufen:
Rufen Sie die Seite Arbeitslasten auf.
Klicken Sie auf den Namen der Arbeitslast, die Sie untersuchen möchten, um die Ansicht Deployment-Details zu öffnen.
Klicken Sie auf den Tab Beobachtbarkeit.
Wählen Sie im Menü auf der linken Seite Startlatenz aus.
Verteilung der Startlatenz von Pods ansehen
Die Startlatenz von Pods bezieht sich auf die gesamte Startlatenz, einschließlich Image-Abrufen. Sie misst die Zeit vom Status Created des Pods bis zum Status Ready. Sie können die Startlatenz von Pods anhand der folgenden beiden Diagramme beurteilen:
Diagramm Verteilung der Pod-Startlatenz: Dieses Diagramm zeigt die Perzentile der Startlatenz von Pods (50., 95. und 99. Perzentil), die anhand der Beobachtungen von Pod-Startereignissen in festen 3-Stunden-Intervallen berechnet werden, z. B. 00:00–03:00 Uhr und 03:00–06:00 Uhr. Sie können dieses Diagramm für die folgenden Zwecke verwenden:
- Grundlegende Pod-Startlatenz verstehen.
- Änderungen der Pod-Startlatenz im Zeitverlauf erkennen.
- Änderungen der Pod-Startlatenz mit aktuellen Ereignissen korrelieren, z. B. Arbeitslast-Deployments oder Cluster Autoscaler-Ereignisse. Sie können die Ereignisse oben im Dashboard in der Liste Anmerkungen auswählen.
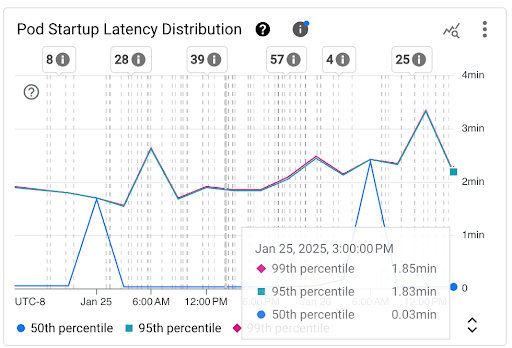
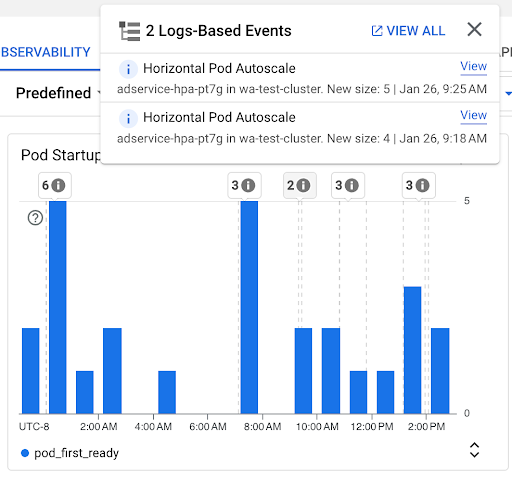
Diagramm Anzahl der Pod-Starts: Dieses Diagramm zeigt die Anzahl der Pods, die in den ausgewählten Zeitintervallen gestartet wurden. Sie können dieses Diagramm für die folgenden Zwecke verwenden:
- Pod-Stichprobengrößen verstehen, die zum Berechnen der Perzentile der Verteilung der Pod-Startlatenz für ein bestimmtes Zeitintervall verwendet werden.
- Ursachen für Pod-Starts verstehen, z. B. Arbeitslast-Deployments oder Ereignisse des horizontalen Pod-Autoscalers. Sie können die Ereignisse oben im Dashboard in der Liste Anmerkungen auswählen.
Startlatenz einzelner Pods ansehen
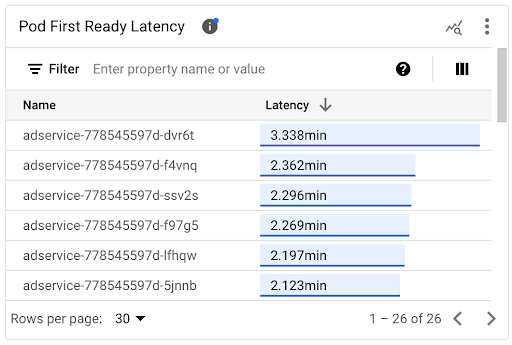
Sie können die Startlatenz einzelner Pods im Zeitachsendiagramm Latenz der Pod-Bereitschaft und in der zugehörigen Liste ansehen.
