
עבודה עם נתונים של פעולות על ציר הזמן
במאמר הזה מוסבר איך להשתמש בפונקציות SQL כדי לתמוך בניתוח של סדרות זמן.
מבוא
סדרת זמן היא רצף של נקודות על הגרף, שכל אחת מהן מורכבת מזמן ומערך שמשויך לזמן הזה. בדרך כלל, לסדרת זמן יש גם מזהה, שנותן שם ייחודי לסדרת הזמן.
במסדי נתונים רלציוניים, סדרת זמנים מוגדרת כטבלה עם קבוצות העמודות הבאות:
- עמודה עם נתוני זמן
- יכול להיות שיש עמודות חלוקה, למשל מיקוד
- עמודה אחת או יותר של ערכים, או סוג
STRUCTשמשלב כמה ערכים, למשל טמפרטורה ו-AQI
הדוגמה הבאה היא של נתוני סדרות זמן שמסודרים כטבלה:
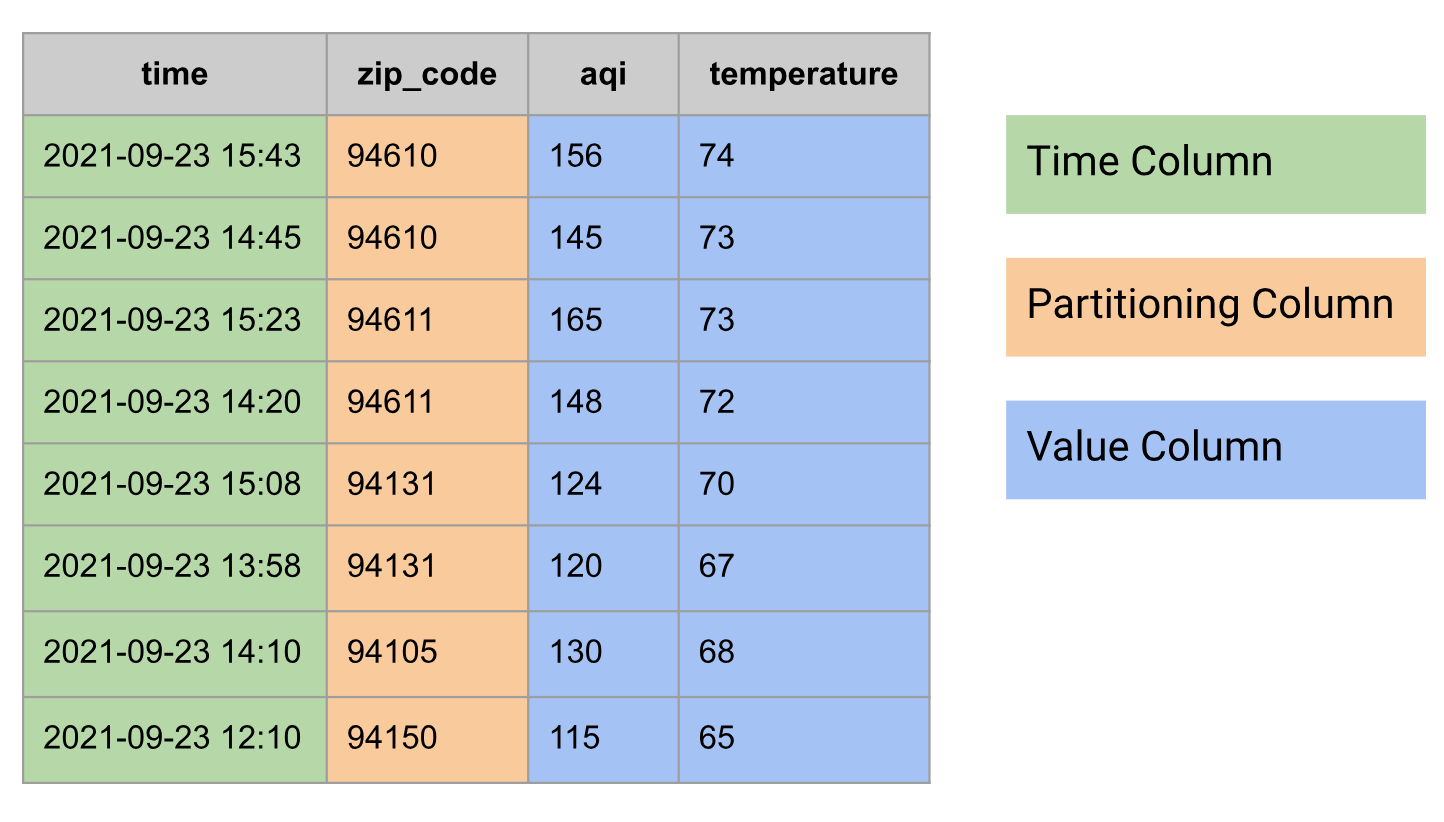
צבירה של סדרת נתונים מבוססת זמן
בניתוח של סדרות נתונים מבוססות זמן, צבירת נתונים לפי זמן היא צבירה שמבוצעת לאורך ציר הזמן.
אפשר לבצע צבירה של נתונים לפי זמן ב-BigQuery בעזרת פונקציות של חלוקה למשבצות זמן (TIMESTAMP_BUCKET, DATE_BUCKET ו-DATETIME_BUCKET). פונקציות של חלוקה למשבצות זמן ממפות ערכי זמן של קלט למשבצת הזמן שאליה הם שייכים.
בדרך כלל, צבירה לפי זמן מתבצעת כדי לשלב כמה נקודות על הגרף בחלון זמן לנקודה על הגרף אחת, באמצעות פונקציית צבירה, כמו AVG, MIN, MAX, COUNT או SUM. לדוגמה, חביון ממוצע של בקשות למשך 15 דקות, טמפרטורות מינימליות ומקסימליות יומיות ומספר הנסיעות היומי במוניות.
עבור השאילתות בקטע הזה, יוצרים טבלה בשם
mydataset.environmental_data_hourly:
CREATE OR REPLACE TABLE mydataset.environmental_data_hourly AS
SELECT * FROM UNNEST(
ARRAY<STRUCT<zip_code INT64, time TIMESTAMP, aqi INT64, temperature INT64>>[
STRUCT(60606, TIMESTAMP '2020-09-08 00:30:51', 22, 66),
STRUCT(60606, TIMESTAMP '2020-09-08 01:32:10', 23, 63),
STRUCT(60606, TIMESTAMP '2020-09-08 02:30:35', 22, 60),
STRUCT(60606, TIMESTAMP '2020-09-08 03:29:39', 21, 58),
STRUCT(60606, TIMESTAMP '2020-09-08 04:33:05', 21, 59),
STRUCT(60606, TIMESTAMP '2020-09-08 05:32:01', 21, 57),
STRUCT(60606, TIMESTAMP '2020-09-08 06:31:14', 22, 56),
STRUCT(60606, TIMESTAMP '2020-09-08 07:31:06', 28, 55),
STRUCT(60606, TIMESTAMP '2020-09-08 08:29:59', 30, 55),
STRUCT(60606, TIMESTAMP '2020-09-08 09:29:34', 31, 55),
STRUCT(60606, TIMESTAMP '2020-09-08 10:31:24', 38, 56),
STRUCT(60606, TIMESTAMP '2020-09-08 11:31:24', 38, 56),
STRUCT(60606, TIMESTAMP '2020-09-08 12:32:38', 38, 57),
STRUCT(60606, TIMESTAMP '2020-09-08 13:29:59', 38, 56),
STRUCT(60606, TIMESTAMP '2020-09-08 14:31:22', 43, 59),
STRUCT(60606, TIMESTAMP '2020-09-08 15:31:38', 42, 63),
STRUCT(60606, TIMESTAMP '2020-09-08 16:34:22', 43, 65),
STRUCT(60606, TIMESTAMP '2020-09-08 17:33:23', 42, 68),
STRUCT(60606, TIMESTAMP '2020-09-08 18:28:47', 36, 69),
STRUCT(60606, TIMESTAMP '2020-09-08 19:30:28', 34, 67),
STRUCT(60606, TIMESTAMP '2020-09-08 20:30:53', 29, 67),
STRUCT(60606, TIMESTAMP '2020-09-08 21:32:28', 27, 67),
STRUCT(60606, TIMESTAMP '2020-09-08 22:31:45', 25, 65),
STRUCT(60606, TIMESTAMP '2020-09-08 23:31:02', 22, 63),
STRUCT(94105, TIMESTAMP '2020-09-08 00:07:11', 60, 74),
STRUCT(94105, TIMESTAMP '2020-09-08 01:07:24', 61, 73),
STRUCT(94105, TIMESTAMP '2020-09-08 02:08:07', 60, 71),
STRUCT(94105, TIMESTAMP '2020-09-08 03:11:05', 69, 69),
STRUCT(94105, TIMESTAMP '2020-09-08 04:07:26', 72, 67),
STRUCT(94105, TIMESTAMP '2020-09-08 05:08:11', 70, 66),
STRUCT(94105, TIMESTAMP '2020-09-08 06:07:30', 68, 65),
STRUCT(94105, TIMESTAMP '2020-09-08 07:07:10', 77, 64),
STRUCT(94105, TIMESTAMP '2020-09-08 08:06:35', 81, 64),
STRUCT(94105, TIMESTAMP '2020-09-08 09:10:18', 82, 63),
STRUCT(94105, TIMESTAMP '2020-09-08 10:08:10', 107, 62),
STRUCT(94105, TIMESTAMP '2020-09-08 11:08:01', 115, 62),
STRUCT(94105, TIMESTAMP '2020-09-08 12:07:39', 120, 62),
STRUCT(94105, TIMESTAMP '2020-09-08 13:06:03', 125, 61),
STRUCT(94105, TIMESTAMP '2020-09-08 14:08:37', 129, 62),
STRUCT(94105, TIMESTAMP '2020-09-08 15:09:19', 150, 62),
STRUCT(94105, TIMESTAMP '2020-09-08 16:06:39', 151, 62),
STRUCT(94105, TIMESTAMP '2020-09-08 17:08:01', 155, 63),
STRUCT(94105, TIMESTAMP '2020-09-08 18:09:23', 154, 64),
STRUCT(94105, TIMESTAMP '2020-09-08 19:08:43', 151, 67),
STRUCT(94105, TIMESTAMP '2020-09-08 20:07:19', 150, 69),
STRUCT(94105, TIMESTAMP '2020-09-08 21:07:37', 148, 72),
STRUCT(94105, TIMESTAMP '2020-09-08 22:08:01', 143, 76),
STRUCT(94105, TIMESTAMP '2020-09-08 23:08:41', 137, 75)
]);
תצפית מעניינת לגבי הנתונים שלמעלה היא שהמדידות מתבצעות במרווחי זמן שרירותיים, שנקראים סדרות זמן לא מיושרות. אגרגציה היא אחת מהדרכים שבהן אפשר ליישר סדרות עיתיות.
