
Ottenere informazioni sul rendimento delle query
Il grafico di esecuzione di una query è una rappresentazione visiva dei passaggi che BigQuery esegue per eseguire la query. Questo documento descrive come utilizzare il grafico di esecuzione delle query per diagnosticare i problemi di prestazioni delle query e per visualizzarne gli approfondimenti.
BigQuery offre prestazioni delle query elevate, ma è anche un sistema distribuito complesso con molti fattori interni ed esterni che possono influire sulla velocità delle query. La natura dichiarativa di SQL può anche nascondere la complessità dell'esecuzione delle query. Ciò significa che quando le tue query vengono eseguite più lentamente del previsto o rispetto alle esecuzioni precedenti, capire cosa è successo può essere difficile.
Il grafico di esecuzione della query fornisce un'interfaccia grafica dinamica per l'ispezione del piano di query e dei dettagli sulle prestazioni della query. Puoi esaminare il grafico di esecuzione delle query per qualsiasi query in esecuzione o completata.
Puoi anche utilizzare il grafico di esecuzione delle query per ottenere informazioni sul rendimento delle query. Gli insight sulle prestazioni offrono suggerimenti secondo il criterio del "best effort" per aiutarti a migliorare le prestazioni delle query. Poiché le prestazioni delle query sono sfaccettate, gli insight sulle prestazioni possono fornire solo un quadro parziale delle prestazioni complessive delle query.
Autorizzazioni obbligatorie
Per utilizzare il grafico di esecuzione delle query, devi disporre delle seguenti autorizzazioni:
bigquery.jobs.getbigquery.jobs.listAll
Queste autorizzazioni sono disponibili tramite i seguenti ruoli IAM (Identity and Access Management) predefiniti di BigQuery:
roles/bigquery.adminroles/bigquery.resourceAdminroles/bigquery.resourceEditorroles/bigquery.resourceViewer
Struttura del grafico di esecuzione
Il grafico di esecuzione della query fornisce una visualizzazione grafica del piano della query nella console. Ogni casella rappresenta una fase del piano di query come le seguenti:
- Input: lettura dei dati da una tabella o selezione di colonne specifiche
- Unione: unione dei dati di due tabelle in base alla condizione
JOIN - Aggregazione: esecuzione di calcoli come
SUM - Ordina: ordinamento dei risultati
Le fasi sono costituite da
passaggi
che descrivono le singole operazioni eseguite da ogni worker all'interno di una fase. Puoi fare clic su una fase per aprirla e visualizzarne i
passaggi. Le fasi includono anche
informazioni relative e assolute sul timing.
I nomi delle fasi riassumono i passaggi eseguiti. Ad esempio, una fase con
join nel nome indica che il passaggio principale della fase è un'operazione JOIN. I nomi delle fasi che terminano con + indicano che
eseguono ulteriori passaggi importanti. Ad esempio, una fase con JOIN+ nel
nome indica che la
fase esegue un'operazione di unione e altri passaggi importanti.
Le linee che collegano le fasi rappresentano lo scambio di dati intermedi tra le fasi. BigQuery archivia i dati intermedi nella memoria di shuffle durante l'esecuzione delle fasi. I numeri sui bordi indicano il numero stimato di righe scambiate tra le fasi. La quota di memoria di shuffling è correlata al numero di slot allocati all'account. Se la quota di shuffle viene superata, la memoria di shuffle può essere riversata sul disco e rallentare drasticamente le prestazioni della query.
Visualizzare gli approfondimenti sul rendimento delle query
Console
Per visualizzare gli approfondimenti sul rendimento delle query:
Apri la pagina BigQuery nella console Google Cloud .
Nel riquadro a sinistra, fai clic su Spazio di esplorazione:

Se non vedi il riquadro a sinistra, fai clic su Espandi riquadro a sinistra per aprirlo.
Nel riquadro Explorer, fai clic su Cronologia dei job.
Fai clic su Cronologia personale o Cronologia del progetto.
