

Ce document de déploiement explique comment déployer un pipeline Dataflow pour traiter des fichiers image à grande échelle avec l'API Cloud Vision. Ce pipeline stocke les résultats des fichiers traités dans BigQuery. Vous pouvez utiliser les fichiers à des fins d'analyse ou pour entraîner des modèles BigQuery ML.
Le pipeline Dataflow que vous créez dans ce déploiement peut traiter des millions d'images par jour. Votre seule limite est votre quota de l'API Vision. Vous pouvez augmenter votre quota de l'API Vision en fonction de vos exigences d'évolutivité.
Ces instructions sont destinées aux ingénieurs de données et aux data scientists. Ce document suppose que vous possédez des connaissances de base sur la création de pipelines Dataflow à l'aide du SDK Java d'Apache Beam, de GoogleSQL pour BigQuery et de scripts shell de base. Nous supposons également que vous maîtrisez l'API Vision.
Architecture
Le schéma suivant illustre le flux système pour la création d'une solution d'analyse de vision ML.

Dans le schéma précédent, les informations circulent dans l'architecture comme suit :
- Un client importe des fichiers image dans un bucket Cloud Storage.
- Cloud Storage envoie un message sur l'importation des données à Pub/Sub.
- Pub/Sub informe Dataflow de l'importation.
- Le pipeline Dataflow envoie les images à l'API Vision.
- L'API Vision traite les images, puis renvoie les annotations.
- Le pipeline envoie les fichiers annotés à BigQuery pour que vous puissiez les analyser.
Objectifs
- Créez un pipeline Apache Beam pour analyser les images chargées dans Cloud Storage.
- Utilisez Dataflow Runner v2 pour exécuter le pipeline Apache Beam en mode flux afin d'analyser les images dès qu'elles sont importées.
- Utiliser l'API Vision pour analyser des images pour un ensemble de types de fonctionnalités.
- Analysez les annotations avec BigQuery.
Coûts
Dans ce document, vous utilisez les composants facturables suivants de Google Cloud :
Pour obtenir une estimation des coûts en fonction de votre utilisation prévue, utilisez le simulateur de coût.
Une fois que vous avez fini de créer l'exemple d'application, vous pouvez éviter de continuer à payer des frais en supprimant les ressources créées. Pour en savoir plus, consultez la section Effectuer un nettoyage.
Avant de commencer
- Connectez-vous à votre compte Google Cloud . Si vous débutez sur Google Cloud, créez un compte pour évaluer les performances de nos produits en conditions réelles. Les nouveaux clients bénéficient également de 300 $ de crédits sans frais pour exécuter, tester et déployer des charges de travail.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Dans la console Google Cloud , activez Cloud Shell.
En bas de la console Google Cloud , une session Cloud Shell démarre et affiche une invite de ligne de commande. Cloud Shell est un environnement de shell dans lequel Google Cloud CLI est déjà installé, et dans lequel des valeurs sont déjà définies pour votre projet actuel. L'initialisation de la session peut prendre quelques secondes.
- Clonez le dépôt GitHub qui contient le code source du pipeline Dataflow :
git clone https://github.com/GoogleCloudPlatform/dataflow-vision-analytics.git - Accédez au dossier racine du dépôt :
cd dataflow-vision-analytics - Suivez les instructions de la section Premiers pas du dépôt dataflow-vision-analytics sur GitHub pour effectuer les tâches suivantes :
- Activez plusieurs API.
- créer un bucket Cloud Storage ;
- Créer un sujet et un abonnement Pub/Sub
- Créez un ensemble de données BigQuery.
- Configurez plusieurs variables d'environnement pour ce déploiement.
Exécuter le pipeline Dataflow pour toutes les fonctionnalités de l'API Vision implémentées
Le pipeline Dataflow demande et traite un ensemble spécifique de fonctionnalités et d'attributs de l'API Vision dans les fichiers annotés.
