

本文介紹的參考架構可協助您建立適用於正式環境、可擴充、容錯的記錄匯出機制,將 Google Cloud 資源中的記錄和事件串流至 Splunk。Splunk 是熱門的分析工具,提供整合式安全性和可觀測性平台。事實上,您可以選擇將記錄資料匯出至 Splunk Enterprise 或 Splunk Cloud Platform。如果您是管理員,也可以將這個架構用於 IT 作業或安全性用途。
這項參考架構假設的資源階層與下圖類似。系統會將機構、資料夾和專案層級的所有 Google Cloud 資源記錄匯集到匯總接收器。接著,匯總接收器會將這些記錄檔傳送至記錄檔匯出管道,該管道會處理記錄檔並匯出至 Splunk。

架構
下圖顯示部署這項解決方案時使用的參考架構。這張圖表說明記錄資料如何從Google Cloud 流向 Splunk。

這個架構包含下列元件:
- Cloud Logging:如要啟動這項程序,Cloud Logging 會將記錄收集到機構層級的匯總記錄接收器,然後將記錄傳送至 Pub/Sub。
- Pub/Sub:Pub/Sub 服務會為記錄檔建立單一主題和訂閱項目,並將記錄檔轉送至主要 Dataflow 管道。
- Dataflow:這個參考架構中有兩個 Dataflow 管道:
- 主要 Dataflow 管道:此程序的核心是主要的 Dataflow 管道,也就是 Pub/Sub 到 Splunk 的串流管道,可從 Pub/Sub 訂閱項目提取記錄,並傳送至 Splunk。
- 次要 Dataflow 管道:與主要 Dataflow 管道平行,次要 Dataflow 管道是 Pub/Sub 對 Pub/Sub 的串流管道,可在傳送失敗時重新傳送訊息。
- Splunk:在程序結束時,Splunk Enterprise 或 Splunk Cloud Platform 會做為 HTTP Event Collector (HEC),接收記錄以供進一步分析。您可以透過地端、Google Cloud 即服務 (SaaS) 或混合式方法部署 Splunk。
用途
這項參考架構採用雲端推播式方法。在這個推送式方法中,您可以使用 Pub/Sub to Splunk Dataflow 範本,將記錄串流至 Splunk HTTP Event Collector (HEC)。參考架構也會討論 Dataflow 管道容量規劃,以及如何處理暫時性伺服器或網路問題造成的潛在傳送失敗。
雖然本參考架構著重於 Google Cloud 記錄,但您也可以使用相同架構匯出其他 Google Cloud 資料,例如資產的即時變更和安全性發現。整合 Cloud Logging 的記錄後,您就能繼續使用 Splunk 等現有合作夥伴服務,做為統一的記錄分析解決方案。
以推送為基礎的資料串流方法具有下列優點: Google Cloud
- 代管服務。Dataflow 是代管服務,因此會維護 Google Cloud 資料處理工作 (例如匯出記錄) 所需的資源。
- 分散式工作負載。這個方法可讓您在多個工作站之間分配工作負載,進行平行處理,因此不會有單一故障點。
- 安全性。由於 Google Cloud 會將資料推送至 Splunk HEC,因此您不必建立及管理服務帳戶金鑰,也不必承擔相關的維護和安全負擔。
- 自動調度資源。Dataflow 服務會根據傳入記錄量和待處理工作量的變化,自動調度工作站數量。
