
이 튜토리얼에서는 변환기 모델을 Open Neural Network Exchange (ONNX) 형식으로 내보내고, ONNX 모델을 BigQuery 데이터 세트로 가져온 후, 모델을 사용하여 SQL 쿼리에서 임베딩을 생성하는 방법을 보여줍니다.
이 튜토리얼에서는 sentence-transformers/all-MiniLM-L6-v2 모델을 사용합니다.
이 문장 트랜스포머 모델은 문장 임베딩을 생성할 때 빠르고 효과적인 성능을 제공하는 것으로 알려져 있습니다. 문장 임베딩은 텍스트의 기본 의미를 포착하여 시맨틱 검색, 클러스터링, 문장 유사성과 같은 작업을 지원합니다.
ONNX는 모든 머신러닝(ML) 프레임워크를 나타내도록 설계된 균일한 형식을 제공합니다. ONNX에 대한 BigQuery ML 지원을 통해 다음을 수행할 수 있습니다.
- 원하는 프레임워크를 사용하여 모델을 학습시키기
- ONNX 모델 형식으로 모델 변환
- ONNX 모델을 BigQuery로 가져와 BigQuery ML을 사용하여 예측 수행
목표
- Hugging Face Optimum CLI를 사용하여
sentence-transformers/all-MiniLM-L6-v2모델을 ONNX로 내보냅니다. CREATE MODEL문을 사용하여 ONNX 모델을 BigQuery로 가져옵니다.ML.PREDICT함수를 사용하여 가져온 ONNX 모델로 임베딩을 생성합니다.
비용
이 문서에서는 비용이 청구될 수 있는 Google Cloud구성요소를 사용합니다.
프로젝트 사용량을 기준으로 예상 비용을 산출하려면 가격 계산기를 사용하세요.
이 문서에 설명된 태스크를 완료했으면 만든 리소스를 삭제하여 청구가 계속되는 것을 방지할 수 있습니다. 자세한 내용은 삭제를 참조하세요.
시작하기 전에
- Google Cloud 계정에 로그인합니다. Google Cloud를 처음 사용하는 경우 계정을 만들고 Google 제품의 실제 성능을 평가해 보세요. 신규 고객에게는 워크로드를 실행, 테스트, 배포하는 데 사용할 수 있는 $300의 무료 크레딧이 제공됩니다.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
BigQuery 및 Cloud Storage API를 사용 설정합니다.
API 사용 설정에 필요한 역할
API를 사용 설정하려면
serviceusage.services.enable권한이 포함된 서비스 사용량 관리자 IAM 역할(roles/serviceusage.serviceUsageAdmin)이 필요합니다. 역할 부여 방법 알아보기- 이 문서의 태스크를 수행하는 데 필요한 권한이 있는지 확인합니다.
필요한 역할
새 프로젝트를 만드는 경우 개발자가 프로젝트 소유자이고 이 튜토리얼을 완료하는 데 필요한 모든 Identity and Access Management(IAM) 권한이 개발자에게 부여됩니다.
기존 프로젝트를 사용하는 경우 다음을 수행합니다.
프로젝트에 다음 역할이 있는지 확인합니다.
- BigQuery Studio 관리자 (
roles/bigquery.studioAdmin) - 스토리지 객체 생성자 (
roles/storage.objectCreator)
역할 확인
-
Google Cloud 콘솔에서 IAM 페이지로 이동합니다.
IAM으로 이동 - 프로젝트를 선택합니다.
-
주 구성원 열에서 나 또는 내가 속한 그룹을 식별하는 모든 행을 찾습니다. 내가 속한 그룹을 알아보려면 관리자에게 문의하세요.
- 나를 지정하거나 포함하는 모든 행의 역할 열을 확인하여 역할 목록에 필요한 역할이 포함되어 있는지 확인합니다.
역할 부여
-
Google Cloud 콘솔에서 IAM 페이지로 이동합니다.
IAM으로 이동 - 프로젝트를 선택합니다.
- 액세스 권한 부여를 클릭합니다.
-
새 주 구성원 필드에 사용자 식별자를 입력합니다. 일반적으로 Google 계정의 이메일 주소입니다.
- 역할 선택을 클릭한 후 역할을 검색합니다.
- 역할을 추가로 부여하려면 다른 역할 추가를 클릭하고 각 역할을 추가합니다.
