
Incorporado a jobs de consulta, o BigQuery inclui informações de cronologia e plano de consulta diagnóstica. Isso é semelhante às informações fornecidas por
instruções como EXPLAIN em outros sistemas analíticos e de bancos de dados. Essas informações podem ser recuperadas a partir das respostas de API de métodos como jobs.get.
Para consultas de longa duração, o BigQuery atualizará essas estatísticas periodicamente. Essas atualizações ocorrem independentemente da taxa em que o status do job é pesquisado, mas não costumam ser com mais frequência do que a cada 30 segundos. Além disso, os jobs de consulta que não usam recursos de execução, como solicitações de simulação ou resultados que podem ser exibidos a partir de resultados armazenados em cache, não incluirão as informações de diagnóstico adicionais, embora outras estatísticas possam ser presente.
Contexto
Quando o BigQuery executa uma consulta, ele converte o SQL em um gráfico de execução que consiste em estágios. Os estágios são compostos de etapas, as operações elementares que executam a lógica da consulta. O BigQuery usa uma arquitetura paralela altamente distribuída que executa etapas em paralelo para reduzir a latência. Os estágios se comunicam entre si usando o embaralhamento, uma arquitetura de memória distribuída rápida.
O plano de consulta usa os termos unidades de trabalho e workers para descrever o paralelismo
de estágio. Em outros locais do
BigQuery, é possível encontrar o termo slot,
que é uma representação abstrata de várias facetas da execução de consulta, incluindo
recursos de computação, memória e E/S. Os slots executam as unidades de trabalho individuais de um
estágio em paralelo. As estatísticas de jobs de nível superior fornecem o custo da consulta individual usando totalSlotMs com base nessa contabilidade abstrata.
Outra propriedade importante da execução de consultas é que o BigQuery pode modificar o plano de consulta enquanto ela está em execução. Por exemplo, o BigQuery introduz estágios de repartição para melhorar a distribuição de dados entre os workers de consulta, o que aumenta o paralelismo e reduz a latência da consulta.
Além do plano de consulta, os jobs de consulta também expõem um cronograma de execução, que fornece uma contabilidade das unidades de trabalho concluídas, pendentes e ativas. Uma consulta pode ter vários estágios com workers ativos simultaneamente, e o cronograma se destina a mostrar o progresso geral da consulta.
Conferir o gráfico de execução com o console do Google Cloud
No console doGoogle Cloud , é possível ver detalhes do plano de consulta de uma consulta concluída clicando no botão Detalhes da execução.
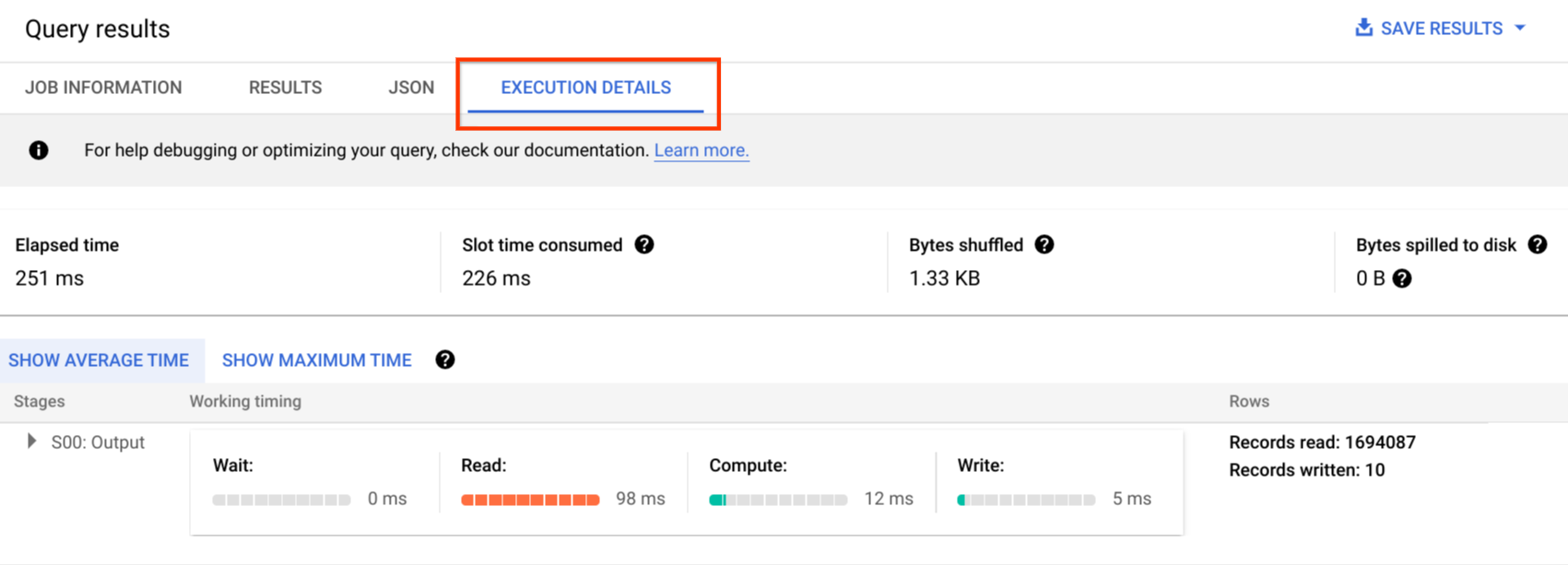
Informações do plano de consulta
Na resposta da API, os planos de consulta são representados como uma lista de estágios de consulta. Cada item na lista mostra estatísticas da visão geral por estágio, informações detalhadas da etapa e classificações de duração dos estágios. Nem todos os detalhes são renderizados no console Google Cloud , mas todos podem estar presentes nas respostas da API.
Entender o gráfico de execução
No console Google Cloud , clique na guia Gráfico de execução para ver os detalhes do plano de consulta.