- Verwenden Sie das Zeitachsendiagramm Latenz der Pod-Bereitschaft , um einzelne Pod-Starts mit aktuellen Ereignissen zu korrelieren, z. B. Ereignissen des horizontalen Pod-Autoscalers oder des Cluster Autoscalers. Sie können diese Ereignisse oben im Dashboard in der Liste Anmerkungen auswählen. Dieses Diagramm hilft Ihnen, potenzielle Ursachen für Änderungen der Startlatenz im Vergleich zu anderen Pods zu ermitteln.
- Verwenden Sie die Liste Latenz der Pod-Bereitschaft , um einzelne Pods zu identifizieren, die am längsten oder kürzesten zum Starten benötigt haben. Sie können die Liste nach der Spalte Latenz sortieren. Wenn Sie Pods mit der höchsten Startlatenz identifizieren, können Sie die Latenzverschlechterung beheben, indem Sie die Pod-Startereignisse mit anderen aktuellen Ereignissen korrelieren.
Sie können herausfinden, wann ein einzelner Pod erstellt wurde, indem Sie sich den Wert im Feld timestamp in einem entsprechenden Pod-Erstellungsereignis ansehen. Führen Sie die folgende Abfrage in
Logs Explorer aus, um das
timestamp Feld zu sehen:
log_id("cloudaudit.googleapis.com/activity") AND
protoPayload.methodName="io.k8s.core.v1.pods.create" AND
resource.labels.project_id=PROJECT_ID AND
resource.labels.cluster_name=CLUSTER_NAME AND
resource.labels.location=CLUSTER_LOCATION AND
protoPayload.response.metadata.namespace=NAMESPACE AND
protoPayload.response.metadata.name=POD_NAME
Verwenden Sie den folgenden Filter
in der vorherigen Abfrage, um alle Pod-Erstellungsereignisse für Ihre Arbeitslast aufzulisten:protoPayload.response.metadata.name=~"POD_NAME_PREFIX-[a-f0-9]{7,10}-[a-z0-9]{5}"
Wenn Sie die Latenzen einzelner Pods vergleichen, können Sie die Auswirkungen verschiedener Konfigurationen auf die Pod-Startlatenz testen und basierend auf Ihren Anforderungen eine optimale Konfiguration ermitteln.
Latenz der Pod-Planung bestimmen
Die Latenz der Pod-Planung ist die Zeit zwischen dem Erstellen eines Pods und dem Planen des Pods auf einem Knoten. Die Latenz der Pod-Planung trägt zur End-to-End-Startzeit eines Pods bei und wird berechnet, indem die Zeitstempel eines Pod-Planungsereignisses und einer Pod-Erstellungsanfrage voneinander subtrahiert werden.
Einen Zeitstempel eines einzelnen Pod-Planungsereignisses finden Sie im Feld jsonPayload.eventTime in einem entsprechenden Pod-Planungsereignis. Führen Sie die folgende Abfrage in
Logs Explorer aus, um das jsonPayload.eventTime Feld zu sehen:
log_id("events")
jsonPayload.reason="Scheduled"
resource.type="k8s_pod"
resource.labels.project_id=PROJECT_ID
resource.labels.location=CLUSTER_LOCATION
resource.labels.cluster_name=CLUSTER_NAME
resource.labels.namespace_name=NAMESPACE
resource.labels.pod_name=POD_NAME
Verwenden Sie den folgenden Filter
in der vorherigen Abfrage:
resource.labels.pod_name=~"POD_NAME_PREFIX-[a-f0-9]{7,10}-[a-z0-9]{5}", um alle Pod-Planungsereignisse für Ihre Arbeitslast aufzulisten:
Latenz beim Abrufen von Images ansehen
Die Latenz beim Abrufen von Container-Images trägt in Szenarien zur Pod-Startlatenz bei, in denen das Image noch nicht auf dem Knoten verfügbar ist oder aktualisiert werden muss. Wenn Sie die Latenz beim Abrufen von Images optimieren, reduzieren Sie die Startlatenz Ihrer Arbeitslast bei Cluster-Scale-out-Ereignissen.