- 저장을 클릭합니다.
BigQuery의 IAM 권한에 대한 자세한 내용은 IAM 권한을 참조하세요.
트랜스포머 모델 파일을 ONNX로 변환
원하는 경우 이 섹션의 단계에 따라 sentence-transformers/all-MiniLM-L6-v2 모델과 토큰화 도구를 ONNX로 수동으로 변환할 수 있습니다.
그렇지 않은 경우 이미 변환된 공개 gs://cloud-samples-data Cloud Storage 버킷의 샘플 파일을 사용할 수 있습니다.
파일을 수동으로 변환하려면 Python이 설치된 로컬 명령줄 환경이 있어야 합니다. Python 설치에 관한 자세한 내용은 Python 다운로드를 참고하세요.
트랜스포머 모델을 ONNX로 내보내기
Hugging Face Optimum CLI를 사용하여 sentence-transformers/all-MiniLM-L6-v2 모델을 ONNX로 내보냅니다.
Optimum CLI를 사용하여 모델을 내보내는 방법에 대한 자세한 내용은 optimum.exporters.onnx를 사용하여 모델을 ONNX로 내보내기를 참고하세요.
모델을 내보내려면 명령줄 환경을 열고 다음 단계를 따르세요.
Optimum CLI를 설치합니다.
pip install optimum[onnx]모델 내보내기
--model인수는 Hugging Face 모델 ID를 지정합니다.--opset인수는 ONNXRuntime 라이브러리 버전을 지정하며 BigQuery에서 지원하는 ONNXRuntime 라이브러리와의 호환성을 유지하기 위해17로 설정됩니다.optimum-cli export onnx \ --model sentence-transformers/all-MiniLM-L6-v2 \ --task sentence-similarity \ --opset 17 all-MiniLM-L6-v2/
모델 파일이 all-MiniLM-L6-v2 디렉터리에 model.onnx으로 내보내집니다.
트랜스포머 모델에 양자화 적용
Optimum CLI를 사용하여 내보낸 트랜스포머 모델에 양자화를 적용하여 모델 크기를 줄이고 추론 속도를 높입니다. 자세한 내용은 양자화를 참고하세요.
모델에 양자화를 적용하려면 명령줄에서 다음 명령어를 실행합니다.
optimum-cli onnxruntime quantize \
--onnx_model all-MiniLM-L6-v2/ \
--avx512_vnni -o all-MiniLM-L6-v2_quantized
양자화된 모델 파일은 all-MiniLM-L6-v2_quantized 디렉터리에 model_quantized.onnx으로 내보내집니다.
토큰 변환기를 ONNX로 변환
ONNX 형식의 트랜스포머 모델을 사용하여 임베딩을 생성하려면 일반적으로 토큰화 도구를 사용하여 모델에 대한 두 입력인 input_ids 및 attention_mask를 생성합니다.
이러한 입력을 생성하려면 onnxruntime-extensions 라이브러리를 사용하여 sentence-transformers/all-MiniLM-L6-v2 모델의 토큰화 도구를 ONNX 형식으로 변환하세요. 토큰 변환기를 변환한 후 원시 텍스트 입력에서 직접 토큰화를 실행하여 ONNX 예측을 생성할 수 있습니다.
토큰 변환기를 변환하려면 명령줄에서 다음 단계를 따르세요.
Optimum CLI를 설치합니다.
pip install optimum[onnx]원하는 텍스트 편집기를 사용하여
convert-tokenizer.py라는 파일을 만듭니다. 다음 예에서는 nano 텍스트 편집기를 사용합니다.nano convert-tokenizer.py다음 Python 스크립트를 복사하여
convert-tokenizer.py파일에 붙여넣습니다.from onnxruntime_extensions import gen_processing_models # Load the Huggingface tokenizer tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L6-v2") # Export the tokenizer to ONNX using gen_processing_models onnx_tokenizer_path = "tokenizer.onnx" # Generate the tokenizer ONNX model, and set the maximum token length. # Ensure 'max_length' is set to a value less than the model's maximum sequence length, failing to do so will result in error during inference. tokenizer_onnx_model = gen_processing_models(tokenizer, pre_kwargs={'max_length': 256})[0] # Modify the tokenizer ONNX model signature. # This is because certain tokenizers don't support batch inference. tokenizer_onnx_model.graph.input[0].type.tensor_type.shape.dim[0].dim_value = 1 # Save the tokenizer ONNX model with open(onnx_tokenizer_path, "wb") as f: f.write(tokenizer_onnx_model.SerializeToString())convert-tokenizer.py파일을 저장합니다.Python 스크립트를 실행하여 토큰화기를 변환합니다.
python convert-tokenizer.py
변환된 토크나이저가 all-MiniLM-L6-v2_quantized 디렉터리에 tokenizer.onnx으로 내보내집니다.