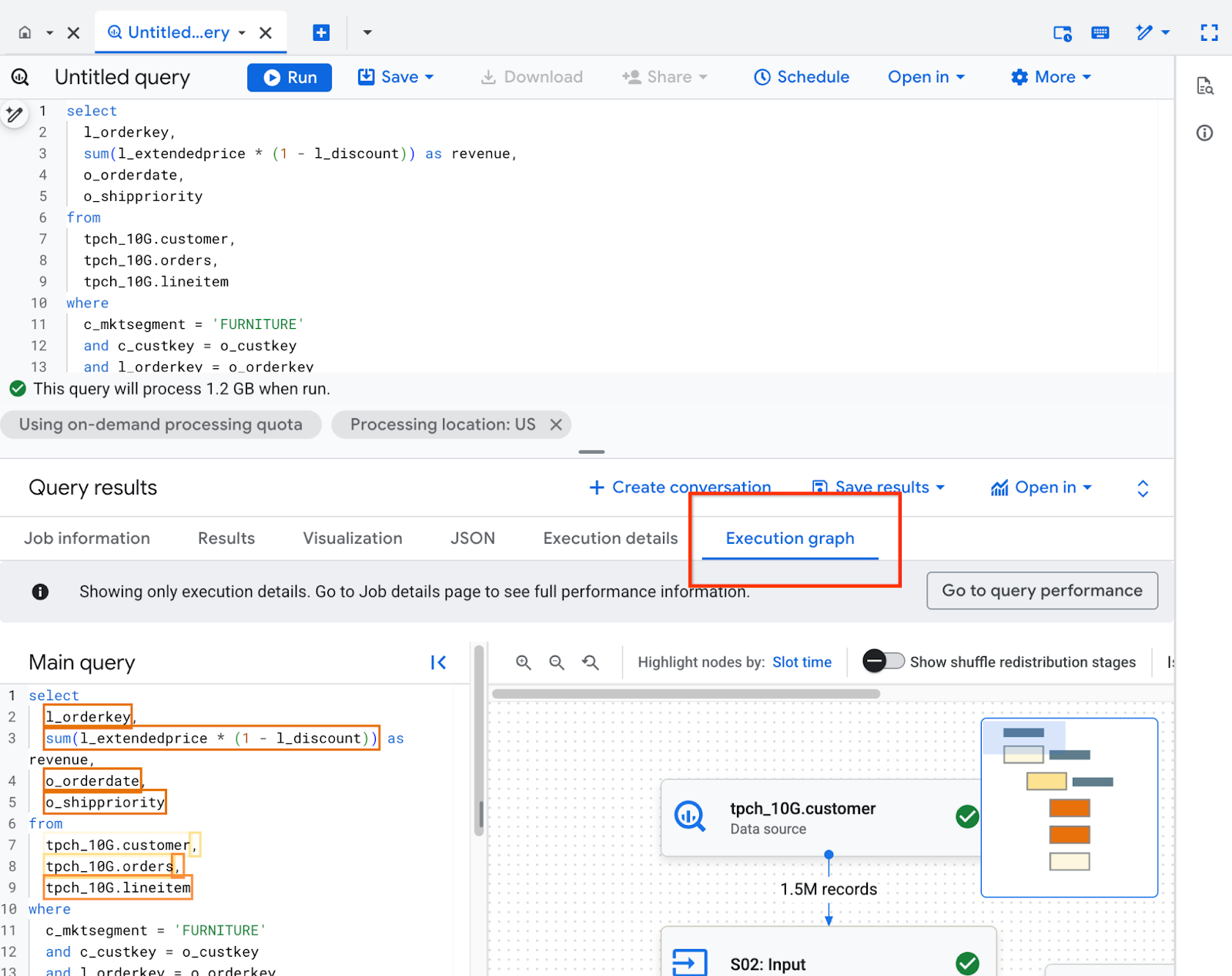
O painel Gráfico de execução é organizado da seguinte forma:
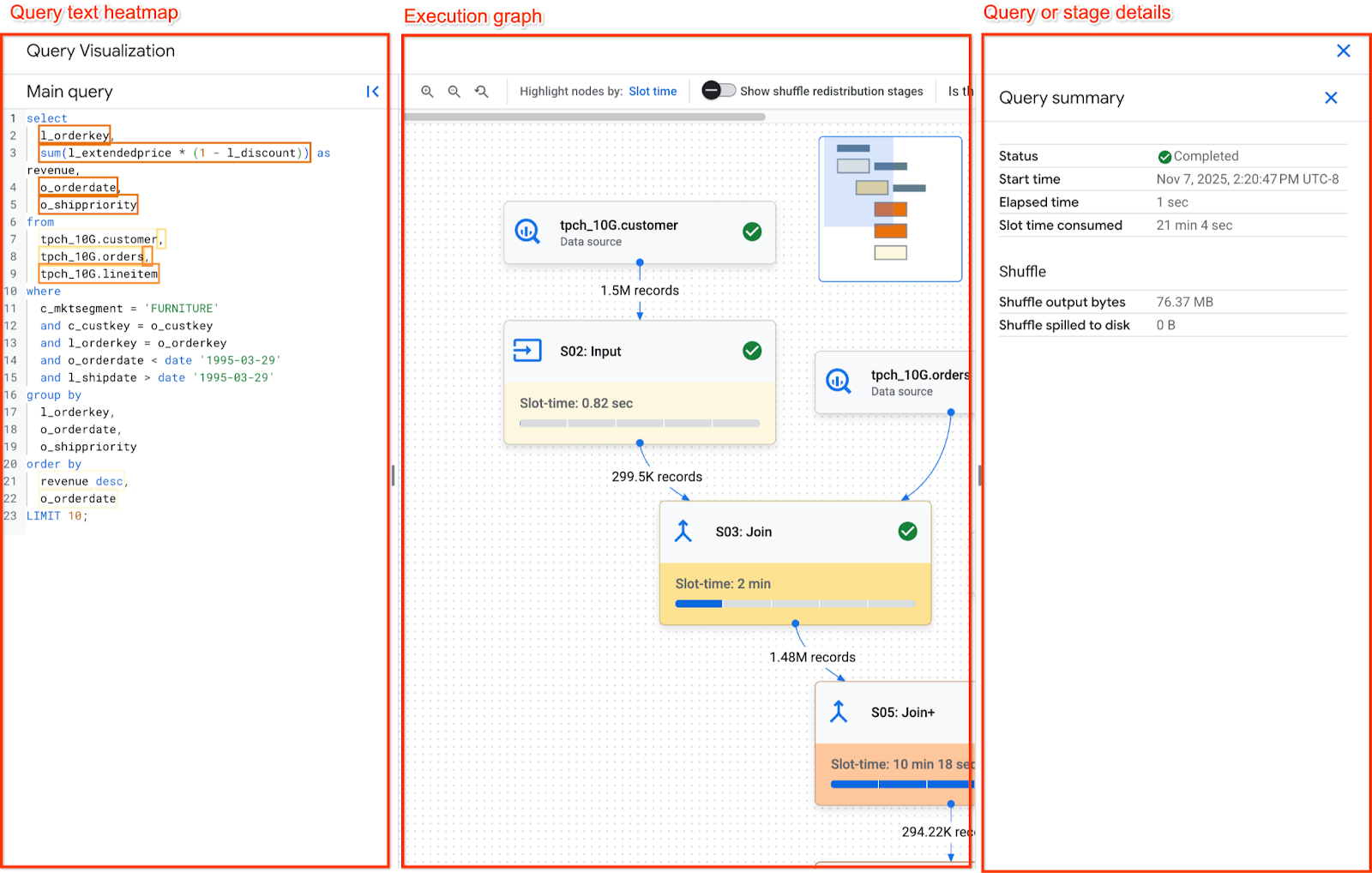
- No centro está o gráfico de execução. Ele mostra as etapas como nós e a memória de embaralhamento trocada entre as etapas como arestas.
- O painel à esquerda tem o mapa de calor do texto da consulta. Ele mostra o texto principal da consulta que foi executada, além de todas as visualizações referenciadas.
- O painel à direita tem os detalhes da consulta ou do estágio.
Como navegar no gráfico de execução
O gráfico de execução aplica um esquema de cores aos nós com base no tempo de slot. Nós com um vermelho mais escuro levam mais tempo de slot em relação ao restante dos estágios no gráfico.
Para navegar pelo gráfico de execução, você pode:
- Clique e mantenha pressionado no plano de fundo do gráfico para navegar por diferentes áreas.
- Use a roda de rolagem do mouse para aumentar e diminuir o zoom do gráfico.
- Clique e mantenha pressionado o minimapa no canto superior direito para mover para diferentes áreas do gráfico.