ממוצע של 3 שעות
השאילתה הבאה מחשבת את מדד איכות האוויר (AQI) הממוצע ואת הטמפרטורה לכל מיקוד, על פני 3 שעות. הפונקציה TIMESTAMP_BUCKET מבצעת צבירה של נתוני זמן על ידי הקצאת כל ערך זמן ליום מסוים.
SELECT
TIMESTAMP_BUCKET(time, INTERVAL 3 HOUR) AS time,
zip_code,
CAST(AVG(aqi) AS INT64) AS aqi,
CAST(AVG(temperature) AS INT64) AS temperature
FROM mydataset.environmental_data_hourly
GROUP BY zip_code, time
ORDER BY zip_code, time;
/*---------------------+----------+-----+-------------+
| time | zip_code | aqi | temperature |
+---------------------+----------+-----+-------------+
| 2020-09-08 00:00:00 | 60606 | 22 | 63 |
| 2020-09-08 03:00:00 | 60606 | 21 | 58 |
| 2020-09-08 06:00:00 | 60606 | 27 | 55 |
| 2020-09-08 09:00:00 | 60606 | 36 | 56 |
| 2020-09-08 12:00:00 | 60606 | 40 | 57 |
| 2020-09-08 15:00:00 | 60606 | 42 | 65 |
| 2020-09-08 18:00:00 | 60606 | 33 | 68 |
| 2020-09-08 21:00:00 | 60606 | 25 | 65 |
| 2020-09-08 00:00:00 | 94105 | 60 | 73 |
| 2020-09-08 03:00:00 | 94105 | 70 | 67 |
| 2020-09-08 06:00:00 | 94105 | 75 | 64 |
| 2020-09-08 09:00:00 | 94105 | 101 | 62 |
| 2020-09-08 12:00:00 | 94105 | 125 | 62 |
| 2020-09-08 15:00:00 | 94105 | 152 | 62 |
| 2020-09-08 18:00:00 | 94105 | 152 | 67 |
| 2020-09-08 21:00:00 | 94105 | 143 | 74 |
+---------------------+----------+-----+-------------*/
התעריף הטוב ביותר לזהב שלכם
בשאילתה הבאה, מחשבים את הטמפרטורות המינימליות והמקסימליות כל 3 שעות לכל מיקוד:
SELECT
TIMESTAMP_BUCKET(time, INTERVAL 3 HOUR) AS time,
zip_code,
MIN(temperature) AS temperature_min,
MAX(temperature) AS temperature_max,
FROM mydataset.environmental_data_hourly
GROUP BY zip_code, time
ORDER BY zip_code, time;
/*---------------------+----------+-----------------+-----------------+
| time | zip_code | temperature_min | temperature_max |
+---------------------+----------+-----------------+-----------------+
| 2020-09-08 00:00:00 | 60606 | 60 | 66 |
| 2020-09-08 03:00:00 | 60606 | 57 | 59 |
| 2020-09-08 06:00:00 | 60606 | 55 | 56 |
| 2020-09-08 09:00:00 | 60606 | 55 | 56 |
| 2020-09-08 12:00:00 | 60606 | 56 | 59 |
| 2020-09-08 15:00:00 | 60606 | 63 | 68 |
| 2020-09-08 18:00:00 | 60606 | 67 | 69 |
| 2020-09-08 21:00:00 | 60606 | 63 | 67 |
| 2020-09-08 00:00:00 | 94105 | 71 | 74 |
| 2020-09-08 03:00:00 | 94105 | 66 | 69 |
| 2020-09-08 06:00:00 | 94105 | 64 | 65 |
| 2020-09-08 09:00:00 | 94105 | 62 | 63 |
| 2020-09-08 12:00:00 | 94105 | 61 | 62 |
| 2020-09-08 15:00:00 | 94105 | 62 | 63 |
| 2020-09-08 18:00:00 | 94105 | 64 | 69 |
| 2020-09-08 21:00:00 | 94105 | 72 | 76 |
+---------------------+----------+-----------------+-----------------*/
קבלת ממוצע של 3 שעות עם התאמה אישית
כשמבצעים צבירה של נתוני סדרות זמן, משתמשים בהתאמה ספציפית לחלונות של סדרות זמן, באופן מרומז או מפורש. השאילתות הקודמות השתמשו בהתאמה מרומזת, שיצרה קבוצות שהתחילו בזמנים כמו 00:00:00, 03:00:00 ו-06:00:00. כדי להגדיר את היישור הזה באופן מפורש בפונקציה TIMESTAMP_BUCKET, מעבירים ארגומנט אופציונלי שמציין את המקור.
בשאילתה הבאה, המקור מוגדר כ-2020-01-01 02:00:00. השינוי הזה משפיע על ההתאמה ויוצר קטגוריות שמתחילות בזמנים כמו 02:00:00, 05:00:00 ו-08:00:00:
SELECT
TIMESTAMP_BUCKET(time, INTERVAL 3 HOUR, TIMESTAMP '2020-01-01 02:00:00') AS time,
zip_code,
CAST(AVG(aqi) AS INT64) AS aqi,
CAST(AVG(temperature) AS INT64) AS temperature
FROM mydataset.environmental_data_hourly
GROUP BY zip_code, time
ORDER BY zip_code, time;
/*---------------------+----------+-----+-------------+
| time | zip_code | aqi | temperature |
+---------------------+----------+-----+-------------+
| 2020-09-07 23:00:00 | 60606 | 23 | 65 |
| 2020-09-08 02:00:00 | 60606 | 21 | 59 |
| 2020-09-08 05:00:00 | 60606 | 24 | 56 |
| 2020-09-08 08:00:00 | 60606 | 33 | 55 |
| 2020-09-08 11:00:00 | 60606 | 38 | 56 |
| 2020-09-08 14:00:00 | 60606 | 43 | 62 |
| 2020-09-08 17:00:00 | 60606 | 37 | 68 |
| 2020-09-08 20:00:00 | 60606 | 27 | 66 |
| 2020-09-08 23:00:00 | 60606 | 22 | 63 |
| 2020-09-07 23:00:00 | 94105 | 61 | 74 |
| 2020-09-08 02:00:00 | 94105 | 67 | 69 |
| 2020-09-08 05:00:00 | 94105 | 72 | 65 |
| 2020-09-08 08:00:00 | 94105 | 90 | 63 |
| 2020-09-08 11:00:00 | 94105 | 120 | 62 |
| 2020-09-08 14:00:00 | 94105 | 143 | 62 |
| 2020-09-08 17:00:00 | 94105 | 153 | 65 |
| 2020-09-08 20:00:00 | 94105 | 147 | 72 |
| 2020-09-08 23:00:00 | 94105 | 137 | 75 |
+---------------------+----------+-----+-------------*/
צבירה של סדרות נתונים מבוססות זמן עם השלמת פערים
לפעמים אחרי שמצברים סדרת נתונים לפי זמן, יכול להיות שיהיו פערים בנתונים שצריך למלא בערכים מסוימים כדי להמשיך לנתח את הנתונים או להציג אותם.