Nell'elenco dei job, identifica il job di query che ti interessa. Fai clic su Azioni e scegli Visualizza lavoro nell'editor.
Seleziona la scheda Grafico di esecuzione per visualizzare una rappresentazione grafica di ogni fase della query:
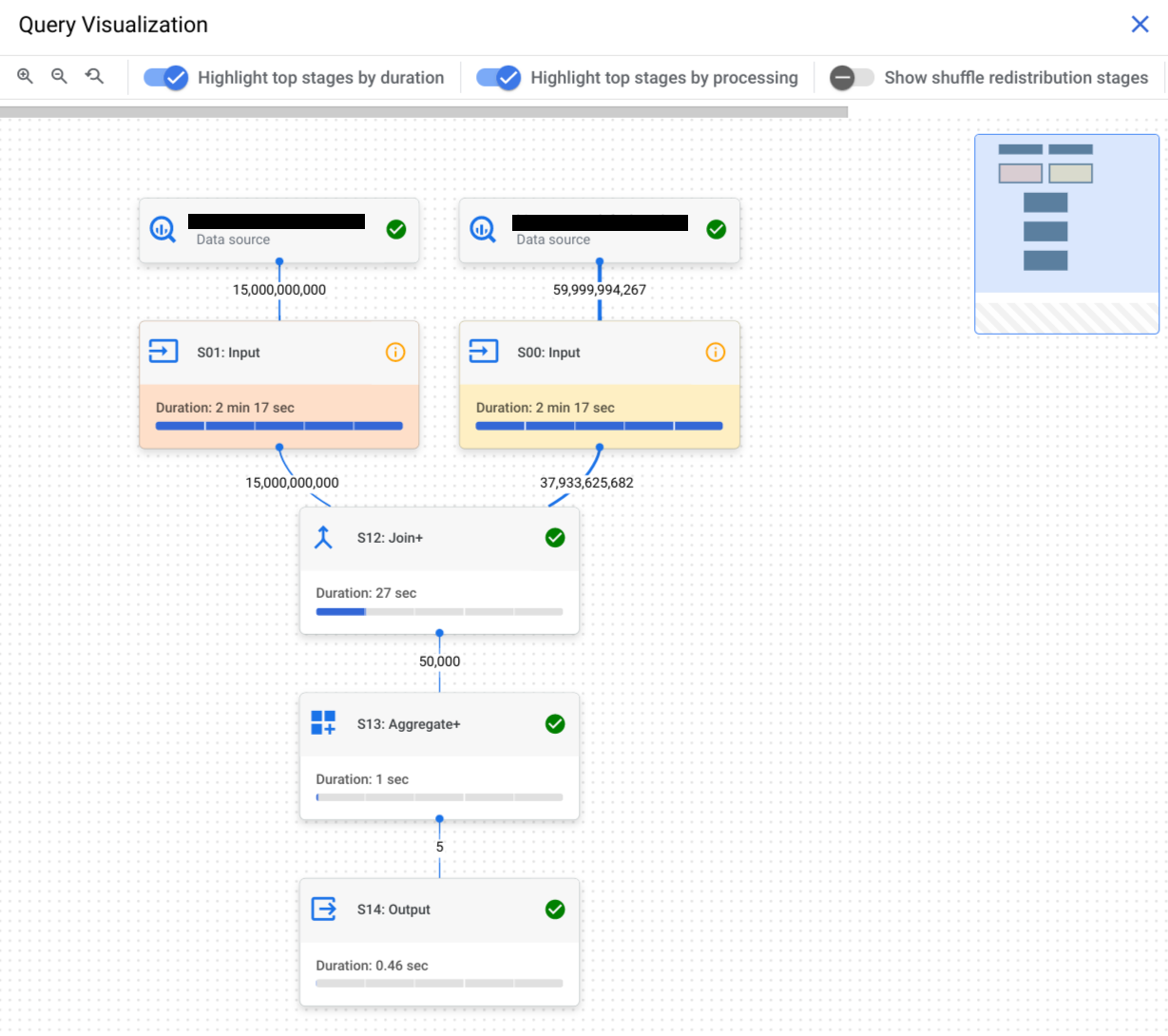
Per determinare se una fase della query ha informazioni sul rendimento, osserva l'icona visualizzata. Le fasi con un'icona informativa hanno approfondimenti sul rendimento. Le fasi con un'icona di controllo non lo fanno.
