
חיפוש נתונים שנוספו לאינדקס
בדף הזה מפורטות דוגמאות לחיפוש נתונים בטבלה ב-BigQuery.
כשמבצעים אינדוקס של הנתונים, מערכת BigQuery יכולה לבצע אופטימיזציה של חלק מהשאילתות שמשתמשות בפונקציה SEARCH או בפונקציות ובאופרטורים אחרים, כמו =, IN, LIKE ו-STARTS_WITH.
שאילתות SQL מחזירות תוצאות נכונות מכל הנתונים שהועברו, גם אם חלק מהנתונים עדיין לא עברו אינדוקס. עם זאת, אפשר לשפר מאוד את ביצועי השאילתה באמצעות אינדקס. החיסכון בבייטים שעברו עיבוד ובאלפיות שנייה של משבצות זמן הוא מקסימלי כשמספר התוצאות בחיפוש מהווה חלק קטן יחסית ממספר השורות הכולל בטבלה, כי נסרקים פחות נתונים. כדי לדעת אם נעשה שימוש באינדקס בשאילתה, אפשר לעיין במאמר בנושא שימוש באינדקס חיפוש.
יצירת אינדקס חיפוש
הטבלה הבאה, שנקראת Logs, משמשת להצגת דרכים שונות לשימוש בפונקציה SEARCH. טבלת הדוגמה הזו קטנה למדי, אבל בפועל, ככל שהטבלה גדולה יותר, כך השיפור בביצועים שמתקבל באמצעות SEARCH גדול יותר.
CREATE TABLE my_dataset.Logs (Level STRING, Source STRING, Message STRING) AS ( SELECT 'INFO' as Level, '65.177.8.234' as Source, 'Entry Foo-Bar created' as Message UNION ALL SELECT 'WARNING', '132.249.240.10', 'Entry Foo-Bar already exists, created by 65.177.8.234' UNION ALL SELECT 'INFO', '94.60.64.181', 'Entry Foo-Bar deleted' UNION ALL SELECT 'SEVERE', '4.113.82.10', 'Entry Foo-Bar does not exist, deleted by 94.60.64.181' UNION ALL SELECT 'INFO', '181.94.60.64', 'Entry Foo-Baz created' );
הטבלה תיראה כך:
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | INFO | 65.177.8.234 | Entry Foo-Bar created | | WARNING | 132.249.240.10 | Entry Foo-Bar already exists, created by 65.177.8.234 | | INFO | 94.60.64.181 | Entry Foo-Bar deleted | | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | | INFO | 181.94.60.64 | Entry Foo-Baz created | +---------+----------------+-------------------------------------------------------+
יוצרים אינדקס חיפוש בטבלה Logs באמצעות הכלי לניתוח טקסט שמוגדר כברירת מחדל:
CREATE SEARCH INDEX my_index ON my_dataset.Logs(ALL COLUMNS);
מידע נוסף על ניהול אינדקסים של חיפוש
שימוש בפונקציה SEARCH
הפונקציה SEARCH מספקת חיפוש מבוסס-טוקנים בנתונים.
הפונקציה SEARCH מיועדת לשימוש עם אינדקס כדי לייעל את החיפושים.
אפשר להשתמש בפונקציה SEARCH כדי לחפש בטבלה שלמה או להגביל את החיפוש לעמודות ספציפיות.
חיפוש בטבלה שלמה
השאילתה הבאה מחפשת בכל העמודות של הטבלה Logs את הערך bar ומחזירה את השורות שמכילות את הערך הזה, ללא קשר לשימוש באותיות רישיות. מכיוון שמדד החיפוש משתמש בניתוח הטקסט שמוגדר כברירת מחדל, לא צריך לציין אותו בפונקציה SEARCH.
