
使用 Spark 和 Lakehouse 執行階段目錄建立 Lakehouse
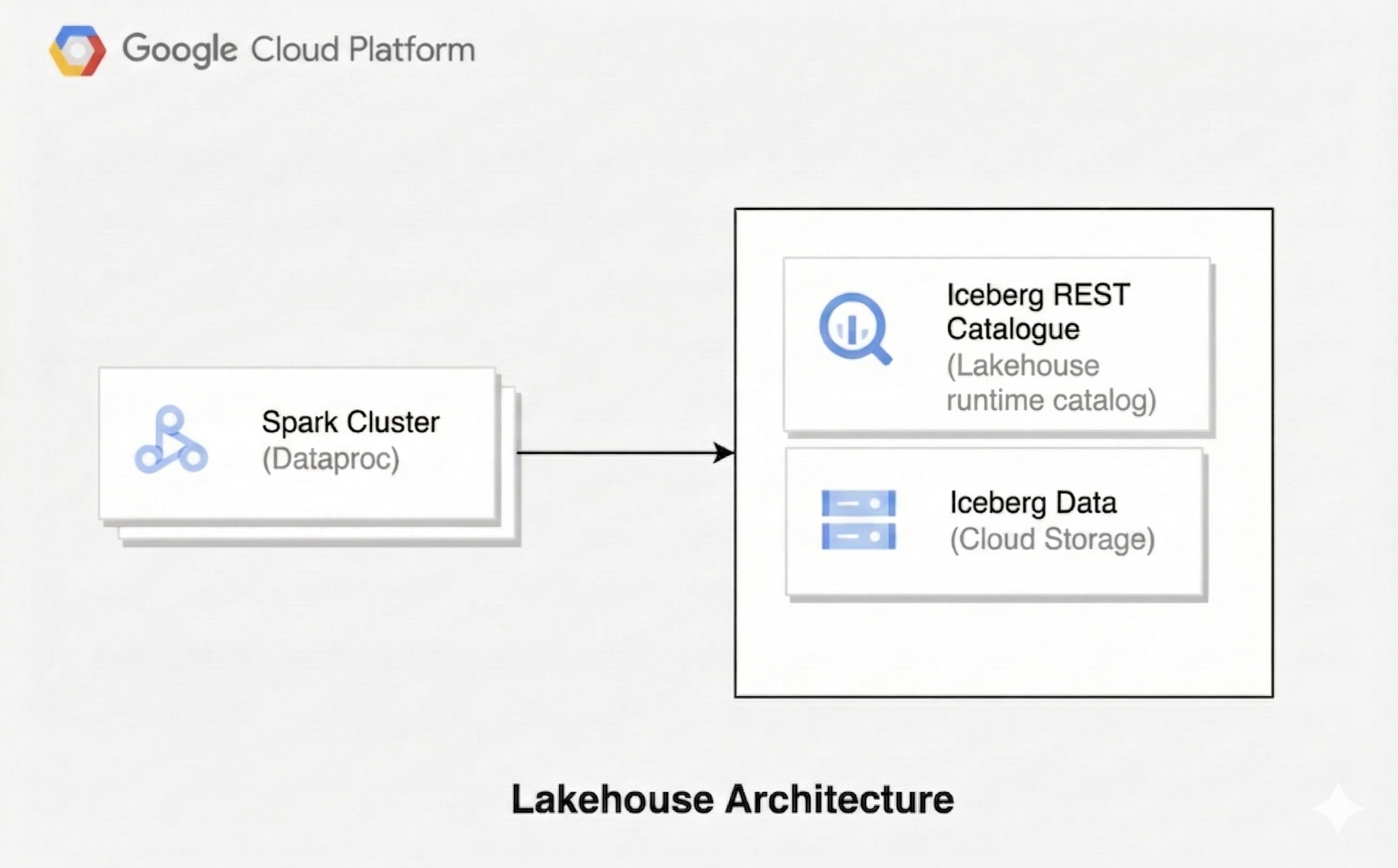
湖倉架構結合了資料湖泊的彈性,以及資料倉儲的資料管理功能。本文說明如何在 Google Cloud上設定 Lakehouse。您使用 Apache Iceberg 做為資料表格式、Managed Service for Apache Spark 進行處理,以及 Lakehouse 執行階段目錄 Iceberg REST 目錄,以進行統一中繼資料管理。
這項架構使用 Iceberg 等開放式資料表格式,為 Cloud Storage 中的資料新增資料倉儲功能,例如交易和結構定義演進。這種做法可為資料建立單一事實來源,供各種引擎存取。
事前準備
- 登入 Google Cloud 帳戶。如果您是 Google Cloud新手,歡迎 建立帳戶,親自評估產品在實際工作環境中的成效。新客戶還能獲得價值 $300 美元的免費抵免額,可用於執行、測試及部署工作負載。
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that you have the permissions required to complete this guide.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that you have the permissions required to complete this guide.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.- 建立 Cloud Storage bucket,用來儲存 Iceberg 資料。
必要的角色
您必須具備特定 Identity and Access Management (IAM) 角色,才能執行本頁面的範例。視組織政策而定,系統可能已授予這些角色。如要檢查角色授予情形,請參閱「您是否需要授予角色?」。
如要進一步瞭解如何授予角色,請參閱「管理專案、資料夾和機構的存取權」。
使用者角色
如要取得建立 Managed Service for Apache Spark 叢集所需的權限,請要求管理員授予您下列 IAM 角色:
- 專案的 Dataproc 編輯者 (
roles/dataproc.editor) - Compute Engine 預設服務帳戶的服務帳戶使用者 (
roles/iam.serviceAccountUser)
服務帳戶角色
為確保 Compute Engine 預設服務帳戶具備建立 Managed Service for Apache Spark 叢集的必要權限,請要求管理員在專案中,將 Dataproc Worker (roles/dataproc.worker) IAM 角色授予 Compute Engine 預設服務帳戶。
建立 Managed Service for Apache Spark 叢集
建立 Managed Service for Apache Spark 叢集,並使用 Iceberg 和 Jupyter 選用元件。
如要建立叢集,請執行下列
gcloud指令:gcloud dataproc clusters create CLUSTER_NAME \ --project=PROJECT_ID \ --region=REGION \ --image-version=2.3-debian12 \ --optional-components=ICEBERG,JUPYTER \ --enable-component-gateway \ --properties 'dataproc:dataproc.lineage.enabled=true'更改下列內容:
CLUSTER_NAME:叢集名稱。PROJECT_ID:您的 Google Cloud 專案 ID。REGION:叢集的 Google Cloud 區域,例如us-central1。
請注意,您不需要設定
dataproc:dataproc.lineage.enabled=true,Lakehouse 執行階段目錄 Iceberg REST 目錄就能正常運作。我們在下方的資料沿襲範例中加入這項設定,是為了追蹤沿襲。使用 Jupyter Notebook 連線至叢集。您可以透過 Vertex AI Workbench 筆記本,或直接在叢集上啟動筆記本。
設定 Spark 工作階段
在 Jupyter Notebook 中,建立設為使用 Lakehouse 執行階段目錄 Iceberg REST 目錄的 Spark 工作階段。
import pyspark
from pyspark.context import SparkContext
from pyspark.sql import SparkSession
catalog_name = "CATALOG_NAME"
spark = SparkSession.builder.appName("APP_NAME") \
.config(f'spark.sql.catalog.{catalog_name}', 'org.apache.iceberg.spark.SparkCatalog') \
.config(f'spark.sql.catalog.{catalog_name}.type', 'rest') \
.config(f'spark.sql.catalog.{catalog_name}.uri', 'https://biglake.googleapis.com/iceberg/v1beta/restcatalog') \
.config(f'spark.sql.catalog.{catalog_name}.warehouse', 'gs://GCS_BUCKET') \
.config(f'spark.sql.catalog.{catalog_name}.header.x-goog-user-project', 'PROJECT_ID') \
.config(f'spark.sql.catalog.{catalog_name}.rest.auth.type', 'org.apache.iceberg.gcp.auth.GoogleAuthManager') \
.config(f'spark.sql.catalog.{catalog_name}.io-impl', 'org.apache.iceberg.gcp.gcs.GCSFileIO') \
.config(f'spark.sql.catalog.{catalog_name}.rest-metrics-reporting-enabled', 'false') \
.config('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions') \
.config('spark.sql.defaultCatalog', catalog_name) \
.getOrCreate()
更改下列內容:
CATALOG_NAME:Iceberg 目錄的名稱,例如iceberg_catalog。APP_NAME:Spark 應用程式的名稱。GCS_BUCKET:用於儲存 Iceberg 表格資料的 Cloud Storage bucket。PROJECT_ID:您的 Google Cloud 專案 ID。
