
Hive マネージド テーブルを Google Cloudに移行する
このドキュメントでは、Hive マネージド テーブルを Google Cloudに移行する方法について説明します。
BigQuery Data Transfer Service の Hive マネージド テーブル移行コネクタを使用すると、オンプレミス環境とクラウド環境の両方から Google Cloudに、Hive metastore で管理されているテーブルをシームレスに移行できます。このコネクタは、Hive 形式と Iceberg 形式の両方をサポートしています。HDFS または Amazon S3 でのファイル ストレージがサポートされています。
Hive マネージド テーブル移行コネクタを使用すると、Cloud Storage をファイル ストレージとして使用しながら、Hive マネージド テーブルを Dataproc Metastore、BigLake Metastore、BigLake Metastore Iceberg REST カタログに登録できます。
次の図は、Hadoop クラスタからのテーブル移行プロセスの概要を示しています。
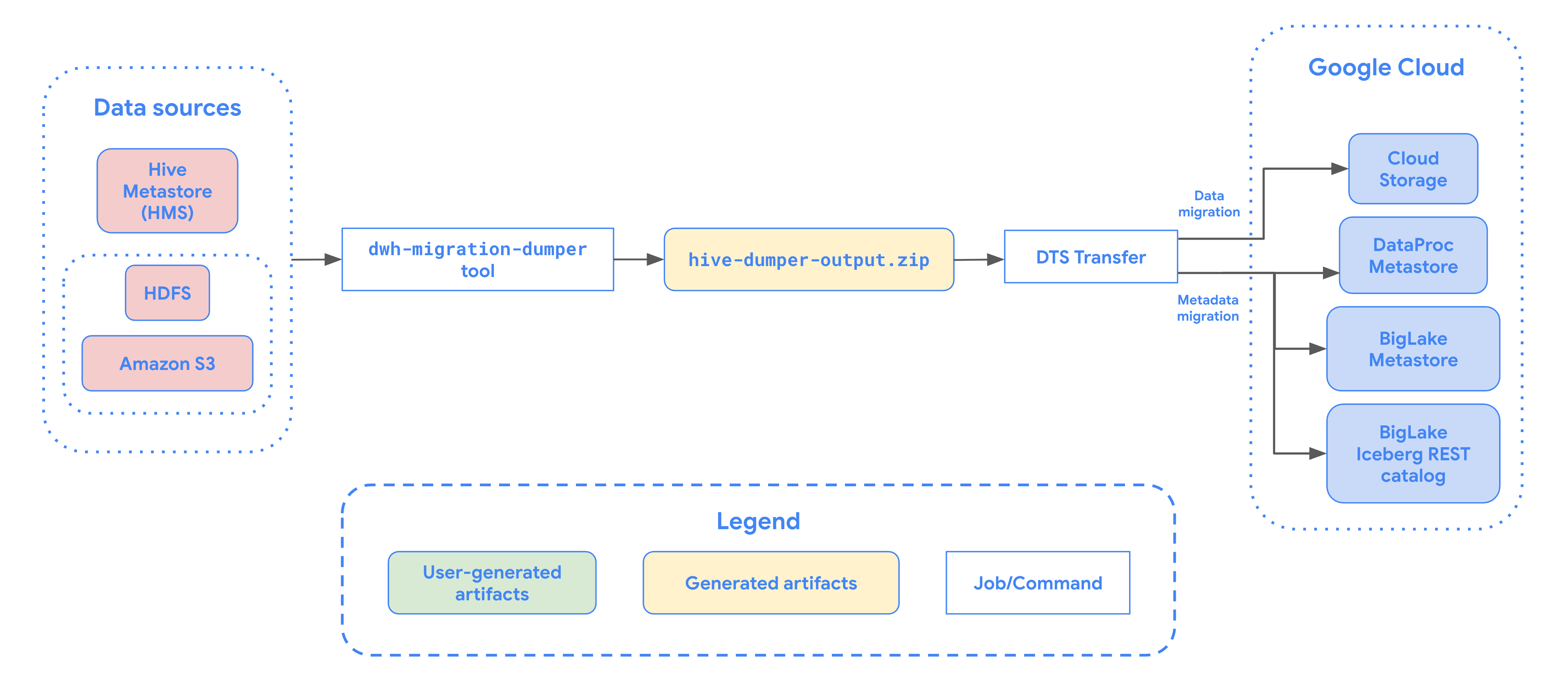
制限事項
Hive マネージド テーブルの転送には、次の制限があります。
- Apache Iceberg テーブルを移行するには、オープンソース エンジン(Apache Spark や Flink など)に書き込みアクセスを、BigQuery に読み取りアクセスを許可できるよう、BigLake Metastore にテーブルを登録する必要があります。
- Hive マネージド テーブルを移行するには、オープンソース エンジンに書き込みアクセスを、BigQuery に読み取りアクセスを許可できるよう、Dataproc Metastore にテーブルを登録する必要があります。
- Hive マネージド テーブルを BigQuery に移行するには、bq コマンドライン ツールを使用する必要があります。
始める前に
Hive マネージド テーブルの転送をスケジュールする前に、次の操作を行う必要があります。
Apache Hive のメタデータ ファイルを生成する
dwh-migration-dumper ツールを実行して、Apache Hive のメタデータを抽出します。このツールは、hive-dumper-output.zip という名前のファイルを Cloud Storage バケット(このドキュメントでは DUMPER_BUCKET と呼びます)に生成します。
API を有効にする
Google Cloud プロジェクトで次の API を有効にします。
- Data Transfer API
- Storage Transfer API
Data Transfer API を有効にすると、サービス エージェントが作成されます。
権限を構成する
- サービス アカウントを作成し、BigQuery 管理者ロール(
roles/bigquery.admin)を付与します。このサービス アカウントは、転送構成の作成に使用されます。 Data Transfer API を有効にすると、サービス エージェント(P4SA)が作成されます。次のロールを付与します。
roles/metastore.metadataOwnerroles/storagetransfer.adminroles/serviceusage.serviceUsageConsumerroles/storage.objectAdmin- BigLake Iceberg テーブルのメタデータを移行する場合は、
roles/bigquery.adminロールも付与する必要があります。 - メタデータを BigLake metastore Iceberg REST カタログに移行する場合は、
roles/biglake.adminロールも付与する必要があります。
- BigLake Iceberg テーブルのメタデータを移行する場合は、
次のコマンドを使用して、サービス エージェントに
roles/iam.serviceAccountTokenCreatorロールを付与します。gcloud iam service-accounts add-iam-policy-binding SERVICE_ACCOUNT --member serviceAccount:service-PROJECT_NUMBER@gcp-sa-bigquerydatatransfer.iam.gserviceaccount.com --role roles/iam.serviceAccountTokenCreator
HDFS データレイク用に Storage Transfer エージェントを構成する
ファイルが HDFS に保存されている場合は必須です。HDFS データレイクの転送に必要な Storage Transfer エージェントを設定するには、次の操作を行います。
- Hadoop クラスタで Storage Transfer エージェントを実行するように権限を構成します。
- オンプレミス エージェント マシンに Docker をインストールします。
- Google Cloud プロジェクトに Storage Transfer Service エージェント プールを作成します。
- オンプレミス エージェント マシンにエージェントをインストールします。
Amazon S3 に Storage Transfer Service 権限を構成する