SELECT * FROM my_dataset.Logs WHERE SEARCH(Logs, 'bar');
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | INFO | 65.177.8.234 | Entry Foo-Bar created | | WARNING | 132.249.240.10 | Entry Foo-Bar already exists, created by 65.177.8.234 | | INFO | 94.60.64.181 | Entry Foo-Bar deleted | | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | +---------+----------------+-------------------------------------------------------+
השאילתה הבאה מחפשת את הערך `94.60.64.181` בכל העמודות בטבלה Logs ומחזירה את השורות שמכילות את הערך הזה. הגרשיים מאפשרים חיפוש מדויק, ולכן השורה האחרונה בטבלה Logs שמכילה את 181.94.60.64 מושמטת.
SELECT * FROM my_dataset.Logs WHERE SEARCH(Logs, '`94.60.64.181`');
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | INFO | 94.60.64.181 | Entry Foo-Bar deleted | | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | +---------+----------------+-------------------------------------------------------+
חיפוש בקבוצת משנה של עמודות
הפונקציה SEARCH מאפשרת לציין בקלות קבוצת משנה של עמודות שבהן יתבצע חיפוש של נתונים. השאילתה הבאה מחפשת את הערך 94.60.64.181 בעמודה Message בטבלה Logs ומחזירה את השורות שמכילות את הערך הזה.
SELECT * FROM my_dataset.Logs WHERE SEARCH(Message, '`94.60.64.181`');
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | +---------+----------------+-------------------------------------------------------+
השאילתה הבאה מחפשת בעמודות Source ו-Message של הטבלה Logs. היא מחזירה את השורות שמכילות את הערך 94.60.64.181 מאחת העמודות.
SELECT * FROM my_dataset.Logs WHERE SEARCH((Source, Message), '`94.60.64.181`');
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | INFO | 94.60.64.181 | Entry Foo-Bar deleted | | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | +---------+----------------+-------------------------------------------------------+
החרגת עמודות מחיפוש
אם בטבלה יש הרבה עמודות ואתם רוצים לחפש ברוב העמודות, יכול להיות שיהיה לכם יותר קל לציין רק את העמודות שאתם רוצים להחריג מהחיפוש. השאילתה הבאה מחפשת בכל העמודות בטבלה Logs, מלבד העמודה Message. הפונקציה מחזירה את השורות של כל העמודות מלבד Message
שמכילות את הערך 94.60.64.181.
SELECT * FROM my_dataset.Logs WHERE SEARCH( (SELECT AS STRUCT Logs.* EXCEPT (Message)), '`94.60.64.181`');
+---------+----------------+---------------------------------------------------+ | Level | Source | Message | +---------+----------------+---------------------------------------------------+ | INFO | 94.60.64.181 | Entry Foo-Bar deleted | +---------+----------------+---------------------------------------------------+
שימוש בכלי אחר לניתוח טקסט
בדוגמה הבאה נוצרת טבלה בשם contact_info עם אינדקס שמשתמש בNO_OP_ANALYZER
ככלי לניתוח טקסט:
CREATE TABLE my_dataset.contact_info (name STRING, email STRING) AS ( SELECT 'Kim Lee' AS name, 'kim.lee@example.com' AS email UNION ALL SELECT 'Kim' AS name, 'kim@example.com' AS email UNION ALL SELECT 'Sasha' AS name, 'sasha@example.com' AS email ); CREATE SEARCH INDEX noop_index ON my_dataset.contact_info(ALL COLUMNS) OPTIONS (analyzer = 'NO_OP_ANALYZER');
+---------+---------------------+ | name | email | +---------+---------------------+ | Kim Lee | kim.lee@example.com | | Kim | kim@example.com | | Sasha | sasha@example.com | +---------+---------------------+
השאילתה הבאה מחפשת את הערך Kim בעמודה name ואת הערך kim
בעמודה email.
מכיוון שמדד החיפוש לא משתמש בכלי ברירת המחדל לניתוח טקסט, צריך להעביר את שם הכלי לניתוח טקסט לפונקציה SEARCH.
