
Cloud Run est une plate-forme d'application entièrement gérée qui vous permet d'exécuter votre code, fonction ou conteneur sur l'infrastructure hautement évolutive de Google.
Vous pouvez déployer du code écrit dans n'importe quel langage de programmation sur Cloud Run si vous pouvez créer une image de conteneur à partir de celui-ci. En réalité, la création d'images de conteneurs est facultative. Si vous utilisez Go, Node.js, Python, Java, .NET, Ruby ou un framework compatible, vous pouvez choisir l'option de déploiement basé sur la source qui crée le conteneur en suivant les bonnes pratiques du langage que vous utilisez.
Google a conçu Cloud Run pour qu'il fonctionne bien avec d'autres services sur Google Cloudafin que vous puissiez développer des applications complètes.
En résumé, Cloud Run permet aux développeurs de passer leur temps à écrire leur code, et très peu de temps à utiliser, configurer et faire évoluer leur service Cloud Run. Vous n'avez pas besoin de créer de cluster ni de gérer une infrastructure pour être productif avec Cloud Run.
Services, jobs et pools de nœuds de calcul : trois façons d'exécuter votre code
Sur Cloud Run, votre code peut être exécuté en tant que service, job ou pool de nœuds de calcul. Tous ces types de ressources exécutent des instances de conteneurs en bac à sable dans le même environnement d'exécution et peuvent s'intégrer aux servicesGoogle Cloud .
Le tableau suivant présente un aperçu des options fournies par chaque type de ressource Cloud Run.
| Ressource | Description |
|---|---|
| Service | Répond aux requêtes HTTP envoyées à un point de terminaison unique et stable, à l'aide d'instances sans état qui évoluent automatiquement en fonction de diverses métriques clés. Répond également aux événements et aux fonctions. |
| Job | Exécute les tâches parallélisables qui sont exécutées manuellement ou selon un calendrier, et qui s'exécutent jusqu'à la fin. |
| Pool de nœuds de calcul | Gère les charges de travail en arrière-plan toujours actives, telles que les charges de travail basées sur l'extraction (par exemple, les consommateurs Kafka, les files d'attente d'extraction Pub/Sub ou les consommateurs RabbitMQ). |
Services Cloud Run
Un service Cloud Run vous fournit l'infrastructure requise pour exécuter un point de terminaison HTTPS fiable. Vous devez vous assurer que votre code écoute sur un port TCP et gère les requêtes HTTP.
Le schéma suivant montre un service Cloud Run exécutant plusieurs instances de conteneur pour gérer les requêtes Web et les événements du client à l'aide d'un point de terminaison HTTPS.

Un service standard comprend les fonctionnalités suivantes :
- Point de terminaison HTTPS unique pour chaque service
- Chaque service Cloud Run dispose d'un point de terminaison HTTPS sur un sous-domaine unique du domaine
*.run.app. Vous pouvez également configurer des domaines personnalisés. Cloud Run gère automatiquement le protocole TLS et est compatible avec WebSockets, HTTP/2 (de bout en bout) et gRPC (de bout en bout). - Autoscaling rapide basé sur les requêtes
- Cloud Run effectue rapidement un scaling horizontal pour gérer toutes les requêtes entrantes ou pour gérer une augmentation de l'utilisation du processeur sans lien avec les requêtes si le paramètre de facturation est défini sur facturation basée sur les instances. Un service peut évoluer rapidement jusqu'à un millier d'instances, voire plus si vous demandez une augmentation de quota. Si la demande diminue, Cloud Run supprime les conteneurs inactifs. Si vous avez des préoccupations concernant les coûts ou la surcharge des systèmes en aval, vous pouvez limiter le nombre maximal d'instances.
- Scaling manuel facultatif
- Par défaut, Cloud Run effectue automatiquement un scaling à la hausse pour gérer un trafic plus important, mais vous pouvez remplacer ce comportement en utilisant le scaling manuel pour contrôler le comportement de scaling.
- Gestion du trafic intégrée
Pour réduire le risque de déploiement d'une nouvelle révision, Cloud Run permet d'effectuer un déploiement progressif, y compris en acheminant le trafic entrant vers la dernière révision, en effectuant un rollback vers une révision précédente et en répartissant le trafic vers plusieurs révisions en même temps.
Par exemple, vous pouvez commencer par envoyer 1 % des requêtes à une nouvelle révision, puis augmenter ce pourcentage tout en surveillant la télémétrie.
- Services publics et privés
Un service Cloud Run peut être accessible depuis Internet. Vous pouvez restreindre l'accès de différentes façons :
- Spécifiez une stratégie d'accès à l'aide de Cloud IAM.