ファイルが Amazon S3 に保存されている場合に必要です。Amazon S3 からの転送はエージェントレス転送であり、特定の権限が必要です。Amazon S3 転送用に Storage Transfer Service を構成するには、次の操作を行います。
- エージェントレス転送の権限を構成する。
- AWS Amazon S3 のアクセス認証情報を設定する。
- アクセス認証情報を設定したら、アクセスキー ID とシークレット アクセスキーをメモします。
- AWS プロジェクトで IP 制限を使用する場合は、Storage Transfer Service ワーカーで使用される IP 範囲を追加します。
Hive マネージド テーブルの転送をスケジュールする
次のオプションのいずれかを選択します。
コンソール
Google Cloud コンソールの [データ転送] ページに移動します。
[転送を作成] をクリックします。
[ソースタイプ] セクションで、[ソース] リストから [Hive Managed Tables] を選択します。
[ロケーション] で、ロケーション タイプを選択し、リージョンを選択します。
[転送構成名] セクションの [表示名] に、データ転送の名前を入力します。
[スケジュール オプション] セクションで、次の操作を行います。
- [繰り返しの頻度] リストで、この転送の実行頻度を指定するオプションを選択します。カスタムの繰り返しの頻度を指定するには、[カスタム] を選択します。[オンデマンド] を選択した場合、手動で転送をトリガーすると、この転送が実行されます。
- 必要に応じて、[すぐに開始] を選択するか、[設定した時刻に開始] を選択して開始日と実行時間を指定します。
[データソースの詳細] セクションで、次のようにします。
- [Table name patterns] で、HDFS データベース内のテーブルと一致するテーブル名またはパターンを指定して、転送する HDFS データレイク テーブルを指定します。テーブル パターンを指定するには、Java の正規表現の構文を使用する必要があります。例:
db1..*は db1 内のすべてのテーブルを照合します。db1.table1;db2.table2は、db1 の table1 と db2 の table2 に一致します。
- [BQMS discovery dump gcs path] に、Apache Hive のメタデータ ファイルを作成したときに生成した
hive-dumper-output.zipファイルを含むバケットのパスを入力します。 - プルダウン リストから metastore のタイプを選択します。
DATAPROC_METASTORE: メタデータを Dataproc Metastore に保存する場合は、このオプションを選択します。[Dataproc metastore url] で Dataproc Metastore の URL を指定する必要があります。BIGLAKE_METASTORE: メタデータを BigLake metastore に保存する場合は、このオプションを選択します。[BigQuery データセット] で BigQuery データセットを指定する必要があります。BIGLAKE_REST_CATALOG: メタデータを BigLake metastore Iceberg REST カタログに保存する場合は、このオプションを選択します。
[Destination gcs path] に、移行したデータを保存する Cloud Storage バケットへのパスを入力します。
省略可: [サービス アカウント] に、このデータ転送で使用するサービス アカウントを入力します。サービス アカウントは、転送構成と宛先データセットが作成されたのと同じGoogle Cloud プロジェクトに属している必要があります。
省略可: [Use translation output] を有効にして、移行するテーブルごとに一意の Cloud Storage パスとデータベースを設定できます。これを行うには、[BQMS translation output gcs path] フィールドに、変換結果を含む Cloud Storage フォルダのパスを指定します。詳細については、変換の出力を構成するをご覧ください。
- 変換出力の Cloud Storage パスを指定すると、宛先の Cloud Storage パスと BigQuery データセットは、そのパス内のファイルから取得されます。
[ストレージの種類] で、次のいずれかのオプションを選択します。
HDFS: ファイル ストレージがHDFSの場合は、このオプションを選択します。[STS agent pool name] フィールドには、Storage Transfer Agent を構成したときに作成したエージェント プールの名前を指定する必要があります。S3: ファイル ストレージがAmazon S3の場合は、このオプションを選択します。[アクセスキー ID] フィールドと [シークレット アクセスキー] フィールドには、アクセス認証情報を設定したときに作成したアクセスキー ID とシークレット アクセスキーを指定する必要があります。
- [Table name patterns] で、HDFS データベース内のテーブルと一致するテーブル名またはパターンを指定して、転送する HDFS データレイク テーブルを指定します。テーブル パターンを指定するには、Java の正規表現の構文を使用する必要があります。例:
bq
Hive マネージド テーブルの転送のスケジュールを設定するには、以下のように bq mk コマンドを入力して、転送作成フラグ --transfer_config を指定します。
