

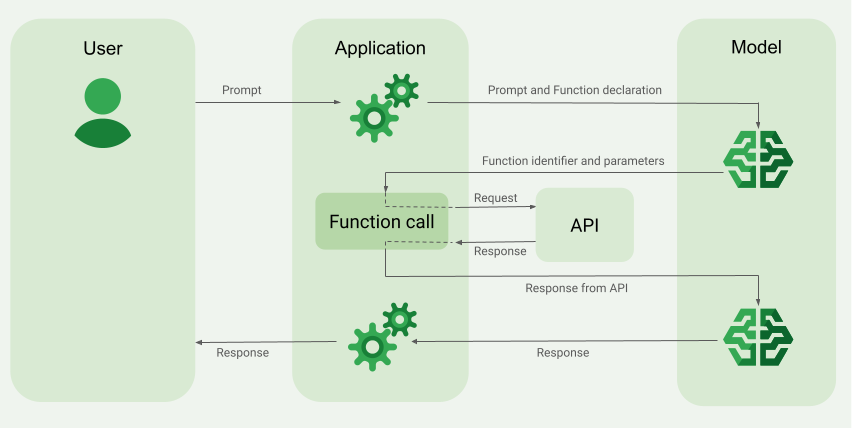
L'appel de fonction, également appelé utilisation d'outils, fournit au LLM des définitions d'outils externes (par exemple, une fonction get_current_weather). Lors du traitement d'une requête, le modèle détermine de manière intelligente si un outil est nécessaire et, le cas échéant, génère des données structurées spécifiant l'outil à appeler et ses paramètres (par exemple, get_current_weather(location='Boston')). Votre application exécute ensuite cet outil et renvoie le résultat au modèle, ce qui lui permet de compléter sa réponse avec des informations dynamiques et réelles, ou avec le résultat d'une action. Cela permet de faire le lien entre le LLM et vos systèmes, et d'étendre ses capacités.
Les appels de fonction permettent deux principaux cas d'utilisation :
Récupération de données : permet d'obtenir des informations à jour pour les réponses du modèle, comme la météo actuelle, la conversion de devises ou des données spécifiques provenant de bases de connaissances et d'API (RAG).
Passer à l'action : effectuer des opérations externes telles que l'envoi de formulaires, la mise à jour de l'état de l'application ou l'orchestration de workflows agentiques (par exemple, les transferts de conversation).
Pour découvrir d'autres cas d'utilisation et exemples basés sur l'appel de fonction, consultez Cas d'utilisation.
Fonctionnalités et limites
Les modèles suivants sont compatibles avec les appels de fonction :
- Modèles Gemini :
Cliquer pour développer les modèles compatibles
Modèles ouverts :
Définissez vos fonctions au format schéma OpenAPI.
Pour les modèles Gemini 3 Pro et ultérieurs, vous pouvez inclure du contenu multimodal (images et PDF) dans les messages
functionResponseque vous renvoyez au modèle. Pour en savoir plus, consultez Réponses multimodales des fonctions.Pour les modèles Gemini 3 Pro et ultérieurs, vous pouvez diffuser en continu les arguments d'appel de fonction à mesure qu'ils sont générés en définissant
streamFunctionCallArgumentssurtruedansfunctionCallingConfig. Pour en savoir plus, consultez Arguments d'appel de fonction en streaming.Pour connaître les bonnes pratiques concernant les déclarations de fonction, y compris des conseils sur les noms et les descriptions, consultez Bonnes pratiques.
Pour les modèles ouverts, suivez ce guide de l'utilisateur.
Créer une application d'appel de fonction
Pour utiliser les appels de fonction, procédez comme suit :
- Envoyez les déclarations de fonctions et le prompt au modèle.
- Fournissez le résultat de l'API au modèle.
Étape 1 : Envoyer le prompt et les déclarations de fonction au modèle
Déclarez un Tool dans un format de schéma compatible avec le schéma OpenAPI. Pour en savoir plus, consultez Exemples de schémas.
Les exemples suivants envoient un prompt et une déclaration de fonction aux modèles Gemini :
REST
PROJECT_ID=myproject
LOCATION=us-central1
MODEL_ID=gemini-2.5-flash
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://${LOCATION}-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/${LOCATION}/publishers/google/models/${MODEL_ID}:generateContent \
-d '{
"contents": [{
"role": "user",
"parts": [{
"text": "What is the weather in Boston?"
}]
}],
"tools": [{
"functionDeclarations": [
{
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city name of the location for which to get the weather.",
"default": {
"string_value": "Boston, MA"
}
}
},
"required": [
"location"
]
}
}
]
}]
}'
SDK Gen AI pour Python
from google import genai
from google.genai.types import GenerateContentConfig, Part
# The project and location are passed directly to the client,
# and vertexai=True is added to specify the use of the Agent Platform backend.
client = genai.Client(vertexai=True, project="PROJECT_ID", location="global")
def get_current_weather(location: str) -> str:
"""Returns the current weather.