Fai clic su una fase per aprire il riquadro dei dettagli della fase, in cui puoi visualizzare le seguenti informazioni:
- Informazioni sul piano di query per la fase.
- I passaggi eseguiti nella fase.
- Eventuali informazioni sul rendimento applicabili.
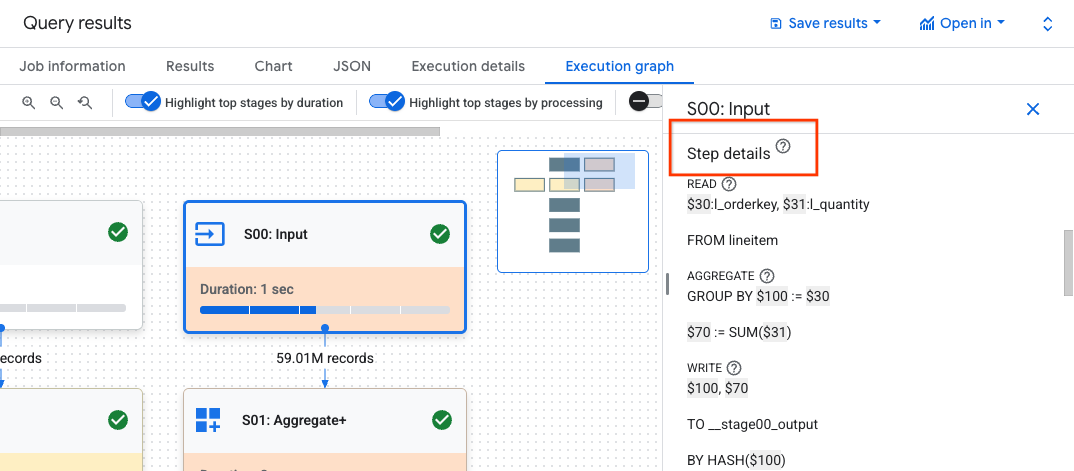
(Facoltativo) Se stai esaminando una query in esecuzione, fai clic su Sincronizza per aggiornare il grafico di esecuzione in modo che rifletta lo stato attuale della query.

(Facoltativo) Per evidenziare le fasi principali in base alla durata della fase nel grafico, fai clic su Evidenzia le fasi principali per durata.

(Facoltativo) Per evidenziare le fasi principali in base al tempo di slot utilizzato nel grafico, fai clic su Evidenzia le fasi principali per elaborazione.

(Facoltativo) Per includere le fasi di ridistribuzione dello shuffling nel grafico, fai clic su Mostra le fasi di ridistribuzione dello shuffling.

Utilizza questa opzione per mostrare le fasi di ridistribuzione e unione nascoste nel grafico di esecuzione predefinito.
Le fasi di ripartizione e unione vengono introdotte durante l'esecuzione della query e vengono utilizzate per migliorare la distribuzione dei dati tra i worker che elaborano la query. Poiché queste fasi non sono correlate al testo della query, vengono nascoste per semplificare il piano di query visualizzato.
