
Présentation des embeddings et de la recherche vectorielle
Ce document présente les embeddings et la recherche vectorielle dans BigQuery. La recherche vectorielle est une technique permettant de comparer des objets similaires à l'aide d'embeddings. Elle est utilisée pour alimenter les produits Google, y compris la recherche Google, YouTube et Google Play. Vous pouvez utiliser la recherche vectorielle pour effectuer des recherches à grande échelle. Lorsque vous utilisez des index vectoriels avec la recherche vectorielle, vous pouvez profiter de technologies fondamentales telles que l'indexation de fichiers inversés (IVF) et l' algorithme ScaNN.
La recherche vectorielle repose sur les embeddings. Les embeddings sont des vecteurs numériques de grande dimension qui représentent une entité donnée, comme un exemple de texte ou un fichier audio. Les modèles de machine learning (ML) utilisent des embeddings pour encoder la sémantique concernant ces entités afin de faciliter leur raisonnement et leur comparaison. Par exemple, une opération courante dans les modèles de clustering, de classification et de recommandation consiste à mesurer la distance entre les vecteurs dans un espace d'embedding afin de trouver les éléments les plus semantically similaires.
Ce concept de similarité et de distance sémantiques dans un espace d'embedding est illustré visuellement lorsque vous examinez la manière dont différents éléments peuvent être représentés. Par exemple, les termes chat, chien et lion, qui représentent tous des types d' animaux, sont regroupés dans cet espace en raison de leurs caractéristiques sémantiques communes. De même, les termes voiture, camion et le terme plus générique véhicule formeraient un autre cluster. Ceci est illustré dans l'image suivante :
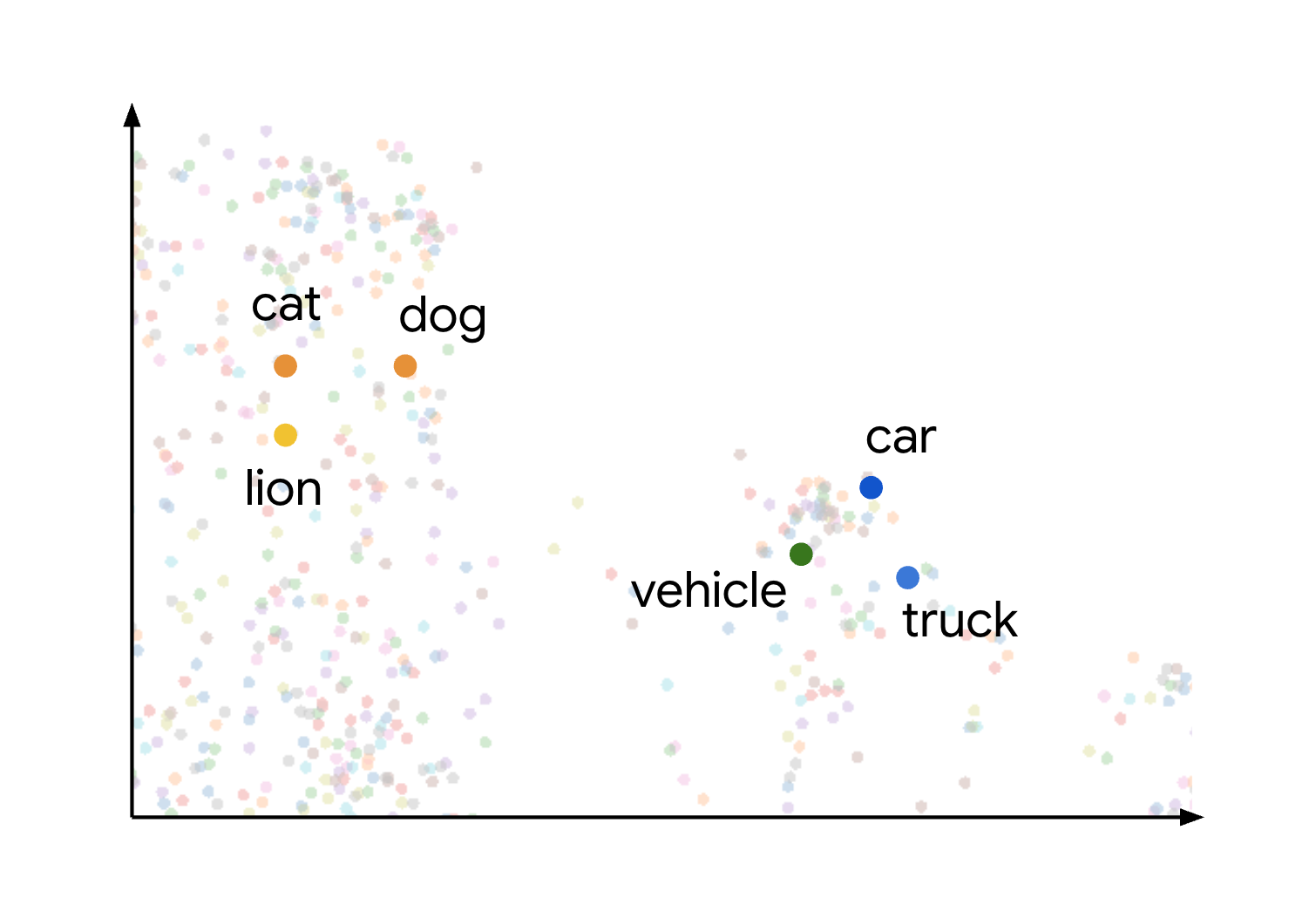
Vous pouvez voir que les clusters d'animaux et de véhicules sont éloignés les uns des autres. La séparation entre les groupes illustre le principe selon lequel plus les objets sont proches dans l'espace d'embedding, plus ils sont sémantiquement similaires, et plus les distances sont grandes, plus la dissemblance sémantique est importante.
Cas d'utilisation
La combinaison de la génération d'embeddings et de la recherche vectorielle permet de nombreux cas d'utilisation intéressants. Voici quelques cas d'utilisation possibles :
- Génération augmentée par récupération (RAG): analysez des documents, effectuez une recherche vectorielle sur le contenu et générez des réponses résumées à des questions en langage naturel à l'aide des modèles Gemini, le tout dans BigQuery. Pour obtenir un notebook illustrant ce scénario, consultez Créer une application de recherche vectorielle à l'aide de BigQuery DataFrames.
- Recommandation de produits de substitution ou de produits correspondants : améliorez les applications d'e-commerce en suggérant des produits alternatifs en fonction du comportement des clients et de la similarité des produits.
- Analyse des journaux : aidez les équipes à trier de manière proactive les anomalies dans les journaux et à accélérer les investigations. Vous pouvez également utiliser cette fonctionnalité pour enrichir le contexte des LLM, afin d'améliorer la détection des menaces, l'analyse forensique et les workflows de dépannage. Pour obtenir un notebook illustrant ce scénario, consultez Détection d'anomalies et investigation dans les journaux avec des embeddings textuels + BigQuery Vector Search.
- Clustering et ciblage : segmentez les audiences avec précision. Par exemple, une chaîne d'hôpitaux peut regrouper les patients à l'aide de notes en langage naturel et de données structurées, ou un spécialiste du marketing peut cibler des annonces en fonction de l'intention de la requête. Pour obtenir un notebook illustrant ce scénario, consultez Create-Campaign-Customer-Segmentation.
- Résolution des entités et déduplication : nettoyez et consolidez les données. Par exemple, une entreprise de publicité peut dédupliquer les enregistrements d'informations personnellement identifiables (IPI), ou une entreprise immobilière peut identifier les adresses postales correspondantes.
Générer des embeddings
Les sections suivantes décrivent les fonctions que BigQuery propose pour vous aider à générer des embeddings ou à les utiliser.
Générer des embeddings uniques
Vous pouvez utiliser la
AI.EMBED fonction
avec les modèles d'embedding de Gemini Enterprise Agent Platform pour générer un seul embedding
de votre entrée.
La fonction AI.EMBED est compatible avec les types d'entrée suivants :
- Données textuelles.
- Données d'image représentées par
ObjectRefvaleurs.
Générer une table d'embeddings
Vous pouvez utiliser les
AI.GENERATE_EMBEDDING
pour créer une table contenant des embeddings pour toutes les données d'une colonne de votre
table d'entrée. Pour tous les types de modèles compatibles, AI.GENERATE_EMBEDDING
fonctionne avec des données structurées dans
des tables standards. Pour les modèles d'embedding multimodaux, AI.GENERATE_EMBEDDING fonctionne également avec du contenu visuel
provenant de colonnes de table standards
contenant des valeurs ObjectRef,
ou de tables d'objets.
Pour les modèles distants, toutes les inférences ont lieu dans Agent Platform. Pour les autres types de modèles, toutes les inférences ont lieu dans BigQuery. Les résultats sont stockés dans BigQuery.
Consultez les rubriques suivantes pour essayer la génération d'embeddings dans BigQuery ML :
- Générer du texte,
images, ou
vidéo à l'aide de la
AI.GENERATE_EMBEDDINGfonction. - Générer et rechercher des embeddings multimodaux
- Effectuer une recherche sémantique et une génération augmentée par récupération
Génération autonome d'embeddings
Vous pouvez utiliser la génération autonome d'embeddings pour simplifier le processus de création, de maintenance et d'interrogation des embeddings. BigQuery gère une colonne d'embeddings dans votre table en fonction d'une colonne source. Lorsque vous ajoutez ou modifiez des données dans la colonne source, BigQuery génère ou met automatiquement à jour la colonne d'embedding pour ces données à l'aide d'un modèle d'embedding Agent Platform. Cela est utile si vous souhaitez que BigQuery gère vos embeddings lorsque vos données sources sont mises à jour régulièrement.
Rechercher
Les fonctions de recherche suivantes sont disponibles :
VECTOR_SEARCH: effectuez une recherche vectorielle à l'aide de SQL.AI.SEARCH(aperçu) : recherchez les résultats proches d'une chaîne que vous fournissez. Vous pouvez utiliser cette fonction si la génération autonome d'embeddings est activée pour votre table.AI.SIMILARITY: comparez deux entrées en calculant la similarité cosinus entre leurs embeddings. Cette fonction est utile si vous souhaitez effectuer un petit nombre de comparaisons et que vous n'avez pas précalculé d'embeddings. Vous devez utiliserVECTOR_SEARCHlorsque les performances sont essentielles et que vous travaillez avec un grand nombre d'embeddings. Comparez leurs fonctionnalités pour choisir la fonction la plus adaptée à votre cas d'utilisation.
Vous pouvez également créer un index vectoriel à
l'aide de
CREATE VECTOR INDEX l'instruction.
Lorsqu'un index vectoriel est utilisé, les fonctions VECTOR_SEARCH et AI.SEARCH utilisent
la technique de recherche approximative du voisin le plus proche
pour améliorer les performances de la recherche vectorielle, avec un compromis consistant à
réduire
le rappel
et renvoyant ainsi des résultats plus approximatifs. Sans index vectoriel, ces
fonctions utilisent
la recherche par force brute pour
mesurer la distance de chaque enregistrement. Vous pouvez également choisir d'utiliser la force brute pour obtenir des résultats exacts, même lorsqu'un index vectoriel est disponible.
Tarifs
Les fonctions VECTOR_SEARCH et AI.SEARCH, ainsi que l'CREATE VECTOR INDEX
instruction utilisent
les tarifs de calcul BigQuery.
VECTOR_SEARCHetAI.SEARCHfonctions : la recherche de similarité vous est facturée à l'aide des tarifs à la demande ou des éditions.- À la demande : vous êtes facturé en fonction du nombre d'octets analysés dans la table de base, l'index et la requête de recherche.
Tarifs des éditions : vous êtes facturé en fonction des emplacements requis pour terminer le job dans votre édition de réservation. Les calculs de similarité plus complexes et plus volumineux entraînent des frais plus élevés.
Instruction
CREATE VECTOR INDEX: le traitement requis pour créer et actualiser vos index vectoriels est sans frais tant que la taille totale des données de table indexées est inférieure à votre limite par organisation. Pour accepter l'indexation au-delà de cette limite, vous devez fournir votre propre réservation pour la gestion des jobs de gestion des index.
Le stockage est également un facteur à prendre en compte pour les embeddings et les index. La quantité d'octets stockés en tant qu'embeddings et index est soumise aux coûts de stockage actif.
- Les index vectoriels entraînent des coûts de stockage lorsqu'ils sont actifs.
- Vous pouvez trouver la taille de stockage de l'index à l'aide de la
INFORMATION_SCHEMA.VECTOR_INDEXESvue. Si l'index vectoriel n'est pas encore à 100% de la couverture, vous êtes toujours facturé pour ce qui a été indexé. Vous pouvez vérifier la couverture de l'index à l'aide de la vueINFORMATION_SCHEMA.VECTOR_INDEXES.
Quotas et limites
Pour en savoir plus, consultez Limites des index vectoriels et Limites des fonctions d'IA générative.
Limites
Les requêtes contenant la fonction VECTOR_SEARCH ou AI.SEARCH ne sont
pas accélérées par
BigQuery BI Engine.
Étape suivante
- Apprenez-en plus sur la création d'un index vectoriel.
- Découvrez comment effectuer une recherche vectorielle à l'aide de la
VECTOR_SEARCHfonction. - Découvrez comment effectuer une recherche sémantique à l'aide de la
AI.SEARCHfonction. - En savoir plus sur la génération autonome d'embeddings.
- Suivez le tutoriel Rechercher des embeddings avec la recherche vectorielle pour apprendre à créer un index vectoriel, puis effectuez une recherche vectorielle d'embeddings avec et sans l'index.
Suivez le tutoriel Effectuer une recherche sémantique et une génération augmentée par récupération pour apprendre à effectuer les tâches suivantes :
- Générer des embeddings textuels.
- Créer un index vectoriel sur les embeddings.
- Effectuer une recherche vectorielle avec les embeddings pour rechercher du texte similaire.
- Effectuer une génération augmentée par récupération (RAG) en utilisant les résultats de la recherche vectorielle pour augmenter l'entrée du prompt et améliorer les résultats.
Suivez le tutoriel Analyser des PDF dans un pipeline de génération augmentée par récupération pour découvrir comment créer un pipeline RAG basé sur le contenu PDF analysé.
Vous pouvez également effectuer des recherches vectorielles à l'aide de BigQuery DataFrames dans Python. Pour obtenir un notebook illustrant cette approche, consultez Créer une application de recherche vectorielle à l'aide de BigQuery DataFrames.