
במדריך הזה תשתמשו במודל רגרסיה לוגיסטית בינארי ב-BigQuery ML כדי לחזות את טווח ההכנסה של אנשים על סמך נתונים דמוגרפיים. מודל רגרסיה לוגיסטית בינארית מנבא אם ערך מסוים שייך לאחת משתי קטגוריות. במקרה הזה, המודל מנבא אם ההכנסה השנתית של אדם מסוים גבוהה מ-50,000 $או נמוכה ממנה.
במדריך הזה נעשה שימוש במערך הנתונים bigquery-public-data.ml_datasets.census_adult_income. קבוצת הנתונים הזו מכילה מידע דמוגרפי ומידע על הכנסות של תושבי ארה"ב משנת 2000 ומשנת 2010.
מטרות
במדריך הזה תבצעו את המשימות הבאות:- יוצרים מודל רגרסיה לוגיסטית.
- הערכת המודל.
- ליצור תחזיות באמצעות המודל.
- הסבר על התוצאות שהמודל הפיק.
עלויות
במדריך הזה נעשה שימוש ברכיבים של Google Cloudשחלים עליהם חיובים, כולל הרכיבים הבאים:
- BigQuery
- BigQuery ML
מידע נוסף על העלויות ב-BigQuery זמין בדף תמחור ב-BigQuery.
מידע נוסף על העלויות של BigQuery ML זמין במאמר תמחור ב-BigQuery ML.
לפני שמתחילים
-
בדף לבחירת הפרויקט במסוף Google Cloud , בוחרים פרויקט ב- Google Cloud או יוצרים אותו.
תפקידים שנדרשים כדי לבחור או ליצור פרויקט
- Select a project: כדי לבחור פרויקט לא צריך תפקיד IAM ספציפי – אפשר לבחור כל פרויקט שקיבלתם בו תפקיד.
-
יצירת פרויקט: כדי ליצור פרויקט, צריך את התפקיד Project Creator (יצירת פרויקטים) (
roles/resourcemanager.projectCreator), שכולל את ההרשאהresourcemanager.projects.create. איך מקצים תפקידים
-
מפעילים את BigQuery API.
תפקידים שנדרשים להפעלת ממשקי API
כדי להפעיל ממשקי API, צריך את תפקיד ה-IAM 'אדמין של Service Usage' (
roles/serviceusage.serviceUsageAdmin), שכולל את ההרשאהserviceusage.services.enable. איך מקצים תפקידים
ההרשאות הנדרשות
כדי ליצור את המודל באמצעות BigQuery ML, אתם צריכים את הרשאות ה-IAM הבאות:
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateDatabigquery.models.updateMetadata
כדי להריץ הסקה, אתם צריכים את ההרשאות הבאות:
bigquery.models.getDataבמודלbigquery.jobs.create
מבוא
משימה נפוצה בלמידת מכונה היא לסווג נתונים לאחד משני סוגים, שנקראים תוויות. לדוגמה, קמעונאי יכול לרצות לחזות אם לקוח מסוים ירכוש מוצר חדש, על סמך מידע אחר על אותו לקוח. במקרה כזה, שתי התוויות יכולות להיות will buy ו-won't buy. הקמעונאי יכול ליצור קבוצת נתונים שבה עמודה אחת מייצגת את שתי התוויות, וכוללת גם נתוני לקוח כמו המיקום שלהם, הרכישות הקודמות שלהם וההעדפות המדווחות שלהם. לאחר מכן, הקמעונאי יכול להשתמש במודל רגרסיה לוגיסטית בינארית שמתבסס על נתוני לקוח אלה כדי לחזות איזו תווית מייצגת בצורה הטובה ביותר כל לקוח.
במדריך הזה יוצרים מודל רגרסיה לוגיסטית בינארית שמנבא אם ההכנסה של משיב למפקד האוכלוסין בארה"ב נכללת באחד משני טווחי הכנסה, על סמך מאפיינים דמוגרפיים של המשיב.
יצירת מערך נתונים
יוצרים מערך נתונים ב-BigQuery לאחסון המודל:
במסוף Google Cloud , עוברים לדף BigQuery.