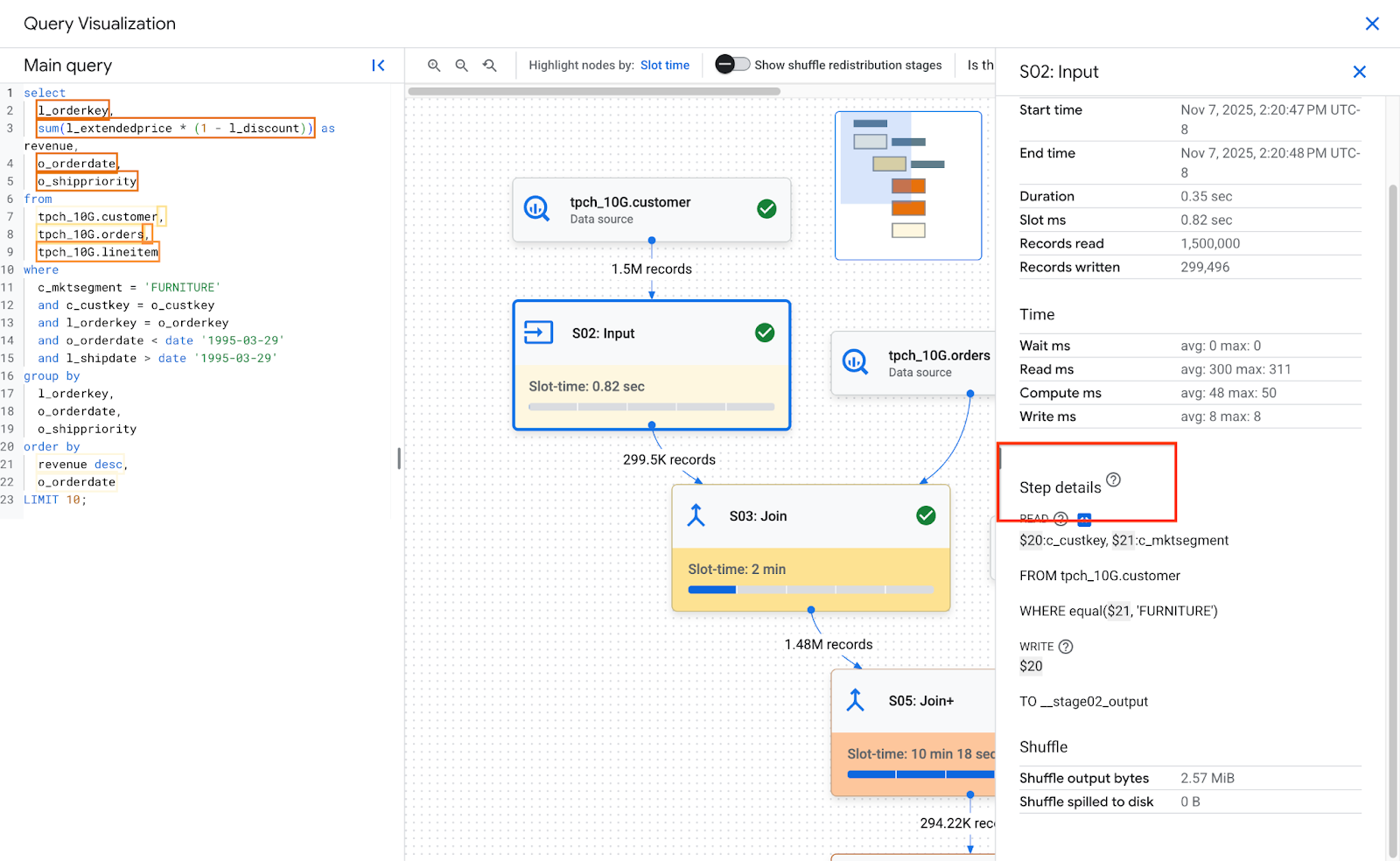
Ao clicar em uma etapa no gráfico, os detalhes dela são mostrados. Os detalhes da etapa têm:
- Estatísticas. Consulte Visão geral da etapa para mais detalhes sobre as estatísticas.
- Detalhes da etapa. As etapas descrevem as operações individuais que executam a lógica da consulta.
Detalhes da etapa
Os estágios são compostos de etapas, as operações individuais que executam a lógica da consulta. As etapas têm subetapas que descrevem o que a etapa fez em pseudocódigo. As subetapas usam variáveis para descrever relações entre etapas. As variáveis começam com um cifrão seguido por um número exclusivo. Os números de variáveis não são compartilhados entre as etapas.
A imagem a seguir mostra as etapas de um estágio:
Confira um exemplo das etapas de uma fase:
READ $30:l_orderkey, $31:l_quantity FROM lineitem AGGREGATE GROUP BY $100 := $30 $70 := SUM($31) WRITE $100, $70 TO __stage00_output BY HASH($100)
As etapas do exemplo descrevem o seguinte:
- A etapa leu as colunas l_orderkey e l_quantity da tabela lineitem e armazenou os valores nas variáveis $30 e $31, respectivamente.
- A etapa agregou as variáveis $30 e $31, armazenando agregações nas variáveis $100 e $70, respectivamente.
- A etapa gravou os resultados das variáveis $100 e $70 para embaralhar. O estágio ordenou os resultados na memória de embaralhamento com base em US $100.
Consulte Interpretar e otimizar etapas para ver todos os detalhes sobre o tipo de etapas e como otimizá-las.
O BigQuery pode truncar subetapas quando o gráfico de execução da consulta é complexo o suficiente para que o fornecimento de subetapas completas cause problemas de tamanho de payload ao recuperar informações da consulta.
Mapa de calor do texto da consulta
O BigQuery pode mapear algumas etapas do estágio para partes do texto da consulta. O mapa de calor de texto da consulta mostra todo o texto correspondente com as etapas do estágio. Ele destaca o texto da consulta com base no tempo total do slot de etapas com texto de consulta mapeado.
A imagem a seguir mostra o texto da consulta destacado:
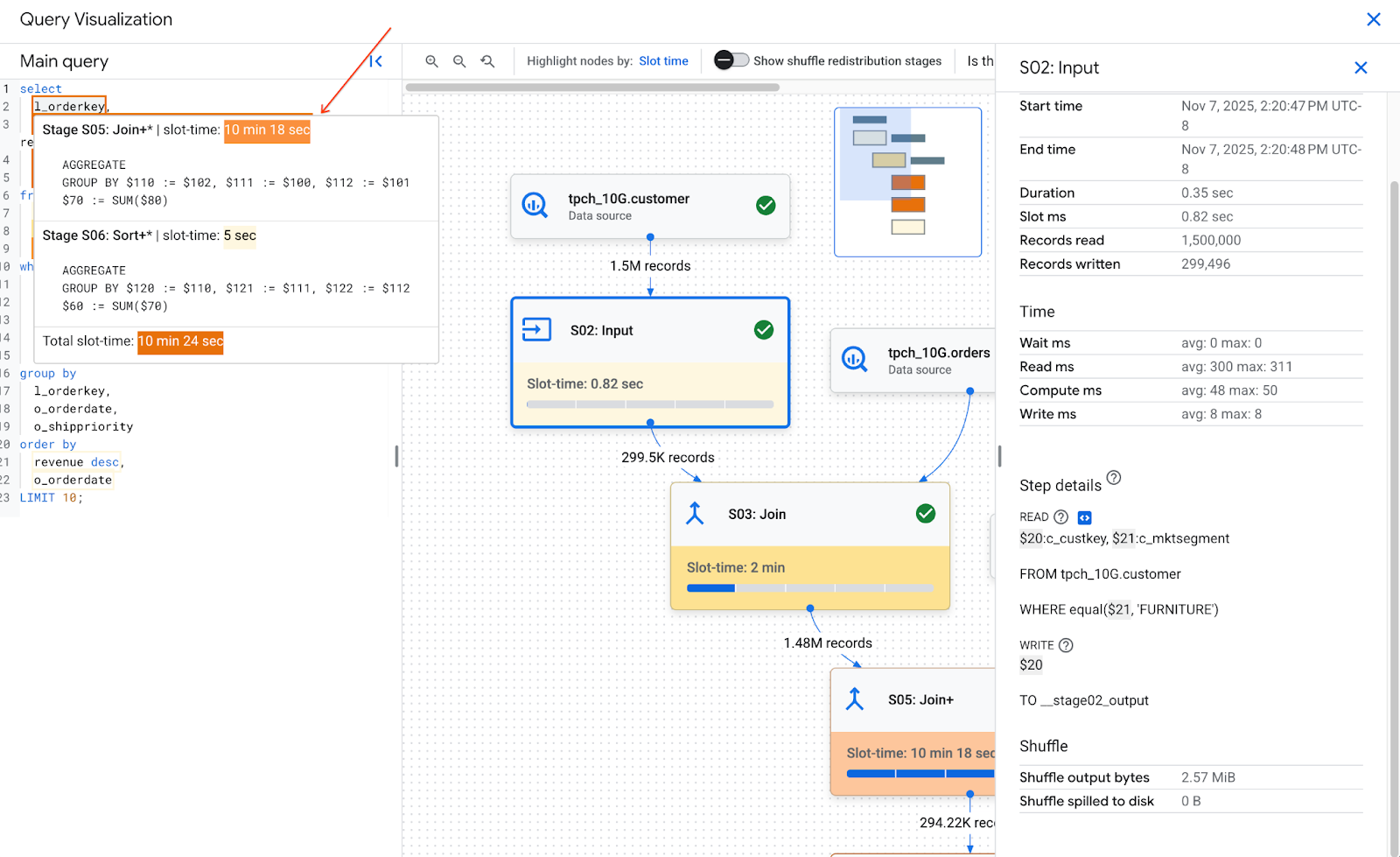
Ao manter o ponteiro sobre uma parte mapeada do texto da consulta, uma dica é exibida com todas as etapas do estágio que correspondem ao texto da consulta, além do tempo de slot do estágio. Ao clicar em um texto de consulta mapeado, a fase é selecionada no gráfico de execução e os detalhes dela são abertos no painel à direita.
