
אחרי שיוצרים ומעריכים את מודל ה-AI הגנרטיבי, אפשר להשתמש במודל כדי ליצור סוכן, כמו צ'אטבוט. שירות ההערכה של AI גנרטיבי מאפשר לכם למדוד את היכולת של הסוכן להשלים משימות ולהשיג יעדים לתרחיש השימוש שלכם.
סקירה כללית
אלה האפשרויות שלכם להערכת הסוכן:
הערכת התגובה הסופית: הערכה של הפלט הסופי של הסוכן (האם הסוכן השיג את היעד שלו או לא).
הערכת המסלול: הערכה של הנתיב (רצף של קריאות לכלים) שהסוכן עבר כדי להגיע לתשובה הסופית.
בעזרת שירות ההערכה של AI גנרטיבי, אתם יכולים להפעיל סוכן ולקבל מדדים להערכת המסלול ולהערכת התשובה הסופית בשאילתה אחת ב-Vertex AI SDK.
נציגי תמיכה נתמכים
שירות ההערכה של AI גנרטיבי תומך בקטגוריות הבאות של סוכנים:
| נציגי תמיכה נתמכים | תיאור |
|---|---|
| סוכן שנבנה באמצעות תבנית של Agent Engine | Agent Engine (LangChain on Vertex AI) היא פלטפורמה שבה אפשר לפרוס סוכנים ולנהל אותם. Google Cloud |
| סוכני LangChain שנבנו באמצעות תבנית שניתנת להתאמה אישית של Agent Engine | LangChain היא פלטפורמה בקוד פתוח. |
| פונקציה מותאמת אישית של נציג | פונקציה מותאמת אישית של סוכן היא פונקציה גמישה שמקבלת הנחיה לסוכן ומחזירה תגובה ומסלול במילון. |
הגדרת מדדים להערכת סוכנים
מגדירים את המדדים להערכת התשובה הסופית או המסלול:
הערכה סופית של התשובה
הערכת התגובה הסופית מתבצעת באותו אופן כמו הערכת תגובת המודל. מידע נוסף זמין במאמר בנושא הגדרת מדדי ההערכה.
הערכת מסלול
המדדים הבאים עוזרים להעריך את היכולת של המודל לפעול בהתאם למסלול הצפוי:
התאמה מדויקת
אם המסלול החזוי זהה למסלול הייחוס, עם אותן קריאות כלים בדיוק ובאותו סדר בדיוק, המדד trajectory_exact_match מחזיר ציון של 1, אחרת 0.
פרמטרים של קלט מדדים
| פרמטר קלט | תיאור |
|---|---|
predicted_trajectory |
רשימת השיחות עם הכלי שבהן השתמש הסוכן כדי להגיע לתשובה הסופית. |
reference_trajectory |
השימוש הצפוי בכלי על ידי הסוכן כדי לענות על השאילתה. |
פרסום ציונים
| ערך | תיאור |
|---|---|
| 0 | המסלול החזוי לא תואם למסלול ההשוואה. |
| 1 | המסלול החזוי תואם לקובץ העזר. |
התאמה לפי סדר
אם המסלול החזוי מכיל את כל הקריאות לכלי מהמסלול להשוואה באותו סדר, ויכול להיות שהוא מכיל גם קריאות נוספות לכלי, מדד trajectory_in_order_match מחזיר ציון של 1, אחרת הוא מחזיר 0.
פרמטרים של קלט מדדים
| פרמטר קלט | תיאור |
|---|---|
predicted_trajectory |
המסלול החזוי שבו הסוכן השתמש כדי להגיע לתשובה הסופית. |
reference_trajectory |
המסלול הצפוי של הסוכן כדי לענות על השאילתה. |
פרסום ציונים
| ערך | תיאור |
|---|---|
| 0 | הקריאות לכלי במסלול החזוי לא תואמות לסדר במסלול ההפניה. |
| 1 | המסלול החזוי תואם לקובץ העזר. |
התאמה בכל סדר
אם המסלול החזוי מכיל את כל הקריאות לכלים ממסלול ההפניה, אבל הסדר לא משנה ויכול להיות שהוא מכיל קריאות נוספות לכלים, המדד trajectory_any_order_match מחזיר ציון של 1, אחרת 0.