Args:
location: The city and state, e.g. San Francisco, CA
"""
return 'sunny'
response = client.models.generate_content(
model="gemini-2.5-flash",
contents="What is the weather in boston?",
config=GenerateContentConfig(tools=[get_current_weather]),
)
SDK Agent Platform
Vous pouvez spécifier le schéma manuellement à l'aide d'un dictionnaire Python ou automatiquement avec la fonction d'assistance from_func. L'exemple suivant montre comment déclarer une fonction manuellement :
import vertexai
from vertexai.generative_models import (
Content,
FunctionDeclaration,
GenerationConfig,
GenerativeModel,
Part,
Tool,
ToolConfig
)
# Initialize Agent Platform
# TODO(developer): Update the project
vertexai.init(project="PROJECT_ID", location="us-central1")
# Initialize Gemini model
model = GenerativeModel(model_name="gemini-2.5-flash")
# Manual function declaration
get_current_weather_func = FunctionDeclaration(
name="get_current_weather",
description="Get the current weather in a given location",
# Function parameters are specified in JSON schema format
parameters={
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city name of the location for which to get the weather.",
"default": {
"string_value": "Boston, MA"
}
}
},
},
)
response = model.generate_content(
contents = [
Content(
role="user",
parts=[
Part.from_text("What is the weather like in Boston?"),
],
)
],
generation_config = GenerationConfig(temperature=0),
tools = [
Tool(
function_declarations=[get_current_weather_func],
)
]
)
Vous pouvez également déclarer la fonction automatiquement avec la fonction d'assistance from_func, comme illustré dans l'exemple suivant :
def get_current_weather(location: str = "Boston, MA"):
"""
Get the current weather in a given location
Args:
location: The city name of the location for which to get the weather.
"""
# This example uses a mock implementation.
# You can define a local function or import the requests library to call an API
return {
"location": "Boston, MA",
"temperature": 38,
"description": "Partly Cloudy",
"icon": "partly-cloudy",
"humidity": 65,
"wind": {
"speed": 10,
"direction": "NW"
}
}
get_current_weather_func = FunctionDeclaration.from_func(get_current_weather)
Node.js
Cet exemple illustre un scénario textuel avec une fonction et un prompt.
Node.js
Avant d'essayer cet exemple, suivez les instructions de configuration pour Node.js décrites dans le guide de démarrage rapide de la plate-forme d'agents à l'aide des bibliothèques clientes.
Pour vous authentifier auprès de la plate-forme d'agents, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Go
Cet exemple illustre un scénario textuel avec une fonction et un prompt.
Découvrez comment installer ou mettre à jour le Go.
Pour en savoir plus, lisez la documentation de référence du SDK.
Définissez des variables d'environnement pour utiliser le SDK Gen AI avec Vertex AI :
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_ENTERPRISE=True
C#
Cet exemple illustre un scénario textuel avec une fonction et un prompt.
C#
Avant d'essayer cet exemple, suivez les instructions de configuration pour C# décrites dans le guide de démarrage rapide de la plate-forme d'agents à l'aide des bibliothèques clientes.
Pour vous authentifier auprès de la plate-forme d'agents, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Java
Java
Avant d'essayer cet exemple, suivez les instructions de configuration pour Java décrites dans le guide de démarrage rapide de la plate-forme d'agents à l'aide des bibliothèques clientes.
Pour vous authentifier auprès de la plate-forme d'agents, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Si le modèle détermine qu'il a besoin du résultat d'une fonction particulière, la réponse que l'application reçoit du modèle contient le nom de la fonction et les valeurs des paramètres avec lesquels la fonction doit être appelée.
Voici un exemple de réponse de modèle au prompt utilisateur "Quel temps fait-il à Boston ?". Le modèle propose d'appeler la fonction get_current_weather avec le paramètre Boston, MA.
candidates {
content {
role: "model"
parts {
function_call {
name: "get_current_weather"
args {
fields {
key: "location"
value {
string_value: "Boston, MA"
}
}
}
}
}
}
...
}
Étape 2 : Fournir la sortie de l'API au modèle
Appeler l'API externe et transmettre le résultat de l'API au modèle
L'exemple suivant utilise des données synthétiques pour simuler une charge utile de réponse provenant d'une API externe et renvoie le résultat au modèle :
REST
PROJECT_ID=myproject
MODEL_ID=gemini-2.5-flash
LOCATION="us-central1"
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://${LOCATION}-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/${LOCATION}/publishers/google/models/${MODEL_ID}:generateContent \
-d '{
"contents": [
{
"role": "user",
"parts": {
"text": "What is the weather in Boston?"
}
},
{
"role": "model",
"parts": [
{
"functionCall": {
"name": "get_current_weather",
"args": {
"location": "Boston, MA"
}
}
}
]
},
{
"role": "user",
"parts": [
{
"functionResponse": {
"name": "get_current_weather",
"response": {
"temperature": 20,
"unit": "C"
}
}
}
]
}
],
"tools": [
{
"function_declarations": [
{
"name": "get_current_weather",
"description": "Get the current weather in a specific location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city name of the location for which to get the weather."
}
},
"required": [
"location"
]
}
}
]
}
]
}'
SDK Agent Platform
function_response_contents = []
function_response_parts = []
# Iterates through the function calls in the response in case there are parallel function call requests
for function_call in response.candidates[0].function_calls:
print(f"Function call: {function_call.name}")
# In this example, we'll use synthetic data to simulate a response payload from an external API
if (function_call.args['location'] == "Boston, MA"):
api_response = { "location": "Boston, MA", "temperature": 38, "description": "Partly Cloudy" }
if (function_call.args['location'] == "San Francisco, CA"):
api_response = { "location": "San Francisco, CA", "temperature": 58, "description": "Sunny" }
function_response_parts.append(
Part.from_function_response(
name=function_call.name,
response={"contents": api_response}
)
)
# Add the function call response to the contents
function_response_contents = Content(role="user", parts=function_response_parts)
# Submit the User's prompt, model's response, and API output back to the model
response = model.generate_content(
[
Content( # User prompt
role="user",
parts=[
Part.from_text("What is the weather like in Boston?"),
],
),
response.candidates[0].content, # Function call response
function_response_contents # API output
],
tools=[
Tool(
function_declarations=[get_current_weather_func],
)
],
)
# Get the model summary response
print(response.text)
Pour connaître les bonnes pratiques relatives aux appels d'API, consultez Bonnes pratiques pour les appels d'API.