Les paramètres répertoriés dans le tableau suivant sont spécifiques au pipeline Dataflow de ce déploiement. Pour obtenir la liste complète des paramètres d'exécution Dataflow standards, consultez Définir les options de pipeline Dataflow.
| Nom du paramètre | Description |
|---|---|
|
Nombre d'images à inclure dans une requête adressée à l'API Vision. La valeur par défaut est 1. Vous pouvez définir cette valeur sur un maximum de 16. |
|
Nom de l'ensemble de données BigQuery de sortie. |
|
Liste des fonctionnalités de traitement d'image. Le pipeline est compatible avec les fonctionnalités de libellé, de point de repère, de logo, de visage, de suggestion de cadrage et de propriétés de l'image. |
|
Paramètre qui définit le nombre maximal d'appels parallèles à l'API Vision. La valeur par défaut est 1. |
|
Paramètres de chaîne avec des noms de table pour diverses annotations. Les valeurs par défaut sont fournies pour chaque tableau (par exemple, label_annotation). |
|
Durée d'attente avant le traitement des images lorsqu'un lot d'images est incomplet. La valeur par défaut est de 30 secondes. |
|
ID de l'abonnement Pub/Sub qui reçoit les notifications Cloud Storage d'entrée. |
|
ID du projet à utiliser pour l'API Vision. |