פרמטרים של קלט מדדים
| פרמטר קלט | תיאור |
|---|---|
predicted_trajectory |
רשימת השיחות עם הכלי שבהן השתמש הסוכן כדי להגיע לתשובה הסופית. |
reference_trajectory |
השימוש הצפוי בכלי על ידי הסוכן כדי לענות על השאילתה. |
פרסום ציונים
| ערך | תיאור |
|---|---|
| 0 | המסלול החזוי לא מכיל את כל קריאות הכלים במסלול ההפניה. |
| 1 | המסלול החזוי תואם לקובץ העזר. |
Precision
המדד trajectory_precision מודד כמה מהקריאות לכלי במסלול החזוי הן רלוונטיות או נכונות בפועל בהשוואה למסלול הייחוס.
הדיוק מחושב באופן הבא: סופרים כמה פעולות במסלול החזוי מופיעות גם במסלול הייחוס. מחלקים את המספר הזה במספר הכולל של הפעולות במסלול החזוי.
פרמטרים של קלט מדדים
| פרמטר קלט | תיאור |
|---|---|
predicted_trajectory |
רשימת השיחות עם הכלי שבהן השתמש הסוכן כדי להגיע לתשובה הסופית. |
reference_trajectory |
השימוש הצפוי בכלי על ידי הסוכן כדי לענות על השאילתה. |
פרסום ציונים
| ערך | תיאור |
|---|---|
| מספר צף בטווח [0,1] | ככל שהציון גבוה יותר, כך המסלול החזוי מדויק יותר. |
Recall
מדד trajectory_recall מודד כמה מהקריאות החיוניות לכלים ממסלול ההפניה נלכדות בפועל במסלול החזוי.
החישוב של Recall מתבצע באופן הבא: סופרים כמה פעולות במסלול הייחוס מופיעות גם במסלול החיזוי. מחלקים את המספר הזה במספר הכולל של הפעולות במסלול ההפניה.
פרמטרים של קלט מדדים
| פרמטר קלט | תיאור |
|---|---|
predicted_trajectory |
רשימת השיחות עם הכלי שבהן השתמש הסוכן כדי להגיע לתשובה הסופית. |
reference_trajectory |
השימוש הצפוי בכלי על ידי הסוכן כדי לענות על השאילתה. |
פרסום ציונים
| ערך | תיאור |
|---|---|
| מספר צף בטווח [0,1] | ככל שהציון גבוה יותר, כך התחזית לגבי מסלול ההמראה טובה יותר. |
שימוש בכלי יחיד
המדד trajectory_single_tool_use בודק אם נעשה שימוש בכלי ספציפי שצוין במפרט המדד במסלול החיזוי. היא לא בודקת את הסדר של קריאות הכלים או כמה פעמים נעשה שימוש בכלי, אלא רק אם הוא קיים או לא.
פרמטרים של קלט מדדים
| פרמטר קלט | תיאור |
|---|---|
predicted_trajectory |
רשימת השיחות עם הכלי שבהן השתמש הסוכן כדי להגיע לתשובה הסופית. |
פרסום ציונים
| ערך | תיאור |
|---|---|
| 0 | הכלי לא מופיע |
| 1 | הכלי קיים. |
בנוסף, כברירת מחדל, שני מדדי הביצועים הבאים של הנציגים מתווספים לתוצאות ההערכה. אין צורך לציין אותם ב-EvalTask.
latency
משך הזמן שחלף עד שהנציג השיב.
| ערך | תיאור |
|---|---|
| מספר ממשי (Float) | החישוב מתבצע בשניות. |
failure
ערך בוליאני שמתאר אם הפעלת הסוכן הסתיימה בשגיאה או בהצלחה.