In der Tabelle Kubelet-Image-Abrufereignisse können Sie sehen, wann die Container-Images der Arbeitslast abgerufen wurden und wie lange der Vorgang gedauert hat.
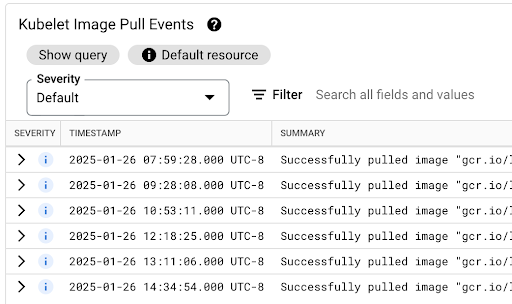
Die Latenz beim Abrufen von Images ist im Feld jsonPayload.message verfügbar, das eine Nachricht wie die folgende enthält:
"Successfully pulled image "gcr.io/example-project/image-name" in 17.093s (33.051s including waiting). Image size: 206980012 bytes."
Verteilung der Latenz von HPA-Skalierungsempfehlungen ansehen
Die Latenz von Skalierungsempfehlungen des horizontalen Pod-Autoscalers (HPA) für das HPA-Ziel ist die Zeit zwischen dem Erstellen der Messwerte und dem Anwenden der entsprechenden Skalierungsempfehlung auf den API-Server. Wenn Sie die Latenz der HPA-Skalierungsempfehlungen optimieren, reduzieren Sie die Startlatenz Ihrer Arbeitslast bei Scale-out-Ereignissen.
Die HPA-Skalierung kann in den folgenden beiden Diagrammen angesehen werden:
Diagramm Verteilung der Latenz von HPA-Skalierungsempfehlungen: Dieses Diagramm zeigt die Perzentile der Latenz von HPA-Skalierungsempfehlungen (50., 95. und 99. Perzentil), die anhand der Beobachtungen von HPA-Skalierungsempfehlungen in den letzten 3-Stunden-Intervallen berechnet werden. Sie können dieses Diagramm für die folgenden Zwecke verwenden:
- Grundlegende Latenz von HPA-Skalierungsempfehlungen verstehen.
- Änderungen der Latenz von HPA-Skalierungsempfehlungen im Zeitverlauf erkennen.
- Änderungen der Latenz von HPA-Skalierungsempfehlungen mit aktuellen Ereignissen korrelieren. Sie können die Ereignisse oben im Dashboard in der Liste Anmerkungen auswählen.
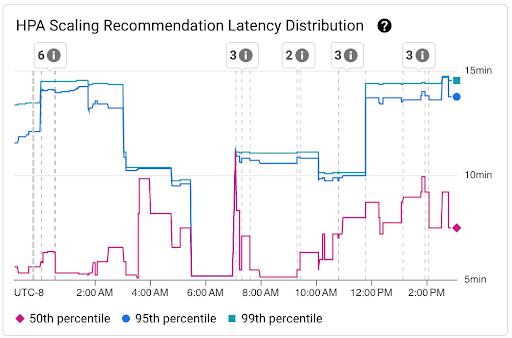
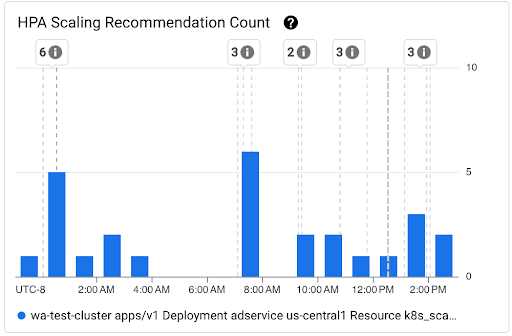
Diagramm Anzahl der HPA-Skalierungsempfehlungen: Dieses Diagramm zeigt die Anzahl der HPA-Skalierungsempfehlungen, die im ausgewählten Zeitintervall beobachtet wurden. Verwenden Sie das Diagramm für die folgenden Aufgaben:
- Stichprobengrößen für HPA-Skalierungsempfehlungen verstehen. Die Stichproben werden verwendet, um die Perzentile in der Verteilung der Latenz für HPA-Skalierungsempfehlungen für ein bestimmtes Zeitintervall zu berechnen.