Dans Cloud Shell, exécutez la commande suivante pour traiter les images pour tous les types de fonctionnalités compatibles avec le pipeline Dataflow :
./gradlew run --args=" \ --jobName=test-vision-analytics \ --streaming \ --runner=DataflowRunner \ --enableStreamingEngine \ --diskSizeGb=30 \ --project=${PROJECT} \ --datasetName=${BIGQUERY_DATASET} \ --subscriberId=projects/${PROJECT}/subscriptions/${GCS_NOTIFICATION_SUBSCRIPTION} \ --visionApiProjectId=${PROJECT} \ --features=IMAGE_PROPERTIES,LABEL_DETECTION,LANDMARK_DETECTION,LOGO_DETECTION,CROP_HINTS,FACE_DETECTION"Le compte de service dédié doit disposer d'un accès en lecture au bucket contenant les images. En d'autres termes, ce compte doit disposer du rôle
roles/storage.objectViewersur ce bucket.Pour en savoir plus sur l'utilisation d'un compte de service dédié, consultez Sécurité et autorisations Dataflow.
Ouvrez l'URL affichée dans un nouvel onglet de navigateur ou accédez à la page Tâches Dataflow et sélectionnez le pipeline test-vision-analytics.
Après quelques secondes, le graphique du job Dataflow s'affiche :
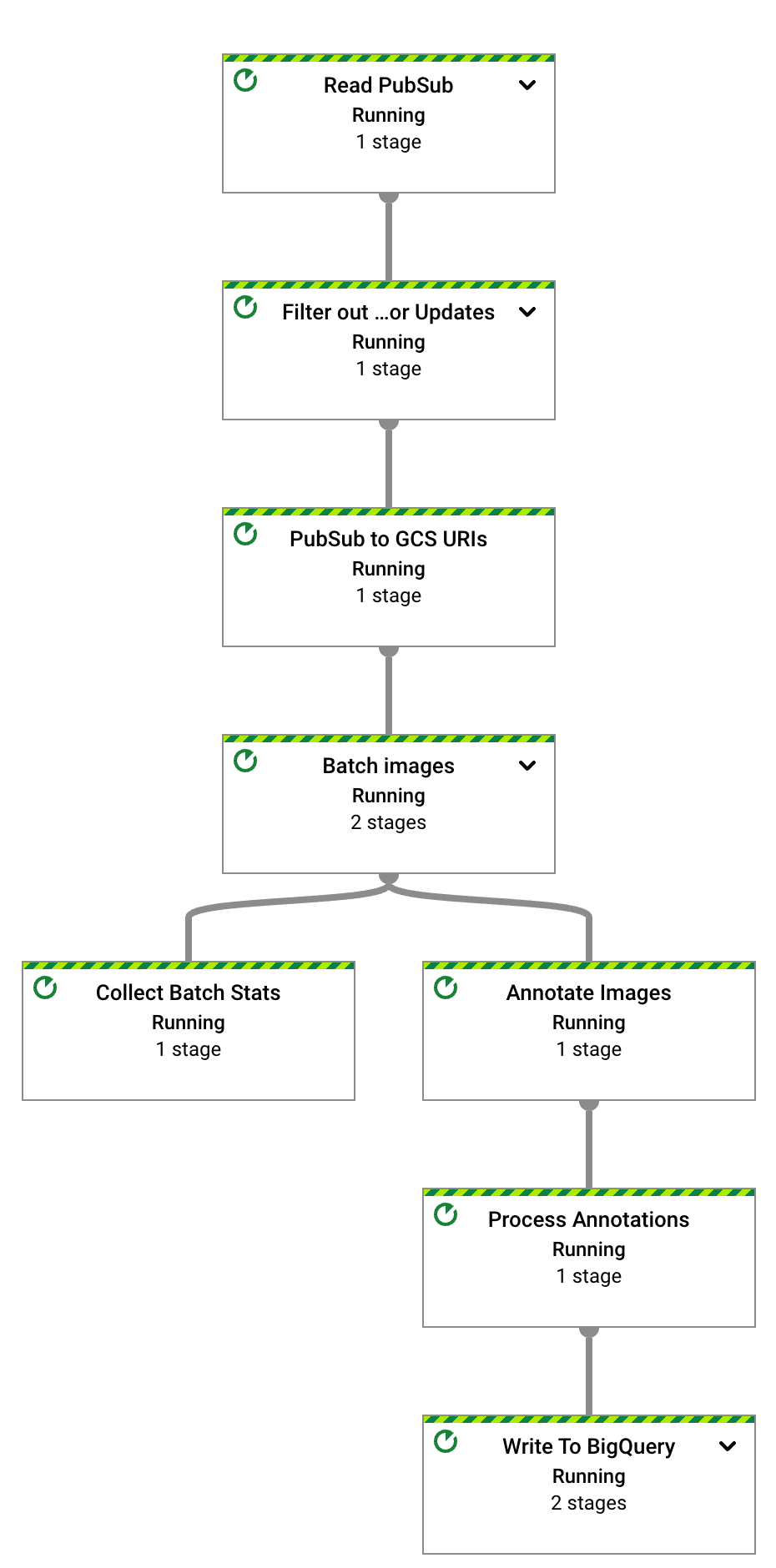
Le pipeline Dataflow est maintenant en cours d'exécution et attend de recevoir des notifications d'entrée de l'abonnement Pub/Sub.
