Com os conectores personalizados, é possível integrar fontes de dados externas que não fazem parte da biblioteca de conectores padrão do Gemini Enterprise. Assim, os dados exclusivos da sua organização podem ser pesquisados e acessados usando linguagem natural, com tecnologia do Gemini e da inteligência de pesquisa avançada do Google. O conector personalizado interage diretamente com a API Discovery Engine, que permite recursos robustos de armazenamento, indexação e pesquisa inteligente de dados. O conector converte as informações de origem no formato de documento padronizado baseado em JSON (estruturando o conteúdo, os metadados e as listas de controle de acesso [ACLs]) e garante que esses dados sejam organizados em repositórios de dados. Essas lojas funcionam como repositórios lógicos, representando idealmente um único formato de documento, cada um com seu próprio índice de pesquisa e configurações dedicados.
Como os conectores personalizados funcionam
Os conectores personalizados usam um pipeline de dados automatizado para realizar três ações principais: busca, transformação e sincronização. Esse processo garante que os dados externos sejam preparados e enviados corretamente para o Gemini Enterprise.
Busca: o conector extrai dados, incluindo documentos, metadados e permissões, do sistema externo usando APIs, bancos de dados ou formatos de arquivo.
Transformação: o conector converte dados brutos no formato de documento do Discovery Engine, estrutura o conteúdo e os metadados e atribui um ID globalmente exclusivo a cada documento. Para controles de acesso, você pode usar identidades reconhecidas pelo Google diretamente ou mapeamento de identidade para usuários externos ou grupos personalizados.
Sincronização: o conector faz upload dos documentos para os repositórios de dados do Gemini Enterprise e os mantém atualizados com jobs programados. A sincronização de dados é realizada usando um repositório de dados criado para uma entidade. Para mais informações sobre como criar um armazenamento de dados, consulte Processo de criação de armazenamento de dados. Escolha um modo de sincronização com base nas suas necessidades: Incremental adiciona e atualiza dados, enquanto Completa substitui todo o conjunto de dados.
ACLs e mapeamento de identidade
Para gerenciar o acesso no nível do documento, escolha entre dois métodos: ACLs puras ou mapeamento de identidade, dependendo do formato de identidade usado pelos dados.
ACLs puras (AclInfo): esse método é usado quando a fonte de dados usa identidades baseadas em e-mail reconhecidas por (Google Cloud). Essa abordagem é ideal para definir diretamente quem tem acesso.
Mapeamento de identidade: esse método é usado quando a fonte de dados usa nomes de usuário, IDs legados ou outros sistemas de identidade externos:
Ela estabelece uma associação clara e individual entre grupos de identidade externos (por exemplo, EXT1) e usuários ou grupos internos do provedor de identidade (IDP, na sigla em inglês), por exemplo,
IDPUser1@example.com).Isso permite que o sistema entenda e aplique controles de acesso baseados em grupos do sistema de origem, o que é útil quando uma API retorna rótulos de grupo sem associações completas de usuários ou para dimensionar ACLs de maneira eficiente sem listar milhares de usuários por documento.
O processo de mapeamento de identidade exige a resolução de todas as estruturas de identidade aninhadas ou hierárquicas em uma lista simples de mapeamentos diretos, geralmente em um formato JSON especificado.
Use IDs exclusivos de grupos de identidades externas (por exemplo, EXT1) para identidades externas para manter a integridade do sistema. Para mais informações e exemplos, consulte Mapear identidades externas.
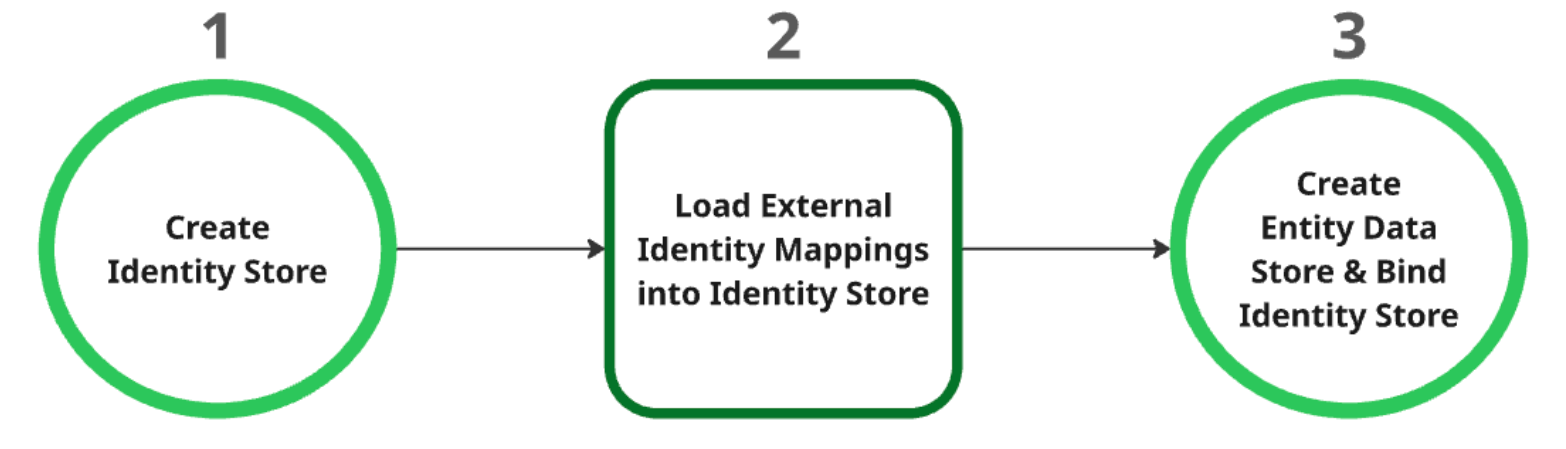
Processo de criação de repositório de dados
Crie o armazenamento de identidades:ele atua como o recurso principal para todos os mapeamentos de identidade. Após a criação, as configurações do provedor de identidade (IDP) no nível do projeto são buscadas automaticamente. Para mais informações, consulte Recuperar ou criar um armazenamento de identidades.
