
במדריך הזה תשתמשו במודל רגרסיה לינארית ב-BigQuery ML כדי לחזות את המשקל של פינגווין על סמך המידע הדמוגרפי שלו. רגרסיה ליניארית היא סוג של מודל רגרסיה שמייצר ערך רציף משילוב ליניארי של תכונות קלט.
במדריך הזה נעשה שימוש במערך הנתונים bigquery-public-data.ml_datasets.penguins.
מטרות
במדריך הזה תבצעו את המשימות הבאות:
- יוצרים מודל של רגרסיה ליניארית.
- הערכת המודל.
- ליצור תחזיות באמצעות המודל.
עלויות
במדריך הזה נעשה שימוש ברכיבים של Google Cloudשחלים עליהם חיובים, כולל הרכיבים הבאים:
- BigQuery
- BigQuery ML
מידע נוסף על העלויות ב-BigQuery זמין בדף תמחור ב-BigQuery.
מידע נוסף על העלויות של BigQuery ML זמין במאמר תמחור ב-BigQuery ML.
לפני שמתחילים
-
בדף לבחירת הפרויקט במסוף Google Cloud , בוחרים פרויקט ב- Google Cloud או יוצרים אותו.
תפקידים שנדרשים כדי לבחור או ליצור פרויקט
- Select a project: כדי לבחור פרויקט לא צריך תפקיד IAM ספציפי – אפשר לבחור כל פרויקט שקיבלתם בו תפקיד.
-
יצירת פרויקט: כדי ליצור פרויקט, צריך את התפקיד Project Creator (יצירת פרויקטים) (
roles/resourcemanager.projectCreator), שכולל את ההרשאהresourcemanager.projects.create. איך מקצים תפקידים
-
מפעילים את BigQuery API.
תפקידים שנדרשים להפעלת ממשקי API
כדי להפעיל ממשקי API, צריך את תפקיד ה-IAM 'אדמין של שימוש בשירות' (
roles/serviceusage.serviceUsageAdmin), שכולל את ההרשאהserviceusage.services.enable. איך מקצים תפקידים
ההרשאות הנדרשות
כדי ליצור את המודל באמצעות BigQuery ML, אתם צריכים את הרשאות ה-IAM הבאות:
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateDatabigquery.models.updateMetadata
כדי להריץ הסקה, אתם צריכים את ההרשאות הבאות:
bigquery.models.getDataבמודלbigquery.jobs.create
יצירת מערך נתונים
יוצרים מערך נתונים ב-BigQuery לאחסון מודל ה-ML.המסוף
במסוף Google Cloud , עוברים לדף BigQuery.
בחלונית Explorer, לוחצים על שם הפרויקט.
לוחצים על הצגת פעולות > יצירת מערך נתונים.
בדף Create dataset, מבצעים את הפעולות הבאות:
בשדה Dataset ID (מזהה מערך הנתונים), מזינים
bqml_tutorial.בקטע Location type, בוחרים באפשרות Multi-region ואז בוחרים באפשרות US.
משאירים את הגדרות ברירת המחדל שנותרו כמו שהן ולוחצים על Create dataset (יצירת מערך נתונים).
BQ
כדי ליצור מערך נתונים חדש, משתמשים בפקודה bq mk --dataset.
יוצרים מערך נתונים בשם
bqml_tutorialעם מיקום הנתונים שמוגדר ל-US.bq mk --dataset \ --location=US \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
בודקים שמערך הנתונים נוצר:
bq ls
API
מבצעים קריאה לשיטה datasets.insert
עם משאב מוגדר של מערך נתונים.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrames
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי הוראות ההגדרה של BigQuery DataFrames במדריך לתחילת העבודה עם BigQuery באמצעות BigQuery DataFrames. מידע נוסף מופיע במאמרי העזרה בנושא BigQuery DataFrames.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת ADC לסביבת פיתוח מקומית.
יצירת המודל
יצירת מודל רגרסיה לינארית באמצעות מערך הנתונים לדוגמה של Analytics לשימוש ב-BigQuery.
