
כלים לניתוח פרוגרמטי
במאמר הזה מוסבר על כמה דרכים לכתוב ולהריץ קוד כדי לנתח נתונים שמנוהלים ב-BigQuery.
למרות ש-SQL היא שפת שאילתות עוצמתית, שפות תכנות כמו Python, Java או R מספקות תחביר ומגוון רחב של פונקציות סטטיסטיות מובנות, שאנליסטים של נתונים עשויים למצוא אותן יותר מובנות וקלות לתפעול עבור סוגים מסוימים של ניתוח נתונים.
באופן דומה, למרות שגיליונות אלקטרוניים נמצאים בשימוש נרחב, סביבות תכנות אחרות כמו מחברות יכולות לפעמים לספק סביבה גמישה יותר לביצוע ניתוח נתונים מורכב ולחיפוש נתונים.
קובצי notebook של Colab Enterprise
אתם יכולים להשתמש במחברות Colab Enterprise ב-BigQuery כדי להשלים תהליכי עבודה של ניתוח ושל למידת מכונה (ML) באמצעות SQL, Python וחבילות וממשקי API נפוצים אחרים. תיקיות Notebook מציעות שיתוף פעולה וניהול משופרים עם האפשרויות הבאות:
- משתפים מחברות עם משתמשים וקבוצות ספציפיים באמצעות ניהול זהויות והרשאות גישה (IAM).
- בודקים את היסטוריית הגרסאות של ה-Notebook.
- חזרה לגרסאות קודמות של המחברת או יצירת ענף מהן.
מחברות הן נכסי קוד של BigQuery Studio שמבוססים על Dataform, אבל המחברות לא מוצגות ב-Dataform. שאילתות שמורות הן גם נכסי קוד. כל נכסי הקוד מאוחסנים באזור שמוגדר כברירת מחדל. עדכון אזור ברירת המחדל משנה את האזור של כל נכסי הקוד שנוצרו אחרי העדכון.
היכולות של מחברת זמינות רק במסוף Google Cloud .
המחברות ב-BigQuery מציעות את היתרונות הבאים:
- שילוב חלק עם Python: אפשר להשתמש ב-BigQuery DataFrames API בלי לבצע הגדרות נוספות.
- פיתוח מבוסס-AI: שימוש ב-AI גנרטיבי של Gemini לפיתוח קוד בעזרת AI.
- תכונות מוכרות של עורך: אפשר להשתמש בהשלמה אוטומטית של SQL, בדומה לעורך ה-SQL של BigQuery.
- המחשות משולבות: אפשר להשתמש בהמחשות אינטראקטיביות של DataFrame או בספריות כמו matplotlib ו-seaborn כדי להמחיש נתונים ישירות בתהליך העבודה.
- אינטראופרביליות של SQL ו-Python: הפעלת SQL בתאים שמפנים למשתני Python.
כדי להתחיל לעבוד עם נוטבוקים, אפשר להשתמש בתבניות מגלריית הנוטבוקים. מידע נוסף זמין במאמר יצירת נוטבוק באמצעות גלריית הנוטבוקים.
BigQuery DataFrames
BigQuery DataFrames היא קבוצה של ספריות Python בקוד פתוח שמאפשרות לכם לנצל את היתרונות של עיבוד נתונים ב-BigQuery באמצעות ממשקי API מוכרים של Python. חבילת BigQuery DataFrames מטמיעה את ממשקי ה-API של pandas ו-scikit-learn על ידי העברת העיבוד ל-BigQuery באמצעות המרה ל-SQL. העיצוב הזה מאפשר לכם להשתמש ב-BigQuery כדי לבחון ולעבד טרה-בייט של נתונים, וגם לאמן מודלים של למידת מכונה, והכול באמצעות ממשקי API של Python.
היתרונות של BigQuery DataFrames:
- יותר מ-750 ממשקי API של pandas ו-scikit-learn הוטמעו באמצעות המרה שקופה של SQL לממשקי BigQuery ו-BigQuery ML API.
