
במדריך הזה מוסבר איך להפעיל רפליקציה אסינכרונית מאוזנת של Hyperdisk בשני אזורים של Google Cloud כפתרון להתאוששות מאסון (DR), ואיך להפעיל את מופעי ה-DR במקרה של אסון.
Microsoft SQL Server Failover Cluster Instances (FCI) הוא מופע יחיד של SQL Server עם זמינות גבוהה, שנפרס במספר צמתים של Windows Server Failover Cluster (WSFC). בכל נקודת זמן, אחד מצמתי האשכול מארח באופן פעיל את מופע ה-SQL. במקרה של הפסקת חשמל אזורית או בעיה במכונה וירטואלית, WSFC מעביר באופן אוטומטי את הבעלות על המשאבים של המופע לצומת אחר באשכול, וכך מאפשר ללקוחות להתחבר מחדש. כדי ש-SQL Server FCI יוכל לגשת לנתונים בכל צמתי ה-WSFC, הנתונים צריכים להיות ממוקמים בדיסקים משותפים.
כדי לוודא שפריסת SQL Server יכולה לעמוד בהפסקת חשמל אזורית, צריך להפעיל רפליקציה אסינכרונית כדי ליצור רפליקה של נתוני הדיסק באזור הראשי באזור משני. במדריך הזה נשתמש בדיסקים של Hyperdisk Balanced High Availability multi-writer כדי להפעיל שכפול אסינכרוני בשני אזורים כפתרון להתאוששות מאסון (DR) עבור SQL Server FCI, ונסביר איך להפעיל את מכונות ה-DR במקרה של אסון. Google Cloud במסמך הזה, אסון הוא אירוע שבו אשכול של מסד נתונים ראשי נכשל או הופך ללא זמין כי האזור של האשכול הופך ללא זמין, אולי בגלל אסון טבע.
המדריך הזה מיועד למומחי ארכיטקטורת מסדי נתונים, לאדמינים ולמהנדסים.
מטרות
- הפעלת שכפול אסינכרוני של Hyperdisk לכל הצמתים של אשכול SQL Server FCI שפועלים ב- Google Cloud.
- כדאי לבצע סימולציה של אירוע אסון ולבצע תהליך מלא של התאוששות מאסון כדי לאמת את הגדרת ההתאוששות מאסון.
עלויות
במסמך הזה משתמשים ברכיבים הבאים של Google Cloud, והשימוש בהם כרוך בתשלום:
כדי להעריך את ההוצאות בהתאם לתחזית השימוש שלכם, אתם יכולים להיעזר במחשבון העלויות.
כשמסיימים את המשימות שמתוארות במסמך הזה אפשר למחוק את המשאבים שיצרתם כדי להימנע מחיובים נוספים. מידע נוסף זמין בקטע הסרת המשאבים.
לפני שמתחילים
במדריך הזה תצטרכו פרויקט Google Cloud . אפשר ליצור פרויקט חדש או לבחור פרויקט שכבר יצרתם:
-
בדף לבחירת הפרויקט במסוף Google Cloud , בוחרים פרויקט ב- Google Cloud או יוצרים אותו.
תפקידים שנדרשים כדי לבחור או ליצור פרויקט
- Select a project: כדי לבחור פרויקט לא צריך תפקיד IAM ספציפי – אפשר לבחור כל פרויקט שקיבלתם בו תפקיד.
-
יצירת פרויקט: כדי ליצור פרויקט, צריך את התפקיד Project Creator (יצירת פרויקטים) (
roles/resourcemanager.projectCreator), שכולל את ההרשאהresourcemanager.projects.create. איך מקצים תפקידים
-
במסוף Google Cloud , מפעילים את Cloud Shell.
-
מגדירים את אשכול SQL Server באזור הראשי לפי השלבים במדריך הגדרת אשכול SQL Server FCI במצב קריאה וכתיבה מרובים של Hyperdisk Balanced High Availability. אחרי שמגדירים את האשכול, חוזרים למדריך הזה כדי להפעיל DR באזור המשני.
הרשאות מתאימות בפרויקט בענן שלכם ב-Google Cloud וב-SQL Server לביצוע גיבויים ושחזורים.
