

Notre service Gen AI Evaluation Service fournit des outils pensés pour les entreprises, qui permettent d'évaluer les modèles d'IA générative de manière objective et en s'appuyant sur les données. Il accompagne et facilite un certain nombre de tâches de développement, comme les migrations de modèles, la modification des prompts et l'affinage.
Fonctionnalités de Gen AI Evaluation Service
La fonctionnalité phare du service d'évaluation de l'IA générative est la possibilité d'utiliser des rubriques adaptatives, un ensemble de tests personnalisés de réussite ou d'échec pour chaque requête. Les rubriques d'évaluation sont semblables aux tests unitaires dans le développement logiciel et visent à améliorer les performances des modèles pour diverses tâches.
Le service d'évaluation de l'IA générative est compatible avec les méthodes d'évaluation courantes suivantes :
Rubriques adaptatives (recommandé) : génère un ensemble unique de rubriques de réussite ou d'échec pour chaque requête individuelle de votre ensemble de données.
Rubriques statiques : appliquez un ensemble fixe de critères de notation à toutes les requêtes.
Métriques issues de calculs : utilisez des algorithmes déterministes tels que
ROUGEouBLEUlorsqu'une vérité terrain est disponible.Fonctions personnalisées : définissez votre propre logique d'évaluation en Python pour des exigences spécifiques.
Génération d'ensembles de données d'évaluation
Vous pouvez créer un ensemble de données d'évaluation de différentes manières :
Importez un fichier contenant des instances d'invite complètes ou fournissez un modèle d'invite avec un fichier de valeurs de variables correspondant pour remplir les invites complètes.
Échantillonnez directement à partir des journaux de production pour évaluer l'utilisation réelle de votre modèle.
Générez des données synthétiques pour obtenir un grand nombre d'exemples cohérents pour n'importe quel modèle d'invite.
Interfaces compatibles
Vous pouvez définir et exécuter vos évaluations à l'aide des interfaces suivantes :
ConsoleGoogle Cloud : interface utilisateur Web qui fournit un workflow guidé de bout en bout. Gérez vos ensembles de données, exécutez des évaluations et explorez en détail des rapports et des visualisations interactifs. Consultez Effectuer une évaluation à l'aide de la console.
SDK Python : exécutez des évaluations par programmation et affichez des comparaisons côte à côte des modèles directement dans votre environnement Colab ou Jupyter. Consultez Effectuer une évaluation à l'aide du client GenAI dans le SDK Agent Platform.
Cas d'utilisation
Gen AI Evaluation Service vous permet de voir les performances d'un modèle pour vos tâches spécifiques et selon vos critères uniques. Il fournit des insights précieux qui ne peuvent pas être obtenus à partir des classements publics ni des benchmarks généraux. Cela permet d'effectuer des tâches de développement critiques, y compris :
Migrations de modèles : comparez les versions de modèles pour comprendre les différences de comportement et ajuster vos requêtes et paramètres en conséquence.
Trouver le meilleur modèle : comparez directement les modèles Google et tiers sur vos données pour établir une référence de performances et identifier celui qui convient le mieux à votre cas d'utilisation.
Amélioration des requêtes : utilisez les résultats de l'évaluation pour orienter vos efforts de personnalisation. En réexécutant une évaluation, vous créez une boucle de rétroaction étroite qui fournit des commentaires immédiats et quantifiables sur vos modifications.
Affinage du modèle : évaluez la qualité d'un modèle affiné en appliquant des critères d'évaluation cohérents à chaque exécution.
Évaluation de l'agent : évaluez les performances d'un agent à l'aide de métriques spécifiques à l'agent, telles que les traces d'agent et la qualité des réponses.
Workflow d'évaluation
Pour effectuer une évaluation, vous devez généralement suivre les étapes suivantes :
Créer un ensemble de données d'évaluation : assemblez un ensemble de données d'instances de prompt qui reflètent votre cas d'utilisation spécifique. Vous pouvez inclure des réponses de référence (vérité terrain) si vous prévoyez d'utiliser des métriques issues de calculs.
Définissez les métriques d'évaluation : choisissez les métriques que vous souhaitez utiliser pour mesurer les performances du modèle.
Générez des réponses de modèle : sélectionnez un ou plusieurs modèles pour générer des réponses pour votre ensemble de données. Le SDK Agent Platform est compatible avec tous les modèles pouvant être appelés via
LiteLLM, tandis que la console est compatible avec les modèles Google Gemini.Exécutez l'évaluation : exécutez le job d'évaluation, qui évalue les réponses de chaque modèle par rapport aux métriques que vous avez sélectionnées.
