
במדריך הזה נסביר איך להריץ מסקנות של למידה עמוקה בעומסי עבודה גדולים באמצעות מעבדי GPU של NVIDIA TensorRT5 שפועלים ב-Compute Engine.
לפני שמתחילים, הנה כמה דברים חשובים שכדאי לדעת:
- הסקת מסקנות בלמידה עמוקה היא השלב בתהליך של למידת מכונה שבו נעשה שימוש במודל שעבר אימון כדי לזהות, לעבד ולסווג תוצאות.
- NVIDIA TensorRT היא פלטפורמה שעברה אופטימיזציה להרצת עומסי עבודה של למידה עמוקה.
- מעבדים גרפיים משמשים להאצת עומסי עבודה עתירי נתונים, כמו למידת מכונה ועיבוד נתונים. מגוון של GPUs של NVIDIA זמינים ב-Compute Engine. במדריך הזה נעשה שימוש ב-GPU מסוג T4, כי הוא מיועד במיוחד לעומסי עבודה (workloads) של הסקת מסקנות בלמידה עמוקה.
מטרות
במדריך הזה נסביר איך:
- הכנת מודל באמצעות גרף שעבר אימון מראש.
- בדיקת מהירות ההסקה של מודל במצבי אופטימיזציה שונים.
- המרת מודל בהתאמה אישית ל-TensorRT.
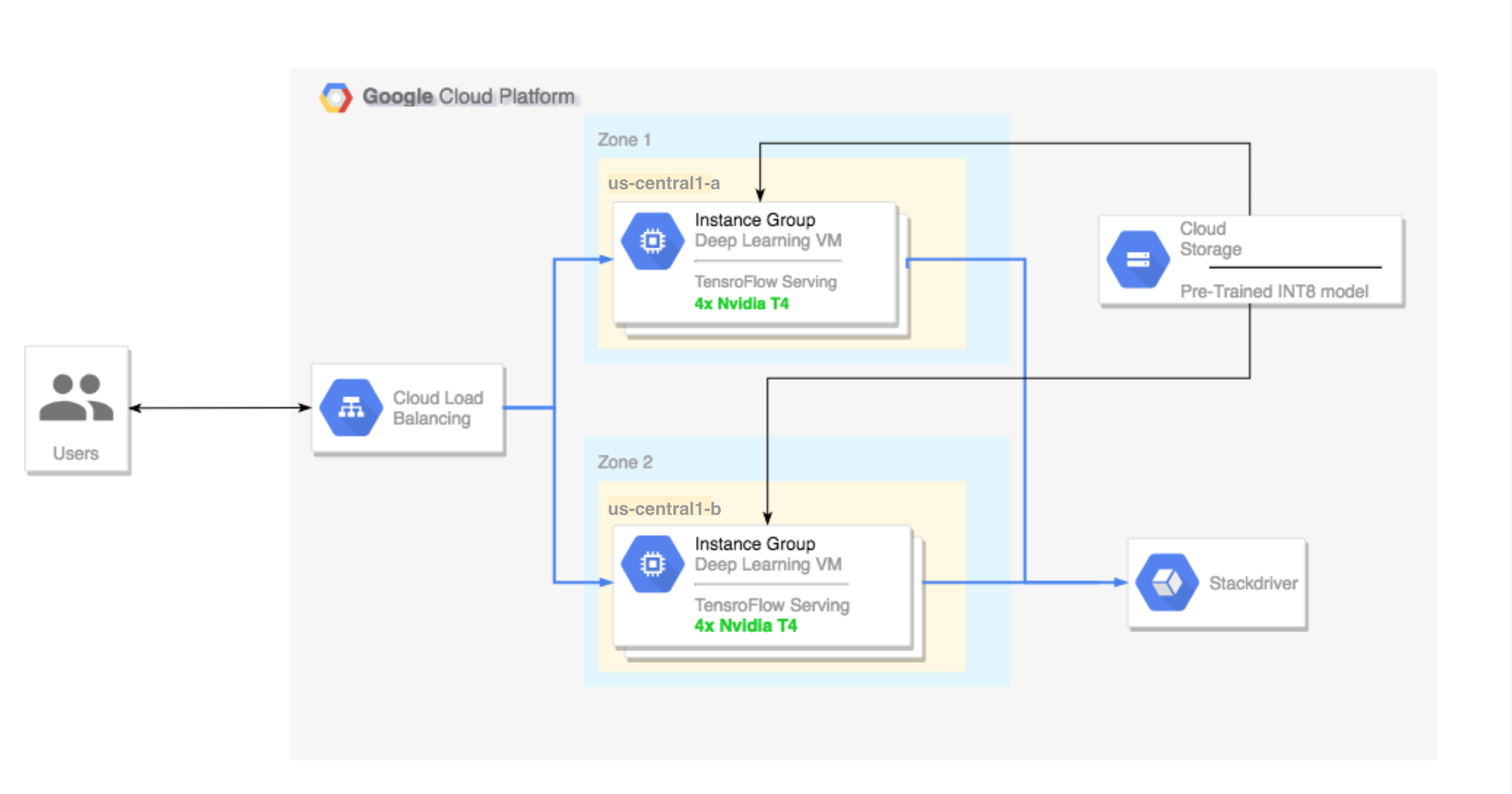
- הגדרת אשכול מרובה אזורים. האשכול הרב-אזורי הזה מוגדר באופן הבא:
- מבוסס על תמונות VM של למידה עמוקה (Deep Learning). התמונות האלה מותקנות מראש עם TensorFlow, TensorFlow Serving ו-TensorRT5.
- התאמה אוטומטית לעומס מופעלת. התאמה אוטומטית לעומס במדריך הזה מבוססת על ניצול ה-GPU.
- איזון העומסים מופעל.
- חומת האש מופעלת.
- הפעלת עומס עבודה של הסקה באשכול מרובה אזורים.
עלויות
העלות של ההפעלה של המדריך הזה משתנה בהתאם לקטע.