使用 Spark SQL 管理資料
設定 Spark 工作階段後,請使用 Spark SQL 執行資料管理作業。
建立命名空間。在 Lakehouse 執行階段目錄 Iceberg REST 目錄中,命名空間對應於 BigQuery 資料集。
spark.sql("CREATE NAMESPACE IF NOT EXISTS NAMESPACE_NAME") spark.sql("USE NAMESPACE_NAME")將
NAMESPACE_NAME替換為命名空間的名稱,例如spark_lakehouse。以 Iceberg 格式建立基本資料表,並插入資料。
spark.sql("DROP TABLE IF EXISTS base_table PURGE") spark.sql("CREATE TABLE base_table (id LONG) USING iceberg") spark.sql("INSERT INTO base_table VALUES 0, 1, 2, 3, 4") spark.sql("SELECT * FROM base_table").show()輸出結果會與下列內容相似:
+---+ | id| +---+ | 0| | 1| | 2| | 3| | 4| +---+建立第二個資料表來存放新資料。
spark.sql("DROP TABLE IF EXISTS newdata PURGE") spark.sql("CREATE TABLE newdata(id LONG) USING iceberg") spark.sql("INSERT INTO newdata VALUES 3, 4, 5, 6") spark.sql("SELECT * FROM newdata").show()輸出結果會與下列內容相似:
+---+ | id| +---+ | 3| | 4| | 5| | 6| +---+將新資料併入基本資料表。
spark.sql("""MERGE INTO base_table USING newdata ON base_table.id = newdata.id WHEN MATCHED THEN UPDATE SET base_table.id = newdata.id WHEN NOT MATCHED THEN INSERT * """) spark.sql("SELECT * FROM base_table").show()輸出結果會與下列內容相似:
+---+ | id| +---+ | 0| | 1| | 2| | 3| | 4| | 5| | 6| +---+更新基本資料表中的記錄。
spark.sql( "UPDATE base_table SET id = (id + 100) WHERE (id % 2 == 0)" ) spark.sql("SELECT * FROM base_table").show()輸出結果會與下列內容相似:
+---+ | id| +---+ | 3| |104| | 5| |106| |100| |102| | 1| +---+從基礎資料表刪除記錄。
spark.sql("DELETE FROM base_table WHERE (id % 2 == 0)") spark.sql("SELECT * FROM base_table").show()輸出結果會與下列內容相似:
+---+ | id| +---+ | 3| | 5| | 1| +---+
查詢歷史快照
查詢特定快照 ID,即可擷取資料表的舊版本。這項作業也稱為「時空旅行」。
