
Les signatures de pensée sont des représentations chiffrées du processus de réflexion interne du modèle. Les signatures de pensée préservent l'état de raisonnement de Gemini lors des conversations en plusieurs tours et en plusieurs étapes, ce qui peut être utile lors de l'utilisation de l'appel de fonction. Les réponses peuvent inclure un champ thought_signature dans n'importe quelle partie du contenu (par exemple, text, functionCall).
Les modèles Gemini 3 appliquent une validation plus stricte des signatures de pensée que les versions précédentes de Gemini, car ils améliorent les performances du modèle pour l'appel de fonctions. Pour vous assurer que le modèle conserve l'intégralité du contexte sur plusieurs tours de conversation, vous devez renvoyer les signatures de réflexion des réponses précédentes dans vos requêtes suivantes, même lorsque vous utilisez des niveaux de réflexion MINIMAL. Si une signature de réflexion requise n'est pas renvoyée lors de l'utilisation des modèles Gemini 3, le modèle renvoie une erreur 400.
Bien que Gemini 3 Pro Image n'applique pas cette validation, vous devez toujours renvoyer les signatures de réflexion des réponses précédentes dans vos requêtes ultérieures pour vous assurer que le modèle conserve l'intégralité du contexte sur plusieurs tours de conversation. Gemini 3 Pro Image ne renvoie pas d'erreur 400 si aucune signature de pensée n'est renvoyée. Pour obtenir des exemples de code liés à la modification d'images multitour à l'aide de Gemini 3 Pro Image, consultez Exemple de modification d'images multitour à l'aide de signatures de pensée.
Si vous utilisez le SDK Google Gen officiel pour l'IA (Python, Node.js, Go ou Java) et les fonctionnalités standard de l'historique des discussions, ou si vous ajoutez la réponse complète du modèle à l'historique, les signatures de pensée sont gérées automatiquement.
Pourquoi sont-elles importantes ?