- Utilisez des paramètres d'entrée pour restreindre l'accès au réseau. Cette fonctionnalité est utile si vous souhaitez n'autoriser que le trafic interne provenant du VPC et des services internes.
- Autorisez uniquement les utilisateurs authentifiés avec Identity-Aware Proxy (IAP).
Vous pouvez diffuser des éléments pouvant être mis en cache à partir d'un emplacement périphérique plus proche des clients en mettant en place un service Cloud Run avec un réseau de diffusion de contenu (CDN), tel que Firebase Hosting et Cloud CDN.
Scaling à zéro et nombre minimal d'instances
Par défaut, si la facturation est définie sur la facturation basée sur les instances, Cloud Run ajoute et supprime automatiquement des instances pour gérer toutes les requêtes entrantes ou pour gérer une augmentation de l'utilisation de processeur sans lien avec les requêtes.
S'il n'y a aucune requête entrante à votre service, la dernière instance restante sera supprimée. Ce comportement est communément appelé "scaling à zéro instance". Ensuite, si aucune instance n'est active lorsqu'une requête est envoyée, Cloud Run en crée une. Cela augmente le temps de réponse pour ces premières requêtes, en fonction de la vitesse à laquelle votre conteneur est prêt à gérer les requêtes.
Pour modifier ce comportement, utilisez l'une des méthodes suivantes :
- Configurez Cloud Run pour qu'une quantité minimale d'instances reste active afin que votre service ne procède pas à un scaling à zéro instance.
- Utilisez le scaling manuel pour mieux contrôler le scaling.
Tarification à l'utilisation pour les services
Le scaling à zéro instance est intéressant pour des raisons économiques, car vous payez le processeur et la mémoire alloués à une instance avec une précision de 100 ms. Si vous ne configurez pas un nombre minimal d'instances, votre service n'est pas facturé. Il existe une version sans frais avantageuse. Consultez la page Tarifs pour en savoir plus.
Vous pouvez activer deux paramètres de facturation :
- Basée sur les requêtes
- Si une instance ne traite pas les requêtes, aucuns frais ne vous sont facturés. Vous payez des frais par requête.
- Basée sur les instances
- La durée de vie d'une instance vous est facturée. Aucuns frais par requête ne sont appliqués.
Il existe une version sans frais avantageuse. Pour plus d'informations, consultez la page Tarifs, et reportez-vous à la section Paramètres de facturation pour découvrir comment activer la facturation basée sur les requêtes ou sur les instances pour votre service.
Système de fichiers de conteneur temporaire
Les instances sur Cloud Run sont suppressibles. Chaque conteneur possède une superposition de système de fichiers en mémoire, accessible en écriture, qui n'est pas conservée si le conteneur s'arrête. Cloud Run détermine quand arrêter d'envoyer des requêtes à une instance et l'arrêter, par exemple lors du scaling vertical.
Pour recevoir un avertissement lorsque Cloud Run est sur le point d'arrêter une instance, votre application peut intercepter le signal SIGTERM. Cela permet à votre code de vider les tampons locaux et de conserver les données locales dans un datastore externe.
Pour conserver les fichiers de manière permanente, intégrez Cloud Storage ou installez un système de fichiers réseau (NFS).
Quand utiliser les services Cloud Run ?
Les services Cloud Run sont parfaitement adaptés au code qui gère les requêtes, les événements ou les fonctions. Voici quelques exemples de cas d'utilisation :
- Sites et applications Web
- Créez votre application Web à l'aide de votre pile préférée, accédez à votre base de données SQL et affichez des pages HTML dynamiques.
- API et microservices
- Vous pouvez créer une API REST, une API GraphQL ou des microservices privés communiquant via HTTP ou gRPC.
- Traitement de flux de données
- Les services Cloud Run peuvent recevoir des messages provenant d'abonnements push Pub/Sub et d'événements Eventarc.
- Charges de travail asynchrones
- Les fonctions Cloud Run peuvent répondre à des événements asynchrones, tels qu'un message sur un sujet Pub/Sub, une modification dans un bucket Cloud Storage ou un événement Firebase.
- Inférence de l'IA
- Les services Cloud Run, avec ou sans GPU configuré, peuvent héberger des charges de travail d'IA telles que des modèles d'inférence et d'entraînement de modèles.
Jobs Cloud Run
Si votre code fonctionne, puis s'arrête, par exemple en utilisant un script, vous pouvez utiliser un job Cloud Run pour exécuter votre code. Vous pouvez exécuter un job depuis la ligne de commande à l'aide de Google Cloud CLI, en programmant un job récurrentou en l'exécutant dans le cadre d'un workflow.