Si le modèle a proposé plusieurs appels de fonction parallèles, l'application doit fournir toutes les réponses au modèle. Pour en savoir plus, consultez Exemple d'appel de fonction parallèle.
Le modèle peut déterminer que le résultat d'une autre fonction est nécessaire pour répondre au prompt. Dans ce cas, la réponse que l'application reçoit du modèle contient un autre nom de fonction et un autre ensemble de valeurs de paramètres.
Si le modèle détermine que la réponse de l'API est suffisante pour répondre au prompt de l'utilisateur, il crée une réponse en langage naturel et la renvoie à l'application. Dans ce cas, l'application doit renvoyer la réponse à l'utilisateur. Voici un exemple de réponse en langage naturel :
It is currently 38 degrees Fahrenheit in Boston, MA with partly cloudy skies.
Appel de fonction avec raisonnement
Lorsque vous appelez des fonctions avec l'analyse activée, vous devez obtenir le thought_signature à partir de l'objet de réponse du modèle et le renvoyer lorsque vous renvoyez le résultat de l'exécution de la fonction au modèle. Exemple :
Python
# Call the model with function declarations
# ...Generation config, Configure the client, and Define user prompt (No changes)
# Send request with declarations (using a thinking model)
response = client.models.generate_content(
model="gemini-2.5-flash", config=config, contents=contents)
# See thought signatures
for part in response.candidates[0].content.parts:
if not part.text:
continue
if part.thought and part.thought_signature:
print("Thought signature:")
print(part.thought_signature)
Il n'est pas obligatoire d'afficher les signatures de pensée, mais vous devrez ajuster l'étape 2 pour les renvoyer avec le résultat de l'exécution de la fonction afin qu'elles puissent être intégrées à la réponse finale :
Python
# Create user friendly response with function result and call the model again
# ...Create a function response part (No change)
# Append thought signatures, function call and result of the function execution to contents
function_call_content = response.candidates[0].content
# Append the model's function call message, which includes thought signatures
contents.append(function_call_content)
contents.append(types.Content(role="user", parts=[function_response_part])) # Append the function response
final_response = client.models.generate_content(
model="gemini-2.5-flash",
config=config,
contents=contents,
)
print(final_response.text)
Lorsque vous renvoyez des signatures de pensée, suivez ces consignes :
- Le modèle renvoie des signatures dans d'autres parties de la réponse, par exemple les parties "Appel de fonction", "Texte", "Texte" ou "Résumés de pensée". Renvoyez l'intégralité de la réponse avec toutes les parties au modèle lors des tours suivants.
- Ne fusionnez pas une partie avec une signature avec une autre partie qui contient également une signature. Les signatures ne peuvent pas être concaténées.
- Ne fusionnez pas une partie avec une signature avec une autre partie sans signature. Cela perturbe le positionnement correct de la pensée représentée par la signature.
En savoir plus sur les limites et l'utilisation des signatures de pensée et sur les modèles de réflexion
Appel de fonction en parallèle
Pour les requêtes de type "Puis-je obtenir des informations sur la météo à Boston et San Francisco ?", le modèle peut proposer plusieurs appels de fonction parallèles. Pour obtenir la liste des modèles compatibles avec l'appel de fonction parallèle, consultez Modèles compatibles.
REST
Cet exemple illustre un scénario avec une fonction get_current_weather.
Le prompt de l'utilisateur est "Puis-je obtenir des informations sur la météo à Boston et San Francisco ?". Le modèle propose deux appels de fonction get_current_weather parallèles : l'un avec le paramètre Boston et l'autre avec le paramètre San Francisco.
{
"candidates": [
{
"content": {
"role": "model",
"parts": [
{
"functionCall": {
"name": "get_current_weather",
"args": {
"location": "Boston"
}
}
},
{
"functionCall": {
"name": "get_current_weather",
"args": {
"location": "San Francisco"
}
}
}
]
},
...
}
],
...
}
La commande suivante montre comment fournir la sortie de la fonction au modèle. Remplacez my-project par le nom de votre projet Google Cloud .
Requête de modèle
PROJECT_ID=my-project
MODEL_ID=gemini-2.5-flash
LOCATION="us-central1"
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://${LOCATION}-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/${LOCATION}/publishers/google/models/${MODEL_ID}:generateContent \
-d '{
"contents": [
{
"role": "user",
"parts": {
"text": "What is difference in temperature in Boston and San Francisco?"
}
},
{
"role": "model",
"parts": [
{
"functionCall": {
"name": "get_current_weather",
"args": {
"location": "Boston"
}
}
},
{
"functionCall": {
"name": "get_current_weather",
"args": {
"location": "San Francisco"
}
}
}
]
},
{
"role": "user",
"parts": [
{
"functionResponse": {
"name": "get_current_weather",
"response": {
"temperature": 30.5,
"unit": "C"
}
}
},
{
"functionResponse": {
"name": "get_current_weather",
"response": {
"temperature": 20,
"unit": "C"
}
}
}
]
}
],
"tools": [
{
"function_declarations": [
{
"name": "get_current_weather",
"description": "Get the current weather in a specific location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city name of the location for which to get the weather."
}
},
"required": [
"location"
]
}
}
]
}
]
}'
La réponse en langage naturel créée par le modèle ressemble à ce qui suit :
Réponse de modèle
[
{
"candidates": [
{
"content": {
"parts": [
{
"text": "The temperature in Boston is 30.5C and the temperature in San Francisco is 20C. The difference is 10.5C. \n"
}
]
},
"finishReason": "STOP",
...
}
]
...
}
]
Python
Cet exemple illustre un scénario avec une fonction get_current_weather.
Le prompt de l'utilisateur est "Quel temps fait-il à Boston et à San Francisco ?".
Remplacez my-project par le nom de votre projet Google Cloud .
import vertexai
from vertexai.generative_models import (
Content,
FunctionDeclaration,
GenerationConfig,
GenerativeModel,
Part,
Tool,
ToolConfig
)
# Initialize Agent Platform
# TODO(developer): Update the project
vertexai.init(project="my-project", location="us-central1")
# Initialize Gemini model
model = GenerativeModel(model_name="gemini-2.5-flash")
# Manual function declaration
get_current_weather_func = FunctionDeclaration(
name="get_current_weather",
description="Get the current weather in a given location",
# Function parameters are specified in JSON schema format
parameters={
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city name of the location for which to get the weather.",
"default": {
"string_value": "Boston, MA"
}
}
},
},
)
response = model.generate_content(
contents = [
Content(
role="user",
parts=[
Part.from_text("What is the weather like in Boston and San Francisco?"),
],
)
],
generation_config = GenerationConfig(temperature=0),
tools = [
Tool(
function_declarations=[get_current_weather_func],
)
]
)
La commande suivante montre comment fournir la sortie de la fonction au modèle.
function_response_contents = []
function_response_parts = []
# You can have parallel function call requests for the same function type.
# For example, 'location_to_lat_long("London")' and 'location_to_lat_long("Paris")'
# In that case, collect API responses in parts and send them back to the model
for function_call in response.candidates[0].function_calls:
print(f"Function call: {function_call.name}")
# In this example, we'll use synthetic data to simulate a response payload from an external API
if (function_call.args['location'] == "Boston, MA"):
api_response = { "location": "Boston, MA", "temperature": 38, "description": "Partly Cloudy" }
if (function_call.args['location'] == "San Francisco, CA"):
api_response = { "location": "San Francisco, CA", "temperature": 58, "description": "Sunny" }
function_response_parts.append(
Part.from_function_response(
name=function_call.name,
response={"contents": api_response}
)
)
# Add the function call response to the contents
function_response_contents = Content(role="user", parts=function_response_parts)
function_response_contents
response = model.generate_content(
contents = [
Content(
role="user",
parts=[
Part.from_text("What is the weather like in Boston and San Francisco?"),
],
), # User prompt
response.candidates[0].content, # Function call response
function_response_contents, # Function response
],
tools = [
Tool(
function_declarations=[get_current_weather_func],
)
]
)
# Get the model summary response
print(response.text)
Go
Réponses de fonction multimodales
Pour les modèles Gemini 3 Pro et ultérieurs, vous pouvez inclure du contenu multimodal dans les parties de réponse de la fonction que vous envoyez au modèle. Le modèle peut traiter ce contenu multimodal lors de son prochain tour pour produire une réponse plus pertinente. Les types MIME suivants sont acceptés pour le contenu multimodal dans les réponses de fonction :
- Images :
image/png,image/jpeg,image/webp - Documents :
application/pdf,text/plain
Pour inclure des données multimodales dans une réponse de fonction, ajoutez-les sous forme d'une ou plusieurs parties imbriquées dans la partie functionResponse. Chaque partie multimodale doit contenir inlineData ou fileData. Si vous référencez une partie multimodale à partir du champ response structuré, elle doit contenir un displayName unique.
Vous pouvez également référencer une partie multimodale à partir du champ response structuré de la partie functionResponse en utilisant le format de référence JSON {"$ref": "<displayName>"}. Le modèle remplace la référence par le contenu multimodal lorsqu'il traite la réponse. Chaque displayName ne peut être référencé qu'une seule fois dans le champ response structuré.
L'exemple suivant montre un message contenant un functionResponse pour une fonction nommée get_image et une partie imbriquée contenant des données d'image. Le champ response de functionResponse fait référence à cette partie de l'image :
Python
from google import genai
from google.genai import types
client = genai.Client()
# This is a manual, two turn multimodal function calling workflow:
# 1. Define the function tool
get_image_declaration = types.FunctionDeclaration(
name="get_image",
description="Retrieves the image file reference for a specific order item.",
parameters={
"type": "object",
"properties": {
"item_name": {
"type": "string",
"description": "The name or description of the item ordered (e.g., 'green shirt')."