Lorsqu'un modèle de réflexion appelle un outil externe, il suspend son processus de raisonnement interne. La signature de pensée agit comme un "état de sauvegarde", permettant au modèle de reprendre sa chaîne de pensée de manière fluide une fois que vous avez fourni le résultat de la fonction. Sans signatures de pensée, le modèle "oublie" ses étapes de raisonnement spécifiques lors de la phase d'exécution de l'outil. Le renvoi de la signature garantit les éléments suivants :
- Continuité du contexte : le modèle conserve et peut vérifier les étapes de raisonnement qui ont justifié l'appel de l'outil.
- Raisonnement complexe : permet d'effectuer des tâches en plusieurs étapes, où la sortie d'un outil éclaire le raisonnement pour la prochaine étape.
Tours et étapes
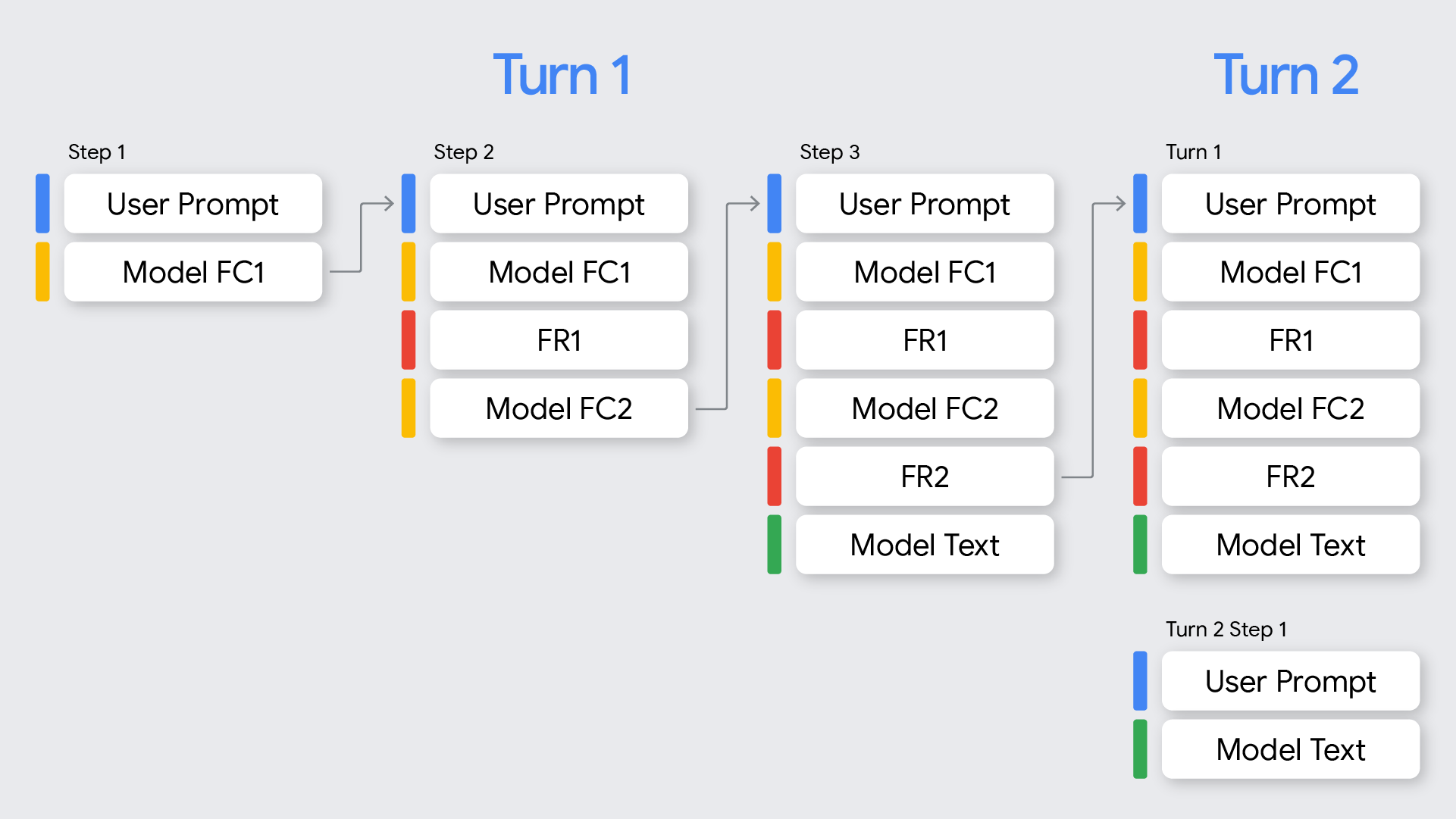
Dans le contexte de l'appel de fonction, il est important de comprendre la différence entre les tours et les étapes :
- Un tour représente un échange complet de conversation, qui commence par une requête de l'utilisateur et se termine lorsque le modèle fournit une réponse finale à cette requête, sans appel de fonction.
- Une étape se produit au cours d'un seul tour lorsque le modèle appelle une fonction et nécessite une réponse de fonction pour poursuivre son processus de raisonnement. Comme le montre le diagramme, un seul tour peut impliquer plusieurs étapes si le modèle doit appeler plusieurs fonctions de manière séquentielle pour répondre à la demande de l'utilisateur.
Utiliser les signatures de pensée
Le moyen le plus simple de gérer les signatures de pensée consiste à inclure tous les Part de tous les messages précédents de l'historique de la conversation lors de l'envoi d'une nouvelle requête, exactement tels qu'ils ont été renvoyés par le modèle.
Si vous n'utilisez pas l'un des SDK Google Gen AI ou si vous devez modifier ou supprimer l'historique des conversations, vous devez vous assurer que les signatures de pensée sont conservées et renvoyées au modèle.
Lorsque vous utilisez le SDK Google Gen AI (recommandé)
Lorsque vous utilisez les fonctionnalités d'historique de chat des SDK ou que vous ajoutez l'objet content du modèle à partir de la réponse précédente au contents de la prochaine requête, les signatures sont gérées automatiquement.