פרסום ציונים
| ערך | תיאור |
|---|---|
| 1 | שגיאה |
| 0 | הוחזרה תגובה תקינה |
הכנת מערך הנתונים להערכת הסוכן
הכנת מערך הנתונים לתשובה סופית או להערכת מסלול.
סכימת הנתונים להערכת התגובה הסופית דומה לזו של הערכת תגובת המודל.
כדי לבצע הערכה של מסלול מבוססת-חישוב, מערך הנתונים צריך לכלול את הפרטים הבאים:
| סוג קלט | תוכן של שדה להזנת קלט |
|---|---|
predicted_trajectory |
רשימת קריאות הכלים שבהן השתמשו הסוכנים כדי להגיע לתגובה הסופית. |
reference_trajectory (לא נדרש עבור trajectory_single_tool_use metric) |
השימוש הצפוי בכלי על ידי הסוכן כדי לענות על השאילתה. |
דוגמאות למערכי נתונים להערכה
בדוגמאות הבאות מוצגים מערכי נתונים להערכת מסלולים. שימו לב: חובה להשתמש בפרמטר reference_trajectory בכל המדדים, חוץ מאשר במדד trajectory_single_tool_use.
reference_trajectory = [
# example 1
[
{
"tool_name": "set_device_info",
"tool_input": {
"device_id": "device_2",
"updates": {
"status": "OFF"
}
}
}
],
# example 2
[
{
"tool_name": "get_user_preferences",
"tool_input": {
"user_id": "user_y"
}
},
{
"tool_name": "set_temperature",
"tool_input": {
"location": "Living Room",
"temperature": 23
}
},
]
]
predicted_trajectory = [
# example 1
[
{
"tool_name": "set_device_info",
"tool_input": {
"device_id": "device_3",
"updates": {
"status": "OFF"
}
}
}
],
# example 2
[
{
"tool_name": "get_user_preferences",
"tool_input": {
"user_id": "user_z"
}
},
{
"tool_name": "set_temperature",
"tool_input": {
"location": "Living Room",
"temperature": 23
}
},
]
]
eval_dataset = pd.DataFrame({
"predicted_trajectory": predicted_trajectory,
"reference_trajectory": reference_trajectory,
})
ייבוא מערך נתונים להערכה
אפשר לייבא את קבוצת הנתונים בפורמטים הבאים:
קובץ JSONL או CSV שמאוחסן ב-Cloud Storage
טבלת BigQuery
Pandas DataFrame
שירות ההערכה של AI גנרטיבי מספק מערכי נתונים ציבוריים לדוגמה כדי להדגים איך אפשר להעריך את הסוכנים. הקוד הבא מראה איך לייבא את מערכי הנתונים הציבוריים מקטגוריה של Cloud Storage:
# dataset name to be imported
dataset = "on-device" # Alternatives: "customer-support", "content-creation"
# copy the tools and dataset file
!gcloud storage cp gs://cloud-ai-demo-datasets/agent-eval-datasets/{dataset}/tools.py .
!gcloud storage cp gs://cloud-ai-demo-datasets/agent-eval-datasets/{dataset}/eval_dataset.json .
# load the dataset examples
import json
eval_dataset = json.loads(open('eval_dataset.json').read())
# run the tools file
%run -i tools.py
כאשר dataset הוא אחד ממערכי הנתונים הציבוריים הבאים:
"on-device"ל-Assistant לבית חכם במכשיר, ששולטת במכשירים בבית. הסוכן עוזר בשאילתות כמו "תזמן את המזגן בחדר השינה כך שהוא יפעל בין 23:00 ל-8:00, ויכבה בשאר הזמן"."customer-support"כדי לדבר עם נציג תמיכה. הנציג עוזר בשאלות כמו "Can you cancel any pending orders and escalate any open support tickets?" (האם אפשר לבטל הזמנות בהמתנה ולהעביר לטיפול ברמה גבוהה יותר כרטיסי תמיכה פתוחים?).