bq mk --transfer_config --data_source=hadoop --display_name='TRANSFER_NAME' --service_account_name='SERVICE_ACCOUNT' --project_id='PROJECT_ID' --location='REGION' --params='{"table_name_patterns":"LIST_OF_TABLES", "table_metadata_path":"gs://DUMPER_BUCKET/hive-dumper-output.zip", "target_gcs_file_path":"gs://MIGRATION_BUCKET", "metastore":"METASTORE", "destination_dataproc_metastore":"DATAPROC_METASTORE_URL", "destination_bigquery_dataset":"BIGLAKE_METASTORE_DATASET", "translation_output_gcs_path":"gs://TRANSLATION_OUTPUT_BUCKET/metadata/config/default_database/", "storage_type":"STORAGE_TYPE", "agent_pool_name":"AGENT_POOL_NAME", "aws_access_key_id":"AWS_ACCESS_KEY_ID", "aws_secret_access_key":"AWS_SECRET_ACCESS_KEY" }'
次のように置き換えます。
TRANSFER_NAME: 転送構成の表示名。転送名には、後で修正が必要になった場合に識別できる任意の名前を使用できます。SERVICE_ACCOUNT: 転送の認証に使用されるサービス アカウント名。サービス アカウントは、転送の作成に使用したproject_idが所有している必要があります。また、必要な権限がすべて付与されている必要があります。PROJECT_ID: 実際の Google Cloud プロジェクト ID。--project_idで特定のプロジェクトを指定しない場合は、デフォルトのプロジェクトが使用されます。REGION: この転送構成のロケーション。LIST_OF_TABLES: 転送するエンティティのリスト。階層型の命名規則(database.table)を使用します。このフィールドでは、RE2 正規表現を使用してテーブルを指定できます。次に例を示します。db1..*: データベース内のすべてのテーブルを指定します。db1.table1;db2.table2: テーブルのリストを指定します。
DUMPER_BUCKET:hive-dumper-output.zipファイルを含む Cloud Storage バケット。MIGRATION_BUCKET: すべての基盤となるファイルが読み込まれる宛先 GCS パス。METASTORE: 移行先のメタストアのタイプ。次のいずれかの値に設定します。DATAPROC_METASTORE: メタデータを Dataproc Metastore に転送します。BIGLAKE_METASTORE: メタデータを BigLake metastore に転送します。BIGLAKE_REST_CATALOG: メタデータを BigLake metastore Iceberg REST カタログに転送します。
DATAPROC_METASTORE_URL: Dataproc Metastore の URL。metastoreがDATAPROC_METASTOREの場合は必須です。BIGLAKE_METASTORE_DATASET: BigLake metastore の BigQuery データセット。metastoreがBIGLAKE_METASTOREの場合は必須です。TRANSLATION_OUTPUT_BUCKET:(省略可)変換出力用の Cloud Storage バケットを指定します。詳細については、変換出力の使用をご覧ください。STORAGE_TYPE: テーブルの基盤となるファイル ストレージを指定します。サポートされるタイプはHDFSとS3です。AGENT_POOL_NAME: エージェントの作成に使用されるエージェント プールの名前。storage_typeがHDFSの場合は必須です。AWS_ACCESS_KEY_ID: アクセス認証情報のアクセスキー ID。storage_typeがS3の場合は必須です。AWS_SECRET_ACCESS_KEY: アクセス認証情報のシークレット アクセスキー。storage_typeがS3の場合は必須です。
このコマンドを実行して転送構成を作成し、Hive マネージド テーブルの転送を開始します。転送は、デフォルトで 24 時間ごとに実行するようにスケジュール設定されていますが、転送スケジュールのオプションで構成できます。
転送が完了すると、Hadoop クラスタのテーブルが MIGRATION_BUCKET に移行されます。
データの取り込みオプション
以降のセクションでは、Hive マネージド テーブルの転送を構成する方法について詳しく説明します。
増分転送
転送構成が定期的なスケジュールで設定されている場合、後続の転送が実行されるたびに、移行元テーブルに加えられた最新の更新を反映するように Google Cloud のテーブルが更新されます。たとえば、スキーマ変更に伴うすべての挿入、削除、更新オペレーションが転送のたびに Google Cloud に反映されます。
転送のスケジュール設定オプション