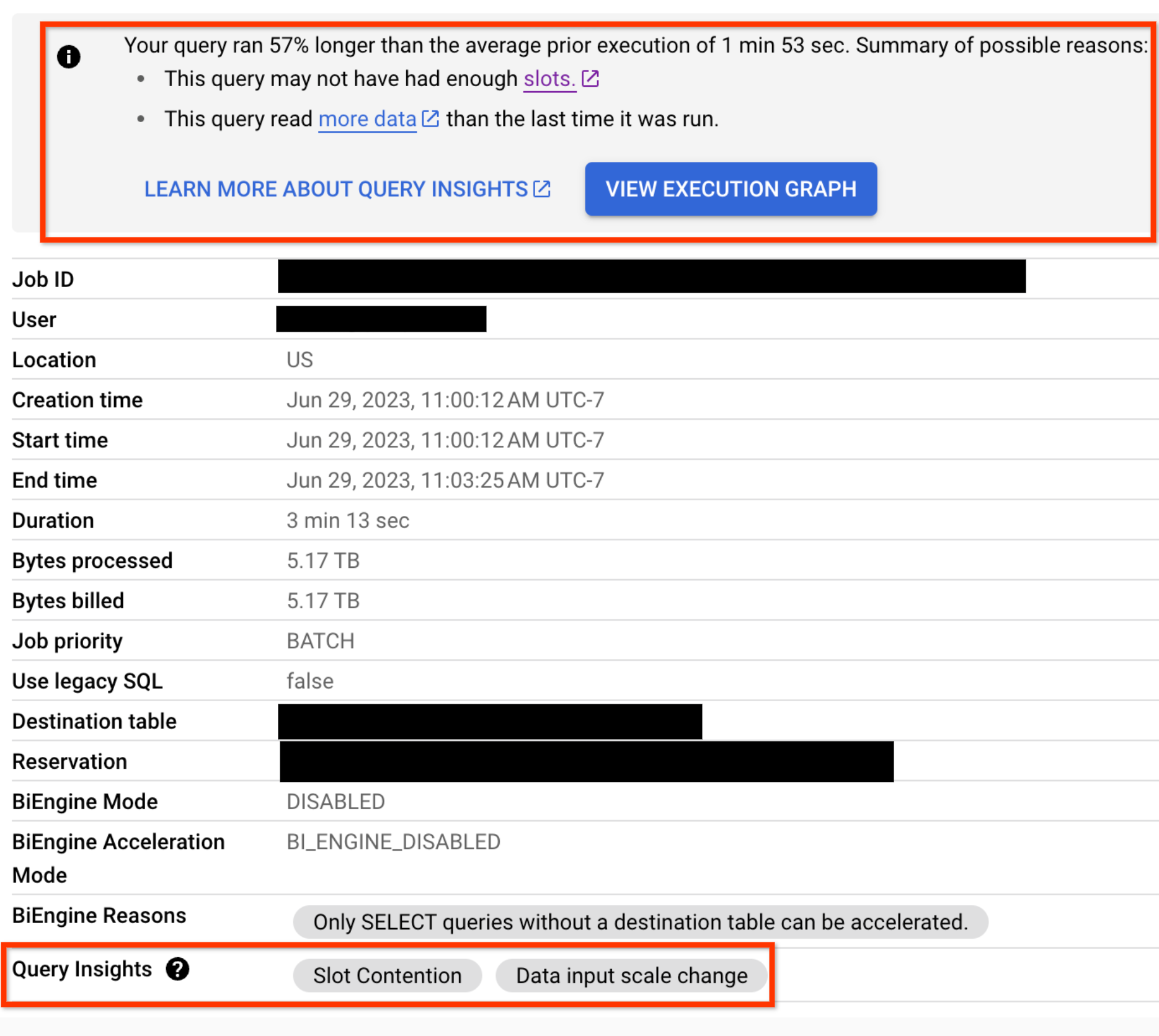
Per qualsiasi query che presenta problemi di regressione delle prestazioni, gli approfondimenti sul rendimento vengono visualizzati anche nella scheda Informazioni sul job per la query:
SQL
Nella console Google Cloud , vai alla pagina BigQuery.