SELECT name, SEARCH(name, 'Kim', analyzer=>'NO_OP_ANALYZER') AS name_Kim, email, SEARCH(email, 'kim', analyzer=>'NO_OP_ANALYZER') AS email_kim FROM my_dataset.contact_info;
הפונקציה NO_OP_ANALYZER לא משנה את הטקסט, ולכן הפונקציה SEARCH מחזירה רק את הערך TRUE להתאמות מדויקות:
+---------+----------+---------------------+-----------+ | name | name_Kim | email | email_kim | +---------+----------+---------------------+-----------+ | Kim Lee | FALSE | kim.lee@example.com | FALSE | | Kim | TRUE | kim@example.com | FALSE | | Sasha | FALSE | sasha@example.com | FALSE | +---------+----------+---------------------+-----------+
הגדרת אפשרויות של כלי לניתוח טקסט
אפשר להתאים אישית את כלי הניתוח של הטקסט LOG_ANALYZER ו-PATTERN_ANALYZER על ידי הוספת מחרוזת בפורמט JSON לאפשרויות ההגדרה. אפשר להגדיר כלי לניתוח טקסט באמצעות הפונקציה SEARCH, הצהרת ה-DDL CREATE
SEARCH INDEX והפונקציה TEXT_ANALYZE.
בדוגמה הבאה נוצרת טבלה בשם complex_table עם אינדקס שמשתמש בכלי לניתוח טקסט LOG_ANALYZER. היא משתמשת במחרוזת בפורמט JSON כדי להגדיר את האפשרויות של הכלי לניתוח:
CREATE TABLE dataset.complex_table( a STRING, my_struct STRUCT<string_field STRING, int_field INT64>, b ARRAY<STRING> ); CREATE SEARCH INDEX my_index ON dataset.complex_table(a, my_struct, b) OPTIONS (analyzer = 'LOG_ANALYZER', analyzer_options = '''{ "token_filters": [ { "normalizer": {"mode": "NONE"} } ] }''');
בטבלה הבאה מוצגות דוגמאות לקריאות לפונקציה SEARCH עם מנתחי טקסט שונים והתוצאות שלהם. בטבלה הראשונה מבוצעת קריאה לפונקציה SEARCH
באמצעות כלי ברירת המחדל לניתוח טקסט, LOG_ANALYZER:
| בקשה להפעלת פונקציה | מחזירה | סיבה |
|---|---|---|
| SEARCH('foobarexample', NULL) | שגיאה | הערך של search_terms הוא NULL. |
| SEARCH('foobarexample', '') | שגיאה | הפרמטר search_terms לא מכיל טוקנים. |
| SEARCH('foobar-example', 'foobar example') | TRUE | התווים '-' ו-' ' הם תווים מפרידים. |
| SEARCH('foobar-example', 'foobarexample') | לא נכון | הערך search_terms לא מפולח. |
| SEARCH('foobar-example', 'foobar\\&example') | TRUE | הקו הנטוי הכפול מבטל את האמפרסנד, שהוא תו הפרדה. |
| SEARCH('foobar-example', R'foobar\&example') | TRUE | הלוכסן הבודד מבטל את המשמעות של הסימן & במחרוזת גולמית. |
| SEARCH('foobar-example', '`foobar&example`') | לא נכון | הגרשיים הנטויים דורשים התאמה מדויקת ל-foobar&example. |
| SEARCH('foobar&example', '`foobar&example`') | TRUE | נמצאה התאמה מדויקת. |
| SEARCH('foobar-example', 'example foobar') | TRUE | סדר המונחים לא משנה. |