L'exemple Python suivant montre la gestion automatique :
from google import genai
from google.genai.types import Content, FunctionDeclaration, GenerateContentConfig, Part, ThinkingConfig, Tool
client = genai.Client()
# 1. Define your tool
get_weather_declaration = FunctionDeclaration(
name="get_weather",
description="Gets the current weather temperature for a given location.",
parameters={
"type": "object",
"properties": {"location": {"type": "string"}},
"required": ["location"],
},
)
get_weather_tool = Tool(function_declarations=[get_weather_declaration])
# 2. Send a message that triggers the tool
prompt = "What's the weather like in London?"
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=prompt,
config=GenerateContentConfig(
tools=[get_weather_tool],
thinking_config=ThinkingConfig(include_thoughts=True)
),
)
# 3. Handle the function call
function_call = response.function_calls[0]
location = function_call.args["location"]
print(f"Model wants to call: {function_call.name}")
# Execute your tool (for example, call an API)
# (This is a mock response for the example)
print(f"Calling external tool for: {location}")
function_response_data = {
"location": location,
"temperature": "30C",
}
# 4. Send the tool's result back
# Append this turn's messages to history for a final response.
# The `content` object automatically attaches the required thought_signature behind the scenes.
history = [
Content(role="user", parts=[Part(text=prompt)]),
response.candidates[0].content, # Signature preserved here
Content(
role="tool",
parts=[
Part.from_function_response(
name=function_call.name,
response=function_response_data,
)
],
)
]
response_2 = client.models.generate_content(
model="gemini-2.5-flash",
contents=history,
config=GenerateContentConfig(
tools=[get_weather_tool],
thinking_config=ThinkingConfig(include_thoughts=True)
),
)
# 5. Get the final, natural-language answer
print(f"\nFinal model response: {response_2.text}")
Lorsque vous utilisez REST ou la gestion manuelle
Si vous interagissez directement avec l'API, vous devez implémenter la gestion des signatures en fonction des règles suivantes pour Gemini 3 Pro :
- Appel de fonction :
- Si la réponse du modèle contient une ou plusieurs parties
functionCall, unthought_signatureest requis pour un traitement correct. - En cas d'appels de fonction parallèles dans une même réponse, seule la première partie
functionCallcontiendra lethought_signature. - En cas d'appels de fonction séquentiels sur plusieurs étapes d'un tour, chaque partie
functionCallcontiendra unthought_signature. - Règle : Lorsque vous construisez la prochaine requête, vous devez inclure le
partcontenant lefunctionCallet sonthought_signatureexactement tel qu'il a été renvoyé par le modèle. Pour l'appel de fonction séquentiel (en plusieurs étapes), la validation est effectuée sur toutes les étapes du tour actuel. Si vous omettez unthought_signatureobligatoire pour la première partiefunctionCalld'une étape du tour actuel, une erreur400se produit. Un tour commence par le message utilisateur le plus récent qui n'est pas unfunctionResponse. - Si le modèle renvoie des appels de fonction parallèles (par exemple,
FC1+signature,FC2), votre réponse doit contenir tous les appels de fonction suivis de toutes les réponses de fonction (FC1+signature,FC2,FR1,FR2). L'entrelacement des réponses (FC1+signature,FR1,FC2,FR2) entraîne une erreur400. - Dans de rares cas, vous devez fournir des parties
functionCallqui n'ont pas été générées par l'API et qui ne sont donc pas associées à une signature de réflexion (par exemple, lors du transfert de l'historique à partir d'un modèle qui n'inclut pas de signatures de réflexion). Vous pouvez définirthought_signaturesurskip_thought_signature_validator, mais cela ne devrait être qu'un dernier recours, car cela aura un impact négatif sur les performances du modèle.
