
במאמר הזה מוצגות אסטרטגיות להתאוששות מאסון (DR) עבור Microsoft SQL Server לאדריכלים ולמנהלי צוותים טכניים שאחראים על תכנון והטמעה של התאוששות מאסון ב- Google Cloud.
יכולות להיות סיבות שונות לכך שמסדי נתונים לא יהיו זמינים, למשל כשלים בחומרה או ברשת. כדי לספק גישה רציפה למסד הנתונים במהלך כשלים, מתחזקים מסד נתונים משני שהוא העתק של מסד נתונים ראשי. העובדה שמסד הנתונים המשני נמצא במיקום אחר מגדילה את הסיכוי שהוא יהיה זמין אם מסד הנתונים הראשי לא יהיה זמין.
אם מסד הנתונים הראשי לא זמין, האפליקציה החיונית מתחברת למסד נתונים משני, וממשיכה מהמצב האחרון של נתונים עקביים כדי לספק שירותים למשתמשים עם השבתה מינימלית או ללא השבתה בכלל.
התהליך של הפיכת מסד נתונים משני לזמין במקרה של כשל במסד הנתונים הראשי נקרא תוכנית התאוששות מאסון (DR) של מסד נתונים. מסד הנתונים המשני מתאושש מהמצב שבו מסד הנתונים הראשי לא זמין. באופן אידיאלי, מסד הנתונים המשני נמצא באותו מצב עקבי בדיוק כמו מסד הנתונים הראשי, כשהוא לא זמין או כשהוא חסר רק קבוצה מינימלית של טרנזקציות מהזמן האחרון ממסד הנתונים הראשי.
שחזור לאחר אסון (DR) של מסד נתונים הוא תכונה חיונית ללקוחות ארגוניים. הגורם העיקרי הוא המשכיות עסקית לאפליקציות קריטיות. לדוגמה, אפליקציה קריטית שמייצרת הכנסות (מסחר אלקטרוני), מספקת שירותים אמינים באופן רציף (ניהול טיסות או תחנות כוח) או תומכת בפונקציות ששומרות על החיים (מעקב אחר מטופלים). בכל הדוגמאות האלה, חשוב מאוד שהאפליקציה תהיה זמינה באופן רציף כי היא נחשבת לקריטית למשימה.
רוב מערכות ניהול מסדי הנתונים מספקות פונקציונליות של התאוששות מאסון, כולל Microsoft SQL Server. במסמך הארכיטקטורה הזה מוסבר איך תכונות DR שמוצעות על ידי SQL Server מיושמות בהקשר של Google Cloud.
הסברים על המונחים
בקטעים הבאים מוסברים המונחים שבהם אנחנו משתמשים במסמך הזה.
ארכיטקטורת DR כללית
התרשים הבא מדגים את טופולוגיית הארכיטקטורה הכללית של DR.
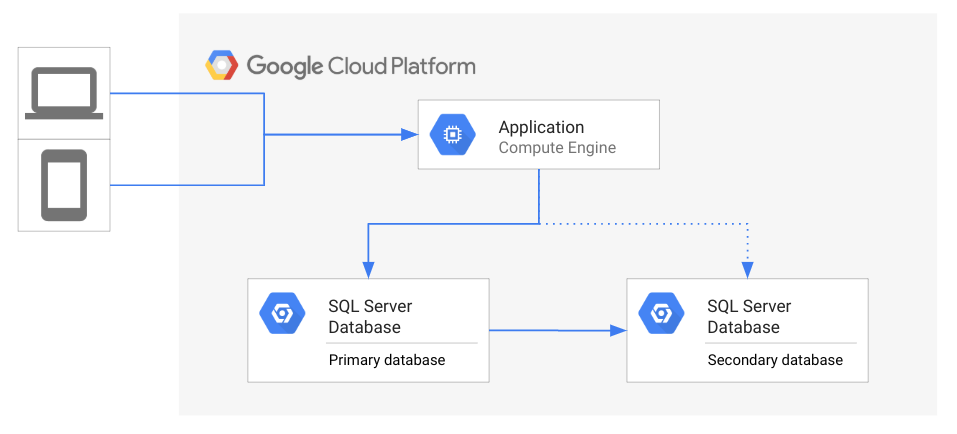
בתרשים שלמעלה, אפליקציה ניגשת למסד נתונים ראשי בזמן שמסד נתונים משני נמצא בהמתנה ומשקף את המצב של מסד הנתונים הראשי. לקוחות ניגשים לאפליקציה שפועלת ב- Google Cloud.
אם מסד הנתונים הראשי לא זמין, אדמינים של מסד הנתונים או צוות התפעול צריכים להחליט אם להתחיל את תוכנית ההתאוששות מאסון (DR). אם מתחילים שחזור של מסד הנתונים אחרי אסון, האפליקציה מתחברת מחדש למסד הנתונים המשני. אחרי החיבור, האפליקציה יכולה לשרת שוב את הלקוחות שלה. במצב אידיאלי, האפליקציה זמינה במסד הנתונים המשני בהקדם האפשרי, כך שלקוחות אפילו לא יחוו הפסקה זמנית בשירות. אפשרות אחת היא להמתין עד שהגישה למסד הנתונים הראשי תתאפשר שוב, במקום להתחיל בתוכנית התאוששות מאסון (DR). לדוגמה, אם האסון הוא לסירוגין, יכול להיות שיהיה מהיר יותר לפתור את הבעיה במקום לבצע מעבר לגיבוי.
מסדי נתונים ראשיים ומשניים
אפליקציה אחת או יותר ניגשות למסד נתונים ראשי כדי לספק שירותי שמירה לניהול המצב של האפליקציה. מסד נתונים משני קשור למסד נתונים ראשי ומכיל העתק של מסד הנתונים הראשי. באופן אידיאלי, התוכן של מסד הנתונים המשני זהה בדיוק לתוכן של מסד הנתונים הראשי בכל נקודת זמן. במקרים רבים, יש פער בין מסד הנתונים המשני לבין מסד הנתונים הראשי בגלל עיכובים בהחלת שינויים בעסקאות שבוצעו במסד הנתונים הראשי. אפשר לשייך יותר ממסד נתונים משני אחד למסד נתונים ראשי, בהתאם לטכנולוגיית מסד הנתונים. SQL Server תומך בשיוך של יותר ממסד נתונים משני אחד למסד נתונים ראשי.
תוכנית התאוששות מאסון (DR)
אם מסד נתונים ראשי הופך ללא זמין, DR משנה את התפקיד של מסד הנתונים המשני כך שהוא הופך למסד הנתונים הראשי. אם יש יותר ממסד נתונים משני, אחד ממסדי הנתונים האלה נבחר באופן ידני או על סמך רשימת מעבר לגיבוי (failover) מועדפת. האפליקציות צריכות להתחבר מחדש למסד הנתונים הראשי החדש כדי להמשיך לגשת למצב שלהן. אם מסד הנתונים הראשי החדש לא היה מסונכרן עם המצב האחרון הידוע של מסד הנתונים הראשי הקודם, האפליקציה מתחילה ממצב קודם (שנקרא גם חזרה למצב קודם).
חשוב שתהיה לכם לפחות מסד נתונים משני אחד בכל רגע נתון לכל מסד נתונים ראשי. אחרי התאוששות מאסון, חשוב לוודא שמגדירים מסד נתונים משני חדש כדי לטפל בתרחישים עתידיים של התאוששות מאסון.
מעבר לגיבוי, מעבר לגיבוי פעיל וחזרה לגיבוי
יש כמה תרחישים שבהם אפשר לשנות את התפקיד בין מסדי נתונים ראשיים למסדי נתונים משניים:
- מעבר לגיבוי (Failover): תהליך שבו משנים את התפקיד של מסד נתונים משני כך שיהפוך למסד הנתונים הראשי החדש, ומקשרים אליו את כל האפליקציות. המעבר לגיבוי הוא לא מכוון כי הוא מופעל כשמסד נתונים ראשי הופך ללא זמין. אתם יכולים להגדיר שהמעבר לגיבוי יופעל באופן אוטומטי או ידני.
- מעבר לגיבוי (Switchover): בניגוד למעבר אוטומטי לגיבוי (Failover), מעבר לגיבוי ממסד נתונים ראשי למסד נתונים משני (מסד נתונים ראשי חדש) מופעל בכוונה לצורך בדיקה ראשונית ותחזוקה מתוזמנת. כדי להבטיח את המשך האמינות של ההתאוששות מאסון, מומלץ לבדוק את מערכת ה-DR באמצעות מעבר גיבוי לשחזור תקופתי קבוע.
- חזרה למצב הקודם: חזרה למצב הקודם היא היפוך התהליך שבו מסד הנתונים הראשי החדש הופך למסד הנתונים המשני, אחרי שמסד הנתונים הראשי תוקן. הפעלה של מעבר לגיבוי (failover) או מעבר בין שרתים (switchover) גורמת להפעלה מכוונת של חזרה למצב הקודם, כדי לשחזר את המצב לפני שהמעבר התחיל. הפעולה הזו לא הכרחית, אבל אפשר לבצע אותה בהתאם לדרישות של תוכנית התאוששות מאסון (DR), כמו רשות מוניציפאלית או משאבים זמינים.
Google Cloud אזורים ותחומים
משאבים כמו מסדי נתונים ממוקמים בGoogle Cloud אזורים ותחומים, כאשר כל תחום שייך לאזור. אזור הוא דומיין כשל. מומלץ לפרוס משאב עם זמינות גבוהה ועמיד בכשלים בכמה אזורים בתוך אזור.
כדי להתגונן מפני הפסקה זמנית בשירות באזור שלם, צריך ליצור אסטרטגיות לתוכנית התאוששות מאסון (DR) במספר אזורים. לדוגמה, מסד הנתונים הראשי ממוקם באזור אחד ומסד הנתונים המשני התואם ממוקם באזור אחר.