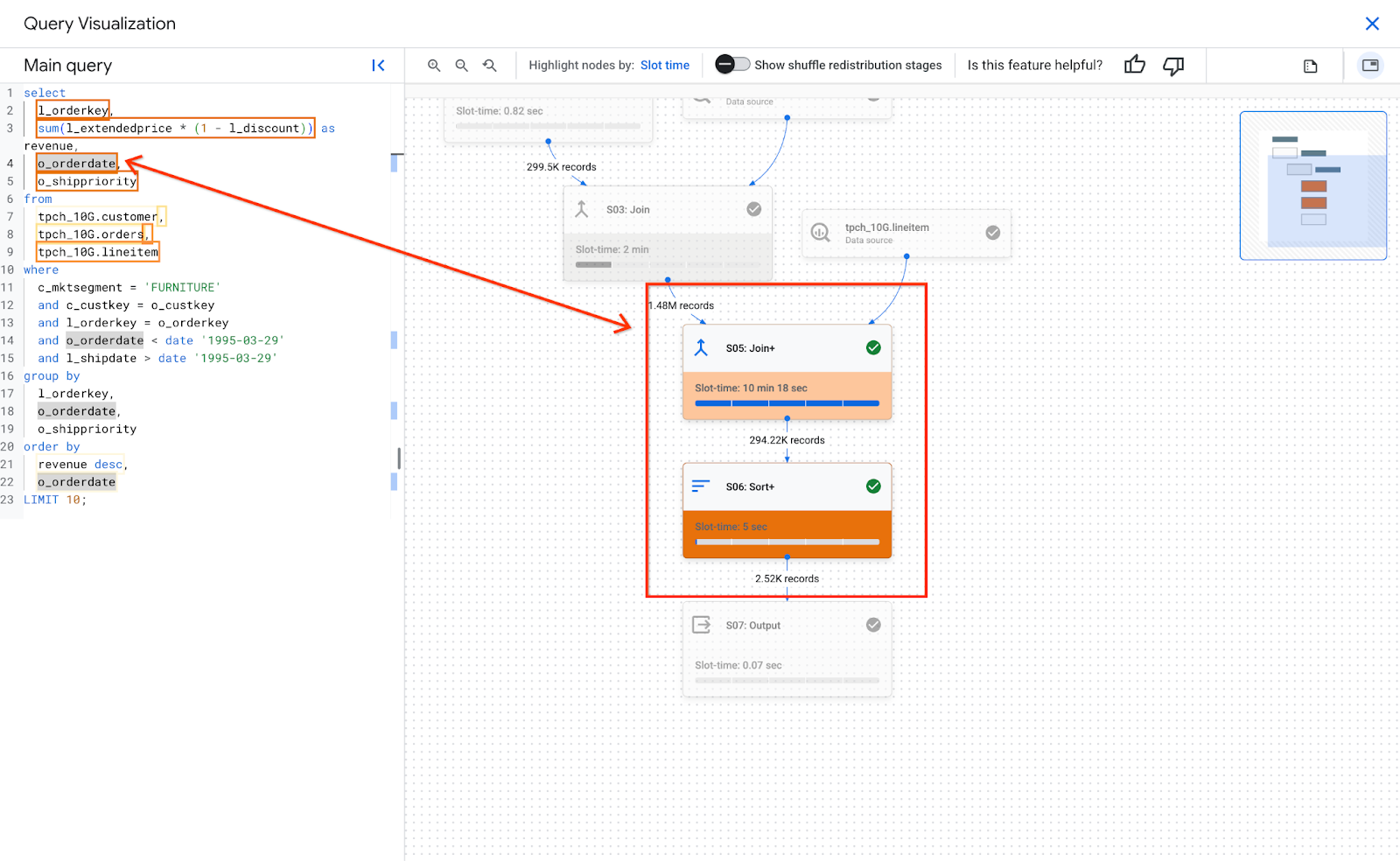
Uma única parte do texto da consulta pode ser mapeada para várias etapas. A dica lista cada etapa mapeada e o tempo de slot dela. Ao clicar no texto da consulta, as etapas correspondentes são destacadas, e o restante do gráfico fica esmaecido. Ao clicar em uma etapa específica, os detalhes dela são mostrados.
A imagem a seguir mostra como o texto da consulta se relaciona aos detalhes da etapa:
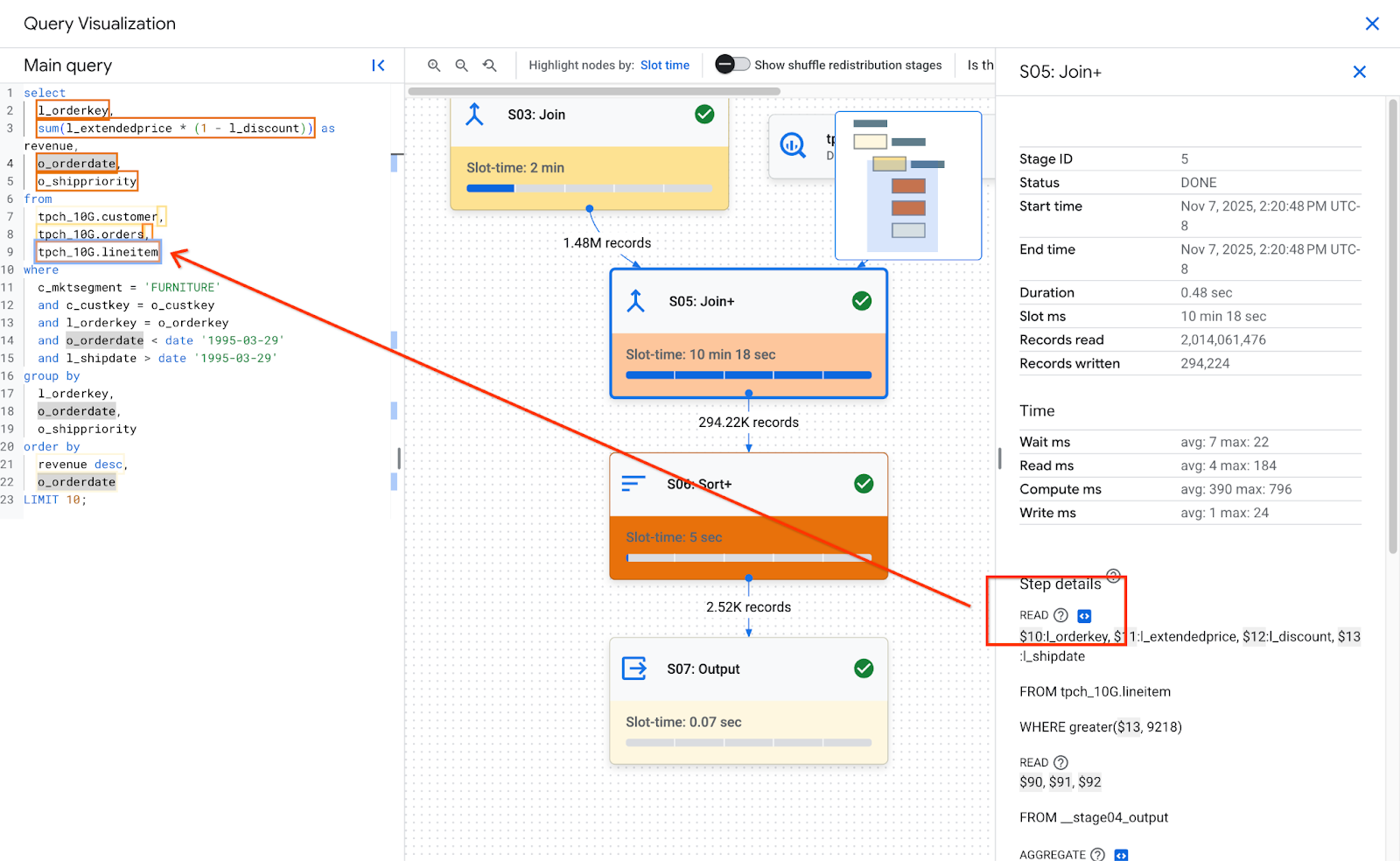
Na seção Detalhes da etapa de um estágio, se uma etapa for mapeada para o texto da consulta, ela terá um ícone de código. Ao clicar no ícone de código, a parte mapeada do texto da consulta à esquerda é destacada.