הטכניקה שמשמשת למילוי הפערים האלה נקראת מילוי פערים. ב-BigQuery, אפשר להשתמש בפונקציית הטבלה GAP_FILL כדי למלא פערים בנתוני סדרות זמן, באמצעות אחת משיטות מילוי הפערים שזמינות:
- NULL, נקרא גם קבוע
- LOCF, last observation carried forward
- ליניארי, אינטרפולציה ליניארית בין שתי נקודות נתונים סמוכות
עבור השאילתות בקטע הזה, צריך ליצור טבלה בשם mydataset.environmental_data_hourly_with_gaps שמבוססת על הנתונים שבהם השתמשנו בקטע הקודם, אבל עם פערים. בתרחישים בעולם האמיתי, יכול להיות שיהיו נקודות נתונים חסרות בגלל תקלה קצרת טווח בתחנת מזג האוויר.
CREATE OR REPLACE TABLE mydataset.environmental_data_hourly_with_gaps AS
SELECT * FROM UNNEST(
ARRAY<STRUCT<zip_code INT64, time TIMESTAMP, aqi INT64, temperature INT64>>[
STRUCT(60606, TIMESTAMP '2020-09-08 00:30:51', 22, 66),
STRUCT(60606, TIMESTAMP '2020-09-08 01:32:10', 23, 63),
STRUCT(60606, TIMESTAMP '2020-09-08 02:30:35', 22, 60),
STRUCT(60606, TIMESTAMP '2020-09-08 03:29:39', 21, 58),
STRUCT(60606, TIMESTAMP '2020-09-08 04:33:05', 21, 59),
STRUCT(60606, TIMESTAMP '2020-09-08 05:32:01', 21, 57),
STRUCT(60606, TIMESTAMP '2020-09-08 06:31:14', 22, 56),
STRUCT(60606, TIMESTAMP '2020-09-08 07:31:06', 28, 55),
STRUCT(60606, TIMESTAMP '2020-09-08 08:29:59', 30, 55),
STRUCT(60606, TIMESTAMP '2020-09-08 09:29:34', 31, 55),
STRUCT(60606, TIMESTAMP '2020-09-08 10:31:24', 38, 56),
STRUCT(60606, TIMESTAMP '2020-09-08 11:31:24', 38, 56),
-- No data points between hours 12 and 15.
STRUCT(60606, TIMESTAMP '2020-09-08 16:34:22', 43, 65),
STRUCT(60606, TIMESTAMP '2020-09-08 17:33:23', 42, 68),
STRUCT(60606, TIMESTAMP '2020-09-08 18:28:47', 36, 69),
STRUCT(60606, TIMESTAMP '2020-09-08 19:30:28', 34, 67),
STRUCT(60606, TIMESTAMP '2020-09-08 20:30:53', 29, 67),
STRUCT(60606, TIMESTAMP '2020-09-08 21:32:28', 27, 67),
STRUCT(60606, TIMESTAMP '2020-09-08 22:31:45', 25, 65),
STRUCT(60606, TIMESTAMP '2020-09-08 23:31:02', 22, 63),
STRUCT(94105, TIMESTAMP '2020-09-08 00:07:11', 60, 74),
STRUCT(94105, TIMESTAMP '2020-09-08 01:07:24', 61, 73),
STRUCT(94105, TIMESTAMP '2020-09-08 02:08:07', 60, 71),
STRUCT(94105, TIMESTAMP '2020-09-08 03:11:05', 69, 69),
STRUCT(94105, TIMESTAMP '2020-09-08 04:07:26', 72, 67),
STRUCT(94105, TIMESTAMP '2020-09-08 05:08:11', 70, 66),
STRUCT(94105, TIMESTAMP '2020-09-08 06:07:30', 68, 65),
STRUCT(94105, TIMESTAMP '2020-09-08 07:07:10', 77, 64),
STRUCT(94105, TIMESTAMP '2020-09-08 08:06:35', 81, 64),
STRUCT(94105, TIMESTAMP '2020-09-08 09:10:18', 82, 63),
STRUCT(94105, TIMESTAMP '2020-09-08 10:08:10', 107, 62),
STRUCT(94105, TIMESTAMP '2020-09-08 11:08:01', 115, 62),
STRUCT(94105, TIMESTAMP '2020-09-08 12:07:39', 120, 62),
STRUCT(94105, TIMESTAMP '2020-09-08 13:06:03', 125, 61),
STRUCT(94105, TIMESTAMP '2020-09-08 14:08:37', 129, 62),
-- No data points between hours 15 and 18.
STRUCT(94105, TIMESTAMP '2020-09-08 19:08:43', 151, 67),
STRUCT(94105, TIMESTAMP '2020-09-08 20:07:19', 150, 69),
STRUCT(94105, TIMESTAMP '2020-09-08 21:07:37', 148, 72),
STRUCT(94105, TIMESTAMP '2020-09-08 22:08:01', 143, 76),
STRUCT(94105, TIMESTAMP '2020-09-08 23:08:41', 137, 75)
]);
קבלת ממוצע ל-3 שעות (כולל פערים)
השאילתה הבאה מחשבת את הממוצע של איכות האוויר והטמפרטורה כל 3 שעות לכל מיקוד:
SELECT
TIMESTAMP_BUCKET(time, INTERVAL 3 HOUR) AS time,
zip_code,
CAST(AVG(aqi) AS INT64) AS aqi,
CAST(AVG(temperature) AS INT64) AS temperature
FROM mydataset.environmental_data_hourly_with_gaps
GROUP BY zip_code, time
ORDER BY zip_code, time;
/*---------------------+----------+-----+-------------+
| time | zip_code | aqi | temperature |
+---------------------+----------+-----+-------------+
| 2020-09-08 00:00:00 | 60606 | 22 | 63 |
| 2020-09-08 03:00:00 | 60606 | 21 | 58 |
| 2020-09-08 06:00:00 | 60606 | 27 | 55 |
| 2020-09-08 09:00:00 | 60606 | 36 | 56 |
| 2020-09-08 15:00:00 | 60606 | 43 | 67 |
| 2020-09-08 18:00:00 | 60606 | 33 | 68 |
| 2020-09-08 21:00:00 | 60606 | 25 | 65 |
| 2020-09-08 00:00:00 | 94105 | 60 | 73 |
| 2020-09-08 03:00:00 | 94105 | 70 | 67 |
| 2020-09-08 06:00:00 | 94105 | 75 | 64 |
| 2020-09-08 09:00:00 | 94105 | 101 | 62 |
| 2020-09-08 12:00:00 | 94105 | 125 | 62 |
| 2020-09-08 18:00:00 | 94105 | 151 | 68 |
| 2020-09-08 21:00:00 | 94105 | 143 | 74 |
+---------------------+----------+-----+-------------*/
שימו לב שיש פערים בפלט במרווחי זמן מסוימים. לדוגמה, בסדרת הזמן של המיקוד 60606 אין נקודה על הגרף ב-2020-09-08 12:00:00, ובסדרת הזמן של המיקוד 94105 אין נקודה על הגרף ב-2020-09-08 15:00:00.
