

커넥터는 Google 및 서드 파티 데이터 소스에서 Gemini Enterprise로 데이터를 가져와 전용 데이터 스토어에 저장합니다. 이 문서에서는 이러한 커넥터에 대해 간략하게 설명합니다. Gemini Enterprise에서 데이터를 중앙 집중화하면 데이터 접근성, 검색 기능, 분석 기능이 향상됩니다.
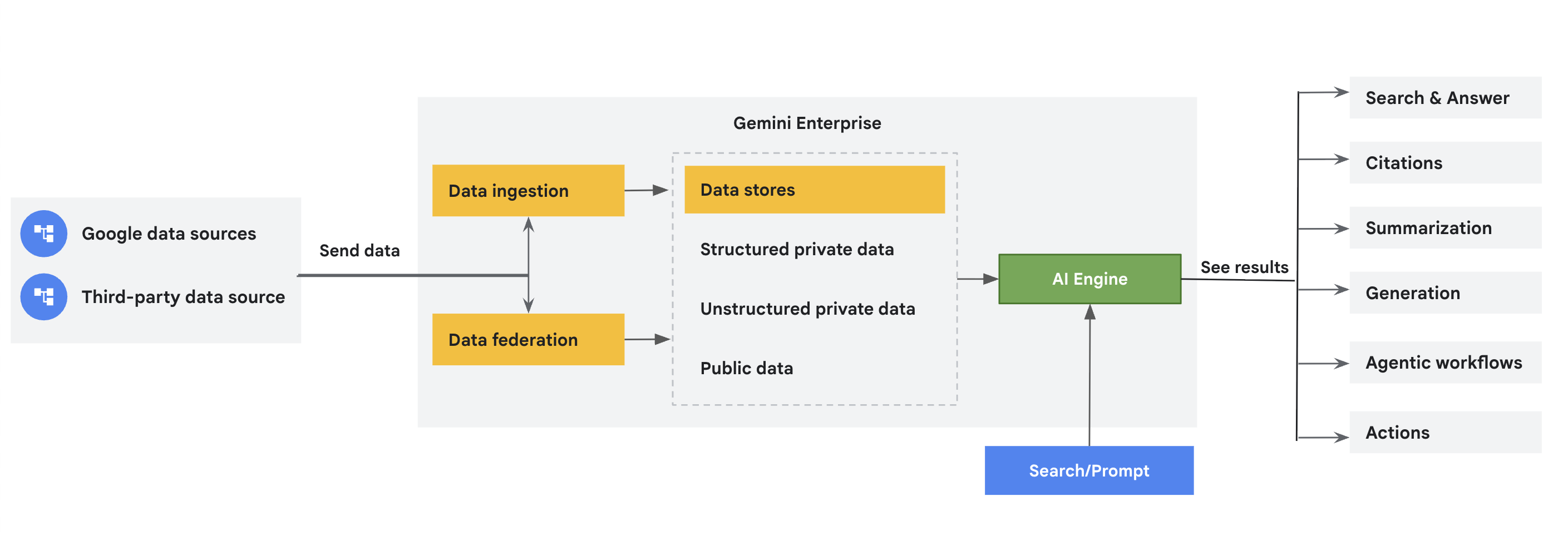
커넥터 및 데이터 스토어 개념
데이터 스토어 |
| 각 데이터 소스는 항목 유형 집합을 지원합니다. 예를 들어 Jira Cloud에는 데이터 소스에 고유한 문제, 첨부파일, 댓글, 작업 로그와 같은 항목이 있습니다. Gemini Enterprise는 항목마다 별도의 데이터 스토어를 만듭니다. 따라서 Google Cloud 콘솔을 사용하여 데이터 스토어를 만들면 이러한 수집된 데이터 항목을 나타내는 데이터 스토어 컬렉션이 생성됩니다. |
데이터 제휴와 수집 (색인 생성) 비교 |
| 데이터 제휴는 지정된 데이터 소스에서 정보를 직접 가져옵니다. 데이터가 Vertex AI Search 색인에 복사되지 않으므로 데이터 스토리지를 걱정할 필요가 없습니다. 하지만 데이터가 색인화되지 않으므로 검색 품질이 낮아질 수 있습니다. 데이터 수집 (색인화)은 데이터를 Vertex AI Search 색인에 복사합니다. 이렇게 하면 검색 품질이 향상될 수 있습니다. 하지만 이 프로세스는 더 많은 스토리지와 시간을 소비합니다. 커넥터가 데이터 페더레이션과 데이터 수집을 모두 지원하는 경우 원하는 데이터 연결 방법을 선택합니다. |
비정형 데이터 |
| 지원되는 데이터 형식은 데이터 소스 및 항목 유형에 따라 다릅니다. 엔티티의 콘텐츠가 PDF, HTML, DOCX, PPTX, XLSX, XLSM과 같은 비정형 형식으로 저장된 경우 Vertex AI Search에서 비정형 데이터 스토어를 만듭니다. 자세한 내용과 지원되는 파일 형식은 비정형 검색을 참고하세요. |
구조화된 데이터 |
| 지원되는 데이터 형식은 데이터 소스 및 항목 유형에 따라 다릅니다. 엔티티의 콘텐츠가 구조화된 형식으로 저장된 경우 Vertex AI Search에서 구조화된 데이터 스토어를 만듭니다. 자세한 내용은 구조화된 검색을 참고하세요. |
데이터 스키마 |
| 데이터 스키마는 데이터 구조를 정의합니다. Gemini Enterprise를 사용하여 구조화된 데이터를 가져오면 시스템에서 스키마를 자동 감지합니다. 자동 감지된 스키마를 사용하거나 API를 사용하여 스키마를 정의할 수 있습니다. 자세한 내용은 스키마 제공 또는 자동 감지를 참고하세요. |
데이터 스토어 리전 |
| 데이터를 수집할 때는 데이터를 저장할 리전(예: 전역, 미국 또는 EU)을 선택해야 합니다. 자세한 내용은 데이터 상주 및 ML 지역 처리 약정을 참고하세요. 미국 또는 EU 리전에 저장된 데이터에는 데이터 암호화가 필요합니다. 기본 암호화는 Google-owned and Google-managed encryption key를 사용하지만 고객 관리 암호화 키를 사용할 수도 있습니다. |
데이터 동기화 |
데이터 동기화는 원래 데이터 소스에서 ID 데이터 (예: 역할, 권한, 사용자)와 엔티티 데이터 (예: 특정 데이터 소스와 관련된 데이터)를 가져와 업데이트합니다. 자세한 내용은 데이터 동기화 유형 및 일정을 참고하세요. |
데이터 동기화 유형 및 일정
데이터 동기화는 항목 데이터, ID 데이터 또는 둘 다를 캡처하고 Gemini Enterprise의 데이터 스토어 콘텐츠를 업데이트합니다.
동기화 유형
Gemini Enterprise의 데이터 스토어는 두 가지 필수 데이터 동기화 유형을 사용합니다.
전체 동기화는 서드 파티 앱 또는 서비스의 전체 상태를 캡처합니다. 여기에는 추가, 업데이트, 삭제가 포함됩니다. 전체 동기화는 데이터 스토어의 기존 콘텐츠를 대체합니다.
증분 동기화는 마지막 동기화 이후 추가되거나 업데이트된 항목 데이터를 주기적으로 캡처합니다. ID 데이터 또는 엔티티 데이터 삭제는 동기화되지 않습니다.
다음 데이터 유형에 대해 전체 동기화를 별도로 예약할 수 있습니다.
엔티티 동기화는 서드 파티 데이터 소스에 특정한 데이터를 캡처합니다. 예를 들어 Jira와 같은 시스템의 데이터 저장소는 문제, 작업 로그, 댓글, 첨부파일을 동기화할 수 있습니다. 엔티티 동기화에는 ID 정보가 포함되지 않습니다.
