
Migrar tablas gestionadas de Hive a Google Cloud
En este documento se explica cómo migrar tus tablas gestionadas de Hive a Google Cloud.
Puedes usar el conector de migración de tablas gestionadas de Hive en BigQuery Data Transfer Service para migrar sin problemas tus tablas gestionadas por metastore de Hive, que admite los formatos de Hive e Iceberg de entornos locales y en la nube a Google Cloud. Admitimos el almacenamiento de archivos en HDFS o Amazon S3.
Con el conector de migración de tablas gestionadas de Hive, puedes registrar tus tablas gestionadas de Hive en Dataproc Metastore, BigLake Metastore o BigLake Metastore Iceberg REST Catalog mientras usas Cloud Storage como almacenamiento de archivos.
En el siguiente diagrama se muestra un resumen del proceso de migración de tablas desde un clúster de Hadoop.
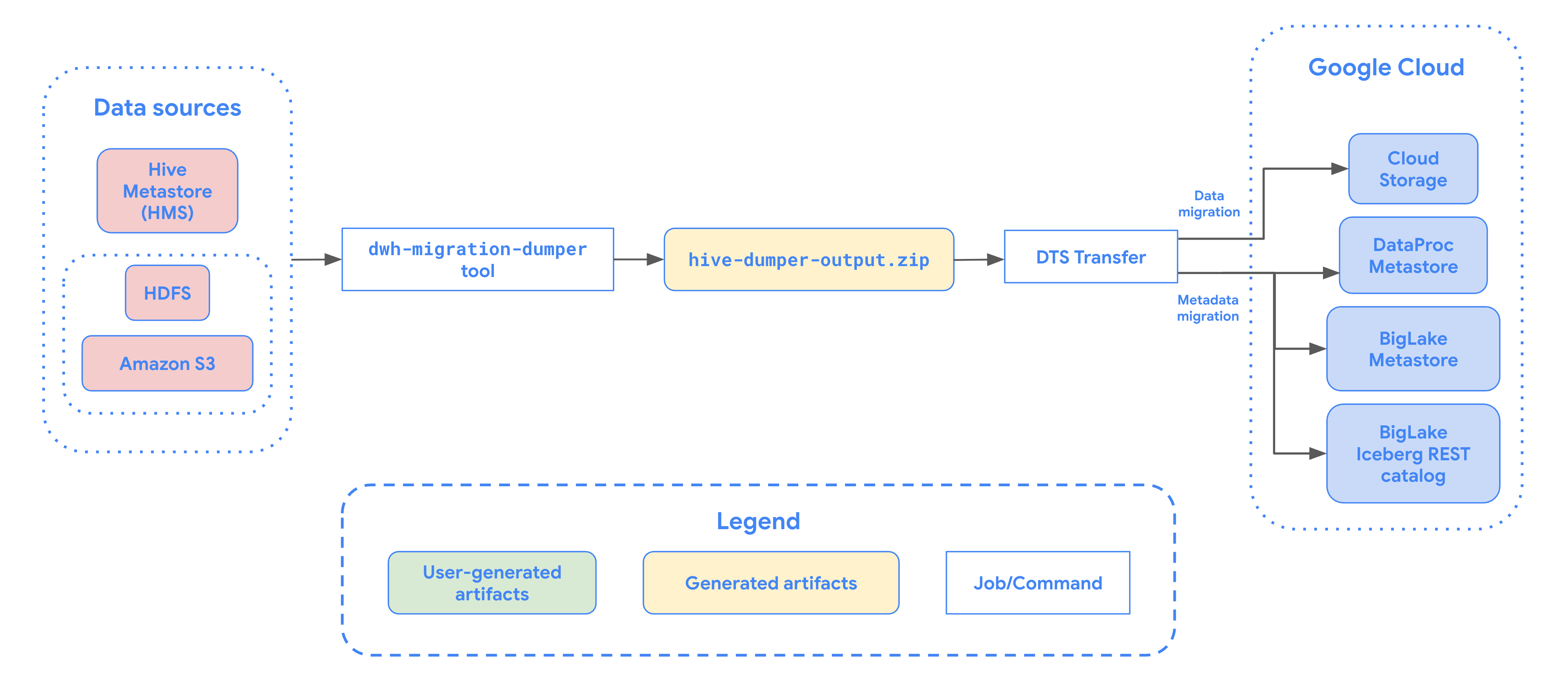
Limitaciones
Las transferencias de tablas gestionadas de Hive están sujetas a las siguientes limitaciones:
- Para migrar tablas de Apache Iceberg, debes registrarlas en el metastore de BigLake para permitir el acceso de escritura a los motores de código abierto (como Apache Spark o Flink) y el acceso de lectura a BigQuery.