בחלונית הימנית, לוחצים על כלי הניתוחים:

אם החלונית הימנית לא מוצגת, לוחצים על הרחבת החלונית הימנית כדי לפתוח אותה.
בחלונית Explorer, לוחצים על שם הפרויקט.
לוחצים על הצגת פעולות > יצירת מערך נתונים.
בדף Create dataset, מבצעים את הפעולות הבאות:
בשדה Dataset ID (מזהה מערך הנתונים), מזינים
census.בקטע Location type (סוג המיקום), בוחרים באפשרות Multi-region (מספר אזורים) ואז באפשרות US (multiple regions in United States) (ארה"ב (מספר אזורים בארצות הברית)).
מערכי הנתונים הציבוריים מאוחסנים ב
USמספר אזורים. כדי לפשט את התהליך, כדאי לאחסן את מערך הנתונים באותו מיקום.משאירים את הגדרות ברירת המחדל שנותרו כמו שהן ולוחצים על Create dataset (יצירת מערך נתונים).
בדיקת הנתונים
בודקים את מערך הנתונים ומזהים את העמודות שבהן צריך להשתמש כנתוני אימון למודל הרגרסיה הלוגיסטית. בוחרים 100 שורות מהטבלה census_adult_income:
SQL
במסוף Google Cloud , עוברים לדף BigQuery.
בעורך השאילתות, מריצים את שאילתת GoogleSQL הבאה:
SELECT age, workclass, marital_status, education_num, occupation, hours_per_week, income_bracket, functional_weight FROM `bigquery-public-data.ml_datasets.census_adult_income` LIMIT 100;
התוצאות אמורות להיראות כך:

BigQuery DataFrames
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי הוראות ההגדרה של BigQuery DataFrames במדריך לתחילת העבודה עם BigQuery באמצעות BigQuery DataFrames. מידע נוסף מופיע במאמרי העזרה בנושא BigQuery DataFrames.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת ADC לסביבת פיתוח מקומית.
תוצאות השאילתה מראות שהעמודה income_bracket בטבלה census_adult_income מכילה רק אחד משני הערכים: <=50K או >50K.
הכנת נתונים לדוגמה
במדריך הזה ננסה לחזות את ההכנסה של משיבים לסקר על סמך הערכים של העמודות הבאות בטבלה census_adult_income:
-
age: הגיל של המשיב/ה. -
workclass: סוג העבודה שבוצעה. לדוגמה, ממשלה מקומית, פרטי או עצמאי. marital_status-
education_num: רמת ההשכלה הגבוהה ביותר של המשיב. occupation-
hours_per_week: שעות עבודה בשבוע.
אתם יכולים להחריג עמודות שכוללות נתונים כפולים. לדוגמה, בעמודה education, כי הערכים בעמודות education ו-education_num מבטאים את אותם נתונים בפורמטים שונים.
העמודה functional_weight היא מספר האנשים שלדעת ארגון המפקד מיוצגים בשורה מסוימת. מכיוון שהערך בעמודה הזו לא קשור לערך של income_bracket בשורה נתונה, משתמשים בערך בעמודה הזו כדי להפריד את הנתונים לקבוצות של אימון, הערכה וחיזוי, על ידי יצירת עמודה חדשה dataframe שנגזרת מהעמודה functional_weight. אתם מתייגים 80% מהנתונים לאימון המודל, 10% מהנתונים להערכה ו-10% מהנתונים לחיזוי.
SQL
יוצרים תצוגה מפורטת עם הנתונים לדוגמה.
התצוגה הזו משמשת את ההצהרה CREATE MODEL בהמשך המדריך הזה.
מריצים את השאילתה שמכינה את הנתונים לדוגמה:
במסוף Google Cloud , עוברים לדף BigQuery.