מצבים פעילים: פעיל-סביל ופעיל-פעיל
מסד נתונים ראשי הוא מסד נתונים שפתוח לפעולות קריאה וכתיבה (פעולות DML) כדי שאפליקציות שגולשות בו יוכלו לנהל את המצב שלהן. מסד הנתונים הראשי נקרא מסד נתונים פעיל. מסד הנתונים המשני התואם הוא פסיבי כי הוא משכפל את מסד הנתונים הראשי, אבל הוא לא זמין לאף אפליקציה לפעולות של שינוי מצב. אחרי מעבר לגיבוי או מעבר פעיל, מסד הנתונים המשני הופך למסד הנתונים הראשי החדש והוא הופך למסד נתונים פעיל.
גם מסד הנתונים הראשי וגם מסד הנתונים המשני יכולים להיות מסדי נתונים פעילים אם טכנולוגיית מסד הנתונים תומכת בתכונה הזו, שנקראת מצב פעיל-פעיל. במקרה כזה, האפליקציות יכולות להתחבר לאחת מהן כי שתי מסדי הנתונים זמינים לניהול מצב. תוכנית התאוששות מאסון במצב פעיל-פעיל לא דורשת יתירות כשל אם רק אחד ממסדי הנתונים הפעילים הופך ללא זמין. אם מסד נתונים פעיל אחד לא זמין, מסד הנתונים הפעיל השני ממשיך להיות זמין. מצב פעיל-פעיל לא נכלל במאמר הזה כי SQL Server לא תומך במצב הזה.
מצבי המתנה: חם, פושר, קר וללא המתנה
כדי שמסד הנתונים הראשי יהיה מסד הנתונים הפעיל, הוא צריך לפעול ולהיות מסוגל להריץ הצהרות DML. מסד הנתונים המשני לא צריך לפעול, אפשר להשבית אותו. אם הוא לא פועל, הזמן שנדרש להתאוששות מאסון מתארך כי צריך להפעיל קודם את מסד הנתונים הראשי החדש לפני שהוא מקבל את התפקיד של מסד הנתונים הראשי החדש.
יש כמה וריאציות להגדרת מסד הנתונים המשני:
- המתנה פעילה: מסד הנתונים המשני פועל ומוכן לחיבור של לקוחות. השינוי האחרון שזמין ממסד הנתונים הראשי תמיד מוחל ברגע שהוא זמין.
- המתנה חמה: מסד נתונים משני פועל, אבל לא כל השינויים ממסד הנתונים הראשי הוחלו עליו.
- המתנה קרה: מסד נתונים משני לא פועל. קודם צריך להפעיל אותו, ואז לסנכרן אותו למצב העדכני ביותר שזמין.
- ללא מצב המתנה: צריך להתקין את תוכנת מסד הנתונים קודם, ואז להפעיל אותה לפני שכל השינויים ממסד הנתונים הראשי יחולו. המצב הזה הוא הכי פחות יקר כי הוא לא צורך משאבים כשאין צורך, אבל בהשוואה למצבים אחרים, לוקח הכי הרבה זמן להפוך למסד נתונים ראשי חדש.
אסטרטגיות DR
בקטעים הבאים מוסברות אסטרטגיות DR שנתמכות ב-Microsoft SQL Server.
מאפיינים של אסטרטגיית התאוששות
יש כמה היבטים חשובים שכדאי להביא בחשבון כשבוחרים או מטמיעים אסטרטגיה של התאוששות מאסון (DR) במסד נתונים. לכל מאפיין יש ספקטרום, וההתנהגות והציפיות של תוכנית התאוששות מאסון (DR) תלויות בבחירת הנקודות בספקטרום. אלה המאפיינים העיקריים:
- יעד להתאוששות מאסון (RPO): משך הזמן המקסימלי המקובל שבמהלכו יכול להיות שאבדו נתונים מהאפליקציה בגלל אירוע משמעותי. המאפיין הזה משתנה בהתאם לדרכים שבהן נעשה שימוש בנתונים. אפשר להגדיר את ה-RPO כמשך זמן (שניות, דקות או שעות) מרגע שהמסד הנתונים הראשי לא זמין, או כמצבי עיבוד שניתן לזהות (הגיבוי המלא האחרון או הגיבוי המצטבר האחרון). לא משנה איך מצוין ה-RPO, אסטרטגיית ההתאוששות מאסון חייבת להטמיע את המדד הספציפי כדי לעמוד בדרישת ה-RPO. המקרה הכי תובעני הוא העסקה האחרונה שאושרה, כלומר לא יכול להיות אובדן נתונים מהמסד הנתונים הראשי למסד הנתונים המשני.
- יעד משך ההתאוששות (RTO). משך הזמן המקסימלי שבו האפליקציה יכולה להיות במצב אופליין. הערך הזה מצוין בדרך כלל כחלק מהסכם רמת שירות גדול יותר. בדרך כלל, RTO מבוטא במונחים של משך הזמן מרגע שהמסד הנתונים הראשי לא זמין. לדוגמה, האפליקציה צריכה להיות פעילה באופן מלא תוך 5 דקות. הדרישה הכי גבוהה היא מיידית, כדי שמשתמשי האפליקציה לא יבחינו בכך שהתבצע שחזור לאחר אסון.
- דומיין כשל בודד. אתם מחליטים אם אזור נחשב לנקודת כשל בודדת בדומיין כשל בהתאם לדרישות שלכם להתאוששות מאסון. אם אזור מסוים הוא דומיין כשל עבורכם, צריך להגדיר תוכנית התאוששות מאסון (DR) כך ששני אזורים או יותר יהיו מעורבים בהגדרה בפועל. אם האזור שמכיל את מסד הנתונים הראשי נכשל, מסד הנתונים המשני באזור אחר הופך למסד הנתונים הראשי החדש. אם מניחים שדומיין הכשל הבודד הוא אזור, אפשר להגדיר תוכנית התאוששות מאסון (DR) באזורים שונים בתוך אזור יחיד. אם אזור נכשל, תוכנית התאוששות מאסון (DR) משתמשת באזור שני ומאפשרת גישה למסד הנתונים הראשי החדש.
ההחלטה לגבי המאפיינים העיקריים האלה היא למעשה החלטה בין עלות לאיכות. ככל שערכי ה-RTO וה-RPO נמוכים יותר, כך פתרון התאוששות מאסון (DR) עלול להיות יקר יותר, כי נעשה שימוש ביותר משאבים פעילים. בסעיפים הבאים נדון בכמה אסטרטגיות חלופיות להתאוששות מאסון, שמייצגות נקודות בממדים בהקשר של מסד הנתונים של Microsoft SQL Server.
אסטרטגיות DR ל-SQL Server
המשכיות עסקית ושחזור מסד נתונים – SQL Server מתאר תכונות זמינות שבהן אפשר להשתמש כדי ליישם אסטרטגיות של התאוששות מאסון (DR).
מוקדמות
שרת SQL פועל גם ב-Windows וגם ב-Linux. עם זאת, לא כל התכונות שקשורות לזמינות זמינות ב-Linux. ל-SQL Server יש כמה מהדורות, אבל לא כל התכונות שקשורות לזמינות זמינות בכל מהדורה.
ב-SQL Server יש הבחנה בין מכונות לבין מסדי נתונים. מופע הוא תוכנת SQL Server שפועלת, ומסד נתונים הוא קבוצת הנתונים שמנוהלת על ידי מופע של SQL Server.
קבוצות זמינות Always On
קבוצות זמינות Always On מספקות הגנה ברמת מסד הנתונים. קבוצת זמינות כוללת שני עותקים משוכפלים או יותר. עותק אחד הוא העותק הראשי עם גישת קריאה וכתיבה, והעותקים הנותרים הם עותקים משניים שיכולים לספק גישת קריאה. כל רפליקה של מסד הנתונים מנוהלת על ידי מופע SQL Server עצמאי. קבוצת זמינות יכולה להכיל מסד נתונים אחד או יותר. מספר מסדי הנתונים שאפשר לכלול בקבוצת זמינות ומספר העותקים המשניים הנתמכים תלויים במהדורת SQL Server. כל מסדי הנתונים בקבוצת זמינות עוברים את אותם שינויים במחזור החיים באותו הזמן. קבוצות הזמינות מיישמות את המצב הפעיל-סביל כי רק מסד הנתונים הראשי תומך בגישת כתיבה.
כשמתרחש מעבר לגיבוי, עותק משני הופך לעותק הראשי החדש. קבוצת זמינות כוללת מכונות עצמאיות של SQL Server, ולכן כל הפעולות שמתועדות ביומני העסקאות זמינות בעותקים המשוכפלים. כל שינוי שלא נרשם ביומן טרנזקציות צריך לסנכרן באופן ידני, למשל התחברויות ברמת המופע של SQL Server או משימות של SQL Server Agent. כדי לספק הגנה ברמת מסד הנתונים והגנה על מופע SQL Server, צריך להגדיר מופעים של Failover Cluster Instances (FCIs). ארכיטקטורת הפריסה הזו מוסברת בהמשך בקטע Always On Failover Cluster Instance.
אפשר להגן על אפליקציות מפני שינויים בתפקידים באמצעות listener. פונקציית listener תומכת באפליקציות שמתחברות לקבוצת הזמינות. האפליקציות לא יודעות אילו מופעים של SQL Server מנהלים את מסד הנתונים הראשי או את העותקים המשניים בכל נקודת זמן. כדי להשתמש ב-Listeners, הלקוחות צריכים להשתמש בגרסה מינימלית של .NET 3.5 עם עדכון או בגרסה 4.0 ומעלה, כמו שמתואר במאמר Business continuity and database recovery - SQL Server.