ID 동기화는 ACL 그룹과 연결된 사용자 계정에 관한 데이터를 캡처합니다.
ID 동기화와 전체 동기화 간의 상호작용
개별 ID 동기화 실행이 전체 동기화 실행과 어떻게 작동하는지 이해하려면 ACL 그룹 group_1에 연결된 page_1 페이지와 ACL 그룹 group_2에 연결된 page_2 페이지가 포함된 예시 시나리오를 고려하세요.
초기 ID 동기화가 실행되고 그룹
group_1및group_2에 관한 정보를 가져옵니다.group_1에 사용자user_1이 포함되어 있다고 가정합니다.group_2에 사용자user_2이 포함되어 있다고 가정합니다.
이 ID 동기화는 다음 매핑을 설정합니다.
user_1는group_1로 매핑됩니다.user_2는group_2로 매핑됩니다.
ID 동기화와 함께 전체 동기화가 실행되어
page_1와page_2를 모두 가져옵니다.이 전체 동기화는 다음 매핑을 설정합니다.
user_1님이group_1앱을 통해page_1에 액세스할 수 있습니다.user_2님이group_2앱을 통해page_2에 액세스할 수 있습니다.
동기화 일정
각 데이터 스토어에 대해 다양한 동기화 유형의 빈도를 선택할 수 있습니다.
모든 ID 데이터와 엔티티 데이터의 전체 동기화는 3시간, 6시간, 12시간, 1일 또는 3일마다 동시에 예약할 수 있습니다.
모든 ID 데이터의 독립적인 전체 동기화와 모든 항목 데이터의 독립적인 전체 동기화는 다음 맞춤 동기화 빈도 중 하나를 사용하여 별도로 예약할 수 있습니다.
엔티티 데이터: 3시간, 6시간, 12시간, 1일, 3일, 5일, 7일마다
ID 데이터: 30분, 1시간, 3시간, 6시간, 12시간, 1일, 3일, 5일, 7일마다
업데이트되거나 추가된 항목 데이터의 증분 동기화는 3시간, 6시간, 12시간, 1일, 3일, 5일 또는 7일마다 예약할 수 있습니다. 기본적으로 증분 동기화는 3시간마다 실행됩니다.
빈도 추천
가져온 레코드 수와 권장 초당 쿼리 수 (QPS)에 맞는 데이터 동기화 빈도를 선택합니다.
다음 표에는 1일, 3일, 5일, 7일 동기화에서 가져오는 일반적인 레코드 수가 나와 있습니다. 실제 레코드 수는 데이터 소스와 해당 구성에 따라 다를 수 있습니다.
| QPS | 1일 동기화의 녹음 볼륨 | 3일 동기화의 녹음 볼륨 | 5일 동기화의 녹음량 | 7일 동기화의 녹음 볼륨 |
|---|---|---|---|---|
| 5 | 432,000 | 129만 6천 | 216만 | 3개월 |
| 10 | 864,000 | 259만 2천 | 432만 | 6개월 |
| 20 | 170만 건 | 510만 | 850만 | 1,190만 |
| 50 | 430만 | 1,290만 | 2,150만 | 3,010만 |
| 100 | 860만 | 2,580만 | 4,300만 | 6,020만 |
동기화 일시중지 및 재개
전체 동기화와 증분 동기화를 모두 일시중지하고 재개할 수 있습니다.
동기화 유형을 일시중지하면 데이터 저장소에서 해당 유형의 진행 중인 동기화를 취소하고 해당 유형의 새 동기화 예약을 중지합니다.
동기화 유형을 재개하면 데이터 스토어는 마지막으로 예약된 동기화 시간을 기준으로 새 동기화를 예약하지만 이전에 중단된 동기화는 계속하지 않습니다.
예를 들어 전체 동기화가 진행되는 동안 전체 동기화를 일시중지하면 데이터 저장소에서 해당 동기화를 취소합니다. 나중에 전체 동기화를 재개하면 데이터 스토어에서 전체 동기화 일정에 따라 새 전체 동기화를 자동으로 예약합니다.
Google 데이터 소스
BigQuery, Spanner, Google Drive와 같은 Google 데이터 소스에 연결할 수 있습니다.
Google 데이터 소스 체크리스트
Gemini Enterprise에 데이터를 보내기 전에 다음 체크리스트를 확인하세요.
데이터 소스의 액세스 제어를 설정합니다. 자세한 내용은 ID 및 권한을 참고하세요.
데이터를 연합할지 또는 처리 (색인 생성)할지 결정합니다.
데이터를 동기화할 빈도를 결정합니다.
고객 관리 암호화 키 (CMEK)를 사용하는 경우 다중 리전 키를 만듭니다. 자세한 내용은 서드 파티 데이터 소스용 단일 리전 키 등록을 참고하세요.
개인 식별 정보 (PII)가 있고 쿼리 추천에 자동 완성 기능을 사용하려는 경우 PII 유출 방지를 참고하세요.
지원되는 Google 데이터 소스
| Google Drive | Gmail | Google Calendar | 사용자 검색 |