SQL
אפשר ליצור מודל רגרסיה ליניארית באמצעות הצהרת CREATE MODEL וציון LINEAR_REG לסוג המודל. יצירת המודל כוללת את אימון המודל.
הנה כמה פרטים חשובים על הצהרת CREATE MODEL:
- האפשרות
input_label_colsמציינת באיזו עמודה בהצהרתSELECTיש להשתמש כעמודת התוויות. כאן, עמודת התווית היאbody_mass_g. במודלים של רגרסיה לינארית, עמודת התווית חייבת להיות בעלת ערכים ממשיים, כלומר, הערכים בעמודה חייבים להיות מספרים ממשיים. ההצהרה
SELECTבשאילתה הזו משתמשת בעמודות הבאות בטבלהbigquery-public-data.ml_datasets.penguinsכדי לחזות את המשקל של פינגווין:-
species: מין הפינגווין. -
island: האי שבו הפינגווין נמצא. -
culmen_length_mm: אורך המקור של הפינגווין במילימטרים. -
culmen_depth_mm: עומק המקור של הפינגווין במילימטרים. -
flipper_length_mm: אורך הסנפירים של הפינגווין במילימטרים. -
sex: המין של הפינגווין.
-
הפסקה
WHEREבהצהרתSELECTשל השאילתה הזו,WHERE body_mass_g IS NOT NULL, מחריגה שורות שבהן העמודהbody_mass_gהיאNULL.
מריצים את השאילתה שיוצרת את מודל הרגרסיה הליניארית:
במסוף Google Cloud , עוברים לדף BigQuery.
בעורך השאילתות, מריצים את השאילתה הבאה:
CREATE OR REPLACE MODEL `bqml_tutorial.penguins_model` OPTIONS (model_type='linear_reg', input_label_cols=['body_mass_g']) AS SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE body_mass_g IS NOT NULL;
יצירת מודל
penguins_modelנמשכת כ-30 שניות.כדי לראות את המודל, מבצעים את השלבים הבאים:
בחלונית הימנית, לוחצים על כלי הניתוחים:

אם החלונית הימנית לא מוצגת, לוחצים על הרחבת החלונית הימנית כדי לפתוח אותה.
בחלונית Explorer, מרחיבים את הפרויקט ולוחצים על Datasets (מערכי נתונים).
לוחצים על מערך הנתונים
bqml_tutorial.לוחצים על הכרטיסייה מודלים.
BigQuery DataFrames
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי הוראות ההגדרה של BigQuery DataFrames במדריך לתחילת העבודה עם BigQuery באמצעות BigQuery DataFrames. מידע נוסף מופיע במאמרי העזרה בנושא BigQuery DataFrames.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת ADC לסביבת פיתוח מקומית.
יצירת המודל נמשכת כ-30 שניות. כדי לראות את המודל, מבצעים את השלבים הבאים:
בחלונית הימנית, לוחצים על כלי הניתוחים:
בחלונית Explorer, מרחיבים את הפרויקט ולוחצים על Datasets (מערכי נתונים).
לוחצים על מערך הנתונים
bqml_tutorial.לוחצים על הכרטיסייה מודלים.
קבלת נתונים סטטיסטיים של הדרכות
כדי לראות את התוצאות של אימון המודל, אפשר להשתמש בפונקציה ML.TRAINING_INFO או לראות את הנתונים הסטטיסטיים במסוף Google Cloud . במדריך הזה נשתמש במסוף Google Cloud .
אלגוריתם של למידת מכונה בונה מודל על ידי בחינת דוגמאות רבות וניסיון למצוא מודל שממזער את ההפסד. התהליך הזה נקרא מזעור סיכונים אמפירי.
הקנס על חיזוי לא מדויק הוא אובדן. זהו מספר שמציין עד כמה התחזית של המודל הייתה שגויה בדוגמה יחידה. אם התחזית של המודל מושלמת, ערך ההפסד הוא אפס. אחרת, ערך ההפסד גבוה יותר. המטרה של אימון מודל היא למצוא קבוצה של משקלים והטיות עם הפסד נמוך, בממוצע, בכל הדוגמאות.
אפשר לראות את הנתונים הסטטיסטיים של אימון המודל שנוצרו כשמריצים את השאילתה CREATE MODEL:
בחלונית הימנית, לוחצים על כלי הניתוחים:
בחלונית Explorer, מרחיבים את הפרויקט ולוחצים על Datasets (מערכי נתונים).
לוחצים על מערך הנתונים
bqml_tutorial.לוחצים על הכרטיסייה מודלים.
כדי לפתוח את חלונית פרטי המודל, לוחצים על penguins_model.
לוחצים על הכרטיסייה הדרכה ואז על טבלה. התוצאות אמורות להיראות כך:
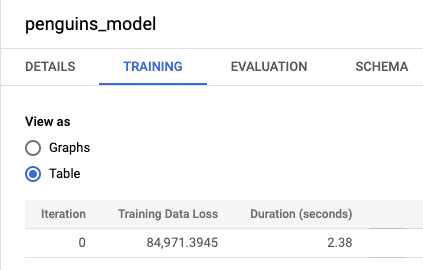
העמודה Training Data Loss מייצגת את מדד ההפסד שמחושב אחרי שהמודל מאומן על מערך הנתונים לאימון. מכיוון שביצעתם רגרסיה לינארית, בעמודה הזו מוצג הערך של השגיאה הריבועית הממוצעת. אסטרטגיית אופטימיזציה של normal_equation משמשת באופן אוטומטי לאימון הזה, ולכן נדרשת רק איטרציה אחת כדי להגיע למודל הסופי. מידע נוסף על הגדרת אסטרטגיית האופטימיזציה של המודל זמין במאמר
optimize_strategy.
הערכת המודל
אחרי שיוצרים את המודל, מעריכים את הביצועים שלו באמצעות הפונקציה ML.EVALUATE או הפונקציה score של BigQuery DataFrames כדי להשוות בין הערכים החזויים שהמודל יצר לבין הנתונים בפועל.
SQL
כקלט, הפונקציה ML.EVALUATE מקבלת את המודל המאומן ומערך נתונים שתואם לסכימה של הנתונים ששימשו לאימון המודל. בסביבת ייצור, צריך להעריך את המודל על נתונים שונים מאלה ששימשו לאימון המודל.
אם מריצים את הפונקציה ML.EVALUATE בלי לספק נתוני קלט, הפונקציה מאחזרת את מדדי ההערכה שחושבו במהלך האימון. החישוב של המדדים האלה מתבצע באמצעות מערך נתוני ההערכה שמוקצה אוטומטית:
SELECT
*
FROM
ML.EVALUATE(MODEL bqml_tutorial.penguins_model);
מריצים את השאילתה ML.EVALUATE:
במסוף Google Cloud , עוברים לדף BigQuery.
בעורך השאילתות, מריצים את השאילתה הבאה:
SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.penguins_model`, ( SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE body_mass_g IS NOT NULL));
BigQuery DataFrames
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי הוראות ההגדרה של BigQuery DataFrames במדריך לתחילת העבודה עם BigQuery באמצעות BigQuery DataFrames. מידע נוסף מופיע במאמרי העזרה בנושא BigQuery DataFrames.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת ADC לסביבת פיתוח מקומית.
התוצאות אמורות להיראות כך:
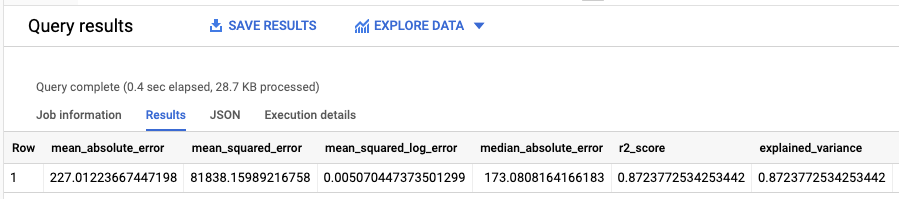
מכיוון שביצעתם רגרסיה לינארית, התוצאות כוללות את העמודות הבאות:
mean_absolute_errormean_squared_errormean_squared_log_errormedian_absolute_errorr2_scoreexplained_variance
מדד חשוב בתוצאות ההערכה הוא ציון R.
ציון R2 הוא מדד סטטיסטי שקובע אם התחזיות של הרגרסיה הלינארית קרובות לנתונים בפועל. ערך של 0 מציין שהמודל לא מסביר אף אחד מהשינויים בנתוני התגובה סביב הממוצע. הערך 1 מציין שהמודל מסביר את כל השונות של נתוני התגובה סביב הממוצע.
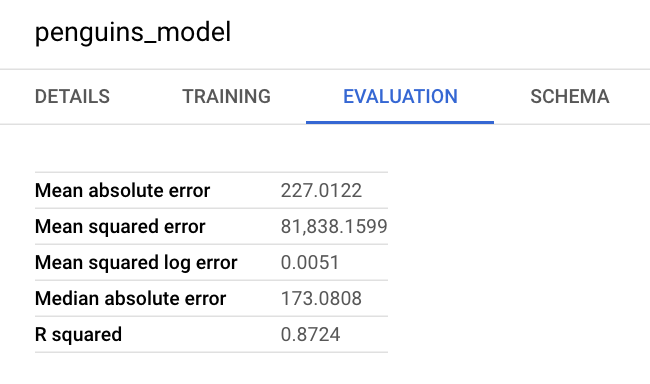
אפשר גם לעיין בחלונית המידע של המודל במסוף Google Cloud כדי לראות את מדדי ההערכה:
שימוש במודל כדי לחזות תוצאות
אחרי שמעריכים את המודל, השלב הבא הוא להשתמש בו כדי לחזות תוצאה. אפשר להריץ את הפונקציה ML.PREDICT או את הפונקציה predict BigQuery DataFrames במודל כדי לחזות את מסת הגוף בגרמים של כל הפינגווינים שחיים באיי ביסקו.
SQL
כקלט, הפונקציה ML.PREDICT מקבלת את המודל המאומן ומערך נתונים שתואם לסכימה של הנתונים ששימשו לאימון המודל, לא כולל עמודת התווית.
מריצים את השאילתה ML.PREDICT:
במסוף Google Cloud , עוברים לדף BigQuery.
בעורך השאילתות, מריצים את השאילתה הבאה:
SELECT * FROM ML.PREDICT(MODEL `bqml_tutorial.penguins_model`, ( SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE island = 'Biscoe'));
BigQuery DataFrames
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי הוראות ההגדרה של BigQuery DataFrames במדריך לתחילת העבודה עם BigQuery באמצעות BigQuery DataFrames. מידע נוסף מופיע במאמרי העזרה בנושא BigQuery DataFrames.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת ADC לסביבת פיתוח מקומית.
התוצאות אמורות להיראות כך:

הסבר על תוצאות התחזית
SQL
כדי להבין למה המודל יוצר את תוצאות התחזית האלה, אפשר להשתמש בפונקציה ML.EXPLAIN_PREDICT.
ML.EXPLAIN_PREDICT היא גרסה מורחבת של הפונקציה ML.PREDICT.
ML.EXPLAIN_PREDICT לא רק מפיק תוצאות של תחזיות, אלא גם מפיק עמודות נוספות כדי להסביר את תוצאות התחזיות. בפועל, אפשר להריץ את הפקודה ML.EXPLAIN_PREDICT במקום ML.PREDICT. מידע נוסף זמין במאמר סקירה כללית על AI שניתן להסבר ב-BigQuery ML.
מריצים את השאילתה ML.EXPLAIN_PREDICT:
- במסוף Google Cloud , עוברים לדף BigQuery.
- בעורך השאילתות, מריצים את השאילתה הבאה:
SELECT * FROM ML.EXPLAIN_PREDICT(MODEL `bqml_tutorial.penguins_model`, ( SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE island = 'Biscoe'), STRUCT(3 as top_k_features));
התוצאות אמורות להיראות כך:
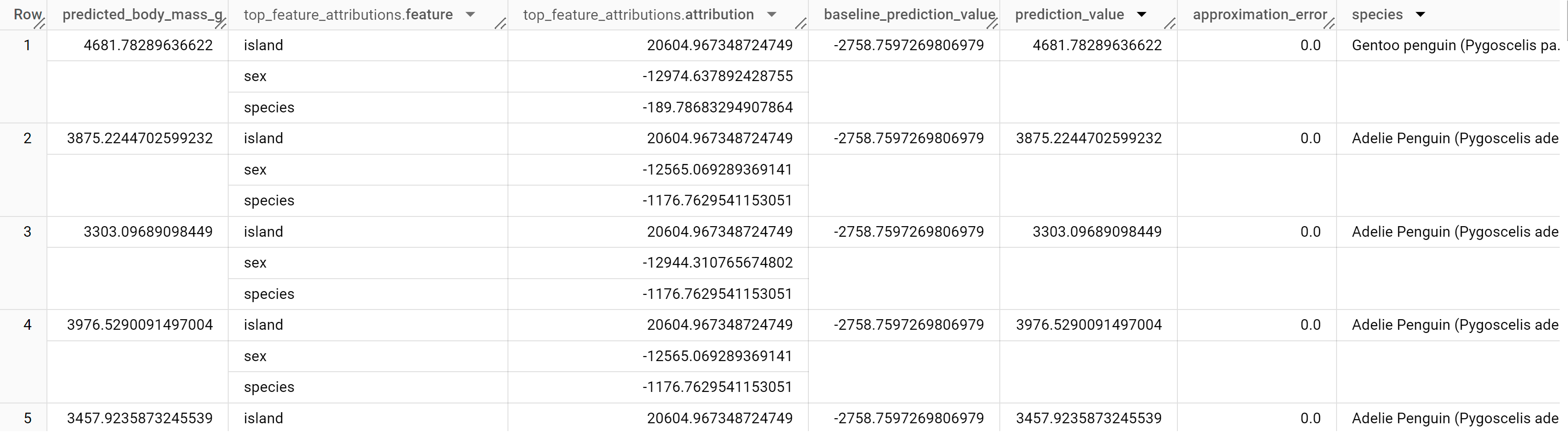
BigQuery DataFrames
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי הוראות ההגדרה של BigQuery DataFrames במדריך לתחילת העבודה עם BigQuery באמצעות BigQuery DataFrames. מידע נוסף מופיע במאמרי העזרה בנושא BigQuery DataFrames.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת ADC לסביבת פיתוח מקומית.
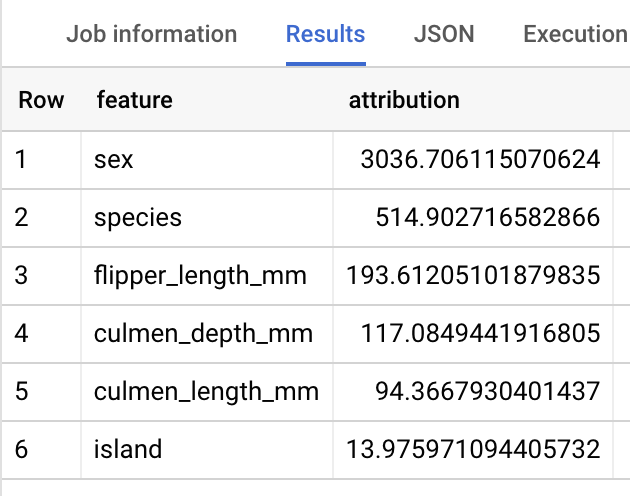
במודלים של רגרסיה לינארית, נעשה שימוש בערכי Shapley כדי ליצור ערכי שיוך של מאפיינים לכל מאפיין במודל. הפלט כולל את שלושת מאפייני התכונות המובילים לכל שורה בטבלה penguins כי הערך של top_k_features הוגדר כ-3. השיוכים האלה ממוינים לפי הערך המוחלט של השיוך בסדר יורד. בכל הדוגמאות, התכונה sex תרמה הכי הרבה לחיזוי הכולל.