Nell'editor di query, inserisci la seguente istruzione:
SELECT `bigquery-public-data`.persistent_udfs.job_url( project_id || ':us.' || job_id) AS job_url, query_info.performance_insights FROM `region-REGION_NAME`.INFORMATION_SCHEMA.JOBS_BY_PROJECT WHERE DATE(creation_time) >= CURRENT_DATE - 30 -- scan 30 days of query history AND job_type = 'QUERY' AND state = 'DONE' AND error_result IS NULL AND statement_type != 'SCRIPT' AND EXISTS ( -- Only include queries which had performance insights SELECT 1 FROM UNNEST( query_info.performance_insights.stage_performance_standalone_insights ) WHERE slot_contention OR insufficient_shuffle_quota OR bi_engine_reasons IS NOT NULL OR high_cardinality_joins IS NOT NULL OR partition_skew IS NOT NULL UNION ALL SELECT 1 FROM UNNEST( query_info.performance_insights.stage_performance_change_insights ) WHERE input_data_change.records_read_diff_percentage IS NOT NULL );
Fai clic su Esegui.
Per saperne di più su come eseguire le query, consulta Eseguire una query interattiva.
API
Puoi ottenere approfondimenti sul rendimento delle query in un formato non grafico chiamando il metodo API jobs.list ed esaminando le informazioni JobStatistics2 restituite.
Interpretare gli approfondimenti sul rendimento delle query
Utilizza questa sezione per scoprire di più sul significato degli insight sul rendimento e su come risolverli.
Gli approfondimenti sul rendimento sono destinati a due segmenti di pubblico:
Analisti: eseguono query in un progetto. Ti interessa scoprire perché una query che hai eseguito in precedenza viene eseguita in modo inaspettato più lentamente e ricevere suggerimenti su come migliorare il rendimento di una query. Disponi delle autorizzazioni descritte in Autorizzazioni richieste.
Amministratori di data lake o data warehouse: gestisci le risorse e le prenotazioni BigQuery della tua organizzazione. Disponi delle autorizzazioni associate al ruolo Amministratore BigQuery.
Ciascuna delle seguenti sezioni fornisce indicazioni su cosa puoi fare per risolvere un approfondimento sul rendimento che ricevi, in base al ruolo che ricopri.
Contesa slot
Quando esegui una query, BigQuery tenta di suddividere il lavoro necessario per la query in attività. Un'attività è una singola porzione di dati che viene inserita in una fase e da questa estratta. Un singolo slot preleva un'attività ed esegue quella porzione di dati per la fase. Idealmente, gli slot di BigQuery eseguono queste attività in parallelo per ottenere prestazioni elevate. La contesa degli slot si verifica quando la query ha molte attività pronte per l'esecuzione, ma BigQuery non riesce a ottenere slot disponibili sufficienti per eseguirle.
Cosa fare se sei un analista
Riduci i dati che elabori nella query seguendo le indicazioni riportate in Ridurre i dati elaborati nelle query.
Cosa fare se sei un amministratore
Aumenta la disponibilità di slot o diminuisci l'utilizzo degli slot eseguendo le seguenti azioni:
- Se utilizzi i prezzi on demand di BigQuery, le tue query utilizzano un pool condiviso di slot. Valuta la possibilità di passare ai prezzi dell'analisi basati sulla capacità acquistando invece prenotazioni. Le prenotazioni ti consentono di riservare slot dedicati alle query della tua organizzazione.
Se utilizzi le prenotazioni BigQuery, assicurati che ci siano slot sufficienti nella prenotazione assegnata al progetto che eseguiva la query. La prenotazione potrebbe non avere slot sufficienti in questi scenari:
- Esistono altri job che utilizzano gli slot di prenotazione. Puoi utilizzare i grafici delle risorse amministrative per vedere come la tua organizzazione utilizza la prenotazione.
- La prenotazione non dispone di slot assegnati sufficienti per eseguire le query abbastanza velocemente. Puoi utilizzare lo strumento di stima degli slot per ottenere una stima delle dimensioni delle prenotazioni necessarie per elaborare in modo efficiente le attività delle query.
Per risolvere il problema, puoi provare una delle seguenti soluzioni:
- Aggiungi altri slot (slot di base o slot di prenotazione massimi) a questa prenotazione.
