
提交 Managed Service for Apache Spark 工作時,Managed Service for Apache Spark 會自動收集工作輸出內容並提供給您。這表示您可以很快地查看工作輸出,而無需在工作執行或查看複雜的記錄檔時維持對叢集的連線。
Spark 記錄
Spark 記錄分為兩種:Spark 驅動程式記錄和 Spark 執行器記錄。
Spark 驅動程式記錄包含工作輸出內容;Spark 執行器記錄包含工作可執行檔或啟動器輸出內容,例如 spark-submit「Submitted application ...」訊息,有助於進行工作失敗問題的偵錯。
Managed Service for Apache Spark 工作驅動程式與 Spark 驅動程式不同,是許多工作類型的啟動器。啟動 Spark 工作時,系統會以基礎 spark-submit 可執行檔的包裝函式形式執行,並啟動 Spark 驅動程式。Spark 驅動程式會在 Managed Service for Apache Spark 叢集上以 Spark client 或 cluster 模式執行工作:
client模式:Spark 驅動程式會在spark-submit程序中執行工作,而 Spark 記錄會傳送至 Managed Service for Apache Spark 工作驅動程式。cluster模式:Spark 驅動程式會在 YARN 容器中執行工作。Managed Service for Apache Spark 工作驅動程式無法存取 Spark 驅動程式記錄。
Managed Service for Apache Spark 和 Spark 工作屬性總覽
| 屬性 | 值 | 預設 | 說明 |
|---|---|---|---|
dataproc:dataproc.logging.stackdriver.job.driver.enable |
true 或 false | false | 必須在建立叢集時設定。如果為 true,工作驅動程式輸出會顯示在 Logging 中,並與工作資源建立關聯;如果為 false,工作驅動程式輸出不會顯示在 Logging 中。注意:如要在 Logging 中啟用工作驅動程式記錄,也必須設定下列叢集屬性,而且建立叢集時,系統會預設設定這些屬性: dataproc:dataproc.logging.stackdriver.enable=true
和 dataproc:jobs.file-backed-output.enable=true
|
dataproc:dataproc.logging.stackdriver.job.yarn.container.enable |
true 或 false | false | 必須在建立叢集時設定。
如果是 true,工作 YARN 容器記錄會與工作資源建立關聯;如果是 false,工作 YARN 容器記錄會與叢集資源建立關聯。 |
spark:spark.submit.deployMode |
用戶端或叢集 | 用戶端 | 控制 Spark client 或 cluster 模式。 |
使用 Managed Service for Apache Spark jobs API 提交的 Spark 工作
本節中的表格列出透過 Managed Service for Apache Spark jobs API 提交工作時,不同屬性設定對 Managed Service for Apache Spark 工作驅動程式輸出目的地造成的影響,包括透過Google Cloud 控制台、gcloud CLI 和 Cloud 用戶端程式庫提交工作。
建立叢集時,可以使用 --properties 旗標設定所列的 Managed Service for Apache Spark 和 Spark 屬性,這些屬性會套用至叢集上執行的所有 Spark 工作;將工作提交至 Managed Service for Apache Spark jobs API 時,也可以使用 --properties 旗標 (不含「spark:」前置字元) 設定 Spark 屬性,這些屬性只會套用至該工作。
Managed Service for Apache Spark 工作驅動程式輸出內容
下表列出不同屬性設定對 Managed Service for Apache Spark 工作驅動程式輸出內容目的地的影響。
dataproc: |
輸出 |
|---|---|
| false (預設) |
|
| true |
|
Spark 驅動程式記錄
下表列出不同屬性設定對 Spark 驅動程式記錄目的地造成的影響。