- HPA-Skalierungsempfehlungen mit Startereignissen neuer Pods und mit Ereignissen des horizontalen Pod-Autoscalers korrelieren. Sie können die Ereignisse oben im Dashboard in der Liste Anmerkungen auswählen.
Planungsprobleme für Pods ansehen
Probleme bei der Pod-Planung können sich auf die End-to-End-Startlatenz Ihrer Arbeitslast auswirken. Um die End-to-End-Startlatenz Ihrer Arbeitslast zu reduzieren, beheben Sie diese Probleme und reduzieren Sie ihre Anzahl.
Die folgenden beiden Diagramme sind verfügbar, um solche Probleme zu verfolgen:
- Das Diagramm Nicht planbare/ausstehende/fehlgeschlagene Pods zeigt die Anzahl der nicht planbaren, ausstehenden und fehlgeschlagenen Pods im Zeitverlauf.
- Das Diagramm Container mit Backoff/Warten/Bereitschaft fehlgeschlagen zeigt die Anzahl der Container in diesen Zuständen im Zeitverlauf.
Dashboard „Startlatenz“ für Knoten aufrufen
Führen Sie die folgenden Schritte in der Google Cloud Console aus, um Messwerte zur Startlatenz für Knoten aufzurufen:
Rufen Sie die Seite Kubernetes-Cluster auf.
Klicken Sie auf den Namen des Clusters, den Sie untersuchen möchten, um die Ansicht Clusterdetails zu öffnen.
Klicken Sie auf den Tab Beobachtbarkeit.
Wählen Sie im Menü auf der linken Seite Startlatenz aus.
Verteilung der Startlatenz von Knoten ansehen
Die Startlatenz eines Knotens bezieht sich auf die gesamte Startlatenz, die die Zeit von CreationTimestamp des Knotens bis zum Status Kubernetes node ready misst. Die Startlatenz von Knoten kann in den folgenden beiden Diagrammen angesehen werden:
Diagramm Verteilung der Latenz beim Knotenstart: Dieses Diagramm zeigt die Perzentile der Latenz beim Knotenstart (50., 95. und 99. Perzentil), die anhand der Beobachtungen von Knotenstartereignissen in festen 3-Stunden-Intervallen berechnet werden, z. B. 00:00–03:00 Uhr und 03:00–06:00 Uhr. Sie können dieses Diagramm für die folgenden Zwecke verwenden:
- Grundlegende Latenz beim Knotenstart verstehen.
- Änderungen der Latenz beim Knotenstart im Zeitverlauf erkennen.
- Änderungen der Latenz beim Knotenstart mit aktuellen Ereignissen korrelieren, z. B. Clusterupdates oder Knotenpoolupdates. Sie können die Ereignisse oben im Dashboard in der Liste Anmerkungen auswählen.

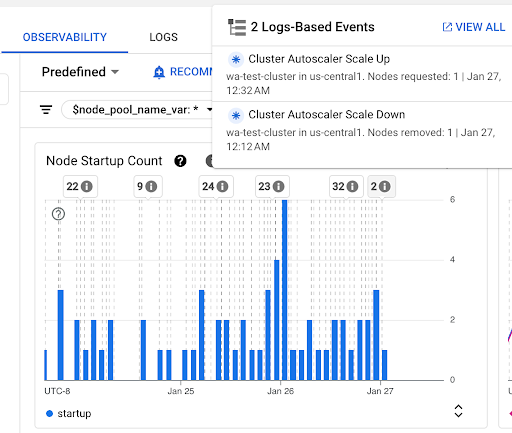
Diagramm Anzahl der Knotenstarts: Dieses Diagramm zeigt die Anzahl der Knoten, die in den ausgewählten Zeitintervallen gestartet wurden. Sie können dieses Diagramm für die folgenden Zwecke verwenden:
- Knotenstichprobengrößen verstehen, die zum Berechnen der Perzentile der Verteilung der Latenz beim Knotenstart für ein bestimmtes Zeitintervall verwendet werden.