Carregar mapeamentos de identidade externa no repositório de identidades:depois de criar o repositório de identidades, carregue os dados de identidade externa nele. Para mais informações, consulte Ingerir mapeamento de identidade no armazenamento de identidade.
Crie e vincule o repositório de dados de entidade:ele só pode ser criado depois que o repositório de identidades é criado e os mapeamentos de identidade são carregados. É preciso vincular o repositório de identidades ao repositório de dados de entidades durante a criação. Para mais informações sobre como criar um repositório de dados de entidades, consulte Criar repositório de dados.
Sincronização de dados
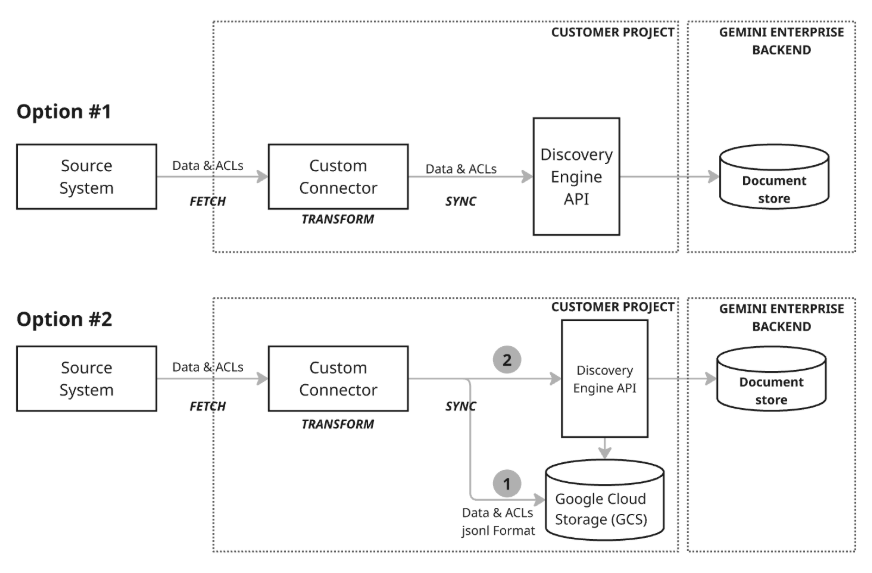
Há dois modelos de arquitetura diferentes para sincronizar dados:
Modelo de arquitetura 1: upsert incremental:a abordagem de upsert incremental é mais adequada para cenários em que os dados estão sendo transmitidos e exigem atualizações em tempo real. O conector usa a API Discovery Engine para realizar upserts incrementais e eficientes (inserção ou atualização de dados) chamando as funções apropriadas com pequenas mudanças à medida que elas ocorrem. Esse foco em tamanhos de mudança e atraso mínimos mantém o armazenamento de documentos altamente atualizado, mesmo com dados que mudam rapidamente.
Modelo de arquitetura 2: sincronização abrangente com o Google Cloud Storage:essa abordagem recomendada oferece um conjunto abrangente de recursos de gerenciamento de dados e alta flexibilidade. Ele oferece suporte a sincronizações completas, que permitem a inserção, atualização e exclusão de dados em todo o conjunto de dados, e sincronizações incrementais, que processam apenas inserções e atualizações enviando mudanças. Isso torna a abordagem robusta para uma ampla variedade de necessidades de dados, principalmente para gerenciar operações de dados maiores ou mais complexas. Esse modelo usa um processo de preparo (etapa 1 no diagrama) em que o conector primeiro grava os dados no Google Cloud Storage (GCS) e, em seguida, aproveita a API Discovery Engine para atualizar o repositório de documentos chamando as funções de importação necessárias do local de preparo do GCS.
Os conectores personalizados são flexíveis o suficiente para oferecer suporte a uma arquitetura híbrida, permitindo implementar upsert incremental para dados que mudam rapidamente e sincronização abrangente para atualizações ou exclusões programadas de dados completos.