
Dokumen ini menguraikan kemampuan dan konfigurasi bandwidth jaringan untuk instance Compute Engine dengan GPU terpasang. Pelajari bandwidth jaringan maksimum, pengaturan Kartu Antarmuka Jaringan (NIC), dan penyiapan jaringan VPC yang direkomendasikan untuk berbagai jenis mesin GPU, termasuk seri A4X Max, A4X, A4, A3, A2, G4, G2, dan N1. Memahami konfigurasi ini dapat membantu Anda mengoptimalkan performa untuk beban kerja terdistribusi di Compute Engine.
Ringkasan
Tabel berikut memberikan perbandingan umum kemampuan jaringan di berbagai jenis mesin GPU.
| Jenis mesin | Model GPU | Bandwidth total maksimum | Teknologi jaringan GPU ke GPU |
|---|---|---|---|
| A4X Max | Superchip Ultra NVIDIA GB300 | 3.600 Gbps | GPUDirect RDMA |
| A4X | Chip Super NVIDIA GB200 | 2.000 Gbps | GPUDirect RDMA |
| A4 | NVIDIA B200 | 3.600 Gbps | GPUDirect RDMA |
| A3 Ultra | NVIDIA H200 | 3.600 Gbps | GPUDirect RDMA |
| A3 Mega | NVIDIA H100 80GB | 1.800 Gbps | GPUDirect-TCPXO |
| A3 Tinggi | NVIDIA H100 80GB | 1.000 Gbps | GPUDirect-TCPX |
| A3 Edge | NVIDIA H100 80GB | 600 Gbps | GPUDirect-TCPX |
| G4 | NVIDIA RTX PRO 6000 | 400 Gbps | T/A |
| A2 Standard dan A2 Ultra | NVIDIA A100 40GB, NVIDIA A100 80GB | 100 Gbps | T/A |
| G2 | NVIDIA L4 | 100 Gbps | T/A |
| N1 | NVIDIA T4, NVIDIA V100 | 100 Gbps | T/A |
| N1 | NVIDIA P100, NVIDIA P4 | 32 Gbps | T/A |
Fungsi GPUDirect RDMA dan MRDMA
Pada jenis mesin tertentu yang dioptimalkan akselerator, Google Cloud menggunakan MRDMA sebagai penerapan antarmuka jaringan untuk jaringan GPU-ke-GPU yang mendukung GPUDirect RDMA.
GPUDirect RDMA adalah teknologi NVIDIA yang memungkinkan kartu antarmuka jaringan (NIC) mengakses memori GPU secara langsung melalui PCIe, tanpa melalui CPU host dan memori sistem. Komunikasi peer-to-peer antara NIC dan GPU ini secara signifikan mengurangi latensi untuk komunikasi GPU-ke-GPU antar-node.
MRDMA adalah implementasi antarmuka jaringan yang digunakan pada jenis mesin A4X Max, A4X, A4, dan A3 Ultra untuk menyediakan kemampuan GPUDirect RDMA. MRDMA didasarkan pada NIC NVIDIA ConnectX dan di-deploy dengan salah satu cara berikut:
- Fungsi Virtual (VF) MRDMA: digunakan dalam seri A3 Ultra, A4, dan A4X.
- Fungsi Fisik (PF) MRDMA: digunakan dalam seri A4X Max.
Fungsi MRDMA dan alat pemantauan jaringan
Jenis mesin A4X, A4, dan A3 Ultra menerapkan jaringan GPU-ke-GPU berperforma tinggi dengan menggunakan Fungsi Virtual (VF) MRDMA. Karena merupakan entitas yang divirtualisasikan, kemampuan pemantauan tingkat hardware tertentu dibatasi dibandingkan dengan Fungsi Fisik (PF).
Dengan VF MRDMA, penghitung port fisik standar (seperti yang
berakhir dengan _phy) muncul di output ethtool -S
tetapi tidak akan diperbarui selama aktivitas jaringan. Hal ini merupakan karakteristik arsitektur VF MRDMA. Untuk melacak performa jaringan secara akurat di
antarmuka ini, tinjau entri untuk vPort Counter Table, bukan
Physical Port Counter Table.
Jenis mesin A4X Max menggunakan PF MRDMA. Tidak seperti jenis mesin berbasis VF MRDMA, A4X Max mendukung rentang lengkap penghitung port fisik untuk jaringan GPU.
Meninjau konsep jaringan untuk jenis mesin GPU
Gunakan bagian berikut untuk meninjau pengaturan jaringan dan kecepatan bandwidth untuk setiap jenis mesin GPU.