אפשר להשתמש במחשבון התמחור כדי לחשב את העלות.
כדי להעריך את העלות של הכנת המודל ובדיקת מהירויות ההסקה במהירויות אופטימיזציה שונות, אפשר להשתמש במפרטים הבאים:
- מכונה וירטואלית אחת:
n1-standard-8(מעבדים וירטואליים: 8, RAM: 30GB) - 1 NVIDIA T4 GPU
כדי לחשב את העלות המשוערת של הגדרת אשכול רב-אזורי, אפשר להשתמש במפרטים הבאים:
- 2 מכונות וירטואליות:
n1-standard-16(vCPU: 16, RAM: 60GB) - 4 GPU NVIDIA T4 לכל מכונה וירטואלית
- 100GB SSD לכל מכונת VM
- כלל העברה אחד
לפני שמתחילים
הגדרת הפרויקט
- נכנסים לחשבון Google Cloud . אם אתם משתמשים חדשים ב- Google Cloud, צרו חשבון כדי שתוכלו להעריך את הביצועים של המוצרים שלנו בתרחישים מהעולם האמיתי. לקוחות חדשים מקבלים בחינם גם קרדיט בשווי 300$ להרצה, לבדיקה ולפריסה של עומסי העבודה.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Compute Engine and Cloud Machine Learning APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Compute Engine and Cloud Machine Learning APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
הגדרת כלים
כדי להשתמש ב-Google Cloud CLI במדריך הזה:
- מתקינים או מעדכנים את הגרסה האחרונה של Google Cloud CLI.
- (אופציונלי) מגדירים אזור ותחום ברירת מחדל.
הכנת המודל
בקטע הזה מוסבר איך ליצור מכונה וירטואלית (VM) שמשמשת להרצת המודל. בקטע הזה מוסבר גם איך להוריד מודל מקטלוג המודלים הרשמיים של TensorFlow.
יוצרים את המכונה הווירטואלית. המדריך הזה נוצר באמצעות
tf-ent-2-10-cu113. במסמכי Deep Learning VM Images אפשר לקרוא על בחירת מערכת הפעלה כדי לראות את הגרסאות העדכניות של התמונות.export IMAGE_FAMILY="tf-ent-2-10-cu113" export ZONE="us-central1-b" export INSTANCE_NAME="model-prep" gcloud compute instances create $INSTANCE_NAME \ --zone=$ZONE \ --image-family=$IMAGE_FAMILY \ --machine-type=n1-standard-8 \ --image-project=deeplearning-platform-release \ --maintenance-policy=TERMINATE \ --accelerator="type=nvidia-tesla-t4,count=1" \ --metadata="install-nvidia-driver=True"
בוחרים מודל. במדריך הזה נעשה שימוש במודל ResNet. מודל ResNet הזה מאומן על מערך הנתונים ImageNet שנמצא ב-TensorFlow.
כדי להוריד את מודל ResNet למכונת ה-VM, מריצים את הפקודה הבאה:
wget -q http://download.tensorflow.org/models/official/resnetv2_imagenet_frozen_graph.pb
שומרים את המיקום של מודל ResNet במשתנה
$WORKDIR. מחליפים אתMODEL_LOCATIONבספריית העבודה שמכילה את המודל שהורדתם.export WORKDIR=MODEL_LOCATION
הרצת בדיקת מהירות ההסקה
בקטע הזה מוסבר איך לבצע את הפעולות הבאות:
- הגדרת מודל ResNet.
- הפעלת בדיקות הסקה במצבי אופטימיזציה שונים.
- בודקים את התוצאות של בדיקות ההסקה.
סקירה כללית של תהליך הבדיקה
TensorRT יכול לשפר את מהירות הביצועים של עומסי עבודה של הסקה, אבל השיפור המשמעותי ביותר מגיע מתהליך הכימות.
קוונטיזציה של מודל היא תהליך שבו מפחיתים את הדיוק של המשקלים של מודל. לדוגמה, אם המשקל הראשוני של מודל הוא FP32, אפשר להקטין את הדיוק ל-FP16, INT8 או אפילו INT4. חשוב לבחור את הפשרה הנכונה בין מהירות (דיוק המשקלים) לבין דיוק המודל. למזלנו, TensorFlow כולל פונקציונליות שעושה בדיוק את זה – מדידת הדיוק לעומת המהירות, או מדדים אחרים כמו קצב העברת נתונים, זמן אחזור, שיעורי המרה של צמתים וזמן האימון הכולל.
התהליך
מגדירים את מודל ResNet. כדי להגדיר את המודל, מריצים את הפקודות הבאות:
git clone https://github.com/tensorflow/models.git cd models git checkout f0e10716160cd048618ccdd4b6e18336223a172f touch research/__init__.py touch research/tensorrt/__init__.py cp research/tensorrt/labellist.json . cp research/tensorrt/image.jpg ..
מריצים את הבדיקה. השלמת הפקודה הזו תימשך זמן מה.
python -m research.tensorrt.tensorrt \ --frozen_graph=$WORKDIR/resnetv2_imagenet_frozen_graph.pb \ --image_file=$WORKDIR/image.jpg \ --native --fp32 --fp16 --int8 \ --output_dir=$WORKDIR
כאשר:
-
$WORKDIRהיא הספרייה שבה הורדתם את מודל ResNet. - הארגומנטים של
--nativeהם מצבי הכמת שרוצים לבדוק.
-
מעיינים בתוצאות. בסיום הבדיקה, אפשר להשוות בין תוצאות ההסקה של כל מצב אופטימיזציה.
Predictions: Precision: native [u'seashore, coast, seacoast, sea-coast', u'promontory, headland, head, foreland', u'breakwater, groin, groyne, mole, bulwark, seawall, jetty', u'lakeside, lakeshore', u'grey whale, gray whale, devilfish, Eschrichtius gibbosus, Eschrichtius robustus'] Precision: FP32 [u'seashore, coast, seacoast, sea-coast', u'promontory, headland, head, foreland', u'breakwater, groin, groyne, mole, bulwark, seawall, jetty', u'lakeside, lakeshore', u'sandbar, sand bar'] Precision: FP16 [u'seashore, coast, seacoast, sea-coast', u'promontory, headland, head, foreland', u'breakwater, groin, groyne, mole, bulwark, seawall, jetty', u'lakeside, lakeshore', u'sandbar, sand bar'] Precision: INT8 [u'seashore, coast, seacoast, sea-coast', u'promontory, headland, head, foreland', u'breakwater, groin, groyne, mole, bulwark, seawall, jetty', u'grey whale, gray whale, devilfish, Eschrichtius gibbosus, Eschrichtius robustus', u'lakeside, lakeshore']
כדי לראות את כל התוצאות, מריצים את הפקודה הבאה:
cat $WORKDIR/log.txt
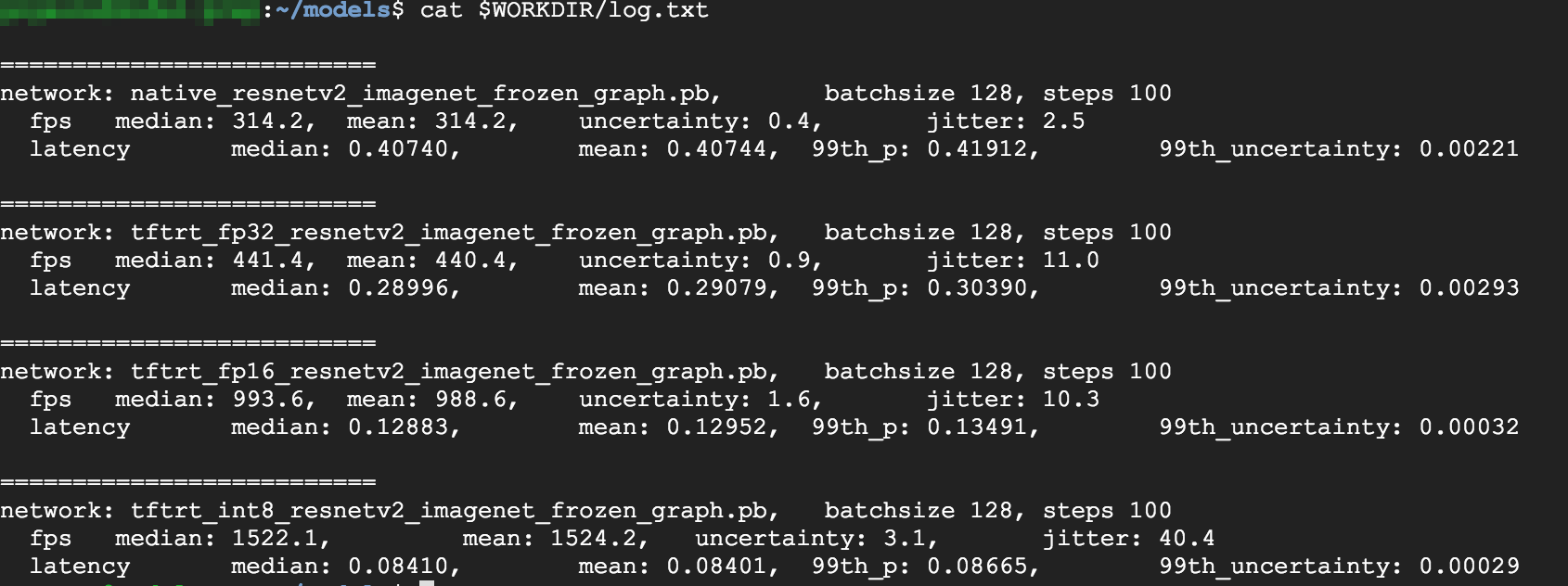
מהתוצאות אפשר לראות שהערכים של FP32 ו-FP16 זהים. המשמעות היא שאם אתם מכירים את TensorRT, אתם יכולים להתחיל להשתמש ב-FP16 באופן מיידי. INT8, מציג תוצאות קצת פחות טובות.
בנוסף, אפשר לראות שהרצת המודל עם TensorRT5 מציגה את התוצאות הבאות:
- שימוש באופטימיזציה של FP32 משפר את קצב העברת הנתונים ב-40% מ-314 פריימים לשנייה ל-440 פריימים לשנייה. במקביל, זמן האחזור יורד בכ-30%, מ-0.40 אלפיות השנייה ל-0.28 אלפיות השנייה.
- שימוש באופטימיזציה של FP16, במקום בתרשים TensorFlow מקורי, מגדיל את המהירות ב-214% מ-314 ל-988 פריימים לשנייה. במקביל, זמן האחזור יורד ב-0.12 אלפיות השנייה, כמעט פי 3.
- באמצעות INT8, אפשר לראות עלייה של 385% במהירות, מ-314 פריימים לשנייה ל-1,524 פריימים לשנייה, והשהיה שקטנה ל-0.08 אלפיות השנייה.
המרת מודל בהתאמה אישית ל-TensorRT
להמרה הזו, אפשר להשתמש במודל INT8.
