
Introdução aos embeddings e à pesquisa vetorial
Este documento oferece uma visão geral dos embeddings e da pesquisa vetorial no BigQuery. A pesquisa vetorial é uma técnica para comparar objetos semelhantes usando embeddings, e é usada para impulsionar produtos do Google, incluindo a Pesquisa Google, o YouTube e o Google Play. É possível usar a pesquisa vetorial para realizar pesquisas em grande escala. Ao usar índices vetoriais com a pesquisa vetorial, você pode aproveitar tecnologias fundamentais, como a indexação de arquivos invertidos (IVF) e o algoritmo ScaNN.
A pesquisa vetorial é baseada em embeddings. Os embeddings são vetores numéricos de alta dimensão que representam uma determinada entidade, como um texto ou um arquivo de áudio. Os modelos de machine learning (ML) usam embeddings para codificar semântica sobre essas entidades, facilitando o entendimento delas e sua comparação. Por exemplo, uma operação comum em modelos de clustering, classificação e recomendação é medir a distância entre vetores em um espaço de embedding para encontrar os itens semanticamente mais parecidos.
Esse conceito de similaridade semântica e distância em um espaço de embedding é demonstrado visualmente quando você considera como diferentes itens podem ser plotados. Por exemplo, termos como gato, cachorro e leão, que representam tipos de animais, são agrupados nesse espaço devido às características semânticas compartilhadas. Da mesma forma, termos como carro, caminhão e o termo mais genérico veículo formariam outro cluster. Isso é mostrado na imagem a seguir:
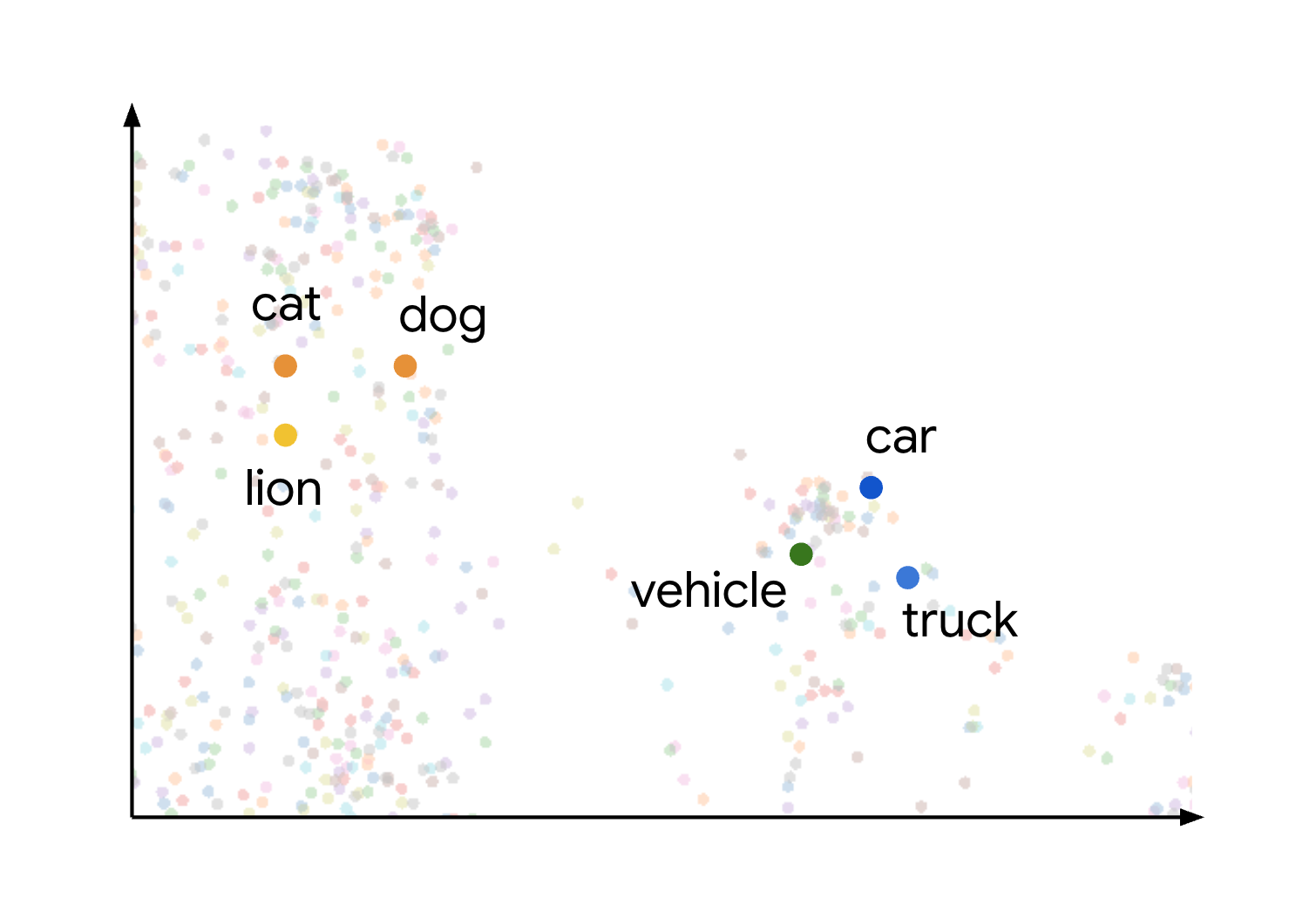
É possível notar que os clusters de animais e veículos estão posicionados bem distantes um do outro. A separação entre os grupos ilustra o princípio de que quanto mais próximos os objetos estiverem no espaço de embedding, mais semelhantes semanticamente eles serão, e distâncias maiores indicam maior dissimilaridade semântica.
