

Ce document décrit une architecture de haut niveau pour une application qui exécute un workflow de data science afin d'automatiser des tâches complexes d'analyse de données et de machine learning.
Cette architecture utilise des ensembles de données hébergés dans BigQuery ou AlloyDB pour PostgreSQL. L'architecture est un système multi-agents qui permet aux utilisateurs d'exécuter des actions à l'aide de commandes en langage naturel. Elle élimine la nécessité d'écrire du code SQL ou Python complexe.
Ce document s'adresse aux architectes, aux développeurs et aux administrateurs qui créent et gèrent des applications d'IA agentique. Cette architecture permet aux équipes commerciales et de données d'analyser les métriques dans un large éventail de secteurs, tels que le commerce, la finance et l'industrie. Ce document suppose que vous possédez des connaissances de base sur les systèmes d'IA agentive. Pour en savoir plus sur les différences entre les agents et les systèmes non agentiques, consultez Quelle est la différence entre les agents IA, les assistants IA et les bots ?
La section Déploiement de ce document fournit des liens vers des exemples de code pour vous aider à expérimenter le déploiement d'une application d'IA agentique qui exécute un workflow de science des données.
Architecture
Le diagramme suivant illustre l'architecture d'un agent de workflow de science des données.
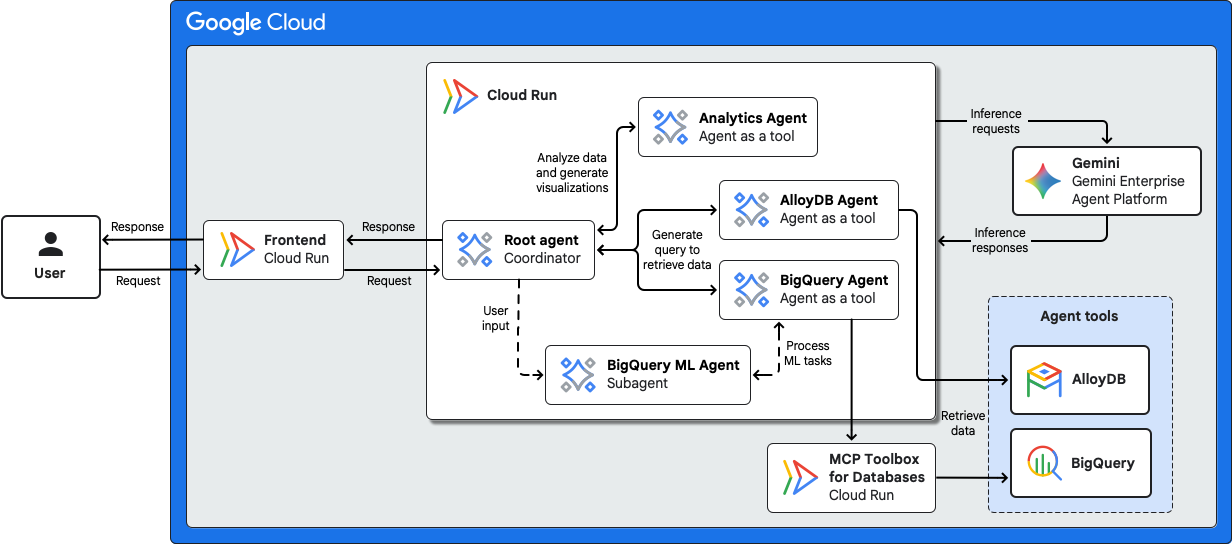
Cette architecture comprend les composants suivants :
| Composant | Description |
|---|---|
| Interface | Les utilisateurs interagissent avec le système multi-agents via une interface utilisateur, telle qu'une interface de chat, qui s'exécute en tant que service Cloud Run sans serveur. |
| Agents | Cette architecture utilise les agents suivants :
|
| Environnement d'exécution des agents | Les agents d'IA de cette architecture sont déployés en tant que services Cloud Run sans serveur. |
| ADK | ADK fournit des outils et un framework pour développer, tester et déployer des agents. ADK abstrait la complexité de la création d'agents et permet aux développeurs d'IA de se concentrer sur la logique et les capacités de l'agent. |
| Modèle d'IA et runtimes de modèle | Pour le service d'inférence, les agents de cette architecture d'exemple utilisent le dernier modèle Gemini sur Gemini Enterprise Agent Platform. |
Produits utilisés
Cette architecture exemple utilise les produits et outils suivants : Google Cloud et Open Source
- Cloud Run : plate-forme de calcul gérée qui vous permet d'exécuter des conteneurs directement sur l'infrastructure évolutive de Google.
- Agent Development Kit (ADK) : ensemble d'outils et de bibliothèques permettant de développer, de tester et de déployer des agents IA.
- Gemini Enterprise Agent Platform : une plate-forme complète qui vous permet de créer, de faire évoluer, de gérer et d'optimiser des agents IA de niveau entreprise.
- Gemini: famille de modèles d'IA multimodaux développés par Google.
- BigQuery : entrepôt de données d'entreprise qui vous aide à gérer et analyser vos données grâce à des fonctionnalités intégrées telles que l'analyse géospatiale du machine learning et l'informatique décisionnelle.
- AlloyDB pour PostgreSQL : service de base de données entièrement géré compatible avec PostgreSQL, conçu pour vos charges de travail les plus exigeantes, y compris le traitement hybride transactionnel et analytique.
- MCP Toolbox for Databases : serveur Model Context Protocol (MCP) Open Source qui permet aux agents d'IA de se connecter de manière sécurisée aux bases de données en gérant les complexités associées, comme le regroupement de connexions, l'authentification et l'observabilité.
Déploiement
Pour déployer un exemple d'implémentation de cette architecture, utilisez Data Science with Multiple Agents. Le dépôt fournit deux exemples de jeux de données pour illustrer la flexibilité du système, y compris un jeu de données sur les vols pour l'analyse opérationnelle et un jeu de données sur les ventes d'e-commerce pour l'analyse commerciale.
Étapes suivantes
- (Vidéo) Regardez le podcast Agent Factory sur les agents d'IA pour l'ingénierie et la science des données.
- (Notebook) Utiliser l'agent de data science dans Colab Enterprise
- Découvrez comment héberger des agents d'IA sur Cloud Run.
- Pour obtenir une présentation des principes et des recommandations d'architecture spécifiques aux charges de travail d'IA et de ML dans Google Cloud, consultez la perspective de l'IA et du ML dans le framework Well-Architected.
- Pour découvrir d'autres architectures de référence, schémas et bonnes pratiques, consultez le Centre d'architecture cloud.
Contributeurs
Auteur : Samantha He | Rédactrice technique
Autres contributeurs :
- Amina Mansour | Cadre chez Cloud Platform Evaluations
- Kumar Dhanagopal Développeur de solutions multiproduits
- Megan O'Keefe | Developer Advocate
- Rachael Deacon-Smith | Developer Advocate
- Shir Meir Lador | Responsable de l'ingénierie des relations avec les développeurs