- Si la réponse du modèle contient une ou plusieurs parties
- Appel de fonction :
- Si la réponse du modèle ne contient pas de
functionCall, elle peut inclure unthought_signaturedans le dernierpartde la réponse (par exemple, la dernière partietext). - Règle : il est recommandé d'inclure cette signature dans la prochaine requête pour optimiser les performances, mais son absence n'entraînera pas d'erreur. Lors de la diffusion en streaming, cette signature peut être renvoyée dans une partie avec un contenu textuel vide. Veillez donc à analyser toutes les parties jusqu'à ce que le modèle renvoie
finish_reason.
- Si la réponse du modèle ne contient pas de
Suivez ces règles pour vous assurer que le contexte du modèle est préservé :
- Renvoie toujours le
thought_signatureau modèle dans sonPartd'origine. - Ne fusionnez pas un
Partcontenant une signature avec un autre qui n'en contient pas. Cela rompt le contexte positionnel de la pensée. - Ne combinez pas deux
Partqui contiennent tous les deux des signatures, car les chaînes de signature ne peuvent pas être fusionnées.
Exemple d'appel de fonction séquentiel
L'exemple suivant montre un exemple d'appel de fonction en plusieurs étapes où l'utilisateur demande "Vérifie l'état du vol AA100 et réserve un taxi en cas de retard", ce qui nécessite plusieurs tâches.
REST
L'exemple suivant montre comment gérer les signatures de pensée dans plusieurs étapes d'un workflow d'appel de fonction séquentiel à l'aide de l'API REST.
Tour 1, étape 1 (demande de l'utilisateur)
{ "contents": [ { "role": "user", "parts": [ { "text": "Check flight status for AA100 and book a taxi 2 hours before if delayed." } ] } ], "tools": [ { "functionDeclarations": [ { "name": "check_flight", "description": "Gets the current status of a flight", "parameters": { "type": "object", "properties": { "flight": { "type": "string", "description": "The flight number to check" } }, "required": [ "flight" ] } }, { "name": "book_taxi", "description": "Book a taxi", "parameters": { "type": "object", "properties": { "time": { "type": "string", "description": "time to book the taxi" } }, "required": [ "time" ] } } ] } ] }
Tour 1, étape 1 (réponse du modèle)
{ "content": { "role": "model", "parts": [ { "functionCall": { "name": "check_flight", "args": { "flight": "AA100" } }, "thoughtSignature": "<SIGNATURE_A>" } ] } }
Tour 1, étape 2 (réponse de l'utilisateur : envoi des résultats de l'outil)
Étant donné que ce tour d'utilisateur ne contient qu'un functionResponse (pas de nouveau texte), nous sommes toujours au tour 1. Vous devez conserver <SIGNATURE_A>.
{ "role": "user", "parts": [ { "text": "Check flight status for AA100 and book a taxi 2 hours before if delayed." } ] }, { "role": "model", "parts": [ { "functionCall": { "name": "check_flight", "args": { "flight": "AA100" } }, "thoughtSignature": "<SIGNATURE_A>" } ] }, { "role": "user", "parts": [ { "functionResponse": { "name": "check_flight", "response": { "status": "delayed", "departure_time": "12 PM" } } } ] }
Tour 1, étape 2 (réponse du modèle)
Le modèle décide maintenant de réserver un taxi en fonction du résultat de l'outil précédent.
{ "content": { "role": "model", "parts": [ { "functionCall": { "name": "book_taxi", "args": { "time": "10 AM" } }, "thoughtSignature": "<SIGNATURE_B>" } ] } }
Tour 1, étape 3 (réponse de l'utilisateur : envoi du résultat de l'outil)
Pour envoyer la confirmation de la réservation de taxi, vous devez inclure des signatures pour tous les appels de fonction de cette boucle (<SIGNATURE_A> et <SIGNATURE_B>).