- Crea una prenotazione aggiuntiva e assegnala al progetto che esegue la query.
- Distribuisci le query che richiedono molte risorse nel tempo all'interno di una prenotazione o in prenotazioni diverse.
Assicurati che le tabelle su cui esegui query siano in cluster. Il clustering consente di garantire che BigQuery possa leggere rapidamente le colonne con dati correlati.
Assicurati che le tabelle su cui esegui query siano partizionate. Per le tabelle non partizionate, BigQuery legge l'intera tabella. Il partizionamento delle tabelle ti consente di eseguire query solo sul sottoinsieme delle tabelle che ti interessano.
Quota di shuffling insufficiente
Prima di eseguire la query, BigQuery divide la logica della query in fasi. Gli slot BigQuery eseguono le attività per ogni fase. Quando uno slot completa l'esecuzione delle attività di una fase, memorizza i risultati intermedi in shuffle. Le fasi successive della query leggono i dati dallo shuffle per continuare l'esecuzione della query. La quota di shuffling insufficiente si verifica quando hai più dati da scrivere in shuffle rispetto alla capacità di shuffle disponibile.
Cosa fare se sei un analista
Analogamente alla contesa degli slot, la riduzione della quantità di dati elaborati dalla query potrebbe ridurre l'utilizzo di shuffle. Per farlo, segui le indicazioni riportate in Ridurre i dati elaborati nelle query.
Determinate operazioni in SQL tendono a fare un uso più esteso di shuffle, in particolare le operazioni JOIN e le clausole GROUP BY.
Ove possibile, la riduzione della quantità di dati in queste operazioni potrebbe ridurre l'utilizzo di shuffle.
Cosa fare se sei un amministratore
Riduci la contesa della quota di shuffling eseguendo le seguenti azioni:
- Analogamente alla contesa degli slot, se utilizzi i prezzi on demand di BigQuery, le tue query utilizzano un pool di slot condiviso. Valuta la possibilità di passare ai prezzi dell'analisi basati sulla capacità acquistando invece prenotazioni. Le prenotazioni ti offrono slot dedicati e capacità di shuffling per le query dei tuoi progetti.
Se utilizzi le prenotazioni BigQuery, gli slot sono dotati di capacità di shuffling dedicata. Se la prenotazione esegue alcune query che utilizzano ampiamente lo shuffle, ciò potrebbe causare una capacità di shuffle insufficiente per altre query eseguite in parallelo. Puoi identificare i job che utilizzano in modo intensivo la capacità di shuffling eseguendo una query sulla colonna
period_shuffle_ram_usage_rationella visualizzazioneINFORMATION_SCHEMA.JOBS_TIMELINE.Per risolvere il problema, puoi provare una o più delle seguenti soluzioni:
- Aggiungi altri posti alla prenotazione.
- Crea una prenotazione aggiuntiva e assegnala al progetto che esegue la query.
- Distribuisci le query che richiedono un utilizzo intensivo dello shuffling nel tempo all'interno di una prenotazione o in prenotazioni diverse.
Per ulteriori informazioni sulla risoluzione dei problemi, consulta Errori relativi al limite di dimensioni dello shuffle nella pagina Risoluzione dei problemi di BigQuery.
Modifica della scala di input dei dati
Questo insight sul rendimento indica che la query legge almeno il 50% di dati in più per una determinata tabella di input rispetto all'ultima volta che è stata eseguita. Puoi utilizzare la cronologia delle modifiche delle tabelle per verificare se le dimensioni di una delle tabelle utilizzate nella query sono aumentate di recente.
Cosa fare se sei un analista
Riduci i dati che elabori nella query seguendo le indicazioni riportate in Ridurre i dati elaborati nelle query.
Join con cardinalità elevata
Quando una query contiene un join con chiavi non univoche su entrambi i lati del join, le dimensioni della tabella di output possono essere notevolmente maggiori di quelle di una delle tabelle di input. Questo approfondimento indica che il rapporto tra le righe di output e le righe di input è elevato e offre informazioni su questi conteggi delle righe.