- Para migrar tablas gestionadas de Hive, debes registrarlas en Dataproc Metastore para permitir el acceso de escritura a los motores de código abierto y el acceso de lectura a BigQuery.
- Debes usar la herramienta de línea de comandos bq para migrar tablas gestionadas de Hive a BigQuery.
Antes de empezar
Antes de programar la transferencia de tablas gestionadas de Hive, debe hacer lo siguiente:
Generar un archivo de metadatos para Apache Hive
Ejecuta la herramienta dwh-migration-dumper para extraer metadatos
de Apache Hive. La herramienta genera un archivo llamado hive-dumper-output.zip
en un segmento de Cloud Storage, al que se hace referencia en este documento como DUMPER_BUCKET.
Habilitar APIs
Habilita las siguientes APIs en tu proyectoGoogle Cloud :
- API de transferencia de datos
- API Transfer de Storage
Se crea un agente de servicio cuando habilitas la API Data Transfer.
Configurar permisos
- Crea una cuenta de servicio y concédele el rol Administrador de BigQuery (
roles/bigquery.admin). Esta cuenta de servicio se usa para crear la configuración de la transferencia. Cuando se habilita la API Data Transfer, se crea un agente de servicio (P4SA). Concédele los siguientes roles:
roles/metastore.metadataOwnerroles/storagetransfer.adminroles/serviceusage.serviceUsageConsumerroles/storage.objectAdmin- Si vas a migrar metadatos de tablas de Iceberg de BigLake, también debes asignar el rol
roles/bigquery.admin. - Si vas a migrar metadatos al catálogo REST de Iceberg de BigLake Metastore, también debes conceder el rol
roles/biglake.admin.
- Si vas a migrar metadatos de tablas de Iceberg de BigLake, también debes asignar el rol
Asigna el rol
roles/iam.serviceAccountTokenCreatoral agente de servicio con el siguiente comando:gcloud iam service-accounts add-iam-policy-binding SERVICE_ACCOUNT --member serviceAccount:service-PROJECT_NUMBER@gcp-sa-bigquerydatatransfer.iam.gserviceaccount.com --role roles/iam.serviceAccountTokenCreator
Configurar Storage Transfer Agent para lagos de datos de HDFS
Obligatorio cuando el archivo se almacena en HDFS. Para configurar el agente de transferencia de Storage necesario para transferir un lago de datos de HDFS, haga lo siguiente:
- Configura los permisos para ejecutar el agente de transferencia de almacenamiento en tu clúster de Hadoop.
- Instala Docker en las máquinas de agente locales.
- Crea un grupo de agentes del Servicio de transferencia de Storage en tu Google Cloud proyecto.
- Instala agentes en tus máquinas de agentes locales.
Configurar los permisos del Servicio de transferencia de Storage para Amazon S3
Obligatorio cuando el archivo se almacena en Amazon S3. Las transferencias desde Amazon S3 son transferencias sin agentes, que requieren permisos específicos. Para configurar Storage Transfer Service para una transferencia de Amazon S3, sigue estos pasos:
- Configurar permisos de transferencia sin agente.
- Configura las credenciales de acceso para AWS Amazon S3.
- Anota el ID de clave de acceso y la clave de acceso secreta después de configurar tus credenciales de acceso.
- Añade los intervalos de direcciones IP que usan los trabajadores del Servicio de Transferencia de Almacenamiento a tu lista de IPs permitidas si tu proyecto de AWS usa restricciones de IP.
Programar la transferencia de tablas gestionadas de Hive
Selecciona una de las opciones siguientes:
Consola
Ve a la página Transferencias de datos de la Google Cloud consola.
Haz clic en Crear transferencia.
En la sección Tipo de fuente, selecciona Tablas gestionadas de Hive en la lista Fuente.
En Ubicación, seleccione un tipo de ubicación y, a continuación, una región.
En la sección Nombre de la configuración de transferencia, en Nombre visible, indica un nombre para la transferencia de datos.
En la sección Opciones de programación, haga lo siguiente:
- En la lista Frecuencia de repetición, selecciona una opción para especificar con qué frecuencia se ejecuta esta transferencia de datos. Para especificar una frecuencia de repetición personalizada, seleccione Personalizada. Si seleccionas Bajo demanda, la transferencia se realizará cuando la inicies manualmente.
- Si procede, selecciona Empezar ahora o Empezar a una hora determinada y proporciona una fecha de inicio y un tiempo de ejecución.
En la sección Detalles de la fuente de datos, haga lo siguiente:
- En Patrones de nombres de tabla, especifique las tablas del lago de datos de HDFS que quiera transferir. Para ello, proporcione los nombres de las tablas o los patrones que coincidan con las tablas de la base de datos de HDFS. Debes usar la sintaxis de expresiones regulares de Java para especificar patrones de tabla. Por ejemplo:
db1..*coincide con todas las tablas de bd1.db1.table1;db2.table2coincide con table1 en db1 y table2 en db2.
- En BQMS discovery dump gcs path (Ruta de GCS de volcado de descubrimiento de BQMS), introduce la ruta al segmento que contiene el archivo
hive-dumper-output.zipque has generado al crear un archivo de metadatos para Apache Hive. - Elige el tipo de metastore en la lista desplegable:
DATAPROC_METASTORE: selecciona esta opción para almacenar tus metadatos en Dataproc Metastore. Debes proporcionar la URL de Dataproc Metastore en URL de Dataproc Metastore.BIGLAKE_METASTORE: selecciona esta opción para almacenar tus metadatos en el metastore de BigLake. Debes proporcionar un conjunto de datos de BigQuery en Conjunto de datos de BigQuery.BIGLAKE_REST_CATALOG: selecciona esta opción para almacenar tus metadatos en el catálogo REST de Iceberg de Metastore de BigLake.
En Ruta de GCS de destino, introduce la ruta de un segmento de Cloud Storage para almacenar los datos migrados.
Opcional: En Cuenta de servicio, introduce una cuenta de servicio que quieras usar para esta transferencia de datos. La cuenta de servicio debe pertenecer al mismo proyecto en el que se hayan creado la configuración de transferencia y el conjunto de datos de destino.Google Cloud
Opcional: Puedes habilitar Usar salida de traducción para configurar una ruta de Cloud Storage y una base de datos únicas para cada tabla que se migre. Para ello, proporcione la ruta a la carpeta de Cloud Storage que contiene los resultados de la traducción en el campo Ruta de GCS de salida de traducción de BQMS. Para obtener más información, consulta Configurar la salida de la traducción.
- Si especificas una ruta de Cloud Storage de salida de traducción, la ruta de Cloud Storage de destino y el conjunto de datos de BigQuery se obtendrán de los archivos de esa ruta.
En Tipo de almacenamiento, selecciona una de las siguientes opciones:
HDFS: selecciona esta opción si tu almacenamiento de archivos esHDFS. En el campo Nombre del grupo de agentes de STS, debes indicar el nombre del grupo de agentes que creaste al configurar tu agente de Transferencia de almacenamiento.S3: selecciona esta opción si tu almacenamiento de archivos esAmazon S3. En los campos ID de clave de acceso y Clave de acceso secreta, debe proporcionar el ID de clave de acceso y la clave de acceso secreta que creó al configurar sus credenciales de acceso.