{ "role": "user", "parts": [ { "text": "Check flight status for AA100 and book a taxi 2 hours before if delayed." } ] }, { "role": "model", "parts": [ { "functionCall": { "name": "check_flight", "args": { "flight": "AA100" } }, "thoughtSignature": "<SIGNATURE_A>" } ] }, { "role": "user", "parts": [ { "functionResponse": { "name": "check_flight", "response": { "status": "delayed", "departure_time": "12 PM" } } } ] }, { "role": "model", "parts": [ { "functionCall": { "name": "book_taxi", "args": { "time": "10 AM" } }, "thoughtSignature": "<SIGNATURE_B>" } ] }, { "role": "user", "parts": [ { "functionResponse": { "name": "book_taxi", "response": { "booking_status": "success" } } } ] } }
Complétions de chat
L'exemple suivant montre comment gérer les signatures de réflexion sur plusieurs étapes d'un workflow d'appel de fonction séquentiel à l'aide de l'API Chat Completions.
Tour 1, étape 1 (demande de l'utilisateur)
{ "model": "google/gemini-3-pro-preview", "messages": [ { "role": "user", "content": "Check flight status for AA100 and book a taxi 2 hours before if delayed." } ], "tools": [ { "type": "function", "function": { "name": "check_flight", "description": "Gets the current status of a flight", "parameters": { "type": "object", "properties": { "flight": { "type": "string", "description": "The flight number to check." } }, "required": [ "flight" ] } } }, { "type": "function", "function": { "name": "book_taxi", "description": "Book a taxi", "parameters": { "type": "object", "properties": { "time": { "type": "string", "description": "time to book the taxi" } }, "required": [ "time" ] } } } ] }
Tour 1, étape 1 (réponse du modèle)
{ "role": "model", "tool_calls": [ { "extra_content": { "google": { "thought_signature": "<SIGNATURE_A>" } }, "function": { "arguments": "{\"flight\":\"AA100\"}", "name": "check_flight" }, "id": "function-call-1", "type": "function" } ] }
Tour 1, étape 2 (réponse de l'utilisateur : envoi des résultats de l'outil)
Étant donné que ce tour d'utilisateur ne contient qu'un functionResponse (pas de nouveau texte), nous sommes toujours au tour 1. Vous devez conserver <SIGNATURE_A>.
"messages": [ { "role": "user", "content": "Check flight status for AA100 and book a taxi 2 hours before if delayed." }, { "role": "model", "tool_calls": [ { "extra_content": { "google": { "thought_signature": "<SIGNATURE_A>" } }, "function": { "arguments": "{\"flight\":\"AA100\"}", "name": "check_flight" }, "id": "function-call-1", "type": "function" } ] }, { "role": "tool", "name": "check_flight", "tool_call_id": "function-call-1", "content": "{\"status\":\"delayed\",\"departure_time\":\"12 PM\"}" } ]
Tour 1, étape 2 (réponse du modèle)
Le modèle décide maintenant de réserver un taxi en fonction du résultat de l'outil précédent.
{ "role": "model", "tool_calls": [ { "extra_content": { "google": { "thought_signature": "<SIGNATURE_B>" } }, "function": { "arguments": "{\"time\":\"10 AM\"}", "name": "book_taxi" }, "id": "function-call-2", "type": "function" } ] }
Tour 1, étape 3 (réponse de l'utilisateur : envoi du résultat de l'outil)
Pour envoyer la confirmation de la réservation de taxi, vous devez inclure des signatures pour tous les appels de fonction de cette boucle (<SIGNATURE_A> et <SIGNATURE_B>).