מורידים את המודל. כדי להמיר מודל בהתאמה אישית לתרשים TensorRT, צריך מודל שמור. כדי לקבל מודל INT8 ResNet שמור, מריצים את הפקודה הבאה:
wget http://download.tensorflow.org/models/official/20181001_resnet/savedmodels/resnet_v2_fp32_savedmodel_NCHW.tar.gz tar -xzvf resnet_v2_fp32_savedmodel_NCHW.tar.gz
ממירים את המודל לתרשים TensorRT באמצעות TFTools. כדי להמיר את המודל באמצעות TFTools, מריצים את הפקודה הבאה:
git clone https://github.com/GoogleCloudPlatform/ml-on-gcp.git cd ml-on-gcp/dlvm/tools python ./convert_to_rt.py \ --input_model_dir=$WORKDIR/resnet_v2_fp32_savedmodel_NCHW/1538687196 \ --output_model_dir=$WORKDIR/resnet_v2_int8_NCHW/00001 \ --batch_size=128 \ --precision_mode="INT8"
עכשיו יש מודל INT8 בספרייה
$WORKDIR/resnet_v2_int8_NCHW/00001.כדי לוודא שהכול מוגדר כמו שצריך, כדאי להריץ בדיקת הסקה.
tensorflow_model_server --model_base_path=$WORKDIR/resnet_v2_int8_NCHW/ --rest_api_port=8888
מעלים את המודל ל-Cloud Storage. השלב הזה נחוץ כדי שאפשר יהיה להשתמש במודל מהאשכול מרובה האזורים שמוגדר בקטע הבא. כדי להעלות את המודל, מבצעים את השלבים הבאים:
מעבירים את המודל לארכיון.
tar -zcvf model.tar.gz ./resnet_v2_int8_NCHW/
מעלים את הארכיון. מחליפים את
GCS_PATHבנתיב לקטגוריה שלכם ב-Cloud Storage.export GCS_PATH=GCS_PATH gcloud storage cp model.tar.gz $GCS_PATH
אם צריך, אפשר לקבל גרף קפוא של INT8 מ-Cloud Storage בכתובת ה-URL הזו:
gs://cloud-samples-data/dlvm/t4/model.tar.gz
הגדרת אשכול מרובה אזורים
בקטע הזה מוסבר על השלבים שצריך לבצע כשמגדירים אשכול מרובה אזורים.