- ביצוע מושהה של שאילתות לשיפור הביצועים.
- הרחבת טרנספורמציות של נתונים באמצעות פונקציות Python שמוגדרות על ידי המשתמש, כדי לאפשר לכם לעבד נתונים בענן. הפונקציות האלה נפרסות אוטומטית כפונקציות מרוחקות של BigQuery.
- שילוב עם Gemini Enterprise Agent Platform כדי לאפשר לכם להשתמש במודלים של Gemini ליצירת טקסט.
פתרונות אחרים לניתוח נתונים באופן פרוגרמטי
ב-BigQuery זמינים גם הפתרונות הבאים לניתוח נתונים באופן פרוגרמטי:
מחברות Jupyter
Jupyter היא אפליקציה מבוססת-אינטרנט בקוד פתוח לפרסום מחברות שמכילות קוד פעיל, תיאורים טקסטואליים והדמיות. מדעני נתונים, מומחים ללמידת מכונה וסטודנטים משתמשים בפלטפורמה הזו בדרך כלל למשימות כמו ניקוי נתונים וטרנספורמציה שלהם, סימולציה מספרית, מודלים סטטיסטיים, הדמיה של נתונים ולמידת מכונה.
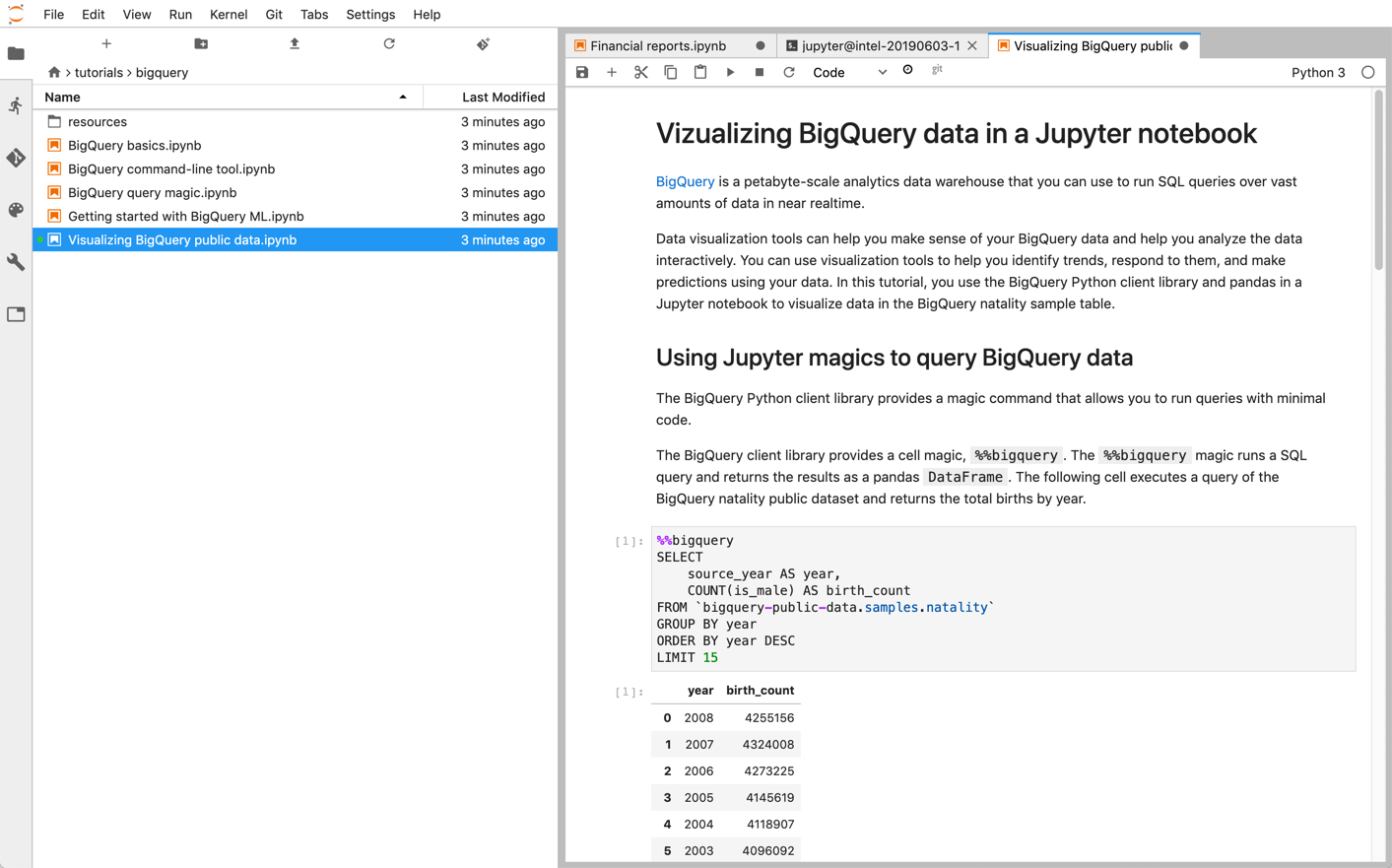
מחברות Jupyter Notebooks מבוססות על ליבת IPython, מעטפת אינטראקטיבית רבת עוצמה שיכולה לקיים אינטראקציה ישירה עם BigQuery באמצעות IPython Magics for BigQuery. לחלופין, אפשר לגשת ל-BigQuery ממופעי מחברות Jupyter על ידי התקנה של אחת מספריות הלקוח של BigQuery שזמינות. אפשר להציג נתונים של BigQuery GIS באמצעות מחברות Jupyter דרך התוסף GeoJSON. פרטים נוספים על השילוב עם BigQuery זמינים במדריך Visualizing BigQuery data in a Jupyter notebook.
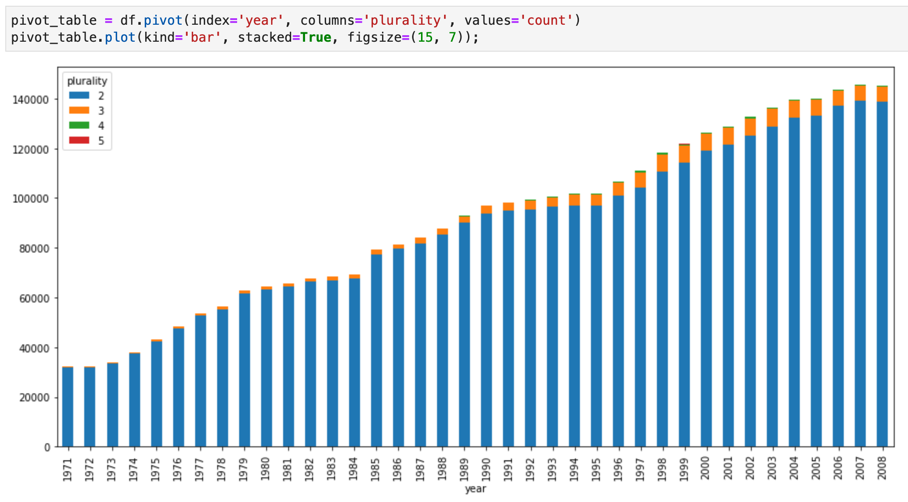
JupyterLab הוא ממשק משתמש מבוסס-אינטרנט לניהול מסמכים ופעילויות כמו מחברות Jupyter, עורכי טקסט, מסופים ורכיבים בהתאמה אישית. ב-JupyterLab, אפשר לסדר כמה מסמכים ופעילויות זה לצד זה באזור העבודה באמצעות כרטיסיות וחלונות מפוצלים.