Cosa fare se sei un analista
Controlla le condizioni di join per verificare che l'aumento delle dimensioni della
tabella di output sia previsto. Evita di utilizzare
cross join.
Se devi utilizzare un cross join, prova a utilizzare una clausola GROUP BY per pre-aggregare
i risultati o utilizza una funzione finestra. Per saperne di più, consulta la sezione
Riduci i dati prima di utilizzare un JOIN.
Distorsione della partizione
Per fornire un feedback o richiedere assistenza per questa funzionalità, invia un'email a
bq-query-inspector-feedback@google.com.
La distribuzione distorta dei dati può causare l'esecuzione lenta delle query. Quando viene eseguita una query, BigQuery suddivide i dati in piccole partizioni per l'elaborazione parallela. Lo sbilanciamento si verifica quando i dati sono distribuiti in modo non uniforme tra queste partizioni, spesso a causa di valori che si verificano frequentemente nelle chiavi di join o di raggruppamento, rendendo alcune partizioni significativamente più grandi di altre. Poiché un singolo slot elabora un'intera partizione e non può condividere il lavoro, una partizione sovradimensionata può rallentare l'elaborazione, causare errori di "risorse superate" e, in casi estremi, arrestare lo slot.
Mentre esegui un'operazione JOIN, BigQuery partiziona i dati
sui lati sinistro e destro del join in base alle chiavi di join. Se una partizione
è troppo grande, BigQuery tenta di ribilanciare i dati. Se la
distorsione è troppo grave per essere completamente ribilanciata, viene aggiunto un approfondimento sulla distorsione della partizione
alla fase JOIN nel grafico di esecuzione.
Identificare lo sbilanciamento delle partizioni
Utilizza la scheda Grafico di esecuzione in BigQuery Studio per scoprire in quale fase della query si verifica la distorsione della partizione. L'approfondimento viene contrassegnato sul palco. Dai dettagli della fase, puoi determinare la parte pertinente del testo della query e le tabelle in fase di elaborazione. Per saperne di più, vedi Comprendere i passaggi con il testo della query.
Esempio
La seguente query unisce le informazioni sul repository a quelle sui file. Lo sbilanciamento può verificarsi se alcuni repository contengono molti più file rispetto ad altri.
SELECT r.repo_name, COUNT(f.path) AS file_count
FROM `bigquery-public-data.github_repos.sample_repos` AS r
JOIN `bigquery-public-data.github_repos.sample_files` AS f
ON r.repo_name = f.repo_name
WHERE r.watch_count > 10
GROUP BY r.repo_name
La chiave di join è repo_name. Nella tabella sample_repos, repo_name
deve essere univoco. Tuttavia, nella tabella sample_files, repo_name può
essere visualizzato più volte. Se alcuni valori di repo_name vengono visualizzati in modo sproporzionato
frequentemente in sample_files, si crea una distorsione dei dati.
Per verificare se esiste una distorsione dei dati, analizza la distribuzione della chiave di join nella
tabella più grande (sample_files in questo caso). Esegui la seguente query per valutare
la distribuzione di repo_name:
SELECT repo_name, COUNT(*) AS occurrences
FROM `bigquery-public-data.github_repos.sample_files`
GROUP BY repo_name
ORDER BY occurrences DESC
Per tabelle molto grandi, utilizza la funzione APPROX_TOP_COUNT
per stimare in modo efficiente i valori più frequenti.
SELECT APPROX_TOP_COUNT(repo_name, 100)
FROM `bigquery-public-data.github_repos.sample_files`
Se i conteggi per i valori principali sono ordini di grandezza superiori rispetto agli altri, è presente una distorsione dei dati.