| SEARCH('foobar-example', 'foobar example') | TRUE | האסימונים הם באותיות קטנות. |
| SEARCH('foobar-example', '`foobar-example`') | TRUE | נמצאה התאמה מדויקת. |
| SEARCH('foobar-example', '`foobar`') | לא נכון | הגרש שומר על השימוש באותיות גדולות. |
| SEARCH('`foobar-example`', '`foobar-example`') | לא נכון | לגרשיים הפוכים אין משמעות מיוחדת בפרמטרים data_to_search ו- |
| SEARCH('foobar@example.com', '`example.com`') | TRUE | נמצאה התאמה מדויקת אחרי התו להפרדה ב-data_to_search. |
| SEARCH('a foobar-example b', '`foobar-example`') | TRUE | נמצאה התאמה מדויקת בין תווי המפריד של הרווחים. |
| SEARCH(['foobar', 'example'], 'foobar example') | לא נכון | אף רשומה במערך לא תואמת לכל מונחי החיפוש. |
| SEARCH('foobar=', '`foobar\\=`') | לא נכון | המחרוזת search_terms שקולה למחרוזת foobar\=. |
| SEARCH('foobar=', R'`foobar\=`') | לא נכון | זה שווה לדוגמה הקודמת. |
| SEARCH('foobar=', 'foobar\\=') | TRUE | סימן השוויון הוא תו מפריד בנתונים ובשאילתה. |
| SEARCH('foobar=', R'foobar\=') | TRUE | זה שווה לדוגמה הקודמת. |
| SEARCH('foobar.example', '`foobar`') | TRUE | נמצאה התאמה מדויקת. |
| SEARCH('foobar.example', '`foobar.`') | לא נכון | המחרוזת `foobar.` לא מנותחת בגלל התווים ` (גרש הפוך); היא לא |
| SEARCH('foobar..example', '`foobar.`') | TRUE | המחרוזת `foobar.` לא מנותחת בגלל התווים ` (גרש הפוך); היא מופיעה |
בטבלה הבאה מופיעות דוגמאות לקריאות לפונקציה SEARCH באמצעות כלי ניתוח הטקסט NO_OP_ANALYZER, וסיבות לערכי החזרה שונים:
| בקשה להפעלת פונקציה | מחזירה | סיבה |
|---|---|---|
| SEARCH('foobar', 'foobar', analyzer=>'NO_OP_ANALYZER') | TRUE | נמצאה התאמה מדויקת. |
| SEARCH('foobar', '`foobar`', analyzer=>'NO_OP_ANALYZER') | לא נכון | הגרש העליון לא נחשב לתו מיוחד ב-NO_OP_ANALYZER. |
| SEARCH('Foobar', 'foobar', analyzer=>'NO_OP_ANALYZER') | לא נכון | השימוש באותיות רישיות לא תואם. |
| SEARCH('foobar example', 'foobar', analyzer=>'NO_OP_ANALYZER') | לא נכון | אין תווי הפרדה ל-NO_OP_ANALYZER. |
| SEARCH('', '', analyzer=>'NO_OP_ANALYZER') | TRUE | אין תווי הפרדה ל-NO_OP_ANALYZER. |
אופרטורים ופונקציות אחרים
אתם יכולים לבצע אופטימיזציות של אינדקס החיפוש באמצעות כמה אופרטורים, פונקציות ופרדיקטים.
אופטימיזציה באמצעות אופרטורים ופונקציות השוואה
BigQuery יכול לבצע אופטימיזציה של חלק מהשאילתות שמשתמשות באופרטור השוויון (=), באופרטור IN, באופרטור LIKE, בפונקציה STARTS_WITH או בפונקציה ENDS_WITH כדי להשוות בין מחרוזות מילוליות לבין נתונים באינדקס.