|

|

|

|
타사 데이터 소스
서드 파티 데이터 스토어는 서드 파티 애플리케이션 데이터를 Gemini Enterprise로 인제스트합니다.
서드 파티 데이터 소스 체크리스트
서드 파티 데이터 소스를 Gemini Enterprise에 연결하기 전에 다음 체크리스트를 확인하세요.
특정 데이터 소스에 대해 특정 범위와 권한을 구성해야 합니다. 서드 파티 애플리케이션의 관리자는 데이터 소스를 연결하고 인증 및 권한을 설정하는 데 필요한 사용자 인증 정보를 검토해야 합니다. 구체적인 범위와 권한에 대한 자세한 내용은 해당 서드 파티 데이터 소스 문서를 참고하세요.
데이터 스토어의 액세스 제어를 설정합니다. 자세한 내용은 ID 및 권한을 참고하세요.
데이터를 연합할지 또는 처리 (색인 생성)할지 결정합니다.
데이터가 수집되는 경우 데이터 소스에 데이터를 수집하는 데 사용하는 사용자 인증 정보에 리소스가 제한되지 않는지 확인합니다.
데이터를 동기화할 빈도를 결정합니다.
고객 관리 암호화 키 (CMEK)를 사용하는 경우 멀티 리전 및 단일 리전 키를 만듭니다. 자세한 내용은 서드 파티 데이터 스토어용 단일 리전 키 등록을 참고하세요.
개인 식별 정보 (PII)가 있고 쿼리 추천에 자동 완성 기능을 사용하려는 경우 PII 유출 방지를 참고하세요.
지원되는 서드 파티 데이터 소스
| Microsoft Entra ID | Microsoft OneDrive | Microsoft Outlook | Microsoft SharePoint |
|
|
|
|
|
| Jira Cloud | Confluence Cloud | ServiceNow | |
|
|
|
|