}
},
"required": ["item_name"],
},
)
tool_config = types.Tool(function_declarations=[get_image_declaration])
# 2. Send a message that triggers the tool
prompt = "Show me the green shirt I ordered last month."
response_1 = client.models.generate_content(
model="gemini-3.1-pro-preview",
contents=[prompt],
config=types.GenerateContentConfig(
tools=[tool_config],
)
)
# 3. Handle the function call
function_call = response_1.function_calls[0]
requested_item = function_call.args["item_name"]
print(f"Model wants to call: {function_call.name}")
# Execute your tool (e.g., call an API)
# (This is a mock response for the example)
print(f"Calling external tool for: {requested_item}")
function_response_data = {
"image_ref": {"$ref": "dress.jpg"},
}
function_response_multimodal_data = types.FunctionResponsePart(
file_data=types.FunctionResponseFileData(
mime_type="image/png",
display_name="dress.jpg",
file_uri="gs://cloud-samples-data/generative-ai/image/dress.jpg",
)
)
# 4. Send the tool's result back
# Append this turn's messages to history for a final response.
history = [
types.Content(role="user", parts=[types.Part(text=prompt)]),
response_1.candidates[0].content,
types.Content(
role="tool",
parts=[
types.Part.from_function_response(
name=function_call.name,
response=function_response_data,
parts=[function_response_multimodal_data]
)
],
)
]
response_2 = client.models.generate_content(
model="gemini-3.1-pro-preview",
contents=history,
config=types.GenerateContentConfig(
tools=[tool_config],
thinking_config=types.ThinkingConfig(include_thoughts=True)
),
)
print(f"\nFinal model response: {response_2.text}")
REST
"contents": [
...,
{
"role": "user",
"parts": [
{
"functionResponse": {
"name": "get_image",
"response": {
"image_ref": {
"$ref": "wakeupcat.jpg"
}
},
"parts": [
{
"fileData": {
"displayName": "wakeupcat.jpg",
"mimeType": "image/jpeg",
"fileUri": "gs://cloud-samples-data/vision/label/wakeupcat.jpg"
}
}
]
}
}
]
}
]
Arguments d'appel de fonction en streaming
Pour les modèles Gemini 3 Pro et ultérieurs, vous pouvez demander que les arguments d'appel de fonction soient diffusés en streaming au fur et à mesure de leur génération par le modèle, au lieu d'attendre que l'ensemble complet d'arguments soit généré. Cela permet de réduire la latence perçue lorsque des fonctions doivent être appelées.
Cette fonctionnalité présente les limites suivantes :
- Cette fonctionnalité est disponible dans les versions d'API
v1etv1beta1.
Pour activer le streaming des arguments d'appel de fonction, définissez streamFunctionCallArguments sur true dans toolConfig.functionCallingConfig lorsque vous appelez streamGenerateContent.
Lorsque streamFunctionCallArguments est activé, les réponses intermédiaires contiennent un objet functionCall avec les champs partialArgs et willContinue.
partialArgs contient les fragments d'arguments tels qu'ils sont générés, et willContinue indique si d'autres fragments sont attendus pour l'appel de fonction.
partialArgs: tableau d'objetsPartialArg, chacun contenant :jsonPath: chaîne JSONPath indiquant le chemin d'accès à ce fragment dans l'objet de paramètres de la fonction. Le chemin d'accès peut pointer vers un argument (par exemple,$.location) ou vers un élément à l'intérieur d'un argument si l'argument est un objet (par exemple,$.location.latitude).- Valeur du fragment, qui peut être
numberValue,stringValue,boolValueounullValue. willContinue: valeur booléenne dans un objetpartialArgs. Ce champ n'esttrueque pour les fragmentsstringValuelorsque la valeur de chaîne est diffusée par blocs et que d'autres blocs sont attendus pour cet argument.
willContinue: valeur booléenne dans l'objetfunctionCall. Si la valeur esttrue, d'autrespartialArgssont attendus pour l'appel de fonction global dans les réponses diffusées ultérieures. Sifalseest défini ou absent, il s'agit de la dernière réponse diffusée pour l'appel de fonction en cours.
