
שימוש בתוסף BigQuery JupyterLab
כדי לבקש משוב או תמיכה בנוגע לתכונה הזו, אפשר לשלוח אימייל לכתובת bigquery-ide-plugin@google.com.
במאמר הזה מוסבר איך להתקין ולהשתמש בפלאגין BigQuery JupyterLab כדי לבצע את הפעולות הבאות:
- לסקור את הנתונים ב-BigQuery.
- משתמשים ב-BigQuery DataFrames API.
- פריסת מחברת BigQuery DataFrames אל Managed Service for Apache Airflow.
התוסף BigQuery JupyterLab כולל את כל הפונקציות של התוסף Managed Service for Apache Spark JupyterLab, כמו יצירת תבנית זמן ריצה של Managed Service for Apache Spark Serverless, הפעלה וניהול של מחברות, פיתוח באמצעות Apache Spark, פריסת הקוד וניהול המשאבים.
התקנת הפלאגין BigQuery JupyterLab
כדי להתקין את הפלאגין BigQuery JupyterLab ולהשתמש בו:
בטרמינל המקומי, בודקים שגרסה Python 3.8 ואילך מותקנת במערכת:
python3 --versionבטרמינל המקומי, מאתחלים את ה-CLI של gcloud:
gcloud initמתקינים את Pipenv, כלי לסביבה וירטואלית של Python:
pip3 install pipenvיוצרים סביבה וירטואלית חדשה:
pipenv shellמתקינים את JupyterLab בסביבה הווירטואלית החדשה:
pipenv install jupyterlabמתקינים את הפלאגין BigQuery JupyterLab:
pipenv install bigquery-jupyter-pluginאם הגרסה המותקנת של JupyterLab קודמת לגרסה 4.0.0, צריך להפעיל את תוסף הפלאגין:
jupyter server extension enable bigquery_jupyter_pluginמפעילים את JupyterLab:
jupyter labJupyterLab ייפתח בדפדפן.
עדכון ההגדרות של הפרויקט והאזור
כברירת מחדל, הסשן פועל בפרויקט ובאזור שהגדרתם כשביצעתם את הפקודה gcloud init. כדי לשנות את הגדרות הפרויקט והאזור של הסשן:
- בתפריט של JupyterLab, לוחצים על Settings > Google BigQuery Settings (הגדרות > הגדרות Google BigQuery).
כדי שהשינויים ייכנסו לתוקף, צריך להפעיל מחדש את הפלאגין.
עיון בנתונים
כדי לעבוד עם נתוני BigQuery ב-JupyterLab, צריך לבצע את הפעולות הבאות:
- בסרגל הצד של JupyterLab, פותחים את החלונית Dataset Explorer (סייר מערכי הנתונים): לוחצים על הסמל
 של מערכי הנתונים.
של מערכי הנתונים. כדי להרחיב פרויקט, בחלונית Dataset Explorer, לוחצים על החץ להרחבה לצד שם הפרויקט.
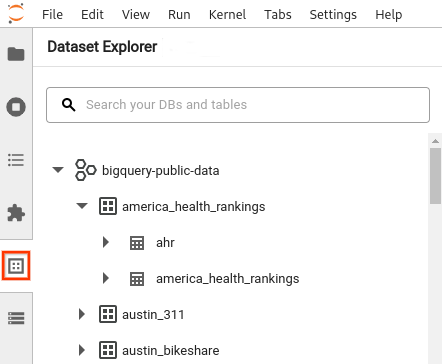
בחלונית Dataset Explorer מוצגים כל מערכי הנתונים בפרויקט שנמצאים באזור BigQuery שהגדרתם לסשן. יש כמה דרכים לאינטראקציה עם פרויקט ועם מערך נתונים:
- כדי לראות מידע על מערך נתונים, לוחצים על השם של מערך הנתונים.
- כדי להציג את כל הטבלאות במערך נתונים, לוחצים על החץ להרחבה לצד מערך הנתונים.
- כדי לראות מידע על טבלה, לוחצים על שם הטבלה.
- כדי לשנות את הפרויקט או את האזור ב-BigQuery, צריך לעדכן את ההגדרות.
הרצת מחברות
כדי להריץ שאילתות על נתוני BigQuery מ-JupyterLab:
- כדי לפתוח את דף מרכז האפליקציות, לוחצים על קובץ > מרכז אפליקציות חדש.
- בקטע BigQuery Notebooks (מחברות BigQuery), לוחצים על הכרטיס BigQuery DataFrames (מסגרות נתונים של BigQuery). מחברת חדשה תיפתח ותציג לכם איך מתחילים לעבוד עם BigQuery DataFrames.
מחברות BigQuery DataFrames תומכות בפיתוח Python בגרעין Python מקומי. פעולות BigQuery DataFrames מבוצעות מרחוק ב-BigQuery, אבל שאר הקוד מבוצע באופן מקומי במחשב שלכם. כשמבצעים פעולה ב-BigQuery, מזהה של משימת שאילתה וקישור למשימה מופיעים מתחת לתא הקוד.
- כדי לראות את העבודה במסוף Google Cloud , לוחצים על Open Job (פתיחת העבודה).
פריסת מחברת BigQuery DataFrames
אפשר לפרוס מחברת BigQuery DataFrames ל-Managed Airflow באמצעות תבנית של זמן ריצה של Managed Service for Apache Spark Serverless. חייבים להשתמש בגרסה 2.1 ואילך של זמן הריצה.
- ב-notebook של JupyterLab, לוחצים על calendar_monthJob Scheduler.
- בשדה Job name (שם המשימה), מזינים שם ייחודי למשימה.
- בשדה Environment (סביבה), מזינים את השם של סביבת Managed Airflow שאליה רוצים לפרוס את העבודה.
- אם הפנקס שלכם מוגדר עם פרמטרים, מוסיפים פרמטרים.
- מזינים את השם של תבנית זמן הריצה ללא שרת.
- כדי לטפל בכשלים בהרצת מחברת, מזינים מספר שלם בשדה Retry count (מספר הניסיונות החוזרים) וערך (בדקות) בשדה Retry delay (השהיה בין ניסיונות חוזרים).
בוחרים אילו התראות על הפעלה לשלוח, ואז מזינים את הנמענים.
ההתראות נשלחות באמצעות הגדרת ה-SMTP של Airflow.
בוחרים לוח זמנים למחברת.
לוחצים על יצירה.
אחרי שתקבעו בהצלחה את התזמון של המחברת, היא תופיע ברשימת המשימות המתוזמנות בסביבת Managed Airflow שבחרתם.
המאמרים הבאים
- אפשר לנסות את המדריך לתחילת העבודה עם BigQuery DataFrames.
- מידע נוסף על BigQuery DataFrames API בשפת Python
- שימוש ב-JupyterLab עבור סשנים של עיבוד ברצף (batch) ושל מחברות (notebook) בלי שרת באמצעות Managed Service for Apache Spark.