- En Patrones de nombres de tabla, especifique las tablas del lago de datos de HDFS que quiera transferir. Para ello, proporcione los nombres de las tablas o los patrones que coincidan con las tablas de la base de datos de HDFS. Debes usar la sintaxis de expresiones regulares de Java para especificar patrones de tabla. Por ejemplo:
bq
Para programar la transferencia de tablas gestionadas de Hive, introduce el comando bq mk
y proporciona la marca de creación de la transferencia --transfer_config:
bq mk --transfer_config --data_source=hadoop --display_name='TRANSFER_NAME' --service_account_name='SERVICE_ACCOUNT' --project_id='PROJECT_ID' --location='REGION' --params='{"table_name_patterns":"LIST_OF_TABLES", "table_metadata_path":"gs://DUMPER_BUCKET/hive-dumper-output.zip", "target_gcs_file_path":"gs://MIGRATION_BUCKET", "metastore":"METASTORE", "destination_dataproc_metastore":"DATAPROC_METASTORE_URL", "destination_bigquery_dataset":"BIGLAKE_METASTORE_DATASET", "translation_output_gcs_path":"gs://TRANSLATION_OUTPUT_BUCKET/metadata/config/default_database/", "storage_type":"STORAGE_TYPE", "agent_pool_name":"AGENT_POOL_NAME", "aws_access_key_id":"AWS_ACCESS_KEY_ID", "aws_secret_access_key":"AWS_SECRET_ACCESS_KEY" }'
Haz los cambios siguientes:
TRANSFER_NAME: el nombre visible de la configuración de la transferencia. El nombre de la transferencia puede ser cualquier valor que te permita identificarla si necesitas modificarla más adelante.SERVICE_ACCOUNT: el nombre de la cuenta de servicio que se usa para autenticar la transferencia. La cuenta de servicio debe ser propiedad del mismoproject_idque se ha usado para crear la transferencia y debe tener todos los permisos necesarios.PROJECT_ID: tu ID de proyecto Google Cloud . Si no se proporciona--project_idpara especificar un proyecto concreto, se usará el proyecto predeterminado.REGION: ubicación de esta configuración de transferencia.LIST_OF_TABLES: una lista de entidades que se van a transferir. Usa una especificación de nomenclatura jerárquica:database.table. Este campo admite expresiones regulares RE2 para especificar tablas. Por ejemplo:db1..*: especifica todas las tablas de la base de datos.db1.table1;db2.table2: una lista de tablas
DUMPER_BUCKET: el segmento de Cloud Storage que contiene el archivohive-dumper-output.zip.MIGRATION_BUCKET: ruta de GCS de destino a la que se cargarán todos los archivos subyacentes.METASTORE: el tipo de metastore al que se va a migrar. Asigna uno de los siguientes valores:DATAPROC_METASTORE: para transferir metadatos a Dataproc Metastore.BIGLAKE_METASTORE: para transferir metadatos a BigLake Metastore.BIGLAKE_REST_CATALOG: para transferir metadatos al catálogo REST de Iceberg de metastore de BigLake.
DATAPROC_METASTORE_URL: la URL de tu Dataproc Metastore. Obligatorio simetastoreesDATAPROC_METASTORE.BIGLAKE_METASTORE_DATASET: el conjunto de datos de BigQuery de tu metastore de BigLake. Obligatorio simetastoreesBIGLAKE_METASTORE.TRANSLATION_OUTPUT_BUCKET: (Opcional) Especifica un segmento de Cloud Storage para la salida de la traducción. Para obtener más información, consulta Usar la salida de traducción.STORAGE_TYPE: especifica el almacenamiento de archivos subyacente de tus tablas. Los tipos admitidos sonHDFSyS3.AGENT_POOL_NAME: el nombre del grupo de agentes que se usa para crear agentes. Obligatorio sistorage_typeesHDFS.AWS_ACCESS_KEY_ID: el ID de clave de acceso de las credenciales de acceso. Obligatorio sistorage_typeesS3.AWS_SECRET_ACCESS_KEY: la clave de acceso secreta de las credenciales de acceso. Obligatorio sistorage_typeesS3.