אפשר לפרוס סביבות Jupyter notebooks ו-JupyterLab ב-Google Cloud באמצעות אחד מהמוצרים הבאים:
- מכונות Vertex AI Workbench, שירות שמציע סביבת JupyterLab משולבת שבה מפתחי למידת מכונה ומדעני נתונים יכולים להשתמש בחלק מה-frameworks העדכניים ביותר של מדעי נתונים ולמידת מכונה. Vertex AI Workbench משולב עם מוצרי נתונים אחרים כמו BigQuery, כך שקל לעבור מהטמעת נתונים לעיבוד מקדים ולבדיקה, ובסופו של דבר לאימון מודלים ולפריסה. Google Cloud מידע נוסף על מכונות של Vertex AI Workbench
- Managed Service for Apache Spark הוא שירות מהיר, קל לשימוש ומנוהל במלואו להפעלת אשכולות של Apache Spark ו-Apache Hadoop בצורה פשוטה וחסכונית. אפשר להתקין מחברות Jupyter ו-JupyterLab באשכול Managed Service for Apache Spark באמצעות רכיב Jupyter האופציונלי. הרכיב מספק ליבת Python להרצת קוד PySpark. כברירת מחדל, שירות Managed Service for Apache Spark מגדיר אוטומטית את המחברות כך שיישלחו ל-Cloud Storage, וכך קובצי המחברות יהיו נגישים גם לאשכולות אחרים. כשמעבירים מחברות קיימות אל Managed Service for Apache Spark, צריך לוודא שהתלות של המחברות נכללת בגרסאות הנתמכות של Managed Service for Apache Spark. אם אתם צריכים להתקין תוכנה בהתאמה אישית, כדאי ליצור תמונה משלכם של Managed Service for Apache Spark, לכתוב פעולות אתחול משלכם או לציין דרישות לחבילות Python בהתאמה אישית. כדי להתחיל, אפשר לעיין במדריך בנושא התקנה והפעלה של Jupyter Notebook באשכול Managed Service for Apache Spark.
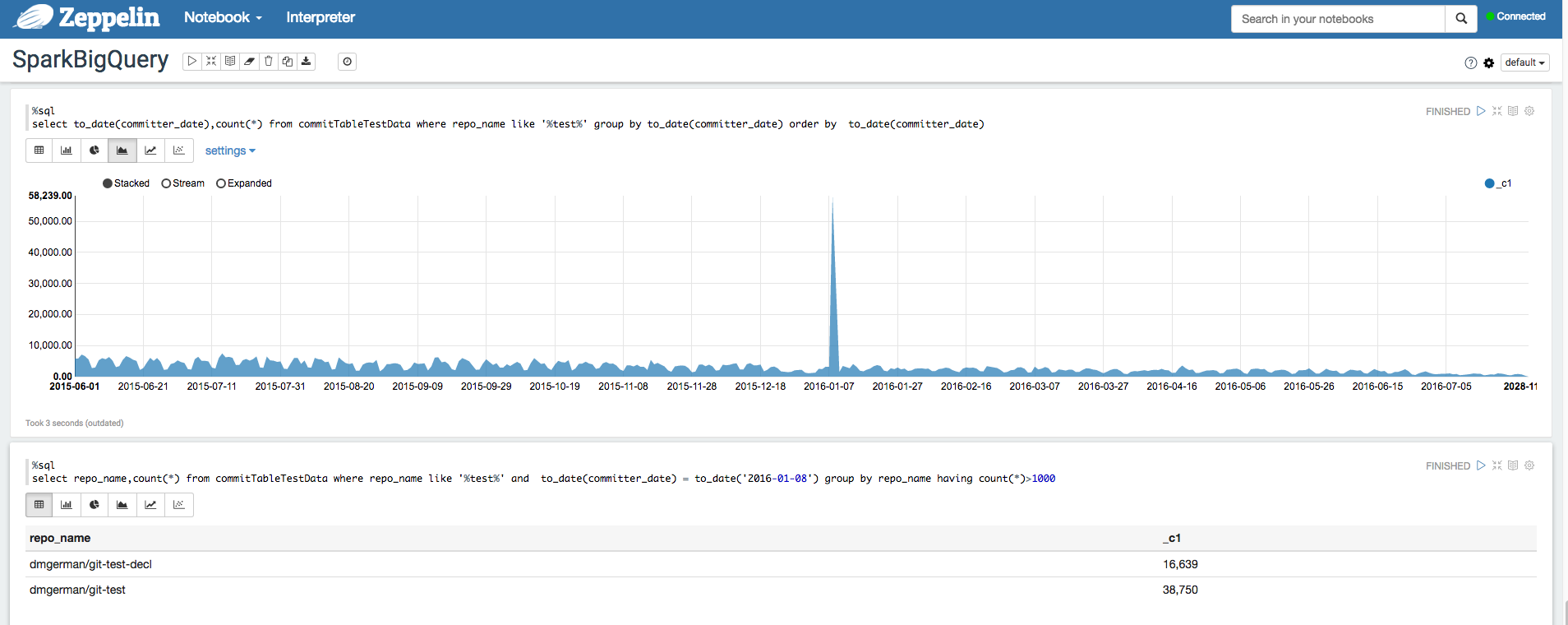
Apache Zeppelin
Apache Zeppelin
הוא פרויקט קוד פתוח שמציע מחברות מבוססות-אינטרנט לניתוח נתונים.
אפשר לפרוס מופע של Apache Zeppelin ב-Managed Service for Apache Spark על ידי התקנת רכיב Zeppelin האופציונלי.
