
整理 BigQuery 資源
BigQuery 資源會以階層方式整理,就像其他Google Cloud 服務一樣。瞭解這個階層架構有助於建構 BigQuery 資源,以便管理工作負載、控管權限、分配配額、指派運算單元預留項目,以及追蹤帳單。
資源階層
BigQuery 會沿用Google Cloud 資源階層,並新增稱為「資料集」的額外分組機制,這項機制專屬於 BigQuery。本節將說明這個階層的元素。
資料集
資料集是邏輯容器,可用來整理 BigQuery 資源並控管存取權。資料集類似於其他資料庫系統中的結構定義。
您建立的大部分 BigQuery 資源 (包括資料表、檢視區塊、函式和程序) 都會建立在資料集中。連線和工作是例外狀況,因為這些項目與專案相關聯,而非資料集。
資料集有位置。建立資料表時,資料表資料會儲存在資料集的位置。建立生產資料表之前,請先考量位置規定。資料集建立之後,就無法更改位置。
專案
每個資料集都與專案相關聯。如要使用 Google Cloud,您必須建立至少一個專案。專案是建立、啟用及使用所有 Google Cloud 服務的基礎。詳情請參閱「資源階層」。一個專案可以包含多個資料集,且同一專案中可存在不同位置的資料集。
對 BigQuery 資料執行作業時 (例如執行查詢或將資料擷取至資料表),您會建立工作。作業一律會與專案建立關聯,但不一定要在包含資料的專案中執行。事實上,工作可能會參照多個專案中資料集的資料表。查詢、載入或擷取工作一律會在參照資料表的位置執行。
每項專案都會連結至一個 Cloud Billing 帳戶,系統會向該帳戶收取專案產生的費用。如果您使用以量計價,系統會將查詢費用計入執行查詢的專案。如果您採用以容量計價,系統會向您用於購買運算單元的管理專案收取運算單元預留費用。系統會向資料集所屬專案收取儲存空間費用。
資料夾
資料夾是在專案之上更進一步的分組機制。資料夾內的專案和資料夾會自動沿用父項資料夾的存取權政策。資料夾可用來為公司內的不同法人、部門和團隊建立模型。
這裡討論的資料夾屬於Google Cloud 資源階層。請勿與 BigQuery 資料夾混淆,後者可用於整理程式碼資產。
組織
機構資源代表組織 (例如公司),同時也是Google Cloud 資源階層的根節點。
您不必擁有機構資源,即可開始使用 BigQuery,但我們建議您建立機構資源。使用機構資源可讓管理員集中控管 BigQuery 資源,而不是由個別使用者控管自己建立的資源。
下圖為資源階層的範例。在這個範例中,機構在資料夾內有一個專案。專案已與帳單帳戶建立關聯,且內含三個資料集。
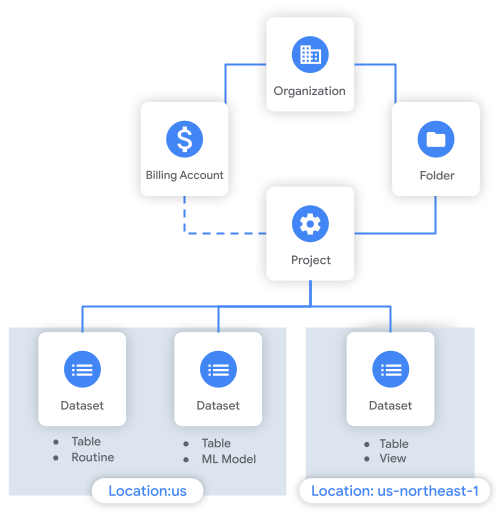
注意事項
選擇如何整理 BigQuery 資源時,請考量下列幾點:
- 配額。許多 BigQuery 配額都是在專案層級套用。其中有幾個適用於資料集層級。涉及運算資源的專案層級配額 (例如查詢和載入工作),會計入建立工作的專案,而非儲存專案。
- 帳單。如果貴機構的不同部門要使用不同的 Cloud Billing 帳戶,請為每個團隊建立不同的專案。在機構層級建立 Cloud Billing 帳戶,並將專案與這些帳戶建立關聯。
- 運算單元預留項目。預留運算單元的範圍為機構資源。購買預留配額容量後,您可以將配額集區指派給機構內的任何專案或資料夾,也可以將配額指派給整個機構資源。專案會繼承上層資料夾或機構的時段預訂。預留運算單元會與管理專案建立關聯,用於管理運算單元。詳情請參閱使用預留項目進行工作負載管理。
權限。請考量權限階層對貴機構中需要存取資料的使用者有何影響。舉例來說,如要讓整個團隊存取特定資料,您可以將該資料儲存在單一專案中,簡化存取權管理作業。