קבלת ממוצע ל-3 שעות (מילוי פערים)
משתמשים בשאילתה מהקטע הקודם ומוסיפים את הפונקציה GAP_FILL כדי למלא את הפערים:
WITH aggregated_3_hr AS (
SELECT
TIMESTAMP_BUCKET(time, INTERVAL 3 HOUR) AS time,
zip_code,
CAST(AVG(aqi) AS INT64) AS aqi,
CAST(AVG(temperature) AS INT64) AS temperature
FROM mydataset.environmental_data_hourly_with_gaps
GROUP BY zip_code, time)
SELECT *
FROM GAP_FILL(
TABLE aggregated_3_hr,
ts_column => 'time',
bucket_width => INTERVAL 3 HOUR,
partitioning_columns => ['zip_code']
)
ORDER BY zip_code, time;
/*---------------------+----------+------+-------------+
| time | zip_code | aqi | temperature |
+---------------------+----------+------+-------------+
| 2020-09-08 00:00:00 | 60606 | 22 | 63 |
| 2020-09-08 03:00:00 | 60606 | 21 | 58 |
| 2020-09-08 06:00:00 | 60606 | 27 | 55 |
| 2020-09-08 09:00:00 | 60606 | 36 | 56 |
| 2020-09-08 12:00:00 | 60606 | NULL | NULL |
| 2020-09-08 15:00:00 | 60606 | 43 | 67 |
| 2020-09-08 18:00:00 | 60606 | 33 | 68 |
| 2020-09-08 21:00:00 | 60606 | 25 | 65 |
| 2020-09-08 00:00:00 | 94105 | 60 | 73 |
| 2020-09-08 03:00:00 | 94105 | 70 | 67 |
| 2020-09-08 06:00:00 | 94105 | 75 | 64 |
| 2020-09-08 09:00:00 | 94105 | 101 | 62 |
| 2020-09-08 12:00:00 | 94105 | 125 | 62 |
| 2020-09-08 15:00:00 | 94105 | NULL | NULL |
| 2020-09-08 18:00:00 | 94105 | 151 | 68 |
| 2020-09-08 21:00:00 | 94105 | 143 | 74 |
+---------------------+----------+------+-------------*/
בטבלת הפלט חסרה עכשיו שורה במיקום 2020-09-08 12:00:00 למיקוד 60606 ובמיקום 2020-09-08 15:00:00 למיקוד 94105, עם ערכי NULL בעמודות המדדים המתאימות. מכיוון שלא ציינת שיטה להשלמת פערים, GAP_FILL השתמש בשיטה להשלמת פערים שמוגדרת כברירת מחדל, NULL.
מילוי פערים באמצעות מילוי פערים ליניארי ומילוי פערים באמצעות LOCF
בשילוב עם הפונקציה GAP_FILL נעשה שימוש בשאילתה הבאה בשיטת מילוי הפערים LOCF עבור העמודה aqi ובאינטרפולציה לינארית עבור העמודה temperature:
WITH aggregated_3_hr AS (
SELECT
TIMESTAMP_BUCKET(time, INTERVAL 3 HOUR) AS time,
zip_code,
CAST(AVG(aqi) AS INT64) AS aqi,
CAST(AVG(temperature) AS INT64) AS temperature
FROM mydataset.environmental_data_hourly_with_gaps
GROUP BY zip_code, time)
SELECT *
FROM GAP_FILL(
TABLE aggregated_3_hr,
ts_column => 'time',
bucket_width => INTERVAL 3 HOUR,
partitioning_columns => ['zip_code'],
value_columns => [
('aqi', 'locf'),
('temperature', 'linear')
]
)
ORDER BY zip_code, time;
/*---------------------+----------+-----+-------------+
| time | zip_code | aqi | temperature |
+---------------------+----------+-----+-------------+
| 2020-09-08 00:00:00 | 60606 | 22 | 63 |
| 2020-09-08 03:00:00 | 60606 | 21 | 58 |
| 2020-09-08 06:00:00 | 60606 | 27 | 55 |
| 2020-09-08 09:00:00 | 60606 | 36 | 56 |
| 2020-09-08 12:00:00 | 60606 | 36 | 62 |
| 2020-09-08 15:00:00 | 60606 | 43 | 67 |
| 2020-09-08 18:00:00 | 60606 | 33 | 68 |
| 2020-09-08 21:00:00 | 60606 | 25 | 65 |
| 2020-09-08 00:00:00 | 94105 | 60 | 73 |
| 2020-09-08 03:00:00 | 94105 | 70 | 67 |
| 2020-09-08 06:00:00 | 94105 | 75 | 64 |
| 2020-09-08 09:00:00 | 94105 | 101 | 62 |
| 2020-09-08 12:00:00 | 94105 | 125 | 62 |
| 2020-09-08 15:00:00 | 94105 | 125 | 65 |
| 2020-09-08 18:00:00 | 94105 | 151 | 68 |
| 2020-09-08 21:00:00 | 94105 | 143 | 74 |
+---------------------+----------+-----+-------------*/
בשורה הראשונה שבה הושלמו נתונים בשאילתה הזו, הערך של aqi הוא 36, שנלקח מנקודה על הגרף הקודמת של סדרת הזמן הזו (מיקוד 60606) בשעה 2020-09-08 09:00:00. הערך temperature 62 הוא תוצאה של אינטרפולציה ליניארית בין נקודות הנתונים 2020-09-08 09:00:00 ו-2020-09-08 15:00:00. השורה החסרה השנייה נוצרה באופן דומה – הערך aqi
value 125 הועבר מנקודת הנתונים הקודמת של סדרת הזמן הזו
(מיקוד 94105), וערך הטמפרטורה 65 הוא תוצאה של אינטרפולציה לינארית בין נקודות הנתונים הקודמות והבאות שזמינות.
התאמה של סדרת נתונים מבוססת זמן עם השלמת פערים
אפשר ליישר את סדרת הזמן או לא ליישר אותה. סדרת זמן מיושרת אם נקודות הנתונים מופיעות רק במרווחי זמן קבועים.
במציאות, בזמן האיסוף, סדרות הזמן הן בדרך כלל לא מיושרות ונדרש עיבוד נוסף כדי ליישר אותן.
לדוגמה, מכשירי IoT ששולחים את המדדים שלהם למרכז איסוף כל דקה. אי אפשר לצפות שהמכשירים ישלחו את המדדים שלהם בדיוק באותם רגעים. בדרך כלל, כל מכשיר שולח את המדדים שלו באותה תדירות (תקופה), אבל עם היסט זמן שונה (התאמה). התרשים הבא ממחיש את הדוגמה הזו. אפשר לראות שכל מכשיר שולח את הנתונים שלו במרווח של דקה, אבל יש מקרים שבהם הנתונים חסרים (מכשיר 3 בשעה 9:36:39) או מתעכבים (מכשיר 1 בשעה 9:37:28).

אפשר לבצע התאמה של סדרות זמן על נתונים לא מותאמים באמצעות צבירה לפי זמן. האפשרות הזו שימושית אם רוצים לשנות את תקופת הדגימה של סדרת הזמן, למשל לשנות מתקופת הדגימה המקורית של דקה אחת לתקופה של 15 דקות. אפשר ליישר את הנתונים כדי לעבד עוד את סדרת הזמנים, למשל כדי לצרף את נתוני סדרת הזמנים, או כדי להציג אותם (למשל, ליצור תרשים).
אפשר להשתמש בפונקציית הטבלה GAP_FILL עם שיטות LOCF או שיטות ליניאריות למילוי פערים כדי לבצע התאמה של סדרות זמן. הרעיון הוא להשתמש ב-GAP_FILL עם תקופת הפלט וההתאמה שנבחרו (שנשלטות על ידי ארגומנט המקור האופציונלי). תוצאת הפעולה היא טבלה עם סדרות זמן מיושרות, שבה הערכים של כל נקודה על הגרף נגזרים מסדרות הזמן של הקלט באמצעות שיטת מילוי הפערים שבה נעשה שימוש בעמודת הערכים הספציפית הזו (LOCF או לינארית).