קבוצות הזמינות מסתמכות על שכבות הפשטה בסיסיות כדי לספק את הפונקציונליות שלהן. קבוצות זמינות פועלות באשכול מעבר לגיבוי בעת כשל של Windows Server (WSFC) כמו שמתואר במאמר מעבר לגיבוי בעת כשל של Windows Server עם SQL Server. כל הצמתים שמריצים מופעים של SQL Server צריכים להיות חלק מאותו WSFC.
העסקאות נשלחות ממסד הנתונים הראשי לכל העותקים המשניים. יש שני מצבי שליחה לשליחת טרנזקציות: סינכרוני ואסינכרוני. אפשר להגדיר כל רפליקה בנפרד כך שתשתמש באחד מהמצבים. במצב השליחה הסינכרוני, העסקה במסד הנתונים הראשי מצליחה רק אם היא מצליחה בכל העותקים המשניים המשוכפלים שמקושרים באופן סינכרוני. במצב האסינכרוני, העסקה במסד הנתונים הראשי יכולה להצליח גם אם לא כל העותקים המשניים כוללים את העסקה.
הבחירה שלכם במצב השליחה משפיעה על ה-RTO, ה-RPO ומצב ההמתנה האפשריים. לדוגמה, אם העסקאות נשלחות לכל העותקים במצב סינכרוני, כל העותקים נמצאים באותו מצב בדיוק. ה-RPO הכי גבוה (העסקה האחרונה) מתבצע כי כל העותקים מסונכרנים באופן מלא. העותקים המשניים הם עותקים חמים, כך שאפשר להשתמש בכל אחד מהם באופן מיידי כבסיס נתונים ראשי.
יתירות כשל יכולה להיות אוטומטית או ידנית. מעבר אוטומטי ליתירות כשל אפשרי אם כל הרפליקות מסונכרנות במלואן. בדוגמה הקודמת, זה אפשרי כי כל העותקים תמיד מסונכרנים באופן מלא.
באיור הבא מוצגת קבוצת זמינות Always On באזור יחיד.
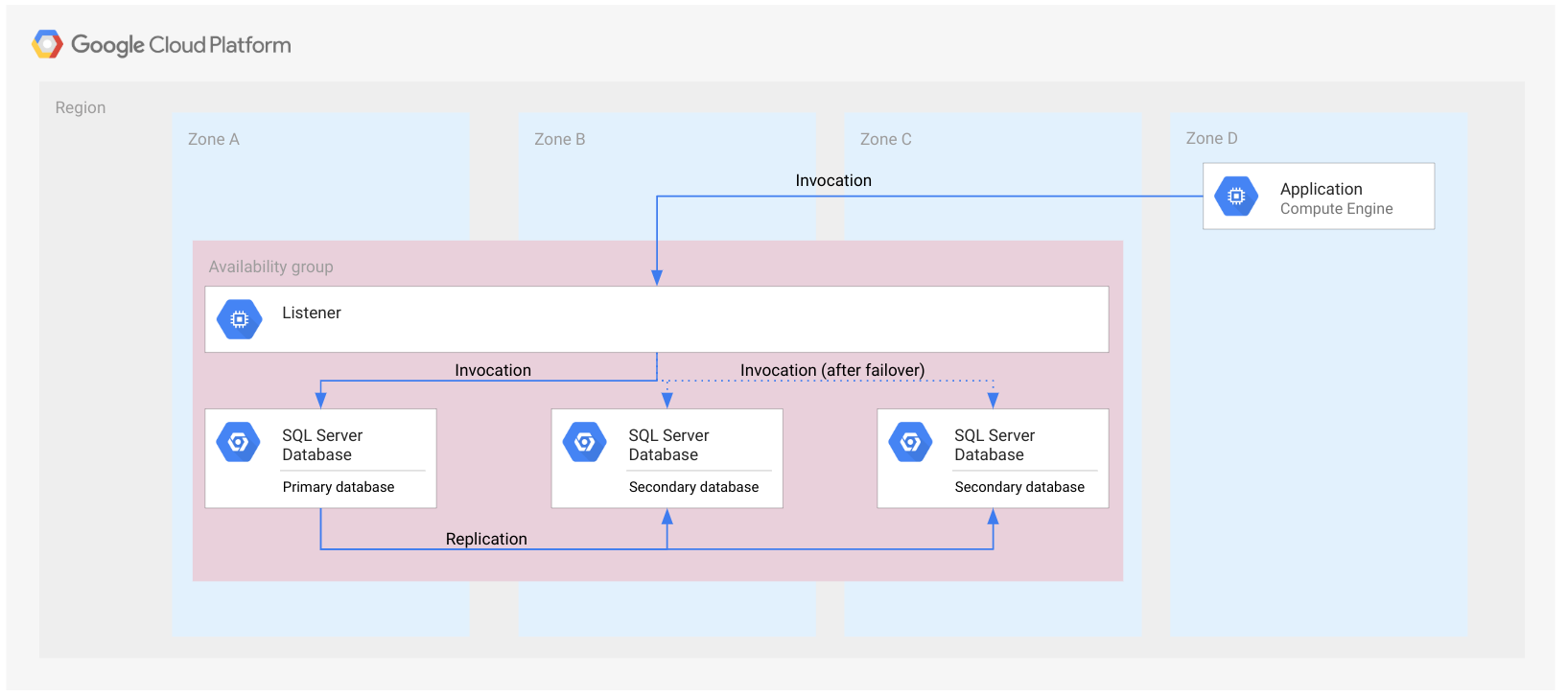
קבוצת הזמינות מיוצגת כמלבן שחוצה אזורים. התמונה הזו מיועדת להמחשה בלבד, כדי להראות שכל מסדי הנתונים שייכים לאותה קבוצת זמינות. קבוצת הזמינות היא לא משאב בענן, ולכן היא לא מיושמת בצומת או בסוג אחר של משאב.
Always On Failover Cluster Instance
כדי להגן על עצמכם מפני כשלים בצמתים, אתם יכולים להשתמש במופעי Failover Cluster (FCI) במקום במופעי SQL Server עצמאיים. יש שני צמתים או יותר שמריצים מופעים של SQL Server כדי לנהל מסד נתונים (ראשי או משני). הצמתים שמנהלים מסד נתונים יוצרים אשכול מעבר לגיבוי. צומת אחד באשכול מריץ באופן פעיל מופע של SQL Server, בעוד שהצמתים האחרים לא מריצים מופעים של SQL Server. כשהצומת שמריץ את המכונה של SQL Server נכשל, צומת אחר באשכול מפעיל מכונה של SQL Server ומקבל את הניהול של מסד הנתונים (מעבר לגיבוי בענן של צומת). התהליך הזה של הפעלה אוטומטית של מופע SQL Server מספק פונקציונליות של זמינות גבוהה.
אשכול ה-FCI מופיע כיחידה אחת, והלקוחות שניגשים לאשכול לא רואים את המעבר לגיבוי בין הצמתים, אלא אם כן מדובר בתקופה קצרה של חוסר זמינות. לא מתרחש אובדן נתונים כשמתבצעת העברה אוטומטית של שירותים (failover) בין צמתים. כל מה שפועל בתוך מופע SQL Server שנכשל מועבר למופע אחר של SQL Server באותו אשכול. לדוגמה, משימות של SQL Server Agent או שרתים מקושרים מועברים למופע אחר.
אפשר להגדיר צמתים של אשכול FCI באזורים שונים. Google Cloud הארכיטקטורה הזו מספקת זמינות גבוהה לא רק במקרה של כשל בצומת, אלא גם במקרה של כשל באזור. דוגמה לפריסה של האסטרטגיה הזו מופיעה בקטע חלופות לפריסת DR.
למרות שצמתים שונים מנהלים את אותו מסד נתונים ומשתפים את מסד הנתונים, לא נדרש אחסון משותף בין הצמתים של אשכול FCI. SQL Server משתמש בפונקציונליות של Storage Spaces Direct (S2D) כדי לנהל מסדי נתונים בדיסקים של צמתים ייעודיים. מידע נוסף זמין במאמר בנושא הגדרת מופעים של אשכולות יתירות כשל של SQL Server.
בדוגמה של הקטע הקודם Always On availability groups מוצגים FCIs במקום מופעים עצמאיים של SQL Server. הדוגמה מוצגת באיור הבא. לכל FCI יש מופע פעיל אחד של SQL Server שמנהל את מסד הנתונים.