התאוששות מאסון ב- Google Cloud
התאוששות מאסון (DR) Google Cloud כוללת שמירה על גישה רציפה לנתונים כשאיזור נכשל או כשאין אליו גישה. יש כמה אפשרויות לפריסת אתר DR, והן ייקבעו לפי הדרישות של יעד נקודת ההתאוששות (RPO) ויעד משך ההתאוששות (RTO). במדריך הזה נסביר על אחת מהאפשרויות שבהן הדיסקים שמצורפים למכונה הוירטואלית משוכפלים מהאזור הראשי לאזור DR.
תוכנית התאוששות מאסון (DR) באמצעות שכפול אסינכרוני של Hyperdisk
רפליקציה אסינכרונית של Hyperdisk היא אפשרות אחסון שמספקת עותק אחסון אסינכרוני לרפליקציה של דיסקים בין שני אזורים. במקרה הלא סביר של הפסקה זמנית בשירות באזור מסוים, רפליקציה אסינכרונית של Hyperdisk מאפשרת לבצע מעבר לגיבוי בעת כשל של הנתונים לאזור משני ולהפעיל מחדש את עומסי העבודה באזור הזה.
רפליקציה אסינכרונית של Hyperdisk מעתיקה נתונים מדיסק שמצורף לעומס עבודה פעיל, שנקרא הדיסק הראשי, לדיסק נפרד שנמצא באזור אחר. הדיסק שמקבל את השכפול נקרא הדיסק המשני. האזור שבו הדיסק הראשי פועל נקרא האזור הראשי, והאזור שבו הדיסק המשני פועל נקרא האזור המשני. כדי לוודא שהעותקים של כל הדיסקים שמצורפים לכל צומת של SQL Server מכילים נתונים מאותה נקודת זמן, הדיסקים מתווספים לקבוצת עקביות. קבוצות עקביות מאפשרות לבצע DR ובדיקות DR בכמה דיסקים.
ארכיטקטורה של תוכנית התאוששות מאסון (DR)
בתרשים הבא מוצגת ארכיטקטורה מינימלית של רפליקציה אסינכרונית של Hyperdisk, שתומכת בזמינות גבוהה של מסד נתונים באזור הראשי, R1, וברפליקציה של הדיסק מהאזור הראשי לאזור המשני, R2.
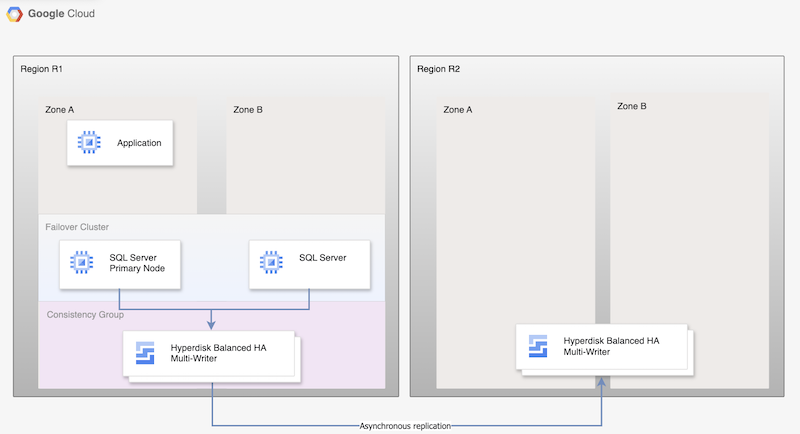
איור 1. ארכיטקטורה של תוכנית התאוששות מאסון (DR) עם Microsoft SQL Server ו-Hyperdisk Asynchronous Replication
הארכיטקטורה הזו פועלת באופן הבא:
- שני מופעים של Microsoft SQL Server, מופע ראשי ומופע המתנה, הם חלק מאשכול FCI, והם ממוקמים באזור הראשי (R1), אבל באזורים שונים (אזורים A ו-B). שתי המכונות הווירטואליות חולקות דיסק Hyperdisk Balanced High Availability, כך ששתיהן יכולות לגשת לנתונים. הוראות מפורטות זמינות במאמר הגדרת אשכול FCI של SQL Server עם מצב ריבוי כתיבה של Hyperdisk Balanced High Availability
- דיסקים משני צמתי ה-SQL מתווספים לקבוצות עקביות ומשוכפלים לאזור DR, R2. Compute Engine משכפל את הנתונים מ-R1 ל-R2 באופן אסינכרוני.