デフォルトでは、転送は 24 時間ごとに実行されるようにスケジュール設定されています。転送の実行頻度を構成するには、転送構成に --schedule フラグを追加し、schedule 構文を使用して転送スケジュールを指定します。Hive マネージド テーブルの転送では、転送の実行間隔を 24 時間以上にする必要があります。
1 回限りの転送の場合は、転送構成に end_time フラグを追加して、転送を 1 回だけ実行できます。
変換出力を構成する
移行されたテーブルごとに、一意の Cloud Storage パスとデータベースを構成できます。これを行うには、次の手順で、転送構成で使用できるテーブル マッピング YAML ファイルを生成します。
DUMPER_BUCKETに、次の内容を含む構成 YAML ファイルを作成します(接尾辞はconfig.yaml)。type: object_rewriter relation: - match: relationRegex: ".*" external: location_expression: "'gs://MIGRATION_BUCKET/' + table.schema + '/' + table.name"
MIGRATION_BUCKETは、テーブル ファイルの移行先となる Cloud Storage バケットの名前に置き換えます。location_expressionフィールドは、Common Expression Language(CEL)式です。
DUMPER_BUCKETに、次の内容を含む別の構成 YAML ファイルを作成します(接尾辞はconfig.yaml)。type: experimental_object_rewriter relation: - match: schema: SOURCE_DATABASE outputName: database: null schema: TARGET_DATABASE
SOURCE_DATABASEとTARGET_DATABASEは、選択した metastore に応じて、ソース データベース名と Dataproc metastore データベースまたは BigQuery データセットの名前に置き換えます。BigLake metastore 用にデータベースを構成する場合は、BigQuery データセットが存在することを確認します。
これらの構成 YAML の詳細については、YAML 構成ファイルを作成するためのガイドラインをご覧ください。
次のコマンドを使用して、テーブル マッピング YAML ファイルを生成します。
curl -d '{ "tasks": { "string": { "type": "HiveQL2BigQuery_Translation", "translation_details": { "target_base_uri": "TRANSLATION_OUTPUT_BUCKET", "source_target_mapping": { "source_spec": { "base_uri": "DUMPER_BUCKET" } }, "target_types": ["metadata"] } } } }' \ -H "Content-Type:application/json" \ -H "Authorization: Bearer TOKEN" -X POST https://bigquerymigration.googleapis.com/v2alpha/projects/PROJECT_ID/locations/LOCATION/workflows
次のように置き換えます。
TRANSLATION_OUTPUT_BUCKET:(省略可)変換出力用の Cloud Storage バケットを指定します。詳細については、変換出力の使用をご覧ください。DUMPER_BUCKET:hive-dumper-output.zipと構成 YAML ファイルを格納している Cloud Storage バケットのベース URI。TOKEN: OAuth トークン。これは、コマンドラインでコマンドgcloud auth print-access-tokenを使用して生成できます。PROJECT_ID: 変換を処理するプロジェクト。LOCATION: ジョブが処理されるロケーション。たとえば、euやusです。
このジョブのステータスをモニタリングします。完了すると、データベース内の各テーブルのマッピング ファイルが
TRANSLATION_OUTPUT_BUCKETの事前定義されたパスに生成されます。
cron コマンドを使用してダンパーの実行をオーケストレートする
cron ジョブを使用して dwh-migration-dumper ツールを実行することで、増分転送を自動化できます。メタデータの抽出を自動化することで、後続の増分転送実行で Hadoop からの最新のダンプを利用できます。
始める前に
この自動化スクリプトを使用する前に、ダンパーのインストールの前提条件を完了してください。スクリプトを実行するには、dwh-migration-dumper ツールがインストールされ、必要な IAM 権限が構成されている必要があります。
自動化のスケジューリング
次のスクリプトをローカル ファイルに保存します。このスクリプトは、