변환된 모델 파일을 Cloud Storage에 업로드
트랜스포머 모델과 토큰 변환기를 변환한 후 다음을 실행합니다.
- 변환된 파일을 저장할 Cloud Storage 버킷을 만듭니다.
- 변환된 트랜스포머 모델과 토큰화 도구 파일을 Cloud Storage 버킷에 업로드합니다.
데이터 세트 만들기
ML 모델을 저장할 BigQuery 데이터 세트를 만듭니다.콘솔
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
탐색기 창에서 프로젝트 이름을 클릭합니다.
작업 보기 > 데이터 세트 만들기를 클릭합니다.
데이터 세트 만들기 페이지에서 다음을 수행합니다.
데이터 세트 ID에
bqml_tutorial를 입력합니다.위치 유형에 대해 멀티 리전을 선택한 다음 US를 선택합니다.
나머지 기본 설정은 그대로 두고 데이터 세트 만들기를 클릭합니다.
bq
새 데이터 세트를 만들려면 bq mk --dataset 명령어를 사용합니다.
데이터 위치가
US로 설정된bqml_tutorial데이터 세트를 만듭니다.bq mk --dataset \ --location=US \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
데이터 세트가 생성되었는지 확인합니다.
bq ls
API
데이터 세트 리소스가 정의된 datasets.insert 메서드를 호출합니다.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrames
이 샘플을 사용해 보기 전에 BigQuery DataFrames를 사용하여 BigQuery 빠른 시작의 BigQuery DataFrames 설정 안내를 따르세요. 자세한 내용은 BigQuery DataFrames 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 ADC 설정을 참조하세요.
ONNX 모델을 BigQuery로 가져오기
변환된 토큰화 도구와 문장 트랜스포머 모델을 BigQuery ML 모델로 가져옵니다.
다음 옵션 중 하나를 선택합니다.
콘솔
Google Cloud 콘솔에서 BigQuery Studio를 엽니다.
쿼리 편집기에서 다음
CREATE MODEL문을 실행하여tokenizer모델을 만듭니다.CREATE OR REPLACE MODEL `bqml_tutorial.tokenizer` OPTIONS (MODEL_TYPE='ONNX', MODEL_PATH='TOKENIZER_BUCKET_PATH')
TOKENIZER_BUCKET_PATH를 Cloud Storage에 업로드한 모델의 경로로 바꿉니다. 샘플 모델을 사용하는 경우TOKENIZER_BUCKET_PATH를gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/tokenizer.onnx로 바꿉니다.작업이 완료되면 쿼리 결과 창에
Successfully created model named tokenizer과 유사한 메시지가 표시됩니다.모델로 이동을 클릭하여 세부정보 창을 엽니다.
특성 열 섹션을 검토하여 모델 입력을 확인하고 라벨 열을 검토하여 모델 출력을 확인합니다.
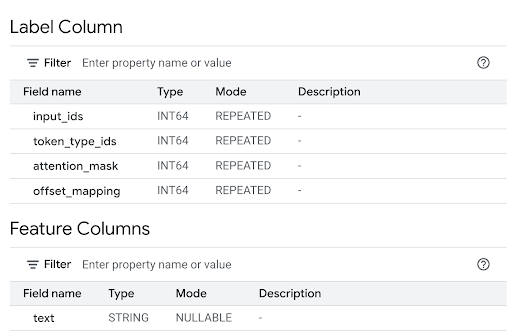
쿼리 편집기에서 다음
CREATE MODEL문을 실행하여all-MiniLM-L6-v2모델을 만듭니다.CREATE OR REPLACE MODEL `bqml_tutorial.all-MiniLM-L6-v2` OPTIONS (MODEL_TYPE='ONNX', MODEL_PATH='TRANSFORMER_BUCKET_PATH')
TRANSFORMER_BUCKET_PATH를 Cloud Storage에 업로드한 모델의 경로로 바꿉니다. 샘플 모델을 사용하는 경우TRANSFORMER_BUCKET_PATH를gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/model_quantized.onnx로 바꿉니다.작업이 완료되면 쿼리 결과 창에
Successfully created model named all-MiniLM-L6-v2과 유사한 메시지가 표시됩니다.모델로 이동을 클릭하여 세부정보 창을 엽니다.
특성 열 섹션을 검토하여 모델 입력을 확인하고 라벨 열을 검토하여 모델 출력을 확인합니다.
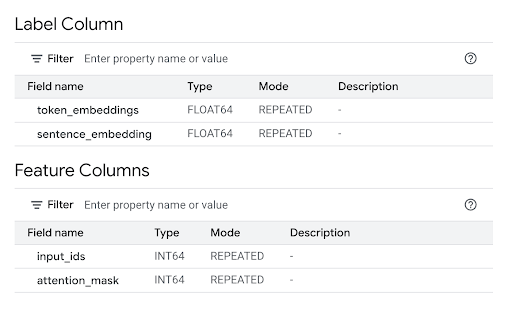
bq
bq 명령줄 도구 query 명령어를 사용하여 CREATE MODEL 문을 실행합니다.
명령줄에서 다음 명령어를 실행하여
tokenizer모델을 만듭니다.bq query --use_legacy_sql=false \ "CREATE OR REPLACE MODEL `bqml_tutorial.tokenizer` OPTIONS (MODEL_TYPE='ONNX', MODEL_PATH='TOKENIZER_BUCKET_PATH')"TOKENIZER_BUCKET_PATH를 Cloud Storage에 업로드한 모델의 경로로 바꿉니다. 샘플 모델을 사용하는 경우TOKENIZER_BUCKET_PATH를gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/tokenizer.onnx로 바꿉니다.작업이 완료되면
Successfully created model named tokenizer과 유사한 메시지가 표시됩니다.명령줄에서 다음 명령어를 실행하여
all-MiniLM-L6-v2모델을 만듭니다.bq query --use_legacy_sql=false \ "CREATE OR REPLACE MODEL `bqml_tutorial.all-MiniLM-L6-v2` OPTIONS (MODEL_TYPE='ONNX', MODEL_PATH='TRANSFORMER_BUCKET_PATH')"TRANSFORMER_BUCKET_PATH를 Cloud Storage에 업로드한 모델의 경로로 바꿉니다. 샘플 모델을 사용하는 경우TRANSFORMER_BUCKET_PATH를gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/model_quantized.onnx로 바꿉니다.작업이 완료되면
Successfully created model named all-MiniLM-L6-v2과 유사한 메시지가 표시됩니다.모델을 가져온 후 모델이 데이터 세트에 표시되는지 확인합니다.
bq ls -m bqml_tutorial
출력은 다음과 비슷합니다.
tableId Type ------------------------ tokenizer MODEL all-MiniLM-L6-v2 MODEL
API
jobs.insert 메서드를 사용하여 모델을 가져옵니다. 요청 본문의 QueryRequest 리소스의 query 매개변수를 CREATE MODEL 문으로 채웁니다.
다음
query파라미터 값을 사용하여tokenizer모델을 만듭니다.{ "query": "CREATE MODEL `PROJECT_ID :bqml_tutorial.tokenizer` OPTIONS(MODEL_TYPE='ONNX' MODEL_PATH='TOKENIZER_BUCKET_PATH')" }다음을 바꿉니다.
PROJECT_ID를 프로젝트 ID로 바꿉니다.TOKENIZER_BUCKET_PATH를 Cloud Storage에 업로드한 모델의 경로로 바꿉니다. 샘플 모델을 사용하는 경우TOKENIZER_BUCKET_PATH를gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/tokenizer.onnx로 바꿉니다.
다음
query파라미터 값을 사용하여all-MiniLM-L6-v2모델을 만듭니다.{ "query": "CREATE MODEL `PROJECT_ID :bqml_tutorial.all-MiniLM-L6-v2` OPTIONS(MODEL_TYPE='ONNX' MODEL_PATH='TRANSFORMER_BUCKET_PATH')" }다음을 바꿉니다.
PROJECT_ID를 프로젝트 ID로 바꿉니다.TRANSFORMER_BUCKET_PATH를 Cloud Storage에 업로드한 모델의 경로로 바꿉니다. 샘플 모델을 사용하는 경우TRANSFORMER_BUCKET_PATH를gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/model_quantized.onnx로 바꿉니다.