- שכפול אסינכרוני משכפל רק את הנתונים בדיסקים ל-R2, ולא משכפל את המטא-נתונים של מכונת ה-VM. במהלך התאוששות מאסון, נוצרות מכונות וירטואליות חדשות והדיסקים המשוכפלים הקיימים מצורפים למכונות הווירטואליות כדי להפעיל את הצמתים.
תהליך התאוששות מאסון (DR)
תהליך ה-DR קובע את השלבים התפעוליים שצריך לבצע אחרי שאזור מסוים הופך ללא זמין, כדי להפעיל מחדש את עומס העבודה באזור אחר. תהליך בסיסי של DR למסד נתונים כולל את השלבים הבאים:
- האזור הראשון (R1), שבו פועל מופע מסד הנתונים הראשי, הופך ללא זמין.
- צוות התפעול מזהה את האסון ומאשר אותו באופן רשמי, ומחליט אם נדרשת יתירות כשל.
- אם נדרש מעבר לגיבוי בעת כשל, צריך להפסיק את השכפול בין הדיסקים הראשי והמשני. מכונה וירטואלית חדשה נוצרת מההעתקים של הדיסק ומועברת למצב אונליין.
- מסד הנתונים באזור הגיאוגרפי להתאוששות מאסון, R2, מאומת ומועבר למצב אונליין. מסד הנתונים ב-R2 הופך למסד הנתונים הראשי החדש שמאפשר קישוריות.
- המשתמשים ממשיכים את העיבוד במסד הנתונים הראשי החדש ומקבלים גישה למופע הראשי ב-R2.
למרות שהתהליך הבסיסי הזה יוצר שוב מסד נתונים ראשי תקין, הוא לא יוצר ארכיטקטורת HA מלאה, כי לא מתבצעת שכפול של מסד הנתונים הראשי החדש.
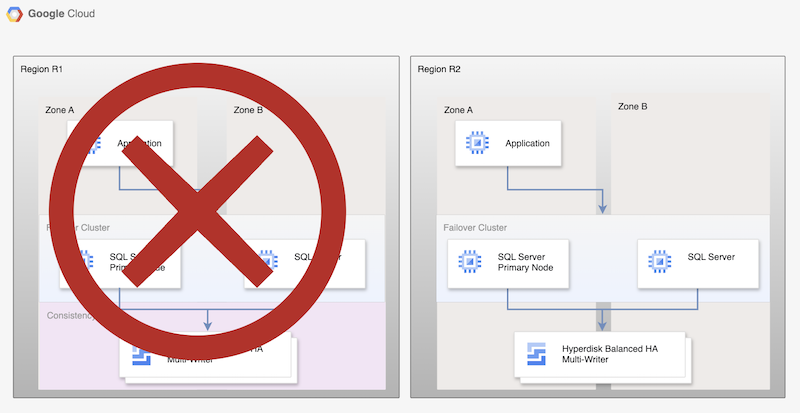
איור 2. פריסת SQL Server אחרי תוכנית התאוששות מאסון (DR) באמצעות שכפול אסינכרוני של דיסק מתמשך
חזרה לאזור משוחזר
כשהאזור הראשי (R1) חוזר למצב אונליין, אפשר לתכנן ולהפעיל את תהליך החזרה למצב תקין. תהליך החזרה למצב תקין כולל את כל השלבים שמפורטים במדריך הזה, אבל במקרה הזה, R2 הוא המקור ו-R1 הוא אזור השחזור.
בחירה של מהדורת SQL Server
המדריך הזה תומך בגרסאות הבאות של Microsoft SQL Server:
- SQL Server 2016 Enterprise ו-Standard Edition
- SQL Server 2017 Enterprise ו-Standard Edition
- SQL Server 2019 Enterprise ו-Standard Edition
- מהדורות SQL Server 2022 Enterprise ו-Standard
המדריך משתמש במופע של אשכול מעבר לגיבוי בענן של SQL Server עם דיסק Hyperdisk Balanced High Availability.