- Ursachen für Knotenstarts verstehen, z. B. Knotenpoolupdates oder Cluster Autoscaler-Ereignisse. Sie können die Ereignisse oben im Dashboard in der Liste Anmerkungen auswählen.
Startlatenz einzelner Knoten ansehen
Wenn Sie die Latenzen einzelner Knoten vergleichen, können Sie die Auswirkungen verschiedener Knotenkonfigurationen auf die Latenz beim Knotenstart testen und basierend auf Ihren Anforderungen eine optimale Konfiguration ermitteln. Sie können die Startlatenz einzelner Knoten im Zeitachsendiagramm Latenz beim Knotenstart und in der zugehörigen Liste ansehen.
Verwenden Sie das Zeitachsendiagramm Latenz beim Knotenstart , um einzelne Knotenstarts mit aktuellen Ereignissen zu korrelieren, z. B. Clusterupdates oder Knotenpoolupdates. Sie können potenzielle Ursachen für Änderungen der Startlatenz im Vergleich zu anderen Knoten ermitteln. Sie können die Ereignisse oben im Dashboard in der Liste Anmerkungen auswählen.
Verwenden Sie die Liste Latenz beim Knotenstart , um einzelne Knoten zu identifizieren, die am längsten oder kürzesten zum Starten benötigt haben. Sie können die Liste nach der Spalte Latenz sortieren. Wenn Sie Knoten mit der höchsten Startlatenz identifizieren, können Sie die Latenzverschlechterung beheben, indem Sie Knotenstartereignisse mit anderen aktuellen Ereignissen korrelieren.

Sie können herausfinden, wann ein einzelner Knoten erstellt wurde, indem Sie sich den Wert des Felds protoPayload.metadata.creationTimestamp in einem entsprechenden Knoten-Erstellungsereignis ansehen. Führen Sie die
folgende Abfrage in Logs Explorer aus, um das protoPayload.metadata.creationTimestamp Feld zu sehen:
log_id("cloudaudit.googleapis.com/activity") AND
protoPayload.methodName="io.k8s.core.v1.nodes.create" AND
resource.labels.project_id=PROJECT_ID AND
resource.labels.cluster_name=CLUSTER_NAME AND
resource.labels.location=CLUSTER_LOCATION AND
protoPayload.response.metadata.name=NODE_NAME
Startlatenz in einem Knotenpool ansehen
Wenn Ihre Knotenpools unterschiedliche Konfigurationen haben, z. B. um verschiedene Arbeitslasten auszuführen, müssen Sie die Latenz beim Knotenstart möglicherweise separat nach Knotenpools überwachen. Wenn Sie die Latenzen beim Knotenstart in Ihren Knotenpools vergleichen, erhalten Sie Einblicke in die Auswirkungen der Knotenkonfiguration auf die Latenz beim Knotenstart und können die Latenz entsprechend optimieren.
Standardmäßig zeigt das Dashboard Latenz beim Knotenstart die aggregierte Verteilung der Startlatenz und die einzelnen Latenzen beim Knotenstart für alle Knotenpools in einem Cluster. Wenn Sie die Latenz beim Knotenstart für einen bestimmten Knotenpool aufrufen möchten, wählen Sie den Namen des Knotenpools mit dem Filter $node_pool_name_var oben im Dashboard aus.
Nächste Schritte
- Informationen zum Optimieren des Pod-Autoscalings anhand von Messwerten
- Weitere Informationen zu Möglichkeiten, die Kaltstartlatenz in GKE zu reduzieren.
- Informationen zum Reduzieren der Latenz beim Abrufen von Images mit Image-Streaming
- Informationen zu den überraschenden wirtschaftlichen Vorteilen der Optimierung des horizontalen Pod-Autoscalings.
- Arbeitslasten mit der automatischen Anwendungsüberwachung überwachen