Déclenchez le traitement des images Dataflow en important les six fichiers exemples dans le bucket d'entrée :
gcloud storage cp data-sample/* gs://${IMAGE_BUCKET}Dans la console Google Cloud , recherchez le panneau "Compteurs personnalisés" et utilisez-le pour examiner les compteurs personnalisés dans Dataflow et vérifier que Dataflow a traité les six images. Vous pouvez utiliser la fonctionnalité de filtrage du panneau pour accéder aux métriques appropriées. Pour n'afficher que les compteurs commençant par le préfixe
numberOf, saisisseznumberOfdans le filtre.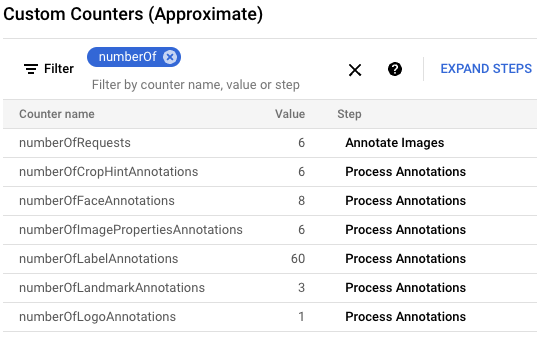
Dans Cloud Shell, vérifiez que les tables ont été créées automatiquement :
bq query --nouse_legacy_sql "SELECT table_name FROM ${BIGQUERY_DATASET}.INFORMATION_SCHEMA.TABLES ORDER BY table_name"Voici le résultat :
+----------------------+ | table_name | +----------------------+ | crop_hint_annotation | | face_annotation | | image_properties | | label_annotation | | landmark_annotation | | logo_annotation | +----------------------+
Affichez le schéma de la table
landmark_annotation. La fonctionnalitéLANDMARK_DETECTIONcapture les attributs renvoyés par l'appel d'API.bq show --schema --format=prettyjson ${BIGQUERY_DATASET}.landmark_annotationVoici le résultat :
[ { "name":"gcs_uri", "type":"STRING" }, { "name":"feature_type", "type":"STRING" }, { "name":"transaction_timestamp", "type":"STRING" }, { "name":"mid", "type":"STRING" }, { "name":"description", "type":"STRING" }, { "name":"score", "type":"FLOAT" }, { "fields":[ { "fields":[ { "name":"x", "type":"INTEGER" }, { "name":"y", "type":"INTEGER" } ], "mode":"REPEATED", "name":"vertices", "type":"RECORD" } ], "name":"boundingPoly", "type":"RECORD" }, { "fields":[ { "fields":[ { "name":"latitude", "type":"FLOAT" }, { "name":"longitude", "type":"FLOAT" } ], "name":"latLon", "type":"RECORD" } ], "mode":"REPEATED", "name":"locations", "type":"RECORD" } ]Affichez les données d'annotation produites par l'API en exécutant les commandes
bq querysuivantes pour voir tous les points de repère trouvés dans ces six images, classés par score de probabilité :bq query --nouse_legacy_sql "SELECT SPLIT(gcs_uri, '/')[OFFSET(3)] file_name, description, score, locations FROM ${BIGQUERY_DATASET}.landmark_annotation ORDER BY score DESC"Le résultat ressemble à ce qui suit :
+------------------+-------------------+------------+---------------------------------+ | file_name | description | score | locations | +------------------+-------------------+------------+---------------------------------+ | eiffel_tower.jpg | Eiffel Tower | 0.7251996 | ["POINT(2.2944813 48.8583701)"] | | eiffel_tower.jpg | Trocadéro Gardens | 0.69601923 | ["POINT(2.2892823 48.8615963)"] | | eiffel_tower.jpg | Champ De Mars | 0.6800974 | ["POINT(2.2986304 48.8556475)"] | +------------------+-------------------+------------+---------------------------------+
Pour obtenir une description détaillée de toutes les colonnes spécifiques aux annotations, consultez
AnnotateImageResponse.Pour arrêter le pipeline de streaming, exécutez la commande suivante. Le pipeline continue de s'exécuter même s'il n'y a plus de notifications Pub/Sub à traiter.
gcloud dataflow jobs cancel --region ${REGION} $(gcloud dataflow jobs list --region ${REGION} --filter="NAME:test-vision-analytics AND STATE:Running" --format="get(JOB_ID)")La section suivante contient d'autres exemples de requêtes qui analysent différentes caractéristiques d'image.
Analyser un ensemble de données Flickr30K
Dans cette section, vous allez détecter des libellés et des points de repère dans l'ensemble de données d'images Flickr30k public hébergé sur Kaggle.