- 容錯功能:如果發生暫時性伺服器或網路問題,系統會自動嘗試使用推送式方法,將資料重新傳送至 Splunk HEC。此外,為避免資料遺失,這項服務也支援未處理的主題 (又稱無效信件主題),可處理任何無法傳送的記錄檔訊息。
- 簡單易用:您可避免管理負擔,以及在 Splunk 中執行一或多個重型轉送器的費用。
這項參考架構適用於許多產業別的企業,包括製藥和金融服務等受監管的產業。選擇將 Google Cloud 資料匯出至 Splunk 時,您可能會基於下列原因:
- 業務分析
- IT 作業
- 應用程式效能監控
- 資安營運
- 法規遵循
設計替代方案
您也可以從Google Cloud提取記錄,做為將記錄匯出至 Splunk 的替代方法。在這種提取式方法中,您會使用 Google Cloud API,透過 Splunk Add-on for Google Cloud 擷取資料。在下列情況下,您可能會選擇使用提取式方法:
- 您的 Splunk 部署作業未提供 Splunk HEC 端點。
- 您的記錄資料量偏低。
- 您想匯出及分析 Cloud Monitoring 指標、Cloud Storage 物件、Cloud Resource Manager API 中繼資料、Cloud Billing 資料或低容量記錄。
- 您已在 Splunk 中管理一或多個重型轉送器。
- 您使用代管的 Inputs Data Manager for Splunk Cloud。
此外,使用這項以提取為基礎的方法時,也請注意下列事項:
- 單一 worker 會處理資料擷取工作負載,但無法自動調度資源。
- 在 Splunk 中,使用大量轉送器提取資料可能會導致單點故障。
- 使用提取式方法時,您必須建立及管理服務帳戶金鑰,才能設定 Splunk 外掛程式以存取 Google Cloud。
使用 Splunk 外掛程式前,必須先使用記錄接收器將記錄項目傳送至 Pub/Sub。如要建立以 Pub/Sub 主題為目的地的記錄檔接收器,請參閱「建立接收器」。請務必授予接收器寫入者身分該 Pub/Sub 主題目的地的 Pub/Sub 發布者角色 (roles/pubsub.publisher)。如要進一步瞭解如何設定接收器目的地權限,請參閱「設定目的地權限」。
如要啟用 Splunk 外掛程式,請按照下列步驟操作:
- 在 Splunk 中,按照 Splunk 操作說明安裝 Splunk 外掛程式 Google Cloud。
- 如果還沒有,請為記錄檔的路由目的地 Pub/Sub 主題建立 Pub/Sub 提取訂閱項目。
- 建立服務帳戶。
- 為剛建立的服務帳戶建立服務帳戶金鑰。
- 將 Pub/Sub 檢視者 (
roles/pubsub.viewer) 和 Pub/Sub 訂閱者 (roles/pubsub.subscriber) 角色授予服務帳戶,允許該帳戶接收 Pub/Sub 訂閱項目中的訊息。 在 Splunk 中,按照 Splunk 的操作說明,在 Splunk Add-on for Google Cloud中設定新的 Pub/Sub 輸入。
來自記錄匯出的 Pub/Sub 訊息會顯示在 Splunk 中。
如要確認外掛程式是否正常運作,請完成下列步驟:
- 在 Cloud Monitoring 中開啟 Metrics Explorer。
- 在「Resources」(資源) 選單中,選取
pubsub_subscription。 - 在「指標」類別中,選取