Casos de uso
A combinação de geração de embeddings e pesquisa vetorial permite muitos casos de uso interessantes. Confira alguns casos de uso possíveis:
- Geração aumentada por recuperação (RAG): analise documentos, realize pesquisas vetoriais em conteúdo e gere respostas resumidas a perguntas em linguagem natural usando modelos do Gemini, tudo no BigQuery. Para conferir um notebook que ilustra esse cenário, consulte Criar um app de pesquisa vetorial usando o BigQuery DataFrames.
- Recomendação de substitutos ou produtos correspondentes:melhore os aplicativos de e-commerce sugerindo alternativas de produtos com base no comportamento do cliente e na similaridade do produto.
- Análise de registros:ajude as equipes a fazer a triagem proativa de anomalias em registros e acelerar as investigações. Também é possível usar esse recurso para enriquecer o contexto dos LLMs, a fim de melhorar a detecção de ameaças, a perícia e os fluxos de trabalho de solução de problemas. Para conferir um notebook que ilustra este cenário, consulte Detecção e investigação de anomalias de registro com embeddings de texto + pesquisa vetorial do BigQuery.
- Clustering e segmentação:segmente públicos-alvo com precisão. Por exemplo, uma rede hospitalar pode agrupar pacientes usando observações em linguagem natural e dados estruturados, ou um profissional de marketing pode segmentar anúncios com base na intenção da consulta. Para conferir um notebook que ilustra esse cenário, consulte Create-Campaign-Customer-Segmentation.
- Resolução e eliminação de duplicação de entidades:limpe e consolide dados. Por exemplo, uma empresa de publicidade pode eliminar a duplicação de registros de informações de identificação pessoal (PII, na sigla em inglês), ou uma imobiliária pode identificar endereços de correspondência correspondentes.
Gerar embeddings
As seções a seguir descrevem as funções que o BigQuery oferece para ajudar você a gerar ou trabalhar com embeddings.
Gerar embeddings únicos
É possível usar a
AI.EMBED função
com modelos de embedding da Gemini Enterprise Agent Platform para gerar um único embedding
da entrada.
A função AI.EMBED oferece suporte aos seguintes tipos de entrada:
- Dados de texto.
- Dados de imagem representados por
ObjectRefvalores.
Gerar uma tabela de embeddings
É possível usar o
AI.GENERATE_EMBEDDING
para criar uma tabela com embeddings para todos os dados em uma coluna da sua
tabela de entrada. Para todos os tipos de modelos com suporte, AI.GENERATE_EMBEDDING
funciona com dados estruturados em
tabelas padrão. Para modelos de embedding multimodais, AI.GENERATE_EMBEDDING também funciona com conteúdo visual
de colunas de tabelas padrão
que contêm valores ObjectRef,
ou de tabelas de objetos.
Para modelos remotos, toda a inferência ocorre na plataforma de agentes. Para outros tipos de modelo, toda a inferência ocorre no BigQuery. Os resultados são armazenados no BigQuery.
Use os tópicos a seguir para tentar a geração de embeddings no BigQuery ML:
- Gerar texto,
imagens, ou
vídeo usando a
AI.GENERATE_EMBEDDINGfunção. - Gerar e pesquisar embeddings multimodais
- Realizar pesquisa semântica e geração aumentada por recuperação
Geração autônoma de embeddings
É possível usar a geração autônoma de embeddings para simplificar o processo de criação, manutenção e consulta de embeddings. O BigQuery mantém uma coluna de embeddings na tabela com base em uma coluna de origem. Quando você adiciona ou modifica dados na coluna de origem, o BigQuery gera ou atualiza automaticamente a coluna de embedding para esses dados usando um modelo de embedding do Agent Platform. Isso é útil se você quiser que o BigQuery mantenha seus embeddings quando os dados de origem forem atualizados regularmente.
Pesquisar
As seguintes funções de pesquisa estão disponíveis:
VECTOR_SEARCH: realiza uma pesquisa vetorial usando SQL.AI.SEARCH(visualização): pesquisa resultados próximos a uma string fornecida. É possível usar essa função se a geração autônoma de embeddings estiver ativada na tabela.AI.SIMILARITY: compara duas entradas calculando a similaridade de cosseno entre os embeddings. Essa função funciona bem se você quiser realizar um pequeno número de comparações e não tiver pré-calculado nenhum embedding. UseVECTOR_SEARCHquando o desempenho for fundamental e você estiver trabalhando com um grande número de embeddings. Compare a funcionalidade deles para escolher a melhor função para seu caso de uso.
Opcionalmente, é possível criar um índice vetorial usando a
instrução
CREATE VECTOR INDEX.
Quando um índice vetorial é usado, as funções VECTOR_SEARCH e AI.SEARCH usam
a técnica de pesquisa do Vizinho aproximado mais perto
para melhorar o desempenho da pesquisa vetorial, mas reduzindo
o recall
e, portanto, retornando resultados mais aproximados. Sem um índice vetorial, essas
funções usam
a pesquisa de força bruta para
medir a distância de cada registro. Também é possível usar a força bruta para encontrar resultados exatos mesmo quando um índice vetorial está disponível.
Preços
As funções VECTOR_SEARCH e AI.SEARCH e a instrução CREATE VECTOR INDEX
usam
os preços de computação do BigQuery.
Funções
VECTOR_SEARCHeAI.SEARCH: você recebe cobranças pela pesquisa de similaridade, usando preços sob demanda ou de edições.- Sob demanda: você recebe cobranças pela quantidade de bytes verificados na tabela de base, no índice e na consulta de pesquisa.
Preços de edições: você recebe cobranças pelos slots necessários para concluir o job na edição da reserva. Cálculos de similaridade maiores e mais complexos geram mais cobranças.
CREATE VECTOR INDEXinstrução: não há cobrança pelo processamento necessário para criar e atualizar os índices vetoriais, desde que o tamanho total dos dados da tabela indexada esteja abaixo do limite por organização limite. Para oferecer suporte à indexação além desse limite, é preciso fornecer sua própria reserva para processar os jobs de gerenciamento de índice.
O armazenamento também é uma consideração para embeddings e índices. A quantidade de bytes armazenados como embeddings e índices está sujeita a custos de armazenamento ativo.
- Os índices vetoriais geram custos de armazenamento quando estão ativos.
- É possível encontrar o tamanho de armazenamento do índice usando a
INFORMATION_SCHEMA.VECTOR_INDEXESvisualização. Se o índice vetorial ainda não tiver 100% de cobertura, você ainda receberá cobranças pelo que foi indexado. É possível verificar a cobertura do índice usando a visualizaçãoINFORMATION_SCHEMA.VECTOR_INDEXES.
Cotas e limites
Para mais informações, consulte Limites de índice vetorial e Limites de função de IA generativa.
Limitações
As consultas que contêm a VECTOR_SEARCH ou AI.SEARCH função não são
aceleradas pelo
BigQuery BI Engine.
A seguir
- Saiba mais sobre como criar um índice vetorial.
- Saiba como realizar uma pesquisa vetorial usando a
VECTOR_SEARCHfunção. - Saiba como realizar uma pesquisa semântica usando a
AI.SEARCHfunção. - Saiba mais sobre a geração autônoma de embeddings.
- Siga o tutorial Pesquisar embeddings com pesquisa de vetor para aprender a criar um índice de vetor e, em seguida, faça uma pesquisa de vetor para embeddings com e sem o índice.
Faça o tutorial Realizar pesquisa semântica e geração aumentada por recuperação para aprender a realizar as seguintes tarefas:
- Gere embeddings de texto.
- Crie um índice de vetor nos embeddings.
- Realize uma pesquisa vetorial com os embeddings para procurar textos semelhantes.
- Realize a geração aumentada por recuperação (RAG) usando resultados da pesquisa de vetor para aumentar a entrada do comando e melhorar os resultados.
Faça o tutorial Analisar PDFs em um pipeline de geração aumentada por recuperação para aprender a criar um pipeline de RAG com base no conteúdo de PDF analisado.
Também é possível realizar pesquisas vetoriais usando o BigQuery DataFrames em Python. Para conferir um bloco que ilustra essa abordagem, consulte Criar um app de pesquisa vetorial usando o BigQuery DataFrames.