Interpréter les résultats : examinez les scores agrégés et les réponses individuelles pour analyser les performances du modèle.
Métriques d'évaluation
Voici les principaux concepts liés aux métriques d'évaluation :
Rubriques : critères permettant d'évaluer la réponse d'un modèle ou d'une application LLM.
Métriques : score qui mesure la sortie du modèle par rapport aux rubriques de notation.
Le service d'évaluation de l'IA générative propose les catégories de métriques suivantes :
Métriques basées sur des rubriques : intègrent des LLM dans les workflows d'évaluation pour évaluer la qualité des réponses du modèle. Les évaluations basées sur des rubriques conviennent à diverses tâches, en particulier la qualité de l'écriture, la sécurité et le respect des instructions, qui sont souvent difficiles à évaluer avec des algorithmes déterministes.
Rubriques adaptatives (recommandées) : les rubriques sont générées de manière dynamique pour chaque requête, comme des tests unitaires. Les réponses sont évaluées à l'aide d'un ensemble unique de tests de réussite ou d'échec pour chaque requête individuelle de votre ensemble de données. Les rubriques permettent de maintenir l'évaluation en lien avec la tâche demandée et visent à fournir des résultats objectifs, explicables et cohérents.
Les rubriques adaptatives sont généralement le moyen le plus rapide de commencer à évaluer, car elles garantissent que chaque évaluation est pertinente pour la tâche spécifique évaluée.
Rubriques statiques : les rubriques sont définies de manière explicite et la même rubrique s'applique à toutes les requêtes. Les réponses sont évaluées avec le même ensemble d'évaluateurs numériques basés sur des scores. Un seul score numérique (par exemple, de 1 à 5) par requête. Utilisez des rubriques statiques lorsqu'une évaluation est requise sur une dimension très spécifique ou lorsque la même rubrique exacte est requise pour toutes les requêtes.
Métriques issues de calculs : évaluez les réponses avec des algorithmes déterministes, généralement à l'aide de la vérité terrain. Score numérique (par exemple, de 0,0 à 1,0) par requête. Lorsque la vérité terrain est disponible et peut être mise en correspondance avec une méthode déterministe.
Métriques de fonction personnalisées (SDK Agent Platform uniquement) : définissez votre propre métrique à l'aide d'une fonction Python.
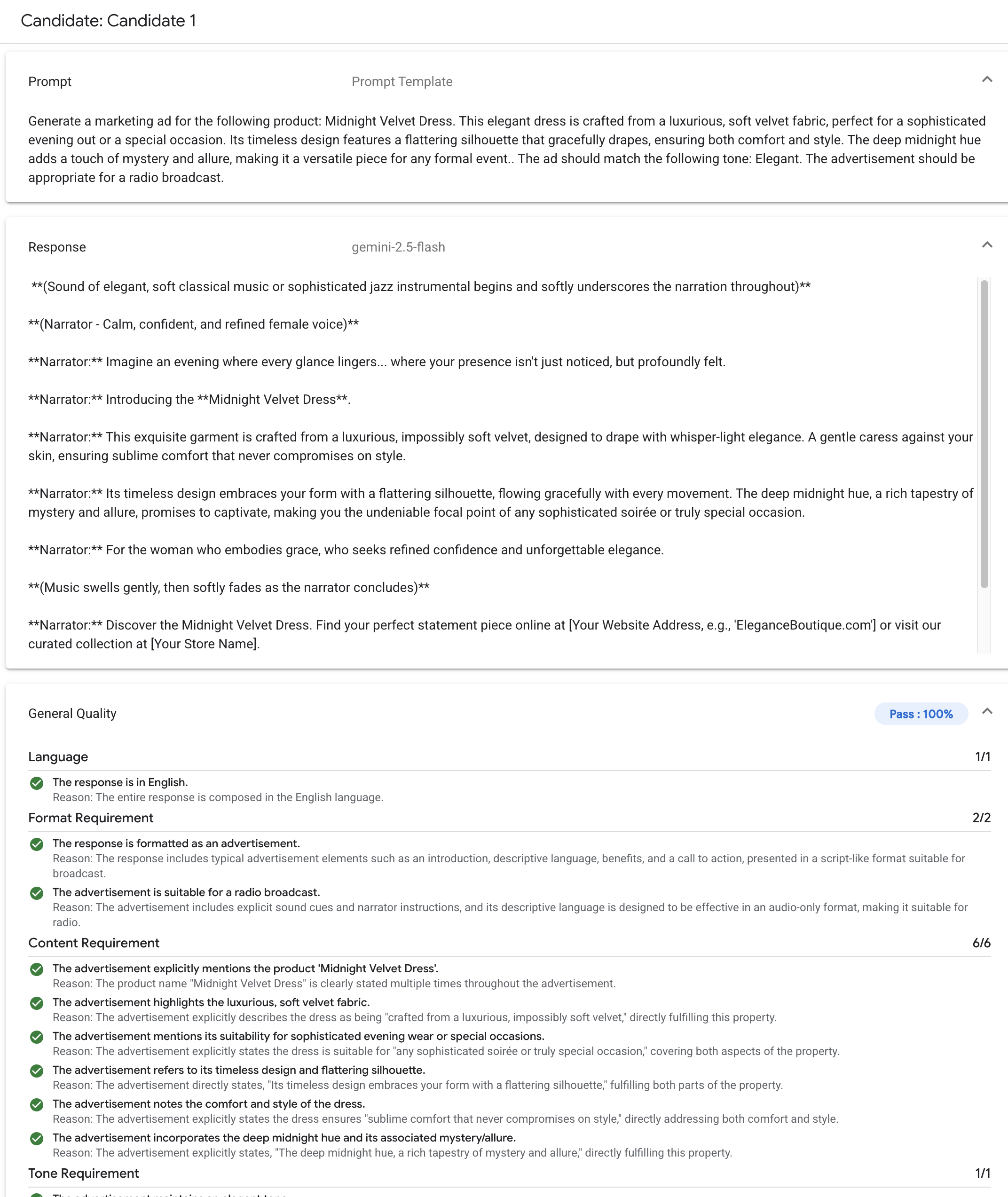
Exemple de grille d'évaluation adaptative
Le processus d'évaluation de chaque requête utilise un système en deux étapes :