Ejecuta este comando para crear la configuración de transferencia e iniciar la transferencia de tablas gestionadas de Hive. Las transferencias se programan para que se ejecuten cada 24 horas de forma predeterminada, pero se pueden configurar con las opciones de programación de transferencias.
Cuando se complete la transferencia, las tablas del clúster de Hadoop se migrarán a MIGRATION_BUCKET.
Opciones de ingestión de datos
En las siguientes secciones se ofrece más información sobre cómo puede configurar sus transferencias de tablas gestionadas de Hive.
Transferencias incrementales
Cuando se configura una transferencia con una programación periódica, cada transferencia posterior actualiza la tabla de Google Cloud con los últimos cambios realizados en la tabla de origen. Por ejemplo, todas las operaciones de inserción, eliminación o actualización con cambios en el esquema se reflejan en Google Cloud con cada transferencia.
Opciones de programación de transferencias
De forma predeterminada, las transferencias se programan para que se ejecuten cada 24 horas. Para configurar la frecuencia con la que se ejecutan las transferencias, añade la marca --schedule a la configuración de la transferencia y especifica una programación de la transferencia con la sintaxis schedule.
Las transferencias de tablas gestionadas de Hive deben tener un mínimo de 24 horas entre ejecuciones.
En el caso de las transferencias únicas, puedes añadir la marca end_time a la configuración de la transferencia para que solo se ejecute una vez.
Configurar la salida de Traducción
Puedes configurar una ruta de Cloud Storage y una base de datos únicas para cada tabla migrada. Para ello, sigue estos pasos para generar un archivo YAML de asignación de tablas que puedas usar en tu configuración de transferencia.
Crea un archivo YAML de configuración (con el sufijo
config.yaml) en el directorioDUMPER_BUCKETque contenga lo siguiente:type: object_rewriter relation: - match: relationRegex: ".*" external: location_expression: "'gs://MIGRATION_BUCKET/' + table.schema + '/' + table.name"
- Sustituye
MIGRATION_BUCKETpor el nombre del segmento de Cloud Storage de destino de los archivos de tabla migrados. El campolocation_expressiones una expresión del lenguaje de expresión común (CEL).
- Sustituye
Crea otro archivo YAML de configuración (con el sufijo
config.yaml) enDUMPER_BUCKETque contenga lo siguiente:type: experimental_object_rewriter relation: - match: schema: SOURCE_DATABASE outputName: database: null schema: TARGET_DATABASE
- Sustituye
SOURCE_DATABASEyTARGET_DATABASEpor el nombre de la base de datos de origen y la base de datos de Dataproc Metastore o el conjunto de datos de BigQuery, según el metastore elegido. Asegúrate de que el conjunto de datos de BigQuery exista si vas a configurar la base de datos para BigLake Metastore.
Para obtener más información sobre estos archivos YAML de configuración, consulta las directrices para crear un archivo YAML de configuración.
- Sustituye
Genera el archivo YAML de asignación de tablas con el siguiente comando:
curl -d '{ "tasks": { "string": { "type": "HiveQL2BigQuery_Translation", "translation_details": { "target_base_uri": "TRANSLATION_OUTPUT_BUCKET", "source_target_mapping": { "source_spec": { "base_uri": "DUMPER_BUCKET" } }, "target_types": ["metadata"] } } } }' \ -H "Content-Type:application/json" \ -H "Authorization: Bearer TOKEN" -X POST https://bigquerymigration.googleapis.com/v2alpha/projects/PROJECT_ID/locations/LOCATION/workflows
Haz los cambios siguientes:
TRANSLATION_OUTPUT_BUCKET: (Opcional) Especifica un segmento de Cloud Storage para la salida de la traducción. Para obtener más información, consulta Usar la salida de traducción.DUMPER_BUCKET: el URI base del bucket de Cloud Storage que contiene el archivohive-dumper-output.zipy el archivo YAML de configuración.TOKEN: el token de OAuth. Puedes generar este archivo en la línea de comandos con el comandogcloud auth print-access-token.PROJECT_ID: el proyecto para procesar la traducción.LOCATION: la ubicación en la que se procesa el trabajo. Por ejemplo,euous.