Jenis mesin A4X Max dan A4X
Seri mesin A4X Max dan A4X, yang keduanya didasarkan pada arsitektur NVIDIA Blackwell, dirancang untuk workload AI terdistribusi berskala besar yang berat. Pembeda utama antara keduanya adalah akselerator terlampir dan hardware jaringan, seperti yang diuraikan dalam tabel berikut:
| Seri mesin A4X Max | Seri mesin A4X | |
|---|---|---|
| Hardware terpasang | Superchip Ultra NVIDIA GB300 | Chip Super NVIDIA GB200 |
| Jaringan GPU-ke-GPU | 4 SuperNIC NVIDIA ConnectX-8 (CX-8) yang menyediakan bandwidth 3.200 Gbps dalam topologi yang selaras dengan rail 8 arah | 4 NIC NVIDIA ConnectX-7 (CX-7) yang menyediakan bandwidth 1.600 Gbps dalam topologi yang selaras dengan rail 4 arah |
| Penerapan jaringan GPU-ke-GPU | 8 Fungsi Fisik (PF) MRDMA dikonfigurasi sebagai 2 PF per NIC | 4 Fungsi Virtual (VF) MRDMA yang dikonfigurasi sebagai 1 VF per NIC |
| Jaringan tujuan umum | 2 NIC smart Titanium yang menyediakan bandwidth 400 Gbps | 2 NIC smart Titanium yang menyediakan bandwidth 400 Gbps |
| Total bandwidth jaringan maksimum | 3.600 Gbps | 2.000 Gbps |
Arsitektur jaringan berlapis
Instance komputasi A4X Max dan A4X menggunakan arsitektur jaringan hierarkis berlapis-lapis dengan desain yang sesuai jalur untuk mengoptimalkan performa berbagai jenis komunikasi. Dalam topologi ini, instance terhubung di beberapa bidang jaringan independen, yang disebut jalur.
- Instance A4X Max menggunakan topologi yang selaras dengan rail 8 arah, di mana setiap NIC ConnectX-8 800 Gbps terhubung ke dua rail 400 Gbps terpisah.
- Instance A4X menggunakan topologi yang selaras dengan rel 4 arah, di mana setiap dari empat NIC ConnectX-7 terhubung ke rel terpisah.
Lapisan jaringan untuk jenis mesin ini adalah sebagai berikut:
Komunikasi Intra-node dan Intra-subblock (NVLink): Fabric NVLink berkecepatan tinggi menginterkoneksi GPU untuk komunikasi ber-bandwidth tinggi dan berlatensi rendah. Fabric ini menghubungkan semua GPU dalam satu instance dan meluas ke seluruh sub-blok, yang terdiri dari 18 instance A4X Max atau A4X (total 72 GPU). Hal ini memungkinkan semua 72 GPU dalam sub-blok berkomunikasi seolah-olah berada dalam satu server GPU berskala besar.
Komunikasi antar-sub-blok (NIC ConnectX dengan RoCE): untuk menskalakan beban kerja di luar satu sub-blok, mesin ini menggunakan NIC NVIDIA ConnectX. NIC ini menggunakan RDMA over Converged Ethernet (RoCE) untuk menyediakan komunikasi berbandwidth tinggi dan berlatensi rendah antar-subblok, sehingga Anda dapat membangun cluster pelatihan skala besar dengan ribuan GPU.
Jaringan tujuan umum (NIC Pintar Titanium): selain jaringan GPU khusus, setiap instance memiliki dua NIC pintar Titanium, yang menyediakan bandwidth gabungan sebesar 400 Gbps untuk tugas jaringan umum. Hal ini mencakup traffic untuk penyimpanan, pengelolaan, dan menghubungkan ke layanan Google Cloud lainnya atau internet publik.
Arsitektur A4X Max
Arsitektur A4X Max dibangun di sekitar Superchip Ultra GB300 NVIDIA. Fitur utama desain ini adalah koneksi langsung empat SuperNIC NVIDIA ConnectX-8 (CX-8) 800 Gbps ke GPU. Setiap ConnectX-8 adalah NIC dual-port, yang diekspos ke instance sebagai dua Fungsi Fisik (PF). NIC ini adalah bagian dari topologi jaringan yang selaras dengan 8 jalur, di mana setiap NIC terhubung ke dua jalur 400 Gbps terpisah. Jalur langsung ini memungkinkan RDMA, yang memberikan bandwidth tinggi dan latensi rendah untuk komunikasi GPU-ke-GPU di berbagai subblok. Instance Compute Engine ini juga mencakup SSD lokal berperforma tinggi yang terpasang ke NIC ConnectX-8, sehingga melewati bus PCIe untuk akses data yang lebih cepat.