pubsub/subscription/pull_message_operation_count。 - 監控訊息提取作業數一到兩分鐘。
設計須知
下列指南可協助您開發架構,滿足貴機構在安全性、隱私權、法規遵循、作業效率、可靠性、容錯能力、效能和成本最佳化方面的需求。
安全性、隱私權和法規遵循
以下各節說明這個參考架構的安全性考量:
- 使用私人 IP 位址保護支援 Dataflow 管道的 VM
- 啟用 Private Google Access
- 將 Splunk HEC 傳入流量限制為 Cloud NAT 使用的已知 IP 位址
- 將 Splunk HEC 權杖儲存在 Secret Manager 中
- 建立自訂 Dataflow 工作站服務帳戶,遵循最小權限最佳做法
- 如果您使用私有 CA,請為內部根 CA 憑證設定 SSL 驗證
使用私人 IP 位址保護支援 Dataflow 管道的 VM
您應限制 Dataflow 管道中使用的 worker VM 存取權。如要限制存取權,請使用私人 IP 位址部署這些 VM。不過,這些 VM 也必須能夠使用 HTTPS,將匯出的記錄串流至 Splunk 並存取網際網路。如要提供這項 HTTPS 存取權,您需要 Cloud NAT 閘道,該閘道會自動將 Cloud NAT IP 位址分配給需要這些位址的 VM。請務必將含有 VM 的子網路對應至 Cloud NAT 閘道。
啟用 Private Google Access
建立 Cloud NAT 閘道時,系統會自動啟用私人 Google 存取權。不過,如要允許使用私人 IP 位址的 Dataflow 工作人員存取 Google Cloud API 和服務使用的外部 IP 位址,您也必須手動為子網路啟用私人 Google 存取權。
將 Splunk HEC 傳入流量限制為 Cloud NAT 使用的已知 IP 位址
如要將 Splunk HEC 的流量限制在已知 IP 位址的子集,可以保留靜態 IP 位址,並手動指派給 Cloud NAT 閘道。然後,您可以根據 Splunk 部署作業,使用這些靜態 IP 位址設定 Splunk HEC 傳入防火牆規則。如要進一步瞭解 Cloud NAT,請參閱「使用 Cloud NAT 設定及管理網路位址轉譯」。
將 Splunk HEC 權杖儲存在 Secret Manager
部署 Dataflow 管道時,您可以透過下列任一方式傳遞權杖值:
- 純文字
- 使用 Cloud Key Management Service 金鑰加密的密文
- 由 Secret Manager 加密及管理的密鑰版本
在本參考架構中,您會使用 Secret Manager 選項,因為這個選項是保護 Splunk HEC 權杖最簡單有效的方式。這個選項也能防止 Splunk HEC 權杖從 Dataflow 控制台或工作詳細資料外洩。
Secret Manager 中的密鑰包含密鑰版本的集合。每個密鑰版本都會儲存實際密鑰資料,例如 Splunk HEC 權杖。如果之後選擇輪替 Splunk HEC 權杖做為額外的安全措施,可以將新權杖新增為這個密鑰的新密鑰版本。如需密鑰輪替的一般資訊,請參閱「關於輪替時間表」。
建立自訂 Dataflow 工作站服務帳戶,遵循最小權限最佳做法