בעורך השאילתות, מריצים את השאילתה הבאה:
CREATE OR REPLACE VIEW `census.input_data` AS SELECT age, workclass, marital_status, education_num, occupation, hours_per_week, income_bracket, CASE WHEN MOD(functional_weight, 10) < 8 THEN 'training' WHEN MOD(functional_weight, 10) = 8 THEN 'evaluation' WHEN MOD(functional_weight, 10) = 9 THEN 'prediction' END AS dataframe FROM `bigquery-public-data.ml_datasets.census_adult_income`;
צפייה בנתונים לדוגמה:
SELECT * FROM `census.input_data`;
BigQuery DataFrames
יוצרים DataFrame בשם input_data. תשתמשו ב-input_data בהמשך המדריך הזה כדי לאמן את המודל, להעריך אותו וליצור תחזיות.
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי הוראות ההגדרה של BigQuery DataFrames במדריך לתחילת העבודה עם BigQuery באמצעות BigQuery DataFrames. מידע נוסף מופיע במאמרי העזרה בנושא BigQuery DataFrames.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת ADC לסביבת פיתוח מקומית.
יצירת מודל רגרסיה לוגיסטית
יוצרים מודל רגרסיה לוגיסטית עם נתוני האימון שסימנתם בתוויות בקטע הקודם.
SQL
משתמשים בהצהרת CREATE MODEL ומציינים את LOGISTIC_REG לסוג המודל.
הנה כמה פרטים חשובים על הצהרת CREATE MODEL:
האפשרות
input_label_colsמציינת איזו עמודה בהצהרתSELECTתשמש כעמודת התווית. כאן, עמודת התווית היאincome_bracket, ולכן המודל לומד איזה מבין שני הערכים שלincome_bracketהוא הסביר ביותר לשורה נתונה, על סמך הערכים האחרים שמופיעים באותה שורה.אין צורך לציין אם מודל רגרסיה לוגיסטית הוא בינארי או רב-סיווגי. מערכת BigQuery ML קובעת איזה סוג של מודל לאמן על סמך מספר הערכים הייחודיים בעמודת התווית.
האפשרות
auto_class_weightsמוגדרת לערךTRUEכדי לאזן את תוויות הסיווג בנתוני האימון. כברירת מחדל, נתוני האימון לא משוקללים. אם התוויות בנתוני האימון לא מאוזנות, יכול להיות שהמודל ילמד לחזות את הסיווג הפופולרי ביותר של התוויות בצורה משמעותית יותר. במקרה הזה, רוב המשיבים במערך הנתונים נמצאים בקבוצת ההכנסה הנמוכה. הדבר עלול להוביל למודל שנותן משקל רב מדי לטווח ההכנסות הנמוך יותר. משקלים של מחלקות מאזנים את תוויות המחלקות על ידי חישוב המשקלים לכל מחלקה ביחס הפוך לתדירות של המחלקה.האפשרות
enable_global_explainמוגדרת לערךTRUEכדי לאפשר לכם להשתמש בפונקציהML.GLOBAL_EXPLAINבמודל בהמשך המדריך.הצהרת
SELECTמבצעת שאילתה בתצוגהinput_dataשמכילה את הנתונים לדוגמה. הפסקהWHEREמסננת את השורות כך שרק השורות שמסומנות כנתוני אימון ישמשו לאימון המודל.
מריצים את השאילתה שיוצרת את מודל הרגרסיה הלוגיסטית:
במסוף Google Cloud , עוברים לדף BigQuery.
בעורך השאילתות, מריצים את השאילתה הבאה:
CREATE OR REPLACE MODEL `census.census_model` OPTIONS ( model_type='LOGISTIC_REG', auto_class_weights=TRUE, enable_global_explain=TRUE, data_split_method='NO_SPLIT', input_label_cols=['income_bracket'], max_iterations=15) AS SELECT * EXCEPT(dataframe) FROM `census.input_data` WHERE dataframe = 'training'
בחלונית הימנית, לוחצים על כלי הניתוחים:
בחלונית Explorer, לוחצים על Datasets.
בחלונית מערכי נתונים, לוחצים על
census.לוחצים על הכרטיסייה מודלים.
לחץ על
census_model.בכרטיסייה פרטים מפורטים המאפיינים שבהם נעשה שימוש ב-BigQuery ML כדי לבצע רגרסיה לוגיסטית.
BigQuery DataFrames
משתמשים בשיטה
fit כדי לאמן את המודל ובשיטה
to_gbq כדי לשמור אותו במערך הנתונים.