כברירת מחדל, מחברות נשמרות ב-Cloud Storage בקטגוריית האחסון הזמני של Managed Service for Apache Spark, שמוגדרת על ידי המשתמש או נוצרת אוטומטית כשיוצרים את האשכול. אפשר לשנות את המיקום של המחברת
על ידי הוספת המאפיין zeppelin:zeppelin.notebook.gcs.dir כשיוצרים את האשכול. מידע נוסף על התקנה והגדרה של Apache Zeppelin זמין במדריך לרכיב Zeppelin.
לדוגמה, אפשר לעיין במאמר בנושא ניתוח מערכי נתונים ב-BigQuery באמצעות BigQuery Interpreter ל-Apache Zeppelin.
Apache Hadoop, Apache Spark ו-Apache Hive
כחלק מההעברה של צינור עיבוד הנתונים שלכם, יכול להיות שתרצו להעביר משימות מדור קודם של Apache Hadoop, Apache Spark או Apache Hive שצריכות לעבד נתונים ישירות ממחסן הנתונים שלכם. לדוגמה, אפשר לחלץ תכונות לעומסי העבודה של למידת מכונה.
Managed Service for Apache Spark מאפשר לכם לפרוס אשכולות של Hadoop ו-Spark שמנוהלים באופן מלא, בצורה יעילה וחסכונית. Managed Service for Apache Spark משתלב עם מחברים של BigQuery בקוד פתוח. המחברים האלה משתמשים ב-BigQuery Storage API, שמעביר נתונים במקביל ישירות מ-BigQuery דרך gRPC.
כשמעבירים את עומסי העבודה הקיימים של Hadoop ו-Spark אל Managed Service for Apache Spark, אפשר לבדוק אם התלות של עומסי העבודה מכוסה על ידי הגרסאות הנתמכות של Managed Service for Apache Spark. אם אתם צריכים להתקין תוכנה בהתאמה אישית, כדאי לשקול ליצור תמונה משלכם של Managed Service for Apache Spark, לכתוב פעולות אתחול משלכם או לציין דרישות לחבילות Python בהתאמה אישית.
כדי להתחיל, אפשר לעיין במדריכים למתחילים בנושא Managed Service for Apache Spark ובדוגמאות קוד של BigQuery Connector.
Apache Beam
Apache Beam היא מסגרת קוד פתוח שמספקת קבוצה עשירה של פרימיטיבים של חלונות וניתוח סשנים, וגם מערכת אקולוגית של מחברים למקורות וליעדים, כולל מחבר ל-BigQuery. Apache Beam מאפשרת לכם לשנות ולהעשיר נתונים גם במצב סטרימינג (בזמן אמת) וגם במצב אצווה (היסטורי) עם אמינות וביטוי שווים.
Dataflow הוא שירות שמנוהל במלואו להרצת משימות של Apache Beam בקנה מידה גדול. הגישה של Dataflow ללא שרתים (serverless) מסירה את התקורה התפעולית, כי הביצועים, ההתאמה לעומס, הזמינות, האבטחה והתאימות מטופלים באופן אוטומטי. כך אתם יכולים להתמקד בתכנות במקום בניהול של אשכולות שרתים.
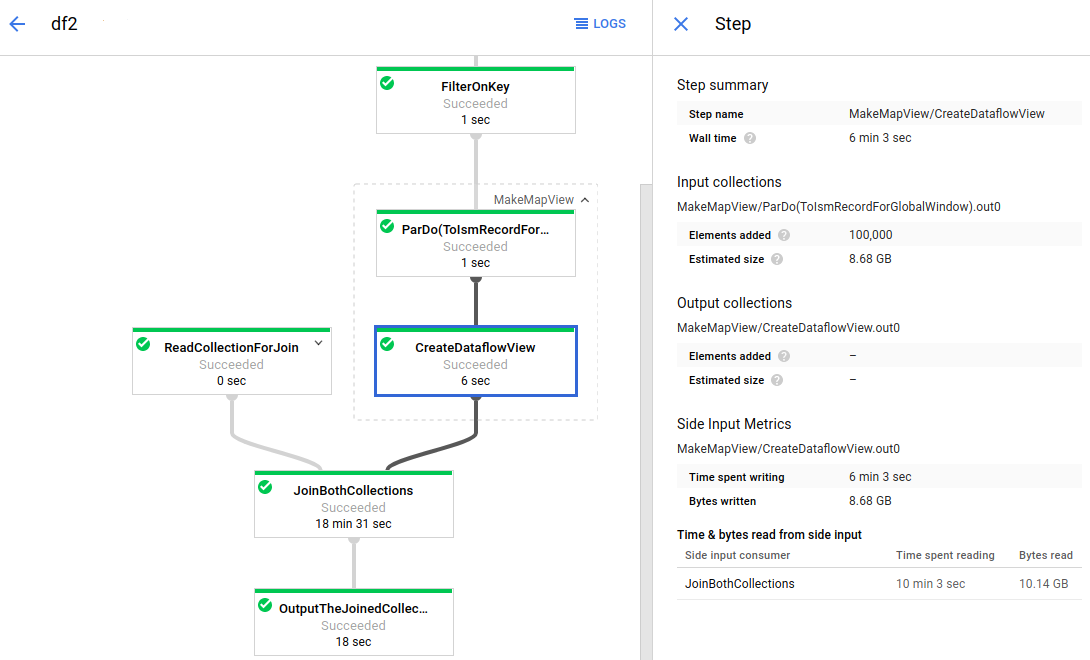
יש כמה דרכים לשלוח משימות Dataflow, למשל דרך ממשק שורת הפקודה, דרך Java SDK או דרך Python SDK.
אם רוצים להעביר את השאילתות והצינורות של הנתונים ממסגרות אחרות אל Apache Beam ו-Dataflow, אפשר לקרוא על מודל התכנות של Apache Beam ולעיין במסמכי התיעוד הרשמיים של Dataflow.
משאבים אחרים
BigQuery מציע מגוון רחב של ספריות לקוח בשפות תכנות שונות, כמו Java, Go, Python, JavaScript, PHP ו-Ruby. חלק ממסגרות הניתוח של הנתונים, כמו pandas, מספקות תוספים שמתקשרים ישירות עם BigQuery. כדי לראות דוגמאות מעשיות, אפשר לעיין במדריך הדמיה של נתוני BigQuery במחברת Jupyter.
לבסוף, אם אתם מעדיפים לכתוב תוכניות בסביבת מעטפת, אתם יכולים להשתמש בכלי שורת הפקודה של BigQuery.