L'exemple suivant montre une séquence de blocs generateContent diffusés en continu, où les arguments d'un seul appel de fonction sont diffusés en continu :
{
"parts": [
{
"functionCall": {
"name": "controlLight",
"partialArgs": [
{
"jsonPath": "$.brightness",
"numberValue": 50
}
],
"willContinue": true
}
}
],
"role": "model"
}
{
"parts": [
{
"functionCall": {
"partialArgs": [
{
"jsonPath": "$.colorTemperature",
"stringValue": "warm",
"willContinue": true
}
],
"willContinue": true
}
}
],
"role": "model"
}
{
"parts": [
{
"functionCall": {
"partialArgs": [
{
"jsonPath": "$.colorTemperature"
}
],
"willContinue": true
}
}
],
"role": "model"
}
{
"parts": [
{
"functionCall": {}
}
],
"role": "model"
}
L'exemple suivant montre comment les arguments des appels de fonction parallèles peuvent être diffusés sur plusieurs réponses pour la requête "Quelle est la différence de température entre New Delhi et San Francisco ?" :
{
"candidates": [{
"content": {
"role": "model",
"parts": [{
"functionCall": {
"name": "get_current_weather",
"willContinue": true
},
}]
}
}],
}
{
"candidates": [{
"content": {
"role": "model",
"parts": [{
"functionCall": {
"partialArgs": [{
"jsonPath": "$.location",
"stringValue": "New Delhi",
"willContinue": true
}],
"willContinue": true
}
}]
}
}],
}
{
"candidates": [{
"content": {
"role": "model",
"parts": [{
"functionCall": {
"partialArgs": [{
"jsonPath": "$.location",
"stringValue": ""
}],
"willContinue": true
}
}]
}
}],
}
{
"candidates": [{
"content": {
"role": "model",
"parts": [{
"functionCall": {
}
}]
}
}],
}
{
"candidates": [{
"content": {
"role": "model",
"parts": [{
"functionCall": {
"name": "get_current_weather",
"willContinue": true
},
}]
}
}],
}
{
"candidates": [{
"content": {
"role": "model",
"parts": [{
"functionCall": {
"partialArgs": [{
"jsonPath": "$.location",
"stringValue": "San Francisco",
"willContinue": true
}],
"willContinue": true
}
}]
}
}],
}
{
"candidates": [{
"content": {
"role": "model",
"parts": [{
"functionCall": {
"partialArgs": [{
"jsonPath": "$.location",
"stringValue": ""
}],
"willContinue": true
}
}]
}
}],
}
{
"candidates": [{
"content": {
"role": "model",
"parts": [{
"functionCall": {
}
}]
}
}],
}
Python
from google import genai
from google.genai import types
client = genai.Client()
get_weather_declaration = types.FunctionDeclaration(
name="get_weather",
description="Gets the current weather temperature for a given location.",
parameters={
"type": "object",
"properties": {"location": {"type": "string"}},
"required": ["location"],
},
)
get_weather_tool = types.Tool(function_declarations=[get_weather_declaration])
for chunk in client.models.generate_content_stream(
model="gemini-3.1-pro-preview",
contents="What's the weather in London and New York?",
config=types.GenerateContentConfig(
tools=[get_weather_tool],
tool_config = types.ToolConfig(
function_calling_config=types.FunctionCallingConfig(
mode=types.FunctionCallingConfigMode.AUTO,
stream_function_call_arguments=True,
)
),
),
):
function_call = chunk.function_calls[0]
if function_call and function_call.name:
print(f"{function_call.name}")
print(f"will_continue={function_call.will_continue}")
Modes d'appel de fonction
Vous pouvez contrôler la manière dont le modèle utilise les outils fournis (déclarations de fonction) en définissant le mode dans function_calling_config.
| Mode | Description |
|---|---|
AUTO |
Comportement par défaut du modèle. Le modèle décide s'il faut prédire des appels de fonction ou répondre en langage naturel en fonction du contexte. Il s'agit du mode le plus flexible, recommandé pour la plupart des scénarios. |
VALIDATED |
Le modèle est contraint de prédire des appels de fonction ou du langage naturel, et garantit le respect du schéma de fonction. Si allowed_function_names n'est pas fourni, le modèle sélectionne toutes les déclarations de fonction disponibles. Si allowed_function_names est fourni, le modèle choisit parmi l'ensemble de fonctions autorisées. À partir de Gemini 3, ce mode impose également la présence des paramètres requis. |
ANY |
Le modèle est contraint de toujours prédire un ou plusieurs appels de fonction et garantit le respect du schéma de fonction. Si allowed_function_names n'est pas fourni, le modèle sélectionne toutes les déclarations de fonction disponibles. Si allowed_function_names est fourni, le modèle choisit parmi l'ensemble de fonctions autorisées. Utilisez ce mode lorsque vous avez besoin d'une réponse d'appel de fonction pour chaque requête (le cas échéant). |
NONE |
Le modèle n'est pas autorisé à effectuer des appels de fonction. Cela équivaut à envoyer une requête sans aucune déclaration de fonction. Utilisez ce mode pour désactiver temporairement l'appel de fonction sans supprimer vos définitions d'outils. |
Appel de fonction forcé
Au lieu de permettre au modèle de choisir entre une réponse en langage naturel et un appel de fonction, vous pouvez l'obliger à ne prédire que les appels de fonction. C'est ce qu'on appelle l'appel de fonction forcé. Vous pouvez également choisir de fournir au modèle un ensemble complet de déclarations de fonctions, mais limiter ses réponses à un sous-ensemble de ces fonctions.
L'exemple suivant est forcé de prédire uniquement les appels de fonction get_weather.
Python
response = model.generate_content(
contents = [
Content(
role="user",
parts=[
Part.from_text("What is the weather like in Boston?"),
],
)
],
generation_config = GenerationConfig(temperature=0),
tools = [
Tool(
function_declarations=[get_weather_func, some_other_function],
)
],
tool_config=ToolConfig(
function_calling_config=ToolConfig.FunctionCallingConfig(
# ANY mode forces the model to predict only function calls
mode=ToolConfig.FunctionCallingConfig.Mode.ANY,
# Allowed function calls to predict when the mode is ANY. If empty, any of
# the provided function calls will be predicted.
allowed_function_names=["get_weather"],
)
)
)
Exemples de schémas de fonctions
Les déclarations de fonctions sont compatibles avec le schéma OpenAPI. Nous acceptons les attributs suivants : type, nullable, required, format, description, properties, items, enum, anyOf, $ref et $defs. Les autres attributs ne sont pas acceptés.