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי הוראות ההגדרה של BigQuery DataFrames במדריך לתחילת העבודה עם BigQuery באמצעות BigQuery DataFrames. מידע נוסף מופיע במאמרי העזרה בנושא BigQuery DataFrames.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת ADC לסביבת פיתוח מקומית.
הערכת הביצועים של המודל
אחרי שיוצרים את המודל, מעריכים את הביצועים שלו בהשוואה לנתוני ההערכה.
SQL
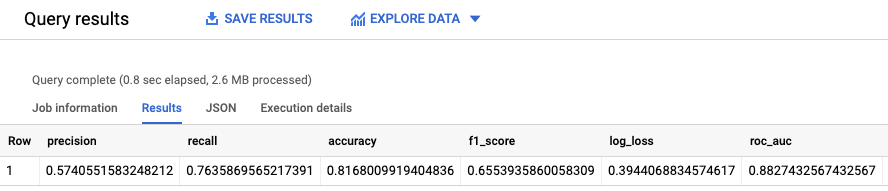
הפונקציה ML.EVALUATE מעריכה את הערכים הצפויים שנוצרו על ידי המודל ביחס לנתוני ההערכה.
כקלט, הפונקציה ML.EVALUATE מקבלת את המודל שאומן ואת השורות מהתצוגה input_data שבהן הערך בעמודה dataframe הוא evaluation. הפונקציה מחזירה שורה אחת של נתונים סטטיסטיים לגבי המודל.
מריצים את השאילתה ML.EVALUATE:
במסוף Google Cloud , עוברים לדף BigQuery.
בעורך השאילתות, מריצים את השאילתה הבאה:
SELECT * FROM ML.EVALUATE (MODEL `census.census_model`, ( SELECT * FROM `census.input_data` WHERE dataframe = 'evaluation' ) );
התוצאות אמורות להיראות כך:
BigQuery DataFrames