אם אתם לא צריכים תכונות של SQL Server Enterprise, אתם יכולים להשתמש במהדורת Standard של SQL Server:
בגרסאות 2016, 2017, 2019 ו-2022 של SQL Server מותקן Microsoft SQL Server Management Studio בתמונה, כך שלא צריך להתקין אותו בנפרד. עם זאת, בסביבת ייצור מומלץ להתקין מופע אחד של Microsoft SQL Server Management Studio במכונה וירטואלית נפרדת בכל אזור. אם מגדירים סביבת זמינות גבוהה, צריך להתקין את Microsoft SQL Server Management Studio פעם אחת לכל אזור כדי לוודא שהיא תישאר זמינה אם אזור אחר לא יהיה זמין.
הגדרת התאוששות מאסון (DR) עבור Microsoft SQL Server
במדריך הזה נעשה שימוש בתמונה sql-ent-2022-win-2022 עבור Microsoft SQL Server
Enterprise.
רשימה מלאה של תמונות זמינה במאמר בנושא תמונות של מערכות הפעלה.
הגדרה של אשכול זמינות גבוהה עם שני מופעים
כדי להגדיר רפליקציה של דיסקים ל-SQL Server בין שני אזורים, צריך קודם ליצור אשכול HA עם שני מופעים באזור מסוים.
מופע אחד משמש כראשי, והמופע השני משמש כגיבוי. כדי לבצע את השלב הזה, פועלים לפי ההוראות במאמר הגדרת אשכול FCI של SQL Server עם מצב מרובה כתיבה של Hyperdisk Balanced High Availability.
במדריך הזה נעשה שימוש ב-us-central1 לאזור הראשי R1.
אם פעלתם לפי השלבים במאמר הגדרת אשכול FCI של SQL Server עם מצב כתיבה מרובה של Hyperdisk Balanced High Availability, יצרתם שני מופעים של SQL Server באותו אזור (us-central1). פרסתם מופע ראשי של SQL Server (node-1) ב-us-central1-a ומופע בהמתנה (node-2) ב-us-central1-b.
הפעלת שכפול אסינכרוני של הדיסק
אחרי שיוצרים ומגדירים את כל המכונות הווירטואליות, משלימים את השלבים הבאים כדי להפעיל שכפול דיסקים בין שני האזורים:
יוצרים קבוצת אפליקציות עקביות לשני צמתי SQL Server ולצומת שמארח את התפקידים של העד ובקר הדומיין. אחת מהמגבלות של קבוצות עקביות היא שהן לא יכולות לכלול תחומים שונים, ולכן צריך להוסיף כל צומת לקבוצת עקביות נפרדת.
gcloud compute resource-policies create disk-consistency-group node-1-disk-const-grp \ --region=$REGION gcloud compute resource-policies create disk-consistency-group node-2-disk-const-grp \ --region=$REGION gcloud compute resource-policies create disk-consistency-group witness-disk-const-grp \ --region=$REGION gcloud compute resource-policies create disk-consistency-group multiwriter-disk-const-grp \ --region=$REGION
מוסיפים את הדיסקים מהמכונות הווירטואליות הראשיות וממכונות ההמתנה לקבוצות העקביות המתאימות.
gcloud compute disks add-resource-policies node-1 \ --zone=$REGION-a \ --resource-policies=node-1-disk-const-grp gcloud compute disks add-resource-policies node-2 \ --zone=$REGION-b \ --resource-policies=node-2-disk-const-grp gcloud compute disks add-resource-policies mw-datadisk-1 \ --region=$REGION \ --resource-policies=multiwriter-disk-const-grp gcloud compute disks add-resource-policies witness \ --zone=$REGION-c \ --resource-policies=witness-disk-const-grp
יוצרים דיסקים משניים ריקים באזור המשני.