אופטימיזציה באמצעות פרדיקטים של מחרוזות
אפשר לבצע אופטימיזציה של אינדקס החיפוש עבור התנאים הבאים:
column_name = 'string_literal''string_literal' = column_namestruct_column.nested_field = 'string_literal'string_array_column[OFFSET(0)] = 'string_literal'string_array_column[ORDINAL(1)] = 'string_literal'column_name IN ('string_literal1', 'string_literal2', ...)column_name LIKE 'prefix%'STARTS_WITH(column_name, 'prefix')ENDS_WITH(column_name, 'some suffix')
אופטימיזציה באמצעות פסוקיות מספריות
אם אינדקס החיפוש נוצר עם סוגי נתונים מספריים, מערכת BigQuery יכולה לבצע אופטימיזציה של חלק מהשאילתות שמשתמשות באופרטור השווה (=) או באופרטור IN עם נתונים באינדקס. הפרדיקטים הבאים עומדים בדרישות לאופטימיזציה של אינדקס החיפוש:
INT64(json_column.int64_field) = 1int64_column = 1int64_array_column[OFFSET(0)] = 1int64_column IN (1, 2)struct_column.nested_int64_field = 1struct_column.nested_timestamp_field = TIMESTAMP "2024-02-15 21:31:40"timestamp_column = "2024-02-15 21:31:40"timestamp_column IN ("2024-02-15 21:31:40", "2024-02-16 21:31:40")
אופטימיזציה של פונקציות שמפיקות נתונים עם אינדקס
מערכת BigQuery תומכת באופטימיזציה של אינדקסים לחיפוש כשמחילים פונקציות מסוימות על נתונים באינדקס.
אם אינדקס החיפוש משתמש במנתח הטקסט LOG_ANALYZER שמוגדר כברירת מחדל, אפשר להחיל את הפונקציות UPPER או LOWER על העמודה, כמו UPPER(column_name) = 'STRING_LITERAL'.
לנתוני מחרוזת סקלריים JSON שחולצו מעמודה עם אינדקס JSON, אפשר להחיל את הפונקציה STRING או את הגרסה הבטוחה שלה, SAFE.STRING.
אם הערך JSON שחולץ הוא לא מחרוזת, הפונקציה STRING מייצרת שגיאה והפונקציה SAFE.STRING מחזירה NULL.
לנתונים בפורמט JSON עם אינדקס STRING (לא JSON), אפשר להחיל את הפונקציות הבאות:
לדוגמה, נניח שיש לכם את הטבלה הבאה עם אינדקס בשם dataset.person_data עם העמודות JSON ו-STRING:
+----------------------------------------------------------------+-----------------------------------------+
| json_column | string_column |
+----------------------------------------------------------------+-----------------------------------------+
| { "name" : "Ariel", "email" : "cloudysanfrancisco@gmail.com" } | { "name" : "Ariel", "job" : "doctor" } |
+----------------------------------------------------------------+-----------------------------------------+
השאילתות הבאות עומדות בדרישות לאופטימיזציה:
SELECT * FROM dataset.person_data WHERE SAFE.STRING(json_column.email) = 'cloudysanfrancisco@gmail.com';
SELECT * FROM dataset.person_data WHERE JSON_VALUE(string_column, '$.job') IN ('doctor', 'lawyer', 'teacher');
המערכת גם מבצעת אופטימיזציה לשילובים של הפונקציות האלה, כמו UPPER(JSON_VALUE(json_string_expression)) = 'FOO'.
אופטימיזציה באמצעות JSON_FLATTEN
BigQuery תומך באופטימיזציה של אינדקסים של חיפוש בשאילתות שמשתמשות בפונקציה JSON_FLATTEN כדי לשטח מערכי JSON, בדרך כלל בשילוב עם EXISTS ו-UNNEST.
לדוגמה, נניח שיש לכם טבלה בשם dataset.logs עם עמודה JSON בשם json_payload. השאילתה הבאה עומדת בדרישות לאופטימיזציה:
SELECT json_payload FROM dataset.logs WHERE EXISTS( SELECT 1 FROM UNNEST(JSON_FLATTEN(JSON_QUERY(json_payload, "lax recursive $.message"))) AS f WHERE SEARCH(f, "nullpointerexception") );
שימוש באינדקס החיפוש
כדי לקבוע אם נעשה שימוש באינדקס חיפוש בשאילתה, אפשר לעיין בפרטי העבודה או להריץ שאילתה באחת מתצוגות INFORMATION_SCHEMA.JOBS*.