Dans Cloud Shell, modifiez les paramètres du pipeline Dataflow afin qu'ils soient optimisés pour un grand ensemble de données. Pour permettre un débit plus élevé, augmentez également les valeurs
batchSizeetkeyRange. Dataflow adapte le nombre de nœuds de calcul en fonction des besoins :./gradlew run --args=" \ --runner=DataflowRunner \ --jobName=vision-analytics-flickr \ --streaming \ --enableStreamingEngine \ --diskSizeGb=30 \ --autoscalingAlgorithm=THROUGHPUT_BASED \ --maxNumWorkers=5 \ --project=${PROJECT} \ --region=${REGION} \ --subscriberId=projects/${PROJECT}/subscriptions/${GCS_NOTIFICATION_SUBSCRIPTION} \ --visionApiProjectId=${PROJECT} \ --features=LABEL_DETECTION,LANDMARK_DETECTION \ --datasetName=${BIGQUERY_DATASET} \ --batchSize=16 \ --keyRange=5"Étant donné que l'ensemble de données est volumineux, vous ne pouvez pas utiliser Cloud Shell pour récupérer les images de Kaggle et les envoyer au bucket Cloud Storage. Pour ce faire, vous devez utiliser une VM avec un disque de taille plus importante.
Pour récupérer les images basées sur Kaggle et les envoyer au bucket Cloud Storage, suivez les instructions de la section Simuler l'importation des images dans le bucket de stockage du dépôt GitHub.
Pour observer la progression du processus de copie en examinant les métriques personnalisées disponibles dans l'UI Dataflow, accédez à la page Tâches Dataflow et sélectionnez le pipeline
vision-analytics-flickr. Les compteurs de clients doivent changer régulièrement jusqu'à ce que le pipeline Dataflow traite tous les fichiers.Le résultat ressemble à la capture d'écran suivante du panneau "Compteurs personnalisés". Le type de l'un des fichiers du jeu de données est incorrect, ce qui se reflète dans le compteur
rejectedFiles. Ces valeurs de compteur sont approximatives. Vous verrez peut-être des chiffres plus élevés. De plus, le nombre d'annotations changera très probablement en raison de la précision accrue du traitement par l'API Vision.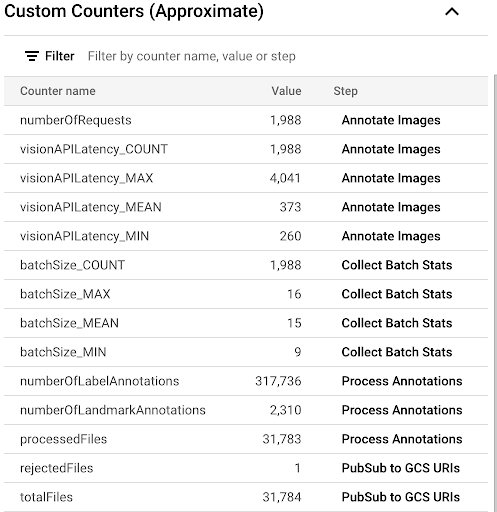
Pour déterminer si vous approchez ou dépassez les ressources disponibles, consultez la page sur les quotas de l'API Vision.
Dans notre exemple, le pipeline Dataflow n'a utilisé qu'environ 50% de son quota. En fonction du pourcentage de quota que vous utilisez, vous pouvez décider d'augmenter le parallélisme du pipeline en augmentant la valeur du paramètre
keyRange.Arrêtez le pipeline :
gcloud dataflow jobs list --region $REGION --filter="NAME:vision-analytics-flickr AND STATE:Running" --format="get(JOB_ID)"
Analyser les annotations dans BigQuery
Dans ce déploiement, vous avez traité plus de 30 000 images pour l'annotation de libellés et de points de repère. Dans cette section, vous allez collecter des statistiques sur ces fichiers. Vous pouvez exécuter ces requêtes dans l'espace de travail GoogleSQL pour BigQuery ou à l'aide de l'outil de ligne de commande bq.
