
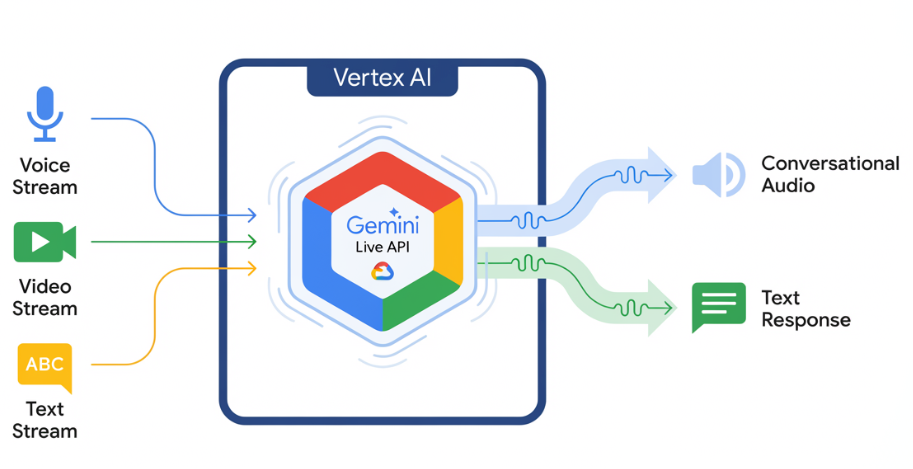
Die Gemini Live API ermöglicht latenzarme Sprach- und Videointeraktionen mit Gemini in Echtzeit. Es verarbeitet kontinuierliche Audio-, Video- oder Textstreams, um sofortige, menschenähnliche gesprochene Antworten zu liefern. So können Sie Ihren Nutzern eine natürliche Konversationsumgebung bieten.
Gemini Live API in Vertex AI Studio testen
Beispielanwendungsfälle
Mit der Gemini Live API können Sie Sprach- und Video-Agents in Echtzeit für eine Vielzahl von Branchen erstellen, darunter:
- E-Commerce und Einzelhandel:Shopping-Assistenten, die personalisierte Empfehlungen geben, und Support-Agenten, die Kundenprobleme lösen.
- Gaming:Interaktive nicht spielbare Charaktere (NPCs), In-Game-Hilfeassistenten und Echtzeitübersetzung von In-Game-Inhalten.
- Schnittstellen der nächsten Generation:Sprach- und videobasierte Funktionen in Robotern, Smart Glasses und Fahrzeugen.
- Gesundheitswesen:Gesundheitsbegleiter zur Unterstützung und Aufklärung von Patienten.
- Finanzdienstleistungen:KI-basierte Beratung für Vermögensverwaltung und Anlageempfehlungen.
- Bildung:KI-Mentoren und Lernbegleiter, die personalisierte Anleitungen und Feedback geben.
Wichtige Features
Die Gemini Live API bietet eine umfassende Reihe von Funktionen zum Erstellen leistungsstarker Sprach- und Video-Agents:
- Hohe Audioqualität: Die Gemini Live API bietet in mehreren Sprachen eine natürliche, realistisch klingende Sprachausgabe.
- Unterstützung mehrerer Sprachen: Sie können sich in 24 unterstützten Sprachen unterhalten.
- Barge-in: Nutzer können das Modell jederzeit unterbrechen, um responsive Interaktionen zu ermöglichen.
- Affektiver Dialog: Das Modell passt den Antwortstil und den Tonfall an die Ausdrucksweise des Nutzers an.
- Tool-Nutzung: Integriert Tools wie Funktionsaufrufe und die Google Suche für dynamische Interaktionen.
- Audio-Transkriptionen: Bietet Texttranskriptionen sowohl der Nutzereingabe als auch der Modellausgabe.
- Proaktive Audioausgabe (Vorabversion): Sie können festlegen, wann und in welchem Kontext das Modell antwortet.
Technische Spezifikationen
In der folgenden Tabelle sind die technischen Spezifikationen für die Gemini Live API aufgeführt:
| Kategorie | Details |
|---|---|
| Eingabemodalitäten | Audio (rohes 16-Bit-PCM-Audio, 16 kHz, Little Endian), Bilder/Video (JPEG, 1 FPS), Text |
| Ausgabemodalitäten | Audio (rohes 16‑Bit-PCM-Audio, 24 kHz, Little Endian), Text |
| Protokoll | Zustandsbehaftete WebSocket-Verbindung (WSS) |
Unterstützte Modelle
Die folgenden Modelle unterstützen die Gemini Live API. Wählen Sie das passende Modell für Ihre Interaktionsanforderungen aus.
| Modell-ID | Verfügbarkeit | Anwendungsfall | Wichtige Features |
|---|---|---|---|
gemini-live-2.5-flash-native-audio |
Allgemein verfügbar | Empfohlen. Sprachagenten mit niedriger Latenz. Unterstützt nahtloses Umschalten zwischen Sprachen und emotionalen Ton. |
|
gemini-live-2.5-flash-preview-native-audio-09-2025 |
Öffentliche Vorschau | Kosteneffizienz bei Echtzeit-Sprachagenten. |
|
Jetzt starten
Wählen Sie die Anleitung aus, die Ihrer Entwicklungsumgebung entspricht:
Gen AI SDK-Tutorial
Mit dem Gen AI SDK eine Verbindung zur Gemini Live API herstellen, um eine multimodale Echtzeitanwendung mit einem Python-Backend zu erstellen.
WebSocket-Tutorial
Stellen Sie über WebSockets eine Verbindung zur Gemini Live API her, um eine multimodale Echtzeitanwendung mit einem JavaScript-Frontend und einem Python-Backend zu erstellen.
ADK-Tutorial
Erstellen Sie einen Agenten und verwenden Sie das ADK-Streaming (Agent Development Kit), um Sprach- und Videokommunikation zu ermöglichen.
Einbindung in Partnerlösungen
Wenn Sie die Gemini Live API in die Plattformen einiger unserer Partner einbinden möchten, ist das ganz einfach, da diese Plattformen die API bereits über das WebRTC-Protokoll integriert haben, um die Entwicklung von Audio- und Videoanwendungen in Echtzeit zu optimieren.