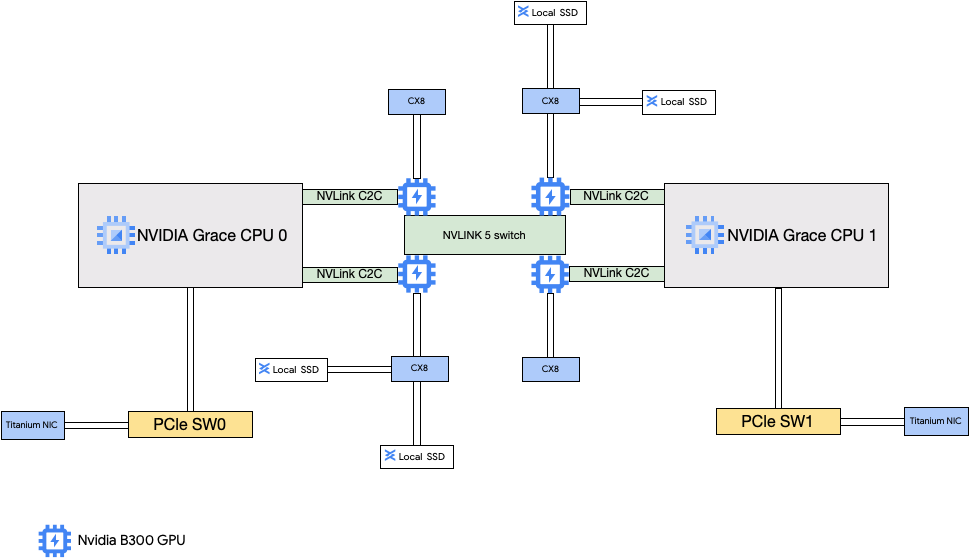
Arsitektur A4X
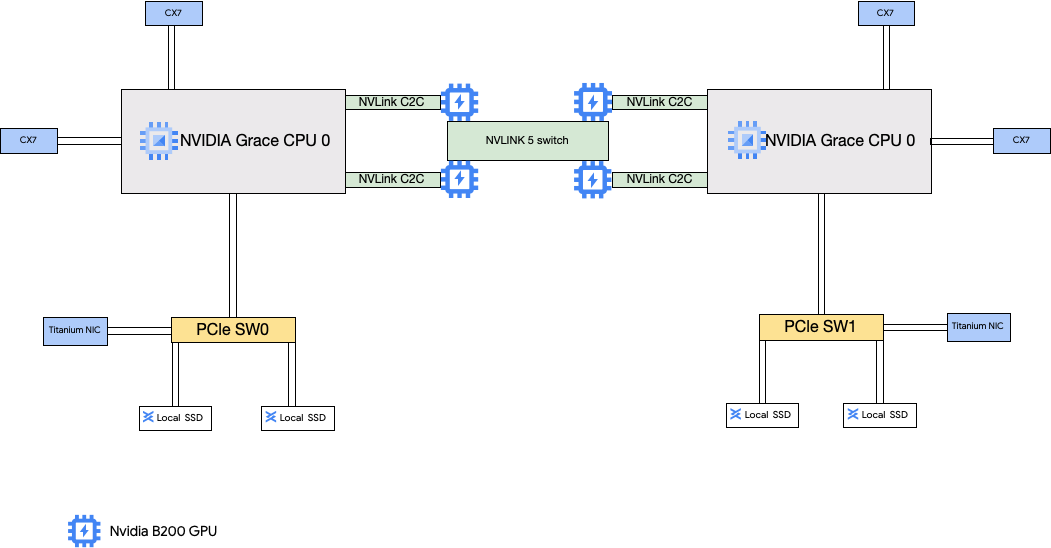
Arsitektur A4X menggunakan Superchip NVIDIA GB200. Dalam konfigurasi ini, empat NIC NVIDIA ConnectX-7 (CX-7) terhubung ke CPU host. Penyiapan ini menyediakan jaringan berperforma tinggi untuk komunikasi GPU-ke-GPU antar- subblok.
Konfigurasi jaringan Virtual Private Cloud (VPC) A4X Max dan A4X
Untuk menggunakan kemampuan jaringan penuh dari jenis mesin ini, Anda perlu membuat dan melampirkan jaringan VPC ke instance Anda. Untuk menggunakan semua NIC yang tersedia, Anda harus membuat jaringan VPC sebagai berikut:
Dua jaringan VPC reguler untuk NIC Smart Titanium.
- Untuk A4X Max, jaringan VPC ini menggunakan driver perangkat PF LAN IDPF Intel.
- Untuk A4X, jaringan VPC ini menggunakan antarmuka jaringan Google Virtual NIC (gVNIC).
Satu jaringan VPC dengan profil jaringan RoCE diperlukan untuk NIC ConnectX saat Anda membuat cluster dari beberapa subblok A4X Max atau A4X. Jaringan VPC RoCE harus memiliki satu subnet untuk setiap jalur jaringan. Artinya, delapan subnet untuk instance A4X Max dan empat subnet untuk instance A4X. Jika menggunakan satu sub-blok, Anda dapat menghilangkan jaringan VPC ini karena fabric NVLink multi-node menangani komunikasi GPU-ke-GPU secara langsung.
Untuk menyiapkan jaringan ini, lihat Membuat jaringan VPC dalam dokumentasi AI Hypercomputer.
Jenis mesin A4X Max dan A4X
A4X Max
| NVIDIA GB300 Grace Blackwell Ultra Superchips terpasang | |||||||
|---|---|---|---|---|---|---|---|
| Jenis mesin | Jumlah vCPU1 | Memori instance (GB) | SSD Lokal yang Terpasang (GiB) | Jumlah NIC fisik | Bandwidth jaringan maksimum (Gbps)2 | Jumlah GPU | Memori GPU3 (GB HBM3e) |
a4x-maxgpu-4g-metal |
144 | 960 | 12.000 | 6 | 3.600 | 4 | 1.116 |
1vCPU diimplementasikan sebagai hardware hyper-thread tunggal di salah satu
platform CPU yang tersedia.
2Bandwidth traffic keluar maksimum tidak boleh melebihi jumlah yang diberikan. Bandwidth
traffic keluar yang sebenarnya bergantung pada alamat IP tujuan dan faktor lainnya.