משתמשים ב-method score כדי להעריך את המודל בהשוואה לנתונים בפועל.
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי הוראות ההגדרה של BigQuery DataFrames במדריך לתחילת העבודה עם BigQuery באמצעות BigQuery DataFrames. מידע נוסף מופיע במאמרי העזרה בנושא BigQuery DataFrames.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת ADC לסביבת פיתוח מקומית.
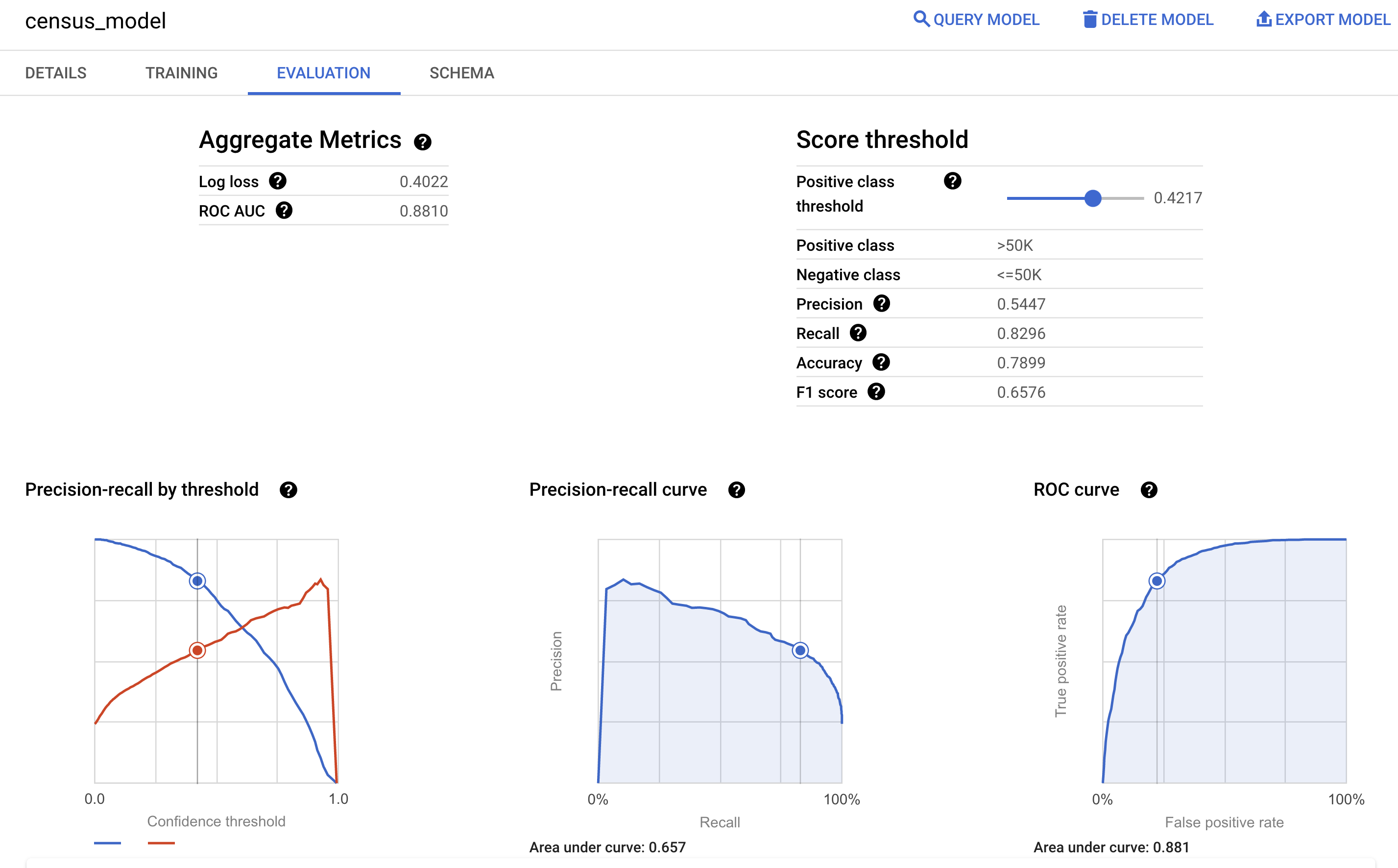
אפשר גם לעיין בחלונית הערכה של המודל במסוף Google Cloud כדי לראות את מדדי ההערכה שחושבו במהלך האימון:
חיזוי של קבוצת ההכנסה
משתמשים במודל כדי לחזות את קבוצת ההכנסה הסבירה ביותר לכל משיב.
SQL
כדי לחזות את קבוצת ההכנסה הסבירה, משתמשים בפונקציה ML.PREDICT. כקלט, הפונקציה ML.PREDICT מקבלת את המודל שאומן ואת השורות מהתצוגה input_data שבהן הערך בעמודה dataframe הוא prediction.
מריצים את השאילתה ML.PREDICT:
במסוף Google Cloud , עוברים לדף BigQuery.
בעורך השאילתות, מריצים את השאילתה הבאה:
SELECT * FROM ML.PREDICT (MODEL `census.census_model`, ( SELECT * FROM `census.input_data` WHERE dataframe = 'prediction' ) );
