커스텀 커넥터를 사용하면 Gemini Enterprise 표준 커넥터 라이브러리에 포함되지 않는 외부 데이터 소스를 통합하여 Gemini 및 Google의 고급 검색 인텔리전스로 구동되는 자연어를 사용하여 조직의 고유한 데이터를 검색하고 액세스할 수 있습니다. 커스텀 커넥터는 Discovery Engine API와 직접 상호작용하여 강력한 데이터 스토리지, 색인 생성, 지능형 검색 기능을 지원합니다. 커넥터는 소스 정보를 표준화된 JSON 기반 문서 형식(콘텐츠, 메타데이터, 액세스 제어 목록(ACL) 구조화)으로 변환하고 이 데이터가 데이터 스토어에 효율적으로 구성되도록 사용 설정합니다. 이러한 스토어는 논리적 저장소 역할을 하며, 이상적으로는 각각 고유한 전용 검색 색인과 구성을 가진 단일 문서 형식을 나타냅니다.
커스텀 커넥터의 작동 방식
커스텀 커넥터는 자동화된 데이터 파이프라인을 사용하여 가져오기, 변환, 동기화라는 세 가지 주요 작업을 실행합니다. 이 프로세스는 외부 데이터가 올바르게 준비되어 Gemini Enterprise에 업로드되도록 보장합니다.
가져오기: 커넥터가 API, 데이터베이스 또는 파일 형식을 사용하여 외부 시스템으로부터 문서, 메타데이터, 권한을 비롯한 데이터를 가져옵니다.
변환: 커넥터는 원시 데이터를 Discovery Engine의 문서 형식으로 변환하고, 콘텐츠와 메타데이터를 구조화하며, 각 문서에 전역 고유 ID를 할당합니다. 액세스 제어의 경우 Google에서 인식하는 ID를 직접 사용하거나 외부 사용자 또는 커스텀 그룹에 대한 ID 매핑을 사용할 수 있습니다.
동기화: 이 커넥터는 문서를 Gemini Enterprise 데이터 스토어에 업로드하고 예약된 작업을 통해 업데이트된 상태로 유지합니다. 데이터 동기화는 항목에 대해 생성된 데이터 스토어를 사용하여 실행됩니다. 데이터 스토어 만들기에 대한 자세한 내용은 데이터 스토어 생성 프로세스를 참조하세요. 필요에 따라 동기화 모드를 선택합니다. 증분은 데이터를 추가하고 업데이트하는 반면 전체는 전체 데이터 세트를 교체합니다.
ACL 및 ID 매핑
문서 수준 액세스를 관리하려면 데이터에서 사용하는 ID 형식에 따라 순수 ACL 또는 ID 매핑 중 한 가지 방법을 선택하세요.
순수 ACL(AclInfo): 이 방법은 데이터 소스가 (Google Cloud)에서 인식하는 이메일 기반 ID를 활용하는 경우 사용됩니다. 이 접근 방식은 액세스 권한을 보유한 사용자를 직접 정의하는 데 적합합니다.
ID 매핑: 이 메서드는 데이터 소스가 사용자 이름, 기존 ID 또는 기타 외부 ID 시스템을 사용하는 경우 사용됩니다. 명확한 일대일 연결을 설정하며, 외부 ID 그룹(예: EXT1)과 내부 ID 공급업체(IDP) 사용자 또는 그룹(예: IDPUser1@example.com) 간에 설정합니다. 이를 통해 시스템은 소스 시스템의 그룹 기반 액세스 제어를 이해하고 적용할 수 있습니다. 이는 API가 전체 사용자 멤버십 없이 그룹 라벨을 반환하는 경우나 문서당 수천 명의 사용자를 나열하지 않고도 ACL을 효율적으로 확장하는 데 유용합니다. 이 프로세스에서는 모든 중첩되거나 계층화된 ID 구조를 직접 매핑의 플랫 목록으로 변환하도록 요구하며, 일반적으로 지정된 JSON 형식으로 수행됩니다. 고유한 외부 ID 그룹 ID를 사용(예: EXT1)하여 시스템 무결성을 유지합니다. 자세한 내용과 예시는 ID 매핑을 참조하세요.
데이터 스토어 생성 프로세스
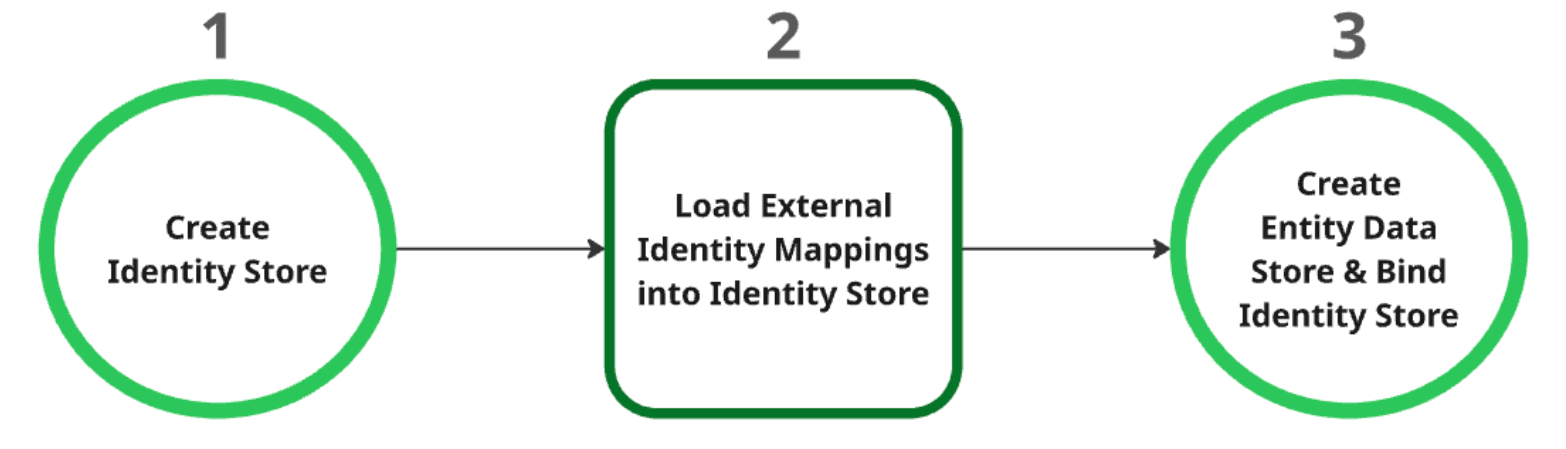
ID 스토어 만들기: 이 저장소는 모든 ID 매핑의 상위 리소스 역할을 합니다. 생성 시 프로젝트 수준 ID 공급업체(IDP) 설정을 자동으로 가져옵니다. 자세한 내용은 ID 스토어 검색 또는 만들기를 참조하세요.
ID 스토어에 외부 ID 매핑 로드: ID 스토어를 만든 후 여기에 외부 ID 데이터를 로드합니다. 자세한 내용은 ID 저장소에 ID 매핑 수집을 참조하세요.
항목 데이터 스토어 생성 및 바인딩: 항목 데이터 스토어는 ID 스토어가 성공적으로 생성되고 ID 매핑이 로드된 후에만 생성할 수 있습니다. ID 스토어를 생성하는 동안 항목 데이터 스토어에 바인딩해야 합니다. 항목 데이터 스토어 만들기에 대한 자세한 내용은 데이터 스토어 만들기를 참조하세요.
데이터 동기화
데이터를 동기화하는 데는 두 가지 아키텍처 모델이 있습니다.
아키텍처 모델 1: 증분 삽입/업데이트(upsert): 삽입/업데이트(upsert) 접근 방식은 데이터가 스트리밍되고 실시간 업데이트가 필요한 시나리오에 가장 적합합니다. 이 커넥터는 Discovery Engine API를 활용하여 약간의 변경이 수행될 때마다 이러한 변경사항으로 적절한 함수를 호출하여 효율적인 증분 삽입/업데이트(upsert)(데이터 삽입 또는 업데이트)를 실행합니다. 최소한의 변경 크기와 최소한의 지연에 초점을 맞추면 데이터가 빠르게 변화하는 상황에서도 문서 스토어를 최신 상태로 유지합니다.
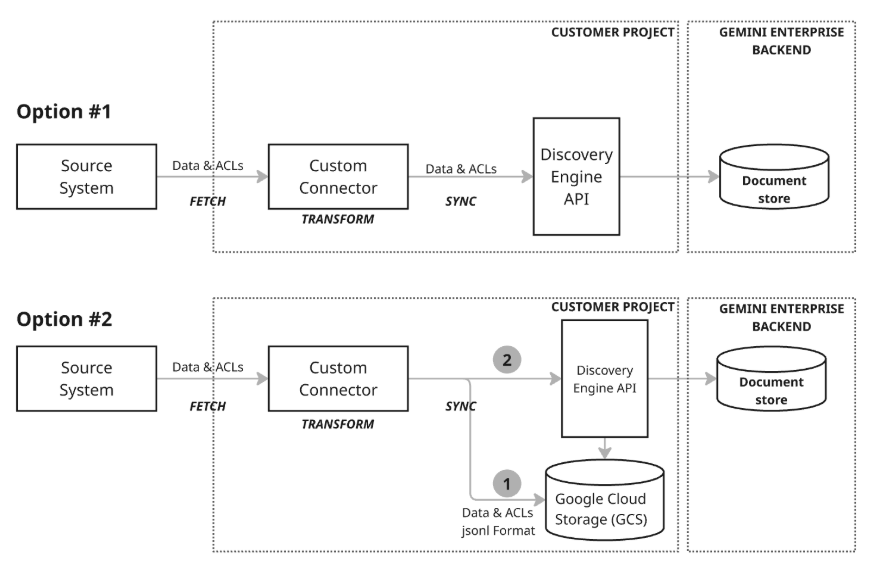
아키텍처 모델 2: Google Cloud Storage와의 포괄적인 동기화: 권장되는 이 접근 방식은 포괄적인 데이터 관리 기능과 높은 유연성을 제공합니다. 전체 동기화를 지원하여 전체 데이터 세트에 대해 데이터 삽입, 업데이트 및 삭제가 가능하며, 증분 동기화를 통해 변경사항만 전송하여 삽입 및 업데이트만 처리합니다. 따라서 이 접근 방식은 다양한 데이터 요구사항, 특히 대규모 또는 복잡한 데이터 작업을 관리하는 데 유용합니다. 이 모델은 커넥터가 먼저 Google Cloud 스토리지(GCS)에 데이터를 쓴 다음 스테이징된 GCS 위치에서 필요한 가져오기 함수를 호출하여 Discovery Engine API를 활용해 문서 스토어를 업데이트하는 스테이징 프로세스(다이어그램의 1단계)를 사용합니다.
커스텀 커넥터는 하이브리드 아키텍처를 지원할 수 있을 만큼 유연하므로 빠르게 변화하는 데이터의 증분 삽입/업데이트(upsert)와 예약된 전체 데이터 업데이트 또는 삭제를 위한 포괄적인 동기화를 구현할 수 있습니다.