Untuk mengetahui informasi selengkapnya tentang bandwidth jaringan, lihat Bandwidth jaringan.
3Memori GPU adalah memori pada perangkat GPU yang dapat digunakan untuk
penyimpanan data sementara. Memori ini terpisah dari memori instance dan dirancang khusus untuk menangani permintaan bandwidth yang lebih tinggi dari workload intensif grafis Anda.
A4X
| Chip Super NVIDIA GB200 Grace Blackwell terpasang | |||||||
|---|---|---|---|---|---|---|---|
| Jenis mesin | Jumlah vCPU1 | Memori instance (GB) | SSD Lokal yang Terpasang (GiB) | Jumlah NIC fisik | Bandwidth jaringan maksimum (Gbps)2 | Jumlah GPU | Memori GPU3 (GB HBM3e) |
a4x-highgpu-4g |
140 | 884 | 12.000 | 6 | 2.000 | 4 | 744 |
1vCPU diimplementasikan sebagai hardware hyper-thread tunggal di salah satu
platform CPU yang tersedia.
2Bandwidth traffic keluar maksimum tidak boleh melebihi jumlah yang diberikan. Bandwidth
traffic keluar yang sebenarnya bergantung pada alamat IP tujuan dan faktor lainnya.
Untuk mengetahui informasi selengkapnya tentang bandwidth jaringan, lihat Bandwidth jaringan.
3Memori GPU adalah memori pada perangkat GPU yang dapat digunakan untuk
penyimpanan data sementara. Memori ini terpisah dari memori instance dan dirancang khusus untuk menangani permintaan bandwidth yang lebih tinggi dari workload intensif grafis Anda.
Jenis mesin A4 dan A3 Ultra
Jenis mesin A4 memiliki GPU NVIDIA B200 yang terpasang dan jenis mesin A3 Ultra memiliki GPU NVIDIA H200 yang terpasang.
Jenis mesin ini menyediakan delapan kartu antarmuka jaringan (NIC) NVIDIA ConnectX-7 (CX-7) dan dua NIC virtual Google (gVNIC). Delapan NIC CX-7 menyediakan total bandwidth jaringan sebesar 3.200 Gbps. NIC ini dikhususkan untuk komunikasi GPU ke GPU ber-bandwidth tinggi saja dan tidak dapat digunakan untuk kebutuhan jaringan lainnya seperti akses internet publik. Seperti yang diuraikan dalam diagram berikut, setiap NIC CX-7 disesuaikan dengan satu GPU untuk mengoptimalkan akses memori non-seragam (NUMA). Kedelapan GPU dapat saling berkomunikasi dengan cepat menggunakan jembatan NVLink all-to-all yang menghubungkannya. Dua kartu antarmuka jaringan gVNIC lainnya adalah NIC pintar yang menyediakan bandwidth jaringan tambahan sebesar 400 Gbps untuk persyaratan jaringan tujuan umum. Jika digabungkan, kartu antarmuka jaringan ini menyediakan total bandwidth jaringan maksimum sebesar 3.600 Gbps untuk mesin ini.
Jaringan GPU-ke-GPU berperforma tinggi pada instance A4 dan A3 Ultra diimplementasikan dengan menggunakan Fungsi Virtual (VF) MRDMA untuk masing-masing delapan NIC ConnectX-7.
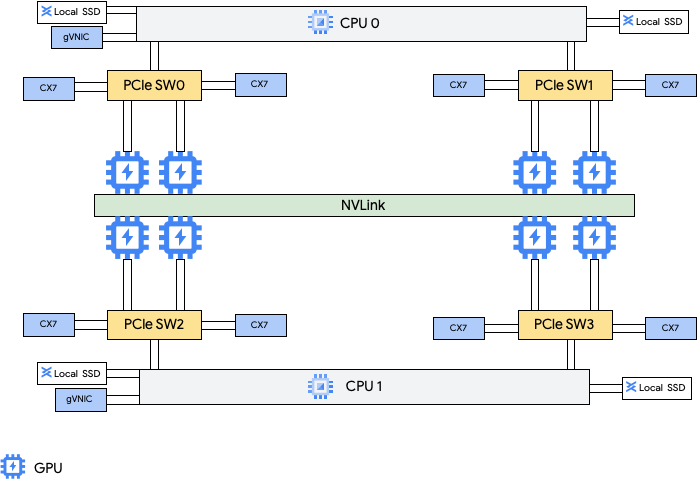
Untuk menggunakan beberapa NIC ini, Anda perlu membuat 3 jaringan Virtual Private Cloud sebagai berikut:
- Dua jaringan VPC reguler: setiap gVNIC harus terhubung ke jaringan VPC yang berbeda
- Satu jaringan VPC RoCE: semua delapan NIC CX-7 berbagi jaringan VPC RoCE yang sama
Untuk menyiapkan jaringan ini, lihat Membuat jaringan VPC dalam dokumentasi AI Hypercomputer.