É importante lembrar que a cor do mapa de calor é baseada no tempo de slot de toda a etapa. Como o BigQuery não mede o tempo de slot das etapas, o mapa de calor não representa o tempo de slot real dessa parte específica do texto da consulta mapeada. Na maioria dos casos, uma etapa realiza apenas uma etapa complexa, como uma junção ou agregação. Assim, a cor do mapa de calor é adequada. No entanto, quando um estágio é composto por etapas que realizam várias operações complexas, a cor do mapa de calor pode representar demais o tempo de slot real. Nesses casos, é importante entender as outras etapas que compõem o estágio para ter uma compreensão mais completa da performance da consulta.
Se uma consulta usar visualizações e as etapas do estágio tiverem mapeamentos para o texto da consulta de uma visualização, o mapa de calor do texto da consulta vai mostrar o nome e o texto da consulta da visualização com os mapeamentos. No entanto, se a visualização for excluída ou se você perder a bigquery.tables.get permissão do IAM nela, o mapa de calor de texto da consulta não vai mostrar os mapeamentos das etapas do estágio para a visualização.
Visão geral do cenário
Os campos de visão geral de cada estágio podem incluir o seguinte:
| Campo da API | Descrição |
|---|---|
id |
Código numérico exclusivo do cenário. |
name |
Nome simples de resumo do cenário. O steps dentro do estágio fornece detalhes adicionais sobre as etapas de execução. |
status |
Status de execução do cenário. Os estados possíveis incluem PENDING, RUNNING, COMPLETE, FAILED e CANCELLED. |
inputStages |
Uma lista dos códigos que formam o gráfico de dependência do cenário. Por exemplo, um cenário JOIN geralmente precisa de dois cenários dependentes que preparam os dados nos lados esquerdo e direito do relacionamento JOIN. |
startMs |
Carimbo de data/hora, em milissegundos da época, que representa quando o primeiro trabalhador no cenário iniciou a execução. |
endMs |
Carimbo de data/hora, em milissegundos de época, que representa quando o último trabalhador concluiu a execução. |
steps |
Lista mais detalhada de etapas de execução no cenário. Consulte a próxima seção para mais informações. |
recordsRead |
Tamanho de entrada do cenário como número de registros, em todos os trabalhadores do cenário. |
recordsWritten |
Tamanho de saída do cenário como número de registros, em todos os trabalhadores do cenário. |
parallelInputs |
Número de unidades de trabalho carregáveis em paralelo do cenário. Dependendo do estágio e da consulta, isso pode representar o número de segmentos colunares em uma tabela ou o número de partições em um embaralhamento intermediário. |
completedParallelInputs |
Número de unidades de trabalho dentro do cenário que foram concluídas. Para algumas consultas, nem todas as entradas dentro de um cenário precisam ser concluídas para que o cenário seja concluído. |
shuffleOutputBytes |
Representa o total de bytes gravados em todos os trabalhadores em um cenário de consulta. |
shuffleOutputBytesSpilled |
Consultas que transmitem dados significativos entre cenários podem precisar recorrer à transmissão baseada em disco. A estatística de bytes espalhados comunica o volume de dados espalhados no disco. Depende de um algoritmo de otimização para que não seja determinístico para qualquer consulta. |
Classificação de cronologia por estágio
Os estágios de consulta fornecem classificações de duração dos estágios, tanto em termos absolutos quanto relativos. Como cada estágio de execução representa o trabalho realizado por um ou mais workers independentes, as informações são fornecidas no tempo médio e no pior cenário. Esses tempos representam o desempenho médio de todos os workers em um estágio, assim como o desempenho mais lento de cauda longa dos workers em uma determinada classificação. Além disso, os tempos médio e máximo são desmembrados nas representações absoluta e relativa. Para estatísticas com base em proporção, os dados são fornecidos como uma fração do maior tempo gasto por qualquer worker em qualquer segmento.
O console Google Cloud apresenta a cronologia dos cenários usando as representações de cronologia relativa.
As informações de cronologia de cenário são relatadas da seguinte maneira:
| Cronologia relativa | Cronologia absoluta | Numerador de proporção |
|---|---|---|
waitRatioAvg |
waitMsAvg |
Tempo que o trabalho médio passou aguardando ser programado. |
waitRatioMax |
waitMsMax |
Tempo que o trabalho mais lento passou aguardando ser programado. |
readRatioAvg |
readMsAvg |
Tempo que o trabalho médio passou lendo dados de entrada. |
readRatioMax |
readMsMax |
Tempo que o trabalho mais lento passou lendo dados de entrada. |
computeRatioAvg |
computeMsAvg |
Tempo que o worker médio passou ligado à CPU. |
computeRatioMax |
computeMsMax |
Tempo que o worker mais lento passou ligado à CPU. |
writeRatioAvg |
writeMsAvg |
Tempo que o trabalho médio passou gravando dados de saída. |
writeRatioMax |
writeMsMax |
Tempo que o worker mais lento passou gravando dados de saída. |
Visão geral da etapa
As etapas contêm as operações que cada worker em um estágio executa, apresentadas como uma lista ordenada de operações. Cada operação de etapa tem uma categoria, e algumas fornecem informações mais detalhadas. As categorias de operação presentes no plano de consulta incluem o seguinte:
| Categoria da etapa | Descrição |
|---|---|
READ |
Uma leitura de uma ou mais colunas de uma tabela de entrada ou de um embaralhamento intermediário. Somente as primeiras dezesseis colunas lidas serão retornadas nos detalhes da etapa. |
WRITE |
Uma gravação de uma ou mais colunas em uma tabela de saída ou em um embaralhamento intermediário. Para saídas particionadas HASH de um estágio, isso também inclui as colunas usadas como a chave de partição. |
COMPUTE |
Avaliação de expressão e funções SQL. |
FILTER |
Usado pelas cláusulas WHERE, OMIT IF e HAVING. |
SORT |
Operação ORDER BY que inclui as chaves de coluna e a ordem de classificação. |
AGGREGATE |
Implementa agregações para cláusulas como GROUP BY ou COUNT, entre outras. |
LIMIT |
Implementa a cláusula LIMIT. |
JOIN |
Implementa junções para cláusulas como JOIN, entre outras. Inclui o tipo de junção e possivelmente as condições de junção. |
ANALYTIC_FUNCTION |
Uma invocação de uma função de janela (também conhecida como "função analítica"). |
USER_DEFINED_FUNCTION |
Uma invocação de uma função definida pelo usuário. |
Interpretar e otimizar etapas
As seções a seguir explicam como interpretar as etapas em um plano de consulta e oferecem maneiras de otimizar suas consultas.
READ etapa
A etapa READ significa que um estágio está acessando dados para processamento. Os dados podem ser lidos diretamente das tabelas referenciadas em uma consulta ou da memória de embaralhamento.
Quando os dados de uma etapa anterior são lidos, o BigQuery lê os dados da memória de
embaralhamento. A quantidade de dados verificados afeta o custo ao usar slots on demand e o desempenho ao usar reservas.
Possíveis problemas de desempenho
- Verificação grande de uma tabela não particionada:se a consulta precisar apenas de uma pequena parte dos dados, isso pode indicar que uma verificação de tabela é ineficiente. O particionamento pode ser uma boa estratégia de otimização.
- Verificação de uma tabela grande com uma pequena proporção de filtro:isso sugere que o filtro não está reduzindo efetivamente os dados verificados. Revise as condições de filtro.
- Bytes de embaralhamento transferidos para o disco:isso sugere que os dados não estão armazenados de maneira eficaz usando técnicas de otimização, como clustering, que podem manter dados semelhantes em clusters.
Otimizar
- Filtragem segmentada:use cláusulas
WHEREde forma estratégica para filtrar dados irrelevantes o quanto antes na consulta. Isso reduz a quantidade de dados que precisam ser processados pela consulta. - Particionamento e clustering:o BigQuery usa o particionamento e o clustering de tabelas para localizar segmentos de dados específicos com eficiência.