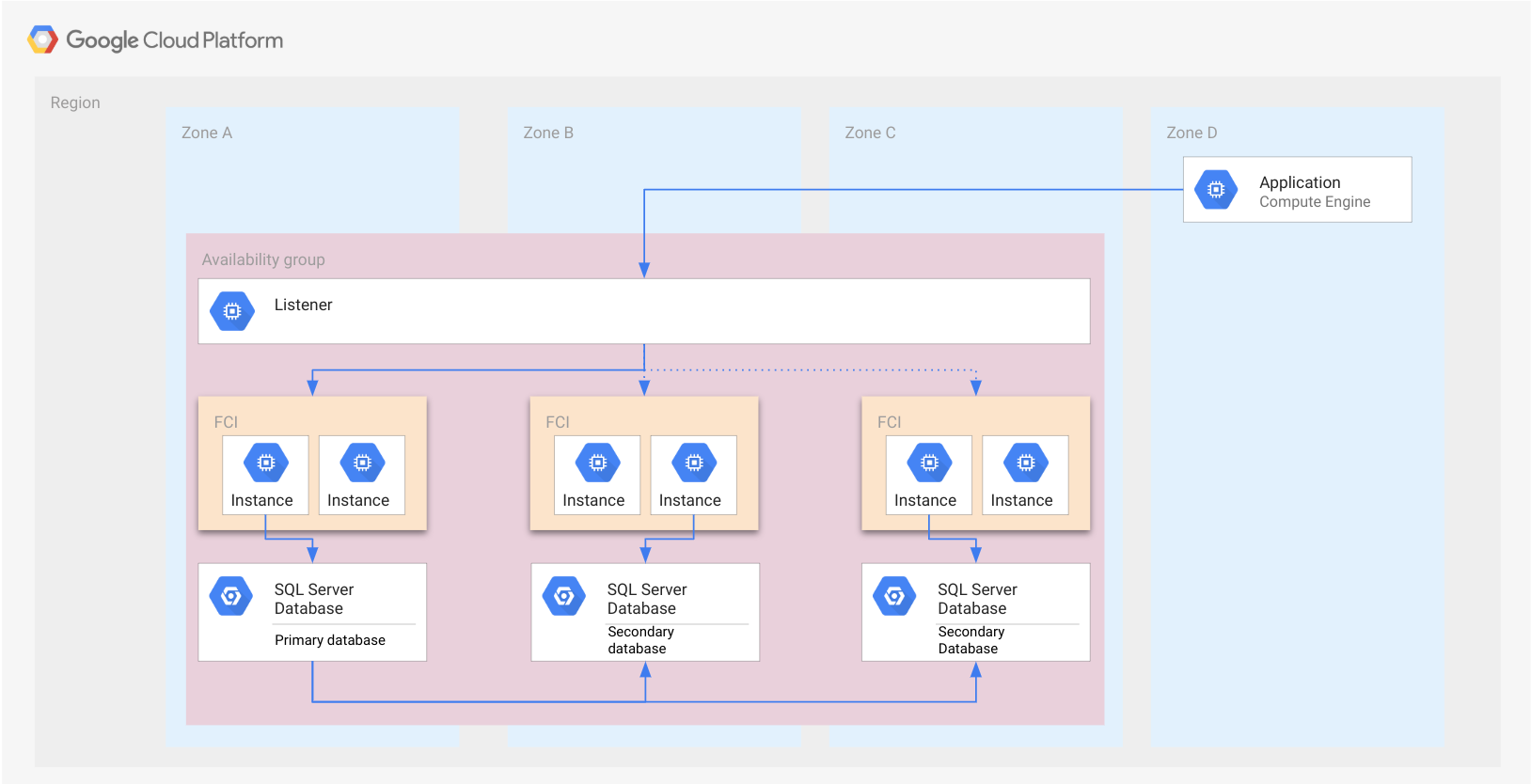
בדומה לקבוצת הזמינות, ה-FCI מיוצג כמלבן. התמונה הזו מיועדת להמחשה בלבד, כדי להראות שכל הצמתים שייכים לאותו FCI. ממשק FCI הוא לא משאב בענן, ולכן הוא לא מיושם בצומת או בכל סוג אחר של משאב.
לדיון מפורט יותר, אפשר לעיין במאמר בנושא Always On Failover Cluster Instances (SQL Server).
קבוצות זמינות מבוזרות
קבוצות זמינות מבוזרות הן סוג מיוחד של קבוצות זמינות. קבוצת זמינות מבוזרת משתרעת על שתי קבוצות זמינות, אחת בתפקיד של קבוצת הזמינות הראשית ואחת בתפקיד של קבוצת הזמינות המשנית. קבוצות זמינות מבוזרות יכולות להעביר עסקאות במצב סינכרוני וגם במצב אסינכרוני מקבוצת הזמינות הראשית לקבוצת הזמינות המשנית.
למרות שלכל קבוצת זמינות יש מסד נתונים ראשי משלה, זה לא פריסה פעילה-פעילה. רק מסד הנתונים הראשי של קבוצת הזמינות הראשית יכול לקבל פעולות כתיבה. מסד הנתונים הראשי של קבוצת הזמינות המשנית נקרא forwarder. השרת להעברת נתונים מקבל את העסקאות מקבוצת הזמינות הראשית ומעביר אותן למסדי הנתונים המשניים של קבוצת הזמינות המשנית. אם מתבצע מעבר לגיבוי במקרה של כשל מקבוצת הזמינות הראשית לקבוצת הזמינות המשנית, מסד הנתונים הראשי של קבוצת הזמינות הראשית החדשה יהיה נגיש לפעולות כתיבה.
קבוצות הזמינות הראשיות והמשניות לא חייבות להיות באותו מיקום ולא באותה מערכת הפעלה. עם זאת, לכל קבוצת זמינות צריך להתקין מאזין. לקבוצת הזמינות המבוזרת עצמה אין מאזין. קבוצות זמינות מבוזרות לא מחייבות ששתי קבוצות הזמינות יהיו באותו WSFC. כל הפונקציונליות שנדרשת כדי להפעיל קבוצות זמינות מבוזרות כלולה בפונקציונליות של SQL Server, ולא נדרשת התקנה נוספת של רכיבים בסיסיים.
קבוצת זמינות מבוזרת משתרעת על שתי קבוצות זמינות בדיוק. קבוצת זמינות יכולה להיות חלק משתי קבוצות זמינות מבוזרות. האפשרות הזו תומכת בטופולוגיות שונות. אחת מהן היא טופולוגיה של שרשור מ-availability group ל-availability group בכמה מיקומים. טופולוגיה נוספת היא טופולוגיה דמוית עץ שבה קבוצת הזמינות הראשית היא חלק משתי קבוצות זמינות מבוזרות שונות ונפרדות.
קבוצות זמינות מבוזרות הן האמצעי העיקרי להטמעת התאוששות מאסון במערכות הפעלה שונות. לדוגמה, אפשר להגדיר את קבוצת הזמינות הראשית ב-Windows, וקבוצת זמינות שנייה תואמת ב-Linux, כך ששתי קבוצות הזמינות יחד יוצרות קבוצת זמינות מבוזרת.
בתרשים הבא מוצגות שתי קבוצות זמינות שמהוות חלק מקבוצת זמינות מבוזרת.
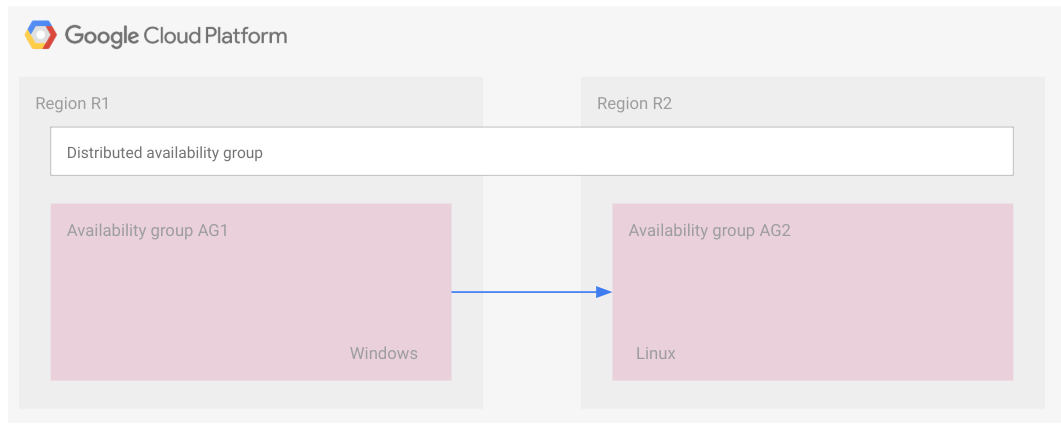
קבוצת הזמינות 1 היא קבוצת הזמינות הראשית וקבוצת הזמינות 2 היא קבוצת הזמינות המשנית.
בדומה למקרה של ה-FCI, קבוצת זמינות מבוזרת מיוצגת כמלבן. הדוגמה הזו מיועדת להמחשה בלבד, כדי להראות שכל קבוצות הזמינות שייכות לאותה קבוצת זמינות מבוזרת. קבוצת זמינות מבוזרת, כמו קבוצת זמינות, היא לא משאב בענן ולכן היא לא מיושמת בצומת או בכל סוג אחר של משאב.
מידע נוסף זמין במאמר בנושא קבוצות זמינות מבוזרות.
העברת יומנים
שליחת יומן טרנזקציות היא תכונת זמינות של SQL Server כשמגבלות ה-RTO וה-RPO לא מחמירות מדי (RTO נמוך או RPO עדכני), כי הפער במצב בין מסד נתונים ראשי לבין מסד נתונים משני גדול משמעותית. הפער גדול יותר מבחינת המצב, כי קובץ יומן טרנזקציות מכיל הרבה שינויים במצב. הפער גדול יותר גם מבחינת זמן ההשהיה, כי קובצי יומן הטרנזקציות מועברים באופן אסינכרוני וצריך להחיל אותם במלואם על מסד נתונים משני.
קובצי יומן טרנזקציות נוצרים על ידי מסד הנתונים הראשי ומגובים, למשל ב-Cloud Storage. כל קובץ של יומן עסקאות מועתק לכל מסד נתונים משני ומוחל עליו. מכיוון שהמסד הנתונים המשני מפגר אחרי מסד הנתונים הראשי, הם במצב המתנה פעיל. צריך להחיל באופן ידני על מסדי הנתונים המשניים אובייקטים ושינויים שלא נרשמים ביומני הטרנזקציות, כדי ליצור סנכרון מלא ללא אובדן נתונים.
הסוכן של SQL Server מבצע אוטומציה של התהליך הכולל של יצירה, העתקה והחלה של יומני טרנזקציות. צריך להגדיר את העברת היומנים לכל מסד נתונים בנפרד. אם קבוצת זמינות מנהלת יותר ממסד נתונים אחד, צריך להגדיר מספר תהליכים של העברת יומנים.