"messages": [ { "role": "user", "content": "Check flight status for AA100 and book a taxi 2 hours before if delayed." }, { "role": "model", "tool_calls": [ { "extra_content": { "google": { "thought_signature": "<SIGNATURE_A>" } }, "function": { "arguments": "{\"flight\":\"AA100\"}", "name": "check_flight" }, "id": "function-call-1d6a1a61-6f4f-4029-80ce-61586bd86da5", "type": "function" } ] }, { "role": "tool", "name": "check_flight", "tool_call_id": "function-call-1d6a1a61-6f4f-4029-80ce-61586bd86da5", "content": "{\"status\":\"delayed\",\"departure_time\":\"12 PM\"}" }, { "role": "model", "tool_calls": [ { "extra_content": { "google": { "thought_signature": "<SIGNATURE_B>" } }, "function": { "arguments": "{\"time\":\"10 AM\"}", "name": "book_taxi" }, "id": "function-call-65b325ba-9b40-4003-9535-8c7137b35634", "type": "function" } ] }, { "role": "tool", "name": "book_taxi", "tool_call_id": "function-call-65b325ba-9b40-4003-9535-8c7137b35634", "content": "{\"booking_status\":\"success\"}" } ]
Exemple d'appel de fonction parallèle
L'exemple suivant montre un exemple d'appel de fonction parallèle où l'utilisateur demande "Vérifie la météo à Paris et à Londres".
REST
L'exemple suivant montre comment gérer les signatures de pensée dans un workflow d'appel de fonction parallèle à l'aide de l'API REST.
Tour 1, étape 1 (demande de l'utilisateur)
{ "contents": [ { "role": "user", "parts": [ { "text": "Check the weather in Paris and London." } ] } ], "tools": [ { "functionDeclarations": [ { "name": "get_current_temperature", "description": "Gets the current temperature for a given location.", "parameters": { "type": "object", "properties": { "location": { "type": "string", "description": "The city name, e.g. San Francisco" } }, "required": [ "location" ] } } ] } ] }
Tour 1, étape 1 (réponse du modèle)
{ "content": { "parts": [ { "functionCall": { "name": "get_current_temperature", "args": { "location": "Paris" } }, "thoughtSignature": "<SIGNATURE_A>" }, { "functionCall": { "name": "get_current_temperature", "args": { "location": "London" } } } ] } }
Tour 1, étape 2 (réponse de l'utilisateur : envoi des résultats de l'outil)
Vous devez conserver <SIGNATURE_A> dans la première partie exactement tel que vous l'avez reçu.
[ { "role": "user", "parts": [ { "text": "Check the weather in Paris and London." } ] }, { "role": "model", "parts": [ { "functionCall": { "name": "get_current_temperature", "args": { "city": "Paris" } }, "thought_signature": "<SIGNATURE_A>" }, { "functionCall": { "name": "get_current_temperature", "args": { "city": "London" } } } ] }, { "role": "user", "parts": [ { "functionResponse": { "name": "get_current_temperature", "response": { "temp": "15C" } } }, { "functionResponse": { "name": "get_current_temperature", "response": { "temp": "12C" } } } ] } ]
Complétions de chat
L'exemple suivant montre comment gérer les signatures de pensée dans un workflow d'appel de fonction parallèle à l'aide de l'API Chat Completions.
Tour 1, étape 1 (demande de l'utilisateur)
{ "contents": [ { "role": "user", "parts": [ { "text": "Check the weather in Paris and London." } ] } ], "tools": [ { "functionDeclarations": [ { "name": "get_current_temperature", "description": "Gets the current temperature for a given location.", "parameters": { "type": "object", "properties": { "location": { "type": "string", "description": "The city name, e.g. San Francisco" } }, "required": [ "location" ] } } ] } ] }
Tour 1, étape 1 (réponse du modèle)
{ "role": "assistant", "tool_calls": [ { "extra_content": { "google": { "thought_signature": "<SIGNATURE_A>" } }, "function": { "arguments": "{\"location\":\"Paris\"}", "name": "get_current_temperature" }, "id": "function-call-f3b9ecb3-d55f-4076-98c8-b13e9d1c0e01", "type": "function" }, { "function": { "arguments": "{\"location\":\"London\"}", "name": "get_current_temperature" }, "id": "function-call-335673ad-913e-42d1-bbf5-387c8ab80f44", "type": "function" } ] }
Tour 1, étape 2 (réponse de l'utilisateur : envoi des résultats de l'outil)
Vous devez conserver <SIGNATURE_A> dans la première partie exactement tel que vous l'avez reçu.