Verifique se as tabelas estão particionadas e em cluster com base nos padrões de consulta típicos para minimizar os dados verificados durante as etapas
READ. - Selecione colunas relevantes:evite usar instruções
SELECT *. Em vez disso, selecione colunas específicas ou useSELECT * EXCEPTpara evitar a leitura de dados desnecessários. - Visualizações materializadas:elas podem pré-calcular e armazenar agregações usadas com frequência, reduzindo a necessidade de ler tabelas de base durante as etapas
READpara consultas que usam essas visualizações.
COMPUTE etapa
Na etapa COMPUTE, o BigQuery realiza as seguintes ações nos seus dados:
- Avalia expressões nas cláusulas
SELECT,WHERE,HAVINGe outras da consulta, incluindo cálculos, comparações e operações lógicas. - Executa funções SQL integradas e definidas pelo usuário.
- Filtra linhas de dados com base em condições na consulta.
Otimizar
O plano de consulta pode revelar gargalos na etapa COMPUTE. Procure estágios com cálculos extensos ou um grande número de linhas processadas.
- Correlacione a etapa
COMPUTEcom o volume de dados:se uma etapa mostrar computação significativa e processar um grande volume de dados, ela poderá ser uma boa candidata à otimização. - Dados com distorção:para estágios em que o máximo de computação é significativamente maior do que a média, isso indica que o estágio gastou uma quantidade desproporcional de tempo processando algumas partes dos dados. Considere analisar a distribuição de dados para verificar se há desvio de dados.
- Considere os tipos de dados:use os tipos de dados adequados para suas colunas. Por exemplo, usar números inteiros, datas e carimbos de data/hora em vez de strings pode melhorar o desempenho.
WRITE etapa
As etapas WRITE acontecem para dados intermediários e saída final.
- Gravação na memória de redistribuição:em uma consulta de vários estágios, a etapa
WRITEgeralmente envolve o envio dos dados processados para outra etapa para processamento adicional. Isso é típico da memória de embaralhamento, que combina ou agrega dados de várias fontes. Os dados gravados durante essa etapa geralmente são um resultado intermediário, não a saída final. - Saída final:o resultado da consulta é gravado no destino ou em uma tabela temporária.
Particionamento por hash
Quando uma etapa no plano de consulta grava dados em uma saída particionada por hash, o BigQuery grava as colunas incluídas na saída e a coluna escolhida como chave de partição.
Otimizar
Embora a etapa WRITE em si não seja diretamente otimizada, entender a função dela pode ajudar a identificar possíveis gargalos em etapas anteriores:
- Minimizar os dados gravados:concentre-se em otimizar as etapas anteriores com filtragem e agregação para reduzir a quantidade de dados gravados durante esta etapa.
Particionamento:a gravação se beneficia muito do particionamento de tabelas. Se os dados gravados estiverem confinados a partições específicas, o BigQuery poderá realizar gravações mais rápidas.
Se a instrução DML tiver uma cláusula
WHEREcom uma condição estática em uma coluna de partição de tabela, o BigQuery só vai modificar as partições relevantes da tabela.Compensações de desnormalização:às vezes, a desnormalização pode levar a conjuntos de resultados menores na etapa intermediária
WRITE. No entanto, há desvantagens, como aumento do uso do armazenamento e desafios de consistência de dados.
JOIN etapa
Na etapa JOIN, o BigQuery combina dados de duas fontes.
As junções podem incluir condições de junção. As junções exigem muitos recursos. Ao unir grandes dados no BigQuery, as chaves de junção são embaralhadas de forma independente para se alinhar no mesmo slot, de modo que a junção seja realizada localmente em cada slot.
O plano de consulta para a etapa JOIN geralmente revela os seguintes detalhes:
- Padrão de junção:indica o tipo de junção usado. Cada tipo define quantas linhas das tabelas unidas são incluídas no conjunto de resultados.
- Colunas de junção:são as colunas usadas para corresponder linhas entre as fontes de dados. A escolha de colunas é crucial para a performance da junção.
Padrões de junção
- Mesclagem por transmissão:quando uma tabela, geralmente a menor, cabe na memória de um único nó de trabalho ou slot, o BigQuery pode transmiti-la para todos os outros nós e realizar a mesclagem com eficiência. Procure
JOIN EACH WITH ALLnos detalhes da etapa. - Junção de hash:quando as tabelas são grandes ou uma junção de transmissão não é adequada, uma junção de hash pode ser usada. O BigQuery usa operações de hash e embaralhamento
para embaralhar as tabelas esquerda e direita, de modo que as chaves correspondentes
acabem no mesmo slot para realizar uma junção local. As junções de hash são uma operação cara, já que os dados precisam ser movidos, mas permitem uma correspondência eficiente de linhas entre hashes. Procure
JOIN EACH WITH EACHnos detalhes da etapa. - Mesclagem automática:um antipadrão de SQL em que uma tabela é mesclada com ela mesma.
- Correlação:um antipadrão de SQL que pode causar problemas significativos de desempenho porque gera dados de saída maiores do que as entradas.
- Junção com desvio:a distribuição de dados na chave de junção em uma tabela é muito enviesada e pode causar problemas de desempenho. Procure casos em que o tempo máximo de computação é muito maior que o tempo médio de computação no plano de consulta. Para mais informações, consulte Junção de alta cardinalidade e Distorção de partição.
Depuração
- Grande volume de dados:se o plano de consulta mostrar uma quantidade significativa de dados processados durante a etapa
JOIN, investigue a condição e as chaves de junção. Considere filtrar ou usar chaves de junção mais seletivas. - Distribuição de dados com distorção:analise a distribuição de dados das chaves de junção. Se uma tabela estiver muito enviesada, use estratégias como dividir a consulta ou pré-filtrar.
- Mesclagens de alta cardinalidade:mesclagens que produzem muito mais linhas do que o número de linhas de entrada à esquerda e à direita podem reduzir drasticamente o desempenho da consulta. Evite junções que produzam um número muito grande de linhas.
- Ordenação incorreta da tabela:escolha o tipo de junção adequado, como
INNERouLEFT, e ordene as tabelas da maior para a menor com base nos requisitos da consulta.
Otimizar
- Chaves de junção seletivas:para chaves de junção, use
INT64em vez deSTRINGquando possível. As comparações deSTRINGsão mais lentas do que as deINT64porque comparam cada caractere em uma string. Os números inteiros exigem apenas uma comparação. - Filtrar antes de combinar:aplique filtros de cláusula
WHEREem tabelas individuais antes da junção. Isso reduz a quantidade de dados envolvidos na operação de junção. - Evite funções em colunas de junção:não chame funções em colunas de junção. Em vez disso, padronize os dados da tabela durante o processo de ingestão ou pós-ingestão usando pipelines SQL ELT. Essa abordagem elimina a necessidade de modificar colunas de junção dinamicamente, o que permite junções mais eficientes sem comprometer a integridade de dados.
- Evite mesclagens automáticas:elas são usadas com frequência para calcular relacionamentos dependentes de linha. No entanto, as autojunções podem quadruplicar o número de linhas de saída, causando problemas de desempenho. Em vez de usar mesclagens automáticas, considere usar funções de janela (analíticas).
- Tabelas grandes primeiro:mesmo que o otimizador de consulta SQL possa determinar qual tabela deve ficar em qual lado da junção, ordene as tabelas unidas adequadamente. Recomenda-se colocar a tabela maior primeiro, seguida da menor, e depois por ordem decrescente de tamanho.
- Desnormalização:em alguns casos, a desnormalização estratégica de tabelas (adição de dados redundantes) pode eliminar as junções. No entanto, essa abordagem tem desvantagens em relação ao armazenamento e à consistência de dados.
- Particionamento e clustering:particionar tabelas com base em chaves de junção e fazer o clustering de dados colocados pode acelerar significativamente as junções, permitindo que o BigQuery segmenta partições de dados relevantes.
- Otimizar junções com distorção:para evitar problemas de desempenho associados a junções com distorção, pré-filtre os dados da tabela o quanto antes ou divida a consulta em duas ou mais consultas.
AGGREGATE etapa
Na etapa AGGREGATE, o BigQuery agrega e agrupa dados.
Depuração
- Detalhes da etapa:verifique o número de linhas de entrada e saída da agregação e o tamanho da redistribuição para determinar a redução de dados alcançada pela etapa de agregação e se houve embaralhamento de dados.