DR_REGION="us-west1" gcloud compute disks create node-1-replica \ --zone=$DR_REGION-a \ --size=50 \ --primary-disk=node-1 \ --primary-disk-zone=$REGION-a gcloud compute disks create node-2-replica \ --zone=$DR_REGION-b \ --size=50 \ --primary-disk=node-2 \ --primary-disk-zone=$REGION-b gcloud compute disks create multiwriter-datadisk-1-replica \ --replica-zones=$DR_REGION-a,$DR_REGION-b \ --size=$PD_SIZE \ --type=hyperdisk-balanced-high-availability \ --access-mode READ_WRITE_MANY \ --primary-disk=multiwriter-datadisk-1 \ --primary-disk-region=$REGION gcloud compute disks create witness-replica \ --zone=$DR_REGION-c \ --size=50 \ --primary-disk=witness \ --primary-disk-zone=$REGION-c
מתחילים לשכפל את הדיסק. הנתונים משוכפלים מהדיסק הראשי לדיסק הריק החדש שנוצר באזור DR.
gcloud compute disks start-async-replication node-1 \ --zone=$REGION-a \ --secondary-disk=node-1-replica \ --secondary-disk-zone=$DR_REGION-a gcloud compute disks start-async-replication node-2 \ --zone=$REGION-b \ --secondary-disk=node-2-replica \ --secondary-disk-zone=$DR_REGION-b gcloud compute disks start-async-replication multiwriter-datadisk-1 \ --region=$REGION \ --secondary-disk=multiwriter-datadisk-1-replica \ --secondary-disk-region=$DR_REGION gcloud compute disks start-async-replication witness \ --zone=$REGION-c \ --secondary-disk=witness-replica \ --secondary-disk-zone=$DR_REGION-c
בשלב הזה, הנתונים אמורים להיות משוכפלים בין האזורים.
סטטוס השכפול של כל דיסק צריך להיות Active.
הדמיה של תוכנית התאוששות מאסון (DR)
בקטע הזה נבדוק את ארכיטקטורת ההתאוששות מאסון שהוגדרה במדריך הזה.
סימולציה של הפסקת חשמל והפעלה של מעבר לגיבוי במקרה של אסון
במהלך יתירות כשל, יוצרים מכונות וירטואליות חדשות באזור DR ומחברים אליהן את הדיסקים המשוכפלים. כדי לפשט את המעבר לגיבוי, אתם יכולים להשתמש בענן וירטואלי פרטי (VPC) אחר באזור DR לצורך שחזור, כדי שתוכלו להשתמש באותה כתובת IP.
לפני שמתחילים ביתירות כשל, מוודאים ש-node-1 הוא הצומת הראשי עבור קבוצת הזמינות AlwaysOn שיצרתם. כדי למנוע בעיות בסנכרון הנתונים, צריך להפעיל את בקר הדומיין ואת הצומת הראשי של SQL Server, כי שני הצמתים מוגנים על ידי שתי קבוצות עקביות נפרדות.
כדי לדמות הפסקת חשמל, פועלים לפי השלבים הבאים:
יוצרים VPC לשחזור.
DRVPC_NAME="default-dr" DRSUBNET_NAME="default-recovery" gcloud compute networks create $DRVPC_NAME \ --subnet-mode=custom CIDR=$(gcloud compute networks subnets describe default \ --region=$REGION --format=value\(ipCidrRange\)) gcloud compute networks subnets create $DRSUBNET_NAME \ --network=$DRVPC_NAME --range=$CIDR --region=$DR_REGION
הפסקת שכפול הנתונים.
PROJECT=$(gcloud config get-value project) gcloud compute disks stop-group-async-replication projects/$PROJECT/regions/$REGION/resourcePolicies/node-1-disk-const-grp \ --zone=$REGION-a gcloud compute disks stop-group-async-replication projects/$PROJECT/regions/$REGION/resourcePolicies/node-2-disk-const-grp \ --zone=$REGION-b gcloud compute disks stop-group-async-replication projects/$PROJECT/regions/$REGION/resourcePolicies/multiwriter-disk-const-grp \ --zone=$REGION-c gcloud compute disks stop-group-async-replication projects/$PROJECT/regions/$REGION/resourcePolicies/witness-disk-const-grp \ --zone=$REGION-c
מפסיקים את המכונות הווירטואליות של המקור באזור הראשי.