במקרה של כשל, צריך להפעיל את תהליך השחזור מאסון באופן ידני, כי אין תמיכה אוטומטית. בנוסף, הגישה של הלקוח לא מופרדת ממסד הנתונים הראשי וממסדי הנתונים המשניים על ידי מאזין. במקרה של יתירות כשל, הלקוחות צריכים להיות מסוגלים להתמודד עם שינוי התפקיד של מסד נתונים מהתפקיד המשני לתפקיד הראשי החדש בעצמם, על ידי התחברות לראשי החדש אחרי תוכנית התאוששות מאסון (DR). אפשר ליצור הפשטות נפרדות באופן עצמאי ממופעים של SQL Server, למשל, כתובות IP צפות כמו שמתואר במאמר שיטות מומלצות לשימוש בכתובות IP צפות.
תהליך העברת היומנים הוא בחלקו ידני, ולכן אפשר בכוונה לדחות את ההחלה של קובצי היומן שהועתקו על מסדי הנתונים המשניים (בניגוד לקבוצות זמינות ולקבוצות זמינות מבוזרות, שבהן השינויים מוחלים באופן מיידי). תרחיש שימוש אפשרי הוא מניעת החלת שגיאות בשינוי נתונים במסד הנתונים הראשי על מסדי נתונים משניים עד לטיפול בשגיאות בשינוי הנתונים. במקרה כזה, מסד נתונים משני שעליו עדיין לא חלה שגיאה בשינוי הנתונים יכול להפוך למסד הנתונים הראשי עד שהשגיאה בשינוי הנתונים תטופל. אחרי כן, אפשר להמשיך בעיבוד הרגיל.
בדומה למקרה של קבוצות זמינות מבוזרות, אפשר להשתמש בהעברת יומנים (Log Shipping) לפתרונות בפלטפורמות שונות, שבהם, לדוגמה, מסד הנתונים הראשי פועל ב-Linux ומסדי הנתונים המשניים פועלים ב-Linux וב-Windows.
הדיאגרמה הבאה ממחישה פריסה בפלטפורמות שונות עם העברת יומנים. חשוב לשים לב שאין הגדרה משותפת בין האזורים, כמו קבוצת זמינות מבוזרת בטופולוגיה הזו.
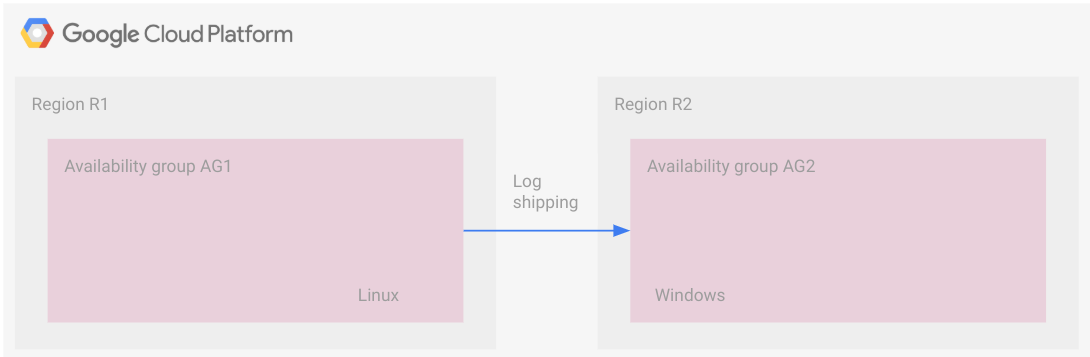
קבוצות הזמינות נמצאות באזורים נפרדים, אחת פועלת ב-Linux והשנייה ב-Windows.
מידע נוסף על העברת יומנים ב-SQL Server זמין במאמר About Log Shipping (SQL Server).
שילוב של תכונות הזמינות ב-SQL Server
אפשר לפרוס תכונות זמינות של SQL Server בשילובים שונים. לדוגמה, בתרחיש השימוש הקודם, נעשה שימוש במשלוח יומנים עם קבוצות זמינות שונות שהותקנו במערכות הפעלה שונות.
רשימה של שילובים אפשריים של תכונות הזמינות של שרת SQL:
- שימוש בהעברת יומנים בין קבוצות זמינות שמותקנות באותה מערכת הפעלה.
- יש קבוצת זמינות ראשית שמשתמשת ב-FCI עם קבוצת זמינות משנית שמשתמשת רק במופעים עצמאיים של SQL Server.
- להשתמש בקבוצת זמינות מבוזרת בין אזורים סמוכים, ולרשום את המשלוחים בין אזורים שנמצאים ביבשות שונות.
אלה רק חלק מהשילובים האפשריים של תכונות הזמינות של SQL Server.
הגמישות של תכונות הזמינות ב-SQL Server מאפשרת לבצע כוונון עדין של אסטרטגיית התאוששות מאסון (DR) בהתאם לדרישות שצוינו.
שכפול של SQL Server
רפליקציה של SQL Server לא נחשבת בדרך כלל לתכונת זמינות, אבל בקטע הזה מתואר בקצרה איך אפשר להשתמש בתכונה הזו לתוכנית התאוששות מאסון (DR).
תכונת השכפול תומכת ביצירה ובתחזוקה של עותקים של מסדי נתונים. סוגים שונים של סוכני SQL Server משתפים פעולה כדי לתעד שינויים, להעביר את השינויים המתועדים ולהחיל אותם על העותקים. התהליך הזה הוא אסינכרוני, ובדרך כלל יש פערים בין העותקים לבין מסד הנתונים המשוכפל.
לדוגמה, אפשר ליצור רפליקה של מסד נתונים של Production. במונחים של תוכנית התאוששות מאסון (DR), מסד הנתונים של הייצור הוא מסד הנתונים הראשי והרפליקה היא מסד הנתונים המשני. תכונת השכפול של SQL Server לא יודעת שהמסדי נתונים מקבלים תפקידים שונים בהקשר של התאוששות מאסון. לכן, אין שכפול של פעולות שתומכות בתהליך של התאוששות מאסון, למשל שינויים בהרשאות. תהליך התאוששות מאסון צריך להתבצע בנפרד מהפונקציונליות של SQL Server, והארגון שמטמיע את התהליך צריך להפעיל אותו כי אין הפשטות של גישת לקוח.
משלוח של קובץ גיבוי
אפשרות נוספת לגיבוי היא משלוח של קובץ הגיבוי, כחלק מתוכנית התאוששות מאסון (DR). גישה סטנדרטית להגדרה ולעדכון מתמשך של מסד נתונים משני היא ביצוע גיבוי מלא ראשוני של מסד הנתונים הראשי, ולאחר מכן גיבויים מצטברים שלו. כל הגיבויים המצטברים מוחלים על מסדי נתונים משניים בסדר הנכון. יש הרבה וריאציות לגישה הזו, בהתאם לתדירות של הגיבויים המצטברים ולמיקום האחסון של קובץ הגיבוי (מיקום גלובלי או העתקה בין מיקומים).
השיטה הזו לא כוללת תכונת זמינות של SQL Server כשמשכפלים שינויים במצב ממסד הנתונים הראשי לכל מסד נתונים משני. הוא לא משתמש ב-SQL Server Agent שמשמש במקרה של העברת יומנים.
מידע נוסף זמין בקטע דוגמה: אסטרטגיה לגיבוי ושחזור לצורך התאוששות מאסון.
בהשוואה לגישת השכפול שנדונה בקטע הקודם, גם שכפול וגם משלוח קובצי גיבוי משותפים בכך שתהליך ההתאוששות מאסון (DR) מיושם מחוץ לסט התכונות של SQL Server ובנפרד ממנו. מבחינת העברת השינויים שתועדו, שכפול של SQL Server נוח יותר כי הוא מבצע את החלק הזה באופן אוטומטי באמצעות סוכני SQL Server.
הערה לגבי האינטראקציה בין מחזור החיים של מסד הנתונים לבין מחזור החיים של האפליקציה
מעבר לגיבוי בעקבות כשל במסד נתונים לא נפרד לחלוטין מהאפליקציות שגשת למסד הנתונים, ולא מתבצע באופן עצמאי. באופן עקרוני, יש שני תרחישי כשל.
קודם כל, האפליקציה ממשיכה לפעול בזמן שהמסד נתונים עובר לגיבוי. מהרגע שבו מסד הנתונים הראשי לא זמין ועד שמסד הנתונים הראשי החדש מתחיל לפעול, לאפליקציות אין גישה למסד הנתונים בכלל. חיבורים קיימים נכשלים ולא נוצרים חיבורים חדשים. במהלך הזמן הזה, האפליקציה לא יכולה לשרת את הלקוחות שלה, לפחות במידה שבה הפונקציונליות דורשת גישה למסד הנתונים. האפליקציות צריכות לזהות מתי מסד הנתונים הראשי החדש זמין, כדי שיוכלו להמשיך את העיבוד הרגיל.
יכול להיות שהאפליקציות יכללו מצב מחוץ למסד הנתונים, למשל במטמון של הזיכרון הראשי. האפליקציה מוודאת שהמטמון עקבי (מסונכרן) עם מסד הנתונים הראשי החדש. אם לא היה אובדן של עסקאות כלל במהלך יתירות כשל, יכול להיות שהמטמון יהיה עקבי ללא תחזוקה נוספת. עם זאת, אם אירע אובדן נתונים של טרנזקציות במהלך יתירות כשל, יכול להיות שהמטמון לא יהיה עקבי ביחס למסד הנתונים הראשי החדש. דיון דומה מתקיים לגבי מצב משותף, למשל, כשחלק מהנתונים במסד הנתונים הם גם חלק מהודעות בתורים או מקבצים במערכת הקבצים. היבט זה של עקביות הנתונים לא נכלל במסגרת המסמך הזה, כי הוא לא קשור ישירות לתוכנית התאוששות מאסון (DR) של מסד נתונים.