הסבר גלובלי על המודל
SQL
כדי לדעת אילו תכונות בדרך כלל הכי חשובות לקביעת המשקל של פינגווין, אפשר להשתמש בפונקציה ML.GLOBAL_EXPLAIN.
כדי להשתמש ב-ML.GLOBAL_EXPLAIN, צריך לאמן מחדש את המודל עם האפשרות ENABLE_GLOBAL_EXPLAIN שמוגדרת ל-TRUE.
אימון מחדש וקבלת הסברים גלובליים לגבי המודל:
- במסוף Google Cloud , עוברים לדף BigQuery.
בעורך השאילתות, מריצים את השאילתה הבאה כדי לאמן מחדש את המודל:
#standardSQL CREATE OR REPLACE MODEL `bqml_tutorial.penguins_model` OPTIONS ( model_type = 'linear_reg', input_label_cols = ['body_mass_g'], enable_global_explain = TRUE) AS SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE body_mass_g IS NOT NULL;
בעורך השאילתות, מריצים את השאילתה הבאה כדי לקבל הסברים גלובליים:
SELECT * FROM ML.GLOBAL_EXPLAIN(MODEL `bqml_tutorial.penguins_model`)
התוצאות אמורות להיראות כך:
BigQuery DataFrames
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי הוראות ההגדרה של BigQuery DataFrames במדריך לתחילת העבודה עם BigQuery באמצעות BigQuery DataFrames. מידע נוסף מופיע במאמרי העזרה בנושא BigQuery DataFrames.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת ADC לסביבת פיתוח מקומית.
הסרת המשאבים
כדי להימנע מחיובים בחשבון Google Cloud בגלל השימוש במשאבים שנעשה במסגרת המדריך הזה, אפשר למחוק את הפרויקט שמכיל את המשאבים, או להשאיר את הפרויקט ולמחוק את המשאבים בנפרד.
- אתם יכולים למחוק את הפרויקט שיצרתם.
- אפשר גם להשאיר את הפרויקט ולמחוק את קבוצת הנתונים.
מחיקת מערך נתונים
אם מוחקים פרויקט, כל מערכי הנתונים וכל הטבלאות בפרויקט נמחקים. אם אתם מעדיפים להשתמש מחדש בפרויקט, אתם יכולים למחוק את מערך הנתונים שיצרתם במדריך הזה:
אם צריך, פותחים את הדף BigQuery במסוףGoogle Cloud .
בחלונית הניווט, לוחצים על מערך הנתונים bqml_tutorial שיצרתם.
בצד שמאל של החלון, לוחצים על מחיקת מערך נתונים. הפעולה הזו מוחקת את מערך הנתונים, את הטבלה ואת כל הנתונים.
בתיבת הדו-שיח מחיקת מערך נתונים, מקלידים את שם מערך הנתונים (
bqml_tutorial) כדי לאשר את פקודת המחיקה, ואז לוחצים על מחיקה.
מחיקת פרויקט
כדי למחוק את הפרויקט:
- במסוף Google Cloud , נכנסים לדף Manage resources.
- ברשימת הפרויקטים, בוחרים את הפרויקט שרוצים למחוק ולוחצים על Delete.
- כדי למחוק את הפרויקט, כותבים את מזהה הפרויקט בתיבת הדו-שיח ולוחצים על Shut down.
המאמרים הבאים
- סקירה כללית על BigQuery ML זמינה במאמר מבוא ל-BigQuery ML.
- מידע על יצירת מודלים זמין בדף התחביר
CREATE MODEL.