- Tamanho do embaralhamento:um tamanho grande pode indicar que uma quantidade significativa de dados foi movida entre nós de trabalho durante a agregação.
- Verifique a distribuição de dados:confira se os dados estão distribuídos de maneira uniforme entre as partições. Isso pode levar a cargas de trabalho desequilibradas na etapa de agregação.
- Analise as agregações:confira se as cláusulas de agregação são necessárias e eficientes.
Otimizar
- Clustering:coloque suas tabelas em cluster nas colunas usadas com frequência em
GROUP BY,COUNTou outras cláusulas de agregação. - Particionamento:escolha uma estratégia de partição que se alinhe aos seus padrões de consulta. Considere usar tabelas particionadas por tempo de processamento para reduzir a quantidade de dados verificados durante a agregação.
- Agregue antes:se possível, faça agregações no início do pipeline de consulta. Isso pode reduzir a quantidade de dados que precisam ser processados durante a agregação.
- Otimização de embaralhamento:se o embaralhamento for um gargalo, procure maneiras de minimizar isso. Por exemplo, desnormalize tabelas ou use clustering para colocar dados relevantes.
Casos extremos
- Agregações DISTINCT:consultas com agregações
DISTINCTpodem ser computacionalmente caras, especialmente em grandes conjuntos de dados. Considere alternativas comoAPPROX_COUNT_DISTINCTpara resultados aproximados. - Grande número de grupos:se a consulta gerar um grande número de grupos, ela poderá consumir uma quantidade considerável de memória. Nesses casos, limite o número de grupos ou use uma estratégia de agregação diferente.
REPARTITION etapa
REPARTITION e COALESCE são técnicas de otimização que o BigQuery aplica diretamente aos dados embaralhados na consulta.
REPARTITION:essa operação tem como objetivo reequilibrar a distribuição de dados entre os nós de trabalho. Suponha que, após o embaralhamento, um nó de trabalho acabe com uma quantidade desproporcionalmente grande de dados. A etapaREPARTITIONredistribui os dados de maneira mais uniforme, evitando que um único worker se torne um gargalo. Isso é muito importante para operações computacionalmente intensivas, como junções.COALESCE:essa etapa acontece quando você tem muitos pequenos intervalos de dados após o embaralhamento. A etapaCOALESCEcombina esses intervalos em outros maiores, reduzindo o overhead associado ao gerenciamento de várias pequenas partes de dados. Isso pode ser especialmente útil ao lidar com conjuntos de resultados intermediários muito pequenos.
Se você encontrar etapas REPARTITION ou COALESCE no plano de consulta, isso não significa necessariamente que há um problema com a consulta. Isso geralmente indica que o BigQuery está otimizando proativamente a distribuição de dados para melhorar a performance. No entanto, se essas operações aparecerem repetidamente, isso pode indicar que os dados estão inerentemente enviesados ou que a consulta está causando um embaralhamento excessivo de dados.
Otimizar
Para reduzir o número de etapas de REPARTITION, tente o seguinte:
- Distribuição de dados:verifique se as tabelas estão particionadas e agrupadas de maneira eficaz. Dados bem distribuídos reduzem a probabilidade de desequilíbrios significativos após o embaralhamento.
- Estrutura da consulta:analise a consulta para identificar possíveis fontes de distorção de dados. Por exemplo, há filtros ou junções altamente seletivos que resultam no processamento de um pequeno subconjunto de dados em um único worker?
- Estratégias de junção:teste diferentes estratégias de junção para verificar se elas levam a uma distribuição de dados mais equilibrada.
Para reduzir o número de etapas de COALESCE, tente o seguinte:
- Estratégias de agregação:considere realizar agregações antes no pipeline de consulta. Isso pode ajudar a reduzir o número de pequenos conjuntos de resultados intermediários que podem causar etapas de
COALESCE. - Volume de dados:se você estiver trabalhando com conjuntos de dados muito pequenos,
COALESCEpode não ser uma preocupação significativa.
Não otimize demais. A otimização prematura pode tornar suas consultas mais complexas sem trazer benefícios significativos.
Explicação para consultas federadas
As consultas federadas permitem enviar uma instrução de consulta a uma fonte de dados externa usando a função EXTERNAL_QUERY.
As consultas federadas estão sujeitas à técnica de otimização conhecida como pushdowns SQL, e o plano de consulta mostra as operações enviadas para a fonte de dados externa, se houver. Por exemplo, se você executar a seguinte consulta:
SELECT id, name
FROM EXTERNAL_QUERY("<connection>", "SELECT * FROM company")
WHERE country_code IN ('ee', 'hu') AND name like '%TV%'
O plano de consulta mostrará as seguintes etapas da fase:
$1:id, $2:name, $3:country_code
FROM table_for_external_query_$_0(
SELECT id, name, country_code
FROM (
/*native_query*/
SELECT * FROM company
)
WHERE in(country_code, 'ee', 'hu')
)
WHERE and(in($3, 'ee', 'hu'), like($2, '%TV%'))
$1, $2
TO __stage00_output
Nesse plano, table_for_external_query_$_0(...) representa a
função EXTERNAL_QUERY. Entre os parênteses, é possível ver a consulta que a
fonte de dados externa executa. Com base nisso, é possível notar que:
- Uma fonte de dados externa retorna apenas três colunas selecionadas.
- Uma fonte de dados externa retorna apenas as linhas em que
country_codeé'ee'ou'hu'. - O operador
LIKEnão é pushdown e é avaliado pelo BigQuery.
Para fins de comparação, se não houver push-downs, o plano de consulta mostrará as seguintes etapas do estágio:
$1:id, $2:name, $3:country_code
FROM table_for_external_query_$_0(
SELECT id, name, description, country_code, primary_address, secondary address
FROM (
/*native_query*/
SELECT * FROM company
)
)
WHERE and(in($3, 'ee', 'hu'), like($2, '%TV%'))
$1, $2
TO __stage00_output
Desta vez, uma fonte de dados externa retorna todas as colunas e linhas da tabela company, e o BigQuery realiza a filtragem.
Metadados do cronograma
O cronograma da consulta informa a evolução em momentos específicos no tempo, fornecendo visualizações instantâneas do progresso geral da consulta. O cronograma é representado por uma série de amostras que informam os seguintes detalhes:
| Campo | Descrição |
|---|---|
elapsedMs |
Milissegundos decorridos desde o início da execução da consulta. |
totalSlotMs |
Uma representação cumulativa dos milissegundos de slot usados pela consulta. |
pendingUnits |
Total de unidades de trabalho programadas que aguardam execução. |
activeUnits |
Total de unidades de trabalho ativas sendo processadas por trabalhadores. |
completedUnits |
Total de unidades de trabalho que foram concluídas durante a execução dessa consulta. |
Um exemplo de consulta
A consulta a seguir conta o número de linhas no conjunto de dados público de Shakespeare e tem uma segunda contagem condicional que restringe os resultados às linhas que fazem referência a "hamlet":
SELECT
COUNT(1) as rowcount,
COUNTIF(corpus = 'hamlet') as rowcount_hamlet
FROM `publicdata.samples.shakespeare`
Clique em Detalhes da execução para ver o plano de consulta:

Os indicadores de cor mostram os tempos relativos de todas as etapas em todos os estágios.