Sachez que les chiffres que vous voyez peuvent varier par rapport aux résultats de l'exemple de requête dans ce déploiement. L'API Vision améliore constamment la justesse de ses analyses. Elle peut produire des résultats plus riches en analysant la même image après que vous avez testé la solution pour la première fois.
Dans la console Google Cloud , accédez à la page Éditeur de requête de BigQuery et exécutez la commande suivante pour afficher les 20 principaux libellés de l'ensemble de données :
Accéder à l'éditeur de requête
SELECT description, count(*)ascount \ FROM vision_analytics.label_annotation GROUP BY description ORDER BY count DESC LIMIT 20Le résultat ressemble à ce qui suit :
+------------------+-------+ | description | count | +------------------+-------+ | Leisure | 7663 | | Plant | 6858 | | Event | 6044 | | Sky | 6016 | | Tree | 5610 | | Fun | 5008 | | Grass | 4279 | | Recreation | 4176 | | Shorts | 3765 | | Happy | 3494 | | Wheel | 3372 | | Tire | 3371 | | Water | 3344 | | Vehicle | 3068 | | People in nature | 2962 | | Gesture | 2909 | | Sports equipment | 2861 | | Building | 2824 | | T-shirt | 2728 | | Wood | 2606 | +------------------+-------+
Déterminez les autres libellés présents sur une image avec un libellé particulier, classés par fréquence :
DECLARE label STRING DEFAULT 'Plucked string instruments'; WITH other_labels AS ( SELECT description, COUNT(*) count FROM vision_analytics.label_annotation WHERE gcs_uri IN ( SELECT gcs_uri FROM vision_analytics.label_annotation WHERE description = label ) AND description != label GROUP BY description) SELECT description, count, RANK() OVER (ORDER BY count DESC) rank FROM other_labels ORDER BY rank LIMIT 20;Voici le résultat : Pour le libellé Instruments à cordes pincées utilisé dans la commande précédente, vous devriez voir :
+------------------------------+-------+------+ | description | count | rank | +------------------------------+-------+------+ | String instrument | 397 | 1 | | Musical instrument | 236 | 2 | | Musician | 207 | 3 | | Guitar | 168 | 4 | | Guitar accessory | 135 | 5 | | String instrument accessory | 99 | 6 | | Music | 88 | 7 | | Musical instrument accessory | 72 | 8 | | Guitarist | 72 | 8 | | Microphone | 52 | 10 | | Folk instrument | 44 | 11 | | Violin family | 28 | 12 | | Hat | 23 | 13 | | Entertainment | 22 | 14 | | Band plays | 21 | 15 | | Jeans | 17 | 16 | | Plant | 16 | 17 | | Public address system | 16 | 17 | | Artist | 16 | 17 | | Leisure | 14 | 20 | +------------------------------+-------+------+