BigQuery DataFrames
이 샘플을 사용해 보기 전에 BigQuery DataFrames를 사용하여 BigQuery 빠른 시작의 BigQuery DataFrames 설정 안내를 따르세요. 자세한 내용은 BigQuery DataFrames 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 ADC 설정을 참조하세요.
ONNXModel 객체를 사용하여 토큰화 도구 및 문장 변환기 모델을 가져옵니다.
import bigframes from bigframes.ml.imported import ONNXModel bigframes.options.bigquery.project = PROJECT_ID bigframes.options.bigquery.location = "US" tokenizer = ONNXModel( model_path= "TOKENIZER_BUCKET_PATH" ) imported_onnx_model = ONNXModel( model_path="TRANSFORMER_BUCKET_PATH" )
다음을 바꿉니다.
PROJECT_ID를 프로젝트 ID로 바꿉니다.TOKENIZER_BUCKET_PATH를 Cloud Storage에 업로드한 모델의 경로로 바꿉니다. 샘플 모델을 사용하는 경우TOKENIZER_BUCKET_PATH를gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/tokenizer.onnx로 바꿉니다.TRANSFORMER_BUCKET_PATH를 Cloud Storage에 업로드한 모델의 경로로 바꿉니다. 샘플 모델을 사용하는 경우TRANSFORMER_BUCKET_PATH를gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/model_quantized.onnx로 바꿉니다.
가져온 ONNX 모델로 임베딩 생성
가져온 토큰화 도구와 문장 트랜스포머 모델을 사용하여 bigquery-public-data.imdb.reviews 공개 데이터 세트의 데이터를 기반으로 임베딩을 생성합니다.
다음 옵션 중 하나를 선택합니다.
콘솔
ML.PREDICT 함수를 사용하여 모델로 임베딩을 생성합니다.
이 쿼리는 다음과 같이 토큰화 도구와 임베딩 모델을 통해 원시 텍스트를 직접 처리하기 위해 중첩된 ML.PREDICT 호출을 사용합니다.
- 토큰화 (내부 쿼리): 내부
ML.PREDICT호출은bqml_tutorial.tokenizer모델을 사용합니다.bigquery-public-data.imdb.reviews공개 데이터 세트의title열을text입력으로 사용합니다.tokenizer모델은input_ids및attention_mask입력을 비롯하여 기본 모델에 필요한 원시 텍스트 문자열을 숫자 토큰 입력으로 변환합니다. - 임베딩 생성 (외부 쿼리): 외부
ML.PREDICT호출은bqml_tutorial.all-MiniLM-L6-v2모델을 사용합니다. 쿼리는 내부 쿼리의 출력에서input_ids및attention_mask열을 입력으로 사용합니다.
SELECT 문은 텍스트의 시맨틱 삽입을 나타내는 FLOAT 값의 배열인 sentence_embedding 열을 가져옵니다.
Google Cloud 콘솔에서 BigQuery Studio를 엽니다.
쿼리 편집기에서 다음 쿼리를 실행합니다.
SELECT sentence_embedding FROM ML.PREDICT (MODEL `bqml_tutorial.all-MiniLM-L6-v2`, ( SELECT input_ids, attention_mask FROM ML.PREDICT(MODEL `bqml_tutorial.tokenizer`, ( SELECT title AS text FROM `bigquery-public-data.imdb.reviews` limit 10))))
결과는 다음과 비슷합니다.
+-----------------------+ | sentence_embedding | +-----------------------+ | -0.02361682802438736 | | 0.02025664784014225 | | 0.005168713629245758 | | -0.026361213997006416 | | 0.0655381828546524 | | ... | +-----------------------+
bq
bq 명령줄 도구 query 명령어를 사용하여 쿼리를 실행합니다. 이 쿼리는 ML.PREDICT 함수를 사용하여 모델로 임베딩을 생성합니다.
이 쿼리는 다음과 같이 토큰화 도구와 임베딩 모델을 통해 원시 텍스트를 직접 처리하기 위해 중첩된 ML.PREDICT 호출을 사용합니다.