Ridurre il disallineamento delle partizioni
Puoi utilizzare le seguenti strategie per risolvere il problema della distorsione della partizione:
- Filtra i dati in anticipo. Riduci la quantità di dati elaborati
applicando i filtri il prima possibile nella query. In questo modo è possibile ridurre il numero di righe associate a chiavi distorte prima che raggiungano operazioni come
JOINoGROUP BY. Dividi la query per isolare i tasti storti. Se la distorsione è causata da alcuni valori chiave specifici, simili al campo
repo_namenell'esempio precedente, valuta la possibilità di dividere la query. Elabora i dati per le chiavi distorte separatamente dal resto dei dati, quindi combina i risultati utilizzandoUNION ALL.Esempio: isolamento di una chiave utilizzata di frequente.
-- Query for the skewed key SELECT r.repo_name, COUNT(f.path) AS file_count FROM `bigquery-public-data.github_repos.sample_repos` AS r JOIN `bigquery-public-data.github_repos.sample_files` AS f ON r.repo_name = f.repo_name WHERE r.watch_count > 10 AND r.repo_name = 'popular_repo' GROUP BY r.repo_name UNION ALL -- Query for all other keys SELECT r.repo_name, COUNT(f.path) AS file_count FROM `bigquery-public-data.github_repos.sample_repos` AS r JOIN `bigquery-public-data.github_repos.sample_files` AS f ON r.repo_name = f.repo_name WHERE r.watch_count > 10 AND r.repo_name != 'popular_repo' GROUP BY r.repo_nameGestione di
NULLe valori predefiniti: una causa comune di distorsione è un numero elevato di righe con valoriNULLo stringhe vuote nelle colonne chiave. Se non hai bisogno di queste righe per l'analisi, filtrale utilizzando una clausolaWHEREprima diJOINoGROUP BY.Riordina operazioni: nelle query con più join, l'ordine può essere importante. Se possibile, esegui i join che riducono significativamente il numero di righe all'inizio della query.
Utilizza funzioni approssimative: per le aggregazioni su dati distorti, valuta se un risultato approssimativo è accettabile. Funzioni come
APPROX_COUNT_DISTINCTsono più tolleranti alla distorsione dei dati rispetto a funzioni esatte comeCOUNT(DISTINCT).
Interpretare le informazioni sulla fase della query
Oltre a utilizzare le informazioni sul rendimento delle query, puoi anche utilizzare le seguenti linee guida quando esamini i dettagli della fase di query per determinare se si è verificato un problema con una query:
- Se il valore di Attesa ms per una o più fasi è elevato rispetto alle esecuzioni precedenti della query:
- Verifica di avere a disposizione slot sufficienti per ospitare il tuo carico di lavoro. In caso contrario, bilancia il carico quando esegui query che richiedono molte risorse in modo che non siano in concorrenza tra loro.
- Se il valore Attesa ms è superiore a quello di una sola fase, esamina la fase precedente per verificare se è stato introdotto un collo di bottiglia in quella fase. Modifiche sostanziali ai dati o allo schema delle tabelle coinvolte nella query potrebbero influire sulle prestazioni della query.
- Se il valore di Byte di output di shuffling per una fase è elevato rispetto alle esecuzioni precedenti della query o rispetto a una fase precedente, valuta i passaggi elaborati in quella fase per verificare se qualcuno crea quantità di dati inaspettatamente grandi. Una causa comune è quando un passaggio elabora un
INNER JOINin cui sono presenti chiavi duplicate su entrambi i lati del join. Questa operazione può restituire una quantità di dati inaspettatamente elevata. - Utilizza il grafico di esecuzione per esaminare le fasi principali in base a durata ed elaborazione. Considera la quantità di dati che producono e se è proporzionata alle dimensioni delle tabelle a cui viene fatto riferimento nella query. In caso contrario, esamina i passaggi di queste fasi per verificare se qualcuno di questi potrebbe produrre una quantità imprevista di dati intermedi.
Passaggi successivi
- Consulta le linee guida per l'ottimizzazione delle query per suggerimenti su come migliorare le prestazioni delle query.