A4
| GPU NVIDIA B200 Blackwell terpasang | |||||||
|---|---|---|---|---|---|---|---|
| Jenis mesin | Jumlah vCPU1 | Memori instance (GB) | SSD Lokal yang Terpasang (GiB) | Jumlah NIC fisik | Bandwidth jaringan maksimum (Gbps)2 | Jumlah GPU | Memori GPU3 (GB HBM3e) |
a4-highgpu-8g |
224 | 3.968 | 12.000 | 10 | 3.600 | 8 | 1.440 |
1vCPU diimplementasikan sebagai hardware hyper-thread tunggal di salah satu
platform CPU yang tersedia.
2Bandwidth traffic keluar maksimum tidak boleh melebihi jumlah yang diberikan. Bandwidth
traffic keluar yang sebenarnya bergantung pada alamat IP tujuan dan faktor lainnya.
Untuk mengetahui informasi selengkapnya tentang bandwidth jaringan, lihat
Bandwidth jaringan.
3Memori GPU adalah memori pada perangkat GPU yang dapat digunakan untuk
penyimpanan data sementara. Memori ini terpisah dari memori instance dan dirancang khusus untuk menangani permintaan bandwidth yang lebih tinggi dari workload intensif grafis Anda.
A3 Ultra
| GPU NVIDIA H200 terpasang | |||||||
|---|---|---|---|---|---|---|---|
| Jenis mesin | Jumlah vCPU1 | Memori instance (GB) | SSD Lokal yang Terpasang (GiB) | Jumlah NIC fisik | Bandwidth jaringan maksimum (Gbps)2 | Jumlah GPU | Memori GPU3 (GB HBM3e) |
a3-ultragpu-8g |
224 | 2.952 | 12.000 | 10 | 3.600 | 8 | 1128 |
1vCPU diimplementasikan sebagai hardware hyper-thread tunggal di salah satu
platform CPU yang tersedia.
2Bandwidth traffic keluar maksimum tidak boleh melebihi jumlah yang diberikan. Bandwidth
traffic keluar yang sebenarnya bergantung pada alamat IP tujuan dan faktor lainnya.
Untuk mengetahui informasi selengkapnya tentang bandwidth jaringan, lihat Bandwidth jaringan.
3Memori GPU adalah memori pada perangkat GPU yang dapat digunakan untuk
penyimpanan data sementara. Memori ini terpisah dari memori instance dan dirancang khusus untuk menangani permintaan bandwidth yang lebih tinggi dari workload intensif grafis Anda.
Jenis mesin A3 Mega, High, dan Edge
Jenis mesin ini memiliki GPU H100 yang terpasang. Setiap jenis mesin ini memiliki jumlah GPU tetap, jumlah vCPU, dan ukuran memori.
- VM A3 NIC Tunggal: Untuk VM A3 dengan 1 hingga 4 GPU yang terpasang, hanya satu kartu antarmuka jaringan (NIC) fisik yang tersedia.
- VM A3 Multi-NIC: Untuk VM A3 dengan 8 GPU terpasang, beberapa NIC fisik tersedia. Untuk jenis mesin A3 ini, NIC diatur sebagai berikut di bus Peripheral Component Interconnect Express (PCIe):
- Untuk jenis mesin A3 Mega: tersedia pengaturan NIC 8+1. Dengan pengaturan ini, 8 NIC berbagi bus PCIe yang sama, dan 1 NIC berada di bus PCIe yang terpisah.
- Untuk jenis mesin A3 High: tersedia pengaturan NIC 4+1. Dengan pengaturan ini, 4 NIC berbagi bus PCIe yang sama, dan 1 NIC berada di bus PCIe terpisah.
- Untuk jenis mesin A3 Edge: tersedia pengaturan NIC 4+1. Dengan pengaturan ini, 4 NIC berbagi bus PCIe yang sama, dan 1 NIC berada di bus PCIe terpisah. Kelima NIC ini menyediakan total bandwidth jaringan sebesar 400 Gbps untuk setiap VM.
NIC yang berbagi bus PCIe yang sama, memiliki penyelarasan akses memori tidak seragam (NUMA) satu NIC per dua GPU NVIDIA H100. NIC ini ideal untuk komunikasi GPU ke GPU ber-bandwidth tinggi khusus. NIC fisik yang berada di bus PCIe terpisah sangat ideal untuk kebutuhan jaringan lainnya. Untuk mengetahui petunjuk tentang cara menyiapkan jaringan untuk VM A3 High dan A3 Edge, lihat menyiapkan jaringan MTU frame jumbo.