cronデーモンによって構成および実行され、ダンパー出力の抽出とアップロードのプロセスを自動化するように設計されています。#!/bin/bash # Exit immediately if a command exits with a non-zero status. set -e # Treat unset variables as an error when substituting. set -u # Pipelines return the exit status of the last command to exit with a non-zero status. set -o pipefail # These values are used if not overridden by command-line options. DUMPER_EXECUTABLE="DUMPER_PATH/dwh-migration-dumper" GCS_BASE_PATH="gs://PATH_TO_DUMPER_OUTPUT" LOCAL_BASE_DIR="LOCAL_BASE_DIRECTORY_PATH" # Function to display usage information usage() { echo "Usage: $0 [options]" echo "" echo "Runs the dwh-migration-dumper tool and uploads its output to provided GCS path." echo "" echo "Options:" echo " --dumper-executable
The full path to the dumper executable. (Required)" echo " --gcs-base-pathThe base GCS path for output files. (Required)" echo " --local-base-dirThe local base directory for logs and temp files. (Required)" echo " -h, --help Display this help message and exit." exit 1 } # This loop processes command-line options and overrides the default configuration. while [[ "$#" -gt 0 ]]; do case $1 in --dumper-executable) DUMPER_EXECUTABLE="$2" shift # past argument shift # past value ;; --gcs-base-path) GCS_BASE_PATH="$2" shift shift ;; --local-base-dir) LOCAL_BASE_DIR="$2" shift shift ;; -h|--help) usage ;; *) echo "Unknown option: $1" usage ;; esac done # This runs AFTER parsing arguments to ensure no placeholder values are left. if [[ "$DUMPER_EXECUTABLE" == "DUMPER_PATH"* || "$GCS_BASE_PATH" == "gs://PATH_TO_DUMPER_OUTPUT" || "$LOCAL_BASE_DIR" == "LOCAL_BASE_DIRECTORY_PATH" ]]; then echo "ERROR: One or more configuration variables have not been set. Please provide them as command-line arguments or edit the script." >&2 echo "Run with --help for more information." >&2 exit 1 fi # Create unique timestamp and directories for this run EPOCH=$(date +%s) LOCAL_LOG_DIR="${LOCAL_BASE_DIR}/logs" mkdir -p "${LOCAL_LOG_DIR}" # Ensures the base and logs directories exist # Define the unique log and zip file path for this run LOG_FILE="${LOCAL_LOG_DIR}/dumper_execution_${EPOCH}.log" ZIP_FILE_NAME="hive-dumper-output_${EPOCH}.zip" LOCAL_ZIP_PATH="${LOCAL_BASE_DIR}/${ZIP_FILE_NAME}" echo "Script execution started. All subsequent output will be logged to: ${LOG_FILE}" # --- Helper Functions --- log() { echo "$(date '+%Y-%m-%d %H:%M:%S') - $@" >> "${LOG_FILE}"} cleanup() { local path_to_remove="$1" log "Cleaning up local file/directory: ${path_to_remove}..." rm -rf "${path_to_remove}" } # This function is called when the script exits to ensure cleanup and logging happen reliably. handle_exit() { local