資料表和其他實體會繼承父項資料集的權限。資料集會繼承資源階層 (專案、資料夾、機構) 中父項實體的權限。如要對資源執行作業,使用者必須同時具備資源的相關權限,以及建立 BigQuery 工作的權限。建立工作的權限與該工作使用的專案相關聯。
圖樣
本節介紹兩種常見的 BigQuery 資源整理模式。
中央資料湖泊、部門資料市集。該機構建立統一的儲存空間專案,用來存放原始資料。機構內的各部門會建立自己的資料市集專案,以供分析。
部門資料湖泊,中央資料倉儲。各部門會建立及管理自己的儲存空間專案,用來存放該部門的原始資料。然後,該機構會建立中央資料倉儲專案,以進行分析。
每種做法各有優缺點。許多機構會結合這兩種模式的元素。
中央資料湖泊、部門資料市集
在這個模式中,您會建立統一的儲存空間專案,用來保存機構的原始資料。資料擷取管道也可以在這個專案中執行。這個統一儲存空間專案可做為貴機構的資料湖泊。
每個部門都有專屬專案,可查詢資料、儲存查詢結果及建立檢視畫面。這些部門層級專案會做為資料市集。這些資源會與部門的帳單帳戶建立關聯。
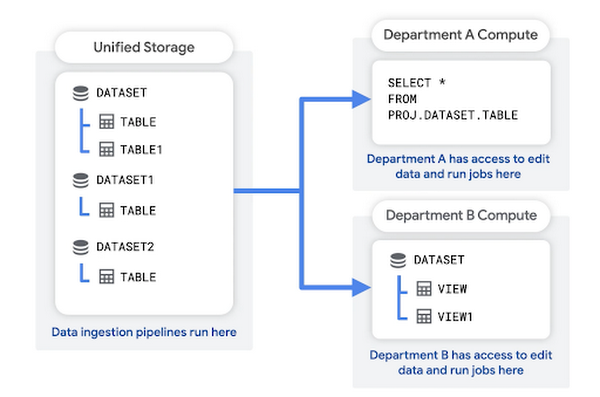
這種結構的優點包括:
- 集中式資料工程團隊可以在單一位置管理擷取管道。
- 原始資料與部門層級專案隔離。
- 若是以量計價,執行查詢的部門會支付查詢費用。
- 採用容量計費時,您可以根據各部門的預估運算需求,為每個部門指派運算單元。
- 就專案層級配額而言,每個部門都是獨立的。
使用這種結構時,通常會授予下列權限:
- 中央資料工程團隊獲授儲存專案的 BigQuery 資料編輯者和 BigQuery 工作使用者角色。這些權限可讓他們在儲存空間專案中擷取及編輯資料。
- 部門分析師在中央資料湖泊專案中,獲得特定資料集的 BigQuery 資料檢視者角色。這樣一來,他們就能查詢資料,但無法更新或刪除原始資料。
- 此外,部門分析師也獲得部門資料市集專案的 BigQuery 資料編輯者和工作使用者角色。這樣一來,他們就能在專案中建立及更新資料表,並執行查詢工作,以便轉換及匯總資料,供部門專用。
詳情請參閱「基本角色和權限」。
部門資料湖泊,中央資料倉儲
在這個模式中,每個部門都會建立及管理自己的儲存空間專案,中央資料倉儲專案會儲存原始資料的匯總或轉換結果。
分析師可以查詢及讀取資料倉儲專案中的匯總資料。資料倉儲專案也會為商業智慧 (BI) 工具提供存取層。
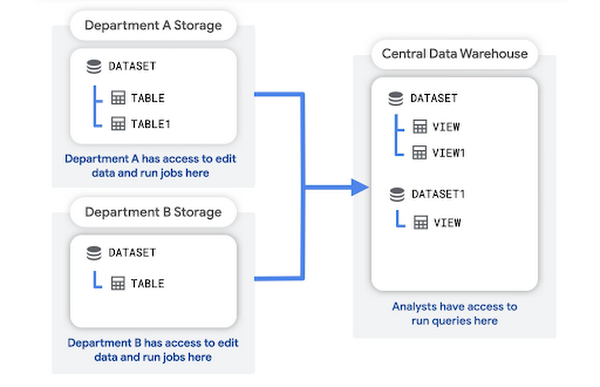
這種結構的優點包括:
- 為每個部門使用不同的專案,可簡化部門層級的資料存取權管理。
- 中央分析團隊有一個專案,可執行分析工作,方便監控查詢。
- 使用者可透過集中式商業智慧工具存取資料,這些資料與原始資料隔離。
- 您可以將 Slot 指派給資料倉儲專案,處理分析師和外部工具的所有查詢。
使用這種結構時,通常會授予下列權限:
- 資料工程師在部門的資料市集獲得 BigQuery 資料編輯者和 BigQuery 工作使用者角色。這些角色可讓他們將資料擷取並轉換至資料市集。
- 在資料倉儲專案中,分析師會獲得 BigQuery 資料編輯者和 BigQuery 工作使用者角色。這些角色可讓他們在資料倉儲中建立匯總檢視畫面,並執行查詢工作。
- 將 BigQuery 連結至商業智慧 (BI) 工具的服務帳戶,會獲得特定資料集的 BigQuery 資料檢視者角色,這些資料集可保留資料湖泊的原始資料,或資料倉儲專案中的轉換資料。
詳情請參閱「基本角色和權限」。
您也可以使用授權檢視畫面和授權使用者定義函式 (UDF) 等安全性功能,向特定使用者提供匯總資料,而不必授予他們在資料市集專案中查看原始資料的權限。
這個專案結構可能會導致資料倉儲專案中出現許多並行查詢。因此,您可能會達到並行查詢上限。如果採用這種結構,建議提高專案的配額限制。此外,也建議您採用以運算資源為基礎的計費方式,購買運算單元集區來執行查詢。