A3 Mega
| GPU NVIDIA H100 terpasang | |||||||
|---|---|---|---|---|---|---|---|
| Jenis mesin | Jumlah vCPU1 | Memori instance (GB) | SSD Lokal yang Terpasang (GiB) | Jumlah NIC fisik | Bandwidth jaringan maksimum (Gbps)2 | Jumlah GPU | Memori GPU3 (GB HBM3) |
a3-megagpu-8g |
208 | 1.872 | 6.000 | 9 | 1.800 | 8 | 640 |
A3 Tinggi
| GPU NVIDIA H100 terpasang | |||||||
|---|---|---|---|---|---|---|---|
| Jenis mesin | Jumlah vCPU1 | Memori instance (GB) | SSD Lokal yang Terpasang (GiB) | Jumlah NIC fisik | Bandwidth jaringan maksimum (Gbps)2 | Jumlah GPU | Memori GPU3 (GB HBM3) |
a3-highgpu-1g |
26 | 234 | 750 | 1 | 25 | 1 | 80 |
a3-highgpu-2g |
52 | 468 | 1.500 | 1 | 50 | 2 | 160 |
a3-highgpu-4g |
104 | 936 | 3.000 | 1 | 100 | 4 | 320 |
a3-highgpu-8g |
208 | 1.872 | 6.000 | 5 | 1.000 | 8 | 640 |
A3 Edge
| GPU NVIDIA H100 terpasang | |||||||
|---|---|---|---|---|---|---|---|
| Jenis mesin | Jumlah vCPU1 | Memori instance (GB) | SSD Lokal yang Terpasang (GiB) | Jumlah NIC fisik | Bandwidth jaringan maksimum (Gbps)2 | Jumlah GPU | Memori GPU3 (GB HBM3) |
a3-edgegpu-8g |
208 | 1.872 | 6.000 | 5 |
|
8 | 640 |
1vCPU diimplementasikan sebagai hardware hyper-thread tunggal di salah satu
platform CPU yang tersedia.
2Bandwidth traffic keluar maksimum tidak boleh melebihi jumlah yang diberikan. Bandwidth
traffic keluar yang sebenarnya bergantung pada alamat IP tujuan dan faktor lainnya.
Untuk mengetahui informasi selengkapnya tentang bandwidth jaringan, lihat Bandwidth jaringan.
3Memori GPU adalah memori pada perangkat GPU yang dapat digunakan untuk
penyimpanan data sementara. Memori ini terpisah dari memori instance dan dirancang khusus untuk menangani permintaan bandwidth yang lebih tinggi dari workload intensif grafis Anda.
Jenis mesin A2
Setiap jenis mesin A2 memiliki jumlah tetap GPU NVIDIA A100 40 GB atau NVIDIA A100 80 GB yang terpasang. Setiap jenis mesin juga memiliki jumlah vCPU dan ukuran memori tetap.
Seri mesin A2 tersedia dalam dua jenis:
- A2 Ultra: jenis mesin ini memiliki GPU A100 80 GB dan disk SSD Lokal yang terpasang.
- A2 Standard: jenis mesin ini memiliki GPU A100 40 GB yang terpasang.
A2 Ultra
| GPU NVIDIA A100 80 GB terpasang | ||||||
|---|---|---|---|---|---|---|
| Jenis mesin | Jumlah vCPU1 | Memori instance (GB) | SSD Lokal yang Terpasang (GiB) | Bandwidth jaringan maksimum (Gbps)2 | Jumlah GPU | Memori GPU3 (GB HBM2e) |
a2-ultragpu-1g |
12 | 170 | 375 | 24 | 1 | 80 |
a2-ultragpu-2g |
24 | 340 | 750 | 32 | 2 | 160 |
a2-ultragpu-4g |
48 | 680 | 1.500 | 50 | 4 | 320 |
a2-ultragpu-8g |
96 | 1.360 | 3.000 | 100 | 8 | 640 |
A2 Standard
| GPU NVIDIA A100 40 GB terpasang | ||||||
|---|---|---|---|---|---|---|
| Jenis mesin | Jumlah vCPU1 | Memori instance (GB) | SSD lokal didukung | Bandwidth jaringan maksimum (Gbps)2 | Jumlah GPU | Memori GPU3 (GB HBM2) |
a2-highgpu-1g |
12 | 85 | Ya | 24 | 1 | 40 |
a2-highgpu-2g |
24 | 170 | Ya | 32 | 2 | 80 |
a2-highgpu-4g |
48 | 340 | Ya | 50 | 4 | 160 |
a2-highgpu-8g |
96 | 680 | Ya | 100 | 8 | 320 |
a2-megagpu-16g |
96 | 1.360 | Ya | 100 | 16 | 640 |
1vCPU diimplementasikan sebagai hardware hyper-thread tunggal di salah satu
platform CPU yang tersedia.
2Bandwidth traffic keluar maksimum tidak boleh melebihi jumlah yang diberikan. Bandwidth
traffic keluar yang sebenarnya bergantung pada alamat IP tujuan dan faktor lainnya.
Untuk mengetahui informasi selengkapnya tentang bandwidth jaringan, lihat Bandwidth jaringan.
3Memori GPU adalah memori pada perangkat GPU yang dapat digunakan untuk
penyimpanan data sementara. Memori ini terpisah dari memori instance dan dirancang khusus untuk menangani permintaan bandwidth yang lebih tinggi dari workload intensif grafis Anda.