Affichez les 10 points de repère détectés les plus populaires :
SELECT description, COUNT(description) AS count FROM vision_analytics.landmark_annotation GROUP BY description ORDER BY count DESC LIMIT 10Voici le résultat :
+--------------------+-------+ | description | count | +--------------------+-------+ | Times Square | 55 | | Rockefeller Center | 21 | | St. Mark's Square | 16 | | Bryant Park | 13 | | Millennium Park | 13 | | Ponte Vecchio | 13 | | Tuileries Garden | 13 | | Central Park | 12 | | Starbucks | 12 | | National Mall | 11 | +--------------------+-------+
Déterminez les images qui contiennent le plus probablement des cascades :
SELECT SPLIT(gcs_uri, '/')[OFFSET(3)] file_name, description, score FROM vision_analytics.landmark_annotation WHERE LOWER(description) LIKE '%fall%' ORDER BY score DESC LIMIT 10Voici le résultat :
+----------------+----------------------------+-----------+ | file_name | description | score | +----------------+----------------------------+-----------+ | 895502702.jpg | Waterfall Carispaccha | 0.6181358 | | 3639105305.jpg | Sahalie Falls Viewpoint | 0.44379658 | | 3672309620.jpg | Gullfoss Falls | 0.41680416 | | 2452686995.jpg | Wahclella Falls | 0.39005348 | | 2452686995.jpg | Wahclella Falls | 0.3792498 | | 3484649669.jpg | Kodiveri Waterfalls | 0.35024035 | | 539801139.jpg | Mallela Thirtham Waterfall | 0.29260656 | | 3639105305.jpg | Sahalie Falls | 0.2807213 | | 3050114829.jpg | Kawasan Falls | 0.27511594 | | 4707103760.jpg | Niagara Falls | 0.18691841 | +----------------+----------------------------+-----------+
Trouvez des images de monuments emblématiques dans un rayon de 3 kilomètres du Colisée à Rome (la fonction
ST_GEOPOINTutilise la longitude et la latitude du Colisée) :WITH landmarksWithDistances AS ( SELECT gcs_uri, description, location, ST_DISTANCE(location, ST_GEOGPOINT(12.492231, 41.890222)) distance_in_meters, FROM `vision_analytics.landmark_annotation` landmarks CROSS JOIN UNNEST(landmarks.locations) AS location ) SELECT SPLIT(gcs_uri,"/")[OFFSET(3)] file, description, ROUND(distance_in_meters) distance_in_meters, location, CONCAT("https://storage.cloud.google.com/", SUBSTR(gcs_uri, 