spark: |
dataproc: |
dataproc: |
驅動程式輸出內容 |
|---|---|---|---|
| 用戶端 | false (預設) | true 或 false |
|
| 用戶端 | true | true 或 false |
|
| 叢集 | false (預設) | false |
|
| 叢集 | true | true |
|
Spark 執行器記錄
下表列出不同屬性設定對 Spark 執行器記錄目的地的影響。
dataproc: |
執行器記錄 |
|---|---|
| false (預設) | 在 Logging 中:叢集資源下方的 yarn-userlogs |
| true | 在 Logging 中:工作資源下方的 dataproc.job.yarn.container |
未使用 Managed Service for Apache Spark jobs API 提交的 Spark 工作
本節列出未使用 Managed Service for Apache Spark jobs API 提交工作時,不同屬性設定對 Spark 工作記錄目的地造成的影響。未使用該 API 提交工作的情況包含直接在叢集節點上使用 spark-submit 提交工作,或使用 Jupyter 或 Zeppelin 筆記本等。
這些工作沒有 Managed Service for Apache Spark 工作 ID 或驅動程式。
Spark 驅動程式記錄
下表列出不同屬性設定對 Spark 驅動程式記錄目的地的影響,適用於未透過 Managed Service for Apache Spark jobs API 提交的工作。
spark: |
驅動程式輸出內容 |
|---|---|
| 用戶端 |
|
| 叢集 |
|
Spark 執行器記錄
如果未透過 Managed Service for Apache Spark jobs API 提交 Spark 工作,執行器記錄會位於 Logging 中叢集資源下方的 yarn-userlogs。
查看工作輸出內容
您可以在 Google Cloud 控制台、gcloud CLI、Cloud Storage 或 Logging 中存取 Managed Service for Apache Spark 工作輸出。
控制台
如要查看工作輸出內容,請前往專案的 Managed Service for Apache Spark「Job」(工作) 部分,然後按一下「Job ID」(工作 ID) 即可查看工作輸出內容。
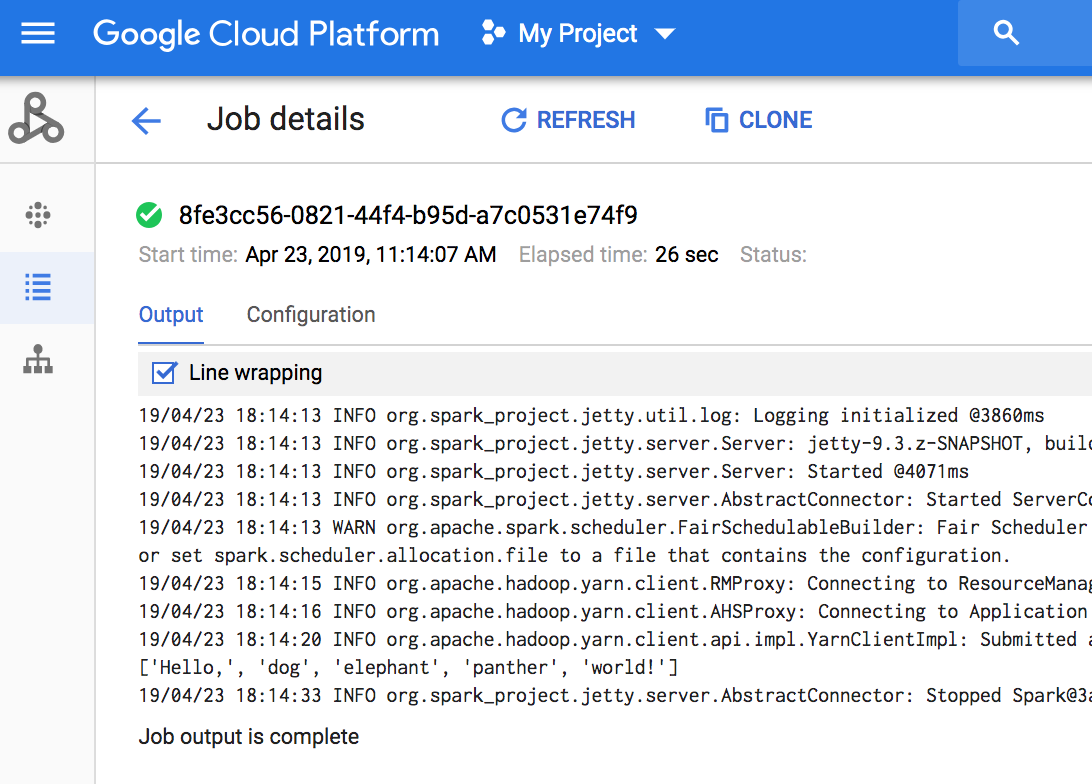
如果工作正在執行,系統會定期重新整理輸出以顯示新內容。
gcloud 指令
使用 gcloud dataproc jobs submit 指令提交工作時,會在控制台顯示工作輸出內容。您可以稍後在不同的電腦上或使用新的視窗「重新彙整」驅動程式輸出,只要將工作 ID 傳送至 gcloud dataproc jobs wait 指令即可。工作 ID 是 GUID,例如 5c1754a5-34f7-4553-b667-8a1199cb9cab。範例如下。
gcloud dataproc jobs wait 5c1754a5-34f7-4553-b667-8a1199cb9cab \ --project my-project-id --region my-cluster-region
Waiting for job output... ... INFO gcs.GoogleHadoopFileSystemBase: GHFS version: 1.4.2-hadoop2 ... 16:47:45 INFO client.RMProxy: Connecting to ResourceManager at my-test-cluster-m/ ...
Cloud Storage
工作輸出內容會儲存在 Cloud Storage 中,可能是暫存 bucket,也可能是您建立叢集時指定的 bucket。Cloud Storage 工作輸出的連結,會顯示在以下項目傳回的 Job.driverOutputResourceUri 欄位中:
- jobs.get API 要求。
- gcloud dataproc jobs describe job-id 指令。
$ gcloud dataproc jobs describe spark-pi ... driverOutputResourceUri: gs://dataproc-nnn/jobs/spark-pi/driveroutput ...