exit_code=$? # Only run the failure logic if the script is exiting with an error if [[ ${exit_code} -ne 0 ]]; then log "ERROR: Script is exiting with a failure code (${exit_code})." local gcs_log_path_on_failure="${GCS_BASE_PATH}/logs/$(basename "${LOG_FILE}")" log "Uploading log file to ${gcs_log_path_on_failure} for debugging..." # Attempt to upload the log file on failure, but don't let this command cause the script to exit. gsutil cp "${LOG_FILE}" "${gcs_log_path_on_failure}" > /dev/null 2>&1 || log "WARNING: Failed to upload log file to GCS." else # SUCCESS PATH log "Script finished successfully. Now cleaning up local zip file...." # Clean up the local zip file ONLY on success cleanup "${LOCAL_ZIP_PATH}" fi log "*****Script End*****" exit ${exit_code} } # Trap the EXIT signal to run the handle_exit function, ensuring cleanup always happens. trap handle_exit EXIT # Validates the dumper log file based on a strict set of rules. validate_dumper_output() { local log_file_to_check="$1" # Check for the specific success message from the dumper tool. if grep -q "Dumper execution: SUCCEEDED" "${log_file_to_check}"; then log "Validation Successful: Found 'Dumper execution: SUCCEEDED' message." return 0 # Success else log "ERROR: Validation failed. The 'Dumper execution: SUCCEEDED' message was not found." return 1 # Failure fi } # --- Main Script Logic --- log "*****Script Start*****" log "Dumper Executable: ${DUMPER_EXECUTABLE}" log "GCS Base Path: ${GCS_BASE_PATH}" log "Local Base Directory: ${LOCAL_BASE_DIR}" # Use an array to build the command safely dumper_command_args=( "--connector" "hiveql" "--output" "${LOCAL_ZIP_PATH}" ) log "Starting dumper tool execution..." log "COMMAND: ${DUMPER_EXECUTABLE} ${dumper_command_args[*]}" "${DUMPER_EXECUTABLE}" "${dumper_command_args[@]}" >> "${LOG_FILE}" 2>&1 log "Dumper process finished." # Validate the output from the dumper execution for success or failure. validate_dumper_output "${LOG_FILE}" # Upload the ZIP file to GCS gcs_zip_path="${GCS_BASE_PATH}/${ZIP_FILE_NAME}" log "Uploading ${LOCAL_ZIP_PATH} to ${gcs_zip_path}..." if [ ! -f "${LOCAL_ZIP_PATH}" ]; then log "ERROR: Expected ZIP file ${LOCAL_ZIP_PATH} not found after dumper execution." # The script will exit here with an error code, and the trap will run. exit 1 fi gsutil cp "${LOCAL_ZIP_PATH}" "${gcs_zip_path}" >> "${LOG_FILE}" 2>&1 log "Upload to GCS successful." # The script will now exit with code 0. The trap will call cleanup and log the script end.次のコマンドを実行して、スクリプトを実行可能にします。