שנית, יכול להיות שאפליקציה אחת או יותר לא יהיו זמינות באותו זמן שבו מסד הנתונים הראשי לא יהיה זמין. לדוגמה, אם אזור מסוים עובר למצב אופליין, מערכת אפליקציות שפועלת באזור הזה לא תהיה זמינה, בדיוק כמו מסד הנתונים הראשי באותו אזור. במקרה כזה, צריך לשחזר גם את האפליקציה, ולא רק את מערכת מסד הנתונים הראשית. בנוסף לתהליך שחזור מסד הנתונים, צריך להתחיל תהליך שחזור אפליקציה דומה. האפליקציה ששוחזרה צריכה להתחבר למסד הנתונים הראשי החדש ולהיות מוגדרת מחדש (לדוגמה, כתובות IP צפות). שחזור אפליקציות לא נכלל במסמך הזה.
הקשר בין גיבוי ושחזור לבין תוכנית התאוששות מאסון (DR)
גיבוי של מסד נתונים הוא תהליך עצמאי ואורתוגונלי לתוכנית התאוששות מאסון של מסד הנתונים. מטרת הגיבוי של מסד הנתונים היא לאפשר שחזור של מצב עקבי, למשל אם מסד הנתונים אבד או נפגם, או אם צריך לשחזר מצב קודם בגלל כשלים או באגים באפליקציה.
בקטע הבא מוסבר איך אפשר להשתמש בגיבויים כמנגנון אפשרי להטמעה של תוכנית התאוששות מאסון (DR) של מסד נתונים. בתרחיש הזה, מעתיקים קובצי גיבוי למיקום של מסד הנתונים המשני כדי שאפשר יהיה לשחזר את מסד הנתונים המשני. עם זאת, קובצי גיבוי הם לא תנאי מוקדם לשחזור אחרי אסון. בדיון הקודם על תכונות הזמינות הוצגו חלופות.
זמינות גבוהה ותוכנית התאוששות מאסון (DR)
גם בזמינות גבוהה וגם בתוכנית התאוששות מאסון (DR), הפתרונות נועדו לטפל במקרים שבהם מסד הנתונים לא זמין. אם מסד נתונים ראשי הופך ללא זמין, מסד נתונים משני הופך למסד הנתונים הראשי החדש, והוא עקבי וזמין.
ההבדל בין זמינות גבוהה לבין התאוששות מאסון הוא דומיין הכשל של נקודת הכשל הבודדת. זמינות גבוהה מטפלת בהפסקת שירות באזור מסוים, למשל כשמתרחשת כשל באזור יחיד או בצומת. פתרון של זמינות גבוהה מספק מסד נתונים ראשי חדש באזור אחר באותו אזור. בנוסף, זמינות גבוהה מטפלת בכשלים של צמתים, ולא רק בכשלים של מסדי נתונים. אם צומת שמריץ מופע של SQL Server נכשל, צומת חדש הופך לזמין ומריץ מופע חדש של SQL Server (ראו את הדיון בקטע Always On Failover Cluster Instance).
תוכנית התאוששות מאסון (DR) כוללת לפחות שני אזורים. הוא מתייחס למצב שבו אזור שלם הופך ללא זמין. תוכנית התאוששות מאסון (DR) יכולה לספק מסד נתונים ראשי חדש באזור אחר.
תכונות הזמינות הגבוהה של SQL Server תומכות בפתרונות לזמינות גבוהה ולהתאוששות מאסון בו-זמנית. קבוצת זמינות אחת יכולה לכלול את האזורים בתוך אזור מסוים, וגם אזורים שונים. קבוצת זמינות יכולה להכיל מקרים של אשכולות מעבר לגיבוי במקרה של כשל כדי לטפל בזמינות גבוהה.
SQL Server יכול ליצור קבוצות זמינות באזור אחד כדי להשיג זמינות גבוהה ולטפל בכשלים באזור, ולשלב את זה עם העברת יומנים בין אזורים כדי לטפל בתוכנית התאוששות מאסון (DR).
חלופות לפריסת DR
בקטעים הבאים מוצגות כמה טופולוגיות אפשריות להתאוששות מאסון, בנוסף לאלה שנדונו עד עכשיו. הטופולוגיות האלה עומדות בדרישות שונות של RPO ו-RTO. זו רשימה חלקית.
DR ו-HA בתוך אזור
הפריסה הזו היא וריאציה של קבוצת זמינות שמכילה FCIs, בתוך אזור שמורכב משלושה תחומים. תחומים נחשבים לנקודה אחת של דומיין כשל בתרחיש הזה.
בהשוואה לפריסה שמוצגת קודם, כל FCI מורכב משלושה צמתים, וכל צומת פועל באזור אחר. היתרון בהגדרה הזו הוא שאפשר שיהיה כשל באזור אחד או בשני אזורים בלי שיידרש תוכנית התאוששות מאסון.
התרשים הבא מציג את ההגדרה הזו.
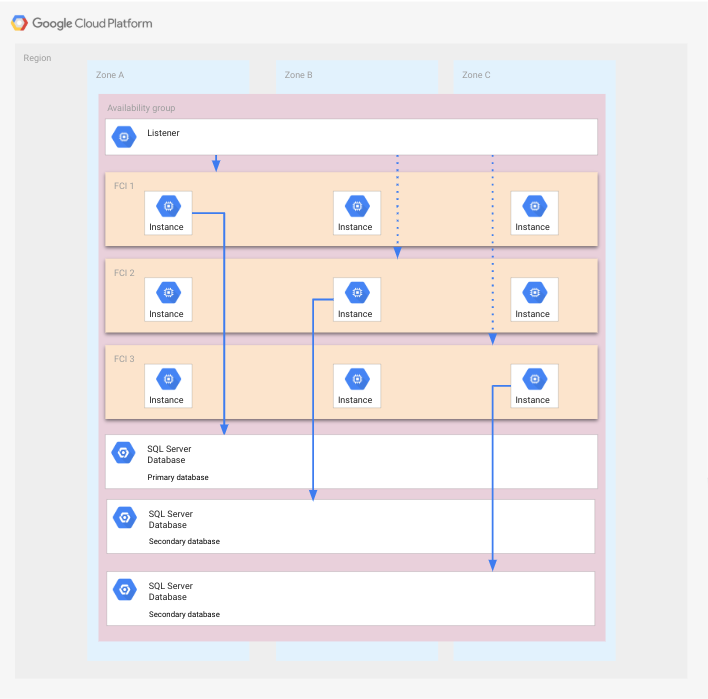
מכשירי FCI משתרעים על פני כל האזורים, ולכל מכשיר FCI יש מכונה אחת של SQL Server שפועלת ומקבלת גישה למסד הנתונים המתאים. יש עוד שני מופעים של SQL Server שלא פועלים בכל FCI, שאפשר להפעיל אותם אם אזור נכשל. מסדי הנתונים מוצגים באזורים שונים, כי כל מסד נתונים משתמש בדיסקים של כל הצמתים ב-FCI נתון. לשם הבהרה, האפליקציה לא מוצגת.
DR בין-אזורי: קבוצת זמינות שמשתרעת על פני אזורים
בתרחיש הזה, קבוצת זמינות פועלת באשכול מעבר לגיבוי בעת כשל של Windows Server ומשתרעת על שני אזורים. אזורים נחשבים לדומיין של נקודת כשל בודדת.
התרשים הבא מדגים את ההגדרה הזו.

כדי לטפל בבעיות פוטנציאליות של זמן אחזור, אפשר להגדיר את העותקים המשוכפלים באזור R1 כך שישתמשו בהפצת עסקאות סינכרונית, ואת העותקים המשוכפלים באזור R2 כך שישתמשו בהפצת עסקאות אסינכרונית.
DR בין אזורים: העברת קובץ גיבוי
בתרחיש הזה נעשה שימוש בהעברת קבצים לגיבוי. שתי קבוצות זמינות בשני אזורים מקושרות. הרפליקות בכל קבוצת זמינות מקבלות את העסקאות באופן סינכרוני, ולכן הרפליקות המשניות בכל אזור נמצאות בהגדרה של המתנה פעילה.
התרשים הבא מדגים את ההגדרה הזו.
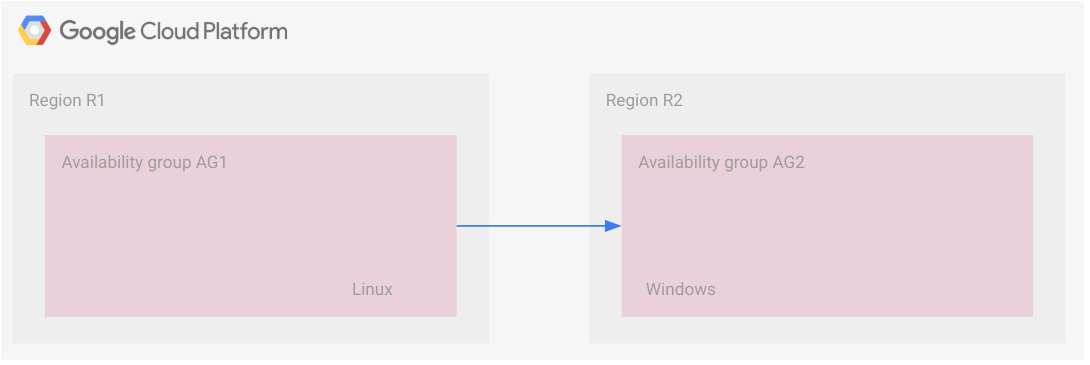
עם זאת, שתי קבוצות הזמינות מחוברות באמצעות העברת קובצי גיבוי. קבוצת הזמינות AG1 היא קבוצת הזמינות הראשית וקבוצת הזמינות AG2 היא קבוצת הזמינות המשנית. כשהקבצים של הגיבוי הופכים לזמינים לקבוצת הזמינות המשנית, הם מוחלים עליה. התרחיש הזה מוסבר בפירוט בקטע הבא, דוגמה: אסטרטגיה לגיבוי ושחזור במקרה של אסון.