"messages": [ { "role": "user", "content": "Check the weather in Paris and London." }, { "role": "assistant", "tool_calls": [ { "extra_content": { "google": { "thought_signature": "<SIGNATURE_A>" } }, "function": { "arguments": "{\"location\":\"Paris\"}", "name": "get_current_temperature" }, "id": "function-call-f3b9ecb3-d55f-4076-98c8-b13e9d1c0e01", "type": "function" }, { "function": { "arguments": "{\"location\":\"London\"}", "name": "get_current_temperature" }, "id": "function-call-335673ad-913e-42d1-bbf5-387c8ab80f44", "type": "function" } ] }, { "role":"tool", "name": "get_current_temperature", "tool_call_id": "function-call-f3b9ecb3-d55f-4076-98c8-b13e9d1c0e01", "content": "{\"temp\":\"15C\"}" }, { "role":"tool", "name": "get_current_temperature", "tool_call_id": "function-call-335673ad-913e-42d1-bbf5-387c8ab80f44", "content": "{\"temp\":\"12C\"}" } ]
Signatures dans les Part non-functionCall
Gemini peut également renvoyer un thought_signature dans le Part final d'une réponse, même si aucun appel de fonction n'est présent.
- Comportement : le contenu final
Part(text,inlineData, etc.) renvoyé par le modèle peut contenir unthought_signature. - Exigence : Il est recommandé de renvoyer cette signature pour s'assurer que le modèle maintient un raisonnement de haute qualité, en particulier pour les workflows complexes de suivi des instructions ou agentifs simulés.
- Validation : l'API n'applique pas strictement la validation des signatures dans les parties non-
functionCall. Vous ne recevrez pas d'erreur bloquante si vous les omettez, mais les performances peuvent se dégrader.
Exemple de réponse du modèle avec une signature dans la partie texte :
Les exemples suivants montrent une réponse du modèle dans laquelle un thought_signature est inclus dans un Part non-functionCall et comment le gérer dans une requête ultérieure.
Tour 1, étape 1 (réponse du modèle)
{ "role": "model", "parts": [ { "text": "I need to calculate the risk. Let me think step-by-step...", "thought_signature": "<SIGNATURE_C>" // OPTIONAL (Recommended) } ] }
Tour 2, étape 1 (utilisateur)
[ { "role": "user", "parts": [{ "text": "What is the risk?" }] }, { "role": "model", "parts": [ { "text": "I need to calculate the risk. Let me think step-by-step...", // If you omit <SIGNATURE_C> here, no error will occur. } ] }, { "role": "user", "parts": [{ "text": "Summarize it." }] } ]
Exemple de modification d'image multitour à l'aide de signatures de pensée
Les exemples suivants montrent comment récupérer et transmettre des signatures de pensée lors de la création et de la retouche d'images en plusieurs tours avec Gemini 3 Pro Image.
Tour 1 : Obtenir la réponse et enregistrer les données incluant les signatures de pensée
chat = client.chats.create( model="gemini-3-pro-image-preview", config=types.GenerateContentConfig( response_modalities=['TEXT', 'IMAGE'] ) ) message = "Create an image of a clear perfume bottle sitting on a vanity." response = chat.send_message(message) data = b'' for part in response.candidates[0].content.parts: if part.text: display(Markdown(part.text)) if part.inline_data: data = part.inline_data.data display(Image(data=data, width=500))
Tour 2 : transmettez les données qui incluent les signatures de pensée.
response = chat.send_message( message=[ types.Part.from_bytes( data=data, mime_type="image/png", ), "Make the perfume bottle purple and add a vase of hydrangeas next to the bottle.", ], ) for part in response.candidates[0].content.parts: if part.text: display(Markdown(part.text)) if part.inline_data: display(Image(data=part.inline_data.data, width=500))
Étapes suivantes
- En savoir plus sur Thinking
- En savoir plus sur l'appel de fonction
- Découvrez comment concevoir des requêtes multimodales.