6)) AS image_url FROM landmarksWithDistances WHERE distance_in_meters < 3000 ORDER BY distance_in_meters LIMIT 100Lorsque vous exécuterez la requête, vous verrez qu'il existe plusieurs images du Colisée, mais aussi de l'Arc de Constantin, du Palatin et d'un certain nombre d'autres lieux fréquemment photographiés.
Vous pouvez visualiser les données dans BigQuery Geo Viz en collant la requête précédente. Sélectionnez un point sur la carte pour afficher ses détails. L'attribut
Image_urlcontient un lien vers le fichier image.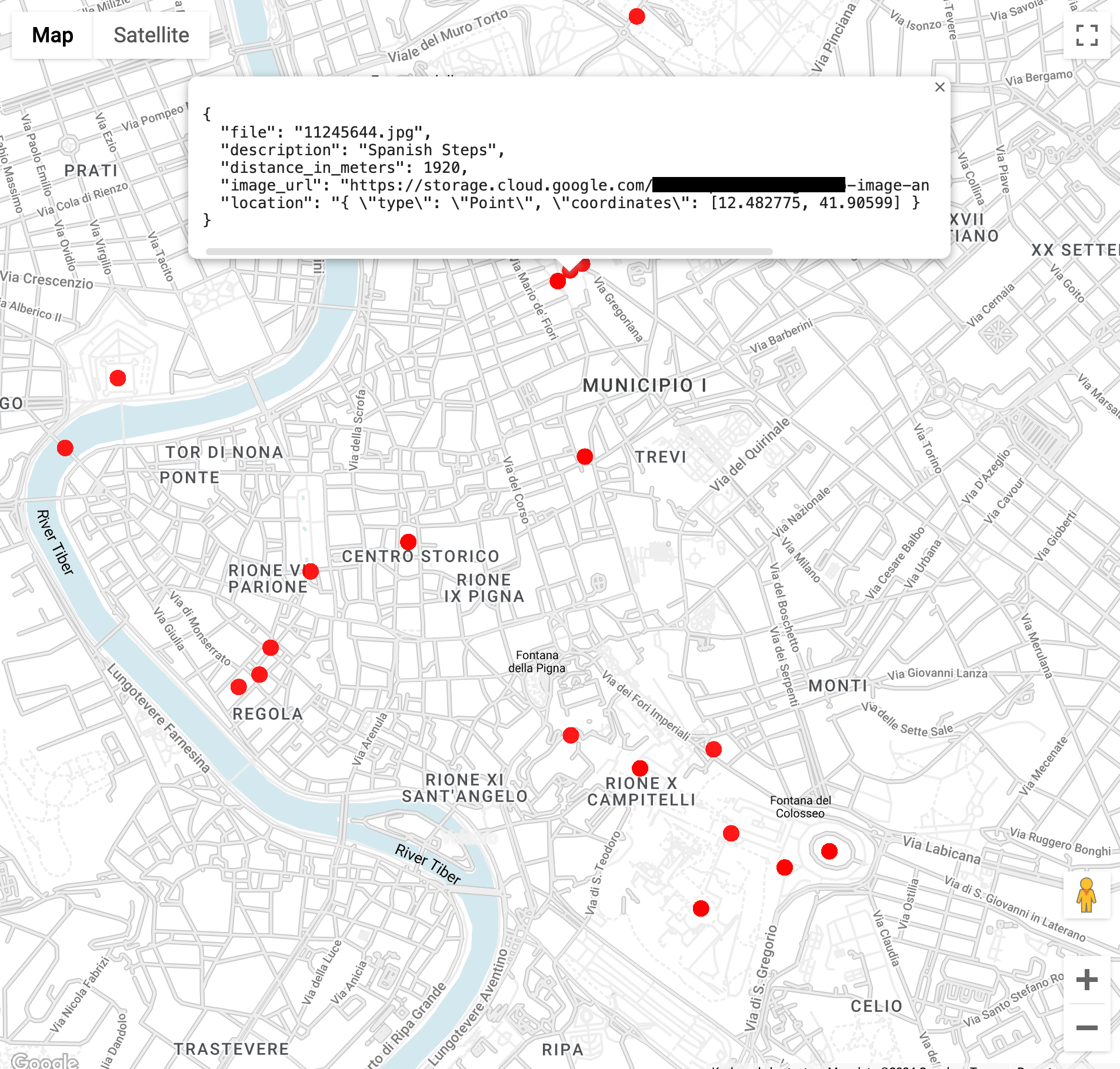
Remarque sur les résultats des requêtes : Des informations concernant la localisation sont généralement disponibles pour les points de repère. La même image peut contenir plusieurs emplacements du même point de repère.
Cette fonctionnalité est décrite dans le type AnnotateImageResponse.
Étant donné qu'un emplacement peut indiquer le lieu de la scène dans l'image, plusieurs éléments LocationInfo peuvent être présents. Un autre emplacement peut indiquer le lieu où l'image a été prise.
Effectuer un nettoyage
Pour éviter que les ressources utilisées dans ce guide ne soient facturées sur votre compte Google Cloud , supprimez le projet contenant les ressources, ou conservez le projet et supprimez les ressources individuelles.
Supprimer le projet Google Cloud
Le moyen le plus simple d'empêcher la facturation est de supprimer le Google Cloud projet que vous avez créé pour ce tutoriel.
- Dans la console Google Cloud , accédez à la page Gérer les ressources.
- Dans la liste des projets, sélectionnez le projet que vous souhaitez supprimer, puis cliquez sur Supprimer.
- Dans la boîte de dialogue, saisissez l'ID du projet, puis cliquez sur Arrêter pour supprimer le projet.
Si vous décidez de supprimer les ressources individuellement, suivez les étapes de la section Nettoyer du dépôt GitHub.
Étapes suivantes
- Pour découvrir d'autres architectures de référence, schémas et bonnes pratiques, consultez le Centre d'architecture cloud.
Contributeurs
Auteurs :
- Masud Hasan | Responsable ingénierie en fiabilité des sites (SRE)
- Sergei Lilichenko | Solutions Architect
- Lakshmanan Sethu | Responsable de compte technique
Autres contributeurs :
- Jiyeon Kang | Ingénieur client
- Sunil Kumar Jang Bahadur | Ingénieur client