"content-creation"לסוכן ליצירת תוכן שיווקי. הסוכן עוזר בשאילתות כמו "תזמן מחדש את קמפיין X כך שיהיה קמפיין חד-פעמי באתר מדיה חברתית Y עם תקציב מופחת ב-50%, רק ב-25 בדצמבר 2024".
הרצת הערכה של סוכן
מריצים הערכה של מסלול או של תשובה סופית:
כדי להעריך סוכנים, אפשר לשלב בין מדדים להערכת תגובות לבין מדדים להערכת מסלול, כמו בקוד הבא:
single_tool_use_metric = TrajectorySingleToolUse(tool_name='tool_name')
eval_task = EvalTask(
dataset=EVAL_DATASET,
metrics=[
"rouge_l_sum",
"bleu",
custom_trajectory_eval_metric, # custom computation-based metric
"trajectory_exact_match",
"trajectory_precision",
single_tool_use_metric,
response_follows_trajectory_metric # llm-based metric
],
)
eval_result = eval_task.evaluate(
runnable=RUNNABLE,
)
התאמה אישית של מדדים
אפשר להתאים אישית מדד שמבוסס על מודל שפה גדול כדי להעריך את מסלול ההתקדמות באמצעות ממשק מבוסס-תבניות או מאפס. פרטים נוספים זמינים בקטע בנושא מדדים שמבוססים על מודלים. לדוגמה:
response_follows_trajectory_prompt_template = PointwiseMetricPromptTemplate(
criteria={
"Follows trajectory": (
"Evaluate whether the agent's response logically follows from the "
"sequence of actions it took. Consider these sub-points:\n"
" - Does the response reflect the information gathered during the trajectory?\n"
" - Is the response consistent with the goals and constraints of the task?\n"
" - Are there any unexpected or illogical jumps in reasoning?\n"
"Provide specific examples from the trajectory and response to support your evaluation."
)
},
rating_rubric={
"1": "Follows trajectory",
"0": "Does not follow trajectory",
},
input_variables=["prompt", "predicted_trajectory"],
)
response_follows_trajectory_metric = PointwiseMetric(
metric="response_follows_trajectory",
metric_prompt_template=response_follows_trajectory_prompt_template,
)
אפשר גם להגדיר מדד מותאם אישית שמבוסס על חישוב להערכת מסלול או להערכת תגובה באופן הבא:
def essential_tools_present(instance, required_tools = ["tool1", "tool2"]):
