

Ce document fournit une architecture de haut niveau pour une application qui utilise l'IA pour générer des solutions aux questions d'assistance des clients.
Ce document s'adresse aux architectes, aux développeurs et aux administrateurs qui créent et gèrent des applications d'IA générative dans le cloud. Ce document part du principe que vous disposez de connaissances de base sur l'IA générative.
La section Déploiement de ce document fournit des exemples de code pour les cas d'utilisation de l'assistance client assistée par l'IA.
Architecture
Le schéma suivant illustre une architecture pour une application de centre d'assistance assistée par l'IA dans Google Cloud. L'application reçoit les questions des clients, récupère les ressources pertinentes d'une base de connaissances, puis génère des solutions pour les questions. L'architecture est une implémentation de l'approche de génération augmentée par récupération (RAG).
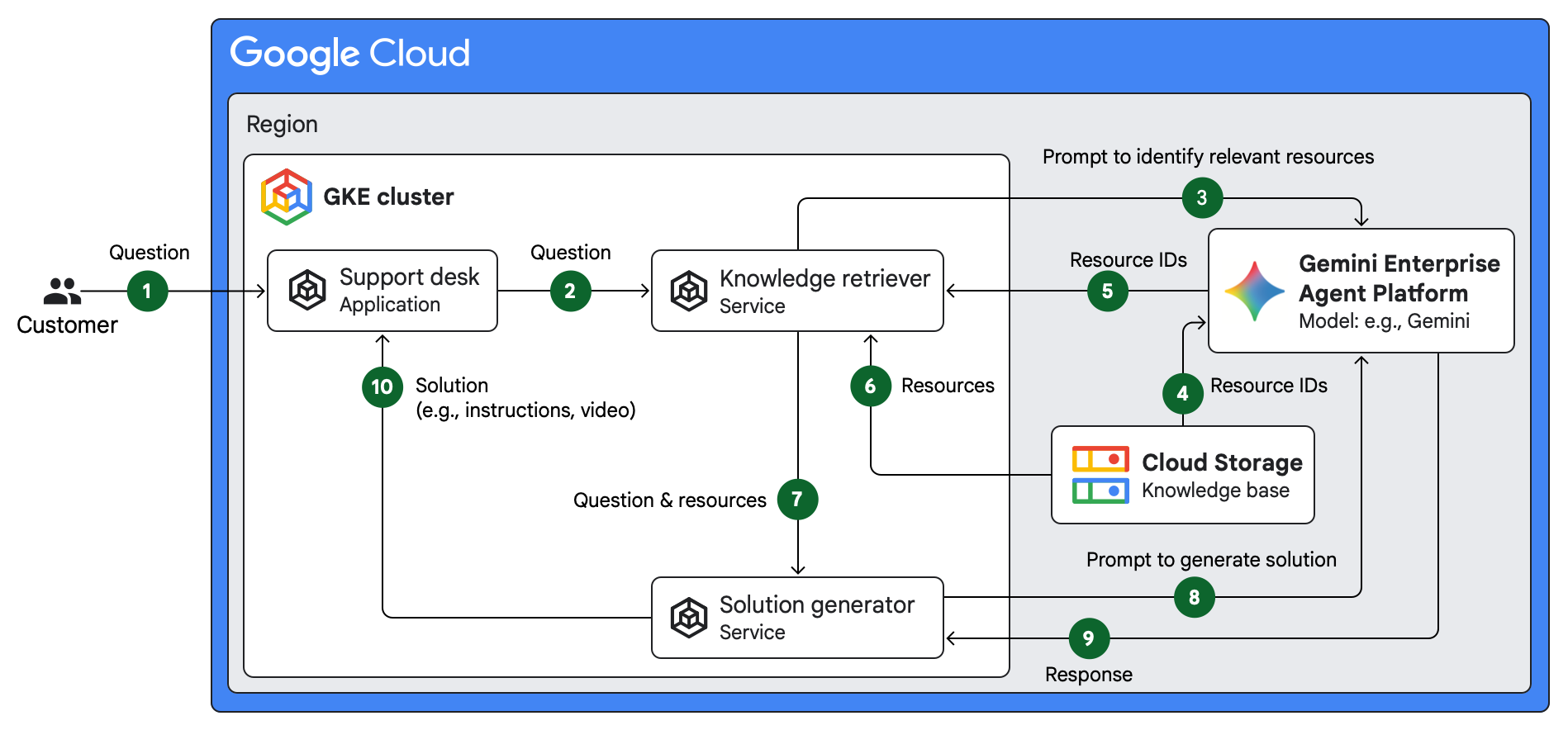
L'application de cette architecture se compose de services conteneurisés déployés dans un cluster Google Kubernetes Engine (GKE). L'architecture présente le flux suivant :
- Un client envoie une question à l'application du service d'assistance.
- L'application du service d'assistance transmet la question du client au service de récupération des connaissances.
- Le service de récupération des connaissances construit et envoie une requête à l'API Gemini pour récupérer les ressources pertinentes par rapport à la question du client.
- Gemini identifie les ressources pertinentes d'une base de connaissances d'assistance stockée dans Cloud Storage.
- Gemini renvoie les ID des ressources pertinentes au service de récupération des connaissances.
- Le service de récupération des connaissances récupère les ressources pertinentes à partir de Cloud Storage.
- Le service de récupération des connaissances envoie la question du client et les ressources pertinentes au service de génération de solutions.
- Le service de génération de solutions envoie les ressources à l'API Gemini, avec une invite pour générer une solution détaillée à la question du client.
- Gemini génère une solution, par exemple des instructions détaillées ou un tutoriel vidéo.
- Le service de génération de solutions fournit la solution au client via l'application du centre d'assistance.
Produits utilisés
Cette architecture d'exemple utilise les produits Google Cloud suivants :
- Google Kubernetes Engine (GKE) : service Kubernetes que vous pouvez utiliser pour déployer et exploiter des applications conteneurisées à grande échelle, à l'aide de l'infrastructure de Google.
- Gemini Enterprise Agent Platform : une plate-forme complète qui vous permet de créer, de faire évoluer, de gérer et d'optimiser des agents IA de niveau entreprise.
- Cloud Storage : store d'objets économique et sans limite pour tout type de données. Les données sont accessibles depuis et en dehors de Google Cloud, et sont répliquées sur plusieurs emplacements à des fins de redondance.
Déploiement
Pour tester les applications d'assistance client assistée par l'IA dansGoogle Cloud, utilisez les exemples de code suivants :
- Créez une application de service client qui utilise l'IA générative.
- Exemple de requête pour les cas d'utilisation du service client assisté par l'IA
Étapes suivantes
- Créez un agent de service client à l'aide de Gemini.
- Créez des agents d'IA pour les cas d'assistance client à l'aide de playbooks, de flux et de data stores dans Dialogflow CX.
- Découvrez d'autres guides sur l'architecture de l'IA générative.
- Pour obtenir une présentation des principes et des recommandations d'architecture spécifiques aux charges de travail d'IA et de ML dans Google Cloud, consultez la perspective de l'IA et du ML dans le framework Well-Architected.
- Pour découvrir d'autres architectures de référence, schémas et bonnes pratiques, consultez le Centre d'architecture cloud.
Contributeurs
Auteur : Kumar Dhanagopal | Cross-product solution developer
Autres contributeurs :
- Amina Mansour | Cadre chez Cloud Platform Evaluations
- Megan O'Keefe | Developer Advocate
- Samantha He | Rédactrice technique
- Shir Meir Lador | Responsable de l'ingénierie des relations avec les développeurs