在
MERGE、UPDATE和DELETE作業之前,擷取資料表版本的快照 ID。snapshot_ids = spark.sql( "SELECT snapshot_id FROM `NAMESPACE_NAME`.`base_table`.snapshots" ).collect() oldest_snapshot_id = snapshot_ids[1]["snapshot_id"]將
NAMESPACE_NAME替換為您建立的命名空間。使用擷取的快照 ID 查詢資料表。
df = ( spark.read.format("iceberg") .option("versionAsOf", oldest_snapshot_id) .load("base_table") ) df.show()輸出內容會顯示
MERGE作業後的資料表狀態,但不會顯示任何UPDATE或DELETE作業。+---+ | id| +---+ | 0| | 1| | 2| | 3| | 4| | 5| | 6| +---+
探索資料歷程
您可以使用資料沿襲,追蹤 Lakehouse 執行階段目錄和 Iceberg REST 目錄資料表之間的資料移動情形。這項功能適用於 Managed Service for Apache Spark 2.2 以上版本。
資料歷程範例
建立來源和目標 Iceberg 資料表,然後複製資料。
spark.sql("DROP TABLE IF EXISTS source_table PURGE") spark.sql("DROP TABLE IF EXISTS target_table PURGE") spark.sql("CREATE TABLE source_table (id LONG) USING iceberg") spark.sql("""CREATE TABLE target_table USING ICEBERG AS SELECT max(id) as top_id FROM source_table """)前往 Google Cloud 控制台的 Knowledge Catalog「Search」(搜尋) 頁面。
搜尋其中一個資料表,然後按一下「
Lineage」分頁標籤: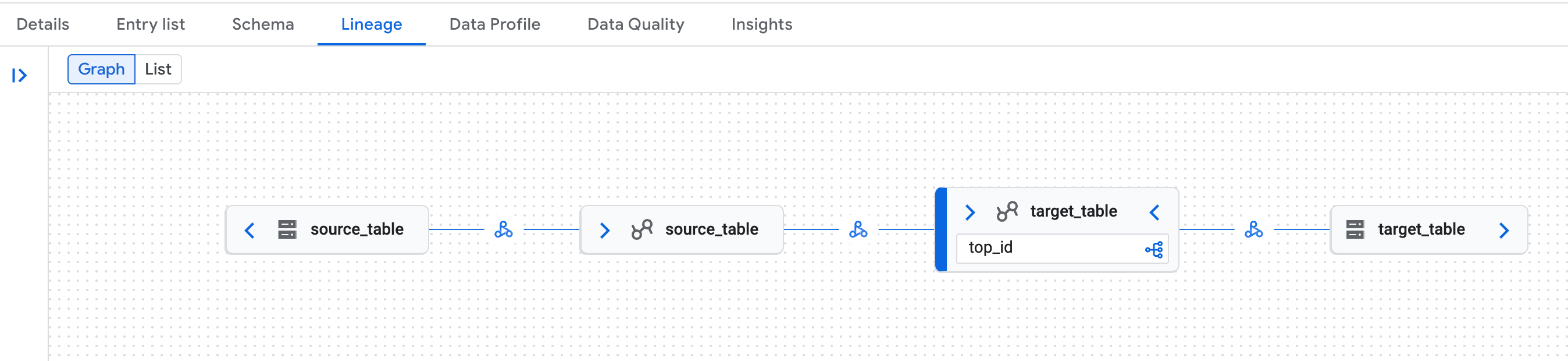 Google Cloud 控制台的 Knowledge Catalog 頁面中,資料歷程圖的範例。
Google Cloud 控制台的 Knowledge Catalog 頁面中,資料歷程圖的範例。資料沿襲會辨識 Lakehouse 執行階段目錄 Iceberg REST 目錄資料表的邏輯 (Lakehouse 執行階段目錄資料表) 和實體 (Cloud Storage) 呈現方式。
資料歷程已知問題
在某些 Managed Service for Apache Spark 叢集中,由於 OpenLineage 程式庫問題,可能無法產生完整資料沿襲。解決方法:在 Spark 工作階段設定中,將 spark.sql.catalog.{catalog_name}.uri 屬性設為 https://biglake.googleapis.com/iceberg/v1beta/restcatalog。
後續步驟
- 進一步瞭解 Lakehouse 執行階段目錄 Iceberg REST 目錄。
- 瞭解 Apache Iceberg 的功能。
- 瞭解如何從 Lakehouse 執行階段目錄查詢 Iceberg 資料。
- 進一步瞭解資料沿襲和 Managed Service for Apache Spark。