Les tâches de tableau sont un moyen plus rapide d'exécuter des tâches
Un job peut démarrer une seule instance pour exécuter votre code. C'est un moyen courant d'exécuter un script ou un outil.
Cependant, vous pouvez également utiliser une tâche de tableau, en démarrant de nombreuses instances indépendantes et identiques en parallèle. Les tâches de tableau sont un moyen plus rapide de traiter des tâches pouvant être divisées en plusieurs tâches indépendantes.
Le schéma suivant montre qu'un job comportant sept tâches prend plus de temps à s'exécuter de manière séquentielle que le même job lorsque quatre instances peuvent traiter des tâches indépendantes en parallèle :

Par exemple, si vous redimensionnez et recadrez 1 000 images à partir de Cloud Storage, il est plus lent de les traiter l'une après l'autre que de les traiter en parallèle avec de nombreuses instances, que Cloud Run gère avec l'autoscaling.
Quand utiliser les tâches Cloud Run ?
Les tâches Cloud Run conviennent parfaitement à l'exécution de code qui effectue une tâche (qui est terminée) et se ferme une fois la tâche terminée. Voici quelques exemples :
- Script ou outil
- Exécutez un script pour effectuer des migrations de bases de données ou d'autres tâches opérationnelles.
- Tâche de tableau
- Effectuez un traitement hautement parallèle de tous les fichiers d'un bucket Cloud Storage.
- Job planifié
- Créez et envoyez des factures à intervalles réguliers, ou enregistrez les résultats d'une requête de base de données au format XML et importez le fichier toutes les deux ou trois heures.
- Charges de travail d'IA
- Les jobs Cloud Run avec ou sans GPU configuré peuvent héberger des charges de travail d'IA telles que l'inférence par lot, l'affinage de modèles et l'entraînement de modèles.
Pools de nœuds de calcul Cloud Run
Les pools de nœuds de calcul sont conçus pour les charges de travail qui ne reposent pas sur le traitement des requêtes HTTP. Ils fournissent un pool de ressources de calcul flexible et évolutif, adapté au traitement en arrière-plan continu, non HTTP et basé sur l'extraction. Les caractéristiques clés suivantes définissent le fonctionnement des pools de nœuds de calcul :
Les pools de nœuds de calcul ne sont pas mis à l'échelle automatiquement. Mettez à l'échelle manuellement le nombre d'instances dont votre pool de nœuds de calcul Cloud Run a besoin pour gérer sa charge de travail. Pour démarrer et rester active, votre charge de travail doit comporter au moins une instance. Si vous définissez le nombre minimal d'instances sur
0, l'instance de nœud de calcul ne démarrera pas, même si le déploiement est réussi.Pour ajuster dynamiquement les instances en fonction de la demande en temps réel, créez votre propre autoscaler. Pour obtenir un exemple, consultez Autoscaler vos charges de travail de consommateur Kafka.
Les pools de nœuds de calcul gèrent les déploiements en répartissant les instances entre les révisions, au lieu de répartir le trafic. Par exemple, pour un pool de nœuds de calcul avec quatre instances, vous pouvez allouer 25 % (une instance) à une nouvelle révision et 75 % (trois instances) à une révision stable.
Les pools de nœuds de calcul sont compatibles avec l'entrée et la sortie VPC directes, et ne disposent pas de point de terminaison ni d'URL à équilibrage de charge. Pour en savoir plus sur la compatibilité avec le serveur de métadonnées (MDS) et sur la récupération des adresses IP privées de l'instance de votre pool de nœuds de calcul, consultez le contrat d'exécution de conteneurs.
Cloud Run ne vous facture que la durée d'exécution de vos instances de pool de nœuds de calcul.
Quand utiliser les pools de nœuds de calcul Cloud Run
Les pools de nœuds de calcul ne nécessitent pas de points de terminaison HTTP publics. Cela renforce la sécurité de votre réseau et simplifie le code de votre application. Vous n'avez pas non plus besoin de gérer les ports pour les vérifications de l'état. Les cas d'utilisation suivants s'appliquent aux pools de nœuds de calcul :
Charges de travail basées sur l'extraction : déployez une charge de travail pour extraire les messages d'une file d'attente à des fins de traitement. Par exemple, Kafka Consumer, Pub/Sub pull et RabbitMQ.