Jenis mesin G4
Jenis mesin yang dioptimalkan untuk akselerator G4
menggunakan
GPU NVIDIA RTX PRO 6000 Blackwell Server Edition (nvidia-rtx-pro-6000)
dan
cocok untuk workload simulasi NVIDIA Omniverse, aplikasi yang intensif secara grafis, transkode
video, dan desktop virtual. Jenis mesin G4 juga memberikan solusi berbiaya rendah untuk
melakukan inferensi host tunggal dan penyesuaian model dibandingkan dengan jenis mesin seri A.
| GPU NVIDIA RTX PRO 6000 terpasang | |||||||
|---|---|---|---|---|---|---|---|
| Jenis mesin | Jumlah vCPU1 | Memori instance (GB) | SSD Titanium maksimum yang didukung (GiB)2 | Jumlah NIC fisik | Bandwidth jaringan maksimum (Gbps)3 | Jumlah GPU | Memori GPU4 (GB GDDR7) |
g4-standard-6 |
6 | 22 | 0 | 1 | 20 | 1/8 | 12 |
g4-standard-12 |
12 | 45 | 375 | 1 | 20 | 1/4 | 24 |
g4-standard-24 |
24 | 90 | 750 | 1 | 20 | 1/2 | 48 |
g4-standard-48 |
48 | 180 | 1.500 | 1 | 50 | 1 | 96 |
g4-standard-96 |
96 | 360 | 3.000 | 1 | 100 | 2 | 192 |
g4-standard-192 |
192 | 720 | 6.000 | 1 | 200 | 4 | 384 |
g4-standard-384 |
384 | 1.440 | 12.000 | 2 | 400 | 8 | 768 |
1vCPU diimplementasikan sebagai hardware hyper-thread tunggal di salah satu
platform CPU yang tersedia.
2Anda dapat menambahkan disk Titanium SSD saat membuat instance G4. Untuk mengetahui jumlah disk yang dapat Anda pasang, lihat Jenis mesin yang mengharuskan Anda memilih jumlah disk SSD Lokal.
3Bandwidth traffic keluar maksimum tidak boleh melebihi jumlah yang diberikan. Bandwidth
traffic keluar yang sebenarnya bergantung pada alamat IP tujuan dan faktor lainnya.
Lihat Bandwidth jaringan.Memori GPU
4adalah memori pada perangkat GPU yang dapat digunakan untuk
penyimpanan data sementara. Memori ini terpisah dari memori instance dan dirancang khusus untuk menangani permintaan bandwidth yang lebih tinggi dari workload intensif grafis Anda.
Jenis mesin G2
Jenis mesin yang dioptimalkan akselerator G2 memiliki GPU NVIDIA L4 yang terpasang dan ideal untuk inferensi yang dioptimalkan biaya, workload komputasi berperforma tinggi dan intensif grafis.
Setiap jenis mesin G2 juga memiliki memori default dan rentang memori kustom. Rentang memori kustom menentukan jumlah memori yang dapat Anda alokasikan ke instance untuk setiap jenis mesin. Anda juga dapat menambahkan disk SSD Lokal saat membuat instance G2. Untuk mengetahui jumlah disk yang dapat Anda pasang, lihat Jenis mesin yang mengharuskan Anda memilih jumlah disk SSD Lokal.
Untuk menerapkan kecepatan bandwidth jaringan yang lebih tinggi (50 Gbps atau lebih tinggi) ke sebagian besar instance GPU, sebaiknya gunakan Google Virtual NIC (gVNIC). Untuk mengetahui informasi selengkapnya tentang cara membuat instance GPU yang menggunakan gVNIC, lihat Membuat instance GPU yang menggunakan bandwidth lebih tinggi.
| GPU NVIDIA L4 terpasang | |||||||
|---|---|---|---|---|---|---|---|
| Jenis mesin | Jumlah vCPU1 | Memori instance default (GB) | Rentang memori instance kustom (GB) | SSD Lokal maksimum yang didukung (GiB) | Bandwidth jaringan maksimum (Gbps)2 | Jumlah GPU | Memori GPU3 (GB GDDR6) |
g2-standard-4 |
4 | 16 | 16 hingga 32 | 375 | 10 | 1 | 24 |
g2-standard-8 |
8 | 32 | 32 hingga 54 | 375 | 16 | 1 | 24 |
g2-standard-12 |
12 | 48 | 48 hingga 54 tahun | 375 | 16 | 1 | 24 |
g2-standard-16 |
16 | 64 | 54 hingga 64 | 375 | 32 | 1 | 24 |
g2-standard-24 |
24 | 96 | 96 hingga 108 | 750 | 32 | 2 | 48 |
g2-standard-32 |
32 | 128 | 96 hingga 128 | 375 | 32 | 1 | 24 |
g2-standard-48 |
48 | 192 | 192 hingga 216 | 1.500 | 50 | 4 | 96 |
g2-standard-96 |
96 | 384 | 384 hingga 432 | 3.000 | 100 | 8 | 192 |
1vCPU diimplementasikan sebagai hardware hyper-thread tunggal di salah satu
platform CPU yang tersedia.
2Bandwidth traffic keluar maksimum tidak boleh melebihi jumlah yang diberikan. Bandwidth
traffic keluar yang sebenarnya bergantung pada alamat IP tujuan dan faktor lainnya.
Untuk mengetahui informasi selengkapnya tentang bandwidth jaringan, lihat Bandwidth jaringan.
3Memori GPU adalah memori pada perangkat GPU yang dapat digunakan untuk
penyimpanan data sementara. Memori ini terpisah dari memori instance dan dirancang khusus untuk menangani permintaan bandwidth yang lebih tinggi dari workload intensif grafis Anda.