Fonction avec des paramètres d'objet et de tableau
L'exemple suivant utilise un dictionnaire Python pour déclarer une fonction qui accepte à la fois des paramètres d'objet et de tableau :
extract_sale_records_func = FunctionDeclaration( name="extract_sale_records", description="Extract sale records from a document.", parameters={ "type": "object", "properties": { "records": { "type": "array", "description": "A list of sale records", "items": { "description": "Data for a sale record", "type": "object", "properties": { "id": {"type": "integer", "description": "The unique id of the sale."}, "date": {"type": "string", "description": "Date of the sale, in the format of MMDDYY, e.g., 031023"}, "total_amount": {"type": "number", "description": "The total amount of the sale."}, "customer_name": {"type": "string", "description": "The name of the customer, including first name and last name."}, "customer_contact": {"type": "string", "description": "The phone number of the customer, e.g., 650-123-4567."}, }, "required": ["id", "date", "total_amount"], }, }, }, "required": ["records"], }, )
Fonction avec paramètre enum
L'exemple suivant utilise un dictionnaire Python pour déclarer une fonction qui accepte un paramètre enum entier :
set_status_func = FunctionDeclaration( name="set_status", description="set a ticket's status field", # Function parameters are specified in JSON schema format parameters={ "type": "object", "properties": { "status": { "type": "integer", "enum": [ "10", "20", "30" ], # Provide integer (or any other type) values as strings. } }, }, )
Fonction avec ref et def
La déclaration de fonction JSON suivante utilise les attributs ref et defs :
{ "contents": ..., "tools": [ { "function_declarations": [ { "name": "get_customer", "description": "Search for a customer by name", "parameters": { "type": "object", "properties": { "first_name": { "ref": "#/defs/name" }, "last_name": { "ref": "#/defs/name" } }, "defs": { "name": { "type": "string" } } } } ] } ] }
Remarques concernant l'utilisation :
- Contrairement au schéma OpenAPI, spécifiez
refetdefssans le symbole$. refdoit faire référence à l'enfant direct dedefs. Aucune référence externe n'est autorisée.- La profondeur maximale du schéma imbriqué est de 32.
- La profondeur de récursion dans
defs(autoréférence) est limitée à deux.
from_func avec paramètre de tableau
L'exemple de code suivant déclare une fonction qui multiplie un tableau de nombres et utilise from_func pour générer le schéma FunctionDeclaration.
from typing import List # Define a function. Could be a local function or you can import the requests library to call an API def multiply_numbers(numbers: List[int] = [1, 1]) -> int: """ Calculates the product of all numbers in an array. Args: numbers: An array of numbers to be multiplied. Returns: The product of all the numbers. If the array is empty, returns 1. """ if not numbers: # Handle empty array return 1 product = 1 for num in numbers: product *= num return product multiply_number_func = FunctionDeclaration.from_func(multiply_numbers) """ multiply_number_func contains the following schema: {'name': 'multiply_numbers', 'description': 'Calculates the product of all numbers in an array.', 'parameters': {'properties': {'numbers': {'items': {'type': 'INTEGER'}, 'description': 'list of numbers', 'default': [1.0, 1.0], 'title': 'Numbers', 'type': 'ARRAY'}}, 'description': 'Calculates the product of all numbers in an array.', 'title': 'multiply_numbers', 'property_ordering': ['numbers'], 'type': 'OBJECT'}} """
Bonnes pratiques pour l'appel de fonction
Pour améliorer vos résultats lorsque vous utilisez l'appel de fonction, suivez ces bonnes pratiques :
Rédigez des noms de fonctions, des descriptions de paramètres et des instructions clairs et détaillés.
Les noms de fonction doivent commencer par une lettre ou un trait de soulignement, et contenir uniquement des lettres (A-Z, a-z), des chiffres (0-9), des traits de soulignement, des points et des tirets, avec une longueur maximale de 64 caractères.
Soyez extrêmement clair et précis dans vos descriptions de fonctions et de paramètres. Le modèle s'appuie sur ces informations pour choisir la fonction appropriée et fournir les arguments adéquats. Par exemple, une fonction
book_flight_ticketpeut avoir la descriptionbook flight tickets after confirming users' specific requirements, such as time, departure, destination, party size and preferred airline.
Utiliser des paramètres fortement typés
Si les valeurs des paramètres proviennent d'un ensemble fini, ajoutez un champ enum au lieu de placer l'ensemble de valeurs dans la description. Si la valeur du paramètre est toujours un entier, définissez le type sur integer plutôt que number.
Sélection des outils
Bien que le modèle puisse utiliser un nombre arbitraire d'outils, en fournir trop peut augmenter le risque de sélectionner un outil incorrect ou non optimal. Pour obtenir les meilleurs résultats, essayez de ne fournir que les outils pertinents pour le contexte ou la tâche, en gardant idéalement l'ensemble actif à un maximum de 10 à 20. Si vous disposez d'un grand nombre d'outils, envisagez de sélectionner les outils de manière dynamique en fonction du contexte de la conversation.
Si vous fournissez des outils génériques de bas niveau (comme bash), le modèle peut utiliser l'outil plus souvent, mais avec moins de précision. Si vous fournissez un outil spécifique de haut niveau (comme get_weather), le modèle pourra l'utiliser plus précisément, mais il risque de ne pas être utilisé aussi souvent.
Utiliser les instructions système
Lorsque vous utilisez des fonctions avec des paramètres de date, d'heure ou d'emplacement, incluez la date et l'heure actuelles ou les informations de localisation pertinentes (par exemple, la ville et le pays) dans l'instruction système. Cela fournit au modèle le contexte nécessaire pour traiter la requête avec précision, même si le prompt de l'utilisateur manque de détails.