צפייה בפרטי המשרה
בקטע Job Information של Query results, השדות Index Usage Mode ו-Index Unused Reasons מספקים מידע מפורט על השימוש באינדקס החיפוש.
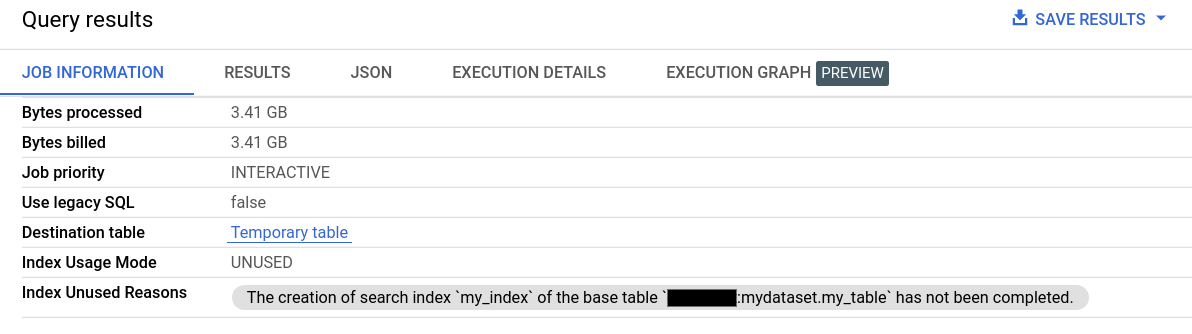
מידע על השימוש באינדקס החיפוש זמין גם דרך השדה searchStatistics בשיטת Jobs.Get API. השדה indexUsageMode ב-searchStatistics מציין אם נעשה שימוש באינדקס חיפוש עם הערכים הבאים:
-
UNUSED: לא נעשה שימוש באינדקס חיפוש. -
PARTIALLY_USED: חלק מהשאילתה השתמש במדדי חיפוש וחלק לא. -
FULLY_USED: כל פונקציהSEARCHבשאילתה השתמשה באינדקס חיפוש.
אם הערך של indexUsageMode הוא UNUSED או PARTIALLY_USED, השדה indexUnusedReasons מכיל מידע על הסיבות לכך שלא נעשה שימוש באינדקסים של חיפוש בשאילתה.
כדי לראות את searchStatistics של שאילתה, מריצים את הפקודה bq show.
bq show --format=prettyjson -j JOB_ID
דוגמה
נניח שאתם מריצים שאילתה שקוראת לפונקציה SEARCH על נתונים בטבלה. אפשר לראות את פרטי העבודה של השאילתה כדי למצוא את מזהה העבודה, ואז להריץ את הפקודה bq show כדי לראות מידע נוסף:
bq show --format=prettyjson --j my_project:US.bquijob_123x456_789y123z456c
הפלט מכיל שדות רבים, כולל searchStatistics, שנראה כך: בדוגמה הזו, indexUsageMode מציין שלא נעשה שימוש באינדקס. הסיבה לכך היא שלטבלה אין אינדקס חיפוש. כדי לפתור את הבעיה, יוצרים אינדקס חיפוש בטבלה. בindexUnusedReason שדה code מופיעה רשימה של כל הסיבות האפשריות לכך שאינדקס חיפוש לא ישמש בשאילתה.
"searchStatistics": {
"indexUnusedReasons": [
{
"baseTable": {
"datasetId": "my_dataset",
"projectId": "my_project",
"tableId": "my_table"
},
"code": "INDEX_CONFIG_NOT_AVAILABLE",
"message": "There is no search index configuration for the base table `my_project:my_dataset.my_table`."