chmod +x PATH_TO_SCRIPT
crontabを使用してスクリプトをスケジュールし、変数をジョブに適した値に置き換えます。ジョブをスケジュールするエントリを追加します。次の例では、スクリプトは毎日午前 2 時 30 分に実行されます。# Run the Hive dumper daily at 2:30 AM for incremental BigQuery transfer. 30 2 * * * PATH_TO_SCRIPT \ --dumper-executable PATH_TO_DUMPER_EXECUTABLE \ --gcs-base-path GCS_PATH_TO_UPLOAD_DUMPER_OUTPUT \ --local-base-dir LOCAL_PATH_TO_SAVE_INTERMEDIARY_FILES
転送を作成するときに、
table_metadata_pathフィールドがGCS_PATH_TO_UPLOAD_DUMPER_OUTPUTに構成した Cloud Storage パスと同じパスに設定されていることを確認します。これは、ダンパー出力 ZIP ファイルを含むパスです。
スケジューリングに関する考慮事項
データの古さを回避するには、スケジュールされた転送が開始される前にメタデータ ダンプを準備する必要があります。それに応じて cron ジョブの頻度を構成します。
スクリプトを数回手動で試行して、ダンパーツールが出力を生成する平均時間を特定することをおすすめします。このタイミングを使用して、DTS 転送の実行より前に、鮮度を確保できる cron スケジュールを設定します。
Hive マネージド テーブルの転送をモニタリングする
Hive マネージド テーブルの転送のスケジュールを設定したら、bq コマンドライン ツールのコマンドを使用して転送ジョブをモニタリングできます。転送ジョブのモニタリングについては、転送を表示するをご覧ください。
テーブルの移行ステータスをトラッキングする
dwh-dts-status ツールを実行して、転送構成または特定のデータベース内のすべての転送済みテーブルのステータスをモニタリングすることもできます。dwh-dts-status ツールを使用して、プロジェクト内のすべての転送構成を一覧表示することもできます。
始める前に
dwh-dts-status ツールを使用するには、まず次の操作を行います。
dwh-migration-toolsGitHub リポジトリからdwh-migration-toolパッケージをダウンロードして、dwh-dts-statusツールを入手します。次のコマンドを使用して、アカウントを Google Cloud に対して認証します。
gcloud auth application-default login詳細については、アプリケーションのデフォルト認証情報の仕組みをご覧ください。
ユーザーに
bigquery.adminロールとlogging.viewerロールがあることを確認します。IAM ロールの詳細については、アクセス制御のリファレンスをご覧ください。
プロジェクト内のすべての転送構成を一覧表示する
プロジェクト内のすべての転送構成を一覧表示するには、次のコマンドを使用します。
./dwh-dts-status --list-transfer-configs --project-id=[PROJECT_ID] --location=[LOCATION]
次のように置き換えます。
PROJECT_ID: 転送を実行している Google Cloud プロジェクト ID。LOCATION: 転送構成が作成されたロケーション。
このコマンドは、転送構成の名前と ID のリストを含むテーブルを出力します。
構成内のすべてのテーブルのステータスを表示する
転送構成に含まれるすべてのテーブルのステータスを表示するには、次のコマンドを使用します。
./dwh-dts-status --list-status-for-config --project-id=[PROJECT_ID] --config-id=[CONFIG_ID] --location=[LOCATION]
次のように置き換えます。
PROJECT_ID: 転送を実行している Google Cloud プロジェクト ID。LOCATION: 転送構成が作成されたロケーション。CONFIG_ID: 指定された転送構成の ID。
このコマンドは、指定された転送構成内のテーブルのリストと転送ステータスを含むテーブルを出力します。転送ステータスは、PENDING、RUNNING、SUCCEEDED、FAILED、CANCELLED のいずれかの値になります。
データベース内のすべてのテーブルのステータスを表示する
特定のデータベースから転送されたすべてのテーブルのステータスを表示するには、次のコマンドを使用します。
./dwh-dts-status --list-status-for-database --project-id=[PROJECT_ID] --database=[DATABASE]
次のように置き換えます。
PROJECT_ID: 転送を実行している Google Cloud プロジェクト ID。DATABASE: 指定したデータベースの名前。
このコマンドは、指定されたデータベース内のテーブルのリストとその転送ステータスを含むテーブルを出力します。転送ステータスは、PENDING、RUNNING、SUCCEEDED、FAILED、CANCELLED のいずれかの値になります。