טופולוגיה של מיקום כפול ומיקום משני
אם יש רק שני מסדי נתונים, מסד נתונים ראשי ומסד נתונים משני, כל אחד באזור נפרד, אז יש פרק זמן לא מוגן אחרי מעבר לגיבוי ולשיקום (failover) מהרגע שמסד הנתונים הראשי החדש פועל ועד שמסד הנתונים המשני החדש מוכן. אם מסד הנתונים הראשי החדש לא זמין בזמן שמסד הנתונים המשני עדיין לא פועל, מתרחשת השבתה קשה שאפשר לצאת ממנה רק כשנוצר מסד נתונים ראשי חדש. אותו עיקרון חל על קבוצות זמינות.
מיקום שלישי שבו פועל מסד נתונים משני אחר או קבוצת זמינות יכול למנוע את משך הזמן הלא מוגן אחרי מעבר לגיבוי. ההגדרה הזו צריכה להבטיח שאחד משני מסדי הנתונים המשניים יישאר משני ויוקצה מחדש למסד נתונים ראשי חדש, כדי שלא יתרחש אובדן נתונים. כמו קודם, אותו עיקרון חל על קבוצות זמינות.
מחזור החיים של DR
לא משנה איזה פתרון להתאוששות מאסון תבחרו, יש שלבים משותפים במחזור החיים של הפתרון.
במצב של התאוששות מאסון, כל בעלי העניין (בעלי האפליקציות, קבוצות התפעול ואדמינים של מסדי נתונים) צריכים להיות זמינים ולהשתתף באופן פעיל בניהול ההתאוששות מאסון. בעלי העניין צריכים להחליט מי יהיה בעל הסמכות לקבל החלטות (לפעמים מכנים אותו מנהל הפגישה) ומה יהיו תהליכי קבלת ההחלטות. בנוסף, בעלי העניין צריכים להסכים על המינוחים ועל שיטות התקשורת שלהם.
החלטה על התחלת תהליך מעבר לגיבוי בעת כשל
אלא אם יתירות כשל מתחילה אוטומטית, בעלי העניין צריכים להחליט אם להתחיל את יתירות הכשל. בעלי העניין השונים צריכים לתאם ביניהם באופן הדוק את ההחלטה מתי להתחיל את המעבר לגיבוי.
התחלת תהליך מעבר לגיבוי תלויה בכמה גורמים, בעיקר בשורש הבעיה לכך שמסד הנתונים הראשי לא זמין.
אם תהליך השחזור מאסון נמשך יותר זמן מהזמן הצפוי לפתרון הבעיה של חוסר הזמינות של מסד הנתונים הראשי, מעבר לגיבוי יגרום נזק. קודם כל, צריך לבדוק אם אפשר לשחזר את מסד הנתונים הראשי.
ככל שהבדיקה של תוכנית ההתאוששות מאסון (DR) טובה יותר וההטמעה שלה מהירה יותר, כך קל יותר להתחיל את תהליך המעבר לגיבוי כי יש פחות אי ודאות שצריך לקחת בחשבון בהחלטה.
הרצת תהליך יתירות כשל
מומלץ לבדוק את תהליך המעבר לגיבוי באופן קבוע, כדי שכל בעלי העניין יהיו בקיאים בו.
הגורם המוסמך לקבלת החלטות צריך להיות מודע לכל השלבים שמתבצעים ולכל הבעיות הבלתי צפויות שמתעוררות. הגורם שמקבל את ההחלטה מפעיל את תהליך המעבר לגיבוי, והגורמים הרלוונטיים אחראים לתמיכה בגורם שמקבל את ההחלטה.
כדאי לשמור נתונים סטטיסטיים לניתוח לאחר המוות ולשיפור תהליך המעבר לגיבוי, כולל משכי הפעילויות, הבעיות שהתעוררו וכל בלבול בשלבי תהליך המעבר לגיבוי.
הגנה חסרה
אם יש לכם רק מסד נתונים משני אחד, מהרגע שמסד הנתונים הראשי החדש זמין ומוכן לפעולה ועד להגדרה של מסד נתונים משני חדש, לא קיימת הגנה על DR. חוסר זמינות בזמן הזה עלול לגרום להשבתה קשה כי אי אפשר לבצע מעבר לגיבוי למסד נתונים אחר. אם זה קורה, צריך להגדיר מסד נתונים ראשי אחר, וה-RPA הוא הנקודה האחרונה שאפשר לשחזר על סמך הגיבויים הזמינים.
אלא אם אסטרטגיית ההתאוששות מאסון מוגדרת כך שתהיה הגנה בכל רגע נתון, כל בעלי העניין צריכים להיות מודעים למשך הזמן הזה שבו אין הגנה, כדי לנקוט אמצעי זהירות נוספים במהלך ההגדרה או השינויים בהגדרות הסביבה.
כדי להימנע מהתקופה הזו שבה אין הגנה, אפשר לדחות את הגישה של האפליקציה למסד הנתונים הראשי החדש עד שמסד הנתונים המשני החדש יפעל. ברגע שהשינויים ממסד הנתונים הראשי מוחלים, מסד הנתונים הראשי זמין לאפליקציות. הגישה הזו מונעת מצב שבו האפליקציות לא מוגנות מפני DR, אבל היא מעכבת את השלמת תהליך השחזור מאסון.
איך להימנע ממצבים של פיצול אישיות
חשוב שאפליקציות לא יוכלו לגשת בו-זמנית למסד נתונים ראשי ולמסד נתונים משני, ולבצע פעולות DML. במצב כזה, נוצרת אי-התאמה בנתונים, כי גם מסד הנתונים הראשי וגם מסד הנתונים המשני לא מסכימים לגבי ערכי הנתונים של אותו פריט נתונים (Split-brain). הארכיטקטורה הזו חשובה במיוחד אם מסד הנתונים הראשי לא זמין בזמן שהוא ממשיך לפעול ויכול לקבל פעולות כתיבה. אם חוסר הזמינות נגרם בגלל חלוקה זמנית של הרשת, החלוקה יכולה להיפסק בכל שלב, והאפליקציה עשויה לקבל גישה שוב. אם מתרחש תהליך יתירות כשל בזמן הזה, יכול להיות ששינויים במסד הנתונים הראשי הישן יאבדו, או שחלק מהאפליקציות יתחילו לפעול במסד הנתונים הראשי החדש בזמן שאחרות עדיין ניגשות למסד הנתונים הראשי הישן.
כל הגישה לאפליקציות מושבתת לכל מסד נתונים במהלך תהליך המעבר לגיבוי, כדי שלא יתרחש שינוי מצב באף אחד ממסדי הנתונים. אחרי המעבר לגיבוי, רק מסד נתונים אחד זמין לפעולות כתיבה – מסד הנתונים הראשי החדש.
הצהרה על השלמת התהליך
לאחר השלמת תהליך יתירות כשל, רשות ההחלטה צריכה לעדכן במפורש את כל בעלי העניין שהתהליך הסתיים. כל בעיה שמופיעה אחרי השלמת התהליך צריכה להיחשב כאירוע נפרד שלא קשור יותר לתהליך המעבר לגיבוי, אלא לעיבוד רגיל. יכול להיות שהבעיה היא תוצאה של בעיה בתהליך המעבר לגיבוי, או בעיה עצמאית לחלוטין. עם זאת, הגישה לטיפול בבעיה לאחר השלמת תהליך היתירות כשל עשויה להיות שונה מהגישה לטיפול בבעיה במהלך הרצת תהליך היתירות כשל.
ניתוח ודיווח לאחר המוות
כדי שיהיה לכם מידע לעיון בעתיד וכדי לשפר את תהליך יתירות הכשל, מומלץ לבצע פוסט-מורטם באופן מיידי ולרשום את ההיבטים החשובים, הממצאים ופריטי הפעולה.
לכתוב דוח שמסכם את אירוע ההתאוששות מאסון, את שורשי הבעיה ואת כל הפעולות שננקטו. יכול להיות שהדוח הזה יהיה חובה אם אתם מטמיעים דרישות רגולטוריות.
בדיקה ואימות של DR
התאוששות מאסון היא לא חלק מהפעולות השוטפות, ולכן צריך לבדוק את פתרון ה-DR באופן קבוע כדי לוודא שהוא פועל בצורה תקינה כשבאמת צריך אותו.
תדירות הבדיקות תלויה בדרישות התפעוליות, והיא משתנה בהתאם למסד הנתונים, לאפליקציה ולעסק. בנוסף, שינויים בסביבה, כמו שינויים בהגדרות הרשת ועדכונים של רכיבי התשתית, צריכים להפעיל בדיקה של תוכנית התאוששות מאסון (DR) אם השינויים מתבצעים במערכות שפתרון ה-DR שנבחר מסתמך עליהן. כל שינוי עלול לגרום לפתרון תוכנית התאוששות מאסון (DR) להיכשל, או לדרוש התאמה של תהליך תוכנית התאוששות מאסון (DR).
אפשר לבדוק באופן ידני על ידי הפעלת תהליך המעבר, או באופן אוטומטי על ידי שימוש בגישה של הנדסת כאוס, כפי שמתואר במאמר בנושא הנדסת כאוס. בבדיקה ידנית, אפשר למזער את ההשפעה על העסק במקרה של השבתה משמעותית צפויה.
היבט חשוב בבדיקות הוא איסוף נתונים סטטיסטיים מוגדרים היטב. הנה כמה נתונים סטטיסטיים חשובים שכדאי לקחת בחשבון:
- זמן השחזור בפועל: מדידת זמן השחזור בפועל והשוואה שלו ל-RTO.
- הנקודה בפועל להתאוששות מאסון: אפשר לראות את הנקודה בפועל להתאוששות ולהשוות אותה ל-RPO.