}
],
"indexUsageMode": "UNUSED"
},
שאילתות בתצוגות של INFORMATION_SCHEMA
אפשר לראות את השימוש באינדקס החיפוש בכמה משימות באזור מסוים בתצוגות הבאות:
INFORMATION_SCHEMA.JOBSINFORMATION_SCHEMA.JOBS_BY_USERINFORMATION_SCHEMA.JOBS_BY_FOLDERINFORMATION_SCHEMA.JOBS_BY_ORGANIZATION
השאילתה הבאה מציגה מידע על השימוש באינדקס לגבי כל השאילתות שאפשר לבצע בהן אופטימיזציה של אינדקס החיפוש ב-7 הימים האחרונים:
SELECT job_id, search_statistics.index_usage_mode, index_unused_reason.code, index_unused_reason.base_table.table_id, index_unused_reason.index_name FROM `region-REGION_NAME`.INFORMATION_SCHEMA.JOBS, UNNEST(search_statistics.index_unused_reasons) AS index_unused_reason WHERE end_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 7 DAY) AND CURRENT_TIMESTAMP();
התוצאה אמורה להיראות כך:
+-----------+----------------------------------------+-----------------------+ | job_id | index_usage_mode | code | table_id | index_name | +-----------+------------------+---------------------+-----------------------+ | bquxjob_1 | UNUSED | BASE_TABLE_TOO_SMALL| my_table | my_index | | bquxjob_2 | FULLY_USED | NULL | my_table | my_index | +-----------+----------------------------------------+-----------------------+
שיטות מומלצות
בקטעים הבאים מפורטות שיטות מומלצות לחיפוש.
חיפוש סלקטיבי
החיפוש עובד הכי טוב כשמוצאים מעט תוצאות. כדאי לנסח את החיפושים בצורה ספציפית ככל האפשר.
אופטימיזציה של ORDER BY LIMIT
אפשר לבצע אופטימיזציה לשאילתות שמשתמשות בפונקציות SEARCH, =, IN, LIKE או STARTS_WITH בטבלה מחולקת גדולה מאוד, אם משתמשים בפסוקית ORDER BY בשדה המחולק ובפסוקית LIMIT.
בשביל שאילתות שלא מכילות את הפונקציה SEARCH, אפשר להשתמש באופרטורים ובפונקציות אחרות כדי ליהנות מהאופטימיזציה. האופטימיזציה מיושמת בין אם הטבלה נוספה לאינדקס ובין אם לא. השיטה הזו מתאימה אם מחפשים מונח נפוץ.
לדוגמה, נניח שהטבלה Logs שנוצרה קודם מחולקת למחיצות בעמודה נוספת מסוג DATE שנקראת day. השאילתה הבאה עברה אופטימיזציה:
SELECT Level, Source, Message FROM my_dataset.Logs WHERE SEARCH(Message, "foo") ORDER BY day LIMIT 10;
הגדרת היקף החיפוש
כשמשתמשים בפונקציה SEARCH, צריך לחפש רק בעמודות של הטבלה שצפויות להכיל את מונחי החיפוש. כך משפרים את הביצועים ומקטינים את מספר הבייטים שצריך לסרוק.
שימוש בגרשיים הפוכים
כשמשתמשים בפונקציה SEARCH עם הכלי LOG_ANALYZER לניתוח טקסט, הוספת גרשיים הפוכים לשאילתת החיפוש מאלצת התאמה מדויקת. זה שימושי אם החיפוש תלוי באותיות רישיות או מכיל תווים שלא אמורים להתפרש כמפרידים. לדוגמה, כדי לחפש את כתובת ה-IP
192.0.2.1, משתמשים ב-`192.0.2.1`. בלי המירכאות, החיפוש מחזיר כל שורה שמכילה את הטוקנים 192, 0, 2 ו-1, בכל סדר.