trajectory = instance["predicted_trajectory"]
tools_present = [tool_used['tool_name'] for tool_used in trajectory]
if len(required_tools) == 0:
return {"essential_tools_present": 1}
score = 0
for tool in required_tools:
if tool in tools_present:
score += 1
return {
"essential_tools_present": score/len(required_tools),
}
custom_trajectory_eval_metric = CustomMetric(name="essential_tools_present", metric_function=essential_tools_present)
צפייה בתוצאות ופירוש שלהן
במקרה של הערכת מסלול או הערכת תגובה סופית, תוצאות ההערכה מוצגות באופן הבא:
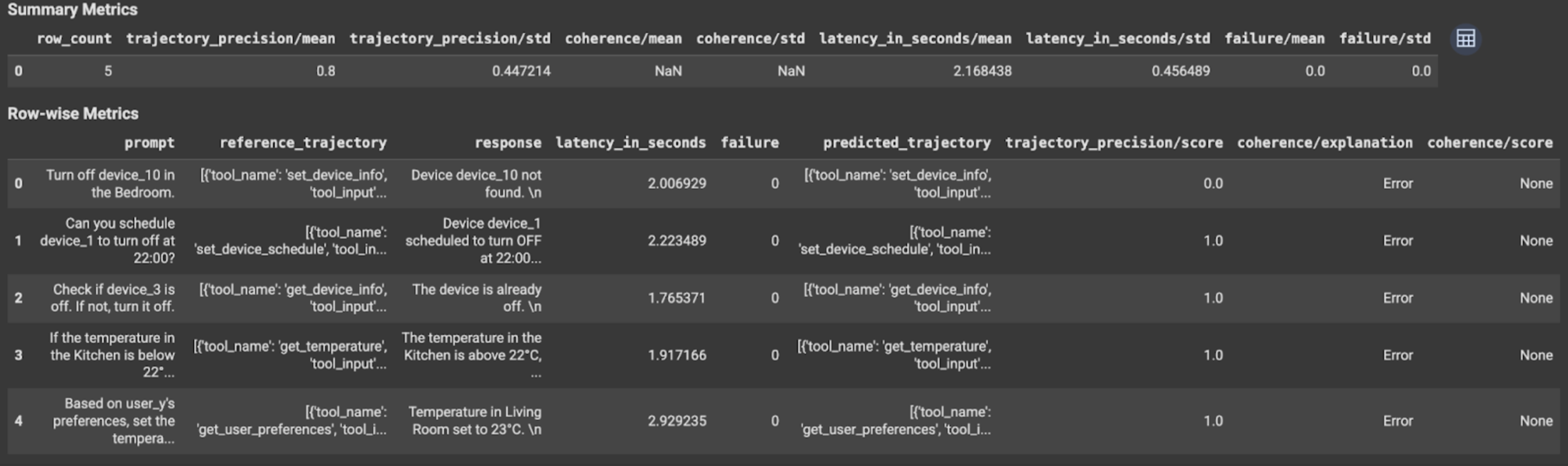
תוצאות ההערכה כוללות את הפרטים הבאים:
מדדים של תשובה סופית
תוצאות ברמת המופע
| עמודה | תיאור |
|---|---|
| תשובה | התשובה הסופית שנוצרה על ידי הסוכן. |
| latency_in_seconds | משך הזמן שלקח ליצור את התשובה. |
| נכשלה | מציין אם נוצרה תשובה תקינה או לא. |
| score | ציון שמחושב לתשובה שצוינה במפרט המדד. |
| הסבר | ההסבר לציון שצוין במפרט המדד. |
תוצאות מצטברות
| עמודה | תיאור |
|---|---|
| mean | הציון הממוצע של כל המופעים. |
| סטיית תקן | סטיית תקן של כל הציונים. |
מדדים של מסלול
תוצאות ברמת המופע
| עמודה | תיאור |
|---|---|
| predicted_trajectory | רצף של קריאות לכלים שאחריהן הסוכן מגיע לתשובה הסופית. |
| reference_trajectory | רצף של קריאות צפויות לכלים. |
| score | ציון שמחושב לגבי מסלול התנועה החזוי ומסלול התנועה להשוואה שצוינו במפרט המדד. |
| latency_in_seconds | משך הזמן שלקח ליצור את התשובה. |
| נכשלה | מציין אם נוצרה תשובה תקינה או לא. |
תוצאות מצטברות
| עמודה | תיאור |
|---|---|
| mean | הציון הממוצע של כל המופעים. |
| סטיית תקן | סטיית תקן של כל הציונים. |
פרוטוקול Agent2Agent (A2A)
אם אתם בונים מערכת מרובת סוכנים, מומלץ לעיין בפרוטוקול A2A. פרוטוקול A2A הוא תקן פתוח שמאפשר תקשורת ושיתוף פעולה חלקים בין סוכני AI, ללא קשר למסגרות הבסיסיות שלהם. הוא נתרם על ידי Google Cloud ל-Linux Foundation ביוני 2025. כדי להשתמש בערכות ה-SDK של A2A או לנסות את הדוגמאות, אפשר לעיין במאגר GitHub.
המאמרים הבאים
אפשר לנסות את מחברות ההערכה הבאות של סוכנים: