
Pengantar embedding dan penelusuran vektor
Dokumen ini memberikan ringkasan tentang embedding dan penelusuran vektor di BigQuery. Penelusuran vektor adalah teknik untuk membandingkan objek serupa menggunakan embedding, dan digunakan untuk mendukung produk Google, termasuk Google Penelusuran, YouTube, dan Google Play. Anda dapat menggunakan penelusuran vektor untuk melakukan penelusuran dalam skala besar. Saat menggunakan indeks vektor dengan penelusuran vektor, Anda dapat memanfaatkan teknologi dasar seperti pengindeksan file terbalik (IVF) dan algoritma ScaNN.
Penelusuran vektor dibangun berdasarkan embedding. Embedding adalah vektor numerik berdimensi tinggi yang merepresentasikan entity tertentu, seperti teks atau file audio. Model machine learning (ML) menggunakan embedding untuk mengenkode semantik tentang entity tersebut agar lebih mudah untuk dipertimbangkan dan dibandingkan. Misalnya, operasi umum dalam model pengelompokan, klasifikasi, dan rekomendasi adalah mengukur jarak antarvektor dalam ruang embedding untuk menemukan item yang paling mirip secara semantik.
Konsep kesamaan dan jarak semantik dalam ruang embedding ini ditunjukkan secara visual saat Anda mempertimbangkan bagaimana item yang berbeda dapat diplot. Misalnya, istilah seperti cat, dog, dan lion, yang semuanya mewakili jenis hewan, dikelompokkan berdekatan dalam ruang ini karena karakteristik semantik yang sama. Demikian pula, istilah seperti car, truck, dan istilah yang lebih umum vehicle akan membentuk cluster lain. Hal ini ditunjukkan pada gambar berikut:
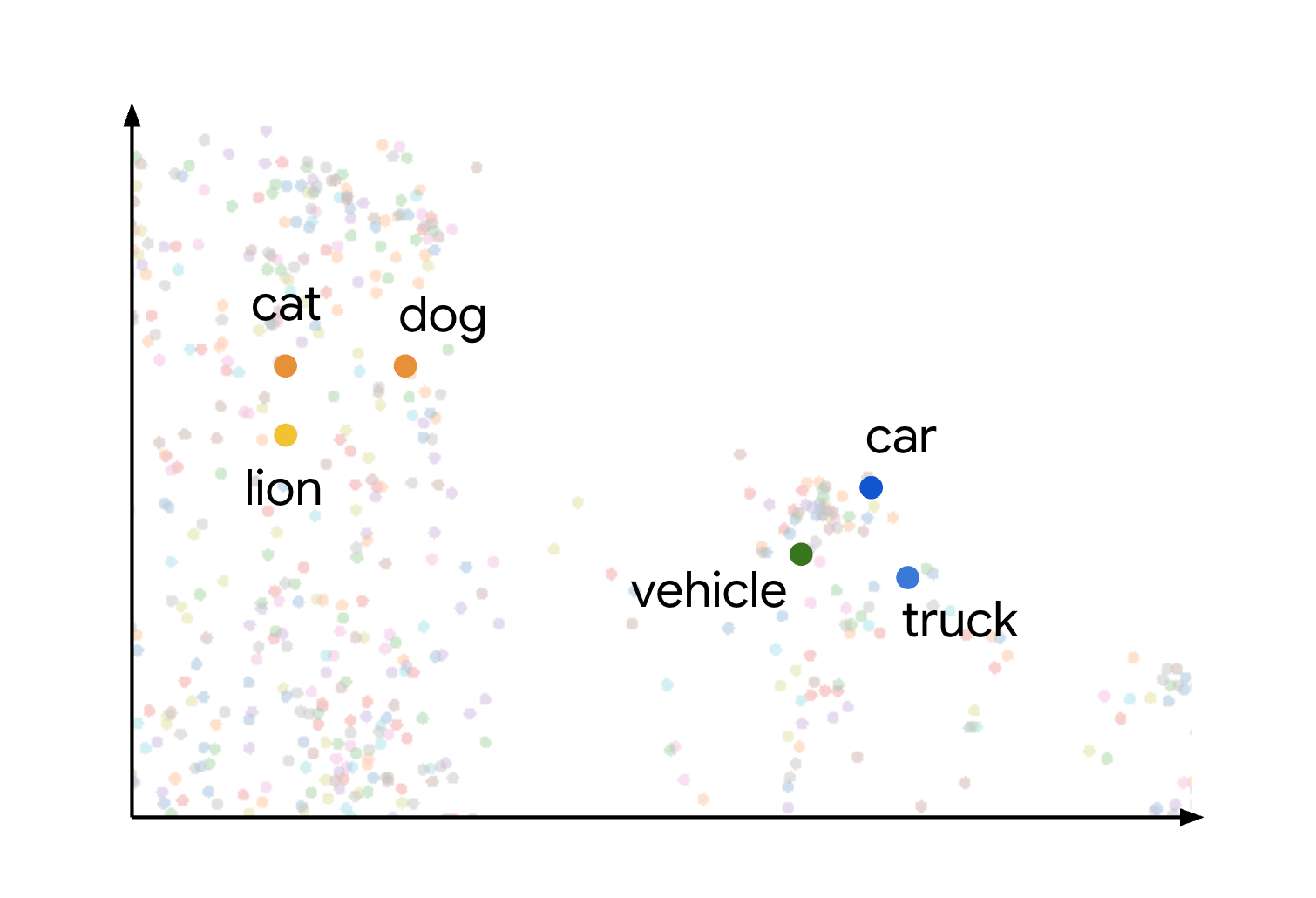
Anda dapat melihat bahwa cluster hewan dan kendaraan ditempatkan berjauhan satu sama lain. Pemisahan antara grup mengilustrasikan prinsip bahwa semakin dekat objek dalam ruang embedding, semakin mirip semantik objek tersebut, dan jarak yang lebih jauh menunjukkan perbedaan semantik yang lebih besar.
Kasus penggunaan
Kombinasi pembuatan embedding dan penelusuran vektor memungkinkan banyak kasus penggunaan yang menarik. Beberapa kemungkinan kasus penggunaan adalah sebagai berikut:
- Retrieval-augmented generation (RAG): Mengurai dokumen, melakukan penelusuran vektor pada konten, dan membuat jawaban ringkas untuk pertanyaan bahasa alami menggunakan model Gemini, semuanya dalam BigQuery. Untuk notebook yang mengilustrasikan skenario ini, lihat Membangun aplikasi Penelusuran Vektor menggunakan BigQuery DataFrames.
- Merekomendasikan pengganti produk atau produk yang cocok: Meningkatkan aplikasi e-commerce dengan menyarankan alternatif produk berdasarkan perilaku pelanggan dan kemiripan produk.
- Analisis log: Membantu tim secara proaktif menyortir anomali dalam log dan mempercepat investigasi. Anda juga dapat menggunakan kapabilitas ini untuk memperkaya konteks LLM, guna meningkatkan deteksi ancaman, forensik digital, dan alur kerja pemecahan masalah. Untuk notebook yang mengilustrasikan skenario ini, lihat Deteksi & Investigasi Anomali Log dengan Embedding Teks + Penelusuran Vektor BigQuery.
- Pengelompokan dan penargetan: Membuat segmen audiens dengan presisi. Misalnya, jaringan rumah sakit dapat mengelompokkan pasien menggunakan catatan bahasa alami dan data terstruktur, atau pemasar dapat menargetkan iklan berdasarkan niat kueri. Untuk notebook yang mengilustrasikan skenario ini, lihat Create-Campaign-Customer-Segmentation.
- Resolusi dan penghapusan duplikat entitas: Membersihkan dan mengonsolidasikan data. Misalnya, perusahaan periklanan dapat menghapus duplikat data informasi identitas pribadi (PII), atau perusahaan real estate dapat mengidentifikasi alamat surat yang cocok.
Membuat embedding
Bagian berikut menjelaskan fungsi yang ditawarkan BigQuery untuk membantu Anda membuat atau menggunakan embedding.
Membuat embedding tunggal
Anda dapat menggunakan fungsi
AI.EMBEDdengan model embedding Gemini Enterprise Agent Platform untuk membuat satu embedding
input Anda.
Fungsi AI.EMBED mendukung jenis input berikut:
- Data teks.
- Data gambar yang direpresentasikan oleh
ObjectRefnilai.
Membuat tabel embedding
Anda dapat menggunakan
AI.GENERATE_EMBEDDING
untuk membuat tabel yang memiliki embedding untuk semua data dalam kolom tabel
input Anda. Untuk semua jenis model yang didukung, AI.GENERATE_EMBEDDING
berfungsi dengan data terstruktur dalam
tabel standar. Untuk model embedding
embedding multimodal, AI.GENERATE_EMBEDDING juga berfungsi dengan konten visual
dari kolom tabel standar
yang berisi nilai ObjectRef,
atau dari tabel objek.
Untuk model jarak jauh, semua inferensi terjadi di Agent Platform. Untuk jenis model lainnya, semua inferensi terjadi di BigQuery. Hasilnya disimpan di BigQuery.
Gunakan topik berikut untuk mencoba pembuatan embedding di BigQuery ML:
- Membuat teks,
gambar, atau
video menggunakan
AI.GENERATE_EMBEDDINGfungsi. - Membuat dan menelusuri embedding multimodal
- Melakukan penelusuran semantik dan retrieval-augmented generation
Pembuatan embedding otonom
Anda dapat menggunakan pembuatan embedding otonom untuk menyederhanakan proses pembuatan, pemeliharaan, dan kueri embedding. BigQuery mempertahankan kolom embedding di tabel Anda berdasarkan kolom sumber. Saat Anda menambahkan atau mengubah data di kolom sumber, BigQuery akan otomatis membuat atau memperbarui kolom embedding untuk data tersebut menggunakan model embedding Agent Platform. Hal ini berguna jika Anda ingin BigQuery mempertahankan embedding saat data sumber Anda diperbarui secara rutin.
Penelusuran
Fungsi penelusuran berikut tersedia:
VECTOR_SEARCH: Melakukan penelusuran vektor menggunakan SQL.AI.SEARCH(Pratinjau): Menelusuri hasil yang dekat dengan string yang Anda berikan. Anda dapat menggunakan fungsi ini jika tabel Anda mengaktifkan pembuatan embedding otonom.AI.SIMILARITY: Membandingkan dua input dengan menghitung kesamaan kosinus antara embedding-nya. Fungsi ini berfungsi dengan baik jika Anda ingin melakukan sejumlah kecil perbandingan dan Anda belum melakukan pra-komputasi embedding apa pun. Anda harus menggunakanVECTOR_SEARCHjika performa sangat penting dan Anda menggunakan sejumlah besar embedding. Bandingkan fungsinya untuk memilih fungsi terbaik untuk kasus penggunaan Anda.
Secara opsional, Anda dapat membuat indeks vektor dengan
menggunakan pernyataan
CREATE VECTOR INDEX.
Saat indeks vektor digunakan, fungsi VECTOR_SEARCH dan AI.SEARCH menggunakan teknik penelusuran Tetangga Terdekat Perkiraan untuk meningkatkan performa penelusuran vektor, dengan mengurangi recall dan menampilkan hasil yang lebih perkiraan. Tanpa indeks vektor, fungsi ini menggunakan penelusuran brute force untuk mengukur jarak setiap rekaman. Anda juga dapat memilih untuk menggunakan brute force guna mendapatkan hasil yang tepat meskipun indeks vektor tersedia.
Harga
Fungsi VECTOR_SEARCH dan AI.SEARCH serta pernyataan CREATE VECTOR INDEX
menggunakan
harga komputasi BigQuery.
Fungsi
VECTOR_SEARCHdanAI.SEARCH: Anda akan dikenai biaya untuk penelusuran kemiripan, menggunakan harga on-demand atau edisi.- On-demand: Anda akan dikenai biaya untuk jumlah byte yang dipindai dalam tabel dasar, indeks, dan kueri penelusuran.
Harga edisi: Anda akan dikenai biaya untuk slot yang diperlukan untuk menyelesaikan tugas dalam edisi reservasi Anda. Perhitungan kemiripan yang lebih besar dan lebih kompleks akan dikenai biaya yang lebih besar.
Pernyataan
CREATE VECTOR INDEX: Tidak ada biaya untuk pemrosesan yang diperlukan untuk membangun dan memuat ulang indeks vektor Anda selama ukuran total data tabel yang diindeks berada di bawah batas per organisasi Anda. Untuk mendukung pengindeksan di luar batas ini, Anda harus menyediakan reservasi sendiri untuk menangani tugas pengelolaan indeks.
Penyimpanan juga merupakan pertimbangan untuk embedding dan indeks. Jumlah byte yang disimpan sebagai embedding dan indeks dikenai biaya penyimpanan aktif.
- Indeks vektor akan dikenai biaya penyimpanan saat aktif.
- Anda dapat menemukan ukuran penyimpanan indeks menggunakan tampilan
INFORMATION_SCHEMA.VECTOR_INDEXES. Jika indeks vektor belum mencapai cakupan 100%, Anda tetap akan dikenai biaya untuk apa pun yang telah diindeks. Anda dapat memeriksa cakupan indeks menggunakan tampilanINFORMATION_SCHEMA.VECTOR_INDEXES.
Kuota dan batas
Untuk mengetahui informasi selengkapnya, lihat Batas indeks vektor dan batas fungsi AI generatif.
Batasan
Kueri yang berisi fungsi VECTOR_SEARCH atau AI.SEARCH tidak akan
dipercepat oleh
BigQuery BI Engine.
Langkah berikutnya
- Pelajari lebih lanjut tentang cara membuat indeks vektor.
- Pelajari cara melakukan penelusuran vektor menggunakan
VECTOR_SEARCHfungsi. - Pelajari cara melakukan penelusuran semantik menggunakan fungsi
AI.SEARCH. - Pelajari lebih lanjut pembuatan embedding otonom.
- Coba tutorial Menelusuri embedding dengan penelusuran vektor untuk mempelajari cara membuat indeks vektor, lalu melakukan penelusuran vektor untuk embedding dengan dan tanpa indeks.
Coba tutorial Melakukan penelusuran semantik dan retrieval-augmented generation untuk mempelajari cara melakukan tugas berikut:
- Membuat embedding teks.
- Membuat indeks vektor pada embedding.
- Melakukan penelusuran vektor dengan embedding untuk menelusuri teks serupa.
- Melakukan retrieval-augmented generation (RAG) menggunakan hasil penelusuran vektor untuk menambah input perintah dan meningkatkan hasil.
Coba tutorial Mengurai PDF dalam pipeline retrieval-augmented generation untuk mempelajari cara membuat pipeline RAG berdasarkan konten PDF yang diurai.
Anda juga dapat melakukan penelusuran vektor menggunakan BigQuery DataFrames di Python. Untuk notebook yang mengilustrasikan pendekatan ini, lihat Membangun aplikasi Penelusuran Vektor menggunakan BigQuery DataFrames.