Dataflow 管道中的工作站會使用 Dataflow 工作站服務帳戶存取資源及執行作業。根據預設,工作站會將專案的 Compute Engine 預設服務帳戶做為工作站服務帳戶使用,這會授予工作站專案中所有資源的廣泛權限。不過,如要在正式環境中執行 Dataflow 工作,建議您建立自訂服務帳戶,並授予最低必要角色和權限。然後將這個自訂服務帳戶指派給 Dataflow 管道工作站。
下圖列出必須指派給服務帳戶的角色,Dataflow 工作站才能順利執行 Dataflow 工作。
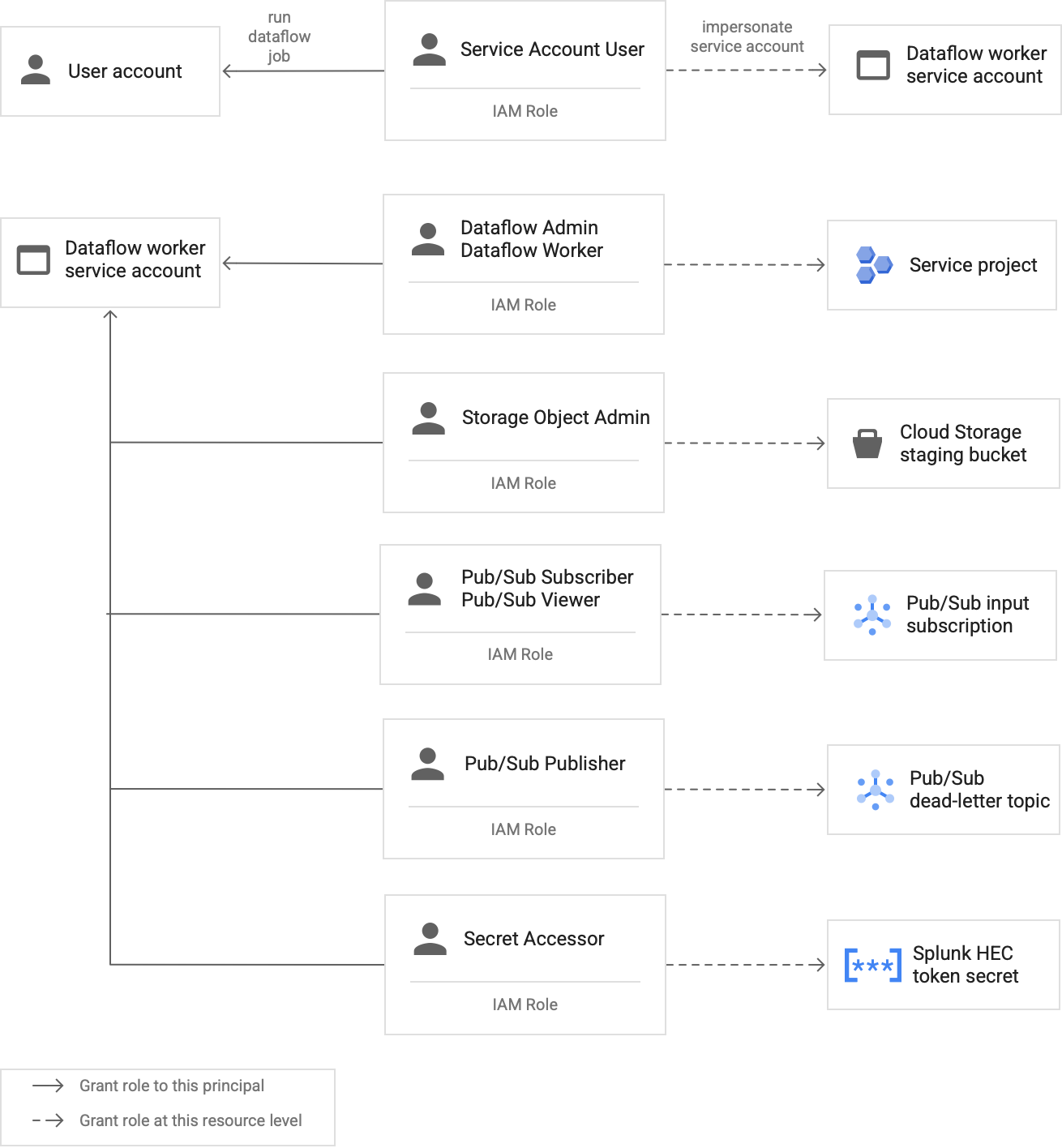
如上圖所示,您需要為 Dataflow 工作者服務帳戶指派下列角色:
- Dataflow 管理員
- Dataflow 工作者
- Storage 物件管理員
- 發布/訂閱訂閱者
- 發布/訂閱檢視者
- Pub/Sub 發布者
- 密鑰存取者
如果您使用私有 CA,請使用內部根 CA 憑證設定 SSL 驗證
根據預設,Dataflow 管道會使用 Dataflow worker 的預設信任存放區,驗證 Splunk HEC 端點的 SSL 憑證。如果您使用私有憑證授權單位 (CA) 簽署 Splunk HTTP 事件收集器 (HEC) 端點使用的 SSL 憑證,可以將內部根 CA 憑證匯入信任儲存庫。Dataflow 工作人員隨後就能使用匯入的憑證驗證 SSL 憑證。
對於使用自行簽署或私下簽署憑證的 Splunk 部署作業,您可以匯入及使用自己的內部根 CA 憑證。您也可以完全停用 SSL 驗證,但僅限用於內部開發和測試。這個內部根 CA 方法最適合非面向網際網路的內部 Splunk 部署作業。
詳情請參閱「Pub/Sub to Splunk Dataflow 範本參數」rootCaCertificatePath和 disableCertificateValidation。
提升作業效率
以下各節說明這項參考架構的作業效率考量:
使用 UDF 轉換傳輸中的記錄或事件
Pub/Sub to Splunk Dataflow 範本支援使用者定義函式 (UDF),可自訂事件轉換作業。用途範例包括使用額外欄位擴充記錄、遮蓋部分敏感欄位,或篩除不想要的記錄。您可以使用 UDF 變更 Dataflow 管道的輸出格式,不必重新編譯或維護範本程式碼本身。這個參考架構會使用 UDF 處理管道無法傳送至 Splunk 的訊息。
重播未處理的訊息
有時管道會收到遞送錯誤,且不會嘗試再次遞送訊息。在這種情況下,Dataflow 會將這些未處理的訊息傳送至未處理的主題,如下圖所示。修正傳送失敗的根本原因後,即可重新傳送未處理的訊息。
以下步驟說明上圖所示的程序:
- 從 Pub/Sub 到 Splunk 的主要傳送管道會自動將無法傳送的訊息轉送至未處理的主題,供使用者調查。
運算子或網站穩定性工程師 (SRE) 會調查未處理訂閱項目中失敗的訊息。服務人員會排解問題,並修正傳送失敗的根本原因。舉例來說,修正 HEC 權杖設定錯誤,或許就能傳送訊息。
營運商會觸發重播失敗訊息管道。這個「Pub/Sub 到 Pub/Sub」管道 (上圖虛線部分標示的管道) 是臨時管道,可將未處理訂閱項目中的失敗訊息移回原始記錄接收器主題。
主要傳送管道會重新處理先前傳送失敗的郵件。這個步驟需要管道使用 UDF,才能正確偵測及解碼失敗的訊息酬載。以下是實作這項條件式解碼邏輯的函式範例,包括用於追蹤的遞送嘗試次數統計:
// If the message has already been converted to a Splunk HEC object // with a stringified obj.event JSON payload, then it's a replay of // a previously failed delivery. // Unnest and parse the obj.event. Drop the previously injected // obj.attributes such as errorMessage and timestamp if (obj.event) { try { event = JSON.parse(obj.event); redelivery = true; } catch(e) { event = obj; } } else { event = obj; } // Keep a tally of delivery attempts event.delivery_attempt = event.delivery_attempt || 1; if (redelivery) { event.delivery_attempt += 1; }
可靠性和容錯能力
就可靠性和容錯能力而言,下表 (表 1) 列出一些可能的 Splunk 傳送錯誤。這份表格也會列出管道在將這些訊息轉送至未處理主題之前,針對每則訊息記錄的對應 errorMessage 屬性。
表 1:Splunk 傳送錯誤類型
| 傳送錯誤類型 | 管道是否會自動重試? | 「errorMessage」屬性範例 |
|---|---|---|
暫時性網路錯誤 |
是 |
或
|
Splunk 伺服器 5xx 錯誤 |
是 |
|
Splunk 伺服器 4xx 錯誤 |
否 |
|
Splunk 伺服器發生問題 |
否 |
|
Splunk SSL 憑證無效 |
否 |
|
使用者定義函式 (UDF) 中的 JavaScript 語法錯誤 |
否 |
|
在某些情況下,管道會套用「指數輪詢」,並自動嘗試再次傳送訊息。舉例來說,如果 Splunk 伺服器產生 5xx 錯誤代碼,管道就必須重新傳送訊息。如果 Splunk HEC 端點超載,就會發生這些錯誤代碼。
或者,也可能是持續性問題,導致訊息無法提交至 HEC 端點。如果問題持續發生,管道就不會再次嘗試傳送訊息。以下是持續性問題的範例:
- UDF 函式中的語法錯誤。
- 無效的 HEC 權杖,導致 Splunk 伺服器產生「Forbidden」
4xx伺服器回應。
效能和成本最佳化
就效能和成本最佳化而言,您需要判斷 Dataflow 管道的最大大小和輸送量。您必須計算正確的大小和輸送量值,讓管道能夠處理上游 Pub/Sub 訂閱項目傳來的每日尖峰記錄量 (GB/天) 和記錄訊息速率 (每秒事件數,或 EPS)。
您必須選取大小和輸送量值,以免系統發生下列任一問題:
- 訊息積壓或訊息節流導致延遲。
- 管道超量佈建造成的額外費用。
完成大小和輸送量計算後,您可以使用結果設定最佳管道,兼顧效能和成本。如要設定管道容量,請使用下列設定:
- 機器類型和機器數量標記是gcloud 指令的一部分,用於部署 Dataflow 工作。您可以使用這些標記定義要使用的 VM 類型和數量。
- 「Parallelism」(平行處理) 和「Batch count」(批次計數) 參數是 Pub/Sub to Splunk Dataflow 範本的一部分。這些參數非常重要,可提高 EPS,同時避免 Splunk HEC 端點負載過重。