יצירת האשכול
עכשיו שיש לכם מודל בפלטפורמת Cloud Storage, אתם יכולים ליצור אשכול.
יוצרים תבנית של הגדרות מכונה. תבנית של הגדרות מכונה היא משאב שימושי ליצירת מכונות חדשות. תבניות מכונה מחליפים את
YOUR_PROJECT_NAMEבמזהה הפרויקט.export INSTANCE_TEMPLATE_NAME="tf-inference-template" export IMAGE_FAMILY="tf-ent-2-10-cu113" export PROJECT_NAME=YOUR_PROJECT_NAME gcloud beta compute --project=$PROJECT_NAME instance-templates create $INSTANCE_TEMPLATE_NAME \ --machine-type=n1-standard-16 \ --maintenance-policy=TERMINATE \ --accelerator=type=nvidia-tesla-t4,count=4 \ --min-cpu-platform=Intel\ Skylake \ --tags=http-server,https-server \ --image-family=$IMAGE_FAMILY \ --image-project=deeplearning-platform-release \ --boot-disk-size=100GB \ --boot-disk-type=pd-ssd \ --boot-disk-device-name=$INSTANCE_TEMPLATE_NAME \ --metadata startup-script-url=gs://cloud-samples-data/dlvm/t4/start_agent_and_inf_server_4.sh- תבנית של הגדרות מכונה זו כוללת סקריפט לטעינה בזמן ההפעלה שמוגדר על ידי פרמטר המטא-נתונים.
- הסקריפט הזה לטעינה בזמן ההפעלה יופעל במהלך יצירת המכונה בכל מכונה שמשתמשת בתבנית הזו.
- סקריפט לטעינה בזמן ההפעלה הזה מבצע את הפעולות הבאות:
- התקנת סוכן מעקב שמבצע מעקב אחרי השימוש ב-GPU במופע.
- הורדת המודל.
- מפעיל את שירות ההסקה.
- בסקריפט לטעינה בזמן ההפעלה,
tf_serve.pyמכיל את הלוגיקה של ההסקה. הדוגמה הזו כוללת קובץ פייתון קטן מאוד שמבוסס על חבילת TFServe - כדי לראות את הסקריפט לטעינה בזמן ההפעלה, אפשר לעיין ב-startup_inf_script.sh.