gcloud compute instances stop node-1 \ --zone=$REGION-a gcloud compute instances stop node-2 \ --zone=$REGION-b gcloud compute instances stop witness \ --zone=$REGION-c
כדאי לשנות את השם של מכונות ה-VM הקיימות כדי למנוע שמות כפולים בפרויקט.
gcloud compute instances set-name witness \ --new-name=witness-old \ --zone=$REGION-c gcloud compute instances set-name node-1 \ --new-name=node-1-old \ --zone=$REGION-a gcloud compute instances set-name node-2 \ --new-name=node-2-old \ --zone=$REGION-b
יצירת מכונות וירטואליות באזור DR באמצעות הדיסקים המשניים. למכונות הווירטואליות האלה יהיה כתובת ה-IP של המכונה הווירטואלית של המקור.
NODE1IP=$(gcloud compute instances describe node-1-old --zone $REGION-a --format=value\(networkInterfaces[0].networkIP\)) NODE2IP=$(gcloud compute instances describe node-2-old --zone $REGION-b --format=value\(networkInterfaces[0].networkIP\)) WITNESSIP=$(gcloud compute instances describe witness-old --zone $REGION-c --format=value\(networkInterfaces[0].networkIP\)) gcloud compute instances create node-1 \ --zone=$DR_REGION-a \ --machine-type $MACHINE_TYPE \ --network=$DRVPC_NAME \ --subnet=$DRSUBNET_NAME \ --private-network-ip $NODE1IP\ --disk=boot=yes,device-name=node-1-replica,mode=rw,name=node-1-replica \ --disk=boot=no,device-name=mw-datadisk-1-replica,mode=rw,name=mw-datadisk-1-replica,scope=regional gcloud compute instances create witness \ --zone=$DR_REGION-c \ --machine-type=n2-standard-2 \ --network=$DRVPC_NAME \ --subnet=$DRSUBNET_NAME \ --private-network-ip $WITNESSIP \ --disk=boot=yes,device-name=witness-replica,mode=rw,name=witness-replica gcloud compute instances create node-2 \ --zone=$DR_REGION-b \ --machine-type $MACHINE_TYPE \ --network=$DRVPC_NAME \ --subnet=$DRSUBNET_NAME \ --private-network-ip $NODE2IP\ --disk=boot=yes,device-name=node-2-replica,mode=rw,name=node-2-replica \ --disk=boot=no,device-name=mw-datadisk-1-replica,mode=rw,name=mw-datadisk-1-replica,scope=regional
הפעלתם סימולציה של הפסקת חשמל ועברתם לאזור DR. עכשיו אפשר לבדוק אם המופע המשני פועל כמו שצריך.
אימות הקישוריות ל-SQL Server
אחרי שיוצרים את המכונות הווירטואליות, צריך לוודא שהמסד נתונים שוחזר בהצלחה והשרת פועל כמצופה. כדי לבדוק את מסד הנתונים, מריצים שאילתה ממסד הנתונים ששוחזר.
- מתחברים למכונת ה-SQL Server הווירטואלית באמצעות Remote Desktop.
- פותחים את SQL Server Management Studio.
- בתיבת הדו-שיח 'התחברות לשרת', מוודאים ששם השרת מוגדר ל-
node-1ולוחצים על התחברות. בתפריט הקובץ, בוחרים באפשרות קובץ > חדש > שאילתה עם החיבור הנוכחי.
USE [bookshelf]; SELECT * FROM Books;
הסרת המשאבים
כדי להימנע מחיובים בחשבון Google Cloud בגלל השימוש במשאבים שנעשה במסגרת המדריך הזה, פועלים לפי השלבים שבקטע הזה כדי למחוק את המשאבים שיצרתם.
מחיקת הפרויקט
- במסוף Google Cloud , נכנסים לדף Manage resources.
- ברשימת הפרויקטים, בוחרים את הפרויקט שרוצים למחוק ולוחצים על Delete.
- כדי למחוק את הפרויקט, כותבים את מזהה הפרויקט בתיבת הדו-שיח ולוחצים על Shut down.
המאמרים הבאים
- כדאי להעמיק את הקריאה ולהכיר דוגמאות לארכיטקטורות, תרשימים ושיטות מומלצות בנושאי Google Cloud. כל אלה זמינים במרכז הארכיטקטורה של Cloud.