以下各節將說明這些設定。這些章節也會視情況提供公式,以及使用各公式的計算範例。這些範例計算和結果值假設機構具有下列特徵:
- 每天產生 1 TB 的記錄。
- 平均訊息大小為 1 KB。
- 持續尖峰訊息速率是平均速率的兩倍。
由於您的 Dataflow 環境是獨一無二的,因此在逐步完成這些步驟時,請以貴機構的值取代範例值。
機型
最佳做法:將 --worker-machine-type 標記設為 n2-standard-4,選取可提供最佳效能與成本比率的機器大小。
由於 n2-standard-4 機型可處理 12, 000 EPS,建議您將此機型做為所有 Dataflow 工作站的基準。
在本參考架構中,請將 --worker-machine-type 旗標設為 n2-standard-4 值。
機器數量
最佳做法:設定 --max-workers 旗標,控管處理預期尖峰 EPS 時所需的 worker 數量上限。
Dataflow 自動調度資源功能可讓服務根據資源用量和負載變化,調整用來執行串流管道的工作站數量。為避免自動調度資源時過度佈建,建議您一律定義做為 Dataflow 工作站的虛擬機器數量上限。部署 Dataflow 管道時,您可以使用 --max-workers 標記定義虛擬機數量上限。
Dataflow 會靜態佈建儲存空間元件,方式如下:
自動調度資源管道會為每個潛在的串流工作站部署一個資料永久磁碟。預設永久磁碟大小為 400 GB,您可以使用
--max-workers標記設定工作站數量上限。磁碟會在任何時間點 (包括啟動時) 掛接至執行中的工作站。由於每個工作站執行個體最多只能有 15 個永久磁碟,因此啟動工作站的數量下限為
⌈--max-workers/15⌉個。因此,如果預設值為--max-workers=20,管道用量 (和費用) 如下:- 儲存空間:靜態,含 20 個永久磁碟。
- 運算:動態,worker 執行個體數量下限為 2 (⌈20/15⌉ = 2),上限為 20。
這個值相當於 8 TB 的永久磁碟。如果磁碟未充分使用,這個大小的永久磁碟可能會產生不必要的費用,特別是只有一或兩個工作站大部分時間都在執行作業時。
如要判斷管道所需的工作站數量上限,請依序使用下列公式:
使用下列公式計算每秒平均事件數 (EPS):
\( {AverageEventsPerSecond}\simeq\frac{TotalDailyLogsInTB}{AverageMessageSizeInKB}\times\frac{10^9}{24\times3600} \)計算範例:假設每天的記錄檔為 1 TB,平均訊息大小為 1 KB,則此公式會產生 11.5k EPS 的平均 EPS 值。
使用下列公式判斷持續尖峰 EPS,其中乘數 N 代表記錄的突發性質:
\( {PeakEventsPerSecond = N \times\ AverageEventsPerSecond} \)計算範例:假設範例值為 N=2,且您在上一個步驟中計算出的平均每股盈餘值為 11.5k,則此公式會產生 23k EPS 的持續尖峰每股盈餘值。
使用下列公式,判斷所需 vCPU 的數量上限:
\( {maxCPUs = ⌈PeakEventsPerSecond / 3k ⌉} \)計算範例:使用您在上一個步驟中計算的持續尖峰 EPS 值 23, 000,這個公式會產生最多 ⌈23 / 3⌉ = 8 個 vCPU 核心。
使用下列公式,判斷 Dataflow 工作站的數量上限:
\( maxNumWorkers = ⌈maxCPUs / 4 ⌉ \)計算範例:使用上一個步驟計算出的最大 vCPU 值 (8),這個公式 [8/4] 會為
n2-standard-4機器類型產生最大值 2。
在本範例中,您會根據先前的範例計算結果,將 --max-workers 旗標設為 2。不過,在環境中部署這個參考架構時,請務必使用自己的專屬值和計算結果。
平行處理工作數量
最佳做法:在「Pub/Sub 到 Splunk」Dataflow 範本中,將 parallelism 參數設為 Dataflow 工作站使用的 vCPU 數量上限的兩倍。
parallelism 參數有助於盡量增加並行 Splunk HEC 連線數量,進而盡量提高管線的 EPS 速率。
1 的預設 parallelism 值會停用平行處理,並限制輸出速率。您需要覆寫這項預設設定,才能為每個 vCPU 考量 2 到 4 個並行連線,並部署工作站數量上限。一般來說,您要計算這項設定的覆寫值,方法是將 Dataflow 工作站的數量上限乘以每個工作站的 vCPU 數量,然後將這個值加倍。
如要判斷所有 Dataflow 工作站與 Splunk HEC 的平行連線總數,請使用下列公式:
計算範例:使用先前為機器數量計算的 8 個 vCPU 上限範例,這個公式會產生 8 x 2 = 16 個平行連線。
在本範例中,您會根據先前的範例計算,將 parallelism 參數設為 16。不過,在您的環境中部署這個參考架構時,請務必使用自己的專屬值和計算結果。
批次數量
最佳做法:如要讓 Splunk HEC 能夠分批處理事件,而非一次處理一個事件,請將 batchCount 參數設為 10 到 50 個事件/要求 (適用於記錄)。
設定批次計數有助於提高每秒事件數,並減少 Splunk HEC 端點的負載。這項設定會將多個事件合併為單一批次,以提高處理效率。建議您將 batchCount
參數設為 10 到 50 個事件/要求 (適用於記錄),前提是可接受最多兩秒的緩衝延遲。
由於本例中的平均記錄訊息大小為 1 KB,我們建議您每個要求至少批次處理 10 個事件。在本範例中,您會將 batchCount 參數設為 10 值。不過,在您的環境中部署這個參考架構時,請務必使用自己的專屬值和計算結果。
如要進一步瞭解這些效能和成本最佳化建議,請參閱「規劃 Dataflow 管道」。
後續步驟
- 如需 Pub/Sub 至 Splunk Dataflow 範本參數的完整清單,請參閱 Pub/Sub 至 Splunk Dataflow 說明文件。
- 如需有助於部署這項參考架構的對應 Terraform 範本,請參閱
terraform-splunk-log-exportGitHub 存放區。其中包含預先建構的 Cloud Monitoring 資訊主頁,可監控 Splunk Dataflow 管道。 - 如要進一步瞭解 Splunk Dataflow 自訂指標和記錄功能,協助您監控及排解 Splunk Dataflow 管道問題,請參閱這篇網誌:New observability features for your Splunk Dataflow streaming pipelines (Splunk Dataflow 串流管道的全新可觀測性功能)。
- 如要查看更多參考架構、圖表和最佳做法,請瀏覽 Cloud Architecture Center。