צור טבלה mydataset.device_data, שדומה לאיור הקודם:
CREATE OR REPLACE TABLE mydataset.device_data AS
SELECT * FROM UNNEST(
ARRAY<STRUCT<device_id INT64, time TIMESTAMP, signal INT64, state STRING>>[
STRUCT(2, TIMESTAMP '2023-11-01 09:35:07', 87, 'ACTIVE'),
STRUCT(1, TIMESTAMP '2023-11-01 09:35:26', 82, 'ACTIVE'),
STRUCT(3, TIMESTAMP '2023-11-01 09:35:39', 74, 'INACTIVE'),
STRUCT(2, TIMESTAMP '2023-11-01 09:36:07', 88, 'ACTIVE'),
STRUCT(1, TIMESTAMP '2023-11-01 09:36:26', 82, 'ACTIVE'),
STRUCT(2, TIMESTAMP '2023-11-01 09:37:07', 88, 'ACTIVE'),
STRUCT(1, TIMESTAMP '2023-11-01 09:37:28', 80, 'ACTIVE'),
STRUCT(3, TIMESTAMP '2023-11-01 09:37:39', 77, 'ACTIVE'),
STRUCT(2, TIMESTAMP '2023-11-01 09:38:07', 86, 'ACTIVE'),
STRUCT(1, TIMESTAMP '2023-11-01 09:38:26', 81, 'ACTIVE'),
STRUCT(3, TIMESTAMP '2023-11-01 09:38:39', 77, 'ACTIVE')
]);
אלה הנתונים בפועל, מסודרים לפי העמודות time ו-device_id:
SELECT * FROM mydataset.device_data ORDER BY time, device_id;
/*-----------+---------------------+--------+----------+
| device_id | time | signal | state |
+-----------+---------------------+--------+----------+
| 2 | 2023-11-01 09:35:07 | 87 | ACTIVE |
| 1 | 2023-11-01 09:35:26 | 82 | ACTIVE |
| 3 | 2023-11-01 09:35:39 | 74 | INACTIVE |
| 2 | 2023-11-01 09:36:07 | 88 | ACTIVE |
| 1 | 2023-11-01 09:36:26 | 82 | ACTIVE |
| 2 | 2023-11-01 09:37:07 | 88 | ACTIVE |
| 1 | 2023-11-01 09:37:28 | 80 | ACTIVE |
| 3 | 2023-11-01 09:37:39 | 77 | ACTIVE |
| 2 | 2023-11-01 09:38:07 | 86 | ACTIVE |
| 1 | 2023-11-01 09:38:26 | 81 | ACTIVE |
| 3 | 2023-11-01 09:38:39 | 77 | ACTIVE |
+-----------+---------------------+--------+----------*/
הטבלה מכילה את סדרת הזמן של כל מכשיר עם שתי עמודות של מדדים:
-
signal– רמת האות כפי שנצפתה על ידי המכשיר בזמן הדגימה, מיוצגת כערך שלם בין0ל-100. -
state- מצב המכשיר בזמן הדגימה, שמוצג כמחרוזת חופשית.
בשאילתה הבאה, נעשה שימוש בפונקציה GAP_FILL כדי ליישר את סדרת הזמן במרווחי זמן של דקה אחת. שימו לב איך נעשה שימוש באינטרפולציה לינארית כדי לחשב את הערכים בעמודה signal, ואיך נעשה שימוש ב-LOCF בעמודה state. בדוגמה הזו, אינטרפולציה לינארית היא בחירה מתאימה לחישוב ערכי הפלט.
SELECT *
FROM GAP_FILL(
TABLE mydataset.device_data,
ts_column => 'time',
bucket_width => INTERVAL 1 MINUTE,
partitioning_columns => ['device_id'],
value_columns => [
('signal', 'linear'),
('state', 'locf')
]
)
ORDER BY time, device_id;
/*---------------------+-----------+--------+----------+
| time | device_id | signal | state |
+---------------------+-----------+--------+----------+
| 2023-11-01 09:36:00 | 1 | 82 | ACTIVE |
| 2023-11-01 09:36:00 | 2 | 88 | ACTIVE |
| 2023-11-01 09:36:00 | 3 | 75 | INACTIVE |
| 2023-11-01 09:37:00 | 1 | 81 | ACTIVE |
| 2023-11-01 09:37:00 | 2 | 88 | ACTIVE |
| 2023-11-01 09:37:00 | 3 | 76 | INACTIVE |
| 2023-11-01 09:38:00 | 1 | 81 | ACTIVE |
| 2023-11-01 09:38:00 | 2 | 86 | ACTIVE |
| 2023-11-01 09:38:00 | 3 | 77 | ACTIVE |
+---------------------+-----------+--------+----------*/
טבלת הפלט מכילה סדרת זמן מיושרת לכל מכשיר ועמודות ערכים (signal ו-state), שמחושבות באמצעות שיטות למילוי פערים שצוינו בקריאה לפונקציה.
איחוד נתונים של פעולות על ציר הזמן
אפשר להצטרף לנתוני סדרות זמן באמצעות הצטרפות עם חלון או הצטרפות מסוג AS OF.
איחוד בחלון
לפעמים צריך לצרף שתי טבלאות או יותר עם נתונים של סדרות עיתיות. כדאי לעיין בשתי הטבלאות הבאות:
-
mydataset.sensor_temperatures, מכיל נתוני טמפרטורה שדווחו על ידי כל חיישן כל 15 שניות. -
mydataset.sensor_fuel_rates, מכיל את קצב צריכת הדלק שנמדד על ידי כל חיישן כל 15 שניות.
כדי ליצור את הטבלאות האלה, מריצים את השאילתות הבאות:
CREATE OR REPLACE TABLE mydataset.sensor_temperatures AS
SELECT * FROM UNNEST(
ARRAY<STRUCT<sensor_id INT64, ts TIMESTAMP, temp FLOAT64>>[
(1, TIMESTAMP '2020-01-01 12:00:00.063', 37.1),
(1, TIMESTAMP '2020-01-01 12:00:15.024', 37.2),
(1, TIMESTAMP '2020-01-01 12:00:30.032', 37.3),
(2, TIMESTAMP '2020-01-01 12:00:01.001', 38.1),
(2, TIMESTAMP '2020-01-01 12:00:15.082', 38.2),
(2, TIMESTAMP '2020-01-01 12:00:31.009', 38.3)
]);
CREATE OR REPLACE TABLE mydataset.sensor_fuel_rates AS
SELECT * FROM UNNEST(
ARRAY<STRUCT<sensor_id INT64, ts TIMESTAMP, rate FLOAT64>>[
(1, TIMESTAMP '2020-01-01 12:00:11.016', 10.1),
(1, TIMESTAMP '2020-01-01 12:00:26.015', 10.2),
(1, TIMESTAMP '2020-01-01 12:00:41.014', 10.3),
(2, TIMESTAMP '2020-01-01 12:00:08.099', 11.1),
(2, TIMESTAMP '2020-01-01 12:00:23.087', 11.2),
(2, TIMESTAMP '2020-01-01 12:00:38.077', 11.3)
]);
אלה הנתונים בפועל מהטבלאות:
SELECT * FROM mydataset.sensor_temperatures ORDER BY sensor_id, ts;
/*-----------+---------------------+------+
| sensor_id | ts | temp |
+-----------+---------------------+------+
| 1 | 2020-01-01 12:00:00 | 37.1 |
| 1 | 2020-01-01 12:00:15 | 37.2 |
| 1 | 2020-01-01 12:00:30 | 37.3 |
| 2 | 2020-01-01 12:00:01 | 38.1 |
| 2 | 2020-01-01 12:00:15 | 38.2 |
| 2 | 2020-01-01 12:00:31 | 38.3 |
+-----------+---------------------+------*/
SELECT * FROM mydataset.sensor_fuel_rates ORDER BY sensor_id, ts;
/*-----------+---------------------+------+
| sensor_id | ts | rate |
+-----------+---------------------+------+
| 1 | 2020-01-01 12:00:11 | 10.1 |
| 1 | 2020-01-01 12:00:26 | 10.2 |
| 1 | 2020-01-01 12:00:41 | 10.3 |
| 2 | 2020-01-01 12:00:08 | 11.1 |
| 2 | 2020-01-01 12:00:23 | 11.2 |
| 2 | 2020-01-01 12:00:38 | 11.3 |
+-----------+---------------------+------*/
כדי לבדוק את קצב צריכת הדלק בטמפרטורה שמדווחת על ידי כל חיישן, אפשר לאחד את שתי סדרות הזמן.
למרות שהנתונים בשתי סדרות הזמן לא מיושרים, הם נדגמים באותו מרווח זמן (15 שניות), ולכן הנתונים האלה מתאימים לצירוף עם חלון. כדי להתאים את חותמות הזמן שמשמשות כמפתחות לאיחוד, משתמשים בפונקציות של חלוקה לטווחים לפי זמן.
