
שימוש בשדות בתוך שדות ושדות חוזרים
אפשר להשתמש ב-BigQuery עם שיטות רבות ושונות של מודלים של נתונים, ובדרך כלל הוא מספק ביצועים גבוהים בשיטות רבות של מודלים של נתונים. כדי לשפר את הביצועים של מודל נתונים, אפשר להשתמש בשיטה של דה-נורמליזציה של נתונים. כלומר, להוסיף עמודות של נתונים לטבלה אחת כדי לצמצם או להסיר את הצירופים של הטבלאות.
שיטה מומלצת: השתמשו בשדות בתוך שדות ובשדות חוזרים כדי לבצע דה-נורמליזציה של אחסון הנתונים ולשפר את ביצועי השאילתות.
ביטול הנרמול היא שיטה נפוצה להגדלת ביצועי הקריאה של מערכי נתונים יחסיים שנורמלו בעבר. הדרך המומלצת לבצע דה-נורמליזציה של נתונים ב-BigQuery היא באמצעות שדות מקוננים וחוזרים. מומלץ להשתמש בשיטה הזו כאשר הקשרים הם היררכיים ולעיתים קרובות נשלחות אליהם שאילתות ביחד, למשל בקשרים של הורה-צאצא.
החיסכון בנפח האחסון כתוצאה משימוש בנתונים מנורמלים פחות משמעותי במערכות מודרניות. העלייה בעלויות האחסון שווה לשיפורים בביצועים שמתקבלים משימוש בנתונים לא מנורמלים. לצירופים נדרשת תיאום נתונים (רוחב פס של תקשורת). הדה-נורמליזציה ממקמת את הנתונים במשבצות נפרדות, כך שהביצוע יכול להתבצע במקביל.
כדי לשמור על הקשרים בין הנתונים בזמן ביטול הנורמליזציה, אפשר להשתמש בשדות מקוננים ובשדות חוזרים במקום לשטח את הנתונים לגמרי. כשמבצעים החלקה מלאה של נתונים רלציוניים, תקשורת הרשת (ערבוב) עלולה להשפיע לרעה על ביצועי השאילתה.
לדוגמה, כדי לבצע דה-נורמליזציה של סכימת הזמנות בלי להשתמש בשדות מקוננים וחוזרים, יכול להיות שתצטרכו לקבץ את הנתונים לפי שדה כמו order_id(כשיש יחס של אחד לרבים). בגלל הערבוב, קיבוץ הנתונים פחות יעיל מביטול הנורמליזציה של הנתונים באמצעות שדות מוטמעים וחוזרים.
במקרים מסוימים, ביטול הנורמליזציה של הנתונים ושימוש בשדות מקוננים וחוזרים לא מוביל לשיפור בביצועים. לדוגמה, סכימות מסוג star הן בדרך כלל סכימות שעברו אופטימיזציה לניתוח נתונים, ולכן יכול להיות שהביצועים לא יהיו שונים באופן משמעותי אם תנסו לבצע דה-נורמליזציה נוספת.
שימוש בשדות בתוך שדות ובשדות חוזרים
ב-BigQuery לא נדרשת דה-נורמליזציה שטוחה לחלוטין. אפשר להשתמש בשדות בתוך שדות ובשדות חוזרים כדי לשמור על קשרים.
נתונים של קינון (
STRUCT)- הטמנת נתונים מאפשרת לייצג ישויות חיצוניות בשורה.
- כשמבצעים שאילתות על נתונים מקוננים, משתמשים בתחביר של נקודה כדי להפנות לשדות עלים, בדומה לתחביר שמשמש לאיחוד.
- נתונים מקוננים מיוצגים כסוג
STRUCTב-GoogleSQL.
נתונים חוזרים (
ARRAY)- יצירת שדה מסוג
RECORDעם מצב שמוגדר ל-REPEATEDמאפשרת לשמור על קשר של אחד לרבים בשורה (כל עוד הקשר לא כולל מספר גדול של ערכים ייחודיים). - אם הנתונים חוזרים על עצמם, אין צורך לערבב אותם.
- נתונים שחוזרים על עצמם מיוצגים כ-
ARRAY. אפשר להשתמש בפונקציהARRAYב-GoogleSQL כששולחים שאילתה לגבי הנתונים החוזרים.
- יצירת שדה מסוג
נתונים בתוך נתונים ונתונים חוזרים (
ARRAYמתוךSTRUCT)- הקינון והחזרה משלימים זה את זה.
- לדוגמה, בטבלה של רשומות עסקאות, אפשר לכלול מערך של
STRUCTs של פריטים.