- 토큰화 (내부 쿼리): 내부
ML.PREDICT호출은bqml_tutorial.tokenizer모델을 사용합니다.bigquery-public-data.imdb.reviews공개 데이터 세트의title열을text입력으로 사용합니다.tokenizer모델은input_ids및attention_mask입력을 비롯하여 기본 모델에 필요한 원시 텍스트 문자열을 숫자 토큰 입력으로 변환합니다. - 임베딩 생성 (외부 쿼리): 외부
ML.PREDICT호출은bqml_tutorial.all-MiniLM-L6-v2모델을 사용합니다. 쿼리는 내부 쿼리의 출력에서input_ids및attention_mask열을 입력으로 사용합니다.
SELECT 문은 텍스트의 시맨틱 삽입을 나타내는 FLOAT 값의 배열인 sentence_embedding 열을 가져옵니다.
명령줄에서 다음 명령어를 실행하여 쿼리를 실행합니다.
bq query --use_legacy_sql=false \ 'SELECT sentence_embedding FROM ML.PREDICT (MODEL `bqml_tutorial.all-MiniLM-L6-v2`, ( SELECT input_ids, attention_mask FROM ML.PREDICT(MODEL `bqml_tutorial.tokenizer`, ( SELECT title AS text FROM `bigquery-public-data.imdb.reviews` limit 10))))'
결과는 다음과 비슷합니다.
+-----------------------+ | sentence_embedding | +-----------------------+ | -0.02361682802438736 | | 0.02025664784014225 | | 0.005168713629245758 | | -0.026361213997006416 | | 0.0655381828546524 | | ... | +-----------------------+
BigQuery DataFrames
이 샘플을 사용해 보기 전에 BigQuery DataFrames를 사용하여 BigQuery 빠른 시작의 BigQuery DataFrames 설정 안내를 따르세요. 자세한 내용은 BigQuery DataFrames 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 ADC 설정을 참조하세요.
predict 메서드를 사용하여 ONNX 모델을 통해 임베딩을 생성합니다.
import bigframes.pandas as bpd
df = bpd.read_gbq("bigquery-public-data.imdb.reviews", max_results=10)
df_pred = df.rename(columns={"title": "text"})
tokens = tokenizer.predict(df_pred)
predictions = imported_onnx_model.predict(tokens)
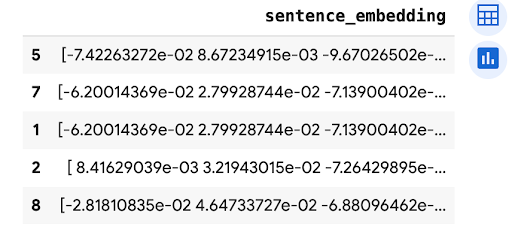
predictions.peek(5)
출력은 다음과 비슷합니다.
삭제
이 튜토리얼에서 사용된 리소스 비용이 Google Cloud 계정에 청구되지 않도록 하려면 리소스가 포함된 프로젝트를 삭제하거나 프로젝트를 유지하고 개별 리소스를 삭제하세요.
프로젝트 삭제
콘솔
- Google Cloud 콘솔에서 리소스 관리 페이지로 이동합니다.
- 프로젝트 목록에서 삭제할 프로젝트를 선택하고 삭제를 클릭합니다.
- 대화상자에서 프로젝트 ID를 입력한 후 종료를 클릭하여 프로젝트를 삭제합니다.
gcloud
Google Cloud 프로젝트를 삭제합니다.
gcloud projects delete PROJECT_ID
개별 리소스 삭제
또는 이 튜토리얼에서 사용된 개별 리소스를 삭제하려면 다음을 수행합니다.
선택사항: 데이터 세트를 삭제합니다.
다음 단계
- 시맨틱 검색 및 검색 증강 생성 (RAG)에 텍스트 임베딩을 사용하는 방법을 알아봅니다.
- 트랜스포머 모델을 ONNX로 변환하는 방법에 관한 자세한 내용은
optimum.exporters.onnx로 모델을 ONNX로 내보내기를 참고하세요. - ONNX 모델 가져오기에 대한 자세한 내용은 ONNX 모델의
CREATE MODEL문 참조하기 - 예측 실행에 대한 자세한 내용은
ML.PREDICT함수를 참고하세요. - BigQuery ML 개요는 BigQuery ML 소개를 참조하세요.
- BigQuery ML을 시작하려면 BigQuery ML에서 머신러닝 모델 만들기 참조하기