Le diagramme suivant illustre les cas d'utilisation du déploiement de pools de nœuds de calcul pour les charges de travail basées sur l'extraction :
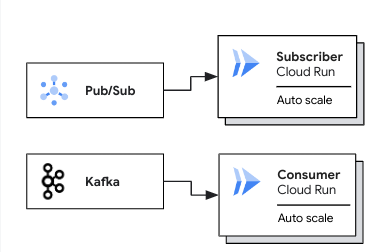
Dans un cas d'utilisation Pub/Sub, un abonné Cloud Run à autoscaling extrait les messages d'un abonnement Pub/Sub. Dans un cas d'utilisation Kafka, un consommateur Cloud Run autoscalé extrait les messages d'un sujet Kafka.
Charges de travail génériques non liées aux requêtes : exécutez une charge de travail basée sur un conteneur qui n'est pas destinée à gérer les requêtes entrantes.
IntégrationsGoogle Cloud
Cloud Run s'intègre à l'écosystème plus large de Google Cloud, ce qui vous permet de créer des applications complètes.
Les intégrations essentielles incluent les suivantes :
- Stockage de données
- Cloud Run s'intègre à Cloud SQL (services gérés MySQL, PostgreSQL et SQL Server), Memorystore (services gérés Redis et Memcached), Firestore, Spanner, Cloud Storage, etc. Pour obtenir la liste complète, consultez la page Stockage des données.
- Journalisation et rapports d'erreurs
- Cloud Logging ingère automatiquement les journaux de conteneurs. Si les journaux contiennent des exceptions, Error Reporting les regroupe, puis vous avertit. Les langages suivants sont compatibles : Go, Java, Node.js, PHP, Python, Ruby et .NET.
- Identité du service
- Chaque révision Cloud Run est associée à un compte de service, et les bibliothèques clientes Google Cloud utilisent ce compte de service de manière transparente pour s'authentifier auprès des API Google Cloud .
- Livraison continue
- Si vous stockez votre code source dans GitHub, vous pouvez configurer Cloud Run pour qu'il déploie automatiquement les nouveaux commits.
- Mise en réseau privée
- Les instances Cloud Run peuvent accéder aux ressources situées dans le réseau de cloud privé virtuel (VPC) par le biais du connecteur d'accès au VPC sans serveur. Votre service peut ainsi se connecter aux machines virtuelles Compute Engine ou aux produits basés sur Compute Engine, tels que Google Kubernetes Engine ou Memorystore.
- APIGoogle Cloud
- Le code de votre service s'authentifie de manière transparente avec les API Google Cloud . Cela inclut les API d'IA et de machine learning, telles que l'API Cloud Vision, l'API Speech-to-Text, l'API AutoML Natural Language, l'API Cloud Translation et bien d'autres encore.
- Tâches en arrière-plan
- Vous pouvez planifier l'exécution du code ultérieurement ou immédiatement après le renvoi d'une requête Web. Cloud Run fonctionne bien avec Cloud Tasks pour fournir une exécution asynchrone fiable et évolutive.
Consultez la page Se connecter aux services pour obtenir la liste des nombreux services Google Cloud qui fonctionnent bien avec Cloud Run. Google Cloud
Le code s'exécute dans une image de conteneur
Bien qu'il ne soit pas nécessaire de connaître les conteneurs pour déployer votre code sur Cloud Run, votre code finit toujours par s'exécuter dans des instances de conteneur en bac à sable.
Si vous ne connaissez pas bien les conteneurs, voici une brève présentation conceptuelle.

Comme le montre le schéma, vous utilisez le code source, les éléments et les dépendances de bibliothèque pour créer l'image de conteneur, qui est un package contenant tout ce dont votre service a besoin pour s'exécuter. Cela inclut les artefacts de compilation, les éléments, les packages système et (éventuellement) un environnement d'exécution. Ainsi, une application conteneurisée est intrinsèquement portable : elle s'exécute partout où un conteneur peut s'exécuter. Voici des exemples d'artefacts de compilation : les fichiers binaires ou les fichiers de script compilés. L'environnement d'exécution JavaScript Node.js ou une machine virtuelle Java (JVM) sont des exemples d'environnements d'exécution.
Les experts avancés considèrent que Cloud Run n'impose pas de charge supplémentaire à l'exécution de leur code : vous pouvez exécuter n'importe quel binaire sur Cloud Run.
Si vous souhaitez plus de commodité ou déléguer la conteneurisation de votre application à Google, Cloud Run s'intègre aux buildpacks Open Source de Google Cloud pour proposer un déploiement basé sur la source.
Étapes suivantes
- Déployer un service Cloud Run
- Créer et exécuter une tâche Cloud Run
- Exécuter des jobs selon un calendrier
- Déployer un pool de nœuds de calcul
- Explorer le modèle de ressource
- En savoir plus sur le contrat d'exécution du conteneur