Se quiser saber mais sobre as etapas dos estágios de execução, clique em para expandir os detalhes de cada um:
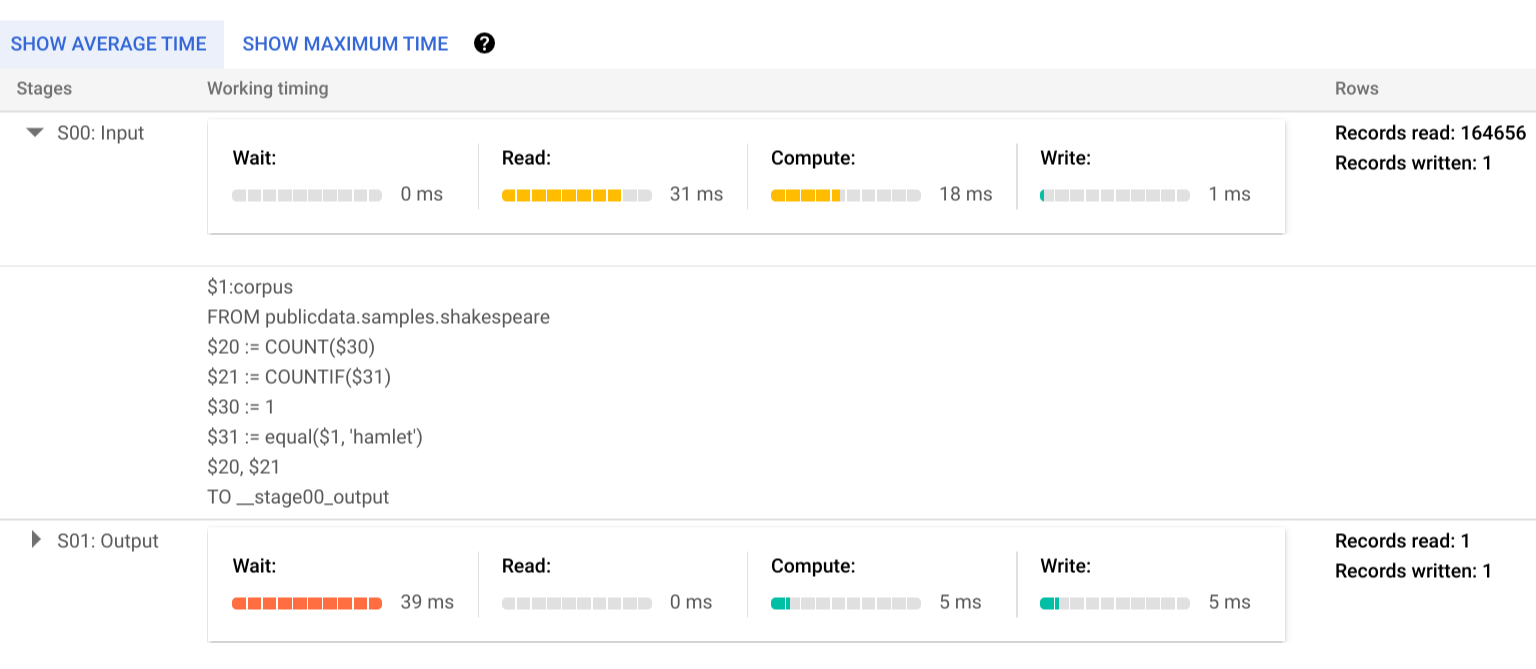
Neste exemplo, o maior tempo em qualquer segmento foi aquele em que o único worker no Estágio 01 passou aguardando a conclusão do Estágio 00. Isso ocorre porque o Estágio 01 era dependente da entrada do Estágio 00 e não podia ser iniciado até que o primeiro estágio gravasse a saída no embaralhamento intermediário.
Error Reporting
É possível que os jobs de consulta falhem no meio da execução. Como as informações do plano são atualizadas periodicamente, é possível observar, no gráfico de execução, onde ocorreu a falha. No console Google Cloud , os estágios bem-sucedidos ou com falha têm uma marca de seleção ou um ponto de exclamação ao lado do nome.
Para mais informações sobre como interpretar e corrigir erros, consulte o Guia de solução de problemas.
Representação de amostra de API
As informações do plano de consulta são incorporadas nas informações de resposta do job. Você consegue recuperá-las chamando jobs.get.
Por exemplo, o trecho a seguir de uma resposta JSON de um job que retorna a consulta de amostra de Hamlet mostra o plano de consulta e as informações de cronograma.
"statistics": {
"creationTime": "1576544129234",
"startTime": "1576544129348",
"endTime": "1576544129681",
"totalBytesProcessed": "2464625",
"query": {
"queryPlan": [
{
"name": "S00: Input",
"id": "0",
"startMs": "1576544129436",
"endMs": "1576544129465",
"waitRatioAvg": 0.04,
"waitMsAvg": "1",
"waitRatioMax": 0.04,
"waitMsMax": "1",
"readRatioAvg": 0.32,
"readMsAvg": "8",
"readRatioMax": 0.32,
"readMsMax": "8",
"computeRatioAvg": 1,
"computeMsAvg": "25",
"computeRatioMax": 1,
"computeMsMax": "25",
"writeRatioAvg": 0.08,
"writeMsAvg": "2",
"writeRatioMax": 0.08,
"writeMsMax": "2",
"shuffleOutputBytes": "18",
"shuffleOutputBytesSpilled": "0",
"recordsRead": "164656",
"recordsWritten": "1",
"parallelInputs": "1",
"completedParallelInputs": "1",
"status": "COMPLETE",
"steps": [
{
"kind": "READ",
"substeps": [
"$1:corpus",
"FROM publicdata.samples.shakespeare"
]
},
{
"kind": "AGGREGATE",
"substeps": [
"$20 := COUNT($30)",
"$21 := COUNTIF($31)"
]
},
{
"kind": "COMPUTE",
"substeps": [
"$30 := 1",
"$31 := equal($1, 'hamlet')"
]
},
{
"kind": "WRITE",
"substeps": [
"$20, $21",
"TO __stage00_output"
]
}
]
},
{
"name": "S01: Output",
"id": "1",
"startMs": "1576544129465",
"endMs": "1576544129480",
"inputStages": [
"0"
],
"waitRatioAvg": 0.44,
"waitMsAvg": "11",
"waitRatioMax": 0.44,
"waitMsMax": "11",
"readRatioAvg": 0,
"readMsAvg": "0",
"readRatioMax": 0,
"readMsMax": "0",
"computeRatioAvg": 0.2,
"computeMsAvg": "5",
"computeRatioMax": 0.2,
"computeMsMax": "5",
"writeRatioAvg": 0.16,
"writeMsAvg": "4",
"writeRatioMax": 0.16,
"writeMsMax": "4",
"shuffleOutputBytes": "17",
"shuffleOutputBytesSpilled": "0",
"recordsRead": "1",
"recordsWritten": "1",
"parallelInputs": "1",
"completedParallelInputs": "1",
"status": "COMPLETE",
"steps": [
{
"kind": "READ",
"substeps": [
"$20, $21",
"FROM __stage00_output"
]
},
{
"kind": "AGGREGATE",
"substeps": [
"$10 := SUM_OF_COUNTS($20)",
"$11 := SUM_OF_COUNTS($21)"
]
},
{
"kind": "WRITE",
"substeps": [
"$10, $11",
"TO __stage01_output"
]
}
]
}
],
"estimatedBytesProcessed": "2464625",
"timeline": [
{
"elapsedMs": "304",
"totalSlotMs": "50",
"pendingUnits": "0",
"completedUnits": "2"
}
],
"totalPartitionsProcessed": "0",
"totalBytesProcessed": "2464625",
"totalBytesBilled": "10485760",
"billingTier": 1,
"totalSlotMs": "50",
"cacheHit": false,
"referencedTables": [
{
"projectId": "publicdata",
"datasetId": "samples",
"tableId": "shakespeare"
}
],
"statementType": "SELECT"
},
"totalSlotMs": "50"
},
Como usar informações de execução
Os planos de consulta do BigQuery fornecem informações sobre como o serviço executa consultas, mas a natureza gerenciada do serviço limita se alguns detalhes são diretamente acionáveis. Muitas otimizações acontecem automaticamente com o uso do serviço, que pode ser diferente de outros ambientes em que o ajuste, provisionamento e monitoramento exigem uma equipe dedicada e capacitada.
Para técnicas específicas capazes de melhorar a execução e o desempenho de consultas, consulte a documentação de práticas recomendadas. O plano de consulta e as estatísticas da linha do tempo podem ajudar você a entender se determinadas etapas dominam a utilização de recursos. Por exemplo, um estágio JOIN que gera muito mais linhas de saída do que de entrada pode indicar uma oportunidade para fazer a filtragem mais cedo na consulta.
Além disso, as informações de cronograma podem ajudar a identificar se determinada consulta é lenta isoladamente ou devido aos efeitos de outras consultas que disputam os mesmos recursos. Se o número de unidades ativas permanece limitado durante todo o ciclo de vida da consulta, mas a quantidade de unidades de trabalho consultadas permanece alta, isso pode indicar que, nesses casos, reduzir o número de consultas simultâneas melhora significativamente o tempo de execução geral de determinadas consultas.