- הזמן שחלף עד לזיהוי הכשל: הזמן שחלף עד שאדמיניסטרטורים של מסדי נתונים או צוות התפעול הבינו שיש צורך ביתירות כשל.
- הזמן עד להתחלת השחזור: הזמן שחלף מרגע זיהוי הכשל ועד לתחילת תהליך המעבר לגיבוי.
- מידת האמינות: עד כמה תהליך המעבר לגיבוי (failover) בוצע בצורה מדויקת, או האם נדרשו סטיות ממנו? האם התעוררו בעיות לא צפויות שצריך לבדוק, ואולי יגרמו לשינוי באסטרטגיית השחזור?
על סמך הנתונים הסטטיסטיים שנאספו, יכול להיות שיהיה צורך להתאים או לשפר את תהליך היתירות כשל כדי להתאים טוב יותר לציפיות לגבי RPO ו-RTO.
דוגמה: אסטרטגיית DR של גיבוי ושחזור
בקטעים הבאים מפורטת דוגמה לאסטרטגיה של גיבוי ושחזור לצורך תוכנית התאוששות מאסון (DR). התרחיש הזה מצמצם את השימוש בתכונות הזמינות של SQL Server כדי להמחיש את המאמץ שנדרש כדי לציין אסטרטגיה של גיבוי ושחזור לצורך התאוששות מאסון, ולדון בהיבטים שלא נראים בהגדרות אוטומטיות יותר.
תרחיש לדוגמה
קבוצת זמינות ראשית של Always On ממוקמת ופועלת באזור R1. קבוצת הזמינות המשנית Always On מתווספת באזור R2 להגנה נוספת בין אזורים, והיא זמינה כיעד ליתירות כשל או למעבר לגיבוי.
האסטרטגיה
תוכנית ההתאוששות מאסון מבוססת על גיבויים של מסדי נתונים. מתבצע גיבוי מלא ראשוני, ואחריו גיבויים דיפרנציאליים. הגיבויים מוחלים על קבוצת הזמינות המשנית Always On בזמן שהם מתבצעים. כל הגיבויים מאוחסנים בקטגוריה של Cloud Storage.
בדוגמה הזו, מקובל שאחרי השלמת המעבר לגיבוי, קבוצת הזמינות החדשה הראשית Always On ב-R2 תהיה פעילה ולא מוגנת לזמן מוגבל עד שקבוצת הזמינות המשנית החדשה Always On ב-R1 תפעל.
לא צריך להפעיל גיבוי כי קבוצת הזמינות Always On בכל אחד מהאזורים כשירה באותה מידה לשמש כקבוצת זמינות Always On לייצור.
RTO ו-RPO
בדוגמה הזו, ה-RPO מוגדר ל-60 דקות לכל היותר, ולכן גיבוי דיפרנציאלי מתבצע כל 60 דקות.
ה-RTO לא מוגדר במפורש כמשך זמן, אלא כמשך הזמן המינימלי האפשרי – המקרה הטוב ביותר הוא מיידי. צריך להגדיר את קבוצת הזמינות המשנית כגיבוי פעיל. במקרה של גיבוי פעיל, כל הגיבויים מוחלים באופן מיידי כדי שלא יהיה עיכוב במעבר לגיבוי.
אסטרטגיה כללית של DR
בקטעים הבאים מפורטת אסטרטגיית ה-DR. הוא קצר כדי להתמקד בשלבים החיוניים.
הגדרה ראשונית
- יוצרים קבוצת זמינות משנית של Always On באזור R2.
- מונעים גישה של אפליקציות לקבוצת הזמינות המשנית, כדי שלא יקרה בטעות מצב של פיצול המוח.
- יוצרים קטגוריה של קובץ גיבוי B1 ב-Cloud Storage שתכיל את הגיבוי המלא הראשוני של קבוצת הזמינות Always On ב-R1 ואת הגיבויים הדיפרנציאליים השעתיים הבאים של קבוצת הזמינות Always On ב-R1. צריך לקבוע את הסדר הנכון של הגיבויים הדיפרנציאליים כדי שהתהליך של החלת הגיבויים על קבוצת הזמינות המשנית יוכל להסיק את הסדר הנכון. אפשר למשל להשתמש במוסכמה למתן שמות שתאפשר לקבוע את הסדר הכרונולוגי הנכון על סמך התאריך והשעה שמופיעים בשמות הקבצים השונים.
אסטרטגיית השקה
- החלת הגיבוי המלא על קבוצת הזמינות המשנית Always On באזור R2.
- כאשר גיבויים דיפרנציאליים הופכים לזמינים, צריך להחיל אותם באופן מיידי על קבוצת הזמינות המשנית Always On ב-R2. ההחלה המיידית נדרשת כדי לטפל ב-RTO.
- אחרי הגיבוי המלא הראשוני וכל הגיבויים המצטברים, קבוצת הזמינות המשנית Always On מוכנה.
- בודקים את אסטרטגיית ה-DR על ידי ביצוע מעבר מקבוצת הזמינות הראשית לקבוצת הזמינות המשנית. במהלך הבדיקה, צריך להיות זמין לפחות גיבוי מצטבר אחד.
מקרה של מעבר לגיבוי או מעבר
ב-R2, השלבים העיקריים הם:
- מוודאים שהגיבוי הדיפרנציאלי האחרון הוחל על קבוצת הזמינות המשנית Always On ב-R2.
- מגדירים את R2 כקבוצת הזמינות החדשה הראשית Always On.
- יוצרים מאגר חדש B2, מבצעים גיבוי מלא כבסיס ופותחים את קבוצת הזמינות הראשית החדשה לגישה לאפליקציה.
- מתחילים לבצע גיבויים דיפרנציאליים.
ב-R1, השלבים העיקריים הם:
- מסירים את דלי B1 כי הוא כבר לא נחוץ.
- כשהקבוצה Always On של זמינות ב-R1 חוזרת להיות זמינה (כקבוצה משנית חדשה של Always On), צריך למנוע גישה לאפליקציה ולהסיר את כל הנתונים ממסד הנתונים או לאפס אותו למצב ההתחלתי (הריק) שלו (אלא אם היה צורך ליצור אותו מחדש).
- מחילים את הגיבוי המלא מקבוצת הזמינות החדשה של Always On ב-R2, וממשיכים להחיל גיבויים דיפרנציאליים באופן מיידי כשהם זמינים (מאוחסנים בדלי B2).
שיפורים אפשריים
שיפור אפשרי באסטרטגיה של DR הוא להימנע מביצוע גיבוי מלא אחרי יתירות כשל או מעבר לגיבוי חם, ועדיין להיות מסוגלים להגדיר במהירות את קבוצת הזמינות המשנית החדשה. במקום גיבוי מלא יחיד וגיבויים דיפרנציאליים עוקבים, כדאי לבצע גיבוי מלא מדי שבוע וליצור מאגר שבועי שמכיל את הגיבוי המלא של השבוע ואת כל הגיבויים הדיפרנציאליים העוקבים של אותו שבוע. קבוצת הזמינות הראשית החדשה צריכה ליצור גיבויים דיפרנציאליים רק אחרי יתירות כשל (ולא גיבוי מלא) ולהוסיף אותם לקטגוריה. קבוצת הזמינות המשנית החדשה פשוט מחילה את כל הגיבויים בדלי של השבוע הנוכחי. אם משתמשים בגישה השבועית הזו, צריך להטמיע אסטרטגיה של ניקוי נתונים או למחוק באופן סופי כדי להסיר גיבויים שיצאו משימוש.
שיפור נוסף מבוסס על העובדה שקבוצת הזמינות המשנית החדשה הייתה קבוצת הזמינות הראשית הקודמת. אם מסד הנתונים קיים ופועל אחרי שהוא זמין שוב, שחזור לנקודת זמן לגיבוי הדיפרנציאלי האחרון שלו מאפשר להימנע משחזור מלא שלו מהגיבוי המלא האחרון, כמו שמתואר במאמר שחזור מסד נתונים של SQL Server לנקודת זמן (מודל שחזור מלא). במקרה כזה, המאמץ שנדרש מצטמצם ומשך הזמן שבו קבוצת הזמינות הראשית החדשה לא מוגנת קצר יותר.
שיטות מומלצות להפקה
בפתרון הזה לא מצוין אם מופעי SQL Server בקבוצות הזמינות Always On הם מופעים עצמאיים או מופעי FCI. צריך להחליט מראש באיזה סוג של מופעים להשתמש.
עד שקבוצת זמינות משנית חדשה Always On תפעל אחרי יתירות כשל, יש פרק זמן שבו לא מוגנת DR. מומלץ להגדיר קבוצת זמינות Always On של צד שלישי באזור שלישי.
בנוסף, מומלץ להטמיע מעקב כדי לוודא שכל כשל או שגיאה מזוהים. המעקב לא נכלל במסגרת המסמך הזה, אבל הוא חיוני לפתרון פעיל של תוכנית התאוששות מאסון (DR).
המאמרים הבאים
- הגדרת קבוצות זמינות של SQL Server Always On
- פריסת קבוצת זמינות של SQL Server 2016 Always On עם כמה רשתות משנה ב-Compute Engine.
- הגדרה של מופעים של אשכולות למעבר אוטומטי לגיבוי (Failover) ב-SQL Server
- הפעלת אשכולות של מעבר לגיבוי בעת כשל ב-Windows Server.
- איך מפעילים את Cloud Logging, Cloud Monitoring ו-Error Reporting באפליקציות .NET
- התקנת סוכן Cloud Monitoring.
- כדאי להעמיק את הקריאה ולהכיר דוגמאות לארכיטקטורות, תרשימים ושיטות מומלצות בנושאי Google Cloud. כל אלה זמינים במרכז הארכיטקטורה של Cloud.