Prompt engineering
Pour de meilleurs résultats, ajoutez les informations suivantes en préfixe au prompt utilisateur :
- Contexte supplémentaire pour le modèle (par exemple,
You are a flight API assistant to help with searching flights based on user preferences.) - Détails ou instructions sur quand et comment utiliser les fonctions (par exemple,
Don't make assumptions on the departure or destination airports. Always use a future date for the departure or destination time.) - Instructions pour poser des questions de clarification si les requêtes des utilisateurs sont ambiguës (par exemple,
Ask clarifying questions if not enough information is available.)
Utiliser la configuration de génération
Pour le paramètre de température, utilisez 0 ou une autre valeur faible. Cela indique au modèle de générer des résultats plus fiables et de réduire les hallucinations.
Utiliser une sortie structurée
Les appels de fonction peuvent être utilisés avec les sorties structurées pour permettre au modèle de toujours prédire des appels de fonction ou des sorties qui respectent un schéma spécifique. Vous recevez ainsi des réponses mises en forme de manière cohérente lorsque le modèle ne génère pas d'appels de fonction.
Valider l'appel d'API
Si le modèle propose d'appeler une fonction qui permet d'envoyer une commande, d'actualiser une base de données ou de provoquer des conséquences importantes, validez l'appel de fonction auprès de l'utilisateur avant de l'exécuter.
Utiliser les signatures de réflexion
Pour obtenir les meilleurs résultats, les signatures de pensée doivent toujours être utilisées avec l'appel de fonction.
Tarifs
Les tarifs des appels de fonction sont basés sur le nombre de caractères dans les entrées et les sorties textuelles. Pour en savoir plus, consultez les tarifs de Gemini Enterprise Agent Platform.
Ici, l'entrée textuelle (prompt) fait référence au prompt utilisateur pour le tour de conversation en cours, aux déclarations de fonction pour le tour de conversation en cours et à l'historique de la conversation. L'historique de la conversation inclut les requêtes, les appels de fonction et les réponses de fonction des tours de conversation précédents. Gemini Enterprise Agent Platform tronque l'historique de la conversation à 32 000 caractères.
La sortie textuelle (réponse) fait référence aux appels de fonction et aux réponses textuelles pour le tour de conversation en cours.
Cas d'utilisation des appels de fonction
Vous pouvez utiliser les appels de fonction pour les tâches suivantes :
| Cas d'utilisation | Exemple de description | Exemple de lien |
|---|---|---|
| Intégrer des API externes | Obtenir des informations météorologiques à l'aide d'une API de service météorologique | Tutoriel de notebook |
| Convertir des adresses en coordonnées de latitude/longitude | Tutoriel de notebook | |
| Convertir des devises à l'aide d'une API de taux de change | Atelier de programmation | |
| Créer des chatbots avancés | Répondre aux questions des clients sur les produits et services | Tutoriel de notebook |
| Créer un assistant pour répondre à des questions financières et d'actualité sur des entreprises | Tutoriel de notebook | |
| Structurer et contrôler les appels de fonction | Extraire des entités structurées à partir de données de journaux brutes | Tutoriel de notebook |
| Extraire un ou plusieurs paramètres de l'entrée utilisateur | Tutoriel de notebook | |
| Gérer les listes et les structures de données imbriquées dans les appels de fonction | Tutoriel de notebook | |
| Gérer le comportement d'appel de fonction | Gérer les appels et les réponses de fonctions parallèles | Tutoriel de notebook |
| Gérer les fonctions que le modèle peut appeler et quand il peut le faire | Tutoriel de notebook | |
| Interroger des bases de données en langage naturel | Convertir des questions en langage naturel en requêtes SQL pour BigQuery | Exemple d'application |
| Appel de fonction multimodal | Utiliser des images, des vidéos, des fichiers audio et des PDF comme entrée pour déclencher des appels de fonction | Tutoriel de notebook |
Voici d'autres cas d'utilisation :
Interpréter des commandes vocales : créez des fonctions correspondant aux tâches effectuées dans un véhicule. Vous pouvez par exemple créer des fonctions qui allument la radio ou activent la climatisation. Envoyez au modèle les fichiers audio des commandes vocales de l'utilisateur, et demandez-lui de convertir l'audio en texte et d'identifier la fonction que l'utilisateur souhaite appeler.
Automatiser les workflows en fonction de déclencheurs d'environnement : créez des fonctions pour représenter les processus pouvant être automatisés. Fournissez au modèle des données provenant de capteurs environnementaux et demandez-lui de les analyser et de les traiter pour déterminer si un ou plusieurs workflows doivent être activés. Par exemple, un modèle peut traiter des données de température dans un entrepôt et choisir d'activer une fonction d'arrosage.
Automatiser l'attribution des demandes d'assistance : fournissez au modèle des demandes d'assistance, des journaux et des règles contextuelles. Demandez au modèle de traiter toutes ces informations pour déterminer à qui la demande doit être attribuée. Appelez une fonction pour attribuer la demande à la personne suggérée par le modèle.
Récupérer des informations à partir d'une base de connaissances : créez des fonctions permettant de récupérer des articles universitaires sur un sujet donné et de les résumer. Autorisez le modèle à répondre à des questions sur des sujets académiques et à fournir des citations pour ses réponses.