השאילתות הבאות ממחישות איך אפשר להקצות כל חותמת זמן לחלונות של 15 שניות באמצעות הפונקציה TIMESTAMP_BUCKET:
SELECT *, TIMESTAMP_BUCKET(ts, INTERVAL 15 SECOND) ts_window
FROM mydataset.sensor_temperatures
ORDER BY sensor_id, ts;
/*-----------+---------------------+------+---------------------+
| sensor_id | ts | temp | ts_window |
+-----------+---------------------+------+---------------------+
| 1 | 2020-01-01 12:00:00 | 37.1 | 2020-01-01 12:00:00 |
| 1 | 2020-01-01 12:00:15 | 37.2 | 2020-01-01 12:00:15 |
| 1 | 2020-01-01 12:00:30 | 37.3 | 2020-01-01 12:00:30 |
| 2 | 2020-01-01 12:00:01 | 38.1 | 2020-01-01 12:00:00 |
| 2 | 2020-01-01 12:00:15 | 38.2 | 2020-01-01 12:00:15 |
| 2 | 2020-01-01 12:00:31 | 38.3 | 2020-01-01 12:00:30 |
+-----------+---------------------+------+---------------------*/
SELECT *, TIMESTAMP_BUCKET(ts, INTERVAL 15 SECOND) ts_window
FROM mydataset.sensor_fuel_rates
ORDER BY sensor_id, ts;
/*-----------+---------------------+------+---------------------+
| sensor_id | ts | rate | ts_window |
+-----------+---------------------+------+---------------------+
| 1 | 2020-01-01 12:00:11 | 10.1 | 2020-01-01 12:00:00 |
| 1 | 2020-01-01 12:00:26 | 10.2 | 2020-01-01 12:00:15 |
| 1 | 2020-01-01 12:00:41 | 10.3 | 2020-01-01 12:00:30 |
| 2 | 2020-01-01 12:00:08 | 11.1 | 2020-01-01 12:00:00 |
| 2 | 2020-01-01 12:00:23 | 11.2 | 2020-01-01 12:00:15 |
| 2 | 2020-01-01 12:00:38 | 11.3 | 2020-01-01 12:00:30 |
+-----------+---------------------+------+---------------------*/
אפשר להשתמש במושג הזה כדי לשלב את נתוני קצב צריכת הדלק עם הטמפרטורה שדווחה על ידי כל חיישן:
SELECT
t1.sensor_id AS sensor_id,
t1.ts AS temp_ts,
t1.temp AS temp,
t2.ts AS rate_ts,
t2.rate AS rate
FROM mydataset.sensor_temperatures t1
LEFT JOIN mydataset.sensor_fuel_rates t2
ON TIMESTAMP_BUCKET(t1.ts, INTERVAL 15 SECOND) =
TIMESTAMP_BUCKET(t2.ts, INTERVAL 15 SECOND)
AND t1.sensor_id = t2.sensor_id
ORDER BY sensor_id, temp_ts;
/*-----------+---------------------+------+---------------------+------+
| sensor_id | temp_ts | temp | rate_ts | rate |
+-----------+---------------------+------+---------------------+------+
| 1 | 2020-01-01 12:00:00 | 37.1 | 2020-01-01 12:00:11 | 10.1 |
| 1 | 2020-01-01 12:00:15 | 37.2 | 2020-01-01 12:00:26 | 10.2 |
| 1 | 2020-01-01 12:00:30 | 37.3 | 2020-01-01 12:00:41 | 10.3 |
| 2 | 2020-01-01 12:00:01 | 38.1 | 2020-01-01 12:00:08 | 11.1 |
| 2 | 2020-01-01 12:00:15 | 38.2 | 2020-01-01 12:00:23 | 11.2 |
| 2 | 2020-01-01 12:00:31 | 38.3 | 2020-01-01 12:00:38 | 11.3 |
+-----------+---------------------+------+---------------------+------*/
AS OF הצטרפות
בקטע הזה נשתמש בטבלה mydataset.sensor_temperatures וניצור טבלה חדשה, mydataset.sensor_location.
הטבלה mydataset.sensor_temperatures מכילה נתוני טמפרטורה מחיישנים שונים, שמדווחים כל 15 שניות:
SELECT * FROM mydataset.sensor_temperatures ORDER BY sensor_id, ts;
/*-----------+---------------------+------+
| sensor_id | ts | temp |
+-----------+---------------------+------+
| 1 | 2020-01-01 12:00:00 | 37.1 |
| 1 | 2020-01-01 12:00:15 | 37.2 |
| 1 | 2020-01-01 12:00:30 | 37.3 |
| 2 | 2020-01-01 12:00:45 | 38.1 |
| 2 | 2020-01-01 12:01:01 | 38.2 |
| 2 | 2020-01-01 12:01:15 | 38.3 |
+-----------+---------------------+------*/
כדי ליצור את mydataset.sensor_location, מריצים את השאילתה הבאה:
CREATE OR REPLACE TABLE mydataset.sensor_locations AS
SELECT * FROM UNNEST(
ARRAY<STRUCT<sensor_id INT64, ts TIMESTAMP, location GEOGRAPHY>>[
(1, TIMESTAMP '2020-01-01 11:59:47.063', ST_GEOGPOINT(-122.022, 37.406)),
(1, TIMESTAMP '2020-01-01 12:00:08.185', ST_GEOGPOINT(-122.021, 37.407)),
(1, TIMESTAMP '2020-01-01 12:00:28.032', ST_GEOGPOINT(-122.020, 37.405)),
(2, TIMESTAMP '2020-01-01 07:28:41.239', ST_GEOGPOINT(-122.390, 37.790))
]);
/*-----------+---------------------+------------------------+
| sensor_id | ts | location |
+-----------+---------------------+------------------------+
| 1 | 2020-01-01 11:59:47 | POINT(-122.022 37.406) |
| 1 | 2020-01-01 12:00:08 | POINT(-122.021 37.407) |
| 1 | 2020-01-01 12:00:28 | POINT(-122.02 37.405) |
| 2 | 2020-01-01 07:28:41 | POINT(-122.39 37.79) |
+-----------+---------------------+------------------------*/
עכשיו מאחדים את הנתונים מ-mydataset.sensor_temperatures עם הנתונים מ-mydataset.sensor_location.
בתרחיש הזה, אי אפשר להשתמש ב-windowed join, כי נתוני הטמפרטורה ונתוני המיקום לא מדווחים באותו מרווח זמן.
אחת הדרכים לעשות את זה ב-BigQuery היא להמיר את נתוני חותמת הזמן לטווח, באמצעות סוג הנתונים RANGE. הטווח מייצג את התוקף הזמני של שורה, ומספק את שעת ההתחלה ושעת הסיום שבהן השורה תקפה.
משתמשים בפונקציית החלון LEAD כדי למצוא את נקודת הנתונים הבאה בסדרת הזמן, ביחס לנקודת הנתונים הנוכחית, שהיא גם הגבול הסופי של התוקף הזמני של השורה הנוכחית. השאילתות הבאות מדגימות את זה, וממירות נתוני מיקום לטווחים של תוקף:
WITH locations_ranges AS (
SELECT
sensor_id,
RANGE(ts, LEAD(ts) OVER (PARTITION BY sensor_id ORDER BY ts ASC)) AS ts_range,
location
FROM mydataset.sensor_locations
)
SELECT * FROM locations_ranges ORDER BY sensor_id, ts_range;
/*-----------+--------------------------------------------+------------------------+
| sensor_id | ts_range | location |
+-----------+--------------------------------------------+------------------------+
| 1 | [2020-01-01 11:59:47, 2020-01-01 12:00:08) | POINT(-122.022 37.406) |
| 1 | [2020-01-01 12:00:08, 2020-01-01 12:00:28) | POINT(-122.021 37.407) |
| 1 | [2020-01-01 12:00:28, UNBOUNDED) | POINT(-122.02 37.405) |
| 2 | [2020-01-01 07:28:41, UNBOUNDED) | POINT(-122.39 37.79) |
+-----------+--------------------------------------------+------------------------*/
עכשיו אפשר לצרף את נתוני הטמפרטורות (מימין) לנתוני המיקום (משמאל):
WITH locations_ranges AS (
SELECT
sensor_id,
RANGE(ts, LEAD(ts) OVER (PARTITION BY sensor_id ORDER BY ts ASC)) AS ts_range,
location
FROM mydataset.sensor_locations
)
SELECT
t1.sensor_id AS sensor_id,
t1.ts AS temp_ts,
t1.temp AS temp,
t2.location AS location
FROM mydataset.sensor_temperatures t1
LEFT JOIN locations_ranges t2
ON RANGE_CONTAINS(t2.ts_range, t1.ts)
AND t1.sensor_id = t2.sensor_id
ORDER BY sensor_id, temp_ts;
/*-----------+---------------------+------+------------------------+
| sensor_id | temp_ts | temp | location |
+-----------+---------------------+------+------------------------+
| 1 | 2020-01-01 12:00:00 | 37.1 | POINT(-122.022 37.406) |
| 1 | 2020-01-01 12:00:15 | 37.2 | POINT(-122.021 37.407) |
| 1 | 2020-01-01 12:00:30 | 37.3 | POINT(-122.02 37.405) |
| 2 | 2020-01-01 12:00:01 | 38.1 | POINT(-122.39 37.79) |
| 2 | 2020-01-01 12:00:15 | 38.2 | POINT(-122.39 37.79) |
| 2 | 2020-01-01 12:00:31 | 38.3 | POINT(-122.39 37.79) |
+-----------+---------------------+------+------------------------*/
שילוב ופיצול של נתונים בטווח
בקטע הזה, אפשר לשלב נתונים של טווחים עם חפיפה ולפצל נתונים של טווחים לטווחים קטנים יותר.
שילוב נתונים של טווח
בטבלאות עם ערכי טווח יכול להיות שיהיו טווחים חופפים. בשאילתה הבאה, טווחי הזמן מתעדים את מצב החיישנים במרווחי זמן של כ-5 דקות:
CREATE OR REPLACE TABLE mydataset.sensor_metrics AS
SELECT * FROM UNNEST(
ARRAY<STRUCT<sensor_id INT64, duration RANGE<DATETIME>, flow INT64, spins INT64>>[
(1, RANGE<DATETIME> "[2020-01-01 12:00:01, 2020-01-01 12:05:23)", 10, 1),
(1, RANGE<DATETIME> "[2020-01-01 12:05:12, 2020-01-01 12:10:46)", 10, 20),
(1, RANGE<DATETIME> "[2020-01-01 12:10:27, 2020-01-01 12:15:56)", 11, 4),
(1, RANGE<DATETIME> "[2020-01-01 12:16:00, 2020-01-01 12:20:58)", 11, 9),
(1, RANGE<DATETIME> "[2020-01-01 12:20:33, 2020-01-01 12:25:08)", 11, 8),
(2, RANGE<DATETIME> "[2020-01-01 12:00:19, 2020-01-01 12:05:08)", 21, 31),
(2, RANGE<DATETIME> "[2020-01-01 12:05:08, 2020-01-01 12:10:30)", 21, 2),
(2, RANGE<DATETIME> "[2020-01-01 12:10:22, 2020-01-01 12:15:42)", 21, 10)
]);
השאילתה הבאה בטבלה מציגה כמה טווחים חופפים:
SELECT * FROM mydataset.sensor_metrics;
/*-----------+--------------------------------------------+------+-------+
| sensor_id | duration | flow | spins |
+-----------+--------------------------------------------+------+-------+
| 1 | [2020-01-01 12:00:01, 2020-01-01 12:05:23) | 10 | 1 |
| 1 | [2020-01-01 12:05:12, 2020-01-01 12:10:46) | 10 | 20 |
| 1 | [2020-01-01 12:10:27, 2020-01-01 12:15:56) | 11 | 4 |
| 1 | [2020-01-01 12:16:00, 2020-01-01 12:20:58) | 11 | 9 |
| 1 | [2020-01-01 12:20:33, 2020-01-01 12:25:08) | 11 | 8 |
| 2 | [2020-01-01 12:00:19, 2020-01-01 12:05:08) | 21 | 31 |
| 2 | [2020-01-01 12:05:08, 2020-01-01 12:10:30) | 21 | 2 |
| 2 | [2020-01-01 12:10:22, 2020-01-01 12:15:42) | 21 | 10 |
+-----------+--------------------------------------------+------+-------*/
בחלק מהטווחים החופפים, הערך בעמודה flow זהה.
לדוגמה, שורות 1 ו-2 חופפות, ויש להן גם את אותם קריאות flow. אפשר לשלב בין שתי השורות האלה כדי לצמצם את מספר השורות בטבלה. אפשר להשתמש בפונקציית הטבלה RANGE_SESSIONIZE כדי למצוא טווחים שחופפים לכל שורה, ולספק עמודה נוספת session_range שמכילה טווח שהוא איחוד של כל הטווחים החופפים. כדי להציג את טווחי הסשנים בכל שורה, מריצים את השאילתה הבאה:
SELECT sensor_id, session_range, flow
FROM RANGE_SESSIONIZE(
# Input data.
(SELECT sensor_id, duration, flow FROM mydataset.sensor_metrics),
# Range column.
"duration",
# Partitioning columns. Ranges are sessionized only within these partitions.
["sensor_id", "flow"],
# Sessionize mode.
"OVERLAPS")
ORDER BY sensor_id, session_range;
/*-----------+--------------------------------------------+------+
| sensor_id | session_range | flow |
+-----------+--------------------------------------------+------+
| 1 | [2020-01-01 12:00:01, 2020-01-01 12:10:46) | 10 |
| 1 | [2020-01-01 12:00:01, 2020-01-01 12:10:46) | 10 |
| 1 | [2020-01-01 12:10:27, 2020-01-01 12:15:56) | 11 |
| 1 | [2020-01-01 12:16:00, 2020-01-01 12:25:08) | 11 |
| 1 | [2020-01-01 12:16:00, 2020-01-01 12:25:08) | 11 |
| 2 | [2020-01-01 12:00:19, 2020-01-01 12:05:08) | 21 |
| 2 | [2020-01-01 12:05:08, 2020-01-01 12:15:42) | 21 |
| 2 | [2020-01-01 12:05:08, 2020-01-01 12:15:42) | 21 |
+-----------+--------------------------------------------+------*/
שימו לב: אם sensor_id הוא בעל הערך 2, גבול הסיום של השורה הראשונה זהה לערך התאריך והשעה של גבול ההתחלה של השורה השנייה. עם זאת, מכיוון שהגבולות של סוף הטווח לא נכללים, הם לא חופפים (רק נפגשים) ולכן הם לא היו באותם טווחי סשנים. אם רוצים למקם את שתי השורות האלה באותם טווחי סשנים, צריך להשתמש במצב MEETS sessionize.
כדי לשלב את הטווחים, מקבצים את התוצאות לפי session_range ועמודות החלוקה (sensor_id ו-flow):
SELECT sensor_id, session_range, flow
FROM RANGE_SESSIONIZE(
(SELECT sensor_id, duration, flow FROM mydataset.sensor_metrics),
"duration",
["sensor_id", "flow"],
"OVERLAPS")
GROUP BY sensor_id, session_range, flow
ORDER BY sensor_id, session_range;
/*-----------+--------------------------------------------+------+
| sensor_id | session_range | flow |
+-----------+--------------------------------------------+------+
| 1 | [2020-01-01 12:00:01, 2020-01-01 12:10:46) | 10 |
| 1 | [2020-01-01 12:10:27, 2020-01-01 12:15:56) | 11 |
| 1 | [2020-01-01 12:16:00, 2020-01-01 12:25:08) | 11 |
| 2 | [2020-01-01 12:00:19, 2020-01-01 12:05:08) | 21 |
| 2 | [2020-01-01 12:05:08, 2020-01-01 12:15:42) | 21 |
+-----------+--------------------------------------------+------*/
לבסוף, מוסיפים את העמודה spins לנתוני הסשן על ידי צבירה שלה באמצעות SUM.
SELECT sensor_id, session_range, flow, SUM(spins) as spins
FROM RANGE_SESSIONIZE(
TABLE mydataset.sensor_metrics,
"duration",
["sensor_id", "flow"],
"OVERLAPS")
GROUP BY sensor_id, session_range, flow
ORDER BY sensor_id, session_range;
/*-----------+--------------------------------------------+------+-------+
| sensor_id | session_range | flow | spins |
+-----------+--------------------------------------------+------+-------+
| 1 | [2020-01-01 12:00:01, 2020-01-01 12:10:46) | 10 | 21 |
| 1 | [2020-01-01 12:10:27, 2020-01-01 12:15:56) | 11 | 4 |
| 1 | [2020-01-01 12:16:00, 2020-01-01 12:25:08) | 11 | 17 |
| 2 | [2020-01-01 12:00:19, 2020-01-01 12:05:08) | 21 | 31 |
| 2 | [2020-01-01 12:05:08, 2020-01-01 12:15:42) | 21 | 12 |
+-----------+--------------------------------------------+------+-------*/
פיצול נתונים בטווח
אפשר גם לפצל טווח לטווחים קטנים יותר. בדוגמה הזו, משתמשים בטבלה הבאה עם נתוני טווח:
/*-----------+--------------------------+------+-------+
| sensor_id | duration | flow | spins |
+-----------+--------------------------+------+-------+
| 1 | [2020-01-01, 2020-12-31) | 10 | 21 |
| 1 | [2021-01-01, 2021-12-31) | 11 | 4 |
| 2 | [2020-04-15, 2021-04-15) | 21 | 31 |
| 2 | [2021-04-15, 2021-04-15) | 21 | 12 |
+-----------+--------------------------+------+-------*/
עכשיו מחלקים את הטווחים המקוריים למרווחים של 3 חודשים:
WITH sensor_data AS (
SELECT * FROM UNNEST(
ARRAY<STRUCT<sensor_id INT64, duration RANGE<DATE>, flow INT64, spins INT64>>[
(1, RANGE<DATE> "[2020-01-01, 2020-12-31)", 10, 21),
(1, RANGE<DATE> "[2021-01-01, 2021-12-31)", 11, 4),
(2, RANGE<DATE> "[2020-04-15, 2021-04-15)", 21, 31),
(2, RANGE<DATE> "[2021-04-15, 2022-04-15)", 21, 12)
])
)
SELECT sensor_id, expanded_range, flow, spins
FROM sensor_data, UNNEST(GENERATE_RANGE_ARRAY(duration, INTERVAL 3 MONTH)) AS expanded_range;
/*-----------+--------------------------+------+-------+
| sensor_id | expanded_range | flow | spins |
+-----------+--------------------------+------+-------+
| 1 | [2020-01-01, 2020-04-01) | 10 | 21 |
| 1 | [2020-04-01, 2020-07-01) | 10 | 21 |
| 1 | [2020-07-01, 2020-10-01) | 10 | 21 |
| 1 | [2020-10-01, 2020-12-31) | 10 | 21 |
| 1 | [2021-01-01, 2021-04-01) | 11 | 4 |
| 1 | [2021-04-01, 2021-07-01) | 11 | 4 |
| 1 | [2021-07-01, 2021-10-01) | 11 | 4 |
| 1 | [2021-10-01, 2021-12-31) | 11 | 4 |
| 2 | [2020-04-15, 2020-07-15) | 21 | 31 |
| 2 | [2020-07-15, 2020-10-15) | 21 | 31 |
| 2 | [2020-10-15, 2021-01-15) | 21 | 31 |
| 2 | [2021-01-15, 2021-04-15) | 21 | 31 |
| 2 | [2021-04-15, 2021-07-15) | 21 | 12 |
| 2 | [2021-07-15, 2021-10-15) | 21 | 12 |
| 2 | [2021-10-15, 2022-01-15) | 21 | 12 |
| 2 | [2022-01-15, 2022-04-15) | 21 | 12 |
+-----------+--------------------------+------+-------*/
בשאילתה הקודמת, כל טווח מקורי פוצל לטווחים קטנים יותר, והרוחב הוגדר ל-INTERVAL 3 MONTH. עם זאת, טווחי 3 החודשים לא מתחילים באותו תאריך. כדי ליישר את הטווחים האלה למקור משותף
2020-01-01, מריצים את השאילתה הבאה:
WITH sensor_data AS (
SELECT * FROM UNNEST(
ARRAY<STRUCT<sensor_id INT64, duration RANGE<DATE>, flow INT64, spins INT64>>[
(1, RANGE<DATE> "[2020-01-01, 2020-12-31)", 10, 21),
(1, RANGE<DATE> "[2021-01-01, 2021-12-31)", 11, 4),
(2, RANGE<DATE> "[2020-04-15, 2021-04-15)", 21, 31),
(2, RANGE<DATE> "[2021-04-15, 2022-04-15)", 21, 12)
])
)
SELECT sensor_id, expanded_range, flow, spins
FROM sensor_data
JOIN UNNEST(GENERATE_RANGE_ARRAY(RANGE<DATE> "[2020-01-01, 2022-12-31)", INTERVAL 3 MONTH)) AS expanded_range
ON RANGE_OVERLAPS(duration, expanded_range);
/*-----------+--------------------------+------+-------+
| sensor_id | expanded_range | flow | spins |
+-----------+--------------------------+------+-------+
| 1 | [2020-01-01, 2020-04-01) | 10 | 21 |
| 1 | [2020-04-01, 2020-07-01) | 10 | 21 |
| 1 | [2020-07-01, 2020-10-01) | 10 | 21 |
| 1 | [2020-10-01, 2021-01-01) | 10 | 21 |
| 1 | [2021-01-01, 2021-04-01) | 11 | 4 |
| 1 | [2021-04-01, 2021-07-01) | 11 | 4 |
| 1 | [2021-07-01, 2021-10-01) | 11 | 4 |
| 1 | [2021-10-01, 2022-01-01) | 11 | 4 |
| 2 | [2020-04-01, 2020-07-01) | 21 | 31 |
| 2 | [2020-07-01, 2020-10-01) | 21 | 31 |
| 2 | [2020-10-01, 2021-01-01) | 21 | 31 |
| 2 | [2021-01-01, 2021-04-01) | 21 | 31 |
| 2 | [2021-04-01, 2021-07-01) | 21 | 31 |
| 2 | [2021-04-01, 2021-07-01) | 21 | 12 |
| 2 | [2021-07-01, 2021-10-01) | 21 | 12 |
| 2 | [2021-10-01, 2022-01-01) | 21 | 12 |
| 2 | [2022-01-01, 2022-04-01) | 21 | 12 |
| 2 | [2022-04-01, 2022-07-01) | 21 | 12 |
+-----------+--------------------------+------+-------*/
בשאילתה הקודמת, השורה עם הטווח [2020-04-15, 2021-04-15) פוצלה ל-5 טווחים, החל מהטווח [2020-04-01, 2020-07-01). הערה:
גבול ההתחלה מתרחב עכשיו מעבר לגבול ההתחלה המקורי, כדי להתאים למקור המשותף. אם אתם לא רוצים שגבול ההתחלה יתרחב מעבר לגבול ההתחלה המקורי, אתם יכולים להגביל את התנאי JOIN:
WITH sensor_data AS (
SELECT * FROM UNNEST(
ARRAY<STRUCT<sensor_id INT64, duration RANGE<DATE>, flow INT64, spins INT64>>[
(1, RANGE<DATE> "[2020-01-01, 2020-12-31)", 10, 21),
(1, RANGE<DATE> "[2021-01-01, 2021-12-31)", 11, 4),
(2, RANGE<DATE> "[2020-04-15, 2021-04-15)", 21, 31),
(2, RANGE<DATE> "[2021-04-15, 2022-04-15)", 21, 12)
])
)
SELECT sensor_id, expanded_range, flow, spins
FROM sensor_data
JOIN UNNEST(GENERATE_RANGE_ARRAY(RANGE<DATE> "[2020-01-01, 2022-12-31)", INTERVAL 3 MONTH)) AS expanded_range
ON RANGE_CONTAINS(duration, RANGE_START(expanded_range));
/*-----------+--------------------------+------+-------+
| sensor_id | expanded_range | flow | spins |
+-----------+--------------------------+------+-------+
| 1 | [2020-01-01, 2020-04-01) | 10 | 21 |
| 1 | [2020-04-01, 2020-07-01) | 10 | 21 |
| 1 | [2020-07-01, 2020-10-01) | 10 | 21 |
| 1 | [2020-10-01, 2021-01-01) | 10 | 21 |
| 1 | [2021-01-01, 2021-04-01) | 11 | 4 |
| 1 | [2021-04-01, 2021-07-01) | 11 | 4 |
| 1 | [2021-07-01, 2021-10-01) | 11 | 4 |
| 1 | [2021-10-01, 2022-01-01) | 11 | 4 |
| 2 | [2020-07-01, 2020-10-01) | 21 | 31 |
| 2 | [2020-10-01, 2021-01-01) | 21 | 31 |
| 2 | [2021-01-01, 2021-04-01) | 21 | 31 |
| 2 | [2021-04-01, 2021-07-01) | 21 | 31 |
| 2 | [2021-07-01, 2021-10-01) | 21 | 12 |
| 2 | [2021-10-01, 2022-01-01) | 21 | 12 |
| 2 | [2022-01-01, 2022-04-01) | 21 | 12 |
| 2 | [2022-04-01, 2022-07-01) | 21 | 12 |
+-----------+--------------------------+------+-------*/
עכשיו אפשר לראות שהטווח [2020-04-15, 2021-04-15) פוצל ל-4 טווחים, החל מהטווח [2020-07-01, 2020-10-01).
שיטות מומלצות לאחסון נתונים
כשמאחסנים נתונים של סדרות זמן, חשוב לקחת בחשבון את דפוסי השאילתות שמופעלות על הטבלאות שבהן הנתונים מאוחסנים. בדרך כלל, כשמבצעים שאילתה על נתוני סדרות זמן, אפשר לסנן את הנתונים לפי טווח זמן ספציפי.
כדי לייעל את דפוסי השימוש האלה, מומלץ לאחסן נתונים של סדרות זמן בטבלאות עם חלוקה למחיצות, עם חלוקת נתונים למחיצות לפי עמודת הזמן או לפי זמן ההטמעה. הפעולה הזו יכולה לשפר באופן משמעותי את ביצועי השאילתות של נתוני הסדרות העיתיות, כי היא מאפשרת ל-BigQuery להסיר מחיצות שלא מכילות נתונים שנכללים בשאילתה.
אתם יכולים להפעיל אשכולות בעמודת הזמן, הטווח או אחת מעמודות החלוקה למחיצות כדי לשפר עוד יותר את הביצועים בזמן השאילתה.