מידע נוסף זמין במאמר בנושא ציון עמודות מקוננות ועמודות שחוזרות על עצמן בסכימות של טבלאות.
מידע נוסף על דה-נורמליזציה של נתונים זמין במאמר בנושא דה-נורמליזציה.
דוגמה
נניח שיש טבלת Orders עם שורה לכל פריט שנמכר:
| Order_Id | Item_Name |
|---|---|
| 001 | A1 |
| 001 | B1 |
| 002 | A1 |
| 002 | C1 |
אם רוצים לנתח נתונים מהטבלה הזו, צריך להשתמש בסעיף GROUP BY, בדומה לדוגמה הבאה:
SELECT COUNT (Item_Name) FROM Orders GROUP BY Order_Id;
השימוש בסעיף GROUP BY כרוך בתקורה נוספת של חישובים, אבל אפשר להימנע מכך על ידי קינון של נתונים חוזרים. כדי להימנע משימוש בסעיף GROUP BY, אפשר ליצור טבלה עם הזמנה אחת בכל שורה, שבה פריטי ההזמנה נמצאים בשדה מקונן:
| Order_Id | Item_Name |
|---|---|
| 001 |
A1 B1 |
| 002 |
A1 C1 |
ב-BigQuery, בדרך כלל מציינים סכימה מקוננת כאוסף של אובייקטים מסוג ARRAY.STRUCT משתמשים באופרטור UNNEST כדי לשטח את הנתונים המקוננים, כמו שמוצג בשאילתה הבאה:
SELECT * FROM UNNEST( [ STRUCT('001' AS Order_Id, ['A1', 'B1'] AS Item_Name), STRUCT('002' AS Order_Id, ['A1', 'C1'] AS Item_Name) ] );
השאילתה הזו מניבה תוצאות שדומות לתוצאות הבאות:
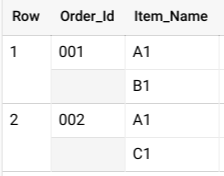
אם הנתונים האלה לא היו מקוננים, יכול להיות שהיו כמה שורות לכל הזמנה, שורה אחת לכל פריט שנמכר בהזמנה, והתוצאה הייתה טבלה גדולה ופעולת GROUP BY יקרה.
פעילות גופנית
כדי לראות את ההבדל בביצועים בין שאילתות שמשתמשות בשדות מקוננים לבין שאילתות שלא משתמשות בהם, פועלים לפי השלבים שמפורטים בקטע הזה.
יצירת טבלה על סמך
bigquery-public-data.stackoverflow.commentsמערך הנתונים הציבורי:CREATE OR REPLACE TABLE `PROJECT.DATASET.stackoverflow` AS ( SELECT user_id, post_id, creation_date FROM `bigquery-public-data.stackoverflow.comments` );
בעזרת הטבלה
stackoverflow, מריצים את השאילתה הבאה כדי לראות את התגובה הראשונה של כל משתמש:SELECT user_id, ARRAY_AGG(STRUCT(post_id, creation_date AS earliest_comment) ORDER BY creation_date ASC LIMIT 1)[OFFSET(0)].* FROM `PROJECT.DATASET.stackoverflow` GROUP BY user_id ORDER BY user_id ASC;
השאילתה הזו רצה במשך כ-25 שניות ומעבדת 1.88GB של נתונים.
יוצרים טבלה שנייה עם נתונים זהים שיוצרת שדה
commentsבאמצעות סוגSTRUCTלאחסון הנתוניםpost_idו-creation_date, במקום שני שדות נפרדים:CREATE OR REPLACE TABLE `PROJECT.DATASET.stackoverflow_nested` AS ( SELECT user_id, ARRAY_AGG(STRUCT(post_id, creation_date) ORDER BY creation_date ASC) AS comments FROM `bigquery-public-data.stackoverflow.comments` GROUP BY user_id );
באמצעות הטבלה
stackoverflow_nested, מריצים את השאילתה הבאה כדי לראות את התגובה הראשונה של כל משתמש:SELECT user_id, (SELECT AS STRUCT post_id, creation_date as earliest_comment FROM UNNEST(comments) ORDER BY creation_date ASC LIMIT 1).* FROM `PROJECT.DATASET.stackoverflow_nested` ORDER BY user_id ASC;
ההרצה של השאילתה הזו נמשכת כ-10 שניות, והיא מעבדת 1.28GB של נתונים.
אחרי שמסיימים להשתמש בטבלאות
stackoverflowו-stackoverflow_nested, צריך למחוק אותן.