Monitoriza el estado de este trabajo. Cuando se completa, se genera un archivo de asignación para cada tabla de la base de datos en una ruta predefinida de
TRANSLATION_OUTPUT_BUCKET.
Orquestar la ejecución de dumper mediante el comando cron
Puedes automatizar las transferencias incrementales mediante un trabajo cron para ejecutar la herramienta dwh-migration-dumper. Al automatizar la extracción de metadatos, te aseguras de que haya disponible un volcado actualizado de Hadoop para las ejecuciones de transferencia incremental posteriores.
Antes de empezar
Antes de usar esta secuencia de comandos de automatización, completa los requisitos previos de instalación de dumper. Para ejecutar la secuencia de comandos, debes tener instalada la herramienta dwh-migration-dumper y configurados los permisos de gestión de identidades y accesos necesarios.
Programar la automatización
Guarda la siguiente secuencia de comandos en un archivo local. Esta secuencia de comandos se ha diseñado para que la configure y ejecute un daemon
croncon el fin de automatizar el proceso de extracción y subida de la salida de dumper:#!/bin/bash # Exit immediately if a command exits with a non-zero status. set -e # Treat unset variables as an error when substituting. set -u # Pipelines return the exit status of the last command to exit with a non-zero status. set -o pipefail # These values are used if not overridden by command-line options. DUMPER_EXECUTABLE="DUMPER_PATH/dwh-migration-dumper" GCS_BASE_PATH="gs://PATH_TO_DUMPER_OUTPUT" LOCAL_BASE_DIR="LOCAL_BASE_DIRECTORY_PATH" # Function to display usage information usage() { echo "Usage: $0 [options]" echo "" echo "Runs the dwh-migration-dumper tool and uploads its output to provided GCS path." echo "" echo "Options:" echo " --dumper-executable
The full path to the dumper executable. (Required)" echo " --gcs-base-pathThe base GCS path for output files. (Required)" echo " --local-base-dirThe local base directory for logs and temp files. (Required)" echo " -h, --help Display this help message and exit." exit 1 } # This loop processes command-line options and overrides the default configuration. while [[ "$#" -gt 0 ]]; do case $1 in --dumper-executable) DUMPER_EXECUTABLE="$2" shift # past argument shift # past value ;; --gcs-base-path) GCS_BASE_PATH="$2" shift shift ;; --local-base-dir) LOCAL_BASE_DIR="$2" shift shift ;; -h|--help) usage ;; *) echo "Unknown option: $1" usage ;; esac done # This runs AFTER parsing arguments to ensure no placeholder values are left. if [[ "$DUMPER_EXECUTABLE" == "DUMPER_PATH"* || "$GCS_BASE_PATH" == "gs://PATH_TO_DUMPER_OUTPUT" || "$LOCAL_BASE_DIR" == "LOCAL_BASE_DIRECTORY_PATH" ]]; then echo "ERROR: One or more configuration variables have not been set. Please provide them as command-line arguments or edit the script." >&2 echo "Run with --help for more information." >&2 exit 1 fi # Create unique timestamp and directories for this run EPOCH=$(date +%s) LOCAL_LOG_DIR="${LOCAL_BASE_DIR}/logs" mkdir -p "${LOCAL_LOG_DIR}" # Ensures the base and logs directories exist # Define the unique log and zip file path for this run LOG_FILE="${LOCAL_LOG_DIR}/dumper_execution_${EPOCH}.log" ZIP_FILE_NAME="hive-dumper-output_${EPOCH}.zip" LOCAL_ZIP_PATH="${LOCAL_BASE_DIR}/${ZIP_FILE_NAME}" echo "Script execution started. All subsequent output will be logged to: ${LOG_FILE}" # --- Helper Functions --- log() { echo "$(date '+%Y-%m-%d %H:%M:%S') - $@" >> "${LOG_FILE}"} cleanup() { local path_to_remove="$1" log "Cleaning up local file/directory: ${path_to_remove}..." rm -rf "${path_to_remove}" } # This function is called when the script exits to ensure cleanup and logging happen reliably. handle_exit() { local exit_code=$? # Only run the failure logic if the script is exiting with an error if [[ ${exit_code} -ne 0 ]]; then log "ERROR: Script is exiting with a failure code (${exit_code})." local gcs_log_path_on_failure="${GCS_BASE_PATH}/logs/$(basename "${LOG_FILE}")" log "Uploading log file to ${gcs_log_path_on_failure} for debugging..." # Attempt to upload the log file on failure, but don't let this command cause the script to exit. gsutil cp "${LOG_FILE}" "${gcs_log_path_on_failure}" > /dev/null 2>&1 || log "WARNING: Failed to upload log file to GCS." else # SUCCESS PATH log "Script finished successfully. Now cleaning up local zip file...." # Clean up the local zip file ONLY on success cleanup "${LOCAL_ZIP_PATH}" fi log "*****Script End*****" exit ${exit_code} } # Trap the EXIT signal to run the handle_exit function, ensuring cleanup always happens. trap handle_exit EXIT # Validates the dumper log file based on a strict set of rules. validate_dumper_output() { local log_file_to_check="$1" # Check for the specific success message from the dumper tool. if grep -q "Dumper execution: SUCCEEDED" "${log_file_to_check}"; then log "Validation Successful: Found 'Dumper execution: SUCCEEDED' message." return 0 # Success else log "ERROR: Validation failed. The 'Dumper execution: SUCCEEDED' message was not found." return 1 # Failure fi } # --- Main Script Logic --- log "*****Script Start*****" log "Dumper Executable: ${DUMPER_EXECUTABLE}" log "GCS Base Path: ${GCS_BASE_PATH}" log "Local Base Directory: ${LOCAL_BASE_DIR}" # Use an array to build the command safely dumper_command_args=( "--connector" "hiveql" "--output" "${LOCAL_ZIP_PATH}" ) log "Starting dumper tool execution..." log "COMMAND: ${DUMPER_EXECUTABLE} ${dumper_command_args[*]}" "${DUMPER_EXECUTABLE}" "${dumper_command_args[@]}" >> "${LOG_FILE}" 2>&1 log "Dumper process finished." # Validate the output from the dumper execution for success or failure. validate_dumper_output "${LOG_FILE}" # Upload the ZIP file to GCS gcs_zip_path="${GCS_BASE_PATH}/${ZIP_FILE_NAME}" log "Uploading ${LOCAL_ZIP_PATH} to ${gcs_zip_path}..." if [ ! -f "${LOCAL_ZIP_PATH}" ]; then log "ERROR: Expected ZIP file ${LOCAL_ZIP_PATH} not found after dumper execution." # The script will exit here with an error code, and the trap will run. exit 1 fi gsutil cp "${LOCAL_ZIP_PATH}" "${gcs_zip_path}" >> "${LOG_FILE}" 2>&1 log "Upload to GCS successful." # The script will now exit with code 0. The trap will call cleanup and log the script end.Ejecuta el siguiente comando para que el script sea ejecutable:
chmod +x PATH_TO_SCRIPT
Programa la secuencia de comandos con
crontaby sustituye las variables por los valores adecuados para tu tarea. Añade una entrada para programar el trabajo. En el siguiente ejemplo, la secuencia de comandos se ejecuta todos los días a las 2:30:# Run the Hive dumper daily at 2:30 AM for incremental BigQuery transfer. 30 2 * * * PATH_TO_SCRIPT \ --dumper-executable PATH_TO_DUMPER_EXECUTABLE \ --gcs-base-path GCS_PATH_TO_UPLOAD_DUMPER_OUTPUT \ --local-base-dir LOCAL_PATH_TO_SAVE_INTERMEDIARY_FILES
Al crear la transferencia, asegúrese de que el campo
table_metadata_pathtenga el mismo valor que el campoGCS_PATH_TO_UPLOAD_DUMPER_OUTPUT. Esta es la ruta que contiene los archivos ZIP de salida del dumper.