- תבנית של הגדרות מכונה זו כוללת סקריפט לטעינה בזמן ההפעלה שמוגדר על ידי פרמטר המטא-נתונים.
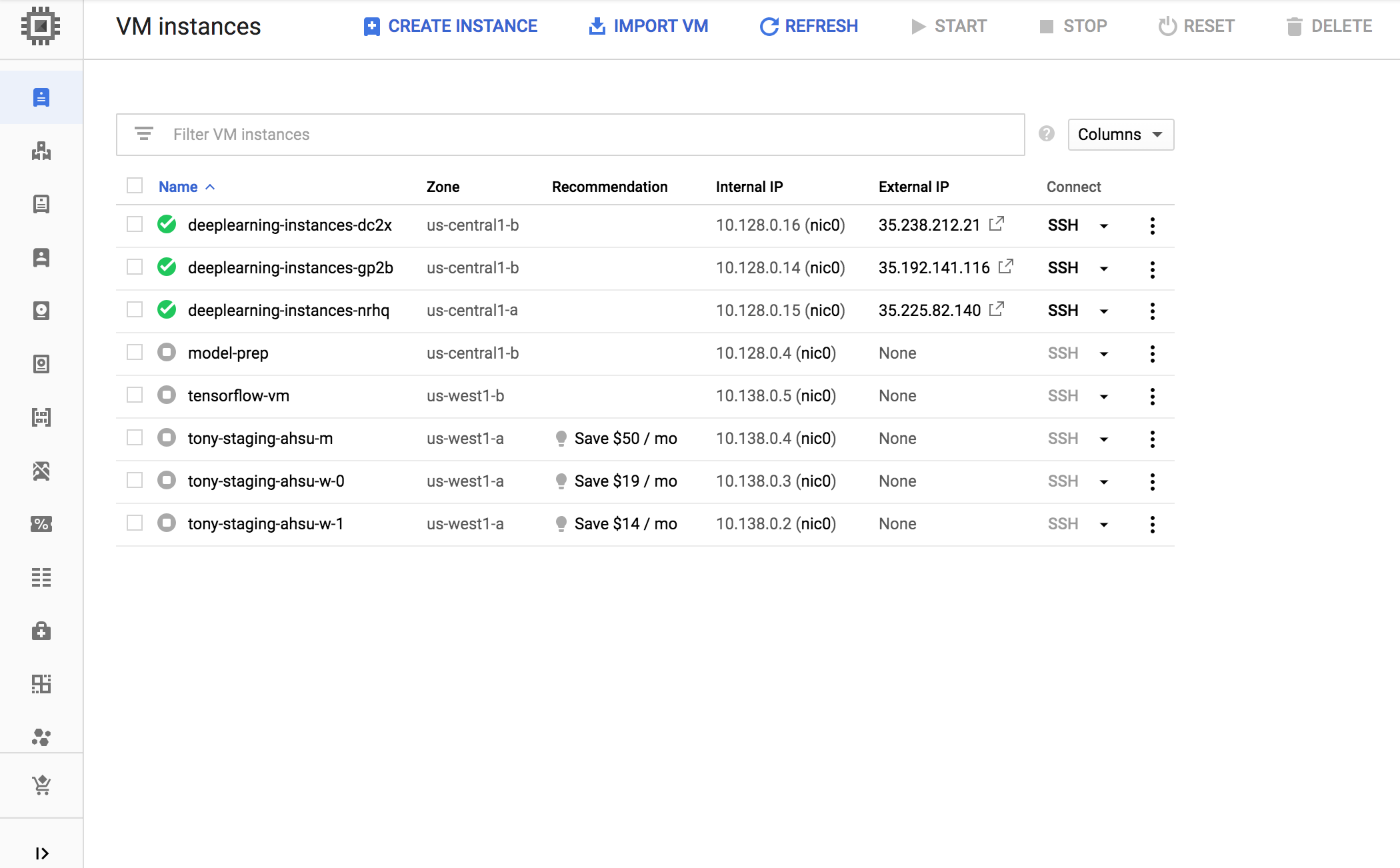
יוצרים קבוצת מופעי מכונה מנוהלים (MIG). קבוצת מופעי מכונה מנוהלים זו נדרשת כדי להגדיר מספר מופעים פעילים בתחומים ספציפיים. המכונות נוצרות על סמך תבנית של הגדרות מכונה שנוצרה בשלב הקודם.
export INSTANCE_GROUP_NAME="deeplearning-instance-group" export INSTANCE_TEMPLATE_NAME="tf-inference-template" gcloud compute instance-groups managed create $INSTANCE_GROUP_NAME \ --template $INSTANCE_TEMPLATE_NAME \ --base-instance-name deeplearning-instances \ --size 2 \ --zones us-central1-a,us-central1-b
אפשר ליצור את המכונה הזו בכל אזור זמינות שתומך ב-GPU מסוג T4. מוודאים שיש לכם מכסות GPU זמינות באזור.
יצירת המופע נמשכת זמן מה. אפשר לעקוב אחרי ההתקדמות באמצעות הפקודות הבאות:
export INSTANCE_GROUP_NAME="deeplearning-instance-group"
gcloud compute instance-groups managed list-instances $INSTANCE_GROUP_NAME --region us-central1

אחרי שקבוצת מופעי מכונה מנוהלים נוצרת, אמור להופיע פלט שדומה לזה:

מוודאים שהמדדים זמינים בדף Google Cloud Cloud Monitoring.
נכנסים לדף Monitoring במסוף Google Cloud .
אם Metrics Explorer מוצג בחלונית הניווט, לוחצים על Metrics Explorer. אחרת, בוחרים באפשרות Resources (משאבים) ואז באפשרות Metrics Explorer.
חיפוש של
gpu_utilization.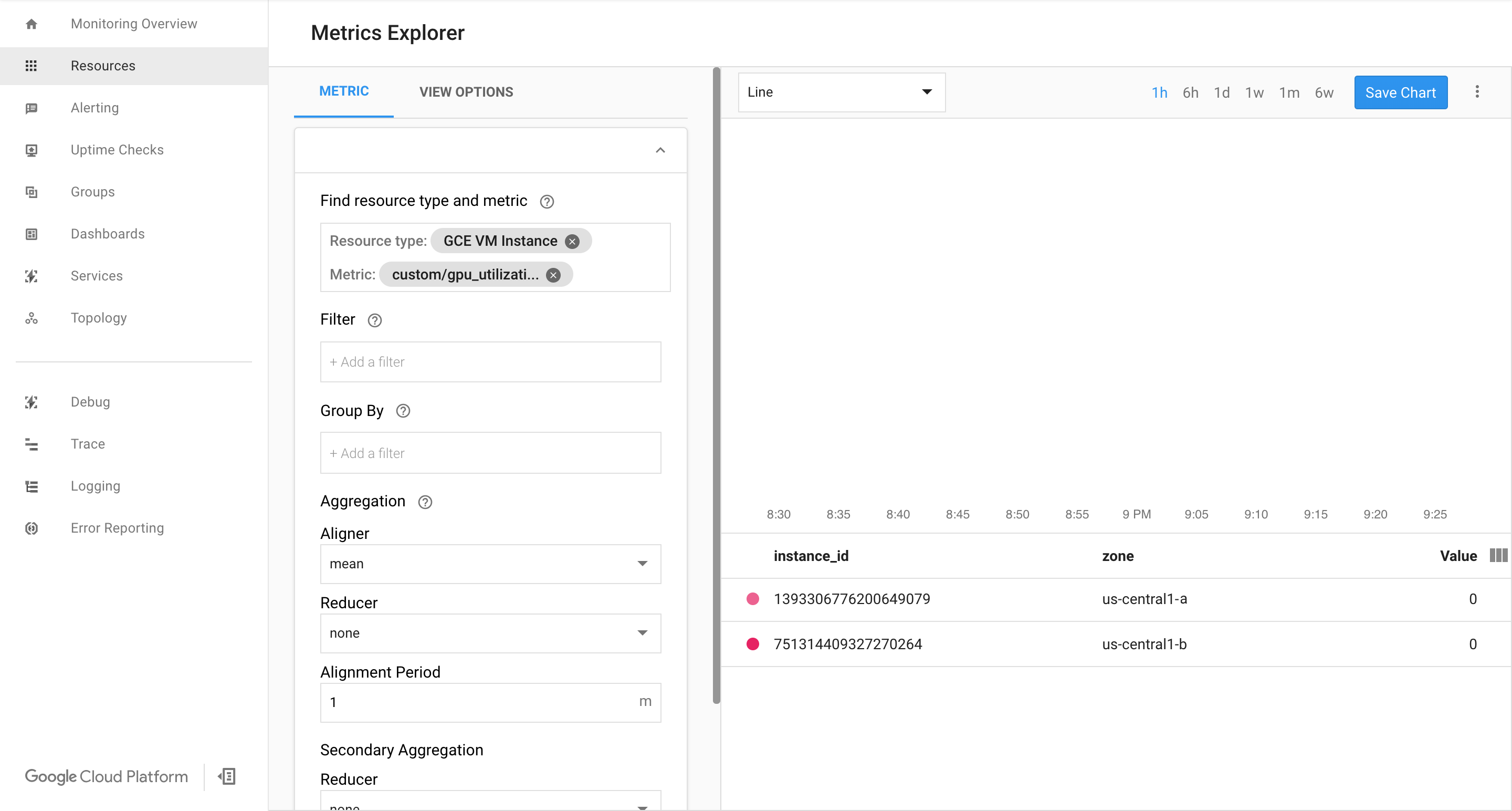
אם הנתונים מגיעים, אמור להופיע משהו כזה:
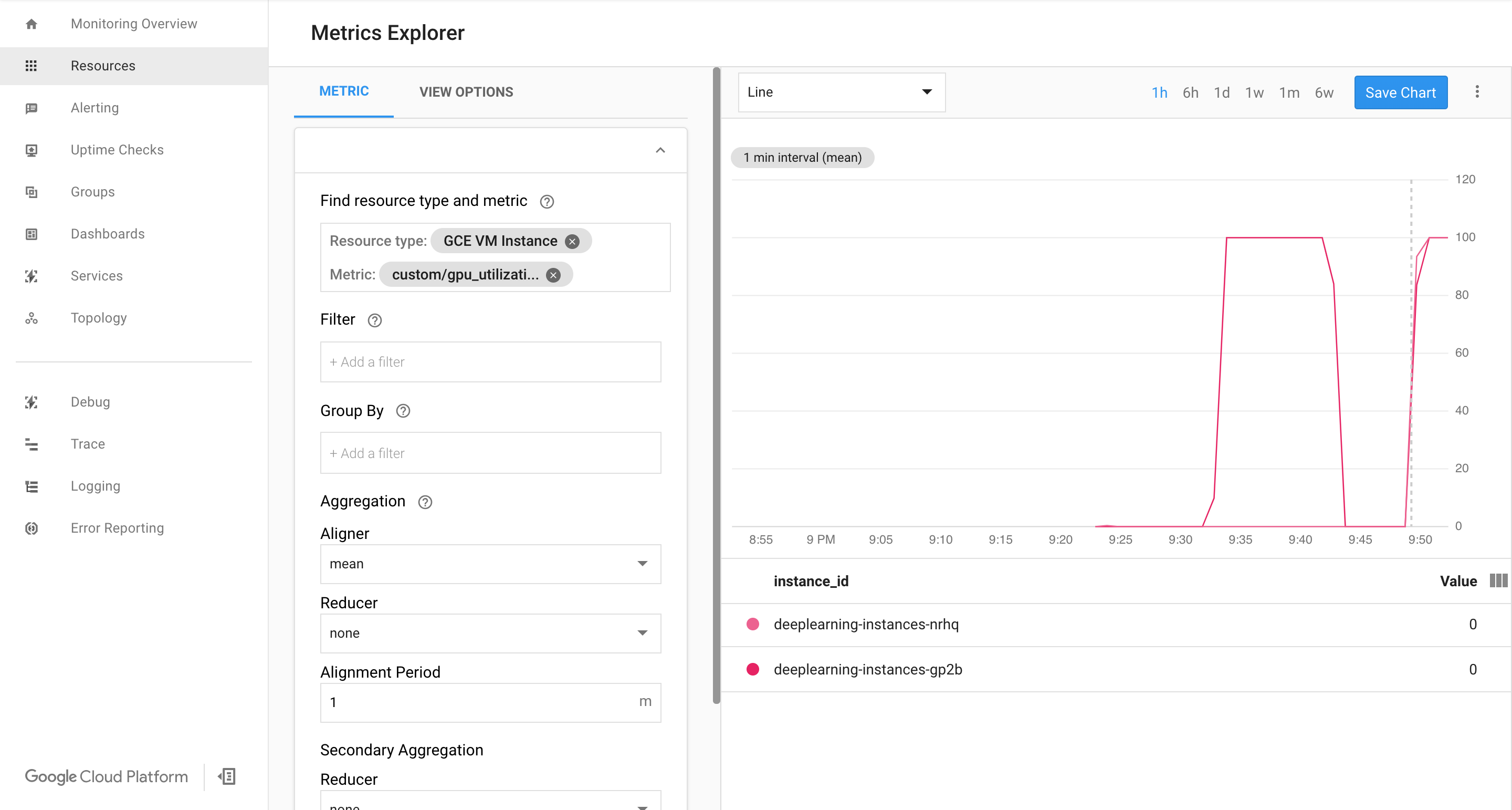
הפעלת התאמה אוטומטית לעומס
מפעילים את התכונה 'שינוי גודל אוטומטי' לקבוצת המופעים המנוהלת.
export INSTANCE_GROUP_NAME="deeplearning-instance-group" gcloud compute instance-groups managed set-autoscaling $INSTANCE_GROUP_NAME \ --custom-metric-utilization metric=custom.googleapis.com/gpu_utilization,utilization-target-type=GAUGE,utilization-target=85 \ --max-num-replicas 4 \ --cool-down-period 360 \ --region us-central1
custom.googleapis.com/gpu_utilizationהוא הנתיב המלא למדד. בדוגמה מוגדרת רמה 85, כלומר בכל פעם שרמת הניצול של ה-GPU מגיעה ל-85, הפלטפורמה יוצרת מופע חדש בקבוצה שלנו.בודקים את שינוי הגודל האוטומטי. כדי לבדוק את ההתאמה האוטומטית לעומס (automatic scaling), צריך לבצע את השלבים הבאים:
- מתחברים למכונה באמצעות SSH. מידע נוסף על חיבור למופעים
משתמשים בכלי
gpu-burnכדי לטעון את ה-GPU לניצול של 100% למשך 600 שניות:git clone https://github.com/GoogleCloudPlatform/ml-on-gcp.git cd ml-on-gcp/third_party/gpu-burn git checkout c0b072aa09c360c17a065368294159a6cef59ddf make ./gpu_burn 600 > /dev/null &
צפייה בדף Cloud Monitoring. מתבוננים בהתאמה אוטומטית לעומס. האשכול מתרחב על ידי הוספת עוד מופע אחד.
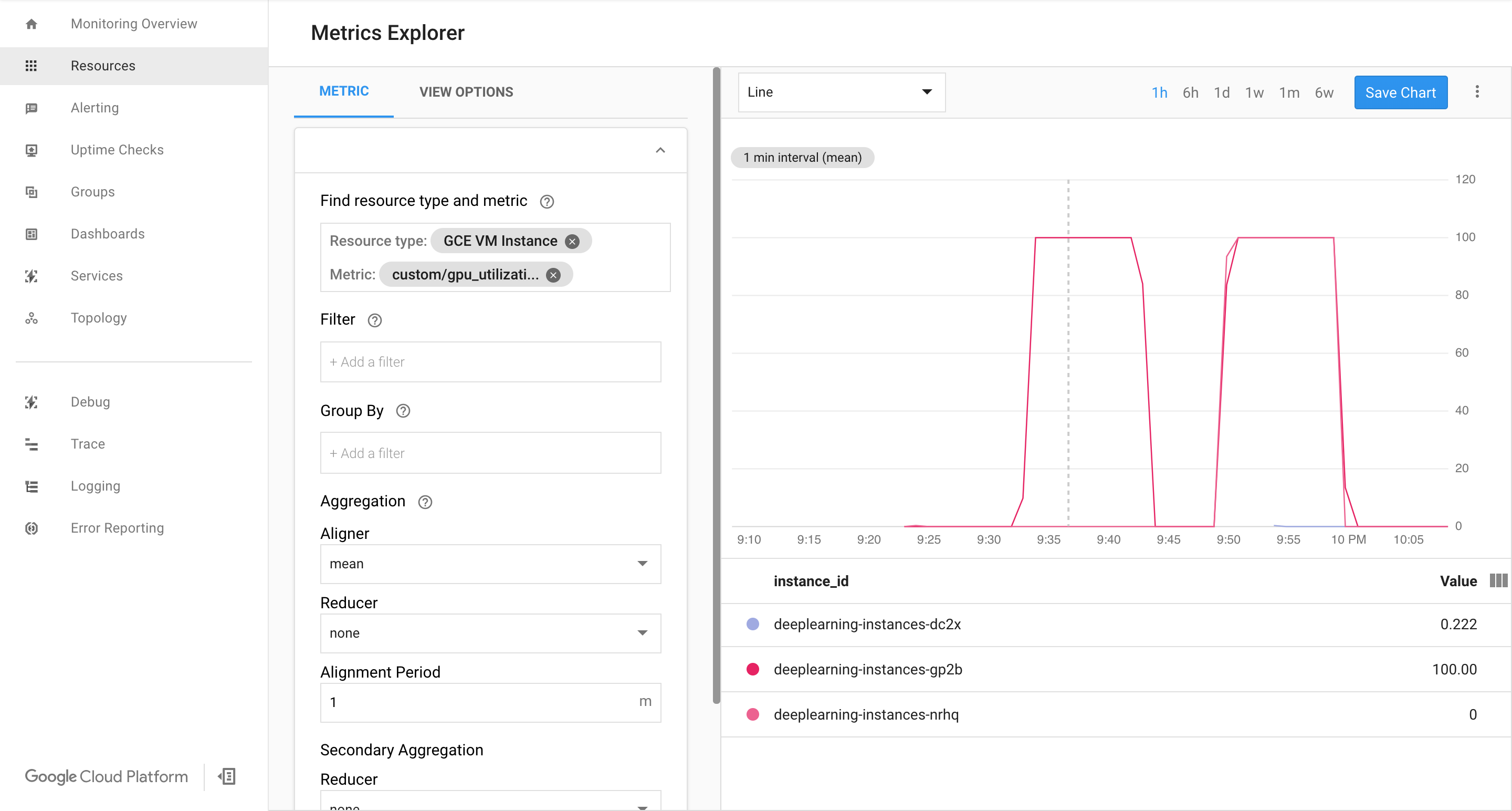
נכנסים לדף Instance groups במסוף Google Cloud .
לוחצים על
deeplearning-instance-groupקבוצת מופעי מכונה מנוהלים.לוחצים על הכרטיסייה מעקב.
בשלב הזה, הלוגיקה של התאמה אוטומטית לעומס אמורה לנסות להפעיל כמה שיותר מכונות כדי להפחית את העומס, אבל ללא הצלחה:
בשלב הזה אפשר להפסיק את ההקצאה של מופעים ולראות איך המערכת מצטמצמת.
הגדרת מאזן עומסים
בואו נראה מה יש לכם עד עכשיו:
- מודל מאומן שעבר אופטימיזציה באמצעות TensorRT5 (INT8)
- קבוצה מנוהלת של מופעי מכונה. המופעים האלה מוגדרים עם קנה מידה אוטומטי שמבוסס על השימוש ב-GPU
עכשיו אפשר ליצור מאזן עומסים לפני המופעים.
יצירת בדיקות תקינות. בדיקות התקינות משמשות כדי לקבוע אם מארח מסוים בקצה העורפי שלנו יכול לשרת את התנועה.
export HEALTH_CHECK_NAME="http-basic-check" gcloud compute health-checks create http $HEALTH_CHECK_NAME \ --request-path /v1/models/default \ --port 8888
יוצרים שירות קצה עורפי שכולל קבוצת מופעים ובדיקת תקינות.
יוצרים את בדיקת התקינות.
export HEALTH_CHECK_NAME="http-basic-check" export WEB_BACKED_SERVICE_NAME="tensorflow-backend" gcloud compute backend-services create $WEB_BACKED_SERVICE_NAME \ --protocol HTTP \ --health-checks $HEALTH_CHECK_NAME \ --global
מוסיפים את קבוצת המופעים לשירות הקצה העורפי החדש.
export INSTANCE_GROUP_NAME="deeplearning-instance-group" export WEB_BACKED_SERVICE_NAME="tensorflow-backend" gcloud compute backend-services add-backend $WEB_BACKED_SERVICE_NAME \ --balancing-mode UTILIZATION \ --max-utilization 0.8 \ --capacity-scaler 1 \ --instance-group $INSTANCE_GROUP_NAME \ --instance-group-region us-central1 \ --global
מגדירים כתובת URL להעברה. מאזן העומסים צריך לדעת לאיזו כתובת URL אפשר להעביר את הבקשות לשירותים לקצה העורפי.
export WEB_BACKED_SERVICE_NAME="tensorflow-backend" export WEB_MAP_NAME="map-all" gcloud compute url-maps create $WEB_MAP_NAME \ --default-service $WEB_BACKED_SERVICE_NAME
יוצרים את מאזן העומסים.
export WEB_MAP_NAME="map-all" export LB_NAME="tf-lb" gcloud compute target-http-proxies create $LB_NAME \ --url-map $WEB_MAP_NAME
מוסיפים כתובת IP חיצונית למאזן העומסים.
export IP4_NAME="lb-ip4" gcloud compute addresses create $IP4_NAME \ --ip-version=IPV4 \ --network-tier=PREMIUM \ --global
מוצאים את כתובת ה-IP שהוקצתה.
gcloud compute addresses list
מגדירים את כלל ההעברה שאומר ל- Google Cloud להעביר את כל הבקשות מכתובת ה-IP הציבורית למאזן העומסים.
export IP=$(gcloud compute addresses list | grep ${IP4_NAME} | awk '{print $2}') export LB_NAME="tf-lb" export FORWARDING_RULE="lb-fwd-rule" gcloud compute forwarding-rules create $FORWARDING_RULE \ --address $IP \ --global \ --load-balancing-scheme=EXTERNAL \ --network-tier=PREMIUM \ --target-http-proxy $LB_NAME \ --ports 80אחרי שיוצרים את כללי ההעברה הגלובליים, יכול להיות שיחלפו כמה דקות עד שההגדרה תופץ.
הפעלת חומת האש
בודקים אם יש כללי חומת אש שמאפשרים חיבורים ממקורות חיצוניים למופעי המכונות הווירטואליות.
gcloud compute firewall-rules list
אם אין לכם כללי חומת אש שמאפשרים את החיבורים האלה, אתם צריכים ליצור אותם. כדי ליצור כללים לחומת האש, מריצים את הפקודות הבאות:
gcloud compute firewall-rules create www-firewall-80 \ --target-tags http-server --allow tcp:80 gcloud compute firewall-rules create www-firewall-8888 \ --target-tags http-server --allow tcp:8888
הרצת הסקת מסקנות
אתם יכולים להשתמש בסקריפט הבא בשפת Python כדי להמיר תמונות לפורמט שאפשר להעלות לשרת.
from PIL import Image import numpy as np import json import codecs
img = Image.open("image.jpg").resize((240, 240)) img_array=np.array(img) result = { "instances":[img_array.tolist()] } file_path="/tmp/out.json" print(json.dump(result, codecs.open(file_path, 'w', encoding='utf-8'), separators=(',', ':'), sort_keys=True, indent=4))מריצים את ההסקה.
curl -X POST $IP/v1/models/default:predict -d @/tmp/out.json
הסרת המשאבים
כדי להימנע מחיובים בחשבון Google Cloud בגלל השימוש במשאבים שנעשה במסגרת המדריך הזה, אפשר למחוק את הפרויקט שמכיל את המשאבים, או להשאיר את הפרויקט ולמחוק את המשאבים בנפרד.
מחיקת כללי העברה.
gcloud compute forwarding-rules delete $FORWARDING_RULE --global
מוחקים את כתובת ה-IPV4.
gcloud compute addresses delete $IP4_NAME --global
מוחקים את מאזן העומסים.
gcloud compute target-http-proxies delete $LB_NAME
מוחקים את כתובת ה-URL להעברה.
gcloud compute url-maps delete $WEB_MAP_NAME
מוחקים את שירות לקצה העורפי.
gcloud compute backend-services delete $WEB_BACKED_SERVICE_NAME --global
מחיקת בדיקות תקינות.
gcloud compute health-checks delete $HEALTH_CHECK_NAME
מוחקים את קבוצת מופעי המכונה המנוהלים.
gcloud compute instance-groups managed delete $INSTANCE_GROUP_NAME --region us-central1
מוחקים את תבנית של הגדרות מכונה.
gcloud beta compute --project=$PROJECT_NAME instance-templates delete $INSTANCE_TEMPLATE_NAME
מוחקים את הכללים של חומת האש.
gcloud compute firewall-rules delete www-firewall-80
gcloud compute firewall-rules delete www-firewall-8888