Jenis mesin N1 + GPU
Untuk instance virtual machine (VM) tujuan umum N1 yang telah memasang GPU T4 dan V100, Anda bisa mendapatkan bandwidth jaringan maksimum hingga 100 Gbps, berdasarkan kombinasi jumlah GPU dan vCPU. Untuk semua instance GPU N1 lainnya, lihat Ringkasan.
Tinjau bagian berikut untuk menghitung bandwidth jaringan maksimum yang tersedia untuk instance T4 dan V100 Anda berdasarkan model GPU, vCPU, dan jumlah GPU.
Kurang dari 5 vCPU
Untuk instance T4 dan V100 yang memiliki 5 vCPU atau kurang, tersedia bandwidth jaringan maksimum sebesar 10 Gbps.
Lebih dari 5 vCPU
Untuk instance T4 dan V100 yang memiliki lebih dari 5 vCPU, bandwidth jaringan maksimum dihitung berdasarkan jumlah vCPU dan GPU untuk VM tersebut.
Untuk menerapkan kecepatan bandwidth jaringan yang lebih tinggi (50 Gbps atau lebih tinggi) ke sebagian besar instance GPU, sebaiknya gunakan Google Virtual NIC (gVNIC). Untuk mengetahui informasi selengkapnya tentang cara membuat instance GPU yang menggunakan gVNIC, lihat Membuat instance GPU yang menggunakan bandwidth lebih tinggi.
| Model GPU | Jumlah GPU | Penghitungan bandwidth jaringan maksimum |
|---|---|---|
| NVIDIA V100 | 1 | min(vcpu_count * 2, 32) |
| 2 | min(vcpu_count * 2, 32) |
|
| 4 | min(vcpu_count * 2, 50) |
|
| 8 | min(vcpu_count * 2, 100) |
|
| NVIDIA T4 | 1 | min(vcpu_count * 2, 32) |
| 2 | min(vcpu_count * 2, 50) |
|
| 4 | min(vcpu_count * 2, 100) |
Setelan MTU dan jenis mesin GPU
Untuk meningkatkan throughput jaringan, tetapkan nilai unit transmisi maksimum (MTU) yang lebih tinggi untuk jaringan VPC Anda. Nilai MTU yang lebih tinggi akan menambah ukuran paket dan mengurangi overhead header paket, sehingga meningkatkan throughput data payload.
Untuk jenis mesin GPU, sebaiknya gunakan setelan MTU berikut untuk jaringan VPC Anda.
| Jenis mesin GPU | MTU yang direkomendasikan (dalam byte) | |
|---|---|---|
| Jaringan VPC reguler | Jaringan VPC RoCE | |
|
8896 | 8896 |
|
8244 | T/A |
|
8896 | T/A |
Saat menetapkan nilai MTU, perhatikan hal berikut:
- 8192 adalah dua halaman 4 KB.
- 8244 direkomendasikan di VM A3 Mega, A3 High, dan A3 Edge untuk NIC GPU yang mengaktifkan pemisahan header.
- Gunakan nilai 8896 kecuali jika dinyatakan lain dalam tabel.
Membuat mesin GPU dengan bandwidth tinggi
Untuk membuat instance GPU yang menggunakan bandwidth jaringan yang lebih tinggi, gunakan salah satu metode berikut berdasarkan jenis mesin:
Untuk membuat instance A2, G2, dan N1 yang menggunakan bandwidth jaringan lebih tinggi, lihat Menggunakan bandwidth jaringan yang lebih tinggi untuk instance A2, G2, dan N1. Untuk menguji atau memverifikasi kecepatan bandwidth untuk mesin ini, Anda dapat menggunakan pengujian tolok ukur. Untuk mengetahui informasi selengkapnya, lihat Memeriksa bandwidth jaringan.
Untuk membuat instance A3 Mega yang menggunakan bandwidth jaringan yang lebih tinggi, lihat Men-deploy cluster Slurm A3 Mega untuk pelatihan ML. Untuk menguji atau memverifikasi kecepatan bandwidth untuk mesin ini, gunakan pengujian tolok ukur dengan mengikuti langkah-langkah dalam Memeriksa bandwidth jaringan.
Untuk instance A3 High dan A3 Edge yang menggunakan bandwidth jaringan yang lebih tinggi, lihat Membuat VM A3 dengan GPUDirect-TCPX diaktifkan. Untuk menguji atau memverifikasi kecepatan bandwidth untuk mesin ini, Anda dapat menggunakan pengujian tolok ukur. Untuk mengetahui informasi selengkapnya, lihat Memeriksa bandwidth jaringan.
Untuk jenis mesin yang dioptimalkan akselerator lainnya, Anda tidak perlu melakukan tindakan apa pun untuk menggunakan bandwidth jaringan yang lebih tinggi; membuat instance seperti yang didokumentasikan sudah menggunakan bandwidth jaringan yang tinggi. Untuk mempelajari cara membuat instance untuk jenis mesin yang dioptimalkan akselerator lainnya, lihat Membuat VM yang telah memasang GPU.
Apa langkah selanjutnya?
- Pelajari platform GPU lebih lanjut.
- Pelajari cara membuat instance dengan GPU terpasang.
- Pelajari Menggunakan bandwidth jaringan yang lebih tinggi.
- Pelajari harga GPU.