Consideraciones sobre la programación
Para evitar que los datos estén obsoletos, el volcado de metadatos debe estar listo antes de que empiece la transferencia programada. Configura la cronfrecuencia de la tarea según corresponda.
Te recomendamos que ejecutes el script manualmente varias veces para determinar el tiempo medio que tarda la herramienta de volcado en generar el resultado. Usa esta programación para definir una cron que preceda de forma segura a la transferencia de DTS y asegure la actualización.
Monitorizar transferencias de tablas gestionadas de Hive
Después de programar la transferencia de tablas gestionadas de Hive, puedes monitorizar el trabajo de transferencia con comandos de la herramienta de línea de comandos bq. Para obtener información sobre cómo monitorizar tus trabajos de transferencia, consulta Ver tus transferencias.
Hacer un seguimiento del estado de la migración de tablas
También puedes ejecutar la herramienta dwh-dts-status para monitorizar el estado de todas las tablas transferidas en una configuración de transferencia o en una base de datos concreta. También puedes usar la herramienta dwh-dts-status
para enumerar todas las configuraciones de transferencia de un proyecto.
Antes de empezar
Para poder usar la herramienta dwh-dts-status, haz lo siguiente:
Obtén la herramienta
dwh-dts-statusdescargando el paquetedwh-migration-tooldel repositorio de GitHubdwh-migration-tools.Autentica tu cuenta en Google Cloud con el siguiente comando:
gcloud auth application-default loginPara obtener más información, consulta Cómo funcionan las credenciales predeterminadas de la aplicación.
Comprueba que el usuario tenga los roles
bigquery.adminylogging.viewer. Para obtener más información sobre los roles de gestión de identidades y accesos, consulta la referencia de control de acceso.
Mostrar todas las configuraciones de transferencia de un proyecto
Para enumerar todas las configuraciones de transferencia de un proyecto, usa el siguiente comando:
./dwh-dts-status --list-transfer-configs --project-id=[PROJECT_ID] --location=[LOCATION]
Haz los cambios siguientes:
PROJECT_ID: el ID del proyecto Google Cloud que está ejecutando las transferencias.LOCATION: la ubicación en la que se creó la configuración de la transferencia.
Este comando genera una tabla con una lista de nombres e IDs de configuración de transferencia.
Ver los estados de todas las tablas de una configuración
Para ver el estado de todas las tablas incluidas en una configuración de transferencia, usa el siguiente comando:
./dwh-dts-status --list-status-for-config --project-id=[PROJECT_ID] --config-id=[CONFIG_ID] --location=[LOCATION]
Haz los cambios siguientes:
PROJECT_ID: el ID del proyecto Google Cloud que está ejecutando las transferencias.LOCATION: la ubicación en la que se creó la configuración de la transferencia.CONFIG_ID: el ID de la configuración de transferencia especificada.
Este comando genera una tabla con una lista de tablas y su estado de transferencia en la configuración de transferencia especificada. El estado de la transferencia puede ser uno de los siguientes valores: PENDING, RUNNING, SUCCEEDED, FAILED o CANCELLED.
Ver los estados de todas las tablas de una base de datos
Para ver el estado de todas las tablas transferidas desde una base de datos específica, usa el siguiente comando:
./dwh-dts-status --list-status-for-database --project-id=[PROJECT_ID] --database=[DATABASE]
Haz los cambios siguientes:
PROJECT_ID: el ID del proyecto Google Cloud que está ejecutando las transferencias.DATABASE:el nombre de la base de datos especificada.
Este comando genera una tabla con una lista de tablas y su estado de transferencia en la base de datos especificada. El estado de la transferencia puede ser uno de los siguientes valores: PENDING, RUNNING, SUCCEEDED, FAILED o CANCELLED.