התוצאות אמורות להיראות כך:
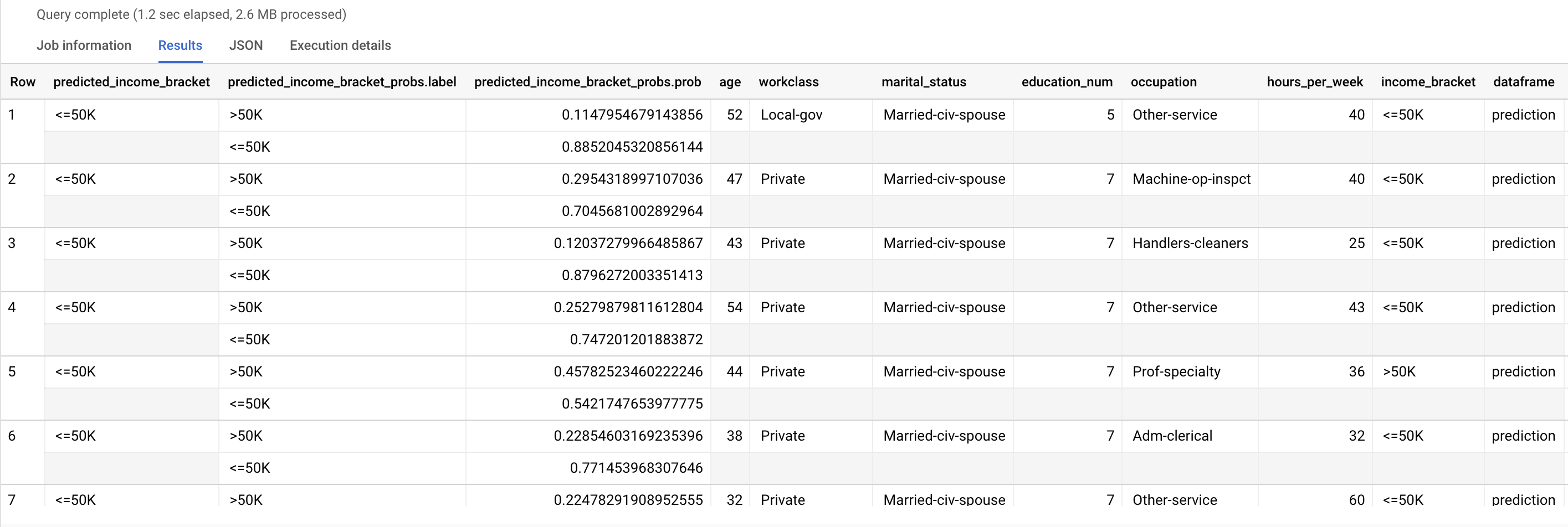
בעמודה predicted_income_bracket מופיע טווח ההכנסה החזוי של המשיב.
BigQuery DataFrames
משתמשים ב-method predict כדי ליצור תחזיות לגבי קבוצת ההכנסה הסבירה.
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי הוראות ההגדרה של BigQuery DataFrames במדריך לתחילת העבודה עם BigQuery באמצעות BigQuery DataFrames. מידע נוסף מופיע במאמרי העזרה בנושא BigQuery DataFrames.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת ADC לסביבת פיתוח מקומית.
הסבר על תוצאות התחזית
כדי להבין למה המודל יוצר את תוצאות החיזוי האלה, אפשר להשתמש בפונקציה ML.EXPLAIN_PREDICT.
ML.EXPLAIN_PREDICT היא גרסה מורחבת של הפונקציה ML.PREDICT.
ML.EXPLAIN_PREDICT לא רק מפיק תוצאות של תחזיות, אלא גם מפיק עמודות נוספות כדי להסביר את תוצאות התחזיות. מידע נוסף על יכולת הסברה זמין במאמר סקירה כללית על AI ניתן להסברה ב-BigQuery ML.
מריצים את השאילתה ML.EXPLAIN_PREDICT:
במסוף Google Cloud , עוברים לדף BigQuery.