Génération de rubriques : le service analyse d'abord votre requête et génère une liste de tests spécifiques et vérifiables (les rubriques) auxquels une bonne réponse doit répondre.
Validation de la grille d'évaluation : une fois que votre modèle a généré une réponse, le service l'évalue par rapport à chaque grille d'évaluation, en fournissant un verdict clair (
PassouFail) et une explication.
Le résultat final est un taux de réussite agrégé et une répartition détaillée des rubriques réussies par le modèle. Vous obtenez ainsi des insights exploitables pour diagnostiquer les problèmes et mesurer les améliorations.
En passant de scores subjectifs de haut niveau à des résultats de tests précis et objectifs, vous pouvez adopter un cycle de développement axé sur l'évaluation et appliquer les bonnes pratiques d'ingénierie logicielle au processus de création d'applications d'IA générative.
L'exemple suivant montre des rubriques adaptatives générées pour un ensemble de requêtes :
Requête utilisateur : Write a four-sentence summary of the provided article about renewable energy, maintaining an optimistic tone.
Pour cette requête, l'étape de génération de la grille d'évaluation peut produire les grilles d'évaluation suivantes :
Grille d'évaluation 1 : la réponse est un résumé de l'article fourni.
Grille d'évaluation 2 : la réponse contient exactement quatre phrases.
Grille d'évaluation 3 : La réponse maintient un ton optimiste.
Votre modèle peut produire la réponse suivante : The article highlights significant growth in solar and wind power. These advancements are making clean energy more affordable. The future looks bright for renewables. However, the report also notes challenges with grid infrastructure.
Lors de la validation de la grille d'évaluation, Gen AI Evaluation Service évalue la réponse par rapport à chaque grille :
Grille d'évaluation 1 : la réponse est un résumé de l'article fourni.
Verdict :
PassRaison : la réponse résume correctement les points principaux.
Grille d'évaluation 2 : la réponse contient exactement quatre phrases.
Verdict :
PassRaison : La réponse se compose de quatre phrases distinctes.
Grille d'évaluation 3 : La réponse maintient un ton optimiste.
Verdict :
FailRaison : la dernière phrase introduit un point négatif, qui nuit au ton optimiste.
Le taux de réussite final pour cette réponse est de 66,7%. Pour comparer deux modèles, vous pouvez évaluer leurs réponses par rapport à ce même ensemble de tests générés et comparer leurs taux de réussite globaux.
Premiers pas avec les évaluations
Vous pouvez commencer à effectuer des évaluations à l'aide de la console.
Vous pouvez également utiliser le code suivant pour effectuer une évaluation avec le client GenAI dans le SDK Agent Platform :
from vertexai import Client
from vertexai import types
import pandas as pd
client = Client(project=PROJECT_ID, location=LOCATION)
# Create an evaluation dataset
prompts_df = pd.DataFrame({
"prompt": [
"Write a simple story about a dinosaur",
"Generate a poem about Agent Platform",
],
})
# Get responses from one or multiple models
eval_dataset = client.evals.run_inference(model="gemini-2.5-flash", src=prompts_df)
# Define the evaluation metrics and run the evaluation job
eval_result = client.evals.evaluate(
dataset=eval_dataset,
metrics=[types.RubricMetric.GENERAL_QUALITY]
)
# View the evaluation results
eval_result.show()
Le service d'évaluation de l'IA générative propose deux interfaces SDK Agent Platform :
Client GenAI dans le SDK Agent Platform (recommandé) (preview)
from vertexai import clientLe client GenAI est la nouvelle interface recommandée pour l'évaluation. Vous pouvez y accéder via la classe Client unifiée. Il est compatible avec toutes les méthodes d'évaluation et est conçu pour les workflows qui incluent la comparaison de modèles, la visualisation dans un notebook et des insights pour la personnalisation de modèles.
Module d'évaluation dans le SDK Agent Platform (disponibilité générale)
from vertexai.evaluation import EvalTaskLe module d'évaluation est l'ancienne interface. Il est conservé pour assurer la rétrocompatibilité avec les workflows existants, mais n'est plus en cours de développement actif. Il est accessible via la classe
EvalTask. Cette méthode est compatible avec les métriques standard LLM-as-a-judge et basées sur le calcul, mais pas avec les méthodes d'évaluation plus récentes comme les rubriques adaptatives.
Régions où le service est disponible
Les régions suivantes sont compatibles avec le service d'évaluation de l'IA générative :
Iowa (
us-central1)Caroline du Sud (
us-east1)Virginie du Nord (
us-east4)Columbus, Ohio (
us-east5)Dallas, Texas (
us-south1)Oregon (
us-west1)Las Vegas, Nevada (
us-west4)Varsovie, Pologne (
europe-central2)Finlande (
europe-north1)Madrid, Espagne (
europe-southwest1)Belgique (
europe-west1)Pays-Bas (
europe-west4)Milan, Italie (
europe-west8)Paris, France (
europe-west9)Numéro international (
global)
Notebooks disponibles
| Liens vers les notebooks | Description |
|---|---|
| Premiers pas : évaluation rapide de l'IA générative | Présente le service d'évaluation de l'IA générative. |
| Évaluer des modèles tiers avec le service d'évaluation de l'IA générative | Montre comment utiliser le **SDK Agent Platform** pour évaluer différents types de modèles tiers, y compris les modèles accessibles à l'aide d'API (comme OpenAI, Anthropic), les modèles en tant que service (MaaS) de Vertex Model Garden et les points de terminaison Bring Your Own Model (BYOM). |
| Migration de modèles avec le service d'évaluation de l'IA générative | Montre comment utiliser le **SDK Agent Platform** pour le service d'évaluation Gen AI afin de comparer deux modèles propriétaires (par exemple, Gemini 2.0 Flash et Gemini 2.5 Flash). Il explique comment utiliser des métriques prédéfinies basées sur des rubriques adaptatives et comment les résultats de l'évaluation peuvent guider l'optimisation des requêtes. Les principales fonctionnalités, telles que l'évaluation multicandidats, la visualisation dans un notebook et l'évaluation par lot asynchrone, sont également abordées. |
| Évaluer la qualité du texte à l'image avec le service d'évaluation de l'IA générative | Montre comment utiliser le SDK Vertex AI pour le service d'évaluation de l'IA générative afin d'évaluer la qualité des images générées en fonction des requêtes textuelles. Il montre comment utiliser la métrique Gecko prédéfinie basée sur une grille d'évaluation adaptative. |
| Évaluer la qualité de la génération de vidéos à partir de texte avec le service d'évaluation de l'IA générative | Montre comment utiliser le **SDK Agent Platform** pour le service d'évaluation de l'IA générative afin d'évaluer la qualité des vidéos générées à partir d'invites textuelles. Il montre comment utiliser la métrique Gecko prédéfinie basée sur une grille d'évaluation adaptative. |