בעורך השאילתות, מריצים את השאילתה הבאה:
SELECT * FROM ML.EXPLAIN_PREDICT(MODEL `census.census_model`, ( SELECT * FROM `census.input_data` WHERE dataframe = 'evaluation'), STRUCT(3 as top_k_features));
התוצאות אמורות להיראות כך:
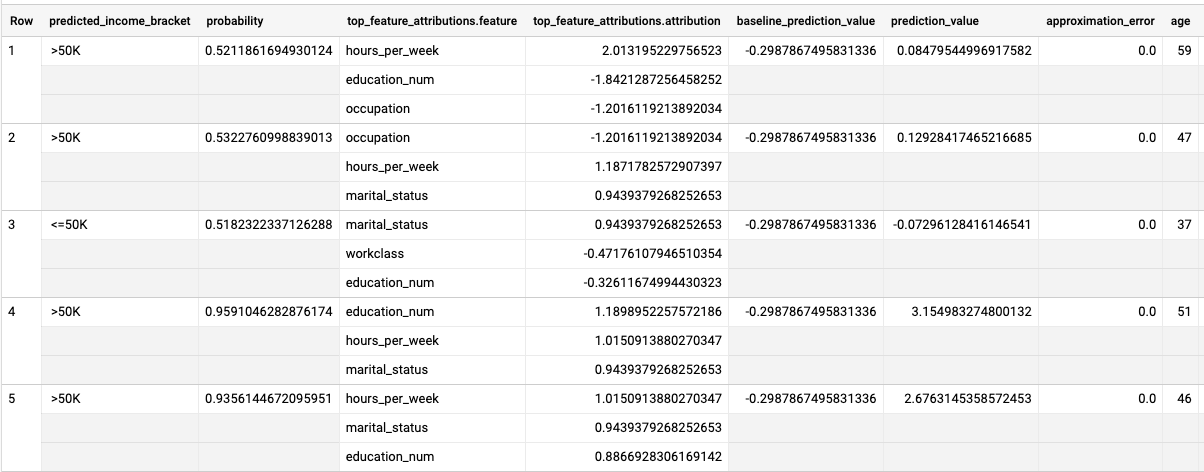
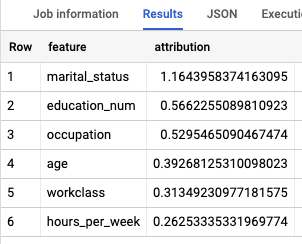
במודלים של רגרסיה לוגיסטית, נעשה שימוש בערכי Shapley כדי לקבוע את השיוך היחסי של התכונות לכל תכונה במודל. מכיוון שהאפשרות top_k_features
הוגדרה ל-3 בשאילתה, ML.EXPLAIN_PREDICT מחזירה את שלושת
השיוכים המובילים של התכונות לכל שורה בתצוגה input_data. השיוכים האלה מוצגים בסדר יורד לפי הערך המוחלט של השיוך.
הסבר גלובלי על המודל
כדי לדעת אילו תכונות הכי חשובות לקביעת קבוצת ההכנסה, משתמשים בפונקציה ML.GLOBAL_EXPLAIN.
קבלת הסברים גלובליים לגבי המודל:
במסוף Google Cloud , עוברים לדף BigQuery.
בעורך השאילתות, מריצים את השאילתה הבאה כדי לקבל הסברים גלובליים:
SELECT * FROM ML.GLOBAL_EXPLAIN(MODEL `census.census_model`)
התוצאות אמורות להיראות כך:
הסרת המשאבים
כדי להימנע מחיובים בחשבון Google Cloud בגלל השימוש במשאבים שנעשה במסגרת המדריך הזה, אפשר למחוק את הפרויקט שמכיל את המשאבים, או להשאיר את הפרויקט ולמחוק את המשאבים בנפרד.
מחיקת מערך נתונים
אם מוחקים פרויקט, כל מערכי הנתונים וכל הטבלאות בפרויקט נמחקים. אם אתם מעדיפים להשתמש מחדש בפרויקט, אתם יכולים למחוק את מערך הנתונים שיצרתם במדריך הזה:
אם צריך, פותחים את הדף BigQuery במסוףGoogle Cloud .
בתפריט הניווט, לוחצים על מערך הנתונים census שיצרתם.
בצד שמאל של החלון, לוחצים על מחיקת מערך נתונים. הפעולה הזו מוחקת את מערך הנתונים ואת המודל.
בתיבת הדו-שיח מחיקת מערך נתונים, מקלידים את שם מערך הנתונים (
census) כדי לאשר את פקודת המחיקה, ואז לוחצים על מחיקה.
מחיקת פרויקט
כדי למחוק את הפרויקט:
- במסוף Google Cloud , נכנסים לדף Manage resources.
- ברשימת הפרויקטים, בוחרים את הפרויקט שרוצים למחוק ולוחצים על Delete.
- כדי למחוק את הפרויקט, כותבים את מזהה הפרויקט בתיבת הדו-שיח ולוחצים על Shut down.
המאמרים הבאים
- סקירה כללית על BigQuery ML זמינה במאמר מבוא ל-BigQuery ML.
- מידע על יצירת מודלים זמין בדף התחביר
CREATE MODEL.